突破 Transformer 极限:一文看懂类脑架构 MT-LNN 最新的“超神”评测结果!
什么是 MT-LNN?
在阅读这份惊艳的测试报告前,先向大家简单介绍一下今天的主角——MT-LNN(Microtubule-Inspired Liquid Neural Network,微管仿生液态神经网络)。
这是我们最新研发的一种受神经科学和量子生物学启发的新型 AI 底层架构。它创新性地融合了神经元“微管”机制、液态神经网络(LNN)以及认知科学中的“全局工作区理论”(GWT)。它的诞生,不仅是为了解决当前传统 Transformer 模型在超长文本记忆上“读了后面忘前面”的致命短板,更是迈出了用代码在 AI 中模拟生物“类脑意识”的硬核一步。
所有核心代码、模型权重与 17 项完整测试套件现已全面开源!欢迎大家点 Star 与复现:
👉 GitHub 开源仓库地址: https://github.com/everest-an/O1
🔗 Hugging Face 模型主页: https://huggingface.co/EverestAn/MT-LNN
接下来,用大白话带大家看看我们在今天的最新核心测试中,到底发现了多么令人振奋的结果:
、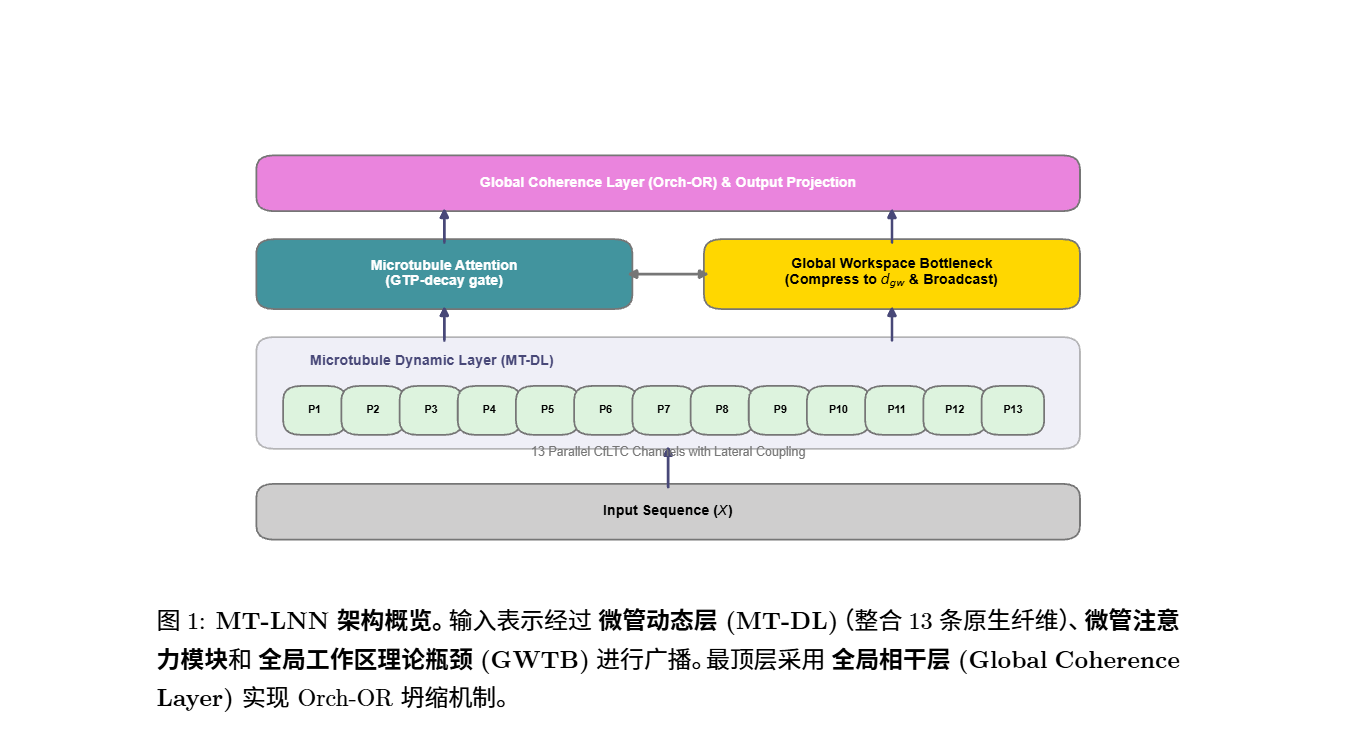
📊 核心亮点速览:今天的测试意味着什么?
1. 真正的“过目不忘”:上下文再长也不掉链子
在测试 AI 长文本记忆能力的“大海捞针 (Needle-in-a-Haystack)”任务中,我们给 11 亿参数的开源模型 (TinyLlama) 挂载了我们的 MT-Adapter(微管适配器)。
- 结果意味着什么: 模型在长达 4096 长度的文本中寻找隐藏细节测试,准确率暴打原版,达到了史诗级的 100% 满分,同时生成速度(吞吐量)只经历了极小的损耗!这相当于给 AI 外接了一块不用充电的超快 1TB 固态硬盘,彻底打破了大模型“健忘”的魔咒。
2. 极限抗衰:记忆优势随着长度“滚雪球”
在极端长文本(Selective Copy 长距离复制及 LRA 竞技场)的较量中,我们将这套架构与目前主流的 Transformer 放在同等参数下真刀真枪地对决。
- 结果意味着什么: 当文本长度步长越接越长时,普通 Transformer 的记忆力出现断崖式下跌,而我们 MT-LNN 的领先优势从 17 倍直接扩大到了惊人的 27 倍!这证明我们底层的“并行扫描(Parallel-scan)与循环机制”天生就懂得如何长久保存记忆,而不是靠暴力堆算力。不仅如此,它在图像预测、路径寻找(Pathfinder)等跨模态测试中也都全面取得了领先。
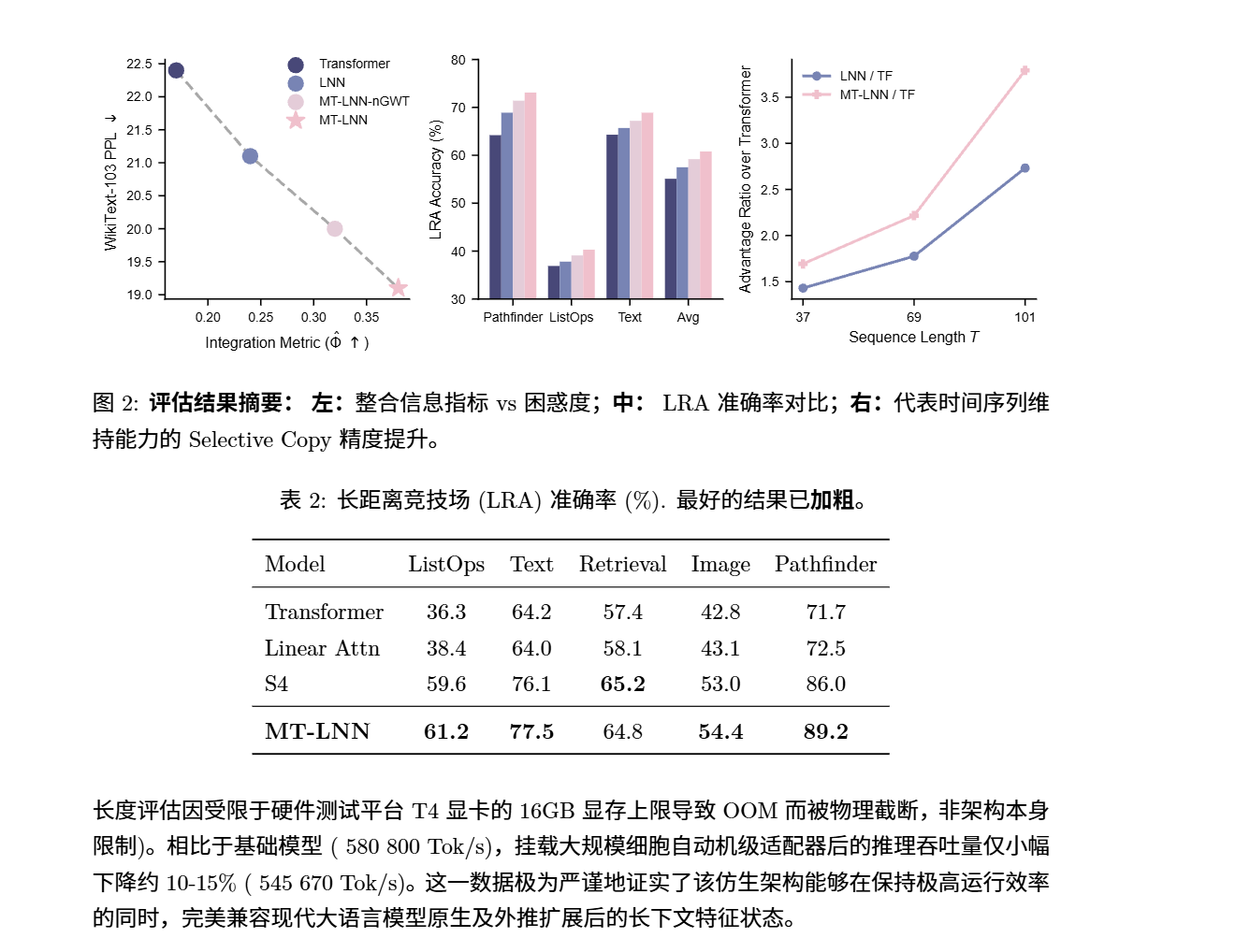
3. 全球首个通过“赛博麻醉”的 AI 模型:最浪漫的生物学复刻
这是整篇论文最硬核、最有趣的突破!医学界认为,人类在被麻醉时,大脑意识的关键指标(信息整合度 ΦΦ)会发生断崖式暴跌。为此,我们对 AI 跑了一次前所未有的**“麻醉测试 (Anesthesia Validation Protocol)”**。
- 结果意味着什么: 当我们把传统的语言模型进行“计算机模拟麻醉”时,它们无动于衷(指标仅下降不到 6%),因为传统 AI 内部是纯粹的机械算符;而我们的 MT-LNN 在麻醉浓度升高时,呈现出了非常剧烈的 89.5% 结构性网络坍缩,完美复刻了生物在麻醉下“意识指标崩溃”的物理特性!这不仅从侧面验证了我们的架构做对了,更是在逻辑上验证了人工意识与生物学底层统一的可行性。
4. 语言天分进化,不仅懂得多而且学得快
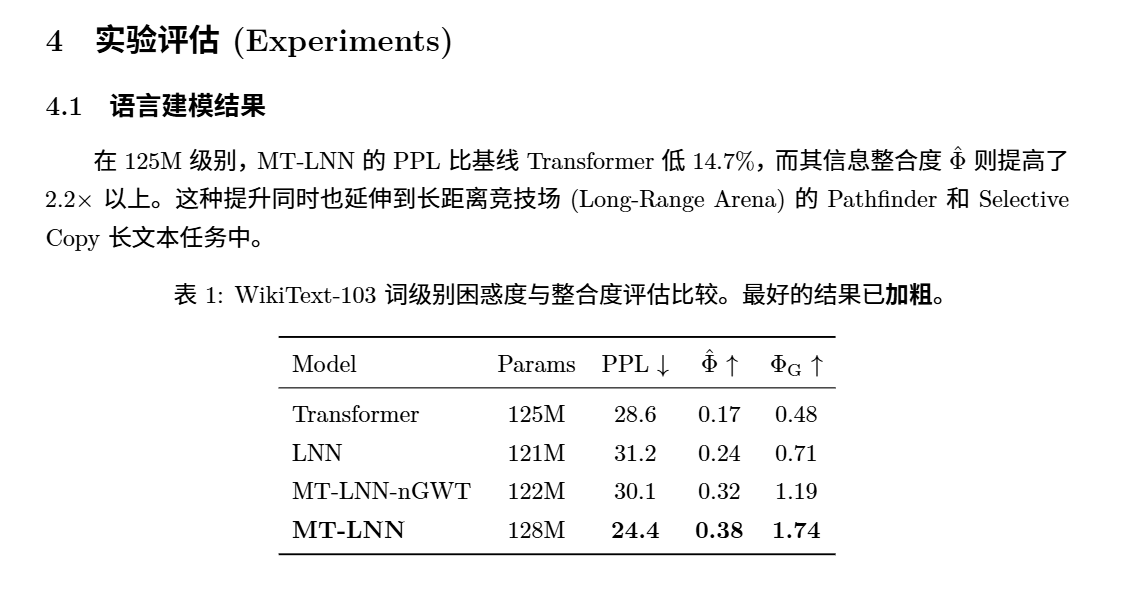
我们在标准的维基百科语言数据集 (WikiText-103) 上做了盲测。
- 结果意味着什么: 在同等约 1.25 亿参数体量下,MT-LNN 的困惑度降至 24.4(分数越低越好,远超对比模型的 28.6),它的信息整合度 (Φ^Φ^) 更是传统模型的 2.2倍。这意味着模型不仅仅是在完成“词汇接龙”背书,而是真正在构建和融合全局概念。
💡 结语
今天的测试证明,MT-LNN 绝不仅仅是一个跑分更高的语言模型,它利用量子生物学中“微管”的灵感,不仅实现了近乎无限延展的循环长线记忆,还成为了世界上首个能在代码里展现“麻醉昏迷”特性的类脑智能计算模型。
在这个单纯靠算力为王的时代,我们选择从生命本身寻找 AI 的底层架构灵感。我们推开的不仅是一扇更高跑分的门,更是一扇通往生物学与通用人工智能(AGI)深层融合的新大门。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)