用 Dify 工作流把新闻自动变成分析报告、HTML 页面和思维导图
从 0 到 1 搭建一个“智能资讯雷达”:用 Dify 工作流把新闻自动变成分析报告、HTML 页面和思维导图
公众号:码海寻道
适合读者:刚接触 Dify、AI 工作流、前后端接口调用的小白开发者
项目关键词:Dify、Workflow、YAML、Python、前后端、智能资讯分析、Markdown、HTML、思维导图

一、为什么要做一个“智能资讯雷达”?
我们每天都会看到大量信息:新闻、政策、公告、会议纪要、行业研报、舆情动态……
问题是,信息太多之后,人很容易陷入三个困境:
- 看不过来:每天几十条甚至上百条资讯,人工筛选非常耗时。
- 抓不住重点:一篇政策到底重要在哪里?和我有什么关系?风险和机会是什么?
- 难以沉淀:今天看过的内容,明天想整理成日报、周报或分析材料,又要重新加工。
所以我做了一个 Dify 工作流,名字叫:智能资讯雷达。
它的目标非常明确:
输入一篇新闻、政策、公告或会议纪要,自动输出结构化要情卡片、Markdown 分析报告、HTML 展示页、思维导图 JSON 和完整结构化 JSON。
简单来说,它不是只让大模型“总结一下”,而是让大模型按照固定流程,把一篇资讯加工成可以直接阅读、展示和二次开发的数据资产。
二、最终效果是什么?
这个项目最终包含两部分:
- Dify 工作流
- 本地前后端调用页面
工作流负责分析内容,本地页面负责调用工作流并展示结果。
1. 输入内容
用户可以输入:
- 正文
content - 来源
source - 关注主题
focus_topics - 目标读者
target_audience - 输出风格
output_style
例如输入一段关于“虚拟电厂参与电力市场交易”的政策新闻。
2. 输出内容
工作流会输出:
final_markdown:Markdown 分析报告html_result:可直接展示的 HTML 页面mindmap_json:可用于渲染思维导图的 JSONfinal_json:完整结构化结果
前端页面会把这些内容分别展示在不同标签页中:
- 报告 Markdown
- HTML 预览
- 思维导图
- 完整 JSON
这就让一个工作流既能服务阅读,也能服务展示,还能服务后续系统集成。
三、小白先理解:Dify 工作流到底是什么?
很多刚接触 Dify 的朋友,会把 Dify 简单理解为“套壳大模型聊天”。
其实 Dify 更有价值的地方是:它可以把大模型能力编排成一个稳定流程。
你可以把 Dify Workflow 理解成一条自动化流水线:
输入内容
-> 大模型分析
-> 代码节点清洗和格式转换
-> 再次调用大模型生成脑图
-> 代码节点整合最终结果
-> 输出给用户
也就是说,工作流不只是一个 Prompt,而是多个节点协同完成任务。
每个节点负责一件事情:
- 开始节点:接收用户输入
- LLM 节点:调用大模型分析文本
- Code 节点:用 Python 处理 JSON、Markdown、HTML
- 结束节点:把最终结果返回出去
这样做的好处是:
- 稳定:每一步职责清晰,出问题容易定位。
- 可扩展:后面可以加数据库、知识库、HTTP 请求、条件判断。
- 可复用:同一个工作流可以被网页、脚本、自动化任务调用。
四、智能资讯雷达的工作流设计
这个工作流的整体结构如下:
Start 开始节点
-> LLM 资讯雷达结构化分析
-> Code JSON 清洗与多格式生成
-> LLM 思维导图 JSON 生成
-> Code 最终结果整合
-> End 输出节点
下面逐个解释。
五、开始节点:定义用户输入
开始节点负责接收用户输入。
我设计了 5 个输入变量:
| 变量名 | 含义 | 示例 |
|---|---|---|
content |
要分析的正文 | 新闻、政策、公告、会议纪要 |
source |
信息来源 | 某省能源主管部门通知 |
focus_topics |
关注主题 | 电力市场、虚拟电厂、储能 |
target_audience |
目标读者 | 管理层和研究人员 |
output_style |
输出风格 | brief / professional / report |
为什么要设计这些变量?
因为同一篇内容,给不同人看,分析重点不一样。
例如:
- 给管理层看,要突出影响和建议动作。
- 给研究人员看,要突出政策背景和逻辑链条。
- 给运营团队看,要突出机会和落地动作。
所以工作流一开始就应该让用户告诉系统:你是谁,你关心什么,你想要什么风格。
六、第一个 LLM 节点:结构化资讯分析
第一个大模型节点的核心任务是:
把原始资讯转成结构化 JSON。
它不是简单总结,而是要求模型输出固定字段,例如:
- 标题
- 一句话摘要
- 分类
- 重要性
- 相关性评分
- 关键要点
- 风险
- 机会
- 建议动作
这一步非常关键。
如果直接让大模型输出一段自然语言,后续就很难做 HTML、脑图和系统集成。
但如果让它输出 JSON,后面的代码节点就可以稳定读取字段,再生成不同格式。
这就是 AI 工作流里一个非常重要的思想:
先结构化,再展示化。
七、Code 节点:为什么还要写 Python?
很多小白会问:既然大模型这么强,为什么还需要 Code 节点?
原因很简单:
大模型擅长理解和生成,代码擅长稳定处理格式。
例如,大模型返回的 JSON 有时可能带有 Markdown 代码块:
```json
{"title": "某某政策发布"}
也可能前后带解释文字。
这时候 Code 节点就负责做几件事:
1. 清洗 LLM 输出
2. 尝试解析 JSON
3. 容错处理缺失字段
4. 生成 Markdown 报告
5. 生成 HTML 页面
6. 输出结构化中间结果
这一步让整个工作流从“看起来能跑”变成“更稳定可用”。
---
## 八、第二个 LLM 节点:生成思维导图 JSON
为什么思维导图要单独用一个 LLM 节点?
因为思维导图和分析报告的表达方式不同。
分析报告偏线性阅读:
```text
背景 -> 要点 -> 风险 -> 机会 -> 建议
思维导图偏结构化展开:
{
"name": "中心主题",
"children": [
{
"name": "核心摘要",
"children": []
},
{
"name": "风险",
"children": []
}
]
}
所以我单独设计了一个 LLM 节点,让它基于前面已经清洗好的结构化数据,生成 name/children 形式的脑图 JSON。
这样前端就可以直接渲染。
九、最终整合节点:把所有结果统一输出
最后一个 Code 节点负责整合结果。
它会把前面产生的内容统一包装成最终输出:
final_markdown
html_result
mindmap_json
final_json
其中:
final_markdown适合复制到文档、日报、周报。html_result适合在网页里直接展示。mindmap_json适合做可视化脑图。final_json适合给其他系统继续处理。
到这里,一个完整的 Dify 工作流就形成了。
十、工作流 YAML:为什么要导出成文件?
Dify 支持把应用导出为 YAML 文件。
这个 YAML 文件可以理解为工作流的“源代码”。
我们这次生成的文件是:
要情智能体/工作流草稿/智能资讯雷达.yml
它的好处是:
- 可以备份。
- 可以分享给别人导入。
- 可以版本管理。
- 可以在不同 Dify 环境迁移。
对于学习 Dify 的朋友,我非常建议养成一个习惯:
重要工作流不要只停留在网页编辑器里,一定要导出 YAML 文件保存。
十一、本地前后端项目:为什么还要自己写页面?
Dify 自带调试页面,为什么我们还要写一个前端页面?
原因有三个。
1. 更接近真实业务系统
真实业务里,用户通常不会直接进入 Dify 后台,而是通过自己的系统调用 Dify API。
所以我们需要一个前端页面模拟真实业务场景。
2. 可以更好地展示结果
Dify 返回的是接口数据。
但我们的工作流有多种输出:
- Markdown
- HTML
- JSON
- 思维导图
自己写页面后,就可以针对不同输出做不同展示。
3. 方便理解前后端调用流程
这个项目非常适合小白理解:
浏览器页面
-> 请求本地 Python 后端
-> Python 后端请求 Dify API
-> Dify 执行工作流
-> Python 后端返回结果
-> 浏览器渲染结果
这就是一个非常典型的前后端调用链路。
十二、本地项目结构
前后端项目目录如下:
技术理解材料/intelligence-radar-ui/
├─ server.py
├─ .env.local.example
├─ README.md
└─ templates/
└─ index.html
它非常轻量,没有使用 Flask,也没有使用 FastAPI,而是直接使用 Python 标准库里的 http.server。
这样做的好处是:
- 不需要安装额外依赖
- 在 Anaconda 环境里直接运行
- 适合教学和快速验证
十三、后端 server.py 做了什么?
后端主要做四件事。
1. 读取本地环境变量
项目支持 .env.local 文件。
里面配置 Dify 地址和 API Key:
DIFY_BASE_URL=https://api.dify.ai
DIFY_APP_KEY=app-xxxxxxxxxxxxxxxxxxxx
DIFY_DEFAULT_USER=radar-local-user
DIFY_TIMEOUT_SECONDS=600
DIFY_DISABLE_SYSTEM_PROXY=true
UI_HOST=127.0.0.1
UI_PORT=7865
注意:
API Key 不应该写在前端 HTML 里,而应该放在后端环境变量中。
这是一个很重要的安全意识。
如果把 API Key 写到前端,任何打开浏览器开发者工具的人都能看到。
2. 提供页面访问
当浏览器访问:
http://127.0.0.1:7865
后端会返回:
templates/index.html
也就是我们的前端页面。
3. 提供健康检查接口
前端页面会请求:
/api/health
用来判断:
- Dify 地址是什么
- 是否配置了 API Key
- 当前调用 endpoint 是什么
所以页面右上角可以显示服务配置状态。
4. 代理调用 Dify 工作流
当前端点击“运行智能资讯雷达”时,会请求本地后端:
/api/run-workflow
后端再去请求 Dify:
/v1/workflows/run
请求体大致长这样:
{
"inputs": {
"content": "资讯正文",
"source": "信息来源",
"focus_topics": "关注主题",
"target_audience": "目标读者",
"output_style": "professional"
},
"response_mode": "streaming",
"user": "radar-local-user",
"files": []
}
这里要注意,inputs 里的字段必须和 Dify 工作流开始节点里的变量名一致。
如果 Dify 里叫 content,代码里也必须叫 content。
十四、前端页面 index.html 做了什么?
前端页面主要负责三件事:
- 收集用户输入
- 调用本地后端接口
- 展示返回结果
1. 收集输入
页面上有几个输入框:
- 正文
- 来源
- 关注主题
- 目标读者
- 输出风格
- 响应模式
- user 标识
这些字段会被整理成 JSON,然后通过 fetch 发给后端。
2. 调用接口
核心逻辑是:
const resp = await fetch('/api/run-workflow', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(payload),
});
这就是浏览器调用后端接口的基本写法。
3. 展示结果
返回结果后,页面会分别展示:
final_markdownhtml_resultmindmap_json- 完整 JSON
其中 html_result 会直接渲染到 HTML 预览区。
mindmap_json 会被转换成树状结构显示。
十五、为什么使用 streaming 模式?
Dify Workflow API 一般支持两种响应模式:
blockingstreaming
小白可以这样理解:
blocking
等工作流全部执行完,再一次性返回结果。
优点是简单。
缺点是如果工作流执行时间比较长,可能超时。
streaming
服务端边执行边返回事件流。
优点是更适合长流程。
我们的工作流包含多个 LLM 节点和 Code 节点,所以推荐使用:
streaming
本地后端已经做了 SSE 事件解析,会从最终事件中提取 outputs。
十六、如何在 Anaconda 环境中运行?
用户当前使用的是 Anaconda 创建的 dify_test 虚拟环境。
运行方式如下。
进入项目目录:
cd D:\md_test\dify_学习\技术理解材料\intelligence-radar-ui
复制配置文件:
Copy-Item .\.env.local.example .\.env.local
编辑 .env.local,填入你的 Dify App Key:
DIFY_BASE_URL=https://api.dify.ai
DIFY_APP_KEY=app-你的应用Key
激活环境并启动服务:
conda activate dify_test
python .\server.py
浏览器打开:
http://127.0.0.1:7865
如果能看到智能资讯雷达页面,就说明本地前后端启动成功。
效果如下: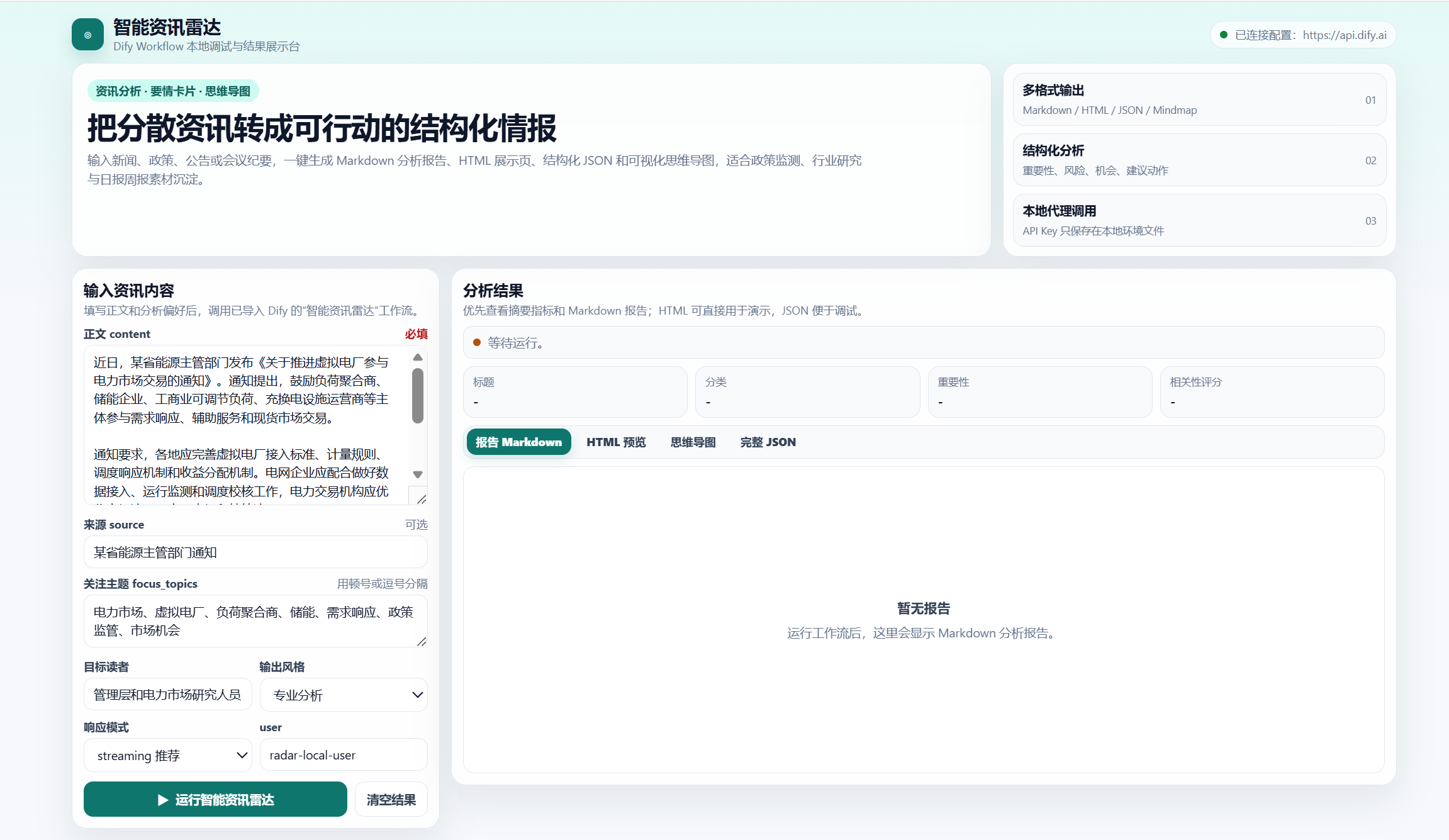
十七、一次完整调用的流程
我们用一个真实例子串起来。
用户在前端输入:
近日,某省能源主管部门发布《关于推进虚拟电厂参与电力市场交易的通知》。通知提出,鼓励负荷聚合商、储能企业、工商业可调节负荷、充换电设施运营商等主体参与需求响应、辅助服务和现货市场交易。
点击运行后,流程是:
1. 浏览器收集表单数据
2. 浏览器请求 /api/run-workflow
3. Python 后端读取请求体
4. Python 后端拼接 Dify Workflow API 请求
5. Dify 执行智能资讯雷达工作流
6. Dify 返回 outputs
7. Python 后端把结果返回给浏览器
8. 浏览器分别渲染 Markdown、HTML、脑图和 JSON
最终页面会展示一个结构化分析结果。
分析结果-HTML效果: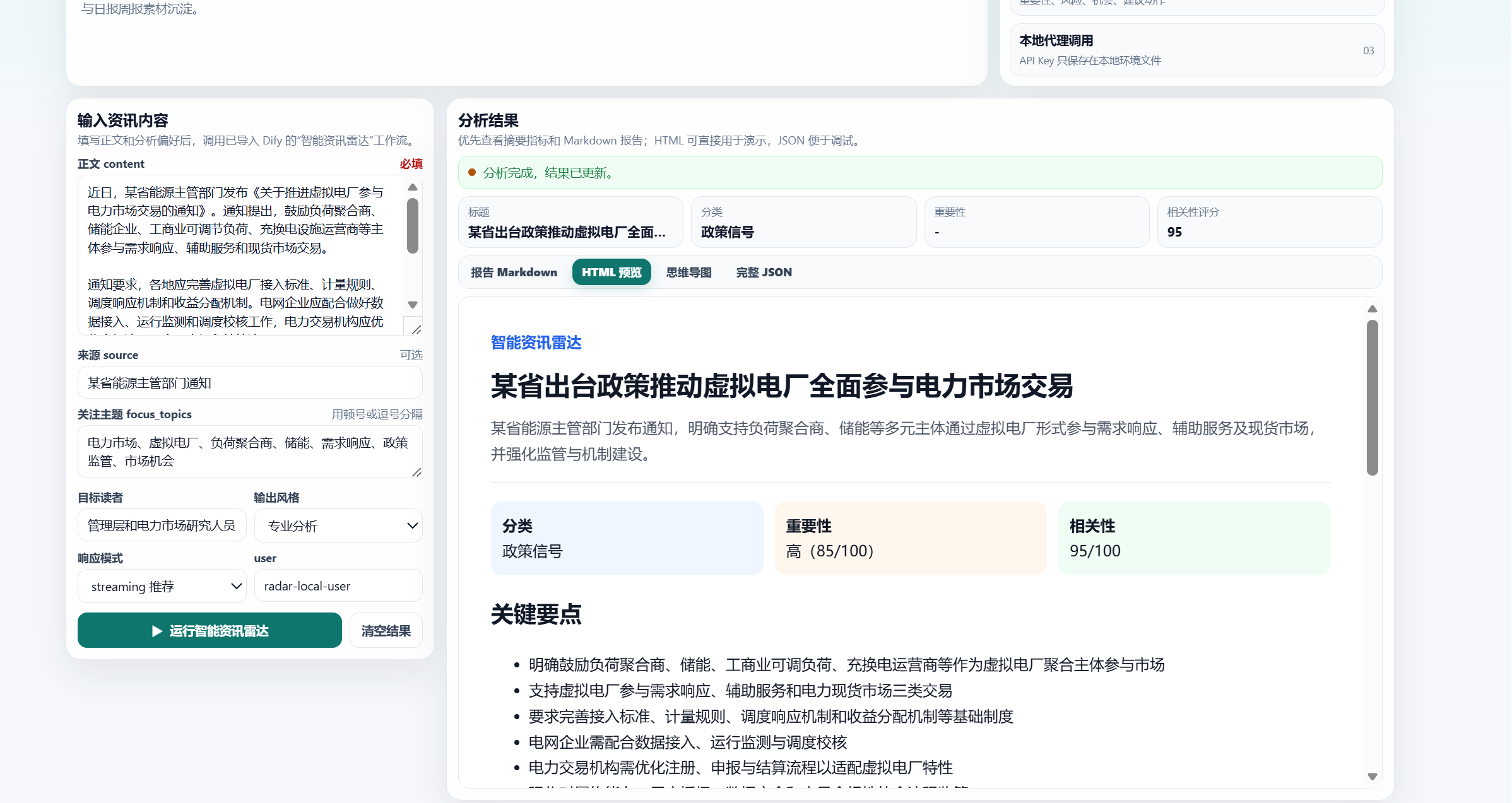
脑图效果: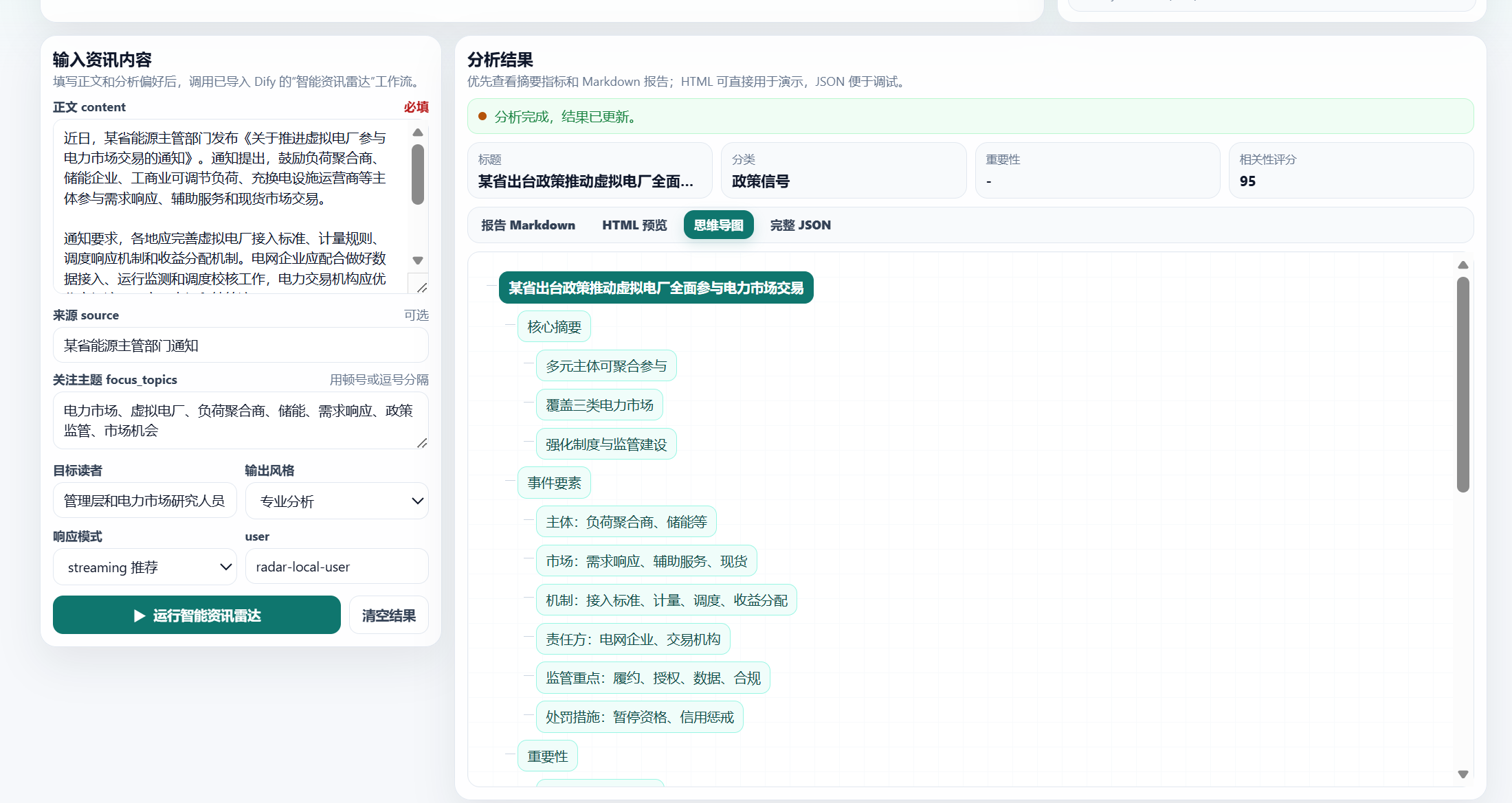
这就是一个完整的 AI 应用调用链路。
十八、几个小白常见坑
1. DIFY_APP_KEY 没配置
如果页面提示:
Missing DIFY_APP_KEY
说明 .env.local 里没有配置:
DIFY_APP_KEY=app-xxxxxxxxxxxxxxxxxxxx
注意要使用 Dify 应用的 API Key,不是模型供应商的 Key。
2. DIFY_BASE_URL 配错
如果你用 Dify Cloud,通常是:
DIFY_BASE_URL=https://api.dify.ai
如果你用本地 Docker 版 Dify,可能是:
DIFY_BASE_URL=http://127.0.0.1
具体取决于你的 Dify 服务端口和 Nginx 配置。
3. 工作流变量名不一致
前端和后端传入的是:
content
source
focus_topics
target_audience
output_style
Dify 工作流开始节点也必须有这些变量。
如果变量名不一致,工作流可能拿不到输入。
4. 返回结果为空
如果页面没有展示 Markdown 或 HTML,先看“完整 JSON”标签页。
重点检查:
response.outputs
里面是否包含:
final_markdown
html_result
mindmap_json
final_json
5. 请求超时
如果文本很长,或者模型响应慢,可能超时。
可以在 .env.local 中调大:
DIFY_TIMEOUT_SECONDS=900
也建议使用:
response_mode=streaming
十九、这个项目还能怎么扩展?
目前这个项目已经能完成从资讯输入到多格式输出。
后续还可以继续扩展。
1. 增加文件上传
支持上传 PDF、Word、网页正文,然后先做文档提取,再进入资讯雷达分析。
2. 增加历史记录
把每次分析结果保存到本地数据库,例如 SQLite。
这样就能做一个资讯分析库。
3. 增加日报周报生成
把多条资讯的 final_json 汇总,再交给另一个工作流生成日报或周报。
4. 增加关键词监测
结合定时任务,每天抓取指定来源内容,自动判断是否命中关注主题。
5. 增加正式前端框架
当前页面是原生 HTML + CSS + JavaScript。
如果要做成更完整的产品,可以使用:
- React
- Vue
- Next.js
- Tailwind CSS
但对小白学习来说,当前版本更容易理解前后端本质。
二十、从这个项目可以学到什么?
这个项目看起来是一个“资讯分析工具”,但它背后其实包含很多 AI 应用开发的基础知识。
你可以学到:
- 如何设计 Dify 工作流
- 如何让 LLM 输出结构化 JSON
- 如何用 Code 节点清洗和转换数据
- 如何导出和管理 Dify YAML
- 如何通过 API 调用 Dify Workflow
- 如何用 Python 写一个轻量后端代理
- 如何用前端页面展示多格式 AI 输出
- 如何处理 API Key、超时、streaming 响应等工程问题
这比单纯写一个 Prompt 更接近真实 AI 应用开发。
二十一、总结
“智能资讯雷达”这个项目的核心思路可以概括成一句话:
用 Dify 编排大模型分析流程,用 Python 后端安全调用 API,用前端页面把结果变成可读、可展示、可复用的情报产品。
对于刚入门 AI 应用开发的朋友,我建议不要一开始就追求复杂架构。
可以先从这样的轻量项目开始:
一个稳定的工作流
一个清晰的 API 调用
一个能展示结果的页面
把这三件事跑通,你就已经迈过了从“会用大模型”到“会做 AI 应用”的第一道门槛。
如果你正在学习 Dify、AI 工作流和前后端开发,希望这篇文章能给你一个可复现的参考。
附录:项目文件清单
Dify 工作流 YAML
D:\md_test\dify_学习\要情智能体\工作流草稿\智能资讯雷达.yml
工作流设计文档
D:\md_test\dify_学习\技术理解材料\智能资讯雷达工作流设计_可直接搭建.md
本地前后端项目
D:\md_test\dify_学习\技术理解材料\intelligence-radar-ui
核心文件:
server.py
.env.local.example
README.md
templates/index.html
附录:推荐测试文本
近日,某省能源主管部门发布《关于推进虚拟电厂参与电力市场交易的通知》。通知提出,鼓励负荷聚合商、储能企业、工商业可调节负荷、充换电设施运营商等主体参与需求响应、辅助服务和现货市场交易。
通知要求,各地应完善虚拟电厂接入标准、计量规则、调度响应机制和收益分配机制。电网企业应配合做好数据接入、运行监测和调度校核工作,电力交易机构应优化市场注册、交易申报和结算流程。
通知还强调,要加强对市场主体履约能力、用户授权、数据安全和交易合规性的监管。对于存在虚假响应、数据造假、扰乱市场秩序等行为的主体,将依法依规采取暂停交易资格、信用惩戒等措施。
推荐参数:
source: 某省能源主管部门通知
focus_topics: 电力市场、虚拟电厂、负荷聚合商、储能、需求响应、政策监管、市场机会
target_audience: 管理层和电力市场研究人员
output_style: professional
response_mode: streaming

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)