大模型幻觉本质:源于Transformer架构天生固有缺陷 + RAG根治方案参数调优.184
一、前言
不知道大家是不是也一样,做大模型应用做的久了,回过来头来总结思考,一直都有一个误区:总觉得大模型胡说八道、编造事实的幻觉问题,改改代码、修修bug、优化一下推理逻辑就能彻底解决。但实际行业踩过无数坑后才明白,幻觉从来不是程序故障,而是Transformer天生自带的架构短板。模型天生只擅长预测文字通顺概率,不擅长分辨真假对错,长上下文注意力衰减、知识分布冷热不均、采样逻辑发散,都会让模型一本正经地输出错误信息。不管是通用对话、政企问答、合同解析还是行业知识库,幻觉都会直接影响可信度、业务安全与落地合规。
今天我们抛开晦涩空洞理论,结合一线工程实操,从底层原理、成因逻辑、参数调节、RAG 根治方案、RLHF 对齐训练,再到企业私有化知识库真实避坑经验,由浅入深的总结一下如何识别、压制、规避大模型幻觉,用接地气、可落地、能直接上线使用的方法,用自己走过的弯路做一个阶段性总结,希望能让大伙也少踩踩坑,真正做出靠谱、严谨、少幻觉的商用大模型应用。

二、幻觉核心概念
1. 幻觉的基础定义
大模型幻觉,指代大模型在生成回答时,凭空编造不存在事实、虚假数据、错误关联逻辑、杜撰文献来源、歪曲真实常识,输出看似通顺流畅、语法严谨、逻辑连贯,却与客观真实世界完全不符的内容。
起初我们初次接触通常会误以为幻觉是代码漏洞、程序异常、部署bug、模型微调失误导致的故障问题,只要修复补丁、优化推理逻辑就能彻底消除。但行业长期技术验证结论表明,幻觉永远无法彻底根除,只能压制、规避、约束、降低发生概率,根源不在于后天开发失误,而在于Transformer自注意力原生架构底层逻辑缺陷。
大模型本质是序列文本概率预测模型,并非事实记忆数据库,训练全程学习文字上下文关联规律,而非客观真理对错,天生就不具备事实校验、真伪判断、逻辑溯源能力,通顺优先于真实,流畅优先于准确,这是幻觉诞生的底层宿命。
2. 幻觉类型与危害
大模型幻觉主要分为三类:
- 事实型幻觉,编造时间、人物、事件、数据、政策条款;
- 关联型幻觉,强行拼接无关知识,构建虚假因果逻辑;
- 引用型幻觉,杜撰文献、论文、接口返回、知识库内容。
在通用对话场景幻觉影响有限,但是金融、医疗、法律、政企知识库、政务问答、企业内控场景,幻觉会直接造成决策失误、合规风险、业务损失、公信力崩塌。企业级大模型落地最大痛点不是效果不够智能,而是回答不可信、不可溯源、不可验证,幻觉直接限制大模型商用落地边界。
3. 幻觉的认知误区
在我们早期接触了解不深的情况下会混淆bug与架构缺陷:
- Bug 是偶然、可复现、可修复、异常报错问题;
- Transformer幻觉是必然、常态、不可根除、无报错正常输出。
Transformer依靠词元概率分布预测下一个字符,上下文语义通顺即为最优解,不需要匹配客观事实,架构本身没有内置事实校验模块、知识溯源链路、真假判别机制,只要文本序列合理,模型就会自信输出错误答案,这是架构原生逻辑,而非后天故障。
三、幻觉底层成因
1. Transformer自注意力机制
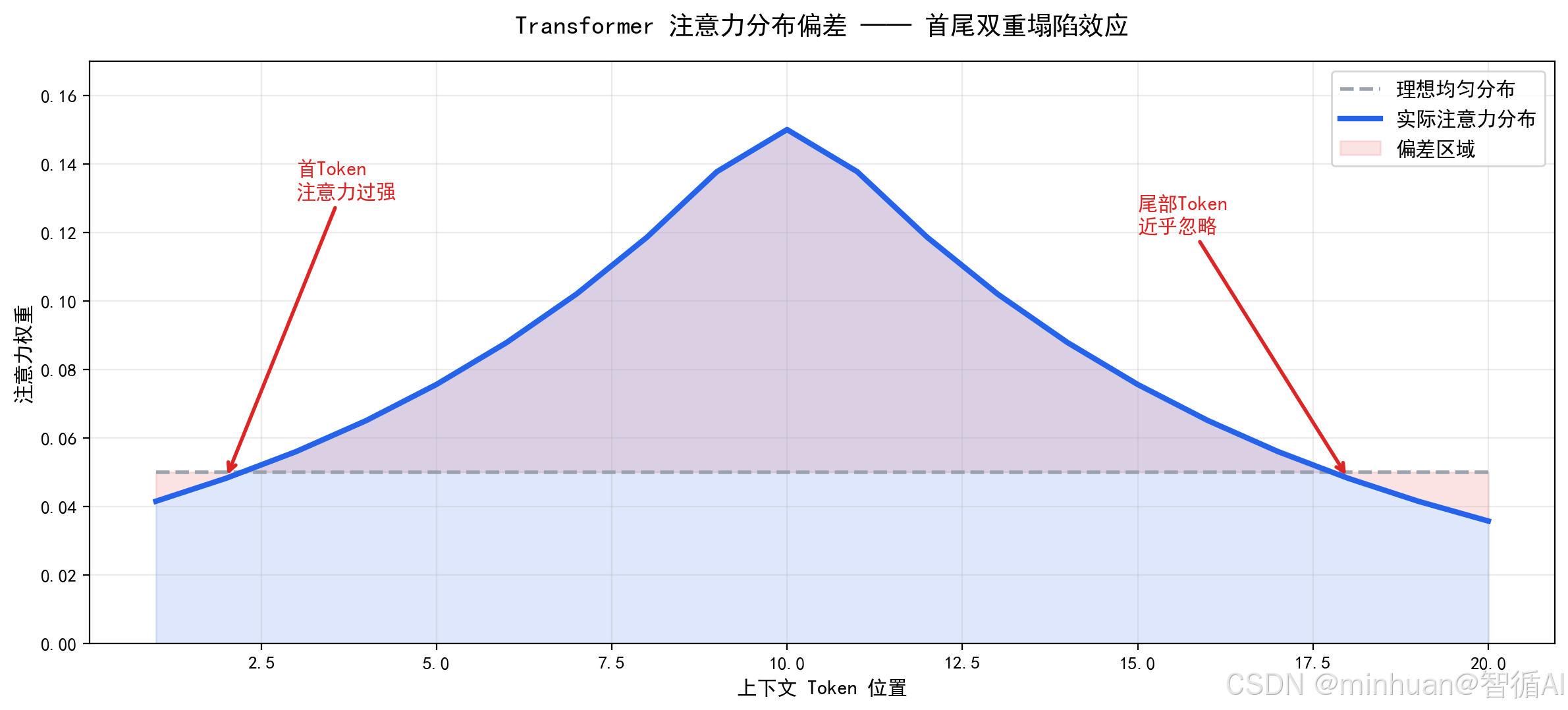
Transformer核心依靠多头自注意力机制计算每个词元之间关联权重,注意力权重决定模型重点关注上下文哪些内容。
长文本场景下,远距离词元注意力权重快速衰减,首尾信息关联断裂,模型无法精准抓取全局关键事实。局部相邻词汇注意力过度集中,远距离关键事实被忽略,模型依据局部碎片化语义编造完整逻辑链条,形成逻辑跳跃、前后矛盾、事实错位幻觉。
注意力权重归一化计算特性,会强制分配合理权重,即使信息缺失、信息冲突,依然会生成连贯语句,不会提示信息不足,只会自行补全虚假内容。多头注意力并行计算时,不同头注意力偏向不一致,语义融合混乱,进一步放大事实错乱问题。
2. 预训练语料知识分布
大模型预训练依托海量互联网文本,热门领域知识重复度极高,冷门专业知识稀疏零散,冲突知识大量共存。高频常识模型记忆牢固,低频专业知识记忆模糊、混淆、错乱。
模型遇到陌生问题时,不会如实告知无法回答,而是调取相似高频知识强行匹配答案,混淆相似概念、混淆相近事件、混淆同类术语,形成系统性知识幻觉。同时互联网本身存在大量错误信息、矛盾观点、虚假传闻,模型全盘学习文本规律,不会区分对错,只会复刻概率分布,错误知识同样被固化进模型权重。
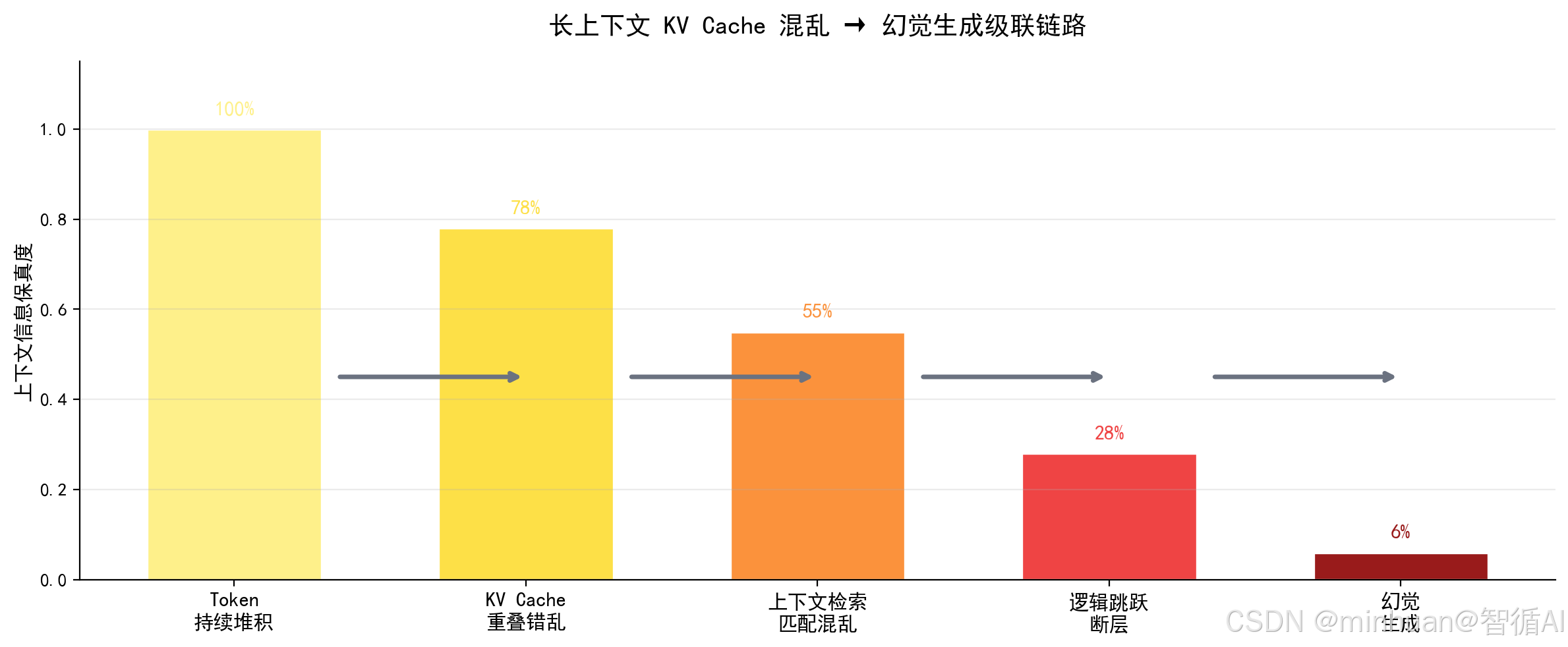
3. 长上下文检索混乱
长上下文场景下,词元序列长度扩张,注意力稀疏化加剧,KV缓存键值对混乱重叠,上下文信息检索匹配错乱。模型无法有序梳理长文档因果、时间、从属逻辑,只能跳跃式拼接语义片段。
上下文越长,注意力漂移越严重,前后逻辑无法闭环,事实依据不断丢失。模型依靠语义通顺度填补逻辑空白,不断编造衔接内容,最终出现严重逻辑断层、前后矛盾、时间错乱、主体错位,长文本幻觉爆发概率呈指数级上升。
四、长上下文幻觉机理
1、长序列Transformer注意力稀疏退化机制
- 标准Transformer在序列长度超过阈值后,注意力矩阵复杂度指数上升,注意力稀疏效应显著。
- 远距离依赖建模能力极差,上下文关键事实无法被有效聚焦,模型只能依赖局部上下文推断全局内容。
- 上下文窗口越长,信息遗忘越快,关键事实丢失越严重,幻觉越严重。
- FlashAttention、PagedAttention 虽优化推理速度与显存占用,但并未从架构上解决远距离注意力偏差问题,仅缓解显存压力,无法根治长文本幻觉。
2、KV缓存错乱引发检索匹配混乱原理
- 大模型推理阶段依靠KV Cache存储上下文键值信息,长上下文持续追加词元后,KV缓存重叠、错乱、覆盖、优先级混乱。
- 历史知识、最新知识、关联知识检索优先级错乱,模型无法精准调取对应事实依据,随机选取语义相近内容作答。
- 键值对无序堆积,事实关联错乱,直接诱发无依据推断、虚假关联、逻辑跳跃幻觉,企业长文档问答、合同解析、财报分析高频出现此类问题。
3、上下文语义稀释与逻辑链条断裂全过程
- 海量上下文叠加后,核心事实被次要信息稀释,语义权重被无关内容挤占。
- 模型逻辑链条无法逐层推导,只能跳跃总结、模糊概括、主观推演。
- 长文档问答不会逐句溯源校验,只会整体语义归纳,极易歪曲原文含义、篡改数据、颠倒因果、遗漏关键约束,形成高隐蔽、高危害逻辑幻觉,人工很难快速识别错误。
五、RAG 根治方案
1. RAG架构核心逻辑
RAG架构的核心逻辑是模型不记忆知识,只检索知识, 原生大模型依靠权重内嵌静态知识,极易过期、错乱、幻觉;
RAG 检索增强生成,剥离模型内置知识记忆,所有专业事实全部来自外部结构化知识库。推理阶段先检索相关文档片段,再把精准上下文注入模型提示词,模型只做阅读理解总结,不做原创事实编造,从根源切断幻觉生成源头。
Transformer架构缺陷无法改变,但可以用外部可信数据源约束输出,强制模型依据真实资料作答,大幅降低幻觉概率。
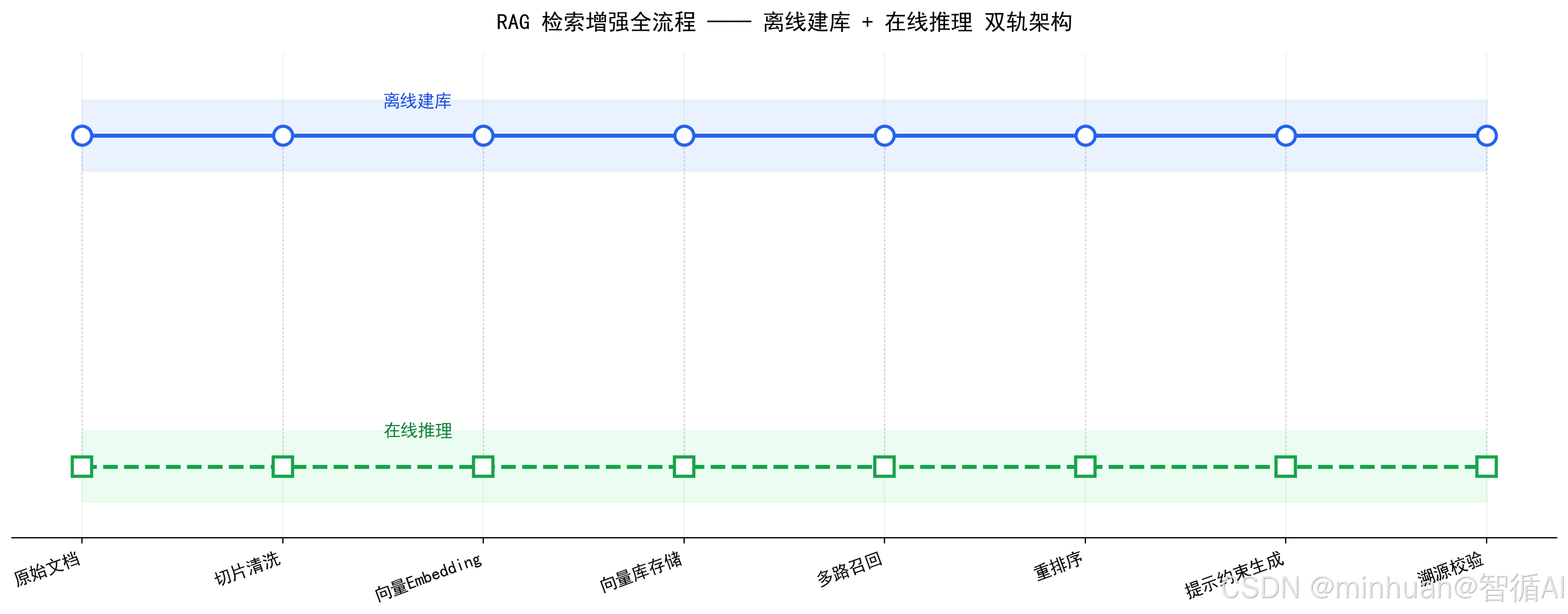
2. RAG标准执行步骤

- 1. 知识库预处理:文档清洗、格式统一、去重纠错、分段切片、冗余剔除、敏感内容过滤,保证原始数据源100%真实准确。
- 2. 向量结构化处理:文本切片向量化,构建向量数据库,优化分片粒度、重叠窗口、元数据标签。
- 3. 召回检索优化:多路召回 + 关键词检索 + 向量检索混合检索,提升相关度准确率,过滤无关噪声片段。
- 4. 重排序精排:使用轻量重排模型筛选 Top 高相关片段,剔除低相关干扰内容。
- 5. 提示词工程约束:严格指令限定只引用检索内容,禁止自由发挥、禁止拓展延伸、禁止编造信息。
- 6. 后处理校验:事实溯源、片段匹配校验、重复内容过滤、冲突内容告警。
3. 向量检索优化与幻觉防控
分片长度不合理会导致语义残缺、事实割裂,重叠窗口不足会导致上下文不连贯;向量模型精度不足会召回无关文档,直接诱发幻觉。
- 采用多级分片、分层索引、Metadata精准过滤、时间权重过滤、权限分级检索,提升召回精准度。
- 限制单次检索片段数量,避免上下文过长再次触发注意力混乱。
- 加入引用标注机制,每一条回答都绑定原文片段来源,实现事实可溯源、可核对、可追责,彻底解决幻觉不可验证难题。
4. RAG应用幻觉防控示例
以下示例用faiss向量库+多语言语义模型构建企业知识库RAG检索链路,将用户问题精准匹配到唯一事实来源,拼接成严格约束Prompt喂给大模型,从根源上杜绝幻觉编造。
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
from modelscope import snapshot_download
# 1. 加载多语言向量模型(支持中文语义),构建企业知识库切片
cache_dir = "D:\\modelscope\\hub"
embedding_model_dir = snapshot_download(
model_id="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2", # ★ 多语言模型,支持中文
cache_dir=cache_dir,
revision="master"
)
model = SentenceTransformer(embedding_model_dir)
knowledge_chunks = [
"2025企业所得税税率一般为25%",
"小规模纳税人增值税征收率现行1%",
"劳动合同试用期最长不得超过6个月"
]
# 2. 文本向量化,构建向量库
embeddings = model.encode(knowledge_chunks)
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings).astype(np.float32))
# 3. 用户提问检索,只召回真实知识库内容,根治幻觉
query = "企业所得税税率是多少"
query_emb = model.encode([query])
D, I = index.search(np.array(query_emb).astype(np.float32), k=2)
# 4. 打印检索结果验证
print("【检索结果验证】")
print("-" * 50)
for i, (idx, dist) in enumerate(zip(I[0], D[0])):
print(f" Top{i+1}: 距离={dist:.4f} | {knowledge_chunks[idx]}")
print("-" * 50)
# 5. 拼接精准检索上下文,约束大模型不编造
retrieve_text = "\n".join([knowledge_chunks[i] for i in I[0]])
prompt = f"""
严格依据以下知识库内容回答,禁止编造、禁止延伸、禁止虚构信息:
{retrieve_text}
用户问题:{query}
"""
print("\n防控幻觉标准Prompt:\n", prompt)输出结果:
【检索结果验证】
--------------------------------------------------████████████████| 449M/449M [04:28<00:00, 3.16MB/s]
Top1: 距离=11.4082 | 2025企业所得税税率一般为25%
Top2: 距离=11.4561 | 小规模纳税人增值税征收率现行1%
--------------------------------------------------防控幻觉标准Prompt:
严格依据以下知识库内容回答,禁止编造、禁止延伸、禁止虚构信息:
2025企业所得税税率一般为25%
小规模纳税人增值税征收率现行1%
用户问题:企业所得税税率是多少
六、采样参数调优
1. 温度参数与幻觉关联关系
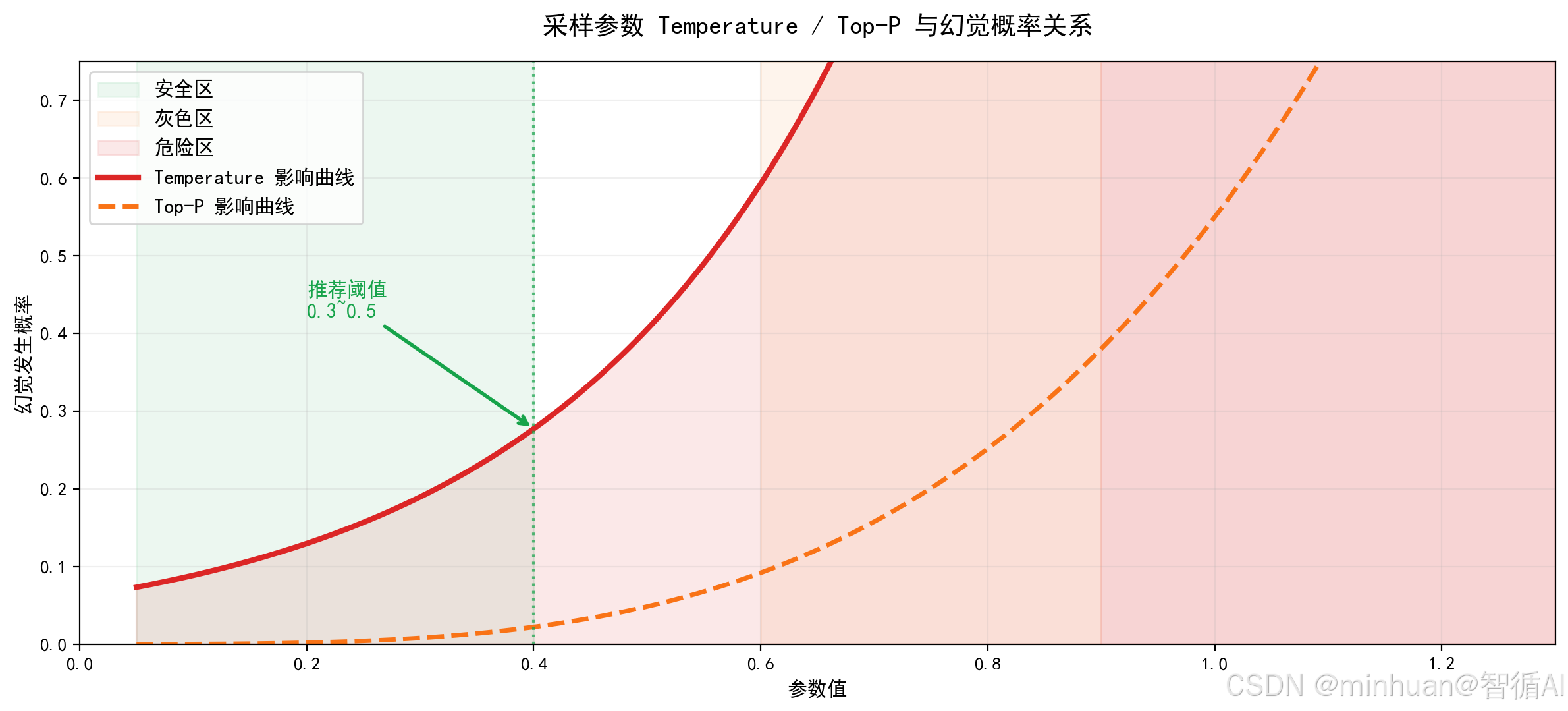
温度temperature控制模型输出随机性、发散程度、概率分布平滑度:
- 温度数值越高,模型越愿意选择低概率词汇,发散创作能力越强,逻辑联想越自由,编造内容概率越高,幻觉爆发越频繁。
- 温度越低,模型越保守,只选择最高概率词汇,输出严谨刻板,重复度高,幻觉概率显著下降。
- 温度趋近0时,模型接近贪心解码,几乎不编造内容,但表达生硬、逻辑死板、交互体验差。
政企知识库、金融法律场景必须压低温度,通用闲聊场景可适度抬高温度。
2. top_p核采样阈值调控原理
top_p限定模型只选取累计概率在前N%的词汇集合,截断长尾低概率异常词汇。
- top_p数值越大,可选词汇范围越广,创意越强,幻觉风险越高;
- top_p越小,可选词汇越集中,输出越稳定严谨,幻觉越少。
- top_p过高会让模型大量选用小众冷门词汇,自由拼接陌生语义,凭空构建虚假逻辑;
- top_p过低会导致语句单调、重复、句式僵化,丢失对话流畅性。
温度与top_p联动配合,单一参数调整无法最优压制幻觉。
3. 标准参数组合调优配比
- 通用问答:温度 0.3~0.5,top_p 0.7~0.8,平衡流畅度与幻觉风险。
- 企业知识库严谨问答:温度 0.1~0.2,top_p 0.3~0.5,极致压低幻觉,优先事实准确。
- 长文档专业解析:温度 0.2~0.3,top_p 0.4~0.6,兼顾长上下文逻辑与事实真实性。
- 创意生成场景:温度 0.6~0.9,top_p 0.8~0.9,接受适度幻觉换取表达丰富度。
同时搭配重复惩罚参数、存在惩罚参数,抑制模型重复编造、无依据延伸内容,进一步降低幻觉概率。
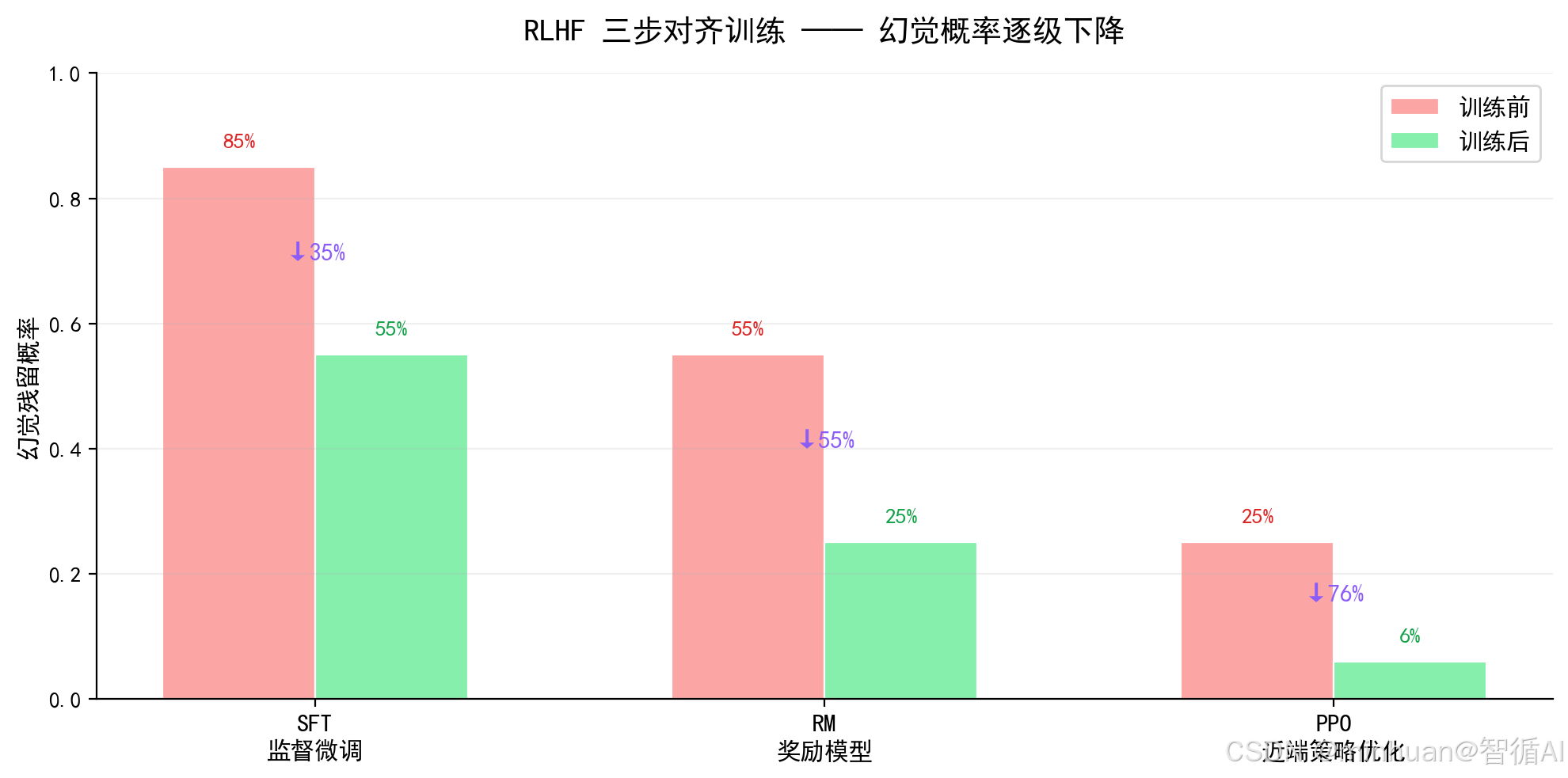
七、RLHF 对齐训练
1. 基础概念
RLHF即基于人类反馈的强化学习对齐训练,是大模型主流对齐方案。通过人工标注问答优劣、训练奖励模型打分,再用强化学习优化模型输出,约束模型减少幻觉、逻辑错误,让回答更贴合事实、安全严谨,不改变 Transformer 原生架构,仅修正生成偏好。
2. 核心作用
主要是修正模型价值观与事实优先级,原生Transformer预训练全程只学习文本上下文流畅概率,只要语句通顺、衔接自然,模型就判定为优质输出,完全不区分内容真假、逻辑对错、是否符合客观事实。这也是模型一本正经胡说八道的根源,通顺优先级远高于真实性。
RLHF人类反馈强化对齐,本质就是重新给模型树立作答规则,强行调整模型输出权重偏好,把事实准确、严谨有据放在第一位,语句流畅自然放在第二位。通过人工打分、优劣对比、奖惩机制,让模型慢慢记住:编造信息会被惩罚,如实回答、有据作答会被奖励,信息不足时主动说明无法作答,而不是随意脑补、拼接逻辑、杜撰内容。整个过程不会改动Transformer原生注意力架构,无法修复底层天生缺陷,但能大幅约束模型输出习惯,从生成源头主动减少幻觉概率,是大模型应用必做的标准化对齐工序。
3. 完整流程

1. 第一步:SFT监督微调
基础规范训练:先整理大量高质量、零幻觉、事实严谨的行业问答样本,用监督微调方式让模型模仿标准答案格式。
让模型学习固定回答逻辑:引用依据、不随意延伸、不跨领域联想、不模糊推断,规范句式结构与作答边界,从源头减少自由发散式编造,打好事实回答基础,降低基础常识幻觉。
2. 第二步:RM奖励模型训练
幻觉判别打分:单独训练一个轻量化判别模型,专门用来识别大模型回答是否存在幻觉、事实错误、逻辑跳跃、虚假引用。
人类对同一问题多个答案打分排序,优质真实回答高分,幻觉错误回答低分,让奖励模型学会自动评判答案可信度,替代人工逐句校验,实现自动化幻觉评分。
3. 第三步:PPO近端策略优化
持续奖惩迭代:以奖励模型分数作为优化目标,不断迭代模型权重。模型输出高分严谨内容就持续强化,频繁产生幻觉、编造内容就持续削弱对应词元概率。
长期迭代后,模型会自发规避高幻觉话术,优先选择稳妥、真实、低风险表述,系统性降低整体幻觉发生率。
4. RLHF局限性
RLHF只能优化模型输出偏好,无法解决Transformer注意力衰减、长上下文检索混乱、知识分布不均天生架构问题。冷门小众知识、超长文档问答、跨专业交叉问题,依旧极易出现幻觉。
单独依靠RLHF完全达不到企业私有化安全标准,必须和RAG检索溯源、推理参数限流、提示词强约束、输出事后校验搭配使用。同时过度对齐会引发对齐退化、模型过度谨慎、拒绝正常回答、话术死板重复,出现对齐过拟合,需要严格控制训练轮次与奖惩强度,平衡智能度与准确性。
5. 通俗示例理解
问题:某行业政策正式生效日期是哪天?
- 原生大模型:只看语句通顺度,自己脑补一个日期,回答流畅自然,但时间完全错误,形成典型事实幻觉。
- 人工打分标注:人类对比多条答案,精准标准答案打高分,编造、猜测、模糊答案打低分,划分好坏等级。
- RM奖励模型学习:模仿人类打分逻辑,自动识别对错,稳定给真实内容高分、幻觉虚假内容低分。
- PPO策略优化:模型频繁输出高分正确内容就加强权重,频繁编造错误内容就降低生成概率。长期训练后,模型遇到不确定信息不会强行瞎编,会如实说明信息不足,优先依据事实严谨作答。
6. SFT→RM→PPO压制幻觉示例
示例通过劳动法试用期问答场景,用极简代码演示 RLHF人类反馈强化学习三阶段核心逻辑:SFT 提供标准答案、RM 奖励模型自动评分区分事实与幻觉、PPO 根据奖励反馈压制模型幻觉生成概率,抽象展现大模型对齐训练的本质。
# ===================== 1.SFT监督微调:用正确标准答案规范模型作答 =====================
# 高质量无幻觉标准答案
sft_good_data = [
{"question": "劳动法试用期最长多久?",
"answer": "根据劳动合同法规定,试用期最长不得超过6个月"}
]
# 模型原生幻觉错误答案
sft_bad_hallucination = [
{"question": "劳动法试用期最长多久?",
"answer": "劳动合同试用期一般可以约定1年左右"}
]
print("【SFT监督微调】")
print("标准正确回答:", sft_good_data[0]["answer"])
print("模型原生幻觉回答:", sft_bad_hallucination[0]["answer"])
print("-"*60)
# ===================== 2.RM奖励模型:自动识别幻觉并打分 =====================
def reward_model_score(answer):
# 规则模拟人类偏好:严谨有据高分,编造猜测低分
if "6个月" in answer:
return 0.95 # 事实准确 高奖励
elif "1年" in answer:
return 0.12 # 编造幻觉 低惩罚分
else:
return 0.3
# 分别打分
good_score = reward_model_score(sft_good_data[0]["answer"])
bad_score = reward_model_score(sft_bad_hallucination[0]["answer"])
print("【RM奖励模型打分】")
print(f"正确答案得分:{good_score}")
print(f"幻觉答案得分:{bad_score}")
print("-"*60)
# ===================== 3.PPO近端策略优化:压制幻觉、强化真实回答 =====================
class SimpleLLM:
def __init__(self):
self.hallucinate_prob = 0.8 # 初始幻觉生成概率很高
def reduce_hallucinate(self):
self.hallucinate_prob *= 0.3 # 低分幻觉→大幅降低生成权重
def enhance_truth(self):
self.hallucinate_prob *= 0.1 # 高分正确→压低幻觉概率
# 初始化模型
llm = SimpleLLM()
print(f"PPO训练前模型幻觉生成概率:{llm.hallucinate_prob:.2f}")
# 根据奖励分数执行策略更新
if bad_score < 0.3:
llm.reduce_hallucinate()
if good_score > 0.8:
llm.enhance_truth()
print(f"PPO对齐训练后幻觉生成概率:{llm.hallucinate_prob:.4f}")
print("经过RLHF训练,模型不再优先编造错误试用期时长,拒绝无依据猜测")输出结果:
【SFT监督微调】
标准正确回答: 根据劳动合同法规定,试用期最长不得超过6个月
模型原生幻觉回答: 劳动合同试用期一般可以约定1年左右
------------------------------------------------------------
【RM奖励模型打分】
正确答案得分:0.95
幻觉答案得分:0.12
------------------------------------------------------------
PPO训练前模型幻觉生成概率:0.80
PPO对齐训练后幻觉生成概率:0.0240
经过RLHF训练,模型不再优先编造错误试用期时长,拒绝无依据猜测
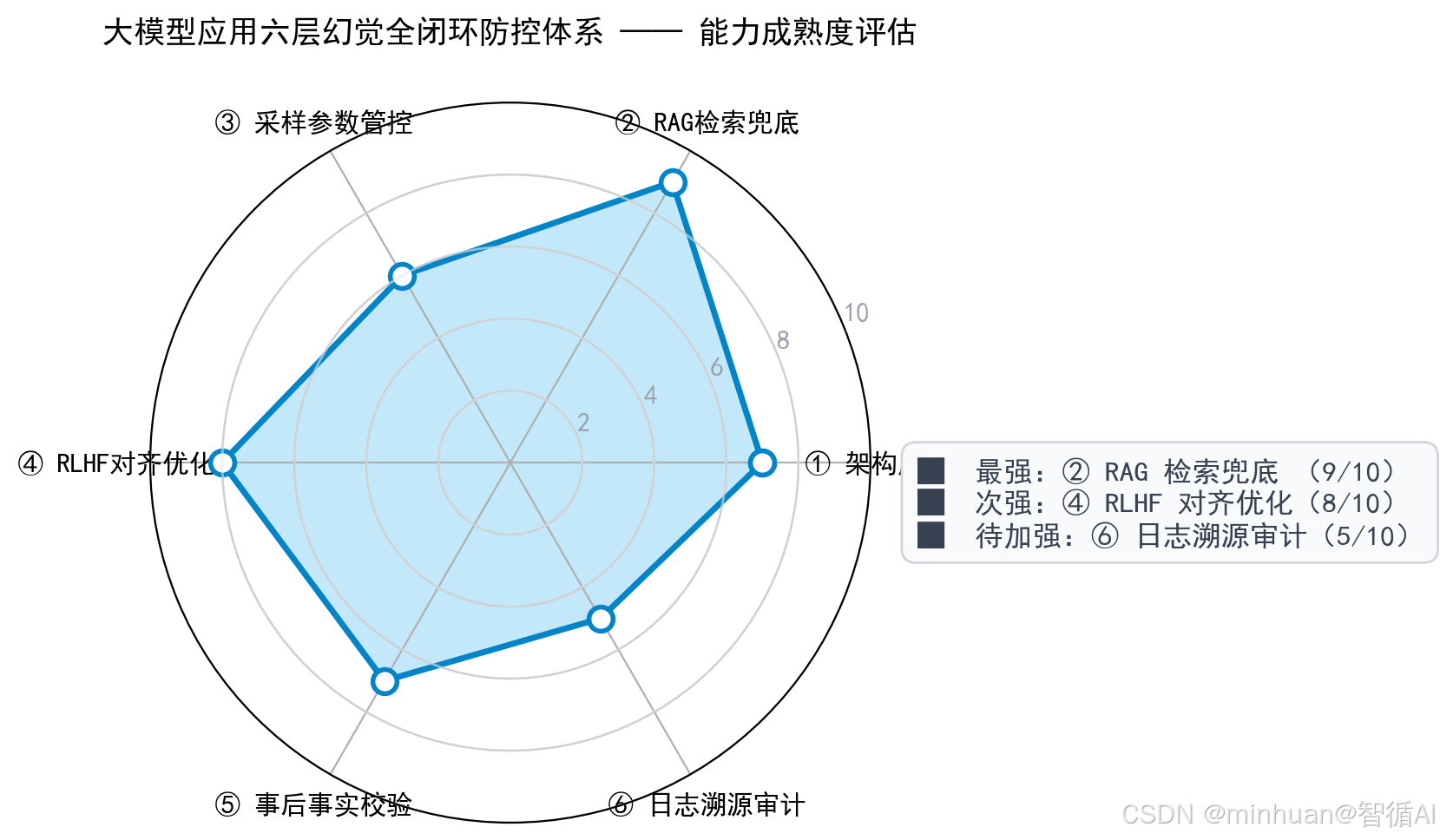
八、事后校验与事实溯源
1. 原生模型与RAG方案依旧存在残留幻觉原因
即便做好检索增强、采样调参、RLHF对齐训练,Transformer架构依旧无法100%杜绝幻觉。召回片段存在语义歧义、多文档交叉信息冲突、专业术语模糊、长上下文语义偏移、冷门知识匹配失败等问题,模型依然会在总结、归纳、转述环节自行补全逻辑,编造不存在关联关系。
通常大模型应用只做前端检索约束,不做后端输出校验,上线后频繁出现隐性幻觉,不容易被快速发现,长期积累会造成严重业务风险。事后校验不属于架构修补,而是大模型应用落地必备最后一道安全闸门,和RAG、参数、对齐训练形成四层防护,全方位压低幻觉概率。
2. 事实一致性校验、冲突检测、引用锚定全流程技术方案

- 1. 第一步做片段引用匹配校验,强制模型每一句关键结论都对应检索原文段落,不允许无依据独立表述。
- 2. 第二步做多源事实冲突检测,对比多条召回文档内容,出现数据、时间、条款不一致时,直接告警不生成确定性答案。
- 3. 第三步语义相似度比对,计算模型生成内容与知识库原文相似度,低于阈值判定为幻觉编造内容。
- 4. 第四步关键实体纠错,自动识别人物、金额、政策、条款、日期等核心信息,逐一核对知识库真实数据,拦截虚假实体。
整套流程轻量化部署,不占用过多推理算力,不影响接口响应速度,适配企业高频并发问答场景。
3. 溯源审计、幻觉日志沉淀与持续迭代优化机制
- 搭建完整回答溯源链路,用户每一条问答都留存检索来源、片段编号、上下文内容、模型输出、参数配置。
- 自动采集高频幻觉错误案例,归类事实错误、逻辑跳跃、上下文错乱、杜撰引用四大类型,定期更新幻觉样本库。
- 同步反向优化向量分片策略、召回权重、提示词约束、奖励模型打分规则,让幻觉问题越用越少。
- 同时对外输出可视化溯源报告,方便业务人员、合规人员快速核查答案真假,满足政企、金融、法务行业审计要求。
- 事后校验 + 前置防控双向配合,才是行业公认稳定、成熟、可长期商用的幻觉全链路治理方案。
九、总结
总的来说,大模型幻觉本质不是后天漏洞,而是Transformer自注意力机制与生俱来的缺陷,核心就是注意力分布失衡、训练知识冷热不均,越长上下文越容易出现检索混乱、逻辑跳跃、胡乱编造。想要彻底根治幻觉,不能只靠调参,也不能单靠模型微调,必须搭建一套组合解决方案:先用 RAG 检索增强把事实来源锁死在可信知识库,从根源不让模型自由编造;再合理调节温度、top_p采样参数,压低随机发散幻觉;接着通过RLHF人类反馈对齐,让模型养成严谨作答、不瞎杜撰的输出习惯;最后结合企业真实业务场景,做好文档切片、向量召回、溯源校验、多层风控运维。
日常开发不用追求完全消灭幻觉,架构本身做不到零幻觉,只要做到可控、可追溯、可校验、低概率出错,就完全满足应用需求。把底层原理理透、流程跑通、参数调好、链路闭环,就能低成本、高效率压制幻觉,让大模型既能流畅好用,又足够真实可靠,顺利落地各类私有化知识库与行业智能问答场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)