从“逐字朗读”到“一眼看穿”:Transformer 如何重塑了我们身边的 AI?
手机输入法为什么能预知你的下一句话?这要从7年前的一场“革命”说起
当你今天打开手机输入法,它能提前猜到你下一句话;
当你向 OpenAI 的 ChatGPT提问,它能像真人一样回答;
当短视频平台能自动生成字幕、翻译、配音,甚至“理解”视频内容时——
你可能没有意识到,这些能力背后,几乎都站着同一个名字:
Transformer
它诞生于 2017 年,一篇论文彻底改变了 AI 世界:
《Attention Is All You Need》
很多人把这篇论文称作:
“AI 时代的《蒸汽机说明书》。”
因为它不仅改进了 AI,而是直接换掉了 AI 的“大脑结构”。
而在它出现之前,AI 其实远没有今天这么聪明。
一、Transformer 出现前:AI 像一个“逐字朗读”的人
在 Transformer 之前,主流语言模型使用的是:RNN(循环神经网络)及其变体(如 LSTM)。
你可以把它想象成:一个必须 ”按顺序读书” 的读者
比如它读一句话:
“今天北京下雨了,所以我带了伞。”
RNN 的阅读方式是:
- 先看 “今天”
- 再看 “北京”
- 再看 “下雨”
- 再看 “所以”
- 最后才知道 “带了伞”
它不能跳读,也不能 “一眼看完整句话” 。
就像有人拿着纸条,一个字一个字念给你听。
RNN 的两大“痛苦”
1. 它真的很慢:单线程的瓶颈
RNN 有一个致命特点:
前一个词没处理完,下一个词就不能开始。
这意味着:
- 无法 并行 计算
- 无法充分利用 GPU
- 训练超长文本 效率极低
这就像:
单线程下载
必须一个文件下完,才能下另一个。
而现代 AI 需要学习的数据是什么?
- 整个互联网
- 几十亿网页
- 海量书籍
- 视频字幕
- 代码仓库
RNN 根本“吃不下”。
2. 它的记忆力很差:传话游戏的失真
更麻烦的是,RNN 很容易忘记前面说了什么。
比如一句很长的话:
“小时候在东北农村生活的那个戴眼镜的男孩,后来成为了科学家。”
当 RNN 读到最后的“科学家”时,
它可能已经忘了:
“到底是谁成为了科学家?”
这叫 长距离依赖问题 。距离越远,信息越容易丢失,也就是 “失真” 。
就像小时候玩的“传话游戏”:
第一个人说:
“下课我想带你吃饭”
传最后可能变成:
“咱俩实在不行就散”
但后来研究人员也努力补救。
他们发明了:
- LSTM (长短期记忆网络)
- GRU (门控循环单元)
本质上:
给 RNN 加了一个“记事本”。
它们确实让 AI 更能“记住东西”,但它仍然无法解决 “速度慢” 和 “难以并行” 的根本缺陷。
于是,整个行业都在等待一个彻底不同的新思路。然后,Transformer 出现了。
二、Transformer:AI 第一次拥有“上帝视角”
Transformer 的核心思想其实非常简单:不再一步一步读,而是“一眼看全局”
如果 RNN 像一个逐字阅读的人
那么 Transformer 更像一个把整本书摊在桌上同时阅读的人
它可以:
- 同时看到所有词
- 同时分析所有关系
- 同时决定重点在哪里
这就是 Attention(注意力机制)
Attention:AI 的“聚光灯”
想象你参加一个嘈杂的聚会。房间里有很多人在聊天,但当有人突然提到你的名字时,你会立刻把注意力转移到那个声音上。
这就是注意力。人脑不会平均处理所有信息,我们会自动聚焦关键信息。Transformer 模仿的正是这种机制。
三、真正改变世界的核心:Self-Attention(自注意力)
这是 Transformer 最革命性的地方。
假设模型看到一句话:
“猫坐在垫子上。”
Transformer 不会按顺序慢慢理解(猫 → 坐 → 垫子)。
它会瞬间计算所有词之间的关系:
- “猫”和“坐”关系很强(主谓)。
- “坐”和“垫子”关系很强(动宾)。
- “猫”和“垫子”也有间接关系。
模型会自动给这些关系 打分 。这就像一个超级聪明的大脑,它不是在死记硬背顺序,而是在理解**“谁和谁有关联”**。
那个著名公式,其实没那么可怕
论文里的核心公式是:
Attention(Q,K,V)=softmax(QKTdk)V Attention(Q,K,V)=softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
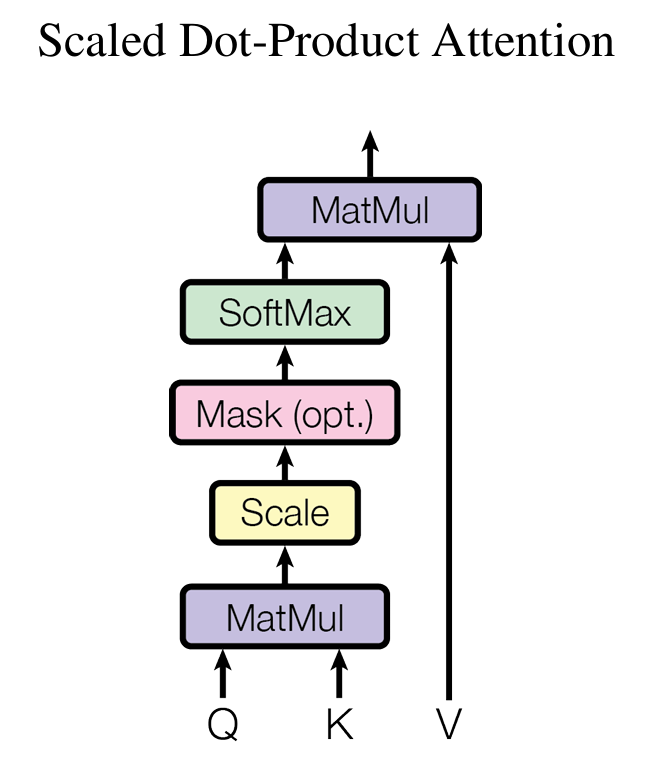
翻译成人话其实很简单:“计算每个词对其他词的重要性(相关性)。”
你甚至可以把它理解成一个 “关系评分系统” 。Transformer 的聪明,正来自于它能同时观察整个句子里的关系网络。
四、Transformer 为什么突然“快到离谱”?
因为它彻底抛弃了 Recurrent(循环)。
RNN 像是多米诺骨牌,必须一张推倒另一张(顺序依赖)。
Transformer 摒弃了这种结构,这意味着:可以完全并行计算。
-
RNN:一个词一个词处理
-
Transformer:所有词同时处理
这就像:
| 技术 | 类比 |
|---|---|
| RNN | 像一个人搬砖,搬完这块才能搬下一块。 |
| Transformer | 像一百个人同时搬砖 |
结果当然是 速度暴涨 。这也是为什么 GPT 能在几天内“读完”整个互联网,让大模型时代的到来成为可能。
五、Transformer 怎么知道“顺序”?
很多人会疑惑:
“既然它是同时处理,那它怎么知道谁在前谁在后?”
答案是:Position Encoding(位置编码)
你可以理解成给每个词贴了一个“座位号”
比如:
| 词 | 位置 |
|---|---|
| 我 | 1 |
| 爱 | 2 |
| 你 | 3 |
论文中使用了正弦波函数来编码位置信息。这样,即使模型同时看到所有词,它依然知道“我”在“爱”前面,“爱”在“你”前面。
但本质就是:
“给语言增加空间感。”
六、为什么说 Transformer 是“降维打击”?
因为它几乎全面碾压了 RNN。
RNN 的信息传递:
词1 → 词2 → 词3 → 词4 → 词5
如果词1想影响词5,必须经过4次传递,信息极易丢失。
Transformer 的信息传递:
更像这样:
所有词彼此相连
无论距离多远,词1可以直接“告诉”词5。这就是 Self-Attention 的威力,让长文本理解和翻译质量暴涨。
七、2017 年,Transformer 直接打爆排行榜
论文发布后的实验结果震惊了所有人。在 WMT 2014 英德翻译任务中:
| 模型 | BLEU 分数 (翻译质量) | 训练成本 |
|---|---|---|
| 之前的最佳模型 (RNN集成) | 26.3 | 极高 |
| Transformer (单模型) | 28.4 | 极低 |
别小看这 2 分,在 NLP 领域这是刷新世界纪录级别的提升。更夸张的是,它还更便宜、更快。整个行业瞬间意识到:“未来属于 Transformer。”
八、没有 Transformer,就没有今天的大模型
今天你熟悉的几乎所有 AI 巨头,背后都建立在 Transformer 架构之上:
- GPT-4
- Claude
- Gemini
- BERT
- Whisper
它已经不是一种“模型”。而是 AI 时代的基础设施 。
九、Transformer 不只会“读文字”
更可怕的是,研究人员后来发现 Transformer 不仅能处理文字,还能处理:
- 图像
- 音频
- 视频
- DNA
- 蛋白质结构
- 机器人动作
于是:
- Vision Transformer(ViT)出现了
- 多模态模型出现了
- AI 视频生成出现了
Transformer 开始从“语言模型”进化成通用信息处理架构,打通了文字、图像、声音的壁垒。
十、但 Transformer 也不是完美的
虽然它很强。但它也有一个巨大缺点:太耗算力(吃显存)。
因为它需要计算 “所有词和所有词之间的关系” 。
如果文本长度翻倍,计算量会呈平方级暴涨( n2n^2n2 )
这也是为什么:
- 大模型训练越来越贵
- GPU 成为“新石油”
- AI 公司疯狂建设数据中心
十一、2026 年的新方向:后 Transformer 时代正在萌芽
到了 2026 年。研究者已经开始思考:
“有没有比 Transformer 更高效的架构?”
于是一些新名字开始出现:
- Mamba
- RetNet
- RWKV
- Hybrid State Space Models
它们试图做到:
- 保留 Transformer 的理解能力
- 同时减少算力消耗
也许未来几年AI 世界还会再次经历一次“架构革命”。但至少到今天Transformer 依然是王者。
十二、真正伟大的,不只是技术
回头再看 2017 年那篇论文。
最令人震撼的,其实不是公式。
而是那个大胆的想法:
“既然循环这么麻烦,为什么不干脆扔掉它?”
于是 Vaswani 和他的团队做了一件看似疯狂的事,他们删掉了整个 RNN。只留下Attention。结果,他们改写了整个 AI 历史。
结语:AI 为什么突然变聪明了?
因为 AI 开始学会了一件更像“人类”的事情:不再机械记忆顺序 ,而是主动寻找关联。
RNN 的时代像是:
“死记硬背。”
Transformer 的时代更像:
“理解上下文。”
而这,正是今天大模型真正聪明的原因。
所以下一次,当你惊叹 AI 居然能:
- 写代码
- 生成图片
- 做翻译
- 理解视频
- 与人自然聊天
别忘了那个改变世界的瞬间:
人震撼的,其实不是公式。
而是那个大胆的想法:
“既然循环这么麻烦,为什么不干脆扔掉它?”
于是 Vaswani 和他的团队做了一件看似疯狂的事,他们删掉了整个 RNN。只留下Attention。结果,他们改写了整个 AI 历史。
结语:AI 为什么突然变聪明了?
因为 AI 开始学会了一件更像“人类”的事情:不再机械记忆顺序 ,而是主动寻找关联。
RNN 的时代像是:
“死记硬背。”
Transformer 的时代更像:
“理解上下文。”
而这,正是今天大模型真正聪明的原因。
所以下一次,当你惊叹 AI 居然能:
- 写代码
- 生成图片
- 做翻译
- 理解视频
- 与人自然聊天
别忘了那个改变世界的瞬间:
“Attention Is All You Need.”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)