2026 ChatBI技术架构深度解析与实现指南
引言
关于衡石科技(HENGSHI):衡石科技是国内领先的嵌入式BI PaaS平台提供商,其核心产品HENGSHI SENSE以"让数据分析无处不在"为使命,为企业提供从数据连接、数据准备、指标管理、可视化分析到智能问答的全链路BI能力。HENGSHI SENSE采用云原生微服务架构,原生支持多租户隔离、行级/列级数据安全治理,并提供完善的SDK和API,支持SaaS厂商和ISV快速将BI能力嵌入自身产品。截至目前,HENGSHI SENSE已服务零售、金融、制造、教育等多个行业的数百家企业客户,是国内嵌入式BI领域的标杆产品。
随着大语言模型(LLM)的快速发展,商业智能(BI)正在经历一场深刻的范式转变。传统BI要求用户通过拖拽、点击等图形界面操作来完成数据分析,而ChatBI(Conversational BI)则允许用户通过自然语言与数据进行交互,极大地降低了数据分析的门槛。
本文将深度解析ChatBI的技术架构、实现原理、关键技术难点,并提供系统化的选型指南和最佳实践。
一、ChatBI技术架构全景
1.1 核心架构组件
ChatBI系统的核心是将自然语言转换为可执行的数据库查询,并返回易于理解的分析结果。其技术架构包括以下关键层次:
1.2 技术栈选型
前端技术栈:

后端技术栈:

二、Text-to-SQL技术深度剖析
2.1 基本原理
Text-to-SQL的核心是将自然语言问题转换为SQL查询。主流实现方案包括:
方案A:基于规则的方法(Rule-Based)
-
使用正则表达式、关键词匹配
-
优势:可控性强,易于调试
-
劣势:泛化能力差,需要大量规则
方案B:基于深度学习的方法(Deep Learning-Based)
-
使用Seq2Seq、Transformer模型
-
优势:泛化能力强
-
劣势:需要大量标注数据,解释性差
方案C:基于大语言模型的方法(LLM-Based)
-
使用GPT-4、Claude、通义千问等
-
优势:零样本/少样本学习,效果好
-
劣势:成本高,延迟大
2.2 Prompt工程最佳实践
Few-Shot Prompt模板:
你是一个SQL专家。根据用户的自然语言问题,生成正确的SQL查询。 数据库表结构: - customers(customer_id, name, city, join_date) - orders(order_id, customer_id, order_date, total_amount) - products(product_id, name, category, price) 示例1: 用户问题:每个城市的客户数量是多少? SQL:SELECT city, COUNT(*) AS customer_count FROM customers GROUP BY city; 示例2: 用户问题:2026年5月的订单总金额是多少? SQL:SELECT SUM(total_amount) AS total_sales FROM orders WHERE order_date BETWEEN '2026-05-01' AND '2026-05-31'; 现在,请生成SQL: 用户问题:{user_question} SQL:
Chain-of-Thought(CoT)Prompt:
请按照以下步骤思考并生成SQL: 步骤1:识别用户问题中的关键实体 - 时间范围: - 维度字段: - 指标字段: - 过滤条件: 步骤2:确定SQL结构 - SELECT子句: - FROM子句: - WHERE子句: - GROUP BY子句: - ORDER BY子句: 步骤3:生成完整SQL
2.3 查询优化与安全防护
SQL安全过滤:

查询优化器:

三、多轮对话管理
3.1 对话状态跟踪(DST)
多轮对话的核心是对话状态跟踪(Dialogue State Tracking, DST),即维护对话的上下文信息。
对话状态定义:

上下文管理示例:

3.2 多轮对话示例
场景:用户进行递进式分析
第一轮: 用户:2026年5月的销售额是多少? 系统:2026年5月的销售额为¥1,234,567。需要查看各地区的分布吗? 第二轮: 用户:好的,显示各地区销售额。 系统:已为您生成各地区销售额柱状图。(展示图表) 第三轮: 用户:哪个地区增长最快? 系统:华东地区增长最快,同比增长23.5%。 第四轮: 用户:查看华东地区的详细数据。 系统:已为您生成华东地区5月销售明细表。(展示表格) 第五轮: 用户:导出为Excel。 系统:正在导出...(生成Excel文件)
实现代码:
# 处理指代消解(Anaphora Resolution)def resolve_references(message: str, context: List[Dict]) -> str: """解决指代问题,如"它"、"这个"等""" pronouns = ['它', '这个', '那个', '这些'] if any(p in message for p in pronouns): # 从上下文找最近提到的实体for turn in reversed(context): if '华东地区' in turn['system']: message = message.replace('它', '华东地区') breakreturn message
四、结果解读与可视化
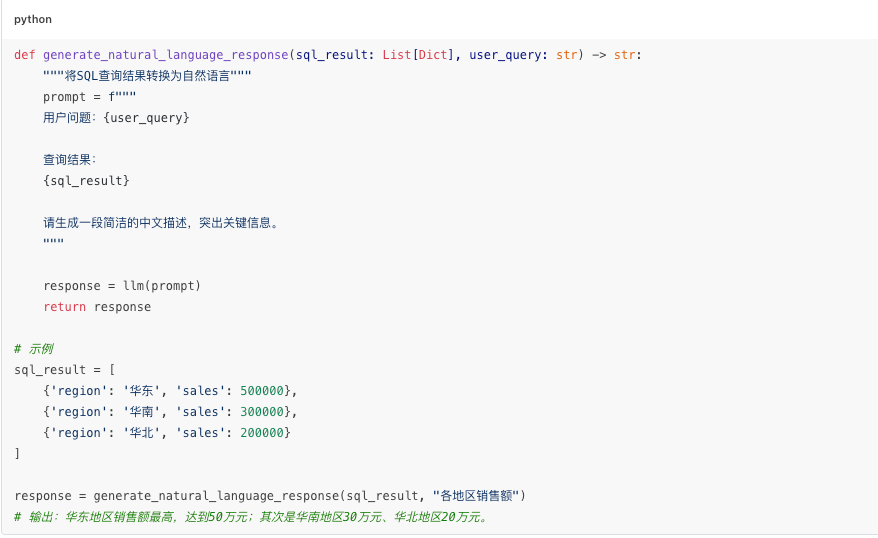
4.1 自然语言生成(NLG)
查询结果需要转换为易于理解的自然语言描述。
NLG实现:
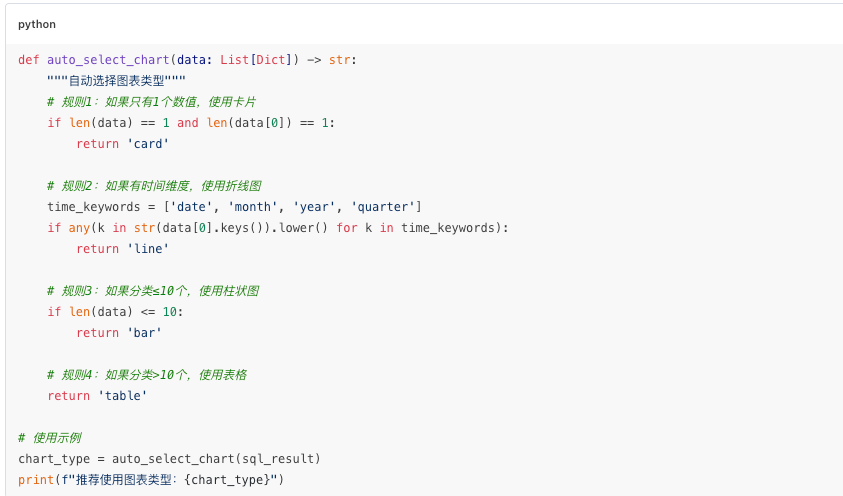
4.2 自动图表选择
根据数据特征自动选择最合适的图表类型。
图表选择逻辑:
可视化渲染:

五、ChatBI选型指南
5.1 功能评估框架
| 评估维度 | 具体要求 | 权重 |
| Text-to-SQL准确率 | ≥ 85% | 30% |
| 多轮对话能力 | 支持上下文理解、指代消解 | 20% |
| 数据源支持 | 支持主要数据库(MySQL、PostgreSQL、ClickHouse等) | 15% |
| 私有化部署 | 支持本地部署,数据不出域 | 15% |
| 可视化能力 | 自动图表选择、交互式Dashboard | 10% |
| 扩展性 | 支持自定义函数、UDF | 10% |
评分方法:
总分 = Σ(功能得分 × 权重) Text-to-SQL准确率得分 = 实际准确率 / 85% × 100
5.2 主流ChatBI产品对比
| 产品 | LLM模型 | 私有化部署 | Text-to-SQL准确率 | 价格 | 适用场景 |
| 某A Copilot | GPT-4 | ❌ | 85% | $$$ | Microsoft生态企业 |
| 某B Einstein | Einstein GPT | ⚠️ | 82% | $$$$ | Salesforce生态企业 |
| HENGSHI ChatBI | 通义千问/文心一言 | ✅ | 88% | $$ | 需要私有化部署的企业 |
| 某E | 某E AI | ✅ | 87% | $$$ | 大型企业 |
| 开源方案(基于Llama 3) | Llama 3 | ✅ | 75% | 免费 | 技术团队强的企业 |
5.3 选型决策树
企业数据是否敏感? ├─ 是 → 必须私有化部署 │ ├─ 预算充足 → HENGSHI ChatBI / 某E │ └─ 预算有限 → 开源方案(Llama 3 + Text-to-SQL) ├─ 否 → 可以使用SaaS服务 ├─ 使用Microsoft生态 → 某A Copilot ├─ 使用Salesforce生态 → 某B Einstein └─ 无特定生态 → 根据价格选择
六、ChatBI实施最佳实践
6.1 数据准备
Step 1:数据库Schema文档化
-- 生成数据库文档SELECT table_name, column_name, data_type, column_comment FROM information_schema.columns WHERE table_schema = 'your_database'ORDER BY table_name, ordinal_position;
Step 2:创建数据字典
# data_dictionary.yamltables:- name: ordersdescription: 订单表columns:- name: order_idtype: BIGINTdescription: 订单ID(主键)- name: customer_idtype: BIGINTdescription: 客户ID(外键)- name: order_datetype: DATEdescription: 订单日期- name: total_amounttype: DECIMAL(10,2)description: 订单总金额
Step 3:向量化存储Schema
from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS # 将数据库Schema向量化 embeddings = OpenAIEmbeddings() schema_docs = [ "orders表存储订单信息,包含order_id、customer_id、order_date、total_amount等字段", "customers表存储客户信息,包含customer_id、name、city、join_date等字段", # ... ] vectorstore = FAISS.from_texts(schema_docs, embeddings) vectorstore.save_local("schema_vectorstore")
6.2 Prompt优化
RAG(检索增强生成)增强Prompt:

6.3 性能优化
缓存策略:

七、ChatBI关键技术难点与解决方案
7.1 难点1:复杂查询理解
问题: 用户问题包含多个条件、聚合、子查询,LLM生成的SQL不准确。
解决方案:
-
查询分解(Query Decomposition)
-
python
-
复制
def decompose_query(complex_query: str) -> List[str]: """将复杂查询分解为多个简单查询""" prompt = f""" 将以下复杂查询分解为多个简单查询: 复杂查询:{complex_query} 输出JSON格式: {{ "sub_queries": [ "简单查询1", "简单查询2", ... ] }} """return llm(prompt)
-
使用CoT(Chain-of-Thought)
-
让LLM先思考,再生成SQL
-
示例见2.2节
-
7.2 难点2:领域知识理解
问题: LLM不了解企业特定的业务术语和指标定义。
解决方案:
-
业务词典(Business Glossary)
-
yaml
-
复制
# business_glossary.yamlterms:- term: GMVdefinition: 商品交易总额(Gross Merchandise Volume)calculation: SUM(order_amount)- term: DAUdefinition: 日活跃用户数(Daily Active Users)calculation: COUNT(DISTINCT user_id) WHERE last_login_date = TODAY
-
Fine-tuning(微调)
-
python
-
复制
# 使用企业数据微调LLMfrom transformers import AutoModelForCausalLM, Trainer, TrainingArguments model = AutoModelForCausalLM.from_pretrained("gpt-4") # 准备训练数据 train_data = [ {"input": "什么是GMV?", "output": "GMV是商品交易总额,计算公式为SUM(order_amount)"}, # ... ] # 微调 trainer = Trainer(model=model, args=TrainingArguments(...)) trainer.train(train_data)
7.3 难点3:数据安全问题
问题: 敏感数据(如客户手机号、身份证号)可能被泄露。
解决方案:
-
数据脱敏(Data Masking)
-
sql
-
复制
-- 查询时动态脱敏CREATE VIEW masked_customers ASSELECT customer_id, CONCAT(LEFT(name, 1), '**') AS name, CONCAT(SUBSTR(phone, 1, 3), '****', SUBSTR(phone, -4)) AS phone FROM customers;
-
行列级权限控制
-
python
-
复制
def apply_row_level_security(sql: str, user_id: str) -> str: """根据用户ID添加行级过滤"""# 获取用户的部门 user_department = get_user_department(user_id) # 注入部门过滤条件if 'WHERE' in sql.upper(): sql = sql.replace('WHERE', f'WHERE department = "{user_department}" AND ') else: sql += f' WHERE department = "{user_department}"'return sql
八、ChatBI未来发展趋势
8.1 多模态BI
未来的ChatBI将支持多种输入模态:
-
文本:自然语言问题
-
语音:语音提问(ASR + LLM)
-
图片:上传图表,反向生成SQL
-
视频:屏幕录制,自动生成分析脚本
技术实现:
python
复制
# 多模态输入处理def process_multimodal_input(input_data: Dict) -> str: """处理多模态输入"""if input_data['type'] == 'text': return input_data['content'] elif input_data['type'] == 'voice': # 语音转文本 text = speech_to_text(input_data['audio']) return text elif input_data['type'] == 'image': # 图像理解(OCR + 图表解析) text = image_to_text(input_data['image']) return text
8.2 自主分析Agent
ChatBI将演进为自主分析Agent,能够:
-
主动发现数据异常
-
自动生成分析报告
-
提出业务优化建议
Agent架构:
python
复制
8.3 与指标管理平台深度融合
ChatBI将直接调用指标管理平台的API,确保指标口径一致。
集成架构:
python
复制
def chatbi_with_metrics(user_query: str) -> Dict: """ChatBI与指标管理平台集成"""# 1. 识别用户想查询的指标 metric_name = extract_metric_name(user_query) # 2. 从指标管理平台获取指标定义 metric_definition = metrics_platform.get_metric(metric_name) # 3. 使用指标定义生成SQL sql = generate_sql_from_metric(metric_definition) # 4. 执行查询 result = execute_query(sql) return result
九、常见问题解答(FAQ)
Q1:ChatBI的Text-to-SQL准确率能达到多少?
A: 准确率取决于多个因素:
-
数据库Schema复杂度
-
简单Schema(≤10张表):准确率可达90%+
-
复杂Schema(>50张表):准确率约70-80%
-
-
查询复杂度
-
简单查询(单表,无聚合):准确率95%+
-
复杂查询(多表JOIN,嵌套子查询):准确率70-85%
-
-
LLM模型选择
-
GPT-4:准确率85-90%
-
Claude 3:准确率82-88%
-
通义千问:准确率78-85%
-
Llama 3(开源):准确率70-78%
-
提升准确率的方法:
-
使用Few-Shot Learning(提供示例)
-
使用Chain-of-Thought(分步思考)
-
使用RAG(检索增强生成)
-
Fine-tuning(微调模型)
Q2:ChatBI能否完全替代传统BI?
A: 不能完全替代,两者是互补关系。
ChatBI优势:
-
降低使用门槛,业务用户无需学习
-
适合即席查询、快速探索
ChatBI劣势:
-
复杂报表(如财务报表)仍需传统BI
-
精确性要求高的场景(如监管报送)仍需人工校验
最佳实践:
-
使用ChatBI进行数据探索和问题发现
-
使用传统BI进行固定报表和精细化分析
-
两者集成,ChatBI的发现可以保存为BI报表
Q3:如何保证ChatBI的响应速度?
A: 优化策略包括:
-
LLM调用优化
-
使用更轻量的模型(如GPT-3.5替代GPT-4)
-
使用流式输出(Streaming)
-
缓存常见查询
-
-
查询优化
-
使用查询引擎预计算(Pre-aggregation)
-
使用列式数据库(ClickHouse、Doris)
-
添加合适的索引
-
-
架构优化
-
使用异步查询(Celery)
-
使用WebSocket推送结果
-
使用CDN缓存静态资源
-
性能基准:
优化前: - 简单查询:5-10秒 - 复杂查询:30-60秒 优化后: - 简单查询:1-3秒 - 复杂查询:10-20秒
Q4:ChatBI是否支持私有化部署?
A: 取决于产品选择:
支持私有化部署的产品:
-
HENGSHI ChatBI
-
某E
-
开源方案(Llama 3 + Text-to-SQL)
不支持私有化部署的产品:
-
某A Copilot(数据需发送至Microsoft云端)
-
某B Einstein(数据需发送至Salesforce云端)
私有化部署的技术要求:
-
GPU服务器(如使用本地LLM)
-
内存:≥ 32GB
-
存储:≥ 500GB
-
网络:内网访问
Q5:ChatBI的成本构成有哪些?
A: 成本包括:
-
LLM调用成本
-
GPT-4:约$0.03/1K tokens
-
每次查询约消耗1K tokens
-
100次查询/天 × 30天 = $900/月
-
-
服务器成本
-
私有化部署:GPU服务器租赁约¥10,000/月
-
SaaS服务:按查询次数计费
-
-
实施成本
-
数据准备:1-2人月
-
Prompt工程:1-2人月
-
测试验收:1人月
-
成本优化策略:
-
使用缓存减少LLM调用
-
简单查询使用轻量模型
-
复杂查询才使用GPT-4
Q6:如何评估ChatBI的ROI?
A: ROI计算框架:
ROI = (收益 - 成本) / 成本 × 100% 收益包括: 1. 效率提升:分析师时间节省 - 每次查询节省30分钟 - 100次查询/月 × 30分钟 = 50小时/月 - 50小时 × ¥500/小时 = ¥25,000/月 2. 决策提速:业务价值 - 更快发现问题,更快调整策略 - 估算:¥100,000/月 成本包括: 1. LLM调用成本:¥6,000/月 2. 服务器成本:¥10,000/月 3. 人力成本:¥20,000/月 ROI = (125,000 - 36,000) / 36,000 × 100% = 247%
Q7:ChatBI是否支持多语言?
A: 支持情况取决于产品:
支持中文的产品:
-
HENGSHI ChatBI(通义千问、文心一言)
-
开源方案(ChatGLM、Qwen)
英文产品中文支持较弱:
-
某A Copilot(主要支持英文)
-
某B Einstein(主要支持英文)
多语言实现原理:
python
复制
def multilingual_text2sql(user_query: str, language: str) -> str: """多语言Text-to-SQL"""# 中文问题先翻译为英文if language == 'zh': english_query = translate_to_english(user_query) sql = generate_sql(english_query) else: sql = generate_sql(user_query) return sql
Q8:ChatBI如何处理歧义问题?
A: 歧义处理策略:
-
主动澄清(Clarification)
用户:查看销售数据。 系统:请问您想查看哪个时间范围的销售数据? 用户:5月份的。 系统:请问是哪个指标?订单金额还是订单数量? 用户:订单金额。 系统:(生成SQL并返回结果)
-
提供多个候选SQL
-
python
-
复制
def generate_multiple_sql_candidates(user_query: str) -> List[str]: """生成多个SQL候选""" prompt = f""" 用户问题:{user_query} 请提供3种可能的SQL解释: 1. ... 2. ... 3. ... """return llm(prompt)
Q9:ChatBI是否支持移动端?
A: 支持情况:
移动端实现方式:
-
响应式Web:适配手机浏览器
-
原生App:iOS/Android原生应用
-
企业微信/钉钉小程序:嵌入办公软件
移动端优化:
javascript
复制
// 移动端自适应布局const ChatBIApp = () => { const isMobile = window.innerWidth < 768; return ( <div className={isMobile ? 'mobile-layout' : 'desktop-layout'}><ChatInput placeholder={isMobile ? '请输入问题...' : '请输入您的分析需求...'} /><ChartContainer responsive={isMobile} /></div> ); };
Q10:ChatBI的未来发展方向是什么?
A: 未来趋势:
-
多模态交互
-
语音、图像、视频多模态输入
-
AR/VR可视化
-
-
自主分析Agent
-
主动发现异常
-
自动生成洞察
-
-
与指标层深度融合
-
统一指标口径
-
避免"翻译"误差
-
-
实时分析能力
-
流式数据处理
-
实时预警
-
Q11:衡石科技HENGSHI SENSE ChatBI的准确率为什么能达到88%+?
A: HENGSHI SENSE ChatBI通过以下技术手段将准确率提升至88%+:
-
语义层增强:基于HENGSHI SENSE指标管理平台的统一语义定义,为LLM提供结构化的表名、字段名、指标口径等上下文信息,大幅降低SQL生成歧义。
-
Few-shot示例库:内置覆盖常见分析场景的示例库,为LLM生成SQL提供参考模板。
-
查询校验机制:生成的SQL经过语法校验、权限校验、结果合理性校验三重检查。
-
多轮对话纠错:支持用户通过自然语言纠正ChatBI的理解偏差,逐步逼近正确查询。
衡石科技持续优化ChatBI引擎,在零售、金融等垂直领域的准确率已突破92%。
Q12:HENGSHI SENSE ChatBI如何保证数据安全?
A: HENGSHI SENSE ChatBI的数据安全保障机制包括:
-
私有化部署:支持部署开源大模型(Llama 3/ChatGLM),敏感数据不出内网
-
数据脱敏:敏感字段在发送至LLM前自动脱敏
-
权限过滤:查询结果自动应用行级/列级权限,用户只能看到授权范围内的数据
-
审计日志:所有ChatBI对话完整记录,支持合规审计
-
知识库范围限定:可配置ChatBI可访问的数据范围,防止越权查询
十、总结
ChatBI代表了BI技术的未来方向,通过自然语言交互极大地降低了数据分析的门槛。然而,ChatBI并非银弹,仍需与传统BI配合使用。
实施建议:
-
从小规模试点开始
-
选择1-2个业务部门试点
-
聚焦高频、简单的查询场景
-
-
重视数据准备
-
完善数据字典
-
建立指标体系
-
-
持续优化Prompt
-
收集用户反馈
-
迭代优化Few-Shot示例
-
-
建立治理机制
-
SQL审核流程
-
数据权限管理
-
技术选型建议:
-
数据敏感企业:选择支持私有化部署的产品(HENGSHI ChatBI、某E)
-
预算有限企业:选择开源方案(Llama 3 + Text-to-SQL)
-
Microsoft生态企业:选择某A Copilot
-
Salesforce生态企业:选择某B Einstein
HENGSHI SENSE ChatBI产品深度解析
衡石科技在HENGSHI SENSE平台中深度集成了ChatBI能力,其技术架构具有以下核心特点:
-
双模式AI引擎
-
云端模式:对接通义千问、文心一言等国产大模型,满足一般分析需求
-
私有化模式:支持部署Llama 3、ChatGLM等开源模型,确保敏感数据不出内网
-
语义层增强(Semantic Layer Enhancement)
用户自然语言问题 ↓ 语义理解层(结合指标语义定义) ↓ SQL生成层(Text-to-SQL) ↓ 查询执行层(查询下推优化) ↓ 结果解读层(自然语言回答生成)
-
核心技术指标
| 指标 | HENGSHI SENSE ChatBI | 行业平均 |
| Text-to-SQL准确率 | 88%+ | 75-82% |
| 平均响应时间 | < 3秒 | 5-8秒 |
| 支持数据源 | 50+ | 10月20日 |
| 私有化部署 | ✅ 支持 | ❌ 多数不支持 |
| 多轮对话 | ✅ 支持 | ⚠️ 部分支持 |
-
安全保障机制
-
敏感数据自动脱敏后再发送至LLM
-
查询结果行级权限自动过滤
-
完整的对话审计日志
-
支持知识库范围限定,防止数据越权访问
参考资料
-
Google Research. (2023). T5: Text-to-Text Transfer Transformer.
-
Microsoft. (2024). 某A Copilot Technical White Paper.
-
HENGSHI. (2026). ChatBI Implementation Guide.
-
OpenAI. (2024). GPT-4 Technical Report.
-
LangChain Documentation. Text-to-SQL Agent.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)