从像素到令牌:VLA模型潜在动作监督的系统性研究
论文信息
- 标题:From Pixels to Tokens: A Systematic Study of Latent Action Supervision for Vision-Language-Action Models
- 会议:ICML 2026
- 单位:中国人民大学信息学院、数据工程与知识工程教育部重点实验室
- 代码:github.com/starVLA/starVLA
- 论文:https://arxiv.org/pdf/2605.04678v1.pdf
一、引言:机器人的"通用语言"终于找到了
如果你关注过具身智能,一定听过这样的吐槽:
- 不同机器人的动作空间完全不一样,一个机械臂的夹爪开合和另一个的关节角度根本没法通用
- 用A机器人的数据训练的模型,放到B机器人上直接废了
- 想混合多个数据集训练?先花三个月统一动作空间吧
这就是当前VLA(视觉-语言-动作)模型最大的痛点:异构数据集的动作语义不匹配。
而"潜在动作"(Latent Action)的出现,就像是给所有机器人发明了一门通用语言。它把不同机器人的原始动作,转换成一个统一的中间表示,让模型可以在不同数据集之间无缝迁移。
但问题来了:怎么把潜在动作和VLA模型结合起来才最好?是让模型先学视觉计划再生成动作?还是直接把动作变成令牌让模型预测?
之前的研究各说各话,没有一个统一的对比。这篇论文就做了一件大好事:在同一个VLA基准上,系统地对比了四种最具代表性的潜在动作监督策略,得出了三个非常实用的结论,直接告诉你不同场景下该用哪种方法。
二、核心概念:什么是潜在动作?
潜在动作是一种紧凑的中间表示,它从视觉变化或原始动作中抽象出与任务相关的信息。根据输入模态的不同,分为两大类:
2.1 图像基潜在动作(Image-based Latent Action)
定义:从连续的视觉帧中学习到的动作表示,描述的是"图像应该怎么变"。
通俗解释:就像你教别人叠衣服,不用告诉他每个手指怎么动,只要给他看"从摊开到叠好"的两张照片,他就知道该怎么做了。图像基潜在动作就是这两张照片之间的"变化量"。
它的数学定义是:
{ctimg=Eθ([ot;ot+δ]),ctimg∈Rd,ztimg=VQ(ctimg),ztimg∈{1,...,Kimg}P,o^t+δ=Dθ([ot;e(ztimg)]). \left\{\begin{array}{lr} c_{t}^{img}=E_{\theta}\left(\left[o_{t} ; o_{t+\delta}\right] \right), & c_{t}^{img} \in \mathbb{R}^{d}, \\ z_{t}^{img}=VQ\left(c_{t}^{img}\right), & z_{t}^{img} \in\left\{ 1, ..., K_{img}\right\}^{P}, \\ \hat{o}_{t+\delta} =D_{\theta}\left( \left[ o_{t}; e\left(z_{t}^{img}\right)\right] \right) . & \end{array}\right. ⎩
⎨
⎧ctimg=Eθ([ot;ot+δ]),ztimg=VQ(ctimg),o^t+δ=Dθ([ot;e(ztimg)]).ctimg∈Rd,ztimg∈{1,...,Kimg}P,
其中:
- oto_tot:t时刻的视觉观测
- ot+δo_{t+\delta}ot+δ:t+δ时刻的视觉观测
- EθE_\thetaEθ:视觉编码器
- DθD_\thetaDθ:视觉解码器
- VQ(⋅)VQ(\cdot)VQ(⋅):向量量化操作(把连续向量变成离散令牌)
- e(⋅)e(\cdot)e(⋅):码本(存储所有离散令牌对应的向量)
- ctimgc_t^{img}ctimg:连续的潜在嵌入
- ztimgz_t^{img}ztimg:离散的潜在动作令牌
- ddd:嵌入维度
- KimgK_{img}Kimg:码本大小
- PPP:每个时间步对应的令牌数
2.2 动作基潜在动作(Action-based Latent Action)
定义:从连续的动作序列中学习到的表示,描述的是"机器人应该怎么动"。
通俗解释:就像把不同国家的语言翻译成世界语,不管你原来的动作是关节角度、笛卡尔坐标还是夹爪力度,都转换成统一的潜在令牌。
它的数学定义是:
{ctact=Eϕ(at),ctact∈RH×d,ztact=VQ(ctact),ztact∈{1,...,Kact}H,a^t=Dϕ(e(ztact)),a^t∈RH×m. \left\{\begin{array}{rlrl} c_{t}^{act } & =E_{\phi}\left(a_{t}\right), & c_{t}^{act } \in \mathbb{R}^{H × d}, \\ z_{t}^{act } & =VQ\left(c_{t}^{act }\right), & z_{t}^{act } \in\left\{1, ..., K_{act }\right\}^{H}, \\ \hat{a}_{t} & =D_{\phi}\left(e\left(z_{t}^{act }\right)\right), & \hat{a}_{t} \in \mathbb{R}^{H × m} . \end{array}\right. ⎩
⎨
⎧ctactztacta^t=Eϕ(at),=VQ(ctact),=Dϕ(e(ztact)),ctact∈RH×d,ztact∈{1,...,Kact}H,a^t∈RH×m.
其中:
- ata_tat:原始动作块(包含H个连续动作)
- EϕE_\phiEϕ:动作编码器
- DϕD_\phiDϕ:动作解码器
- ctactc_t^{act}ctact:连续的动作嵌入
- ztactz_t^{act}ztact:离散的动作令牌
- KactK_{act}Kact:动作码本大小
- mmm:原始动作的维度
三、四种潜在动作监督策略
论文从两个互补的角度,提出了四种监督策略:
- 轨迹正则化:用图像基潜在动作作为高层计划,引导VLM的决策过程
- 目标空间统一:用动作基潜在动作统一不同机器人的动作空间
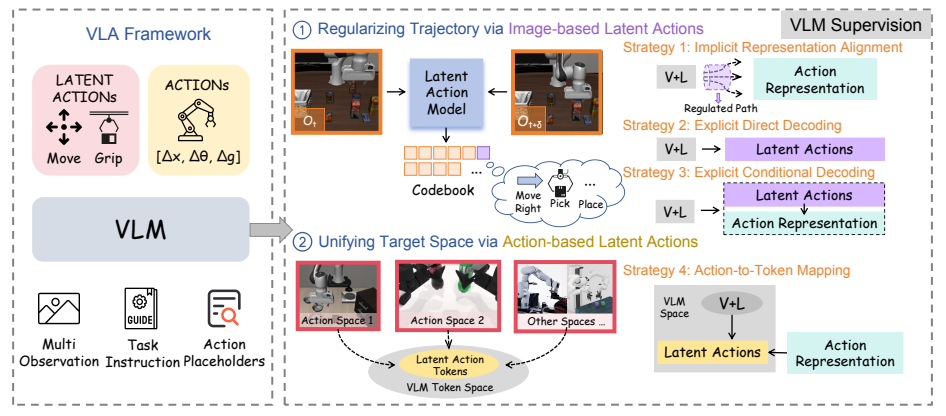
图1:潜在动作监督策略总览(来源:论文Figure 1)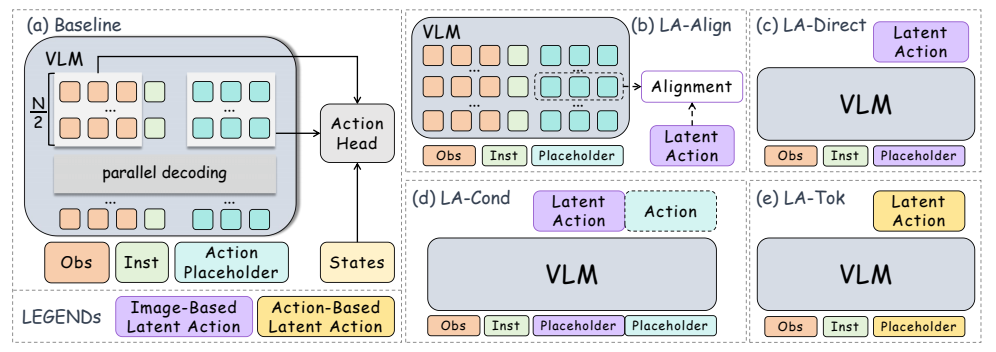
图2:四种策略的架构对比(来源:论文Figure 3)
3.1 统一训练目标
所有策略都使用同一个统一的损失函数:
Laction=Et[∑τ=0H−1∥a^t+τ−at+τ∗∥22],L=Laction+λLlatent. \begin{aligned} \mathcal{L}_{action } & =\mathbb{E}_{t}\left[\sum_{\tau=0}^{H-1}\left\| \hat{a}_{t+\tau}-a_{t+\tau}^{*}\right\| _{2}^{2}\right], \\ \mathcal{L} & =\mathcal{L}_{action }+\lambda \mathcal{L}_{latent } . \end{aligned} LactionL=Et[τ=0∑H−1
a^t+τ−at+τ∗
22],=Laction+λLlatent.
其中:
- Laction\mathcal{L}_{action}Laction:动作回归损失(L2损失)
- Llatent\mathcal{L}_{latent}Llatent:潜在监督损失(不同策略有不同的形式)
- λ\lambdaλ:平衡两个损失的权重
- HHH:动作块大小
- a^t+τ\hat{a}_{t+\tau}a^t+τ:预测的动作
- at+τ∗a_{t+\tau}^*at+τ∗:真实的动作
3.2 策略1:隐式表示对齐(LA-Align)
原理:不直接让VLM预测潜在动作,而是让VLM的内部特征和潜在动作嵌入对齐。
通俗解释:就像老师不用直接考你知识点,只要看你的思路和标准答案是不是一致就行。
它的潜在损失是:
Llatent=−Et[S(ϕalign(νt(k)),ctimg)] \mathcal{L}_{latent }=-\mathbb{E}_{t}\left[\mathcal{S}\left(\phi_{align }\left(\nu_{t}^{(k)}\right), c_{t}^{img}\right)\right] Llatent=−Et[S(ϕalign(νt(k)),ctimg)]
其中:
- νt(k)\nu_t^{(k)}νt(k):VLM第k层的动作占位符隐藏状态
- ϕalign\phi_{align}ϕalign:线性投影层(把VLM特征映射到潜在动作空间)
- S(⋅,⋅)\mathcal{S}(\cdot, \cdot)S(⋅,⋅):余弦相似度函数
- ctimgc_t^{img}ctimg:真实的图像基潜在嵌入
优点:架构改动最小,不需要修改输入序列
缺点:监督信号比较弱,效果不如显式方法
3.3 策略2:显式直接解码(LA-Direct)
原理:直接让VLM预测离散的潜在动作令牌,然后用这些令牌生成最终的动作。
通俗解释:就像写作文先列提纲,VLM先写出"第一步拿碗,第二步叠碗"的提纲,然后再把提纲翻译成具体的动作。
它的潜在损失是交叉熵损失:
Llatent=−∑h=0H−1logπvlm(zt+himg∗∣ot,ℓ) \mathcal{L}_{latent }= -\sum_{h=0}^{H-1} log \pi_{v l m}\left(z_{t+h}^{img *} | o_{t}, \ell\right) Llatent=−h=0∑H−1logπvlm(zt+himg∗∣ot,ℓ)
其中:
- πvlm\pi_{vlm}πvlm:VLM预测的潜在动作分布
- zt+himg∗z_{t+h}^{img *}zt+himg∗:真实的图像基潜在动作令牌
- oto_tot:视觉观测
- ℓ\ellℓ:语言指令
优点:监督信号强,效果最好,特别是长时序任务
缺点:需要把动作占位符全部换成潜在动作占位符
3.4 策略3:显式条件解码(LA-Cond)
原理:把占位符分成两部分,前半部分预测潜在动作,后半部分生成动作,并且动作生成显式依赖于潜在动作。
通俗解释:就像写作文必须先写完提纲才能写正文,VLM必须先完成高层计划,才能生成低层次的动作。
优点:强制模型先规划再执行,在多任务训练时表现最好
缺点:序列长度变长,计算量略有增加
3.5 策略4:动作到令牌映射(LA-Tok)
原理:把连续的动作块直接转换成离散令牌,让VLM直接预测这些动作令牌。
通俗解释:就像把中文直接翻译成英文,不需要中间的提纲,VLM直接输出动作令牌,然后再解码成连续动作。
优点:最适合复杂的运动控制任务,部署最简单
缺点:长时序推理能力不如图像基方法
四、实验结果:谁才是真正的王者?
论文在三个不同的基准上进行了全面的评估,得出了非常清晰的结论。
4.1 LIBERO基准:长时序推理的较量
LIBERO是一个专门评估长时序多阶段任务的基准,包含空间、物体、目标和长时序四个维度。
表1:LIBERO基准结果(来源:论文Table 1)
| 方法 | 空间 | 物体 | 目标 | 长时序 | 平均 | 提升 |
|---|---|---|---|---|---|---|
| Baseline | 96.6 | 97.2 | 92.8 | 85.8 | 93.1 | - |
| LA-Align | 97.4 | 98.6 | 97.2 | 94.8 | 97.0 | +3.9% |
| LA-Direct | 97.2 | 98.6 | 95.8 | 96.6 | 97.1 | +4.0% |
| LA-Cond | 97.0 | 99.4 | 95.8 | 94.2 | 96.6 | +3.5% |
| LA-Tok | 97.0 | 100.0 | 92.2 | 92.6 | 95.5 | +2.4% |
结果分析:
- 所有潜在动作监督策略都显著优于基线
- LA-Direct在长时序任务上表现最好,比基线提升了10.8%
- 图像基方法整体优于动作基方法,说明视觉计划对长时序任务更重要
4.2 RoboTwin 2.0基准:复杂运动控制的考验
RoboTwin 2.0是一个双机械臂操作基准,包含很多精细的运动控制任务。
表2:RoboTwin 2.0基准结果(来源:论文Table 2)
| 方法 | 移扑克牌 | 放容器 | 移罐子 | 拿双瓶 | 平均 | 提升 |
|---|---|---|---|---|---|---|
| Baseline | 73 | 86 | 46 | 37 | 60.5 | - |
| LA-Align | 78 | 88 | 55 | 61 | 70.5 | +10.0% |
| LA-Direct | 76 | 96 | 64 | 51 | 71.8 | +11.3% |
| LA-Cond | 76 | 89 | 52 | 78 | 73.8 | +13.3% |
| LA-Tok | 89 | 89 | 70 | 64 | 78.0 | +17.5% |
结果分析:
- LA-Tok在这个基准上碾压所有其他方法,比基线提升了17.5%
- 动作基方法优于图像基方法,说明离散动作令牌对复杂运动控制更有效
- LA-Cond在"拿双瓶"这个需要双手协调的任务上表现最好,达到了78%的成功率
4.3 真实世界实验:JAKA机械臂
论文还在真实的JAKA 7自由度机械臂上进行了实验,包含叠碗、擦污渍和杂乱桌面抓取任务。
图3:真实世界叠碗任务结果(来源:论文Figure 4)
最震撼的结果:
- 叠4个碗这个最难的任务,基线只能做到48分,而LA-Direct达到了79分,提升了65%
- 擦污渍任务,所有方法都表现很好,LA-Direct达到了98分
- 杂乱桌面抓取的OOD(分布外)场景,基线只有17分,而LA-Cond达到了70分,提升了312%!
这说明潜在动作监督不仅能提升性能,还能极大地增强模型的泛化能力。
4.4 三个核心发现
论文通过大量实验,得出了三个非常实用的结论:
- 配方-任务对应关系:图像基潜在动作适合长时序推理和场景泛化,动作基潜在动作适合复杂运动控制
- 显式优于隐式:直接监督VLM预测离散潜在动作令牌的效果最好
- 多任务训练的救星:潜在动作监督能显著减少多任务训练中的负迁移,让模型在所有任务上都有提升
五、核心代码实现
下面是一个简化版的VLA模型和四种监督策略的实现,基于PyTorch和Transformers:
"""
简化版VLA模型与潜在动作监督策略实现
基于Qwen3-VL-2B,保留核心逻辑
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor
# -------------------------- 核心超参数 --------------------------
HIDDEN_DIM = 1536 # Qwen3-VL-2B的隐藏维度
ACTION_DIM = 7 # 机械臂动作维度(x,y,z,rx,ry,rz,gripper)
ACTION_CHUNK = 8 # 动作块大小
CODEBOOK_SIZE = 256 # 潜在动作码本大小
# ---------------------------------------------------------------
class VQVAE(nn.Module):
"""简化版向量量化VAE,用于生成潜在动作"""
def __init__(self, input_dim, hidden_dim, codebook_size):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim)
)
self.codebook = nn.Embedding(codebook_size, hidden_dim)
self.decoder = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim)
)
def forward(self, x):
z = self.encoder(x)
# 向量量化
distances = torch.cdist(z, self.codebook.weight)
indices = torch.argmin(distances, dim=-1)
z_q = self.codebook(indices)
# 直通梯度估计
z_q = z + (z_q - z).detach()
x_recon = self.decoder(z_q)
return x_recon, z_q, indices
class VLAModel(nn.Module):
"""统一的VLA模型,支持四种潜在动作监督策略"""
def __init__(self, strategy="baseline"):
super().__init__()
self.strategy = strategy
# 加载预训练的Qwen3-VL
self.vlm = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen3-VL-2B",
torch_dtype=torch.bfloat16,
device_map="auto"
)
self.processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-2B")
# 动作头:从VLM隐藏状态预测连续动作
self.action_head = nn.Sequential(
nn.Linear(HIDDEN_DIM, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, ACTION_DIM)
)
# 潜在动作头:预测离散潜在令牌
if strategy in ["direct", "cond", "tok"]:
self.latent_head = nn.Linear(HIDDEN_DIM, CODEBOOK_SIZE)
# 对齐投影层:用于LA-Align
if strategy == "align":
self.align_proj = nn.Linear(HIDDEN_DIM, HIDDEN_DIM)
# 预训练的动作VQ-VAE(需要提前训练好)
self.action_vqvae = VQVAE(ACTION_DIM, HIDDEN_DIM, CODEBOOK_SIZE)
self.action_vqvae.eval() # 训练VLA时冻结
def forward(self, images, instructions, actions=None, latent_actions=None):
"""
Args:
images: 输入图像 [B, 3, 224, 224]
instructions: 语言指令列表 [B]
actions: 真实动作 [B, H, ACTION_DIM]
latent_actions: 真实潜在动作令牌 [B, H]
Returns:
loss: 总损失
pred_actions: 预测的动作
"""
# 构建输入提示
prompts = []
for instr in instructions:
if self.strategy == "baseline":
prompt = f"{instr}\n请预测接下来的{ACTION_CHUNK}个动作:" + "[ACTION]" * ACTION_CHUNK
elif self.strategy == "direct":
prompt = f"{instr}\n请预测接下来的{ACTION_CHUNK}个潜在动作:" + "[LATENT]" * ACTION_CHUNK
elif self.strategy == "cond":
prompt = f"{instr}\n请先预测潜在动作,再生成动作:" + "[LATENT]" * ACTION_CHUNK + "[ACTION]" * ACTION_CHUNK
elif self.strategy == "tok":
prompt = f"{instr}\n请预测接下来的{ACTION_CHUNK}个动作令牌:" + "[TOK]" * ACTION_CHUNK
prompts.append(prompt)
# 处理输入
inputs = self.processor(
text=prompts,
images=images,
return_tensors="pt",
padding=True
).to(self.vlm.device)
# VLM前向传播
outputs = self.vlm(**inputs, output_hidden_states=True)
hidden_states = outputs.hidden_states[-1] # 取最后一层隐藏状态
# 提取占位符对应的隐藏状态
placeholder_mask = inputs.input_ids == self.processor.tokenizer.convert_tokens_to_ids("[ACTION]")
latent_mask = inputs.input_ids == self.processor.tokenizer.convert_tokens_to_ids("[LATENT]")
tok_mask = inputs.input_ids == self.processor.tokenizer.convert_tokens_to_ids("[TOK]")
# 计算损失和预测动作
total_loss = 0.0
pred_actions = None
if self.strategy == "baseline":
# 基线:直接预测动作
action_hidden = hidden_states[placeholder_mask].reshape(-1, ACTION_CHUNK, HIDDEN_DIM)
pred_actions = self.action_head(action_hidden)
if actions is not None:
action_loss = F.mse_loss(pred_actions, actions)
total_loss = action_loss
elif self.strategy == "align":
# LA-Align:隐式表示对齐
action_hidden = hidden_states[placeholder_mask].reshape(-1, ACTION_CHUNK, HIDDEN_DIM)
pred_actions = self.action_head(action_hidden)
if actions is not None and latent_actions is not None:
action_loss = F.mse_loss(pred_actions, actions)
# 对齐损失:VLM特征与潜在嵌入的余弦相似度
aligned_hidden = self.align_proj(action_hidden)
latent_emb = self.action_vqvae.codebook(latent_actions)
align_loss = -F.cosine_similarity(aligned_hidden, latent_emb, dim=-1).mean()
total_loss = action_loss + 1.0 * align_loss
elif self.strategy == "direct":
# LA-Direct:显式直接解码
latent_hidden = hidden_states[latent_mask].reshape(-1, ACTION_CHUNK, HIDDEN_DIM)
pred_latent = self.latent_head(latent_hidden)
pred_actions = self.action_head(latent_hidden)
if actions is not None and latent_actions is not None:
action_loss = F.mse_loss(pred_actions, actions)
latent_loss = F.cross_entropy(pred_latent.transpose(1, 2), latent_actions)
total_loss = action_loss + 0.1 * latent_loss
elif self.strategy == "cond":
# LA-Cond:显式条件解码
latent_hidden = hidden_states[latent_mask].reshape(-1, ACTION_CHUNK, HIDDEN_DIM)
action_hidden = hidden_states[placeholder_mask].reshape(-1, ACTION_CHUNK, HIDDEN_DIM)
pred_latent = self.latent_head(latent_hidden)
# 动作生成依赖于潜在动作
combined_hidden = torch.cat([latent_hidden.mean(dim=1, keepdim=True), action_hidden], dim=1)
pred_actions = self.action_head(combined_hidden[:, 1:, :])
if actions is not None and latent_actions is not None:
action_loss = F.mse_loss(pred_actions, actions)
latent_loss = F.cross_entropy(pred_latent.transpose(1, 2), latent_actions)
total_loss = action_loss + 0.1 * latent_loss
elif self.strategy == "tok":
# LA-Tok:动作到令牌映射
tok_hidden = hidden_states[tok_mask].reshape(-1, ACTION_CHUNK, HIDDEN_DIM)
pred_tok = self.latent_head(tok_hidden)
# 从令牌解码动作
tok_indices = torch.argmax(pred_tok, dim=-1)
tok_emb = self.action_vqvae.codebook(tok_indices)
pred_actions = self.action_vqvae.decoder(tok_emb)
if actions is not None and latent_actions is not None:
action_loss = F.mse_loss(pred_actions, actions)
tok_loss = F.cross_entropy(pred_tok.transpose(1, 2), latent_actions)
total_loss = action_loss + 0.1 * tok_loss
return total_loss, pred_actions
# -------------------------- 示例用法 --------------------------
if __name__ == '__main__':
# 初始化模型(选择策略:baseline/align/direct/cond/tok)
model = VLAModel(strategy="direct")
# 模拟输入
images = torch.randn(2, 3, 224, 224)
instructions = ["把碗叠起来", "擦干净桌子上的污渍"]
actions = torch.randn(2, ACTION_CHUNK, ACTION_DIM)
latent_actions = torch.randint(0, CODEBOOK_SIZE, (2, ACTION_CHUNK))
# 前向传播
loss, pred_actions = model(images, instructions, actions, latent_actions)
print(f"总损失: {loss.item():.4f}")
print(f"预测动作形状: {pred_actions.shape}") # [2, 8, 7]
六、结论与展望
这篇论文是VLA领域非常重要的一篇系统性研究,它用严谨的实验告诉我们:
- 潜在动作监督是提升VLA模型性能和泛化能力的有效手段
- 没有万能的策略,不同的任务需要不同的潜在动作类型
- 直接预测离散潜在令牌是目前最有效的监督方式
对于实际应用来说,这篇论文给出了非常明确的指导:
- 如果你的任务是长时序多阶段操作(比如组装、叠衣服),用LA-Direct
- 如果你的任务是精细的运动控制(比如拧螺丝、插插头),用LA-Tok
- 如果你需要在多个异构数据集上联合训练,用LA-Cond
未来,潜在动作的研究方向可能包括:
- 学习跨模态的统一潜在表示,同时融合视觉和动作信息
- 用大语言模型生成潜在动作计划,进一步提升长时序推理能力
- 让潜在动作具有可解释性,让人类可以理解机器人的决策过程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献95条内容
已为社区贡献95条内容

所有评论(0)