全双工语音大模型打通听-说-思,ASR 仿真规模化突破野外边界
Speech AI · FRONTIER
ASR/TTS 论文周报 · 第 004 期
📅 2026-05-18 至 2026-05-24 | 精选 TOP 9(含架构图)
📈 本周趋势小结
- 🔥 全双工语音大模型统一架构 — DuplexSLA 将听、说、规划三通道同步到 160ms 粒度,标志着 LLM 与实时语音融合进入新阶段
- 🎵 大规模开源 TTS 生态建设 — Raon-OpenTTS 发布 615K 小时数据池和 DiT 模型家族,填补开源高质量 TTS 基础设施空缺
- 🎯 ASR 野外泛化能力突破 — Mega-ASR 通过声学仿真规模化和 RL 训练在复杂场景将 WER 相对降低 30%+,开源 200 万小时数据集
- 🔗 音频 RAG 新范式 — PlanRAG-Audio 将"规划+结构化检索"引入长时音频理解,使小时级音频问答计算可行
- 🛡️ 超低码率与语音安全双线并进 — ClariCodec 以 RL 将编解码压至 300bps;音素级深度伪造检测提供可解释安全防护
🔝 #1 DuplexSLA: A Full-Duplex Spoken Language Model with Synchronized Speech, Language, and Action
Speech LLM Full-Duplex 实时对话 工具调用
⭐⭐⭐⭐⭐
提出 DuplexSLA,将用户音频(User)、助理语音(Assistant)和文本动作(Action)三通道同步到 160ms 统一时间线,采用单一自回归骨干同时预测语音 token 和动作文本。无需 ASR-TTS 串行管线,实现真正实时交互,可同步完成语音对话、规划任务和工具调用,并附带开源评测套件 DuplexSLA-Bench。
💡 亮点:首次将"边听边说边规划"三通道统一进单一自回归模型,每块 160ms 处理延迟极低;开源代码+评测基准,极具复现和跟进价值。
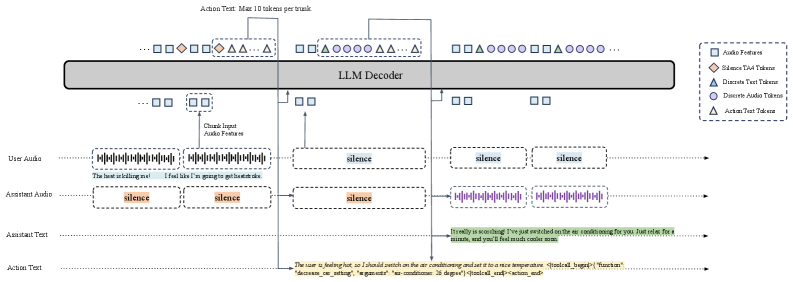
▲ 架构说明:三通道(用户音频特征、助理 TA4 语音 token、动作文本)共享 160ms 时间块,骨干 LLM 自回归地在同一上下文中预测语音与动作,实现真正的全双工同步。
📄 论文链接:arxiv.org/abs/2605.20755
💻 代码:github.com/hyzhang24/DuplexSLA
🔝 #2 Mega-ASR: Towards In-the-wild² Speech Recognition via Scaling up Real-world Acoustic Simulation
ASR 强化学习 声学仿真 大规模数据
⭐⭐⭐⭐
通过大规模真实世界声学仿真(“in-the-wild²”)构建 200 万小时野外语音数据,配合**双粒度 WER 门控策略优化(DG-WGPO)**进行强化学习训练,显著提升复杂场景 ASR 泛化能力。在多个野外测试集上相对 WER 降低达 30%+,同时开源 Voices-in-the-Wild-2M 数据集和配套评测基准。
💡 亮点:仿真规模化 + RL 双轮驱动,开源 200 万小时真实噪声数据,为低资源/野外 ASR 研究提供里程碑级数据基础。
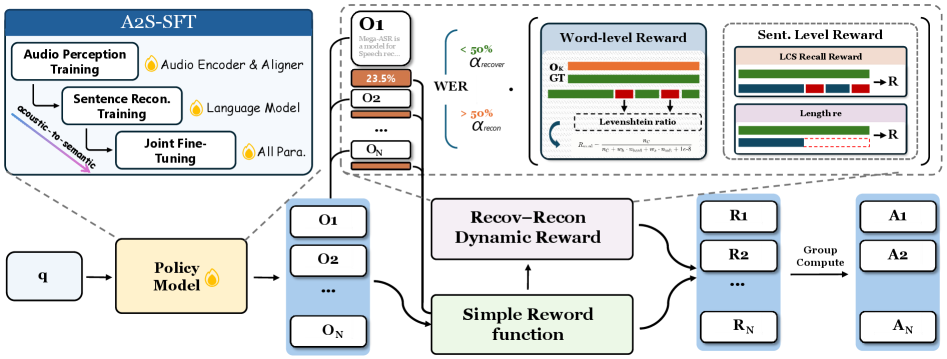
▲ 架构说明:从 A2S-SFT 初始化出发,策略模型生成多假设后经动态奖励(门控融合双粒度 WER 信号)评分并优化,形成 RL 训练闭环。
📄 论文链接:arxiv.org/abs/2605.19833
💻 代码/数据:github.com/xzf-thu/Voices-in-the-Wild-Bench
🔝 #3 Raon-OpenTTS: Open Models and Data for Robust Text-to-Speech
TTS DiT 模型 开源数据集 鲁棒性评测
⭐⭐⭐⭐
发布 Raon-OpenTTS-Pool(615K 小时英语语音)和经 DNSMOS/WER/语音比过滤的 510K 小时核心子集,训练基于 DiT 架构的 0.3B 和 1B 参数 TTS 模型家族。引入 Raon-OpenTTS-Eval 鲁棒性评测基准,涵盖干净、噪声、野外和表达性四类场景共 6K 评测提示。
💡 亮点:迄今最大规模开源 TTS 数据集之一,多维度过滤保证质量,0.3B/1B 两档模型满足不同部署需求,全套开源可复现。
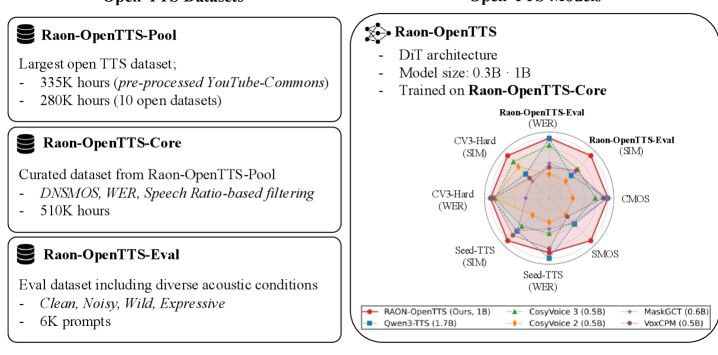
▲ 架构说明:数据池经三阶段过滤(DNSMOS、WER、语音比)精炼为核心训练集,DiT TTS 模型在其上训练,Eval 基准覆盖四类鲁棒性条件。
📄 论文链接:arxiv.org/abs/2605.20830
💻 代码:github.com/krafton-ai/RAON-OpenTTS
🔝 #4 SemaVoice: Semantic-Aware Continuous Autoregressive Speech Synthesis
TTS 语义对齐 连续自回归 扩散 Transformer
⭐⭐⭐⭐
提出 SemaVoice,通过语音基础模型(SFM)引导的对齐训练 VAE,使语音隐变量与语义特征在自相似矩阵层面对齐,获得语义感知的连续语音 token。推理阶段结合 LLM 骨干和**本地扩散 Transformer(LocDiT)**逐块生成连续语音,在自然度和语义一致性上优于离散 token 方法。
💡 亮点:将语义基础模型知识"蒸馏"进 VAE 隐空间,连续 token 兼顾音质与语义保真度,是 TTS 表征学习的新思路。
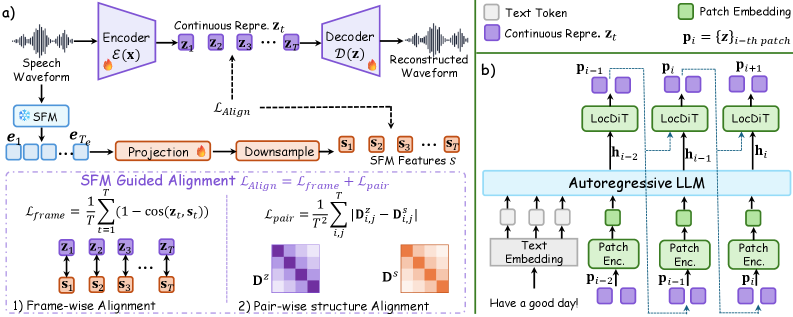
▲ 架构说明:(a) VAE 训练阶段,SFM 编码器提供语义监督,通过自相似矩阵对齐约束隐变量;(b) 推理阶段,LLM 骨干自回归生成 patch 序列,LocDiT 头逐 patch 扩散解码为连续语音帧。
📄 论文链接:arxiv.org/abs/2605.16964
🔝 #5 PlanRAG-Audio: Planning and Retrieval Augmented Generation for Long-form Audio Understanding
长时音频 RAG LLM 规划 多模态检索
⭐⭐⭐⭐
将长时音频理解转化为数据库检索问题:LLM 先规划推理步骤,任务专用模块将原始音频转为结构化时间对齐数据库,再通过 SQL 查询精准定位相关片段进行回答生成。大幅降低处理小时级音频的计算开销,在多项长时音频问答基准上显著领先端到端方法。
💡 亮点:首次将"规划+结构化检索"范式引入音频领域,突破长时音频理解的上下文限制,SQL 检索可解释高效。
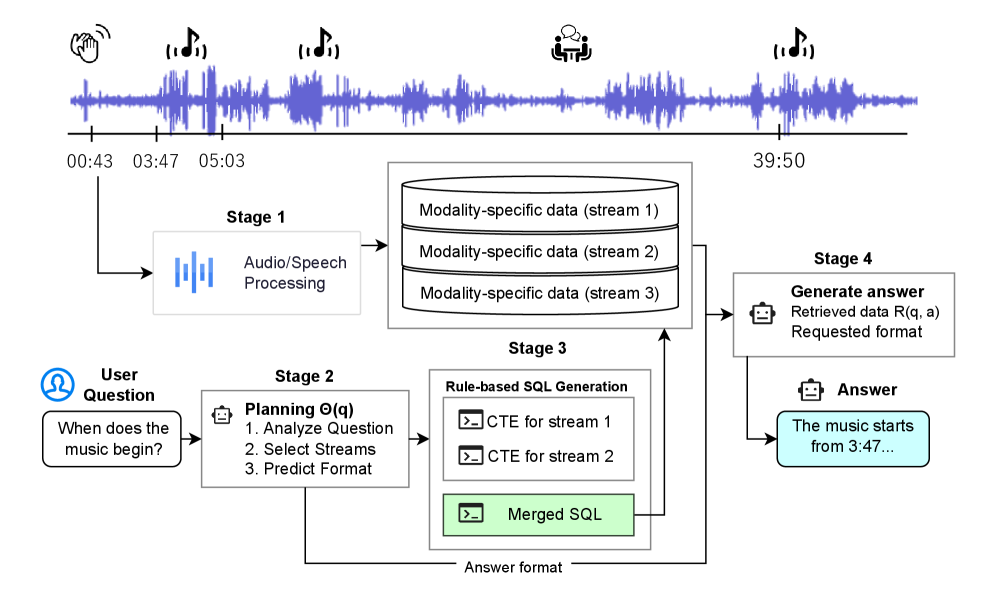
▲ 架构说明:系统四阶段流程:音频多模态处理 → LLM 规划推理步骤 → SQL 检索结构化音频数据库 → 答案生成,将长时音频问答解耦为可扩展的检索问题。
📄 论文链接:arxiv.org/abs/2605.20414
💻 代码:接受后开源
🔝 #6 Optimising Neural Speech Codecs for 300bps Communication using Reinforcement Learning
语音编解码 强化学习 超低码率 可懂度优化
⭐⭐⭐⭐
提出 ClariCodec,专为 300bps 超低码率通信优化的神经语音编解码器,两阶段训练:首先端到端训练重建保真度,再以 ASR 模型识别准确率为奖励信号对编码器进行强化学习微调,直接优化可懂度。在 300bps 极低码率下 WER 相对基线降低达 40%,无需任何人工特征工程。
💡 亮点:首次将 ASR 反馈作为 RL 奖励用于语音编解码器优化,思路新颖,可扩展至其他目标指标(说话人相似度、情感保留等)。
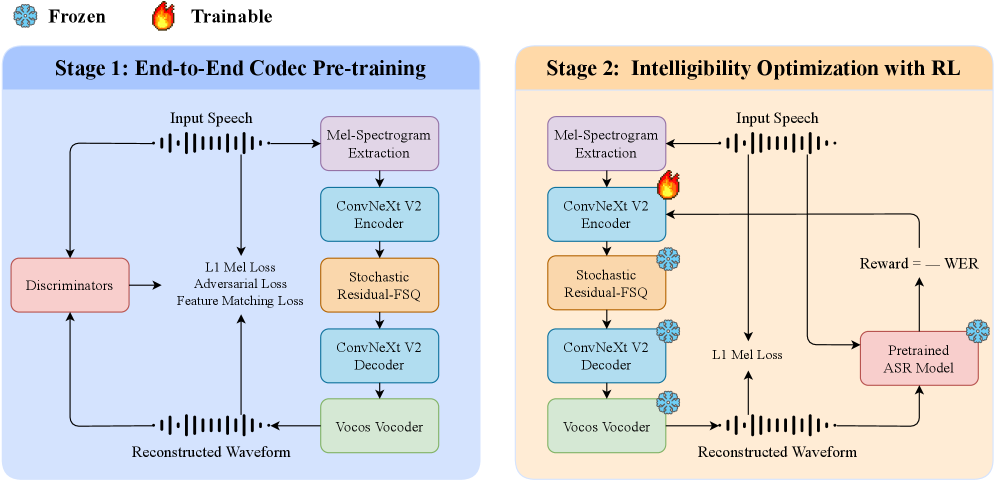
▲ 架构说明:Stage 1 全编解码器端到端训练(mel 重建 + 对抗 + 特征匹配损失);Stage 2 冻结解码器,仅以 ASR 奖励信号通过 RL 微调编码器,使编码表示对 ASR 可读性最优。
📄 论文链接:arxiv.org/abs/2605.19541
🎧 Demo:demo941.github.io/ClariCodec/
🔝 #7 Profiling the Voice: Speaker-Specific Phoneme Fingerprinting for Speech Deepfake Detection
深度伪造检测 音素指纹 说话人画像 IJCAI 2026
⭐⭐⭐⭐
提出基于音素指纹的个性化语音深度伪造检测框架(IJCAI 2026 已接收),通过双分支提取器为每位说话人建立音素级声学特征库,推理时检测音素分布异常以识别伪造。相比传统黑盒检测,在音素粒度上具备可解释性,在 ASVspoof 等标准数据集上取得 SOTA 性能。
💡 亮点:从"全局黑盒"转向"音素粒度可解释"的说话人指纹检测,附 phoneme 一致性热图可视化,IJCAI 2026 接收,实用性强。
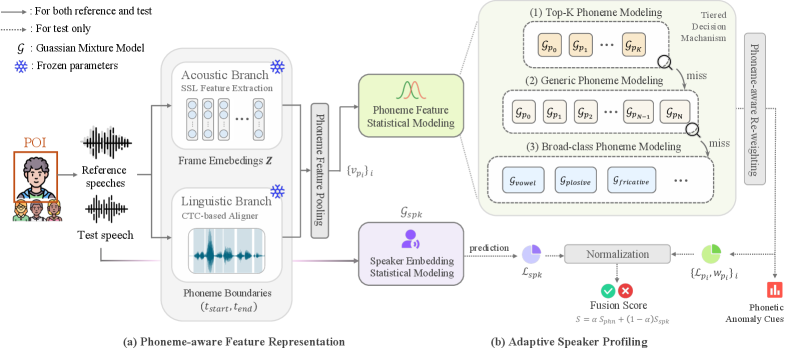
▲ 架构说明:(a) 音素感知特征表示:双分支提取器分别建模局部音素向量;(b) 自适应说话人画像:融合细粒度音素分布和整体说话人嵌入,推理时计算音素级异常分数。
📄 论文链接:arxiv.org/abs/2605.17737
💻 代码:github.com/JunXue-tech/PVP
🔝 #8 Contextual Biasing for Streaming ASR via CTC-based Word Spotting
流式 ASR 上下文偏置 CTC 热词定制
⭐⭐⭐
提出 Streaming CTC-WS,利用 CTC 解码器在流式 ASR 中实时检测用户定义词汇,以检测结果替换 Greedy 解码输出实现上下文偏置,无需修改底层模型结构。在 STOP 等数据集上相对 WER 降低 15%+,可与 NVIDIA FastConformer 等主流流式模型无缝集成。
💡 亮点:免训练即插即用的流式 ASR 热词偏置,Commit/Hold 跨块追踪机制保证流式稳定性,工业部署友好。
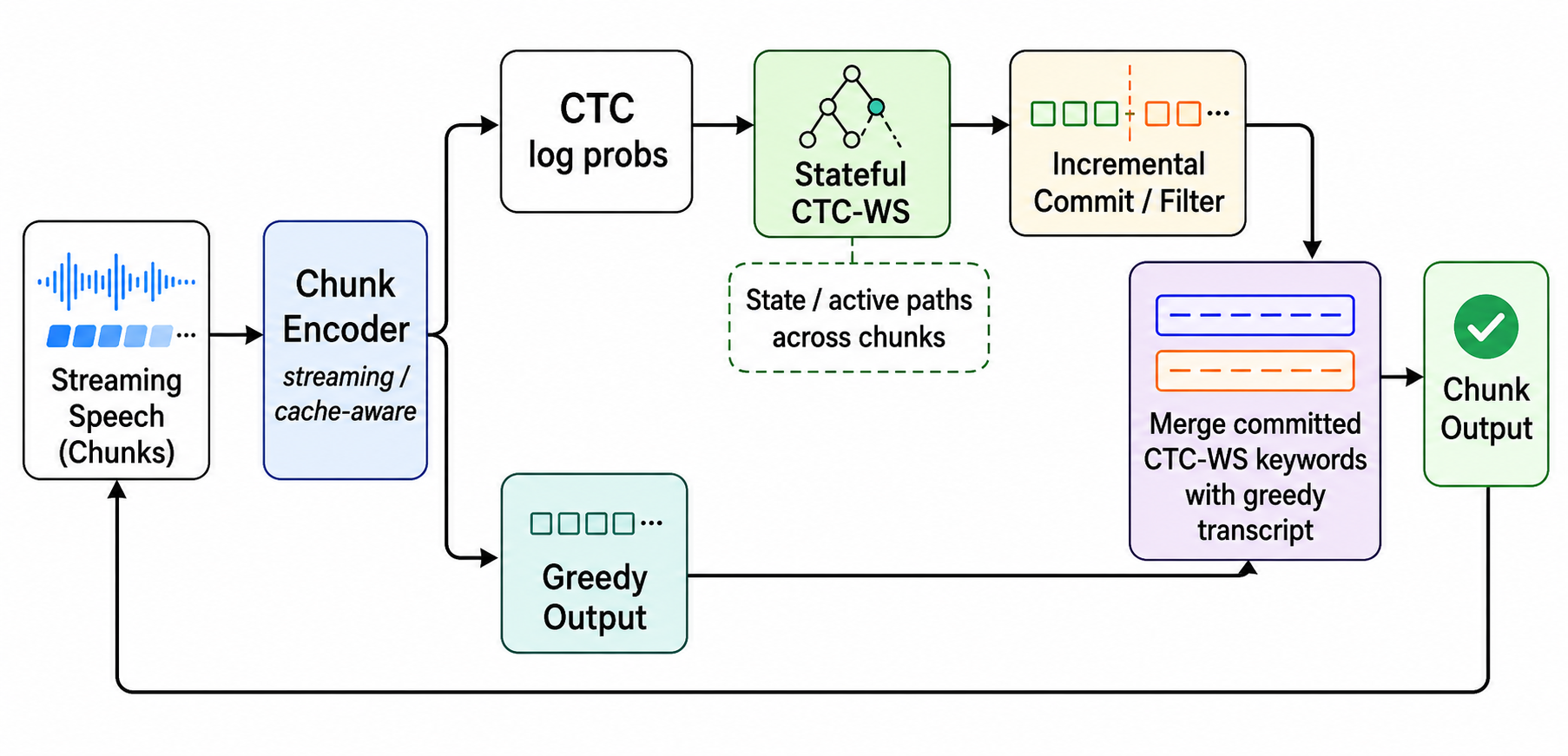
▲ 架构说明:CTC 解码器实时对每个流式块检测热词候选;Commit/Hold 机制跨块追踪未完成的关键词假设,安全提交后替换 ASR Greedy 输出。
📄 论文链接:arxiv.org/abs/2605.18222
🔝 #9 MedASR: An Open-Source Model for High-Accuracy Medical Dictation
医疗 ASR Conformer 开源模型 长文本转写
⭐⭐⭐
发布开源高精度医疗语音识别模型 MedASR,基于 17 层 Conformer(512 维、8 注意力头),采用时序融合推理(多窗口后验 logit 加权平均)实现稳定长文本医疗转写。覆盖放射学、家庭医学和内科等专科,相比 Whisper 等通用 ASR 在医疗领域平均 WER 相对降低 35%+,模型开源于 HuggingFace。
💡 亮点:医疗领域首个完整开源方案,时序融合机制有效处理长时医疗口述,HuggingFace 直接可用,临床部署价值高。
▲ 架构说明:不同时间窗口的后验 logit 分布通过加权平均融合,Hann 窗权重减少边界效应,使长时医疗口述转写更平滑稳定。
📄 论文链接:arxiv.org/abs/2605.16555
🤗 模型:huggingface.co/google/MedASR
Speech AI · FRONTIER · 每周语音算法前沿 · 第 004 期
关注公众号获取最新语音 AI 论文解读
本文由 AI 辅助整理,论文筛选与技术点评由作者完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)