面试官:在高并发场景下,你是如何保证数据的一致性和可靠性的?
最近帮粉丝看简历,发现一个重灾区。很多同学简历上赫然写着“精通高并发”、“熟悉分布式架构”。
结果面试官微微一笑,抛出一个经典必问:
“在高并发场景下,你是如何保证数据的一致性和可靠性的?”
很多同学脑子一热,条件反射就开始背八股文:
“简单啊!加分布式锁!”
“先写库,再删缓存!”
“实在不行用延时双删!”
这时候,面试官的连环炮就来了:
“延时双删里的 sleep 时间你怎么定?靠猜吗?”
“如果删缓存的动作失败了,MQ挂了,数据不就不一致了吗?”
“微服务之间跨库怎么保证事务一致性?难道你要用 2PC?”
这一通问下来,你支支吾吾半天答不上来。这就是你简历上写的“精通”?
今天 Fox 老师带你拆解这个面试“修罗场”,把这层窗户纸彻底捅破!
01 核心矛盾:一场“殊死搏斗”
首先,把你的思维从“码农”升级到“架构师”。
在高并发系统里,核心矛盾到底是什么? 答案是:性能(Performance)与一致性(Consistency)的死磕。
根据 CAP 理论,你想要高可用(Availability)和分区容错性(Partition tolerance),往往就得牺牲强一致性。
所以,把这句话刻在脑子里:
绝大多数高并发业务场景,我们要追求的根本不是不切实际的“强一致性”,而是更具弹性的“最终一致性”。
02 第一层:缓存与数据库的“双重奏”
我们先看最基础的战场:Cache Aside Pattern(旁路缓存模式)。 读请求很简单:缓存没命中就查库,查完回写缓存。 真正让无数人翻车的是写请求!
1. 更新缓存还是删除缓存?
有人说:“老师,更新缓存效率高啊,不用下次再查库了。”
错!大错特错! Tell me why? 假设线程 A 和 B 并发写库。A 先写库(值=1),B 后写库(值=2)。 但因为网络抖动等原因,B 先更新了缓存,A 后更新了缓存。
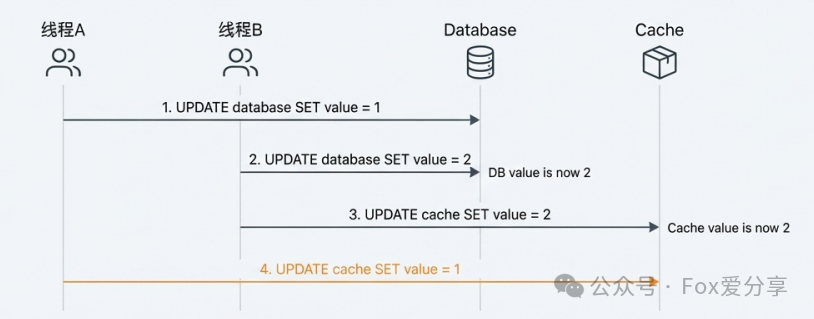
结果: 数据库是新的(2),缓存却是旧的(1)。 这就是典型的脏数据!
所以在高并发写场景下,必须删除缓存,让下一次读请求去回填。
2. 先删缓存还是后删缓存?
那有人又抖机灵了:“那我先删缓存,再写数据库,总行了吧?”
这叫倒行逆施,后果更严重! 来看这个场景:
-
线程 A 删了缓存,还没来得及写库。
-
线程 B 来了,发现缓存空了,去读库(读到了旧数据)。
-
线程 B 把旧数据塞回缓存。
-
线程 A 终于把新数据写入数据库。
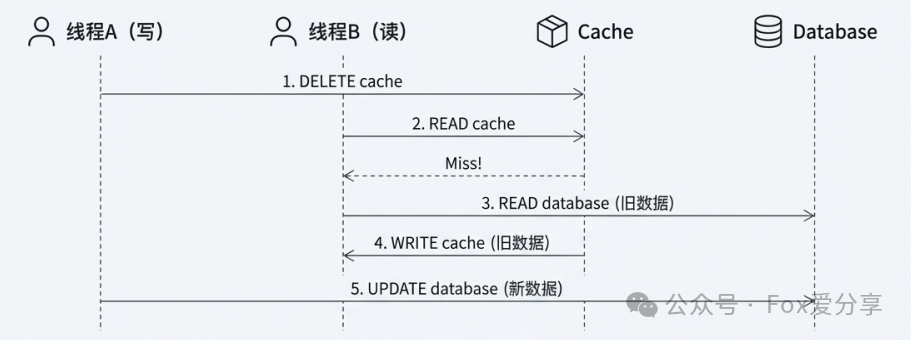
结果: 哪怕 A 写库成功了,缓存里永远躺着那个旧数据。这叫持久性的脏数据!
3. “延时双删”是解药吗?
江湖上流传着一招“延时双删”:
先删缓存 -> 写库 -> sleep 一会儿 -> 再删缓存。
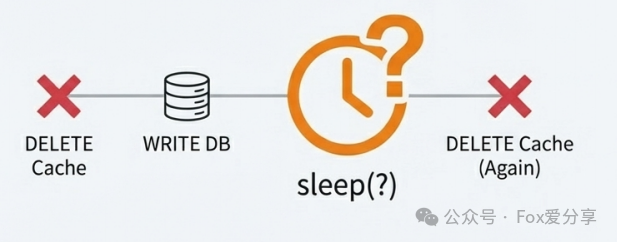
这个 sleep 时间你怎么定?
睡久了,系统吞吐量直接掉底;
睡短了,覆盖不了数据库的主从同步延迟。
我常说一句话:“在生产环境的核心链路里写 Thread.sleep 的,直接拉出去祭天!”
03 第二层:架构师的答案 —— 异步解耦
那到底怎么做才能既优雅又可靠?
答案是:异步解耦!构建基于 Binlog 的异步消息流。
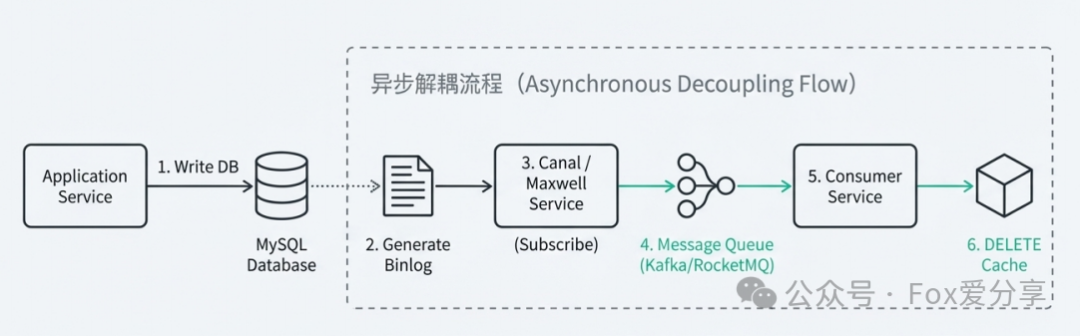
架构思路非常清晰:业务代码只管写 MySQL,其他的“脏活累活”别管。
我们利用 Canal 或 Maxwell 这种组件,把自己伪装成 MySQL 的从节点,监听 MySQL 的 Binlog。
-
一旦数据发生变动,组件自动解析并发送消息到 MQ(Kafka/RocketMQ)。
-
下游消费者收到消息,去执行“删缓存”操作。
为什么这才是满分答案? 因为 MQ 有重试机制! 如果删缓存失败了?没关系,MQ 会一直重试,直到成功。 如果一直失败?消息进入死信队列,触发报警,人工介入。
这就是最终一致性的完美体现——系统虽然有短暂的延迟,但数据终将一致,且业务接口响应极快。
04 第三层:微服务下的“原子性”挑战
难度升级!如果是跨服务的场景呢? 比如“订单服务”下订单,“库存服务”扣库存。

千万别跟我说用** 2PC(两阶段提交)**! XA/2PC 是同步阻塞的,锁定资源时间太长。 谁在高并发系统里用 2PC,谁就是系统的罪人!
终极方案:RocketMQ 的“事务消息”。

这是一套基于“半消息(Half Message)”的魔法:
-
发半消息:订单服务先发一条消息给 MQ。注意,此时消费者(库存服务)是不可见的,消费不到。
-
执行本地事务:订单服务去写自己的数据库(创建订单)。
-
Commit/Rollback:
-
本地事务成功,告诉 MQ “提交”,消费者这时候才能看到这条消息,去扣库存。
-
本地事务失败,告诉 MQ “回滚”,消息直接丢弃。
那么问题又来了!(敲黑板) 如果本地事务成功了,但发送 Commit 的时候网络断了,MQ 没收到怎么办?
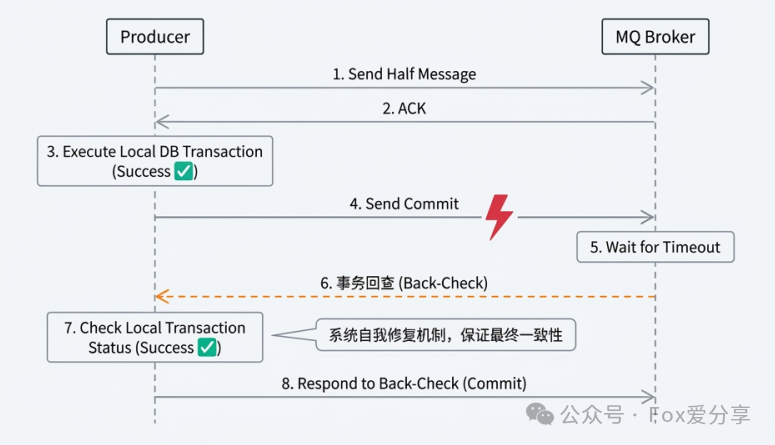
RocketMQ 有个大杀器叫“事务回查(Back-Check)”机制。 MQ 发现这条半消息悬在半空很久了,它会反过来问发送方(订单服务):
“哎,兄弟,你刚才那笔事务到底成没成啊?”
这时候你去查查本地库,如果订单在,就补发 Commit;如果不在,就回滚。
这就是系统的自我修复机制,既保证了性能(没有长锁),又保证了数据绝对不丢!
05 总结
别再死记硬背那些过时的八股文了。
从“删缓存”的陷阱,到 Binlog 异步解耦,再到 RocketMQ 的事务消息,我们在高并发下践行的架构思维其实只有三点:
-
可用性优先 (Availability First)
-
接受软状态 (Accept Soft States)
-
最终一致性兜底 (Eventual Consistency)
这才是真正“精通高并发架构”该有的样子!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)