sklearn 线性回归:原理 + 代码一步到位
前言
线性回归是机器学习中最基础、最经典的监督学习算法,也是新手入门机器学习的首选算法。它的核心思想是通过拟合一条直线 / 超平面,来描述自变量和因变量之间的线性关系,既可以用于预测连续数值,也能分析变量间的关联规律。
一、sklearn - 线性回归介绍
scikit-learn(简称 sklearn)是 Python 中最常用的机器学习库,封装了完善的线性回归算法接口,无需手动实现复杂数学计算,只需几行代码就能完成模型训练、预测和评估。
sklearn 线性回归的核心特点:
- 专门处理连续值预测问题(如预测房价、销售额、温度等);
- 基于最小二乘法优化模型,拟合效果稳定;
- 支持一元线性回归(单个自变量)和多元线性回归(多个自变量);
- 接口简洁,新手易上手,适配各类入门级数据集。
二、线性回归
1. 一元线性回归
定义:只有一个自变量 X和一个因变量 y的线性回归模型,是最简单的线性回归形式。
它的数学表达式):
y = β 0 + β 1 x + ϵ y = \beta_0 + \beta_1 x + \epsilon y=β0+β1x+ϵ
其中:
- y y y:y:预测的目标值(因变量)
- x x x:自变量(特征)
- β 0 \beta_0 β0:截距项(偏置)
- β 1 \beta_1 β1:斜率(权重系数)
- ϵ \epsilon ϵ:随机误差项,通常假设 ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim N(0, \sigma^2) ϵ∼N(0,σ2)
模型的目标是通过最小二乘法找到最优的 β 0 \beta_0 β0 和 β 1 \beta_1 β1,使得预测值与真实值之间的误差平方和最小:
min β 0 , β 1 ∑ i = 1 n ( y i − ( β 0 + β 1 x i ) ) 2 \min_{\beta_0, \beta_1} \sum_{i=1}^{n} (y_i - (\beta_0 + \beta_1 x_i))^2 β0,β1mini=1∑n(yi−(β0+β1xi))2
2. 多元线性回归模型
定义:包含两个及以上自变量 X X X 和一个因变量 y y y 的线性回归模型,更贴合实际业务。
2.1 数学表达式
多元线性回归模型的数学表达式为:
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β p x p + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \epsilon y=β0+β1x1+β2x2+⋯+βpxp+ϵ
其中:
- y y y:因变量(目标值)
- x 1 , x 2 , … , x p x_1, x_2, \dots, x_p x1,x2,…,xp: p p p 个自变量(特征)
- β 0 \beta_0 β0:截距项(偏置)
- β 1 , β 2 , … , β p \beta_1, \beta_2, \dots, \beta_p β1,β2,…,βp:各自变量对应的回归系数(权重)
- ϵ \epsilon ϵ:随机误差项,通常假设 ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim N(0, \sigma^2) ϵ∼N(0,σ2)
多元线性回归就是找一个超平面拟合数据点。
3.最小二乘法
最小二乘法 = 让所有数据点到拟合直线 / 超平面的距离平方和最小。
通俗理解就是我们要找的直线,不能随意画,要让它离所有数据点的 “总距离” 最短,这样模型预测才最准确。sklearn 的线性回归模型,底层自动用最小二乘法优化,我们无需手动实现。
其核心思想是最小化残差平方和(Residual Sum of Squares, RSS)。对于一元线性回归,目标函数为:
min β 0 , β 1 ∑ i = 1 n ( y i − ( β 0 + β 1 x i ) ) 2 \min_{\beta_0, \beta_1} \sum_{i=1}^{n} (y_i - (\beta_0 + \beta_1 x_i))^2 β0,β1mini=1∑n(yi−(β0+β1xi))2
对于多元线性回归,目标函数为:
min β ∑ i = 1 n ( y i − ( β 0 + β 1 x i 1 + β 2 x i 2 + ⋯ + β p x i p ) ) 2 \min_{\boldsymbol{\beta}} \sum_{i=1}^{n} \left( y_i - (\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip}) \right)^2 βmini=1∑n(yi−(β0+β1xi1+β2xi2+⋯+βpxip))2
三、实例讲解
文件预览: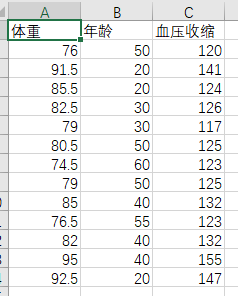
import pandas as pd
from sklearn.linear_model import LinearRegression
data = pd.read_csv("多元线性回归.csv",encoding='gbk')
lr_model = LinearRegression()
x = data[['体重','年龄']]
y = data['血压收缩']
lr_model.fit(x,y)
score = lr_model.score(x,y)
print(lr_model.predict([[80,60]]))
print(lr_model.predict([[70,30],[70,20]]))
a = lr_model.coef_
b = lr_model.intercept_
print("线性回归模型: y ={:.2f}x1+ {:.2f}x2 + {:.2f}.".format(a[0], a[1], b))
首先先导入数据分析工具 pandas,用来读取、处理表格数据(csv/excel)。
pd 是行业通用简写,后面所有 pandas 操作都用 pd.xxx。
同时导入机器学习线性回归算法,用来做预测、拟合公式。
import pandas as pd
from sklearn.linear_model import LinearRegression
读取当前文件夹里的 csv 数据文件,加载成表格格式。
“encoding=”后面是Windows 系统中文文件常用编码,防止中文乱码。
data = pd.read_csv("多元线性回归.csv",encoding='gbk')
创建一个线性回归模型对象,此时模型还没学习数据,只是一个 “空工具”。
lr_model = LinearRegression()
通常选取x作为预测的变量,同时用到多元线性回归是为了多个输入得到1个输出。
这里用双重中括号保证 X 是二维数据。
我们想通过体重、年龄预测血压,所以血压是 y。
# 选取 自变量 X(特征):体重、年龄 两列
x = data[['体重','年龄']]
# 选取 因变量 y(目标):血压收缩
y = data['血压收缩']
用到模型学习的方法 modle.fit(),他可以做到自动算出最优的回归系数、截距,生成数学公式,是训练模型的核心。
lr_model.fit(x,y)
计算模型拟合优度,范围 0~1,值越大说明模型对数据的解释能力越强,越接近1效果越好。
代码里计算了但没打印,根据需求可以加一句 print(score) 看结果。
score = lr_model.score(x,y)
# print(score)
用训练好的模型做预测,输入格式必须是 [[体重,年龄]] 二维列表。
这里我们预测体重 80,年龄 60 的血压值,并打印结果。
print(lr_model.predict([[80,60]]))
我们再一次性预测多组样本,输出两组预测结果。
print(lr_model.predict([[70,30],[70,20]]))
取出多元线性回归的系数。
格式:[x1系数, x2系数] → 对应体重、年龄的系数。
a[0] = 体重系数,a[1] = 年龄系数。
a = lr_model.coef_
b = lr_model.intercept_
输出数学公式,方便直接使用。
这里的“{:.2f}”的目的保留两位小数,更美观。
x1 = 体重,x2 = 年龄,y = 血压收缩。
# 打印最终的线性回归方程,保留2位小数
print("线性回归模型: y ={:.2f}x1+ {:.2f}x2 + {:.2f}.".format(a[0], a[1], b))
输出结果:
前两行输出的是我们分别做预测的结果,即血压为多少。
第三行输出的是是线性回归公式,可理解为:
血压收缩 = 2.14× 体重 + 0.40× 年龄 + -62.96
[131.97426124]
[98.60219521 94.60003367]
线性回归模型: y =2.14x1+ 0.40x2 + -62.96.
代码的流程为:导入工具库 → 读取数据 → 定义特征和目标 → 训练模型 → 预测血压 → 输出模型公式
这段代码是完整的多元线性回归机器学习实现,用体重、年龄两个特征训练模型,预测血压收缩值,如有需要可在自己的计算机上运行此代码。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)