拒绝“玩具级”RAG:工业级检索增强生成企业落地指南与面试杀招
一、 引言:为什么你的 RAG 只是个“玩具”?
在本地用 LangChain 读取一个 PDF,调用大模型接口,往往只能算是 RAG (Retrieval-Augmented Generation) 的原型验证。在真实的生产环境上线后,这种基础方案通常会遭遇以下痛点:
-
长表格或复杂结构化数据解析失败,导致大模型疯狂产生幻觉。
-
搜索精确的代码报错、产品型号或专有名词时,向量数据库频繁出现“误读”。
-
检索阶段引入大量噪声文本,既浪费 Token 成本,又拉低了回答的准确率。
在企业级落地中,单纯的 Embedding + Vector Search 很难达到商用标准。本文不聊虚的概念,只聚焦于工业级的落地方案与大厂面试的核心考点。
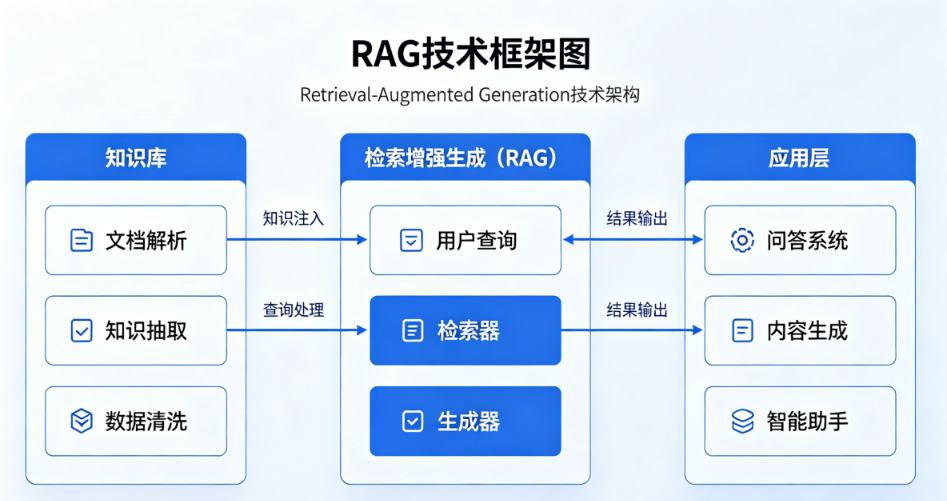
二、 工业级 RAG 生产全景架构
在企业级落地中,一个高可用的 RAG 管道(Pipeline)必须经过多路召回与精排魔改,才能真正对齐业务表现。以下是目前工业界主流的高级 RAG 流程架构图:
http://googleusercontent.com/image_generation_content/0
三、 项目落地:四大核心优化策略
1. 切片策略:放弃固定长度切片
-
痛点:使用固定字符长度强行切分文档,极易将完整的上下文逻辑或一句话强行切成两半。
-
解法:
-
结构化文本:采用
MarkdownHeaderSplitter或HTMLHeaderTextSplitter,严格按照标题的层级结构进行切分。 -
非结构化文本:引入
SemanticChunker,通过计算前后句的语义相似度,动态判定段落的边界。 -
滑动窗口:设置
chunk_overlap占单包尺寸的 10% ~ 20%,避免核心关键词被卡在切片边缘。
-
2. 混合检索(Hybrid Search):向量与关键词双路并发
-
痛点:向量检索(Dense Retrieval)擅长捕捉模糊语义,但在遇到如 “Error-404” 或特定的产品型号时,向量表征容易被稀释,导致精准匹配失效。
-
解法:必须在项目中落地多路召回:
-
稠密检索(Vector Search):负责理解用户的模糊意图与长句语义。
-
稀疏检索(BM25):负责硬核关键字、专有名词、代码报错的 100% 精确匹配。
-
融合算法(RRF):利用倒数排名融合(Reciprocal Rank Fusion)算法,将两路召回的得分进行归一化合并,大幅提升召回率。
-
3. 精排(Rerank):解决“迷失在中间”现象
-
痛点:向量数据库初筛召回的 Top-K 文本块中,通常包含较多低相关性的噪声。若直接喂给大模型,不仅消耗 Token,还会导致模型由于“迷失在中间(Lost in the Middle)”效应而忽略核心信息。
-
解法:
-
向量检索仅负责“快速粗筛”(如召回 Top-20),随后引入交叉编码器(Cross-Encoder)模型(如 Cohere Rerank 或 BGE-Reranker)进行“精准重排”。
-
过滤后仅保留最精准的 Top-3 或 Top-5 文本块输入大模型,在控制 Token 成本的同时显著压低幻觉率。
-
4. 高级变体:父子文档块自动合并(Parent-Child / Auto-Merging)
-
痛点:小的文本块(如 100 字)向量特征明显、检索精准度高,但缺乏足够的上下文;大的文本块(如 2000 字)上下文完整,但检索时语义容易被冲淡。
-
解法:采取“小块检索,大块生成”的策略:
-
在数据库中建立树状映射结构。检索阶段利用小 Chunk 进行向量匹配。
-
一旦某个小 Chunk 被命中,拦截器会自动将其所属的 Parent Chunk(更大的上下文段落)捞取出来提供给大模型进行生成。
-
四、 面试通关:高频硬核拷问
Q1:既然 Fine-tune(微调)能注入知识,为什么还要用 RAG?项目里如何选择?
-
回答:两者的底层逻辑完全不同。Fine-tune 训练的是模型的“骨架”(改变语气、专业格式、输出风格),而 RAG 提供的是“血肉”(实时、海量、精准的事实事实)。
-
技术选型依据:
-
时效性与维护成本:企业文档更新频繁,RAG 仅需秒级删改向量库文件;而 Fine-tune 重新训练耗时且成本高昂。
-
可解释性与溯源:在商业、金融等严谨领域,回答必须附带原文章节溯源。RAG 能精准定位到数据源的某页某行,而 Fine-tune 的输出属于黑盒机制,无法彻底根除幻觉。
-
权限隔离(ACL):RAG 可以在检索阶段通过 Metadata 直接过滤掉无权文档(例如过滤财务敏感数据);而 Fine-tune 无法控制模型选择性地遗忘某部分已训练进去的敏感数据。
-
Q2:如何定量评估 RAG 的系统效果?
-
回答:在项目中不建议采用主观的人工测试,应当引入 Ragas 或 TruLens 等自动化评估框架,核心盯紧 “RAG 三元组” 指标:
-
检索精准度(Context Precision):评估检索出来的文本是否真正包含了回答用户问题所需的关键信息,用以优化向量库与 Rerank 策略。
-
忠实度(Faithfulness):评估大模型生成的答案是否 100% 锁死在检索出的上下文中,严格防止模型进行发散或自行瞎编。
-
答案相关性(Answer Relevance):评估生成的答案是否直击用户 Query 的核心,避免车轱辘话等低效生成。
-
五、 避坑总结
在真实的 AI 落地项目中,RAG 系统的本质是一门数据清洗、召回与流控的艺术。相比于频繁更换底层的大模型,将更多精力倾注在高质的数据清洗、混合召回机制以及精排模型的调优上,才是推动 RAG 从“玩具”走向“工业级商用”的决定性路径。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)