【AI大模型第16集】什么是Skills?Skills核心技术原理详细介绍
文章目录
一、什么是Skills ?
Skills(技能)是一种标准扩展规范,最早由Anthropic公司在2025年10月16日正式推出,作为Claude大模型的能力扩展机制。如今已成为AI Agent开发的行业标准,被微软Azure、GitHub Copilot等主流平台广泛支持。
Skills是将"操作性知识"封装为模块化单元的技术架构,不仅仅是提示词集合,而是包含指令、执行脚本、参考资料和资产模板的完整软件工件。
简单的说,Skill 就像是一个领域专家,比如一个资深护理专家,他具备了丰富的护理理论知识及实操经验,精通各项护理操作流程。当AI需要的处理护理相关操作的时候,就能识别并加载这个Skill,利用这个资深护理专家去处理问题。
二、为什么需要Skills ?
在Skills出现之前,Agent开发可能会遇到以下问题:
- 提示词疲劳:开发者需要为同一任务反复编写复杂的提示词。
- 能力碎片化:每个AI工具都需要单独适配,维护成本极高。
- 专业深度不足:通用模型难以在特定领域达到专家水平。
- 上下文冗余:所有工具schema一次性塞入上下文,导致上下文爆炸式增长,响应延时。
为了解决了这些问题,于是Skills概念被提出,并被大厂广泛采用,其主要是因为他具有以下优势:
- 从"通用助手"到"领域专家"的转变
Skills架构最根本的优势是将AI从通用聊天工具转变为领域专家:
- 专业化能力:每个Skill专注于特定领域(如数据分析、代码审查、测试用例生成)。
- 深度知识封装:将专家经验、最佳实践、业务规则封装为可复用的模块。
- 精准问题解决:不再是泛泛而谈,而是提供具体、可执行的解决方案。
- 知识的结构化与可管理性
相比传统的提示词工程,Skills架构提供了工程化的知识管理:
- 版本控制:Skills可以像代码一样进行版本管理、回滚、协作开发。
- 组织化存储:以文件夹形式组织,包含脚本、配置、文档、参考资料等完整资产。
- 渐进式披露:按需加载技能内容,避免上下文爆炸,优化token使用效率。
- 可复用性与可转移性
Skills架构解决了AI知识孤岛问题:
- 跨项目复用:一个Skill可以在多个项目、团队中重复使用。
- 跨平台兼容:标准化的Skill格式支持在不同AI平台间迁移。
- 知识沉淀:企业内部专家经验可以固化为Skills,避免人员流失导致的知识断层。
- 性能与效率优化
- 减少token消耗:通过渐进式披露机制,只在需要时加载相关技能内容。
- 加速响应时间:预定义的Skills比实时生成提示词更高效。
- 降低错误率:标准化流程减少人为错误和不一致性。
- 工程化与可维护性
- CI/CD集成:Skills可以纳入标准的软件开发流程,支持自动化测试、部署。
- 权限控制:细粒度的访问控制,确保敏感操作的安全性。
- 审计追踪:完整的执行日志和版本历史,便于问题排查和合规性审计。
- 持续学习与进化能力
- 反馈闭环:Skills可以根据使用反馈持续优化改进。
- 组合创新:多个Skills可以组合成更复杂的解决方案。
- 社区共享:Skills可以像开源软件一样在社区中共享、改进。
- 企业级应用价值
- 标准化流程:将企业内部的最佳实践固化为可执行的Skills。
- 降低学习成本:新员工可以通过Skills快速掌握专业工作流程。
- 质量一致性:确保不同人员执行相同任务时输出质量的一致性。
- 生态系统建设
- 技能市场:形成Skills的创建、分享、交易生态系统。
- 专业分工:不同角色(开发者、领域专家、产品经理)可以协作创建Skills。
- 技术融合:Skills可以集成各种工具、API、数据源,形成完整解决方案。
三、Skills 核心设计
Skills 架构核心是三级渐进式披露(Progressive Disclosure),采用严格的三层架构,每层具有不同的信息密度和加载时机,是解决大语言模型上下文窗口限制和token成本优化的核心机制。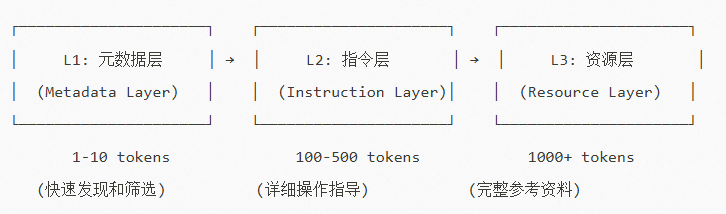
1. L1元数据层(启动加载)
1.1 核心内容
L1层包含技能的最基本信息,用于对技能的快速识别和筛选:
- 技能名称(name):唯一标识符
- 简短描述(description):1-2句话说明技能用途
- 关键词(keywords):用于意图匹配
- 能力标签(capabilities):技能类型标记
- 激活条件(activation_conditions):触发规则
1.2 实现细节
# SKILL.yaml (L1元数据)
name: "data_analysis"
description: "执行数据分析任务,包括数据清洗、统计分析和可视化"
keywords: ["analyze", "data", "statistics", "visualization"]
capabilities:
- data_processing
- statistical_analysis
- report_generation
activation_conditions:
intent_contains: ["analyze", "data", "chart", "graph"]
context_contains: ["dataset", "csv", "excel", "database"]
1.3 加载机制
- 时机:每次用户输入后,意图识别阶段
- 方式:批量加载所有技能的L1元数据
- 规模:通常200-500个技能,总token消耗<500
- 处理流程:
- 提取用户输入中的关键词和意图
- 与所有技能的L1元数据进行相似度匹配
- 选择top-N(通常3-5个)最相关的技能
- 为这些技能激活L2层加载
1.4 优化策略
- 缓存机制:频繁使用的技能元数据常驻内存
- 索引优化:建立倒排索引加速关键词匹配
- 优先级排序:根据历史使用频率调整技能排序
2. L2指令层(触发时加载)
2.1 核心内容
L2层包含技能的详细操作指导,用于任务规划和执行:
- 详细说明(detailed_description):技能的完整功能描述
- 使用场景(use_cases):典型应用场景示例
- 输入规范(input_spec):参数定义和验证规则
- 输出规范(output_spec):结果格式和验证规则
- 执行步骤(execution_steps):详细的操作流程
- 错误处理(error_handling):异常情况处理指南
2.2 实现细节
# SKILL.md (L2指令层)
## 详细说明
本技能专门处理结构化数据分析任务,支持多种数据源(CSV、Excel、数据库)的读取和分析。提供数据清洗、统计计算、可视化生成等完整功能。
## 使用场景
1. 业务数据分析:销售趋势、用户行为分析
2. 科学研究:实验数据统计分析
3. 金融分析:风险评估、收益计算
## 输入规范
- data_source: string (required) - 支持文件路径或数据库连接字符串
- analysis_type: enum ['descriptive', 'inferential', 'predictive']
- output_format: enum ['json', 'csv', 'html', 'image']
## 执行步骤
1. 数据加载:验证数据源并加载数据
2. 数据清洗:处理缺失值、异常值
3. 统计分析:根据analysis_type执行相应计算
4. 结果生成:按output_format格式化结果
5. 验证输出:检查结果完整性和正确性
2.3 加载机制
- 时机:L1筛选后,任务规划阶段
- 方式:仅加载L1筛选出的top-N技能的L2内容
- 规模:3-5个技能,每个技能200-500 tokens
- 处理流程:
- 将激活技能的L2内容注入上下文
- LLM基于这些指令制定详细执行计划
- 识别需要的具体工具和参数
- 决定是否需要加载L3资源
2.4 安全控制
- 权限验证:检查当前用户是否有权限使用该技能
- 资源限制:设置计算资源使用上限
- 沙箱环境:在隔离环境中执行敏感操作
3. L3资源层(按需加载)
3.1 核心内容
L3层包含技能所需的完整参考资料和专业知识:
- 技术文档:详细的API文档、技术规范
- 示例代码:完整的代码示例和模板
- 数据字典:字段定义、数据格式说明
- 业务规则:领域特定的业务逻辑和约束
- 历史案例:类似任务的处理历史
- 外部知识:相关论文、标准文档等
3.2 实现细节
# resources.py (L3资源层示例)
import pandas as pd
import matplotlib.pyplot as plt
from typing import Dict, List, Any
import json
# 完整的数据分析函数库
def load_data(data_source: str) -> pd.DataFrame:
"""加载数据源,支持多种格式"""
if data_source.endswith('.csv'):
return pd.read_csv(data_source)
elif data_source.endswith('.xlsx'):
return pd.read_excel(data_source)
elif '://' in data_source: # 数据库连接
return pd.read_sql(data_source.split('://')[1], data_source.split('://')[0])
else:
raise ValueError(f"Unsupported data source format: {data_source}")
# 详细的统计分析函数
def perform_analysis(df: pd.DataFrame, analysis_type: str) -> Dict[str, Any]:
"""执行不同类型的统计分析"""
results = {}
if analysis_type == 'descriptive':
results['summary'] = df.describe().to_dict()
results['missing_values'] = df.isnull().sum().to_dict()
elif analysis_type == 'inferential':
# 假设检验、置信区间等
results['statistical_tests'] = perform_statistical_tests(df)
elif analysis_type == 'predictive':
# 机器学习模型
results['model_performance'] = train_predictive_model(df)
return results
3.3 加载机制
- 时机:L2规划后,实际执行阶段
- 方式:通过专用工具load_skill_resource按需调用
- 规模:仅加载当前技能所需的特定资源
- 处理流程:
- LLM生成执行计划时识别需要的具体资源
- 调用load_skill_resource工具加载指定资源
- 资源在沙箱环境中执行,结果返回给LLM
- 执行完成后自动清理资源
3.4 关键设计原则
- 延迟加载:只有在真正需要时才加载L3资源
- 局部作用域:资源只在当前任务上下文中可见
- 自动清理:任务完成后自动释放资源
- 版本控制:支持资源版本管理和回滚
4. 三级加载层级间状态如何切换?
复杂的Skills采用状态机模式管理执行流程,Skills 在三个层次间的状态转换遵循严格的规则。每个状态都有明确的进入条件和退出动作,支持错误回滚和重试机制。
状态机转换:
L1 (元数据) --意图匹配--> L2 (指令) --执行需要--> L3 (资源)
↑ |
|---任务完成------------------|
|---超时/错误-----------------|
- L1 → L2:当用户意图与技能关键词匹配度超过阈值。
- L2 → L3:当执行计划明确需要特定资源。
- L3 → L2:资源执行完成,返回结果。
- L2 → L1:任务完成或超时,释放L2上下文。
- 错误处理:任何层次的错误都会触发状态回退,并记录日志。
四、Skills 目录结构
Skills架构采用标准化的目录结构设计,确保技能的可管理性、可复用性和工程化管理。
1. Skills 根目录结构
skills/
├── core/ # 核心基础技能
├── domain/ # 领域专业知识技能
├── tools/ # 工具集成技能
├── utils/ # 通用工具函数
├── templates/ # 技能模板
├── config/ # 全局配置
├── docs/ # 文档
├── tests/ # 测试用例
├── scripts/ # 构建和部署脚本
└── skill_manifest.json # 全局技能清单
2. Skill 技能模块目录结构
每个Skill 技能模块都遵循统一的标准化结构:
skills/
└── {category}/ # 技能类别
└── {skill_name}/ # 具体技能名称
├── SKILL.yaml # 技能元数据定义文件
├── SKILL.md # 技能详细说明文档
├── main.py # 技能主逻辑实现
├── requirements.txt # 依赖包列表
├── config/ # 技能配置文件
│ ├── default.yaml # 默认配置
│ └── production.yaml # 生产环境配置
├── resources/ # 资源文件
│ ├── templates/ # 模板文件
│ ├── data/ # 静态数据
│ └── schemas/ # 数据结构定义
├── tests/ # 单元测试
│ ├── test_main.py # 主逻辑测试
│ └── fixtures/ # 测试数据
├── docs/ # 技能文档
│ ├── API.md # API文档
│ └── examples/ # 使用示例
├── migrations/ # 数据库迁移脚本
├── logs/ # 日志配置
└── .skillignore # 忽略文件配置
3. Skill 核心文件介绍
3.1. SKILL.yaml(技能元数据)
模型可读的"技能身份证",供系统扫描、匹配、路由使用。
# 基本信息
name: "data_analysis"
version: "1.2.0"
description: "执行数据分析任务,包括数据清洗、统计分析和可视化"
category: "data_science"
tags: ["analysis", "statistics", "visualization"]
author: "Data Team <data-team@company.com>"
created_at: "2026-01-15T10:30:00Z"
updated_at: "2026-05-20T14:45:00Z"
# 能力声明
capabilities:
- data_cleaning
- statistical_analysis
- visualization_generation
- report_generation
# 输入输出规范
input_schema:
type: "object"
required: ["data_source", "analysis_type"]
properties:
data_source:
type: "string"
description: "数据源路径或连接字符串"
analysis_type:
type: "string"
enum: ["descriptive", "inferential", "predictive"]
parameters:
type: "object"
description: "分析参数"
output_schema:
type: "object"
properties:
results:
type: "object"
description: "分析结果"
visualizations:
type: "array"
items:
type: "string"
report_url:
type: "string"
# 执行配置
execution:
timeout: 300 # 5分钟超时
memory_limit: "1024MB"
cpu_limit: "2.0"
parallel_execution: false
# 依赖管理
dependencies:
skills:
- name: "data_loader"
version: ">=1.0.0"
- name: "visualization_helper"
version: ">=0.8.0"
external_packages:
- "pandas>=1.3.0"
- "matplotlib>=3.4.0"
- "scikit-learn>=0.24.0"
# 安全配置
security:
permissions:
- "read:files"
- "write:reports"
- "network:api_calls"
sandbox_enabled: true
audit_logging: true
# 部署配置
deployment:
environments:
- "development"
- "staging"
- "production"
auto_scaling:
min_replicas: 1
max_replicas: 10
target_cpu_utilization: 70
3.2. SKILL.md(技能详细说明)
人类可读的"操作手册",通过自然语言告诉 AI 具体怎么做。
# 数据分析技能 (data_analysis)
## 概述
本技能提供完整的数据分析能力,支持从数据加载、清洗到统计分析和可视化的全流程处理。
## 核心功能
- **数据清洗**:处理缺失值、异常值、重复数据
- **统计分析**:描述性统计、推断性统计、预测分析
- **可视化生成**:自动生成图表和报告
- **报告导出**:支持多种格式导出
## 使用场景
1. **业务分析**:销售趋势分析、用户行为分析
2. **科学研究**:实验数据分析、统计验证
3. **金融风控**:风险评估、异常检测
## 输入参数说明
| 参数 | 类型 | 必填 | 说明 | 示例 |
|------|------|------|------|------|
| data_source | string | ✓ | 数据源路径 | "/data/sales.csv" |
| analysis_type | string | ✓ | 分析类型 | "descriptive" |
| time_range | object | ✗ | 时间范围 | {"start": "2026-01-01", "end": "2026-12-31"} |
## 输出结果说明
```json
{
"results": {
"statistics": {
"mean": 125.6,
"median": 120.3,
"std_dev": 15.2
},
"insights": ["销售额呈现上升趋势", "周末销售高峰明显"]
},
"visualizations": [
"/reports/charts/trend_2026.png",
"/reports/charts/distribution.png"
],
"report_url": "/reports/analysis_20260522.html"
}
3.3. main.py(技能主逻辑实现)
技能的"大脑",所有计算逻辑写死在代码里,永不进上下文。
#!/usr/bin/env python3
"""
supply-chain-risk 主逻辑
所有计算公式写死在这里,不让模型猜
"""
import json
import sys
from dataclasses import dataclass
from typing import Optional
@dataclass
class RiskResult:
risk_score: float
level: str
action: str
supplier_id: str
confidence: float
def calculate_risk(delay_rate: float, sentiment: float) -> RiskResult:
"""
风险评分公式(写死,不可修改)
"""
risk_score = (delay_rate * 0.7) + (abs(sentiment) * 0.3)
if risk_score > 75:
level = "CRITICAL"
action = "必须生成预防性建议"
elif risk_score > 50:
level = "HIGH"
action = "建议生成改进方案"
else:
level = "LOW"
action = "无需特殊处理"
return RiskResult(
risk_score=round(risk_score, 2),
level=level,
action=action,
supplier_id="",
confidence=0.95
)
def main():
"""主入口"""
input_data = json.load(sys.stdin)
delay_rate = input_data.get("delay_rate", 0)
sentiment = input_data.get("sentiment", 0)
supplier_id = input_data.get("supplier_id", "UNKNOWN")
result = calculate_risk(delay_rate, sentiment)
result.supplier_id = supplier_id
print(json.dumps(result.__dict__, ensure_ascii=False))
if __name__ == "__main__":
main()
| 对比项 | 传统方式(Prompt 写公式) | main.py 方式 |
|---|---|---|
| 公式位置 | 写在 SKILL.md 里,进上下文 | 写在代码里,永不进上下文 |
| Token 消耗 | 描述公式 ~500 tokens | 0 tokens(只有结果 ~50 tokens) |
| 准确性 | 模型心算,经常算错 | Python 计算,100% 正确 |
| 可测试性 | 无法测试 | 单元测试覆盖 |
| 可复现性 | 每次不同 | 完全一致 |
3.4. requirements.txt(依赖包列表)
声明技能运行所需的 Python 依赖。
加载时机: Skill 安装时
Token 消耗: ~20 tokens(L1 加载)
# skills/supply-chain-risk/requirements.txt
requests>=2.31.0
pandas>=2.0.0
numpy>=1.24.0
pydantic>=2.0.0
| 作用 | 说明 |
|---|---|
| 依赖声明 | 系统安装技能时自动 pip install -r requirements.txt |
| 版本锁定 | 确保可复现性 |
| 沙箱隔离 | 每个 Skill 独立虚拟环境,不互相污染 |
3.5. config/(技能配置文件)
环境相关的配置,支持多环境切换。
加载时机: Skill 启动时读取
Token 消耗: ~100 tokens
skills/supply-chain-risk/config/
├── default.yaml -- 默认配置(开发/测试用)
└── production.yaml -- 生产配置(上线用)
3.5.1. default.yaml(默认配置)
# skills/supply-chain-risk/config/default.yaml
environment: "development"
# MCP 服务地址
mcp_servers:
enterprise_erp: "http://localhost:8001"
news_api: "http://localhost:8002"
# 调试开关
debug: true
log_level: "DEBUG"
# Token 预算
max_tokens: 5000 # 开发环境宽松
# 重试策略
retry:
max_attempts: 3
backoff_seconds: 1
3.5.2. production.yaml(生产配置)
# skills/supply-chain-risk/config/production.yaml
environment: "production"
# MCP 服务地址(生产环境)
mcp_servers:
enterprise_erp: "https://erp.company.com/api"
news_api: "https://news.company.com/api"
# 调试开关
debug: false
log_level: "INFO"
# Token 预算(生产环境严格)
max_tokens: 3000
# 重试策略(生产环境更激进)
retry:
max_attempts: 5
backoff_seconds: 2
3.6. resources/(静态资源)
技能运行所需的静态文件,按需加载。
skills/supply-chain-risk/resources/
├── templates/ -- 输出模板
├── data/ -- 静态数据
└── schemas/ -- 数据结构定义
3.7. templates/(格式化模板)
定义格式化模板。
<!-- resources/templates/risk_report.md -->
# 风险评估报告
## 供应商: {{supplier_name}}
## 风险评分: {{risk_score}} ({{level}})
## 延迟率: {{delay_rate}}
## 新闻情感: {{sentiment}}
## 建议: {{action}}
---
*生成时间: {{timestamp}}*
*置信度: {{confidence}}*
3.8. data/(静态数据)
存放静态数据,比如码表、映射表等。
resources/data/
├── risk_thresholds.json -- 风险阈值配置
├── supplier_list.csv -- 供应商清单
└── region_mapping.yaml -- 地区映射表
// resources/data/risk_thresholds.json
{
"critical": 75,
"high": 50,
"medium": 25,
"low": 0
}
3.9. schemas/(数据结构定义)
# resources/schemas/risk_result.yaml
type: object
required:
- risk_score
- level
- action
properties:
risk_score:
type: number
minimum: 0
maximum: 100
level:
type: string
enum: ["CRITICAL", "HIGH", "MEDIUM", "LOW"]
action:
type: string
supplier_id:
type: string
confidence:
type: number
minimum: 0
maximum: 1
| 作用 | 说明 |
|---|---|
| 数据校验 | AI 输出必须符合此结构 |
| 类型安全 | 防止 AI 输出非法格式 |
| 文档生成 | 可自动生成 API 文档 |
3.10. tests/(单元测试)
确保技能逻辑正确,可复现。
skills/supply-chain-risk/tests/
├── test_main.py -- 主逻辑测试
└── fixtures/ -- 测试数据
├── supplier_a.json
└── supplier_b.json
3.10.1. test_main.py(单元测试入口)
本地测试脚本。
# tests/test_main.py
import json
import subprocess
from main import calculate_risk
def test_risk_calculation():
"""测试风险计算公式"""
result = calculate_risk(delay_rate=0.15, sentiment=-0.3)
assert result.risk_score == pytest.approx(0.195)
assert result.level == "HIGH"
assert result.action == "建议生成改进方案"
def test_critical_threshold():
"""测试临界值"""
result = calculate_risk(delay_rate=0.8, sentiment=-0.5)
assert result.risk_score > 75
assert result.level == "CRITICAL"
def test_main_cli():
"""测试 CLI 接口"""
input_data = json.dumps({"delay_rate": 0.15, "sentiment": -0.3})
result = subprocess.run(
["python", "main.py"],
input=input_data,
capture_output=True,
text=True
)
assert result.returncode == 0
assert "risk_score" in result.stdout
| 作用 | 说明 |
|---|---|
| 逻辑验证 | 确保公式正确 |
| 回归测试 | 改代码后自动验证 |
| CI/CD 集成 | 每次提交自动运行 |
| Token 消耗 | 0 tokens(不进上下文) |
3.10.2. fixtures/ (单元测试数据)
单元测试数据。
// tests/fixtures/supplier_a.json
{
"supplier_id": "ABC123",
"name": "华东电子有限公司",
"delay_rate": 0.15,
"on_time_rate": 0.85,
"quality_score": 0.92
}
3.11. docs/(技能文档)
给使用者阅读的技能文档和示例。
skills/supply-chain-risk/docs/
├── API.md -- API 文档
└── examples/ -- 使用示例
├── basic.md
└── advanced.md
3.12. API.md(API说明)
# Supply Chain Risk API
## 获取风险评分
**Endpoint**: `python main.py --mode calculate`
**输入**:
```json
{
"delay_rate": 0.15,
"sentiment": -0.3,
"supplier_id": "ABC123"
}
输出:
{
"risk_score": 19.5,
"level": "HIGH",
"action": "建议生成改进方案",
"supplier_id": "ABC123",
"confidence": 0.95
}
3.13. examples/(使用示例)
模型参考示例。
<!-- docs/examples/basic.md -->
# 基础用法
## 场景:查询供应商风险
**用户输入**: "供应商 ABC123 风险怎么样"
**AI 执行**:
1. 匹配 `supply-chain-risk` Skill
2. 调用 `enterprise_erp.get_supplier_performance(ABC123)`
3. 调用 `news_api.search_news("ABC123 风险")`
4. 运行 `python main.py --mode calculate`
5. 按模板输出报告
**输出**:
```json
{
"risk_score": 72,
"level": "HIGH",
"action": "建议生成改进方案"
}
3.14. migrations/(数据库迁移脚本)
如果 Skill 需要持久化状态,用迁移脚本管理 Schema 变更。
skills/supply-chain-risk/migrations/
├── 001_create_risk_history.sql
├── 002_add_confidence_field.sql
└── 003_create_audit_log.sql
-- migrations/001_create_risk_history.sql
CREATE TABLE IF NOT EXISTS risk_history (
id SERIAL PRIMARY KEY,
supplier_id VARCHAR(50) NOT NULL,
risk_score FLOAT NOT NULL,
level VARCHAR(20) NOT NULL,
action TEXT,
created_at TIMESTAMP DEFAULT NOW()
);
| 作用 | 说明 |
|---|---|
| Schema 版本管理 | 每次变更可回滚 |
| 多环境同步 | 开发/测试/生产一致 |
| Token 消耗 | 0 tokens(不进上下文) |
3.15. logs/(日志配置)
配置 Skill 的日志输出。
skills/supply-chain-risk/logs/
├── config.yaml -- 日志配置
└── schema.json -- 日志结构定义
# logs/config.yaml
version: 1
handlers:
console:
level: INFO
format: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
file:
level: DEBUG
filename: "logs/skill.log"
max_size: "10MB"
backup_count: 5
// logs/schema.json
{
"type": "object",
"properties": {
"timestamp": { "type": "string" },
"skill_name": { "type": "string" },
"level": { "type": "string" },
"message": { "type": "string" },
"input": { "type": "object" },
"output": { "type": "object" },
"duration_ms": { "type": "number" }
}
}
| 作用 | 说明 |
|---|---|
| 日志级别控制 | 开发 DEBUG / 生产 INFO |
| 日志结构统一 | 便于分析和监控 |
| Token 消耗 | 0 tokens(不进上下文) |
3.16. skillignore(忽略文件配置)
类似 .gitignore,声明哪些文件不应被打包/加载。
# .skillignore
# 忽略测试文件
tests/
fixtures/
# 忽略日志
logs/
*.log
# 忽略临时文件
*.tmp
*.swp
# 忽略大文件(不进上下文)
resources/data/large_dataset.csv
# 忽略敏感文件
config/secrets.yaml
.env
4. Skills 根目录结构介绍
4.1. core 核心技能目录
skills/core/
├── authentication/ # 认证授权
├── logging/ # 日志管理
├── monitoring/ # 监控告警
├── caching/ # 缓存管理
├── error_handling/ # 错误处理
└── context_management/ # 上下文管理
4.2. domain 领域技能目录
skills/domain/
├── finance/ # 金融领域
│ ├── risk_assessment/ # 风险评估
│ ├── fraud_detection/ # 欺诈检测
│ └── portfolio_optimization/ # 投资组合优化
├── healthcare/ # 医疗健康
│ ├── diagnosis_support/ # 诊断辅助
│ ├── patient_monitoring/ # 患者监护
│ └── treatment_planning/ # 治疗规划
├── retail/ # 零售电商
│ ├── inventory_management/ # 库存管理
│ ├── customer_segmentation/ # 客户分群
│ └── sales_forecasting/ # 销售预测
└── manufacturing/ # 制造业
├── quality_control/ # 质量控制
├── predictive_maintenance/ # 预测性维护
└── supply_chain_optimization/ # 供应链优化
4.3. tools 工具技能目录
skills/tools/
├── database/ # 数据库操作
│ ├── sql_executor/ # SQL执行器
│ ├── nosql_connector/ # NoSQL连接器
│ └── data_migration/ # 数据迁移
├── api/ # API集成
│ ├── rest_client/ # REST客户端
│ ├── graphql_client/ # GraphQL客户端
│ └── api_gateway/ # API网关
├── file_system/ # 文件系统
│ ├── file_processor/ # 文件处理器
│ ├── cloud_storage/ # 云存储
│ └── document_parser/ # 文档解析
└── communication/ # 通信工具
├── email_sender/ # 邮件发送
├── messaging/ # 消息通知
└── voice_call/ # 语音通话
4.4. config 配置文件目录
4.4.1. 全局配置 (skills/config/global.yaml)
# 系统配置
system:
max_concurrent_skills: 50
default_timeout: 300
cache_ttl: 3600
log_level: "INFO"
# 安全配置
security:
require_authentication: true
audit_logging: true
data_encryption: true
rate_limiting:
requests_per_minute: 100
burst_limit: 10
# 资源配置
resources:
default_memory: "512MB"
default_cpu: "1.0"
max_memory_per_skill: "4096MB"
storage_quota: "100GB"
# 扩展配置
extensions:
enabled:
- "monitoring"
- "caching"
- "distributed_execution"
monitoring:
metrics_endpoint: "http://metrics:8080"
alert_thresholds:
error_rate: 0.1
latency: 2000
caching:
redis_host: "redis-cache"
redis_port: 6379
4.4.2. 环境配置 (skills/config/environments/)
skills/config/environments/
├── development.yaml # 开发环境
├── staging.yaml # 预发布环境
├── production.yaml # 生产环境
└── testing.yaml # 测试环境
production.yaml示例:
environment: "production"
debug_mode: false
performance_optimization: true
resource_scaling:
auto_scale: true
min_replicas: 3
max_replicas: 20
security_hardening:
network_isolation: true
data_masking: true
compliance_mode: "strict"
monitoring:
detailed_metrics: true
alert_channels:
- "slack:#alerts"
- "email:ops-team@company.com"
4.5. templates 模板目录结构
skills/templates/
├── skill_template/ # 基础技能模板
│ ├── SKILL.yaml.template
│ ├── SKILL.md.template
│ ├── main.py.template
│ └── requirements.txt.template
├── domain_skill_template/ # 领域技能模板
├── tool_skill_template/ # 工具技能模板
├── micro_skill_template/ # 微技能模板
└── composite_skill_template/ # 复合技能模板
4.6. scripts 构建和部署脚本
skills/scripts/
├── build.sh # 构建脚本
├── deploy.sh # 部署脚本
├── test.sh # 测试脚本
├── validate.sh # 验证脚本
├── package.sh # 打包脚本
├── migrate.sh # 迁移脚本
└── monitor.sh # 监控脚本
4.7. tests 测试目录结构
skills/tests/
├── unit/ # 单元测试
├── integration/ # 集成测试
├── performance/ # 性能测试
├── security/ # 安全测试
├── e2e/ # 端到端测试
└── fixtures/ # 测试数据
├── sample_data/ # 样本数据
├── mock_responses/ # 模拟响应
└── test_config/ # 测试配置
五、Skills 完整工作流程
Skills 的工作流程从决策层开始主要分为5个核心阶段:

1. 触发阶段(Trigger Phase)
- 输入接收
- 决策层发送结构化任务请求(包含意图、参数、上下文)
- 接收外部事件触发(定时任务、系统事件、API回调)
- 技能匹配
- 基于意图和参数匹配预注册的Skills
- 优先级评估:选择最合适的技能实例
- 权限验证:检查用户/系统是否有权调用该技能
- 状态初始化
- 创建技能执行上下文
- 分配唯一执行ID
- 设置超时和资源限制
2. 准备阶段(Preparation Phase)
- 参数解析
- 验证输入参数的完整性和合法性
- 类型转换和格式标准化
- 填充默认值,处理可选参数
- 资源准备
- 检查依赖工具的可用性
- 预分配计算资源(内存、CPU、网络)
- 加载必要的数据缓存和配置
- 上下文构建
- 合并全局上下文和局部上下文
- 准备业务规则和策略配置
- 初始化状态管理器
3. 执行阶段(Execution Phase)
-
工具协调
- 按业务逻辑顺序调用底层Tools
- 参数映射:将技能参数转换为工具参数
- 处理工具间的依赖关系和数据流
-
业务逻辑处理
- 执行核心业务计算和数据处理
- 应用领域规则和业务策略
- 处理中间状态和临时数据
-
异常处理
- 捕获和分类执行异常
- 应用重试策略(指数退避、有限重试)
- 执行降级或回滚机制
- 记录详细错误日志
4. 监控阶段(Monitoring Phase)
- 实时监控
- 跟踪执行进度和性能指标
- 监控资源使用情况(CPU、内存、IO)
- 检测异常行为和性能瓶颈
- 质量检查
- 验证中间结果的正确性
- 检查数据完整性和一致性
- 评估业务规则的合规性
- 动态调整
- 根据监控数据动态调整执行策略
- 优化资源分配
- 触发自动修复机制
5. 返回阶段(Return Phase)
- 结果处理
- 标准化输出格式
- 转换工具结果为业务对象
- 过滤敏感信息,确保合规
- 状态更新
- 持久化执行结果和状态
- 更新技能元数据(性能统计、使用频率)
- 同步业务系统状态
- 反馈返回
- 生成结构化响应(成功/失败/部分成功)
- 返回结果数据和元信息
- 传递执行指标供决策层优化
举个例子
用户请求:"分析2024年Q1销售数据"
1. **触发阶段**
→ 决策层识别"数据分析"意图
→ 匹配"sales_analysis_skill"
→ 验证用户有销售数据权限
2. **准备阶段**
→ 解析参数:time_range="2024-Q1"
→ 检查数据库连接和分析工具
→ 加载销售数据schema
3. **执行阶段**
→ 调用database_tool获取原始数据
→ 调用data_processing_tool清洗数据
→ 调用analysis_tool计算关键指标
→ 生成图表和统计摘要
4. **监控阶段**
→ 监控查询执行时间(<30s)
→ 检查数据完整性(100%记录处理)
→ 验证计算结果合理性
5. **返回阶段**
→ 格式化为JSON报告
→ 更新用户分析历史
→ 返回包含图表URL的结构化结果
六、Skills在Agent架构中的定位
在现代企业级AI Agent架构设计中,四层架构已成为主流范式,该架构采用清晰的职责分离,每层专注于特定功能。而Skills(技能) 作为架构中的核心能力载体,在其中扮演着承上启下的关键角色。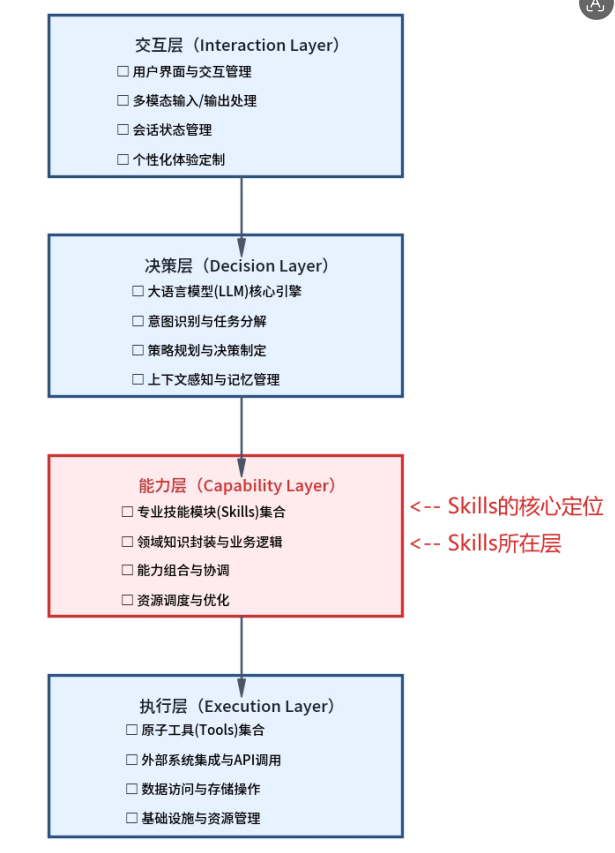
七、Skills 与 MCP 的区别
Skills 和 MCP 不是替代关系,是互补协作关系:
- Skills 是"能力封装",解决的是 AI 知道怎么用工具完成任务的问题。
- MCP 是"连接协议",解决的是 AI 能不能连上外部工具的问题。
MCP 能做什么?
MCP 提供的能力:
1. 定义工具: "我有一个叫 get_weather 的工具,参数是 city"
2. 注册工具: 把工具注册到 Agent 的工具列表中
3. 调用工具: Agent 说"调用 get_weather('北京')",MCP 负责转发并返回结果
4. 管理连接: 维护与外部系统的长连接、认证、重试
MCP 不管的事情:
- 不管调用顺序
- 不管什么时候该调用
- 不管结果怎么处理
- 不管输出什么格式
Skills 能做什么?
Skills 提供的能力:
1. 角色设定: "你是天气分析专家"
2. 执行流程: "Step1: 调 get_weather → Step2: 如果下雨 → Step3: 调 get_traffic"
3. 逻辑判断: "如果降雨量 > 50mm,触发预警"
4. 约束控制: "Max_Token_Usage: 3000,超时重试 3 次"
5. 输出格式: "按 templates/weather_report.md 模板输出 JSON"
6. 错误处理: "API 超时 → 重试 1 次 → 还超时 → 报错"
Skills 不管的事情:
- 不负责连接外部系统(这是 MCP 的活)
- 不负责工具的底层实现(这是 MCP Server 的活)
MCP与Skills不同维度对比
| 维度 | MCP | Skills |
|---|---|---|
| 本质 | 标准化连接协议 | 可复用的能力封装单元 |
| 解决的问题 | AI 能访问什么外部工具和数据 | AI 如何按流程使用这些工具完成任务 |
| 类比 | USB 接口(让设备能插上电脑) | 驱动程序 + 应用软件(让设备能干活) |
| 内容 | 工具定义、API 调用接口、参数 schema | 角色设定、执行流程、约束条件、输出模板、计算逻辑 |
| 上下文占用 | 工具定义始终在上下文(约 200 tokens/个) | 渐进式加载,按需注入(约 3000 tokens/次) |
| 更新方式 | 改 MCP Server 代码,重新注册 | 改 SKILL.md 文件,重新扫描 |
| 使用者 | Agent Runtime(底层执行引擎) | Agent 决策层(上层智能编排) |
| 粒度 | 单个函数/API 调用 | 完整工作流(多步骤 + 多工具 + 逻辑判断) |
| 可测试性 | 工具本身可测试 | 整个工作流可测试(单元测试 + 集成测试) |
| 版本管理 | 工具版本号 | Skill 语义化版本号(支持回滚) |
| 安全控制 | 工具级别权限 | Skill 级别白名单(allowed-tools) |
八、Skills 与 Prompt 的区别
Prompt 是告诉 AI"你想要什么",Skills 是告诉 AI"你怎么做到"。
| 维度 | Prompt | Skills |
|---|---|---|
| 本质 | 需求描述,告诉 AI"你想要什么" | 操作手册,告诉 AI"你怎么做到" |
| 类比 | 告诉员工"帮我做个方案" | 给员工一份"方案撰写 SOP" |
| 解决的问题 | 传递任务意图 | 传递执行方法 |
| AI 的角色 | 自由发挥的顾问 | 按流程执行的专家 |
| 可控性 | 低,每次输出可能不一样 | 高,每次输出一致 |
| Token 效率 | 低,所有知识都塞进上下文 | 高,渐进式加载,按需注入 |
| 上下文占用 | 全部内容进上下文,token 爆炸 | 只在触发时加载,用完即收 |
| 更新方式 | 每次改 Prompt 重新发 | 改 SKILL.md 文件,Agent 自动扫描 |
| 适用场景 | 一次性任务、简单问答 | 重复执行的专业流程 |
| 维护成本 | 高,每次都要重新写 Prompt | 低,写一次,反复调用 |
| 知识与流程 | 知识和流程混在一起写 | 知识写在 references/,流程写在正文 |
| 错误处理 | 靠 Prompt 里写"如果出错怎么办" | 专门的 Gotchas 章节 + 异常处理模块 |
| 输出格式 | 靠 Prompt 描述"请按 XX 格式输出" | 专门的输出格式模块 + 模板文件 |
| Token 量级 | 500-50000 tokens(全部进上下文) | 3000 tokens(触发时才加载) |
| 复用性 | 差,换个任务要重写 | 强,一个 Skill 可被多次调用 |
| 谁来写 | 用户(每次对话时写) | 开发者(提前写好,Agent 自动匹配) |
| 触发方式 | 用户主动发送 | Agent 根据 description 语义匹配自动触发 |
| 核心价值 | 灵活,适合探索性任务 | 稳定,适合专业性任务 |
| 典型例子 | “帮我写一篇周报” | SKILL.md 定义:Step1 读数据 → Step2 算指标 → Step3 按模板输出 |
| 失败原因 | 描述不清楚,AI 理解偏了 | 流程写死了,AI 不会自由发挥导致跑偏 |
| 能力边界 | 取决于 Prompt 写得多好 | 取决于 Skill 写得多完整 |
| 团队协作 | 每人写自己的 Prompt,无法共享 | 团队共建 Skill 库,统一标准 |
| 版本管理 | 无法版本化 | 支持语义化版本号,可回滚 |
| 安全控制 | 靠 Prompt 里写"不要做 XX" | allowed-tools 白名单 + 约束条件 + Human_In_The_Loop |
九、Skills 未来
根据最新行业报告,2026年被公认为"Skills爆发元年"。AI技术正从"对话助手"全面迈向"行动派",Skills成为AI Agent能力分发的主流范式。
Skills不是技术革命,而是协作革命。它重新定义了人与AI的关系:从人指挥AI到AI自动跑,从单次沟通到长期记忆。掌握Skills Engineering,就是掌握了未来人机协同的核心竞争力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)