【2026年版|建议收藏】大模型是如何思考的?揭秘LLM推理完整过程(小白&程序员入门必看)
本文深入浅出解析2026年主流大模型(ChatGPT、Kimi K2.6、混元Hy3等)的内部运作机制,从训练、推理到微调,结合最新技术迭代,通俗阐述模型如何学习知识并落地到实际开发与应用场景。文章详细拆解Transformer架构核心组件及功能,包括嵌入层、编码器、解码器等,清晰解读注意力机制的工作原理的同时,补充2026年MoE架构、LoRA+RAG混合范式等热门技术细节。此外,结合当前算力优化方案,探讨增加模型层数的核心挑战,延伸大模型定律的实际应用价值,助力小白快速入门、程序员夯实基础,为深入学习大模型开发与调优筑牢根基。
编辑2026最新AI大模型学习资料合集,允许白嫖,学完拿下即可就业,存下吧很难找齐的!22 赞同 · 16 评论 文章
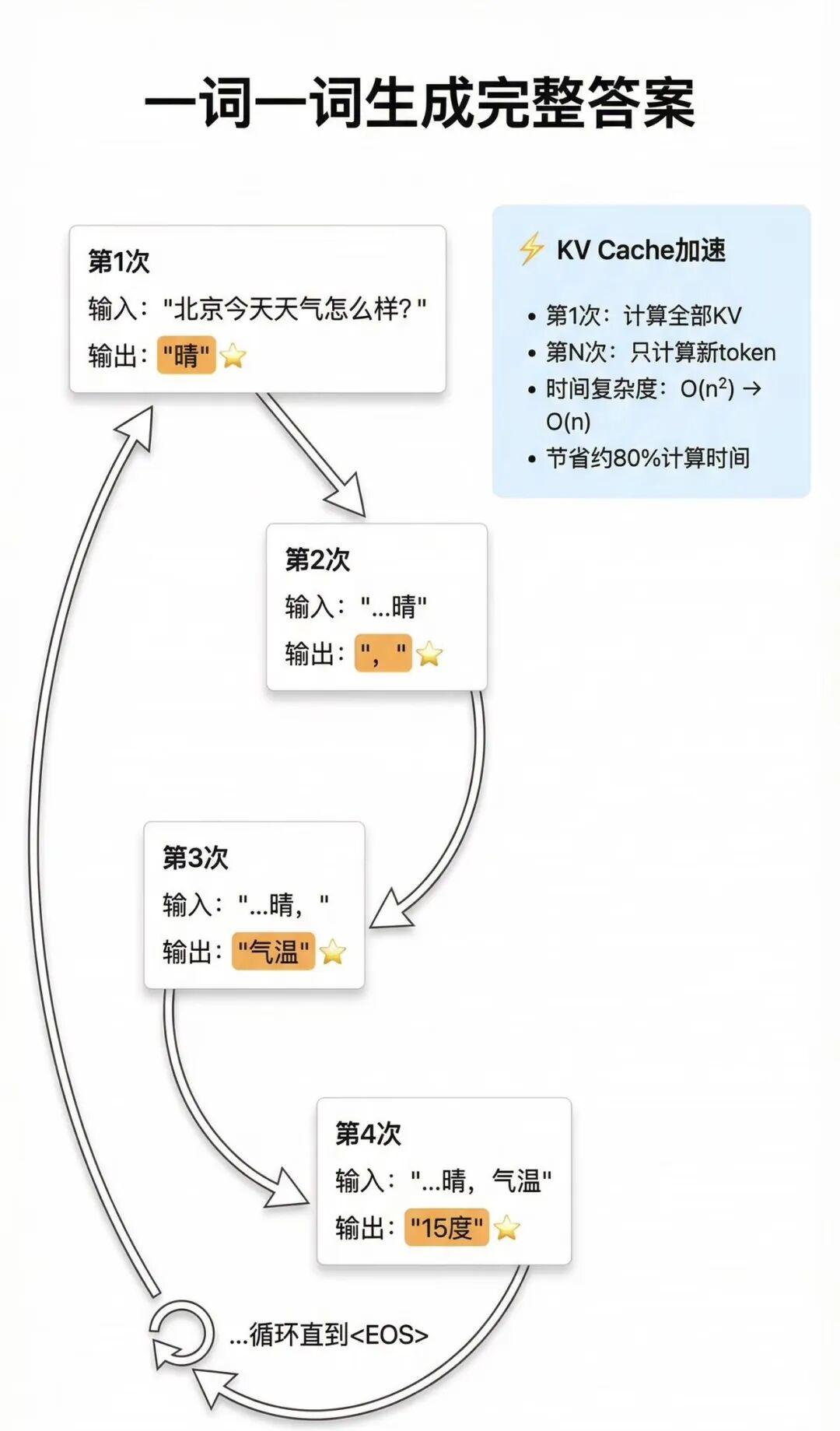
当你问ChatGPT “北京今天天气怎么样?”,它秒回“今天天气晴,气温15度,适合出行”。
看似简单,但你绝对想不到,整个过程它“脑子”里经历了什么!
这不是魔法,是数学。
在深入模型内部细节之前,需先明确训练和推理这两个基本概念。
训练是模型成长的阶段,推理则是模型应用所学知识解决实际问题的过程。理解这两者的区别,有助于把握 大模型的整体运行机制。
训练阶段,开发者会提供海量样本数据让模型反复学习。
常见方式包括有监督学习(Supervised Learning)、自监督学习(Self-supervised Learning)和强化学习(Reinforcement Learning),目标是最小化预测错误(损失函数),让模型参数收敛到良好泛化状态。
推理阶段,模型训练完成后被部署,对新数据进行预测或生成。
此时模型会将训练中学到的内部表示和规则应用于新输入,输出结果。推理的质量高度依赖于训练效果,训练不足的模型在推理时表现会较差。
微调(Fine-tuning)是训练过程的延伸。
它是在预训练模型(Pre-trained Model)基础上,用特定领域数据继续训练,使模型更适用于特定任务。微调通常数据量和计算需求较低,但能显著提升模型在特定应用上的效果。常见微调方法如低秩适配(LoRA, Low-Rank Adaptation),会冻结部分层,仅训练部分参数。
总之,训练赋予模型知识,微调塑造模型专长,推理则是模型运用知识解决问题的过程。
那么推理过程主要分为三个阶段:
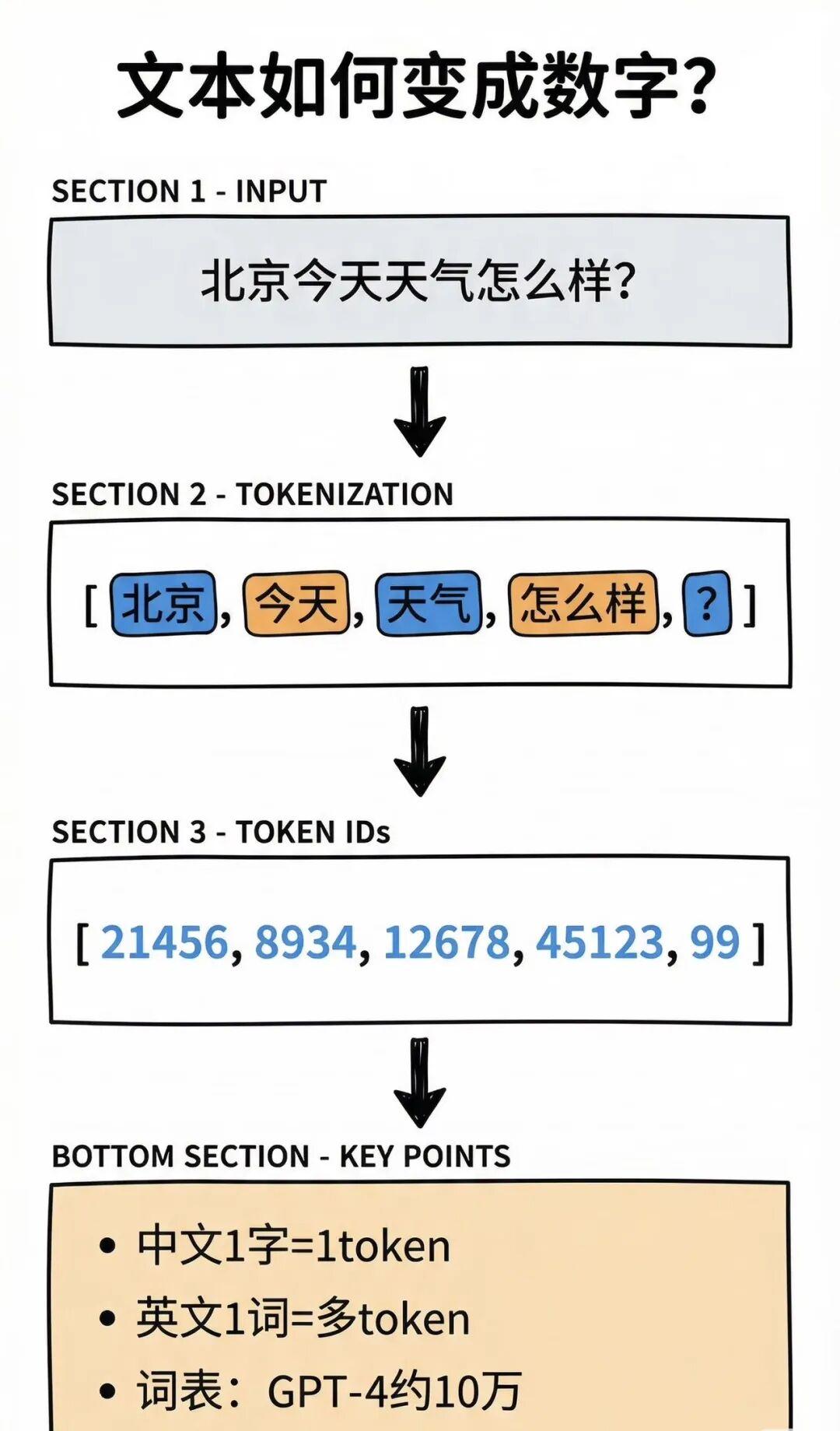
-从一句话文本变成数字(Tokenization)
-利用96层Transformer模型深度思考
-一个字一个字“蹦出来”回答结果
当前主流架构为 Transformer,核心包括嵌入层(Embedding)、编码器(Encoder)、解码器(Decoder)等模块。
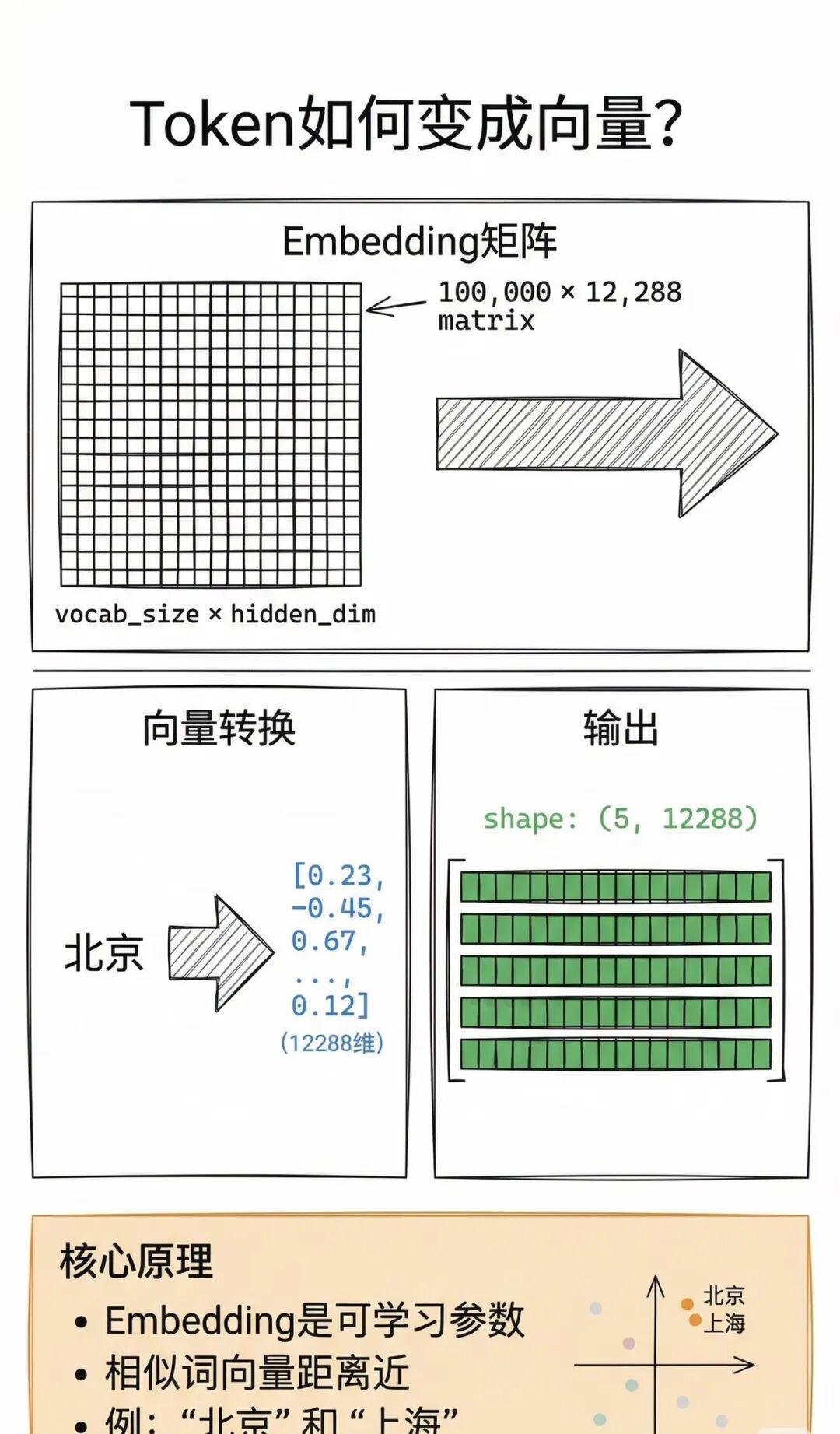
嵌入(Embedding)层:输入文本先分词为 tokens,经嵌入层映射为向量(词向量),并加入位置编码,得到词嵌入序列作为模型输入。
编码器(Encoder):编码器接收嵌入序列,经过多层堆叠,利用多头自注意力机制(Multi-head Self-Attention)和前馈网络,提取词间联系和上下文依赖,输出高维隐状态向量,代表输入序列的深层语义特征。
解码器(Decoder):解码器根据编码器输出的语义表示,逐步生成目标输出序列。每层包括掩码自注意力、交叉注意力和前馈网络。掩码自注意力关注已生成内容,交叉注意力参考编码器输出,帮助决定下一个输出词。
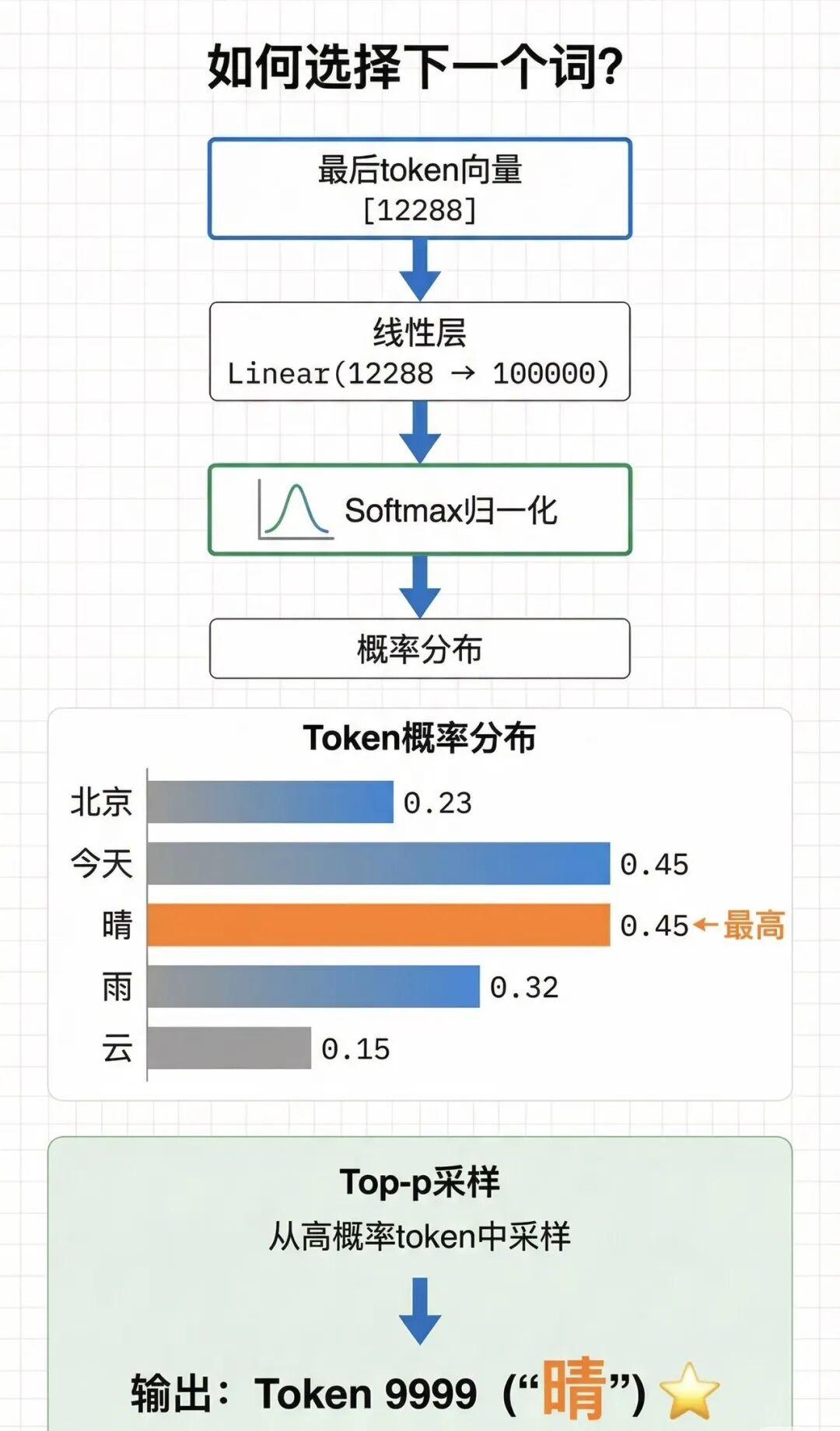
生成输出(Output Generation):解码器最后一层输出隐状态,经线性变换和 Softmax 得到词表概率分布,选取概率最高的词作为下一个输出 token,循环生成直至结束。
Transformer 架构具备并行处理和全局依赖捕捉能力,编码器 - 解码器配合实现输入信息压缩与输出答案解码的闭环。模型“思考”本质是数值计算与概率推断的流转。
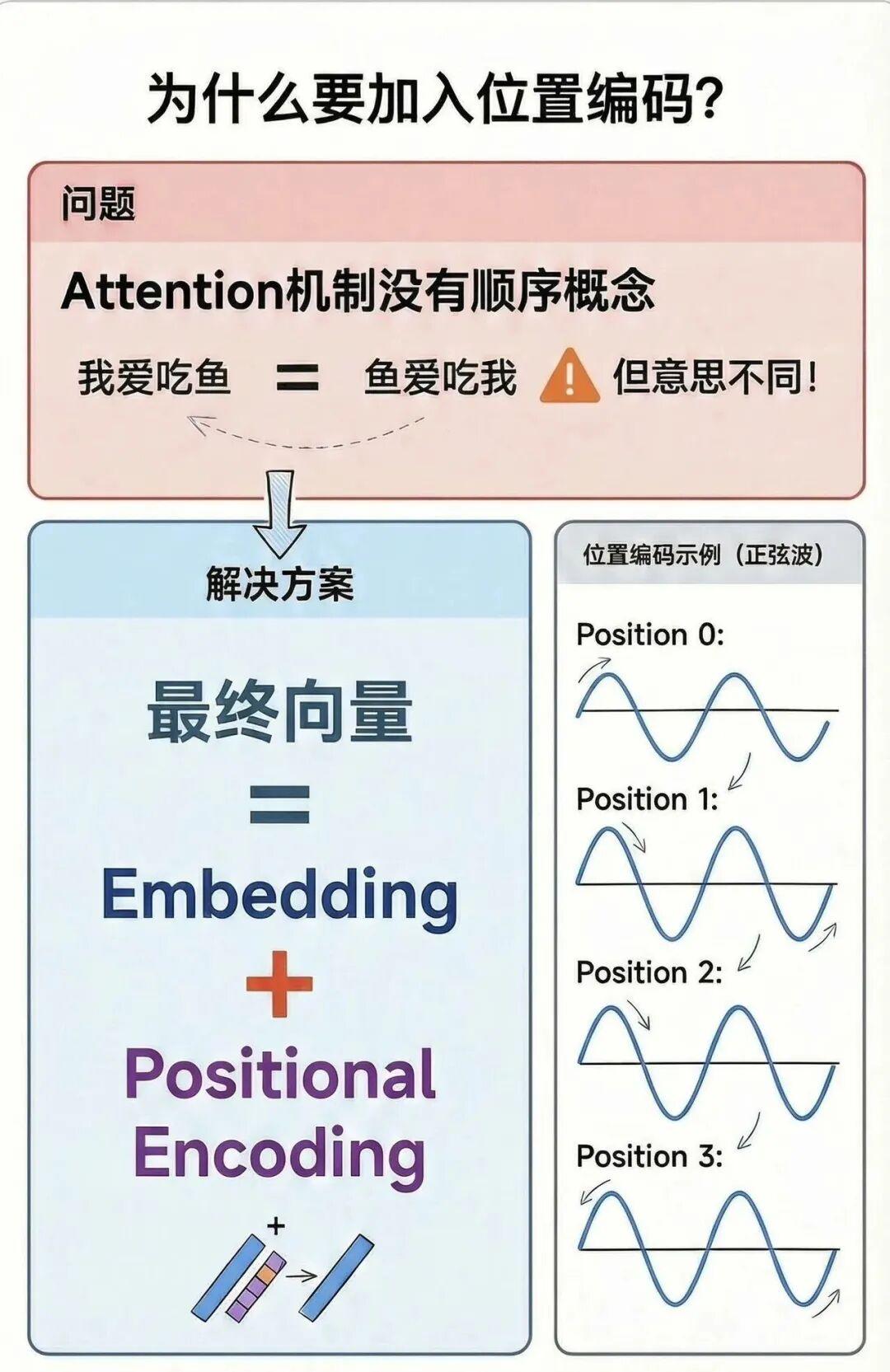
Positional Encoding作用:让模型知道先后顺序!

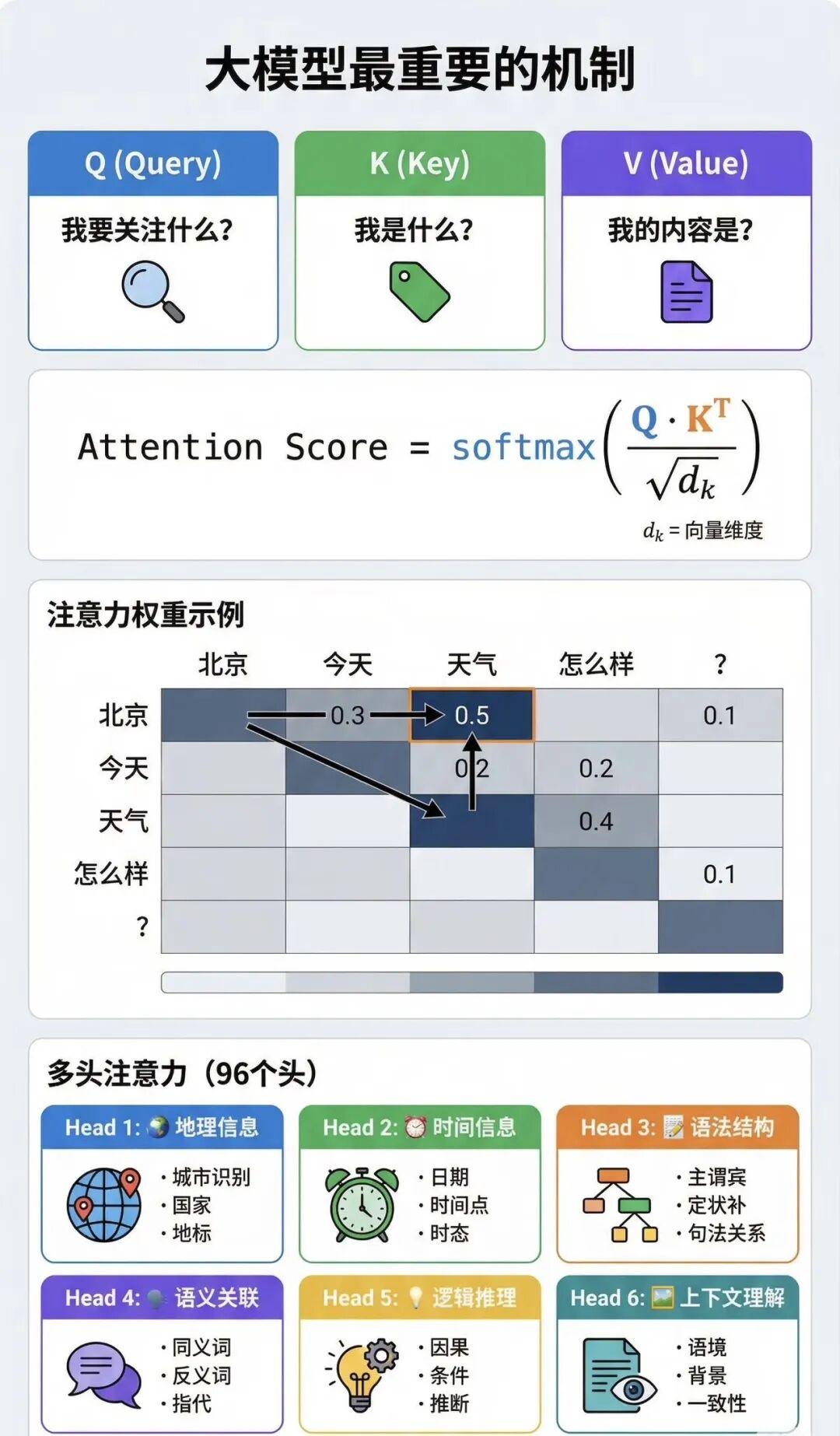
什么是注意力机制?
人类阅读一句话时,并不会平等地关注所有词。例如在问题:
“请解释一下 Kubernetes Ingress 的作用。”
你的注意力会自然集中在:
- Kubernetes
- Ingress
- 作用
而忽略 “请、一下、的” 等词。
注意力机制让模型也能做到这一点:当前 token 在处理时,可以自动选择该重点关注哪些历史 token。
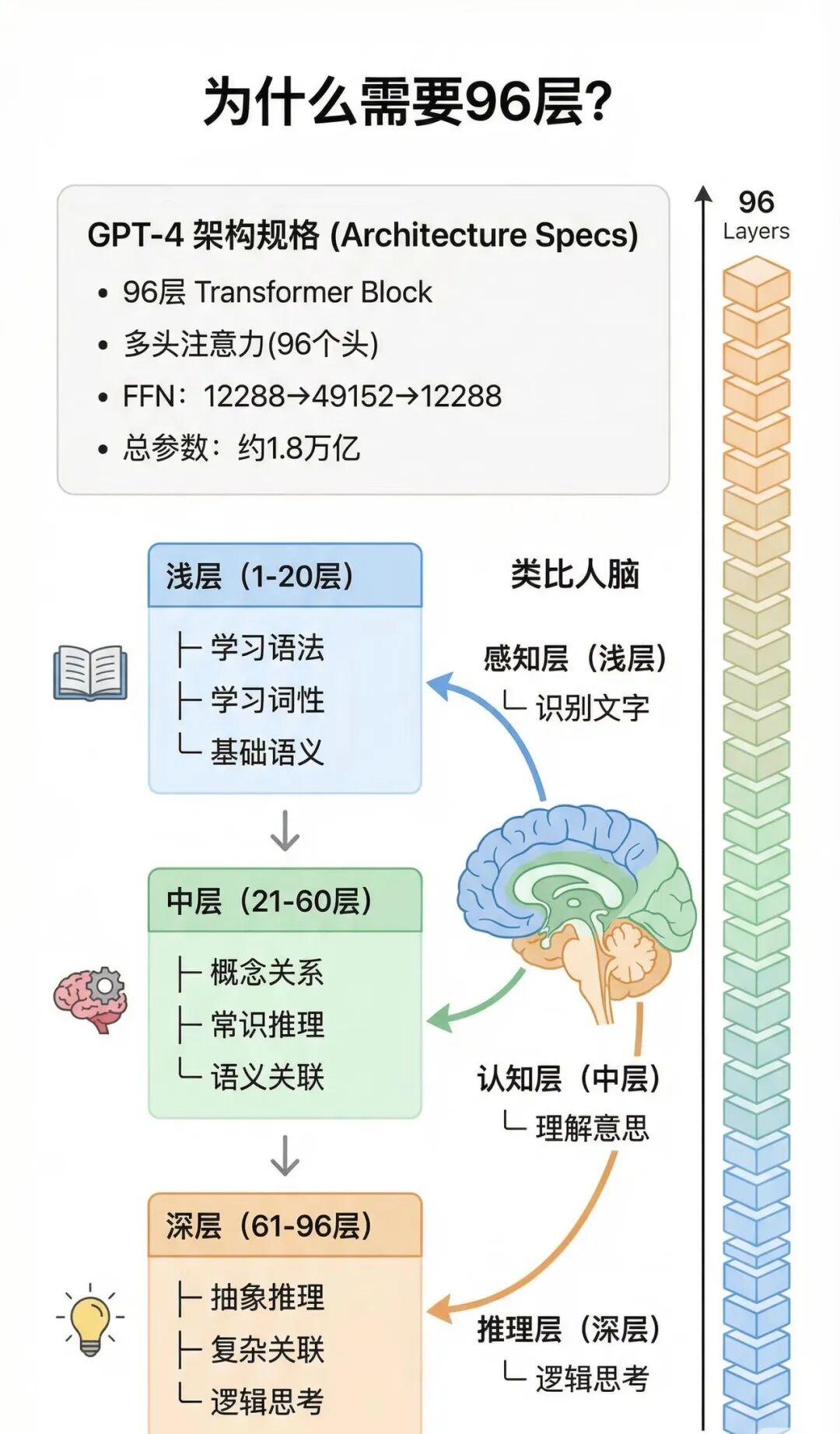
为什么是96层?
既然深层这么好,那我们为什么不做 10,000 层的 Transformer?现在的 GPT-4 大概也就是 96层(推测)。
这里有四个巨大的**“拦路虎”**:
1. 边际效应递减(Diminishing Returns)
这就像复习考试:
- 复习 1 遍:从 0 分到 60 分(提升巨大)。
- 复习 6 遍:从 80 分到 90 分。
- 复习 100 遍:从 98 分到 98.1 分。
在模型中,从 6 层增加到 12 层,性能提升很明显(像 BERT-Base)。从 96 层增加到 192 层,性能提升可能微乎其微,但计算成本却翻倍了。性价比极低。
2. 梯度消失与训练困难(Vanishing Gradient)
虽然 Transformer 有 Residual Connection(残差连接) 和 Layer Norm(归一化) 来缓解这个问题,但如果层数过深(比如 1000 层):
- 反向传播时,误差信号要穿过 1000 层传回第一层。
- 信号在途中会越来越弱,或者变得非常不稳定。
- 结果就是:模型根本训练不起来,或者不收敛。
3. 算力与延迟(Latency)
这是工业界最关心的问题。
推理速度:模型是串行计算的(必须算完 Layer 1 才能算 Layer 2)。层数翻倍,用户等待的时间(Latency)就翻倍。
- 显存占用:每一层都需要存储参数和中间状态(KV Cache)。层数太多,显卡装不下。
4. 过拟合(Overfitting)
如果你的数据量不够大(比如只有几千条数据),却用了一个 100 层的模型:
- 模型因为脑容量太大,它不会去学“规律”,而是直接把答案背下来。
- 结果:训练集满分,测试集零分。
- 大模型定律(Scaling Law)
:层数(参数量)必须和数据量匹配。只有数据量是海量的时候,加深层数才有意义。

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)