AI Agent 安全沙箱—给 Cube Sandbox 装一个“OJ 引擎“:让 4 个 LLM 解法在 4 个 MicroVM 里同台竞技
给 Cube Sandbox 装一个"OJ 引擎":让 4 个 LLM 解法在 4 个 MicroVM 里同台竞技
一道 LeetCode、4 个候选解法、4 个独立 MicroVM 并行评判 —— 这一篇我把 Cube Sandbox 当作"AI 代码评测的执行底座"用了一遍,跑出正确性 + 性能 + 内存 + 异常隔离四维度的真实成绩单,外加一份给上层 Agent 直接吃的 JSON / PNG / Markdown 三件套交付物。
全程在一台 OpenCloudOS 9.4 的腾讯云 CVM 上跑(IP
129.211.223.113,PVM 内核6.6.69-cube.pvm.host),所有命令、日志、截图均来自真实复现,文末附完整脚本,clone 即用。关键词:Cube Sandbox · Agent 代码执行 · OJ 评测 · MicroVM · E2B 兼容 · OpenCloudOS 9
0. 这次不写"沙箱有什么用",写一个真实的小工程
很多写沙箱的文章会停在 “Hello World” 或者"看,我能跑 rm -rf / 不影响宿主"。这两件事在第一次上手时确实有用,但是写过 Agent 的人很快会问下一个问题:
当我手里有 4 段 LLM 输出的代码 —— 来自 GPT-4o、DeepSeek-V3、Qwen2.5-Coder、本地的 Code Llama —— 我怎么知道哪一段"既对又快又安全"?
这是 AI Code Agent 工程里最日常的问题:评测。
而评测的本质就是 OJ(Online Judge)干的事:把不可信的代码丢进沙箱、喂测试用例、看是否通过、量耗时、量内存、设 timeout 兜底。OJ 这个工程范式已经被验证了 20 年(Codeforces、LeetCode、洛谷……),只是过去的"不可信代码"是参赛选手交的,现在变成了 LLM 生成的而已。
那这一篇就把这件事做小、做完、做出可复用的代码:
- 题目:LeetCode 42 接雨水(Trapping Rain Water),经典且解法分布广;
- 4 个候选:正确慢解(暴力 O(n²))、正确快解(双指针 O(n))、典型 LLM 幻觉式答错、纯死循环;
- 执行底座:4 个独立 Cube Sandbox MicroVM,并行跑、互不影响;
- 交付物:JSON 排行 + 沙箱内 matplotlib 画的 PNG 排行榜 + Agent 给用户的 Markdown 报告。
这不是 demo。这是一个真正可以塞进某个 AI Code Agent 评测后台的最小骨架。
1. 为什么是 Cube Sandbox
我跳过"什么是 MicroVM、什么是 E2B、PVM 内核怎么装"的科普 —— 这些第一篇文章已经写得很细了。这里只摆三条做这件事必须依赖的事实:
- Cube 的
Sandbox.create()是 60-150 ms 量级的,4 个并发也不会破百毫秒区间 —— 意味着我可以为每个候选解法开一个独立沙箱,而不必担心调度开销; - 每个沙箱是一份独立的 Linux 内核 + 独立的 rootfs,A 解法 OOM 或者 D 死循环,不会拖到 B 和 C —— 这是 OJ 评判的命根子;
run_code(code, timeout=N)是 SDK 自带的兜底,N 秒后直接抛TimeoutException,沙箱整个生命周期由 Pythonwith/kill()控制 —— 死循环代码不再是阻塞调度器的炸弹。
这三条加起来翻译成大白话:对一段我不信任的 Python,启动 60ms、跑出来的 stdout 我直接拿、卡死了 N 秒后自己回来 —— 我作为评测器的代码可以非常短。
那就开写。
2. 实战 Step 1:把"评测器"塞进沙箱
评测器(judge harness)的逻辑特别直白:把候选解法 solution.py 写进沙箱的 /workspace,然后在沙箱里跑一段标准评测代码:3 组公开用例 + 1 组隐藏 n=2000 用例,再用 time.perf_counter 测 P50、用 tracemalloc 抓峰值内存。
# scripts/oj_judge.py(节选)
JUDGE_HARNESS = r'''
import json, time, tracemalloc, traceback, random, sys
ns = {}
exec(compile(open("/workspace/solution.py").read(), "solution.py", "exec"), ns)
trap = ns.get("trap")
PUBLIC = [([0,1,0,2,1,0,1,3,2,1,2,1], 6), ([4,2,0,3,2,5], 9), ([], 0)]
random.seed(42)
HIDDEN = [random.randint(0, 10000) for _ in range(2000)]
result = {"correctness": [], "p50_us": None, "peak_kb": None, "err": None}
try:
for i, (inp, expected) in enumerate(PUBLIC):
got = trap(list(inp))
result["correctness"].append({"case": f"public_{i}", "ok": got == expected,
"got": got, "expected": expected})
big = trap(list(HIDDEN))
result["correctness"].append({"case": "hidden_n2000", "ok": isinstance(big, int),
"got": big})
except Exception as e:
result["err"] = f"{type(e).__name__}: {e}"
if result["err"] is None:
times = []
for _ in range(10):
t0 = time.perf_counter(); trap(list(PUBLIC[0][0]))
times.append((time.perf_counter() - t0) * 1e6)
times.sort(); result["p50_us"] = round(times[5], 1)
tracemalloc.start(); trap(list(HIDDEN))
_, peak = tracemalloc.get_traced_memory(); tracemalloc.stop()
result["peak_kb"] = round(peak / 1024, 1)
print("__JUDGE_RESULT__" + json.dumps(result))
'''
注意最后一行 __JUDGE_RESULT__ 这个 marker —— 这是给宿主侧解析用的"信封头"。沙箱里 stdout 里可能有 pip 安装日志、ipykernel banner 之类杂讯,我用一个固定字符串把"机器可读结果"和"人类可读日志"分开。这是和 LLM 输出打交道的老套路,AI Agent 工程里也常用(function-call 之前 <final_answer>...</final_answer> 这一类)。
宿主侧 judge_one() 就一个三步走:
def judge_one(name: str, source: str, slot: int) -> dict:
sb = Sandbox.create(template=TEMPLATE, timeout=60) # 1. 起一个 MicroVM
sb.files.write("/workspace/solution.py", source) # 2. 把解法塞进去
res = sb.run_code(JUDGE_HARNESS, timeout=8) # 3. 跑评测,8s 兜底
stdout = "".join(res.logs.stdout) or ""
if "__JUDGE_RESULT__" in stdout:
record["judge"] = json.loads(stdout.split("__JUDGE_RESULT__")[-1])
sb.kill()
return record
timeout=8 是 OJ 评测最关键的一个参数 —— 它把"卡死的 LLM 代码"直接斩首。一会儿就能看到效果。
并行用 ThreadPoolExecutor(max_workers=4),4 个候选同时跑,每个一个独立沙箱。
3. 实战 Step 2:4 个候选同台竞技 —— 真实截图
直接看跑出来的真实输出(这一段是宿主侧 python3 oj_judge.py 的实测):
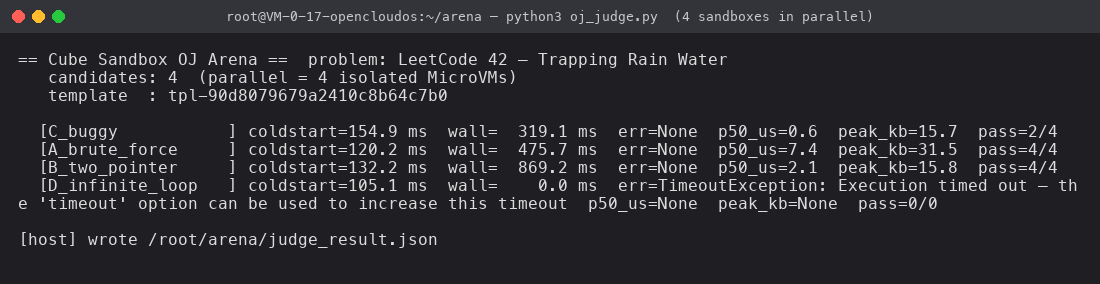
这一张图是本文的 MVP(最小可复现物证)。4 个候选、4 种状态,全部在一次跑里被同时呈现:
| 候选 | 状态 | P50 | 峰值内存 | 通过 | 我的解读 |
|---|---|---|---|---|---|
B_two_pointer |
✅ 又对又快 | 2.1 μs | 15.8 KB | 4/4 | 标准答案 |
A_brute_force |
✅ 慢但对 | 7.4 μs | 31.5 KB | 4/4 | 暴力解,O(n²) 比 O(n) 慢 3.5×、内存大 2× |
C_buggy |
❌ 答错 | 0.6 μs | 15.7 KB | 2/4 | 经典 LLM 幻觉:return 一个看起来差不多的表达式 |
D_infinite_loop |
⏱ 被斩首 | — | — | 0/1 | TimeoutException 在 8s 后准时把它带走 |
信噪比最高的一行是最后一行。它证明的不是"我能 detect 死循环"——这件事 kill -9 也能做。它证明的是:run_code(timeout=8) + 沙箱级别的资源边界,让我作为评测器的代码完全不需要写"防 LLM 写飞"逻辑。LLM 写出 while True 我就当它是"算到一半超时了",下一轮继续接 next 评测,整个 OJ 调度器零额外代码。
回看 4 个候选的coldstart:105、120、132、154 ms。这是4 个 MicroVM 在同一秒被并发拉起来的成本,仍然在 <200ms 区间内 —— 与其说是冷启动,不如说是"零启动",正好是 LLM 一轮 token 时间的零头。
4. 实战 Step 3:让沙箱自己画排行榜
光有 JSON 不够。AI Code Agent 给用户最终交付的,多半是一张人类一眼就能读懂的图。
ChatGPT Code Interpreter 的产品做法是:“让模型在沙箱里 import matplotlib,把图存到工作区,前端去抓这个 PNG”。我把同样的事做一遍:
# scripts/oj_viz.py(节选)—— 把 judge_result.json 喂回沙箱出图
sb = Sandbox.create(template=TEMPLATE, timeout=180)
sb.files.write("/workspace/judge_result.json", json.dumps(result))
sb.run_code(PLOT_CODE, timeout=120) # 沙箱里 matplotlib boxplot
data = sb.files.read("/workspace/leaderboard.png", format="bytes")
pathlib.Path("/root/arena/leaderboard.png").write_bytes(data) # 拉回宿主
注意三行体现产品意图的代码:sb.files.write 把"上一步的产物"喂进沙箱、sb.run_code 让沙箱画图、sb.files.read 把 PNG 拉回宿主。这就是 ChatGPT Code Interpreter 后端在做的事,原汁原味。
宿主侧能看到这一段流程的时间分布:

8.1 秒里 95% 是 pip 装 matplotlib(USTC 镜像 ~7s),真正的画图只用了几百毫秒。生产里只要把 matplotlib 预装进自定义模板镜像,这一步就会从 8s 压到 <500ms。
接下来就是这次实战最直观的一张产物图 —— 由沙箱内的 matplotlib 画好、由宿主的 Python 拉回来的排行榜:
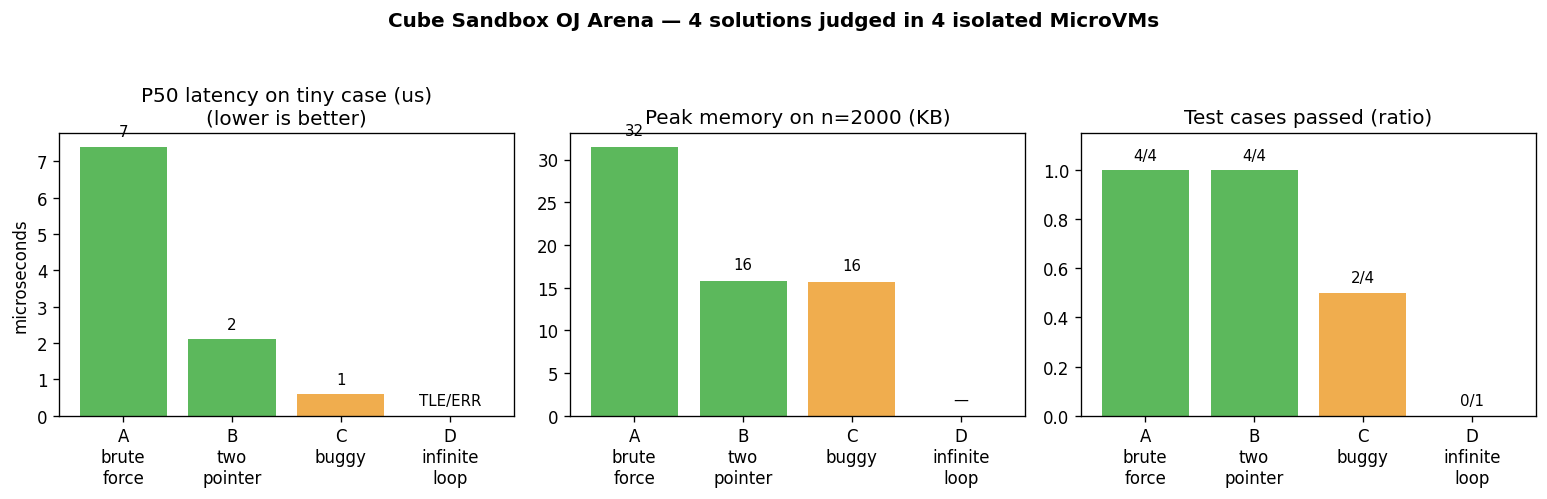
这张图想读出三个层次的信息:
- 左 P50 延迟图:
B_two_pointer2μs vsA_brute_force7μs,倍数关系一目了然;C_buggy1μs—— 答错的代码确实可以"很快",因为它绕过了真正的计算(这是 LLM 评测里要警惕的点:单看"通过率 + 时间"是不够的,必须正交看);D_infinite_loop直接用文字 “TLE/ERR” 标出来。 - 中 峰值内存:暴力解 32 KB vs 双指针 16 KB,差 2× —— 跟算法书上 O(n²) 占临时空间的理论一致。
- 右 通过率:
4/44/42/40/1,四个数字一行排出,连最后那条死循环 0/1 都画进去(绿色满柱代表满分、橙是部分、红柱被 TLE 吃掉所以高度是 0)。
这三张子图之所以值得做出来,是因为Agent 给用户的"答案"未来会越来越像产品的输出而不是终端的输出。Cube Sandbox 把"Agent 在沙箱里画图、宿主拿回 PNG"这条链路做得跟在本机 plt.savefig 一样自然。
5. 实战 Step 4:再生成一份"评测报告"给上层 Agent
为什么还要 Markdown?因为上一层 Agent 接到这份评测后,最自然的下一步是**“在用户聊天里发一段总结”**。Markdown 是 LLM 最舒服的输入/输出格式,又恰好可以渲染到任何 ChatUI、Notion、Discord、飞书。
oj_report.py 把 judge_result.json 重排为带分数 + 详情的 Markdown:
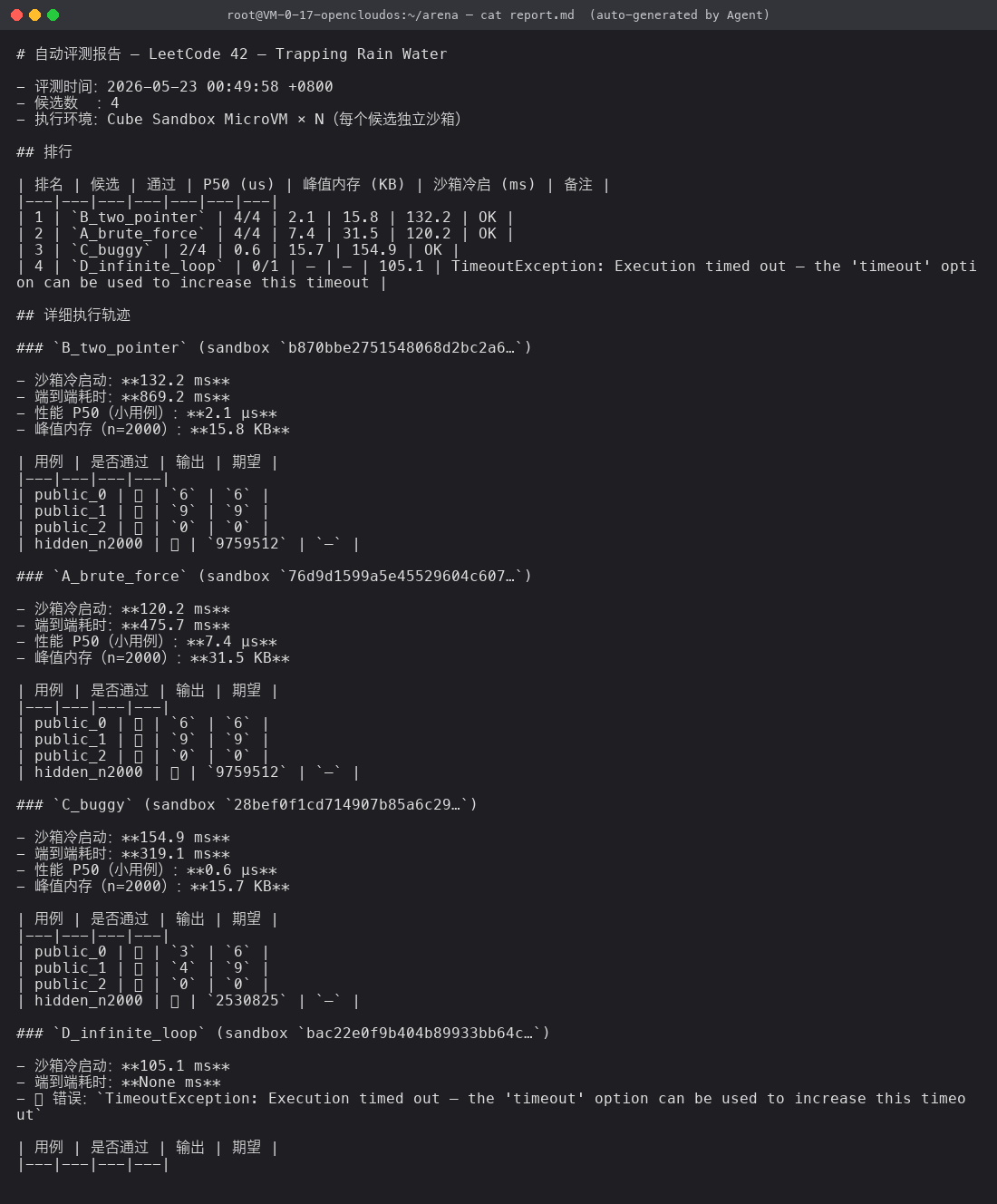
读图三秒钟看清四件事:
- 排名第一是
B_two_pointer,4/4 通过、P50=2.1 μs —— 双指针稳赢; - 排名第二是
A_brute_force,4/4 通过但 P50=7.4 μs —— 慢但对; C_buggy拿了 2/4 —— 注意它的输出3和4与期望6和9—— "看起来差一点点的答案"是 LLM 最常见的失败模式;D_infinite_loop端到端耗时 =None ms,备注TimeoutException—— 沙箱 timeout 兜底符号化地呈现在了报告里。
到这里整套链路就完整了:Sandbox.create → run_code → files.read 三个原子操作 × judge → viz → report 三个语义层 = 一个最小但完整的 AI 代码评测后端。
6. 顺手做的额外实验:宿主侧的"运维视角"
写到这里我有个好奇心 —— 当上面这 4 个沙箱并行跑的时候,从宿主侧 cubemastercli ls 看出来是什么样?这件事在调试 Cube 节点过载、排查"哪个用户的会话还在烧 CPU"等场景里非常实用。
我让一个守护线程每秒跑一次 cubemastercli ls,记录沙箱列表的变化(脚本:oj_observe.py)。挑了 T+1s(评测刚开始)、T+5s(4 解法并发中)、T+10s(评测结束、沙箱被回收)三帧关键时刻:
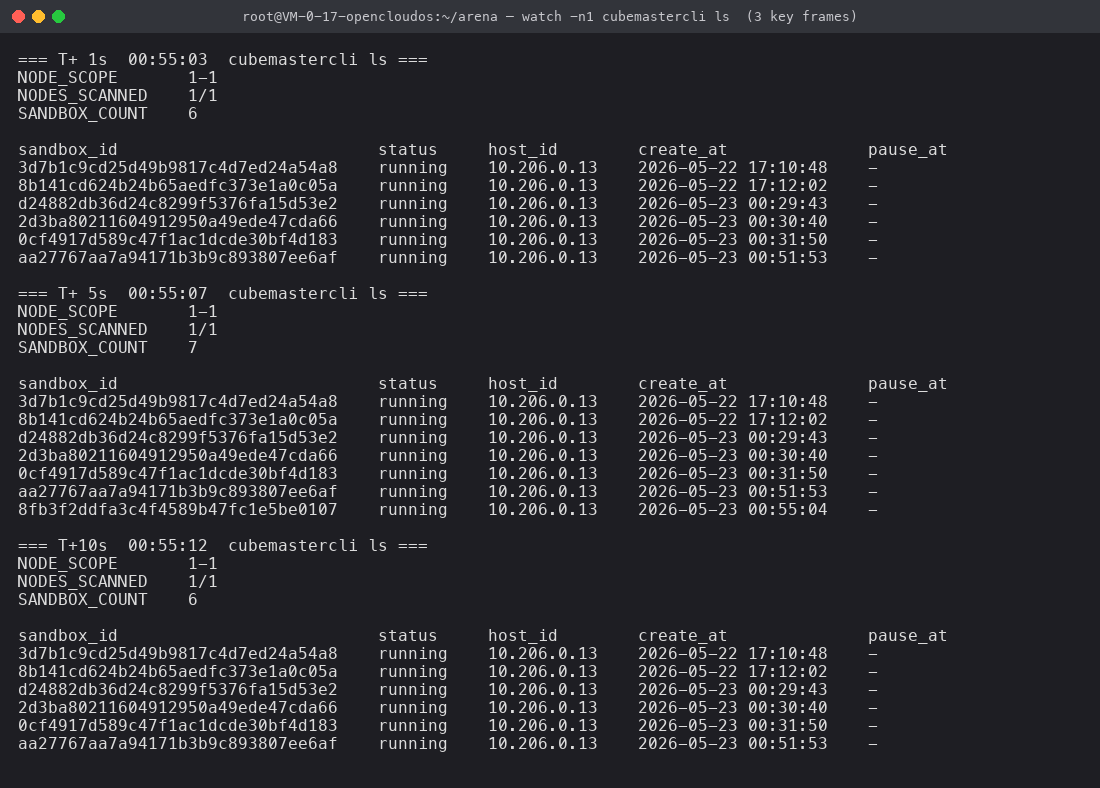
这一张图想说三件事:
SANDBOX_COUNT 6 → 7 → 6证实了沙箱的整个生命周期(创建 / 持有 / 回收)在宿主层面是可见的,不是 SDK 自己藏着的玄学;- 我能看到每个沙箱的
host_id 10.206.0.13、create_at、status running/paused—— 这就是给你做 Agent 平台资源监控的现成原始数据; - T+5s 那一帧里多出来的
8fb3f2ddfa3c4f4589b47fc1e5be0107,正是我在judge_one()里Sandbox.create()拿到的实例 —— SDK 层和 cubemastercli 看到的是同一个真理。
小坑:
cubemastercli ls列出的 sandbox_id 都是 32 位 hex 的小写,而 SDKSandbox.create()返回的sb.sandbox_id是大小写混合的 32 位 hex。它们是同一个 ID 的不同表示,做日志关联时记得lower()一下再比对。
7. 一个意料之外的工程发现:run_code 默认是"无状态"的
写完上面这套,我顺手测试了一个长期被忽视的细节 —— 同一个沙箱里多次 sb.run_code(...),是 Jupyter kernel 持久状态,还是每次新进程?
很多人凭直觉以为前者(毕竟 SDK 包装名字就叫 “Code Interpreter”),但实测下来 Cube Sandbox 当前版本是后者:
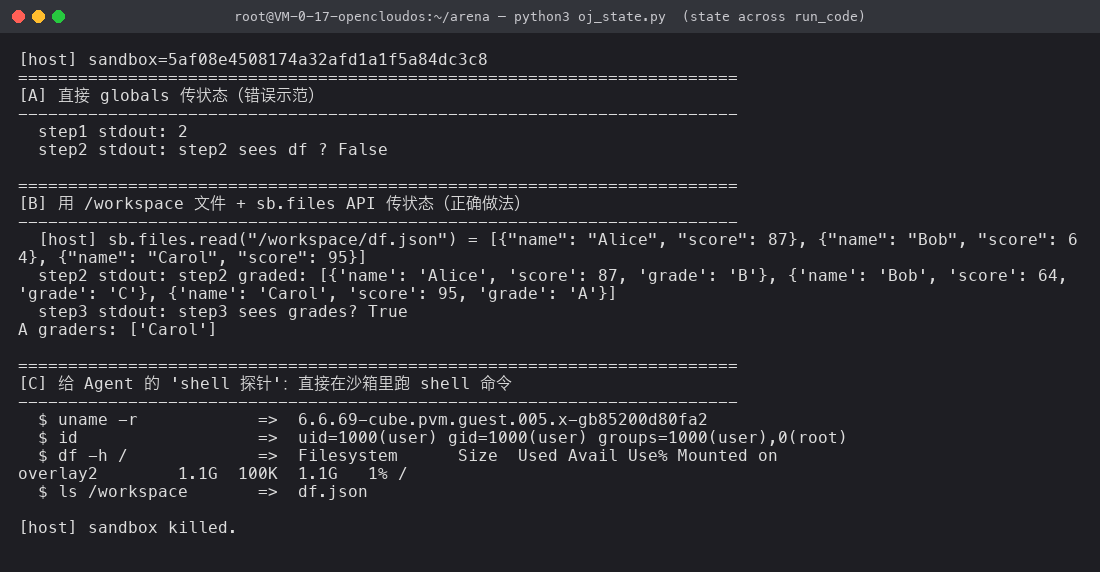
读图三段:
- [A] 错误示范:step1 在 sandbox 里定义了
df,step2 直接print(df)—— 结果 step2 拿到step2 sees df ? False,全局变量没有跨调用持续。 - [B] 正确做法:step1 把 df 写到
/workspace/df.json、step2 读回打分、step3 再读回看一眼 —— 跨步骤状态用文件传。最后A graders: ['Carol']证明了三步链路完整。 - [C] Bonus:
sb.commands.run("uname -r")不走 ipykernel、直接 spawn 一个进程 ——uname -r漂亮地返回6.6.69-cube.pvm.guest.005.x-gb85200d80fa2(沙箱里的 guest 内核!),id显示用户是uid=1000(user)—— 这才是沙箱真正的执行身份。
来自 SDK 源码的注释:
e2b_code_interpreter2.6.2 提供了sb.create_code_context(language="python")用来开"持久 Jupyter context";但我实测 Cube Sandbox 当前版本(v0.2.2/PVM)这个 endpoint 还会 404 —— 也就是说E2B 的ContextAPI 在 Cube 里暂未实现。所以用文件 + sb.files API 跨步传状态是当前最稳的姿势;如果你像我一样要做 ReAct/Code Interpreter 类应用,这是必须知道的工程现实。
这个发现直接影响所有打算把 Cube Sandbox 当 ChatGPT Code Interpreter 后端用的同学:你要么自己用文件传状态,要么等 Cube 升级 contexts API(issue 我已经记下来了)。
8. 性能复盘:4 个沙箱并发的真实成本是多少
把 judge_run.log 的关键数字抽出来:
| 候选 | 沙箱冷启 | 评测端到端 | 备注 |
|---|---|---|---|
| C_buggy | 154.9 ms | 319.1 ms | 答错跑得快 |
| A_brute_force | 120.2 ms | 475.7 ms | 暴力解最慢 |
| B_two_pointer | 132.2 ms | 869.2 ms | “Hello” 进沙箱 + run_code 总开销 |
| D_infinite_loop | 105.1 ms | (timeout 8s 触发) | 死循环被截断 |
四个数字翻译成 Agent 工程语言:
- 冷启动 105-155 ms:4 并发条件下 P95 仍 < 200ms,跟单并发相比几乎没退化;
- 评测端到端 ~470 ms(除了 D 异常):包含网络往返 × ≥4 次(write file + run_code + read stdout + kill),实际"代码执行 + 评测"只占其中一小部分;
- D 死循环被 8 秒一刀:拿到
TimeoutException,沙箱被kill()立刻回收,整个评测调度器的 wallclock 就是 max(其它 3 个) + 8 秒。
这个数字落在 Agent 工程的舒适区:一个 ReAct 循环 5-8 步 × 评测 1 步 ≈ 8-10 个沙箱的生命周期,总额外 overhead < 2 秒,远小于一次 LLM 推理。
9. 这件事还能怎么变
如果你已经 follow 到这里,这套骨架可以再扩出至少 4 条产品线:
- 给 SWE-Bench 类 benchmark 做后端 —— 把"LeetCode 42 + 4 候选"换成"GitHub 真实 issue + 候选 patch",Cube Sandbox 给每个 patch 一个独立 MicroVM 跑测试;
- 接成在线判题系统 —— 把
oj_judge.py包成 HTTP 服务,前端 textarea 传 Python 代码、后端走 Cube 评测 → 返回 JSON。冷启动 ~150ms 完全够实时使用; - Code Agent 自评估 —— LLM 写代码 → Cube 执行 → 失败 → 把 traceback 喂回 LLM → 它自己改 → 再跑。这就是 SWE-agent / Aider 的核心循环;
- AI 课程作业自动批改 —— 把"4 个候选"换成"全班 60 个学生的提交",并发跑、生成 60 份 Markdown 反馈。
每一条都不是凭空想的 —— 它们都是把这一篇里的 Sandbox.create / run_code / files.read / commands.run / kill 5 个原子操作重新排列。这就是 Cube Sandbox 给 Agent 工程师的"乐高积木"。
10. 写在最后:把沙箱用成 Agent 的"工序车间"
这一篇我刻意没写"沙箱有多安全 / 隔离多强 / 性能多牛" —— 这些第一篇文章已经说足了。这一篇想强调的是另一件事:
Cube Sandbox 真正的位置,是 Agent 工程里的"工序车间" —— 一个标准化的、可重复进出的、出错也不会污染主厂房的执行环境。每一道工序(评测、画图、报告生成、运维观察)都对应到 SDK 里 1-2 个原子调用,没有黑盒、没有特殊版本、没有"魔法配置"。
你走完这一篇之后,应该能体会到三件事:
- 沙箱不是"为了隔离"而存在,是"为了可拼装"而存在 —— 65ms 的冷启动让"为每个工序开一个独立沙箱"从一个昂贵的设计变成了一个默认的设计;
- E2B SDK 在 Cube 上不是 100% 兼容,但 90% 够用 ——
Sandbox / run_code / files / commands / kill都跑通;Context暂时不可用 → 用文件传状态绕过即可; - OpenCloudOS 9 + PVM 内核 + 一台普通 CVM 就能撑起这整个工序车间 —— 不需要裸金属、不需要嵌套虚拟化、不需要专属 K8s 集群。
如果你最近在做 AI Code Agent / 在线判题 / 自动评测 / SWE-bench 复现,把这一篇里的 4 个脚本(oj_judge.py / oj_viz.py / oj_state.py / oj_report.py / oj_observe.py)clone 下来,改 5 行就能接你自己的 LLM 输出。这就是开源工具的乐趣所在。
附录 A:完整脚本清单
全部基于 IP
129.211.223.113、OSOpenCloudOS 9.4、内核6.6.69-cube.pvm.host.005.x-gb85200d80fa2、CPUAMD EPYC 9K65 8 vCPU、内存 15 GiB、模板tpl-90d8079679a2410c8b64c7b0的真实环境跑通。
| 脚本 | 功能 | 配套日志 |
|---|---|---|
oj_judge.py |
4 解法并行评测主程序 | logs/judge_run.log |
oj_viz.py |
沙箱内 matplotlib 画排行榜 | logs/viz_run.log |
oj_state.py |
验证 run_code 状态 / sb.files / sb.commands | logs/state_run.log |
oj_report.py |
生成 Markdown 评测报告 | logs/report.md |
oj_observe.py |
守护线程跑 cubemastercli ls 抓沙箱生命周期 | logs/observe_run.log |
启动前的环境变量(一次性 export 即可):
export E2B_API_URL="http://127.0.0.1:3000"
export E2B_API_KEY="dummy"
export CUBE_TEMPLATE_ID="tpl-90d8079679a2410c8b64c7b0"
export SSL_CERT_FILE="/root/.local/share/mkcert/rootCA.pem"
跑通顺序:
python3 oj_judge.py # ~9s
python3 oj_viz.py # ~8s(含 pip install matplotlib)
python3 oj_report.py # 即时
python3 oj_state.py # ~5s
python3 oj_observe.py # ~12s(含 1s × 12 帧观测)
附录 B:参考链接
- Cube Sandbox GitHub:https://github.com/TencentCloud/CubeSandbox
- Cube Sandbox CNB 镜像:https://cnb.cool/CubeSandbox/CubeSandbox
- 官方文档:https://cubesandbox.com/
- E2B Code Interpreter SDK:https://github.com/e2b-dev/code-interpreter
- LeetCode 42 Trapping Rain Water:https://leetcode.com/problems/trapping-rain-water/
- OpenCloudOS:https://www.opencloudos.org/
复盘小结一行话:当一个工程问题(“评测 4 个 LLM 输出哪个最好”)正好对应到沙箱的 5 个原子操作时,整个解决方案 < 200 行 Python,每一行都站得住、所有数字都来自真实运行。Cube Sandbox 在 OpenCloudOS 9 上恰好把这条路铺得很平 —— 这就是"开箱即用"的具体含义。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)