项目实训 (五)| 金融知识问答模块总结及优化思路
一 . 金融知识问答模块核心功能概述🎯
1. 1 分级智能问答
- 支持 入门/中级/高级 三个难度等级
- 根据用户水平自动调整回答风格(通俗讲解 → 专业拆解 → 深度拓展)
- 回答内容引用知识库来源,标注引用编号,保证可追溯
1.2 向量知识检索
- 基于 ChromaDB 向量数据库进行相似性检索
- 支持 元数据过滤 (如按来源类型筛选)
- 多路召回合并:合并原始查询与扩展查询的结果,去重后按相似度排序
1.3 查询扩展增强
- 通过 LLM 自动生成 同义扩展词 ,提升检索召回率
- 例如:“什么是MACD” → “MACD 指数平滑异同移动平均线 技术指标”
1. 4 结构化输出
- 输出包含:详细回答、核心要点、相关术语、追问问题、置信度
- 附带引用知识块,支持溯源验证
1.5 知识管理
- 支持向知识库批量添加新的知识块
- 自动生成唯一ID,支持自定义元数据
二. 模块开发内容总结
2.1 数据来源
当前数据以人工整理的炒股书籍和金融政策文件为主,同时参考了 Gitee、GitHub、HuggingFace 上的开源金融数据集。人工采集效率瓶颈明显,后续计划引入自动化爬取方案补充数据规模。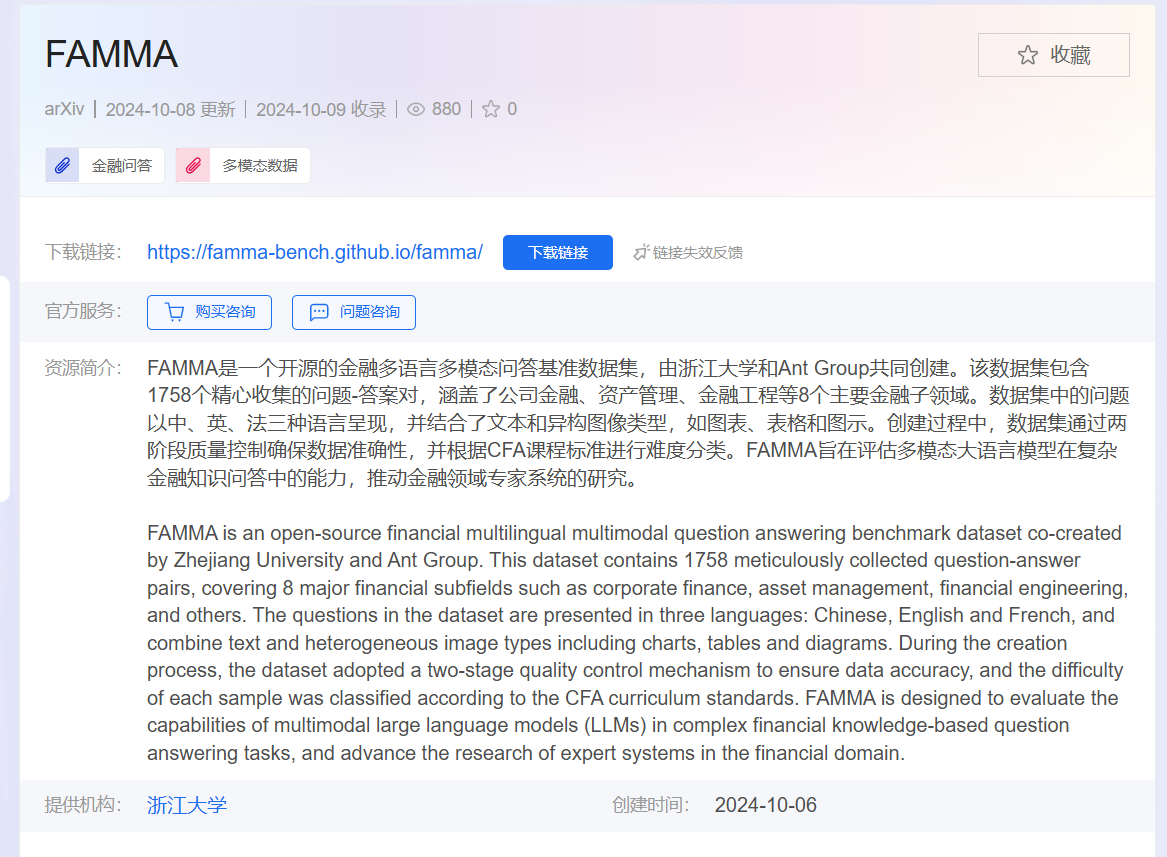
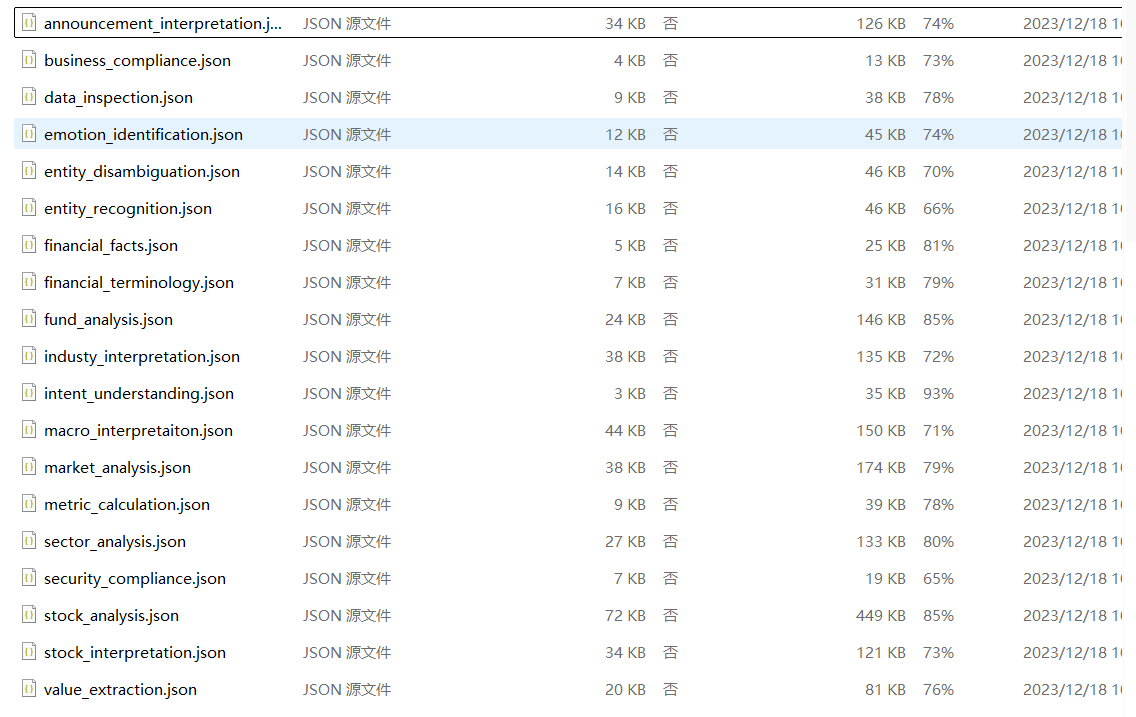
2.2 切块方式
切块是为了把一整篇长文档切成长度可控、有重叠、可追溯、ID 唯一的小文本块,方便后续做向量检索。切块时先按空行分段粗切,用 两个空行把文章切成自然段落。
paragraphs = [p.strip() for p in doc.text.split("\n\n") if p.strip()]
然后再用滑动窗口对超过设定最大长度的超长段落细切,细切时借助overlap控制上下文之间的关联关系,减少因语义割裂带来的负面效果。
step = max(1, chunk_size - overlap)
start = 0
seg_idx = 0
while start < len(para):
end = start + chunk_size
piece = para[start:end].strip()
if piece:
chunk_id = _make_chunk_id(doc.doc_id, para_idx, seg_idx)
chunks.append(
KnowledgeChunk(
chunk_id=chunk_id,
text=piece,
metadata={
**doc.metadata,
"doc_id": doc.doc_id,
"paragraph_index": para_idx,
"segment_index": seg_idx,
},
)
)
start += step
seg_idx += 1
2.3 向量化存储
优先使用国内镜像加速下载Embedding模型,之后将文本列表转换为向量列表,用于后续存储和检索。转化为向量后向指定 Collection 插入或更新向量。
文本向量化
def embed(self, texts: List[str]) -> List[List[float]]:
self._ensure_embedding_model()
return self._embedding_model.encode(
texts,
batch_size=settings.EMBEDDING_BATCH_SIZE, # 默认 32
normalize_embeddings=True, # 向量归一化,提升检索效果
).tolist()
插入或更新向量
def upsert(self, collection_name: str, ids: List[str], texts: List[str], metadatas: Optional[List[Dict]] = None) -> None:
"""向指定 Collection 插入或更新向量"""
collection = self._ensure_collection(collection_name)
embeddings = self.embed(texts) # 关键:文本 → 向量
safe_meta = self._sanitize_metadatas(metadatas, len(texts))
collection.upsert(
ids=ids,
embeddings=embeddings,
documents=texts,
metadatas=safe_meta,
)
2.4 提示词处理
分级回答指南:
根据用户选择的等级,生成适配其理解的语言,有针对性地进行回答调整。
LEVEL_GUIDES: Dict[str, Dict[str, Any]] = {
"入门": {
"answer_style": "通俗讲解",
"description": "用生活化表达解释概念,让零基础用户也能听懂。",
"instructions": [
"先讲清概念是什么,再讲它为什么重要。",
"优先使用比喻、类比和简单例子,必要时才提公式。",
"第一次出现专业术语时,用一句白话解释。",
"结尾补充一个容易踩坑的提醒,帮助建立正确认知。",
],
},
"中级": {
"answer_style": "专业拆解",
"description": "在易懂基础上增加机制、指标和分析框架。",
"instructions": [
"解释核心概念时,补充背后的运行机制和因果链条。",
"可以引入常见指标、公式或分析框架,但避免堆砌术语。",
"说明适用场景,并点出至少一个常见误区或边界条件。",
"回答更偏实务和分析视角,帮助用户从会听懂走向会判断。",
],
},
"高级": {
"answer_style": "深度拓展",
"description": "默认用户有基础,重点讲原理、适用边界与延展用法。",
"instructions": [
"直接解释问题的本质、关键假设和底层逻辑。",
"补充在策略研究、资产配置、风险管理或估值分析中的应用。",
"明确指出局限性、反例、约束条件或不同流派的分歧。",
"在答案结尾给出进一步深入的思考方向或可延展的问题。",
],
},
}
知识问答提示模板
通过设定角色、限制引用和规定范围来约束知识回答情况,减少幻觉出现。
- 角色定义:专业金融知识老师,严格基于检索结果回答
- 引用约束:引用编号必须与知识块对应,禁止杜撰来源
- 降级规则:知识库无法支撑的结论需标注「通识」,而非引用编号
- 域外拒答:非金融领域问题直接说明,不强行作答
KNOWLEDGE_QA_PROMPT = """
你是专业的金融知识老师。请严格根据下方“检索到的知识块”回答用户问题;回答中若引用某条知识,请用对应编号标注,例如“……[1]”“……[3]”。
若检索块不足以支撑某个结论,请明确说明“知识库中未找到直接依据”,此时你可以补充通用金融常识,但必须标注为“通识”而不是引用编号。
用户问题:{question}
用户水平:{user_level}
当前回答风格:{answer_style}
该等级回答目标:{level_description}
分级回答要求:
{level_requirements}
额外要求:
1. 如果问题不属于金融、投资、市场、宏观、公司分析等相关领域,请直接说明当前模块主要回答金融问题。
2. 答案必须结构化、完整、可读,不要只有术语堆砌。
3. 如果引用了知识块,引用编号要与内容对应,不能杜撰来源。
4. key_points 应该提炼出最值得记住的核心点。
5. follow_up_questions 应给出适合当前水平继续追问的 2-3 个问题。
检索到的知识块(编号与上下文一一对应):
{retrieved_context}
请以 JSON 格式输出:
{{
"answer": "详细回答(根据用户水平调整深度;引用处使用 [1] 等形式)",
"key_points": ["核心要点列表"],
"related_terms": ["相关术语列表"],
"follow_up_questions": ["适合继续追问的问题"],
"confidence": <置信度 0.0-1.0>,
"difficulty_level": "入门|中级|高级",
"answer_style": "通俗讲解|专业拆解|深度拓展"
}}
"""
查询扩展
通过 LLM 对原始问题进行同义扩展,补充相关术语,从而提升向量检索的召回覆盖率。
示例:
原始查询:
"什么是MACD"
扩展查询:"MACD 指数平滑异同移动平均线 DIF DEA 金叉死叉 技术指标"
async def _expand_query_for_retrieval(self, question: str) -> Optional[str]:
if not settings.RAG_QUERY_EXPANSION:
return None
try:
response = await self.llm.chat.completions.create(
model=settings.LLM_MODEL_NAME,
messages=[
{
"role": "system",
"content": (
"你是检索查询扩展助手。用户会提出金融相关问题。"
"只输出一行用于向量检索的扩展语句:在原问题基础上补充若干相关词或同义表达,用空格分隔。"
"不要解释,不要换行多条,不要输出多余句子。"
),
},
{"role": "user", "content": question},
],
max_tokens=100,
temperature=0.2,
)
line = (response.choices[0].message.content or "").strip()
line = line.split("\n")[0].strip()
if not line or line == question.strip():
return None
return line
except Exception as exc:
logger.warning(f"[RAGService] 查询扩展失败: {exc}")
return None
2.5 结构化输出
输出结果之前先将多路召回结果合并
@staticmethod
def _merge_retrieval_results(lists: List[List[Dict[str, Any]]], limit: int) -> List[Dict[str, Any]]:
best: Dict[str, Dict[str, Any]] = {}
for lst in lists:
for result in lst:
result_id = result["id"]
previous = best.get(result_id)
if previous is None or result["score"] > previous["score"]:
best[result_id] = result
merged = sorted(best.values(), key=lambda item: item["score"], reverse=True)
return merged[:limit]
每次问答返回标准 JSON,方便前端渲染与用户溯源
KNOWLEDGE_QA_PROMPT = """
...
请以 JSON 格式输出:
{{
"answer": "详细回答(根据用户水平调整深度;引用处使用 [1] 等形式)",
"key_points": ["核心要点列表"],
"related_terms": ["相关术语列表"],
"follow_up_questions": ["适合继续追问的问题"],
"confidence": <置信度 0.0-1.0>,
"difficulty_level": "入门|中级|高级",
"answer_style": "通俗讲解|专业拆解|深度拓展"
}}
"""
2.6 RAG效果测试
测试方案:通过 Mock 外部依赖,对 RAG 服务的检索-生成核心链路进行单元测试,评估字段包括 question、contexts(召回块)、ground_truth(参考答案)和 answer(系统输出)。
典型测试用例如下:
其中ground_truth是参考答案,answer是系统输出答案
{
"question": "什么是市盈率(P/E ratio)?",
"ground_truth": "市盈率是股价与每股收益的比率,计算公式为:市盈率 = 股价 / 每股收益。它是衡量股票估值水平的常用指标,反映投资者为获得每一元净利润愿意支付的价格。市盈率越高,通常意味着市场对公司未来增长预期越高,但也可能表示股票被高估。",
"contexts": [
"# 市盈率",
"市盈率简称PE,是股票价格与每股收益的比值,计算公式为市盈率等于股价除以每股收益。市盈率反映了投资者为获得1元利润愿意支付的价格,是评估股票估值水平最常用的指标之一。一般而言,市盈率越低,股票相对越便宜,但也要结合行业和公司成长性综合判断。",
"市净率简称PB,是股票价格与每股净资产的比值,计算公式为市净率等于股价除以每股净资产。市净率适用于评估重资产行业如银行、钢铁、房地产等公司的估值水平。一般认为市净率低于1的股票价格跌破净资产,具有一定的安全边际。",
"# 市净率",
"# 债券收益率"
],
"answer": "市盈率(P/E ratio)是股票价格与每股收益的比值,计算公式为市盈率等于股价除以每股收益。它反映了投资者为获得1元利润愿意支付的价格,是评估股票估值水平最常用的指标之一。"
}
✅ 系统输出与参考答案核心一致,关键定义与公式均正确召回。
{
"question": "MACD指标是什么?",
"ground_truth": "MACD称为指数平滑异同移动平均线,是一种技术分析指标。它由两条线组成:DIF(差离值)和DEA(讯号线),以及柱状图。当DIF上穿DEA时形成金叉,是买入信号;当DIF下穿DEA时形成死叉,是卖出信号。MACD还可以用来判断股价的背离情况。",
"contexts": [
"# MACD指标",
"# RSI指标",
"MACD称为指数平滑异同移动平均线,由DIF线、DEA线和MACD柱组成。DIF线是短期指数移动平均线与长期指数移动平均线的差值,DEA线是DIF线的移动平均线。当DIF上穿DEA形成金叉时是买入信号,下穿形成死叉时是卖出信号。MACD柱表示DIF与DEA的差值,反映市场动能变化。",
"识,并不打算包罗万象,请读者原谅。\n 有电脑软件的朋友常常会看到MACD、威廉%等等电脑计算的买卖指标,流行\n的有二三十种之多。我学股的第二年曾花很多时间研究这些指标,结果上了大当。",
"RSI称为相对强弱指数,是通过计算一定时期内股价涨跌幅度来评估股票超买超卖状态的指标。RSI取值范围在0到100之间。RSI超过70通常表示股票处于超买状态可能面临回调,RSI低于30表示股票处于超卖状态可能存在反弹机会。RSI常用于判断股价走势的转折点。"
],
"answer": "MACD指标是指数平滑异同移动平均线,由DIF线、DEA线和MACD柱组成。DIF线是短期指数移动平均线与长期指数移动平均线的差值,DEA线是DIF线的移动平均线。当DIF上穿DEA形成金叉时是买入信号,下穿形成死叉时是卖出信号。MACD柱表示DIF与DEA的差值,反映市场动能变化。"
}
✅ 输出准确,结构比参考答案更完整,补充了 DIF / DEA 的计算逻辑。
⚠️ 待优化:召回块中混入了噪声片段(如"……有电脑软件的朋友常常会看到MACD……"),说明当前切块策略和相似度阈值过滤仍有提升空间,建议增加召回后的重排(Rerank)步骤。
三. 核心优化方向
目前已经实现RAG技术支持的金融知识问答模块,能从用户的角度考虑用户的知识接受度,并且有一定的上下文记忆能力,但是该模块可展示功能较为单一。现考虑从以下几点进行补充拓展,使金融知识问答模块的大语言模型功能能更贴近生活习惯。
1.历史会话列表 概括首个问题作为会话名
2.收藏、删除、置顶某会话
3.会话内删除、收藏某个问答
4.长期记忆机制
5.可视化切块过程和检索过程 该功能仅用于展示不作为系统功能
6.反馈问答的正确与否
7.和用户画像、新闻模块联动—
三、后续优化方向
当前模块已具备基础 RAG 问答能力,具有一定的上下文记忆能力,后续计划从三个层面持续迭代:
5.1 交互体验
- 历史会话列表,以首条问题自动命名会话
- 支持对会话的收藏、删除、置顶操作
- 会话内支持对单条问答的收藏与删除
- 问答质量反馈机制(正确 / 错误标注)
5.2 系统能力
- 长期记忆机制:跨会话保留用户偏好、知识盲区等状态
- 用户画像联动:根据用户投资风格、关注领域个性化问答内容
- 新闻模块联动:结合实时热点触发相关知识解读
5.3 开发调试(仅展示用,不作为正式功能)
- 可视化切块过程:展示段落边界、块 ID 与重叠区域
- 可视化检索过程:展示召回路径、向量相似度分布与多路合并结果
与AI关键对话记录如下:




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)