在本地跑一个完整 AI Agent 系统:Ollama、MCP 和 Skill 到底怎么串起来
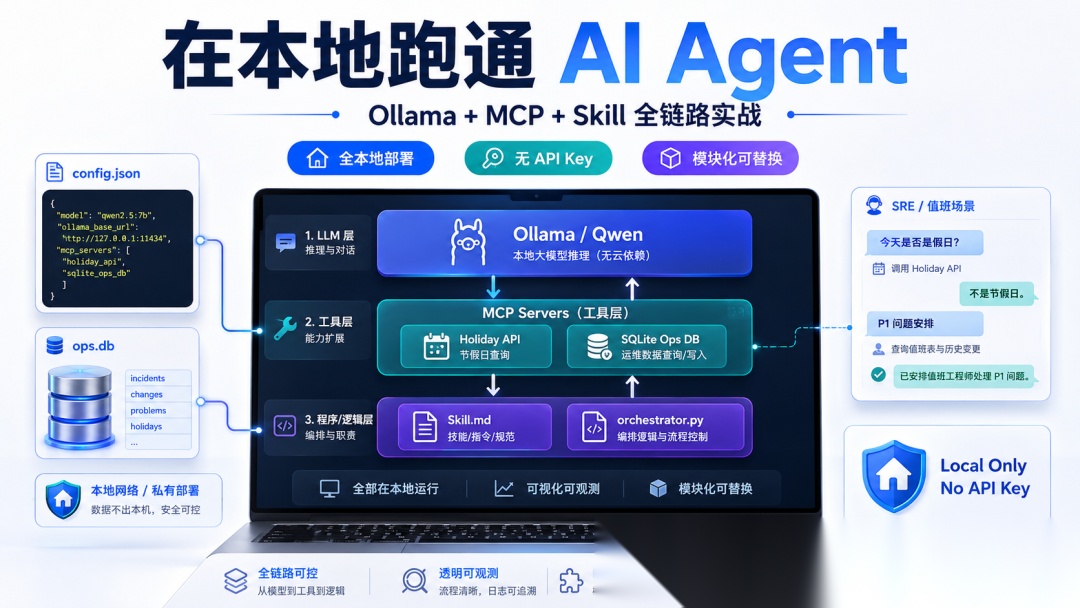
最近在折腾本地 Agent 栈,想搞清楚一件事:到底能不能不依赖任何云端 API,在自己笔记本上把一套完整的 Agent 系统跑起来?答案是可以的,而且比想象中干净很多。
这篇文章就来讲怎么做——用 Ollama 跑 LLM、用 MCP Server 做工具库、用一个 Markdown 文件写"程序逻辑",再用一个小 Python 编排器和一个 JSON 配置文件把所有东西串起来。没有 API Key,没有付费服务,全本地。
“
传统编程和 LLM Agent 系统之间存在一套对应关系——Skill 是程序,MCP 是库,LLM 是语言。这篇就是把那个抽象类比落到真实代码里,每一层都跑得通、看得见、换得掉。
 传统编程与 LLM Agent 系统的类比关系
传统编程与 LLM Agent 系统的类比关系
为了让这套系统有点实际意义,选了一个真实的 SRE 场景来跑通: “现在值班的工程师在 X 国,今天那里有没有公共假日?如果有,他们名下有哪些 P1 问题需要安排人顶班?” 回答这个问题需要联动两个数据源——本地 SQLite 数据库(存放值班轮次和问题列表)和一个免费的公共假日 API(date.nager.at)。两个数据源都包装成 MCP Server,由本地 Qwen 3.5 9B 模型按照 Markdown Skill 协调执行。整个过程用的是 16GB 内存的普通机器,没有任何特殊硬件要求。
“
参考内容:https://medium.com/generative-ai/run-your-own-ai-agent-locally-ollama-mcp-and-skills-explained-a913fe46e938
需要准备什么

依赖真的很少——没有 API Key 要申请,没有账号要注册。运行时唯一会碰外网的地方就是 date.nager.at 这个公共假日 API,免费且无需鉴权,其他全在本地。
项目结构
整个项目就这几个文件,结构很清楚:
agentic-stack/├── config.json├── requirements.txt├── seed_db.py├── server_test.py├── ops.db (自动生成)├── mcp_servers/│ ├── holidays_server.py (API 包装型 MCP)│ └── ops_server.py (纯本地型 MCP)├── skills/│ └── oncall_holiday_check.md└── orchestrator.py
Python 依赖也极简,requirements.txt 就三行:
mcp[cli]>=1.10ollama>=0.4httpx>=0.27
建个 virtualenv,pip install -r requirements.txt 装好,就可以开干了。
配置文件:一个 JSON 管所有
路径、模型名、问题、MCP Server 的环境变量,全塞进 config.json,代码里不硬写任何东西:
{ "python": "python3","model": "qwen3.5:9b","ollama_host": "http://localhost:11434","max_steps": 10,"skill_path": "skills/oncall_holiday_check.md","default_question": "当前值班工程师所在国家今天是否有公共假日?如果有,列出他们名下的 P1 问题。","mcp_servers": { "holidays": { "script": "mcp_servers/holidays_server.py", "env": { "HOLIDAY_API_BASE": "https://date.nager.at/api/v3" } }, "ops": { "script": "mcp_servers/ops_server.py", "env": { "OPS_DB": "{root}/ops.db" } } }}
各字段意思很直白:python 是启动 MCP 子进程的解释器,没填绝对路径会自动回退到当前 venv 的 sys.executable;model 就是 Ollama 跑的模型名,改一个字就能换模型;max_steps 限制工具调用最大轮次,10 轮对这个 Skill 完全够用;skill_path 指向 Skill 文件,换个路径就是换个任务;default_question 是不传命令行参数时的默认问题;mcp_servers 下每个条目包含 script(MCP 脚本路径)和 env(启动时注入的环境变量),{root} 会自动展开成项目根目录的绝对路径。
想换一套完全不同的任务?改 skill_path、换掉 mcp_servers 里的条目就行,一行 Python 都不用动。
搭好 LLM 运行时
先把 Ollama 装好,然后依次跑这几条命令:
# 验证安装ollama --version# 后台启动 daemonollama serve &# 拉取模型ollama pull qwen3.5:9b# 快速冒烟测试ollama run qwen3.5:9b "用一句话打个招呼"
Qwen 3.5 9B 量化版大约 6.6 GB,支持 256K 上下文,带工具调用训练,够用。内存不宽裕的话,config.json 里换成 qwen3.5:4b 就行;想用 Llama 系的,llama3.1:8b 也完全没问题,后面的代码对模型没有任何绑定。
最后那条冒烟测试跑出来有回应,说明运行时 OK。从这里开始就不再直接 ollama run 了,编排器会通过 HTTP API 和 daemon 通信。
MCP Server 一:外部 API 包装型(假日查询)
第一个 MCP Server 是对外部 API 的封装,自己不做任何计算,只是把工具调用翻译成 HTTP 请求、把响应翻译回来。类比一下就是 Python 里 requests 包装 urllib 的关系——MCP 对外暴露一个干净的语义接口,实际网络请求在内部发生,模型根本感知不到。
mcp_servers/holidays_server.py :
import osfrom datetime import date as date_clsfrom typing import Anyimport httpxfrom mcp.server.fastmcp import FastMCPmcp = FastMCP("holidays")API_BASE = os.environ.get("HOLIDAY_API_BASE", "https://date.nager.at/api/v3")USER_AGENT = "agentic-stack-demo/1.0"@mcp.tool()asyncdef is_public_holiday(country_code: str, on_date: str) -> dict[str, Any]: """查询某个日期在指定国家是否为公共假日。 参数: country_code: ISO 3166-1 二位字母国家代码,例如 'US'、'IT'、'JP'。 on_date: 日期字符串,格式为 YYYY-MM-DD。 返回: 包含 'is_holiday'(布尔值)的字典;若为假日,还会包含 'holiday_name' 和 'holiday_local_name'。出错时返回含 'error' 键的字典。 """ try: target = date_cls.fromisoformat(on_date) except ValueError: return {"error": "on_date 格式须为 YYYY-MM-DD"} if len(country_code) != 2: return {"error": "country_code 须为两位 ISO 国家代码"} url = f"{API_BASE}/PublicHolidays/{target.year}/{country_code.upper()}" headers = {"User-Agent": USER_AGENT, "Accept": "application/json"} try: asyncwith httpx.AsyncClient(timeout=10.0) as client: resp = await client.get(url, headers=headers) if resp.status_code == 404: return {"error": f"未知国家代码 {country_code!r}"} resp.raise_for_status() holidays = resp.json() except httpx.HTTPError as e: return {"error": f"假日 API 请求失败:{e}"} iso = target.isoformat() for h in holidays: if h.get("date") == iso: return { "is_holiday": True, "holiday_name": h.get("name"), "holiday_local_name": h.get("localName"), } return {"is_holiday": False}@mcp.tool()asyncdef list_country_holidays(country_code: str, year: int) -> list[dict[str, Any]]: """列出指定国家某年的所有公共假日。 参数: country_code: ISO 3166-1 二位字母国家代码。 year: 四位年份,例如 2026。 返回: 包含 'date'、'name'、'local_name' 的字典列表。出错时返回单元素列表, 其中含 'error' 键。 """ if len(country_code) != 2: return [{"error": "country_code 须为两位 ISO 国家代码"}] url = f"{API_BASE}/PublicHolidays/{year}/{country_code.upper()}" headers = {"User-Agent": USER_AGENT, "Accept": "application/json"} try: asyncwith httpx.AsyncClient(timeout=10.0) as client: resp = await client.get(url, headers=headers) if resp.status_code == 404: return [{"error": f"未知国家代码 {country_code!r}"}] resp.raise_for_status() data = resp.json() except httpx.HTTPError as e: return [{"error": f"假日 API 请求失败:{e}"}] return [ {"date": h["date"], "name": h["name"], "local_name": h.get("localName")} for h in data ]if __name__ == "__main__": mcp.run(transport="stdio")
这段代码有几个地方值得单独说一下。
@mcp.tool() 装饰器把函数变成一个 MCP 工具。模型永远看不到函数体,能看到的只有函数名、docstring 和类型注解——这三样就是"语义契约"。docstring 写得含糊,模型就容易用错工具;类型注解会自动转成 JSON Schema 来约束模型的参数生成。另外,API 错误不抛异常,而是返回带 error key 的结构化结果,这样模型能推理出出了什么问题,然后自己决定下一步怎么处理。
还有一个大坑,这里特别标注一下:stdio MCP Server 里绝对不能 print() 到 stdout。stdout 是协议通道,一旦往里写东西,客户端就会因为 JSON-RPC 解析失败挂掉,还不知道哪里出了问题。调试信息统一走 print(..., file=sys.stderr) 或者 logging。
先测试,再接 LLM
接 LLM 之前,先单独验证一下 MCP Server 本身有没有问题,写个小测试脚本:
server_test.py :
import asyncioimport sysfrom pathlib import Pathfrom mcp import ClientSession, StdioServerParametersfrom mcp.client.stdio import stdio_clientROOT = Path(__file__).resolve().parentasyncdef main(server_script: Path, tool_name: str, arguments: dict) -> None: params = StdioServerParameters( command=sys.executable, args=[str(server_script)], ) asyncwith stdio_client(params) as (read, write): asyncwith ClientSession(read, write) as session: await session.initialize() listed = await session.list_tools() print("服务器暴露的工具列表:") for t in listed.tools: first_line = (t.description or"").splitlines()[0] print(f" - {t.name}: {first_line}") print(f"\n正在调用 {tool_name}({arguments}):") result = await session.call_tool(tool_name, arguments=arguments) for chunk in result.content: if hasattr(chunk, "text"): print(chunk.text)if __name__ == "__main__": asyncio.run(main( server_script=ROOT / "mcp_servers" / "holidays_server.py", tool_name="is_public_holiday", arguments={"country_code": "IT", "on_date": "2026-04-25"}, ))
python server_test.py 跑一下,能看到工具列表和调用结果就说明 Server 没问题。这个脚本顺便也是一份最小化 MCP 客户端的参考实现,以后写新 Server 时直接拿来改就行。
MCP Server 二:纯本地型(运维数据库)
第二个 MCP Server 不访问任何外部服务,直接拥有并查询本地 SQLite 数据库——对应类比里的"纯库",所有逻辑在本地跑,零第三方依赖。
先造数据
Server 跑起来之前得先有数据库,写个种子脚本生成一份合成数据集:
import jsonimport randomimport sqlite3from datetime import datetime, timedelta, timezonefrom pathlib import PathROOT = Path(__file__).resolve().parentCONFIG = json.loads((ROOT / "config.json").read_text())DB_PATH = ROOT / CONFIG["mcp_servers"]["ops"]["env"]["OPS_DB"].replace("{root}/", "")ENGINEERS = [ # (姓名, github账号, 邮箱, 国家代码, 时区) ("Sara Chen", "schen", "sara@example.com", "US", "America/Los_Angeles"), ("Marco Rossi", "marco-r", "marco@example.com", "IT", "Europe/Rome"), ("Priya Patel", "priya-p", "priya@example.com", "IN", "Asia/Kolkata"), ("Felix Mueller", "fmueller", "felix@example.com", "DE", "Europe/Berlin"), ("Yuki Tanaka", "ytanaka", "yuki@example.com", "JP", "Asia/Tokyo"),]ISSUE_TITLES = [ ("API gateway returns 502 under load", "P1"), ("Memory leak in ingestion worker", "P1"), ("Database failover does not promote replica", "P0"), ("Auth token refresh fails for SSO users", "P1"), ("Disk usage alert on log-archive node", "P2"), ("Stale data shown on dashboard for 5+ min", "P1"), ("Slow query on customer search endpoint", "P2"), ("Webhook delivery retries not exponential", "P2"), ("CSV export truncates rows over 10k", "P1"), ("OAuth callback rejects valid state token", "P1"), ("Background job stuck in 'running' state", "P2"), ("Rate limiter counts cached responses", "P3"),]def seed() -> None: if DB_PATH.exists(): DB_PATH.unlink() random.seed(42) with sqlite3.connect(DB_PATH) as conn: conn.executescript(""" CREATE TABLE engineers ( engineer_id INTEGER PRIMARY KEY, name TEXT NOT NULL, github_login TEXT NOT NULL UNIQUE, email TEXT NOT NULL, country_code TEXT NOT NULL, timezone TEXT NOT NULL ); CREATE TABLE rotations ( engineer_id INTEGER NOT NULL, starts_at TEXT NOT NULL, ends_at TEXT NOT NULL, FOREIGN KEY (engineer_id) REFERENCES engineers(engineer_id) ); CREATE INDEX idx_rotations_window ON rotations (starts_at, ends_at); CREATE TABLE issues ( issue_id INTEGER PRIMARY KEY, title TEXT NOT NULL, priority TEXT NOT NULL, status TEXT NOT NULL, assignee_id INTEGER, opened_at TEXT NOT NULL, FOREIGN KEY (assignee_id) REFERENCES engineers(engineer_id) ); """) conn.executemany( "INSERT INTO engineers (name, github_login, email, country_code, timezone) " "VALUES (?, ?, ?, ?, ?)", ENGINEERS, ) now = datetime.now(timezone.utc).replace(microsecond=0) monday = (now - timedelta(days=now.weekday())).replace( hour=0, minute=0, second=0 ) rota_rows = [] for week in range(-2, 8): start = monday + timedelta(weeks=week) end = start + timedelta(weeks=1) engineer_id = (week % len(ENGINEERS)) + 1 rota_rows.append((engineer_id, start.isoformat(), end.isoformat())) conn.executemany("INSERT INTO rotations VALUES (?, ?, ?)", rota_rows) issue_rows = [] for i, (title, priority) in enumerate(ISSUE_TITLES, start=1): assignee_id = random.randint(1, len(ENGINEERS)) opened_at = (now - timedelta(hours=random.randint(2, 240))).isoformat() issue_rows.append((i, title, priority, "open", assignee_id, opened_at)) conn.executemany( "INSERT INTO issues VALUES (?, ?, ?, ?, ?, ?)", issue_rows ) conn.commit() print( f"数据库初始化完成 {DB_PATH}:{len(ENGINEERS)} 名工程师," f"{len(rota_rows)} 个轮班周期,{len(issue_rows)} 条开放问题。" )if __name__ == "__main__": seed()
脚本生成 5 名工程师(分布在美国、意大利、印度、德国、日本,每人一个国家,假日查询才有看头)、10 个轮班周期、12 条开放问题,随机分配给不同工程师。python seed_db.py 跑一下,项目根目录下就有 ops.db 了。
运维数据库 MCP Server
数据库有了,MCP Server 本体就好写了:
import osimport sqlite3from datetime import datetime, timezonefrom pathlib import Pathfrom mcp.server.fastmcp import FastMCPDB_PATH = Path(os.environ.get("OPS_DB", "ops.db")).resolve()mcp = FastMCP("ops")def _conn() -> sqlite3.Connection: conn = sqlite3.connect(DB_PATH) conn.row_factory = sqlite3.Row return conn@mcp.tool()def get_current_oncall() -> dict: """返回当前值班工程师信息。 返回: 包含 engineer_id、name、github_login、email、country_code、timezone 以及当前轮班的 starts_at、ends_at 的字典。若当前无人值班, 返回含 'error' 键的字典。 """ now = datetime.now(timezone.utc).isoformat() with _conn() as conn: row = conn.execute( """ SELECT e.engineer_id, e.name, e.github_login, e.email, e.country_code, e.timezone, r.starts_at, r.ends_at FROM rotations r JOIN engineers e ON e.engineer_id = r.engineer_id WHERE r.starts_at <= ? AND r.ends_at > ? LIMIT 1 """, (now, now), ).fetchone() ifnot row: return {"error": "当前没有工程师在值班。"} return dict(row)@mcp.tool()def list_open_issues( priority: str | None = None, assignee_id: int | None = None,) -> list[dict]: """列出开放状态的问题,可按优先级和/或负责人过滤。 参数: priority: 'P0'、'P1'、'P2'、'P3' 之一,不传则返回所有优先级。 assignee_id: 按工程师 ID 过滤,不传则返回所有人的问题。 返回: 包含 issue_id、title、priority、assignee_id、opened_at 的字典列表。 无匹配时返回空列表。 """ clauses = ["status = 'open'"] params: list = [] if priority: clauses.append("priority = ?") params.append(priority) if assignee_id isnotNone: clauses.append("assignee_id = ?") params.append(assignee_id) sql = ( "SELECT issue_id, title, priority, assignee_id, opened_at " "FROM issues WHERE " + " AND ".join(clauses) + " ORDER BY opened_at" ) with _conn() as conn: rows = conn.execute(sql, params).fetchall() return [dict(r) for r in rows]@mcp.tool()def get_engineer(github_login: str) -> dict: """通过 GitHub 账号查找工程师。 参数: github_login: GitHub 用户名。 返回: 完整的工程师记录,找不到时返回含 'error' 键的字典。 """ with _conn() as conn: row = conn.execute( "SELECT engineer_id, name, github_login, email, country_code, " "timezone FROM engineers WHERE github_login = ?", (github_login,), ).fetchone() return dict(row) if row else {"error": f"未找到工程师 {github_login}"}@mcp.tool()def list_engineers() -> list[dict]: """列出所有工程师。""" with _conn() as conn: rows = conn.execute("SELECT * FROM engineers").fetchall() return [dict(r) for r in rows]if __name__ == "__main__": mcp.run(transport="stdio")
注意这里工具都用同步 def 而不是 async def——SQLite 查询快,阻塞完全没问题;只有真正做网络 I/O 的工具(比如 holidays server 里的 HTTP 请求)才需要 async。FastMCP 两种方式都能处理,不用担心。
Skill:用自然语言写的"程序"
两个 MCP Server 都就位了,接下来写 Skill。Skill 不是一个普通 prompt,而是用自然语言写的带执行逻辑的程序,明确告诉模型该怎么一步步组合这些工具。在这套类比里,Skill 是程序,LLM 是跑它的运行时。
skills/oncall_holiday_check.md :
# 值班假日检查## 目的判断当前值班工程师所在国家今天是否有公共假日,若有,列出其名下待处理的高优先级问题,以便安排备班人员。## 可用工具- `get_current_oncall()` — 返回当前值班工程师,包含 `engineer_id`、`name`、`country_code` 等字段。可能返回 `error` 键。- `is_public_holiday(country_code, on_date)` — 返回`{is_holiday: bool, holiday_name?: str, holiday_local_name?: str}` 或 `{error: str}`。`on_date` 格式须为 YYYY-MM-DD。- `list_open_issues(priority, assignee_id)` — 返回开放问题列表, 两个参数均为可选过滤条件。- `get_engineer(github_login)` — 按 GitHub 账号查找工程师。 主流程不需要此工具。- `list_engineers()` — 列出所有工程师。主流程不需要此工具。- `list_country_holidays(country_code, year)` — 列出某国某年全部假日。 主流程不需要此工具。## 执行步骤今天的日期已在系统上下文中提供。1. 调用 `get_current_oncall()`。若返回 error,回复 "当前没有工程师在值班。"并停止。2. 调用一次 `is_public_holiday(country_code, on_date)`,传入 值班工程师的 `country_code` 和今天的日期。3. 调用一次 `list_open_issues(priority=<问题中指定的优先级>, assignee_id=<id>)`,传入值班工程师的 `engineer_id`。 若问题未指定优先级,省略该过滤条件,返回所有开放问题。4. 组织一段简短的最终回答: - 若 `is_holiday` 为 true:以 "需要升级:" 开头,说明工程师姓名、 所在国家和假日名称,然后将其每条对应优先级的开放问题单独列为 一行,格式为 `#<issue_id> <标题>`。若该优先级下没有问题, 请明确说明。 - 若 `is_holiday` 为 false:以 "值班正常:" 开头,说明工程师姓名、 所在国家和今天是正常工作日,问题列表格式相同。## 约束- 不得自行编造工程师、问题、假日或任何数据,只能使用工具返回的内容。- 三个必要工具各调用一次,不循环、不重试。- 最终回答保持简洁,无需前言,无需总结。
Skill 分三块:目的(这个 Skill 干什么用的)、可用工具(列出所有能调的工具,没用上的也明确注明"主流程不需要",防止模型闲着没事乱调用)、执行步骤 + 约束(明确的执行顺序和两个输出模板,加上不许编造数据、工具各调一次、回答要简洁这几条硬约束)。
Skill 里没有"例子",没有"请尽可能有帮助地回答"这类废话,没有鼓励模型"发散思考"——这就是个程序,模型的任务是执行它,不是发挥它。Skill 和 MCP Server、编排器一起进版本控制,可以 review,可以 diff,可以跑 eval。
编排器:把所有东西串起来
编排器是整套系统里代码量最少、职责最重的一块。它干这几件事:加载配置、把每个 MCP Server 作为子进程拉起来、收集所有工具定义、把工具格式转换成 Ollama 能认的 schema、把 Skill 注入 system prompt,然后跑工具调用循环,直到模型给出最终回答。
orchestrator.py :
import argparseimport asyncioimport jsonimport osimport sysfrom contextlib import AsyncExitStackfrom datetime import datefrom pathlib import Pathimport ollamafrom mcp import ClientSession, StdioServerParametersfrom mcp.client.stdio import stdio_clientROOT = Path(__file__).resolve().parentDEFAULT_CONFIG = ROOT / "config.json"def load_config(config_path: Path) -> dict: cfg = json.loads(config_path.read_text()) cfg["_root"] = config_path.resolve().parent python = os.path.expanduser(cfg.get("python", "python3")) cfg["python"] = python if os.path.isabs(python) else sys.executable return cfgdef env_for_server(server_cfg: dict, root: Path) -> dict[str, str]: """把 server 的 env 块合并进当前环境,展开 {root} 占位符。""" base = os.environ.copy() for k, v in server_cfg.get("env", {}).items(): base[k] = v.replace("{root}", str(root)) return basedef mcp_to_ollama_tool(tool) -> dict: """把 MCP Tool 定义转换成 Ollama 的 function-tool schema。""" return { "type": "function", "function": { "name": tool.name, "description": tool.description or"", "parameters": tool.inputSchema, }, }def trace(msg: str) -> None: print(msg, file=sys.stderr, flush=True)asyncdef run(question: str, cfg: dict) -> None: asyncwith AsyncExitStack() as stack: sessions: dict[str, ClientSession] = {} tool_owner: dict[str, str] = {} ollama_tools: list[dict] = [] for server_name, server_cfg in cfg["mcp_servers"].items(): params = StdioServerParameters( command=cfg["python"], args=[str(cfg["_root"] / server_cfg["script"])], env=env_for_server(server_cfg, cfg["_root"]), ) read, write = await stack.enter_async_context(stdio_client(params)) session = await stack.enter_async_context(ClientSession(read, write)) await session.initialize() sessions[server_name] = session listed = await session.list_tools() for t in listed.tools: if t.name in tool_owner: raise RuntimeError(f"工具名冲突:{t.name}") tool_owner[t.name] = server_name ollama_tools.append(mcp_to_ollama_tool(t)) trace(f"[注册] {server_name}.{t.name}") skill = (cfg["_root"] / cfg["skill_path"]).read_text() system = ( f"今天的日期是 {date.today().isoformat()}。\n\n" f"你可以使用以下 Skill,请严格按照其步骤执行。\n\n" f"---\n{skill}\n---" ) messages = [ {"role": "system", "content": system}, {"role": "user", "content": question}, ] client = ollama.AsyncClient(host=cfg["ollama_host"]) for step in range(cfg["max_steps"]): response = await client.chat( model=cfg["model"], messages=messages, tools=ollama_tools, ) assistant_msg = response.message messages.append(assistant_msg) tool_calls = assistant_msg.tool_calls or [] ifnot tool_calls: print("\n=== 最终回答 ===\n") print(assistant_msg.content or"(空)") return for call in tool_calls: name = call.function.name args = call.function.arguments if isinstance(args, str): args = json.loads(args) owner = tool_owner.get(name) if owner isNone: result_text = json.dumps({"error": f"未知工具 {name}"}) trace(f"[第{step}步] -> ?? {name}({args}) [未知工具]") else: trace(f"[第{step}步] -> {owner}.{name}({args})") result = await sessions[owner].call_tool(name, args) chunks = [c.text for c in result.content if hasattr(c, "text")] result_text = "\n".join(chunks) if chunks else"{}" preview = result_text.replace("\n", " ")[:160] trace(f"[第{step}步] <- {preview}") messages.append({ "role": "tool", "name": name, "content": result_text, }) trace(f"[中止] 已达最大步数 max_steps={cfg['max_steps']},未能得到最终回答")if __name__ == "__main__": parser = argparse.ArgumentParser(description="按 Skill 驱动 MCP Server 回答问题。") parser.add_argument( "--config", type=Path, default=DEFAULT_CONFIG, help="配置文件路径(默认:脚本同目录下的 config.json)。", ) parser.add_argument( "question", nargs="*", help="要提问的内容,不传则使用 config 里的 default_question。", ) args = parser.parse_args() cfg = load_config(args.config.resolve()) question = " ".join(args.question) or cfg["default_question"] asyncio.run(run(question, cfg))
编排器对任何具体 MCP 或 Skill 一无所知,config 才是真正的程序。tool_owner 这张路由表把工具名映射到对应的 Server——工具名从 LLM 视角是全局的,从运行时视角是局部的。如果两个 Server 定义了同名工具,立刻报错,不会悄悄出错。
tool.function.arguments 做了防御性处理,可能是 dict 也可能是 JSON 字符串,两种情况都能接住。
跑起来看看
数据库种好、Ollama daemon 跑着,就可以直接起了:
# 用默认问题python orchestrator.py# 指定问题python orchestrator.py "本周谁在值班?他们有没有 P0 问题?"# 换一套完全不同的任务python orchestrator.py --config configs/deploy_check.json
stderr 会把每一步工具调用都打出来(已格式化):
[注册] holidays.is_public_holiday[注册] holidays.list_country_holidays[注册] ops.get_current_oncall[注册] ops.list_open_issues[注册] ops.get_engineer[第0步] -> ops.get_current_oncall({})[第0步] <- {"engineer_id": 2, "name": "Marco Rossi", "github_login": "marco-r", ...[第1步] -> holidays.is_public_holiday({'country_code': 'IT', 'on_date': '2026-04-25'})[第1步] <- {"is_holiday": true, "holiday_name": "Liberation Day", "holiday_local_name": "Festa della Liberazione"}[第2步] -> ops.list_open_issues({'priority': 'P1', 'assignee_id': 2})[第2步] <- [{"issue_id": 1, "title": "API gateway returns 502 under load", "priority": "P1", ...
stdout 里最终输出:
=== 最终回答 ===需要升级:Marco Rossi(意大利)正在值班,但今天是意大利的公共假日:解放日(Festa della Liberazione)。其名下开放的 P1 问题:- #1 API 网关在高负载下返回 502- #6 仪表盘数据超过 5 分钟未刷新- #10 OAuth 回调拒绝有效的 state token
模型做了什么一目了然:调 get_current_oncall 找到值班人 → 调 is_public_holiday 发现今天是意大利解放日 → 调 list_open_issues 拿到该工程师名下的 P1 问题 → 按 Skill 的步骤组装出带"需要升级:“前缀的最终回答。平时没有假日,输出就变成"值班正常:”,逻辑完全一样,两条路都有用。
想看模型完整的对话历史?在 return 前加一行 trace(json.dumps(messages, default=str, indent=2)) 就完事了——这就是这套系统的可观测层,等价于传统调试里的 profiler 或 debug log。
这套东西的本质是什么
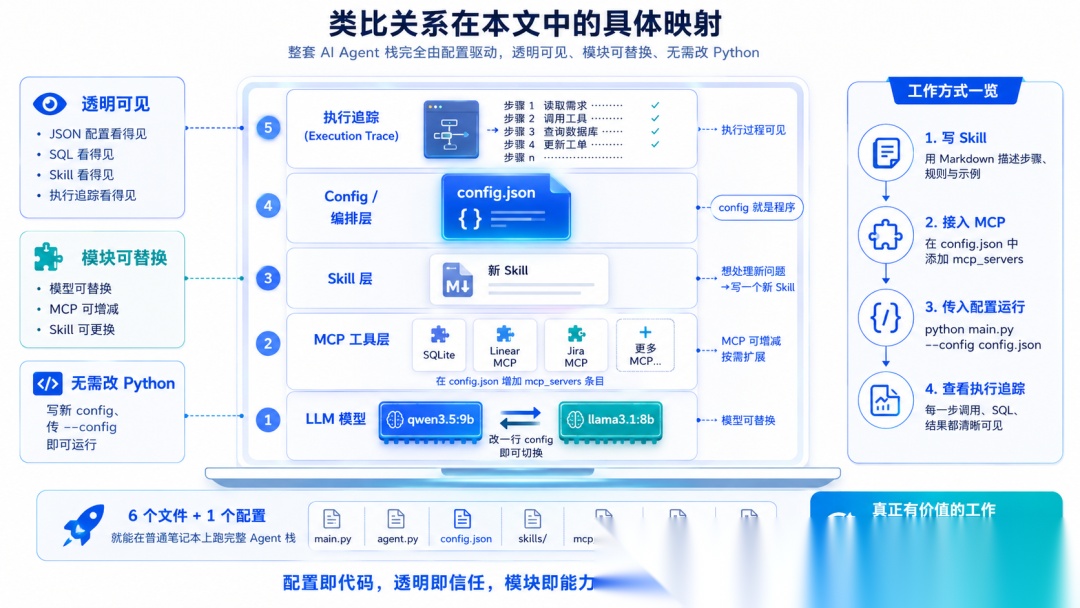
类比关系在本文中的具体映射
回到最开始的类比。这套系统每一层都是透明的:JSON 配置看得见,SQL 看得见,Skill 看得见,执行追踪看得见。每一层也都是可替换的:把 qwen3.5:9b 换成 llama3.1:8b,改一行 config;把 SQLite 换成真实的 Linear 或 Jira MCP,加一条 mcp_servers 条目;想处理完全不同的问题,写一个新 Skill、建一个新 config、传 --config 参数进去。全程没有动过任何 Python。
编排器对任何具体的 MCP 和 Skill 都不知情,config 就是程序。要加第三个、第四个、第十个 MCP,只需要在 config.json 里多写一个条目,填上 script 和 env 就完了,真的就这么多。
整个系统六个文件加一个配置,跑在一台普通笔记本上。把它当模板,不要当终点。真正有意思的工作在后面:写什么样的 Skill,怎么给它们跑 eval,以及把哪些内部系统包装成 MCP 暴露出来——这才是这套架构真正值钱的地方。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献161条内容
已为社区贡献161条内容

所有评论(0)