一个 Token 值多少钱?我终于搞懂了大模型定价的底层逻辑
一个 Token 值多少钱?我终于搞懂了大模型定价的底层逻辑
作者按:最近豆包在 App Store 上线了三档付费订阅,最低每月 68 元,最高每月 500 元。我盯着这个价格表想了很久——这个数字是怎么来的?凭感觉定的?还是有什么硬道理?
正好看到一期硬核播客,Dwarkesh Patel 请来了 AI 芯片创业公司 MatX 的 CEO 莱纳·波普(Reiner Pope),用 7 个方程,把 Token 从生成到计费的整条链路讲得明明白白。
莱纳·波普来头不小。他在谷歌做过 PaLM 大模型的推理效率负责人,深度参与了 TPU v5e 的设计,个人持有 11 项 AI 芯片专利。今年 2 月,MatX 完成了 5 亿美元 B 轮融资,领投方之一是量化巨头 Jane Street。
这篇文章,我把这期两小时的黑板课浓缩成你 10 分钟能读完的版本。

GPU 在干什么?
你发出一条消息,到大模型吐出回复,中间到底发生了什么?
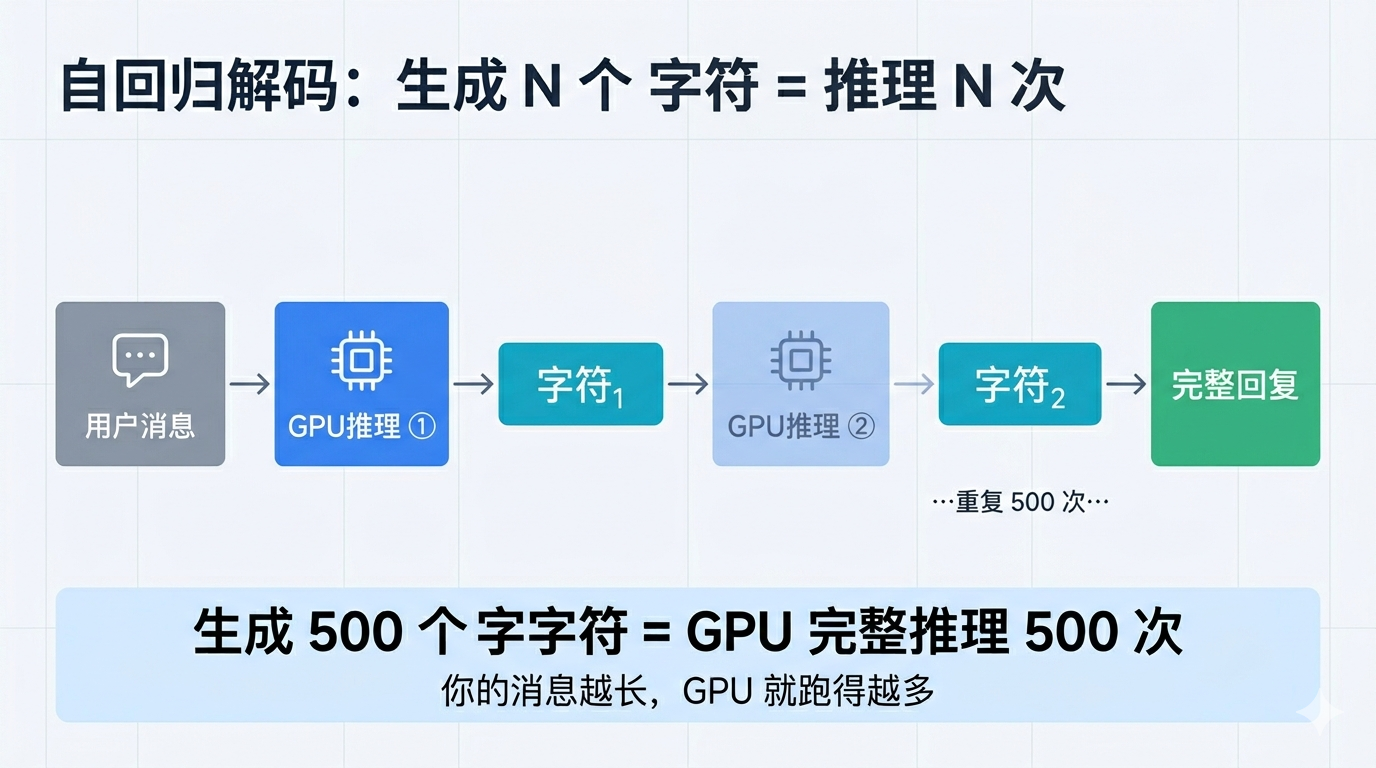
大模型生成回复的方式,是一个字一个字往外蹦的。技术上叫「自回归解码」——每生成一个新 Token,模型都要完整跑一遍前向传播,看看之前生成的所有内容,再决定下一个 Token 是什么。
换句话说,你让 Claude 输出一段 500 个 Token 的回答,GPU 就要老老实实跑 500 次完整的推理。
那每跑一次,要多长时间?
莱纳·波普用了一个框架,叫 Roofline 分析。核心只有一个公式:
T ≥ max(T_内存, T_计算)
生成一个 Token 的总耗时,由内存读取时间和计算时间中更慢的那个决定。
注意,是取最大值,不是相加。
这意味着什么?意味着两者中有一个成为瓶颈,另一个再快也没用。就像一条生产线,速度最慢的那道工序决定了整条线的产能。
两个瓶颈,一个临界点
先说计算瓶颈。
大模型的核心运算是矩阵乘法。但这里有个容易被误解的地方——每次推理,GPU 并不需要用到模型的全部参数。
以 DeepSeek V3 为例,总参数是 671 亿,但处理每个 Token 时实际只激活了大约 37 亿参数。模型内置了 256 个「专家模块」,每次只有极少数被调用。这种架构叫 MoE(混合专家),激活参数量与总参数量的比值叫稀疏度,DeepSeek V3 约为 8。
计算耗时的公式就是:
T_计算 = batch × 活跃参数 / FLOPS
batch 是同时处理的用户数,FLOPS 是芯片的算力。
再说内存瓶颈。
GPU 最快的存储叫 HBM(高带宽内存),紧贴芯片,速度远高于普通内存。但即便如此,把模型参数从 HBM 读进计算单元,依然要花时间。
内存耗时有两部分:
- 读取模型权重:固定开销,不管同时服务 1 个用户还是 1000 个,权重都要完整读一遍。
- 读取 KV 缓存:每生成一个新 Token,模型需要回头看之前所有 Token 的「记忆」(键值缓存),这部分随上下文越来越长。
公式是:
T_内存 = 总参数/带宽 + batch × 上下文长度 × 每Token字节数/带宽
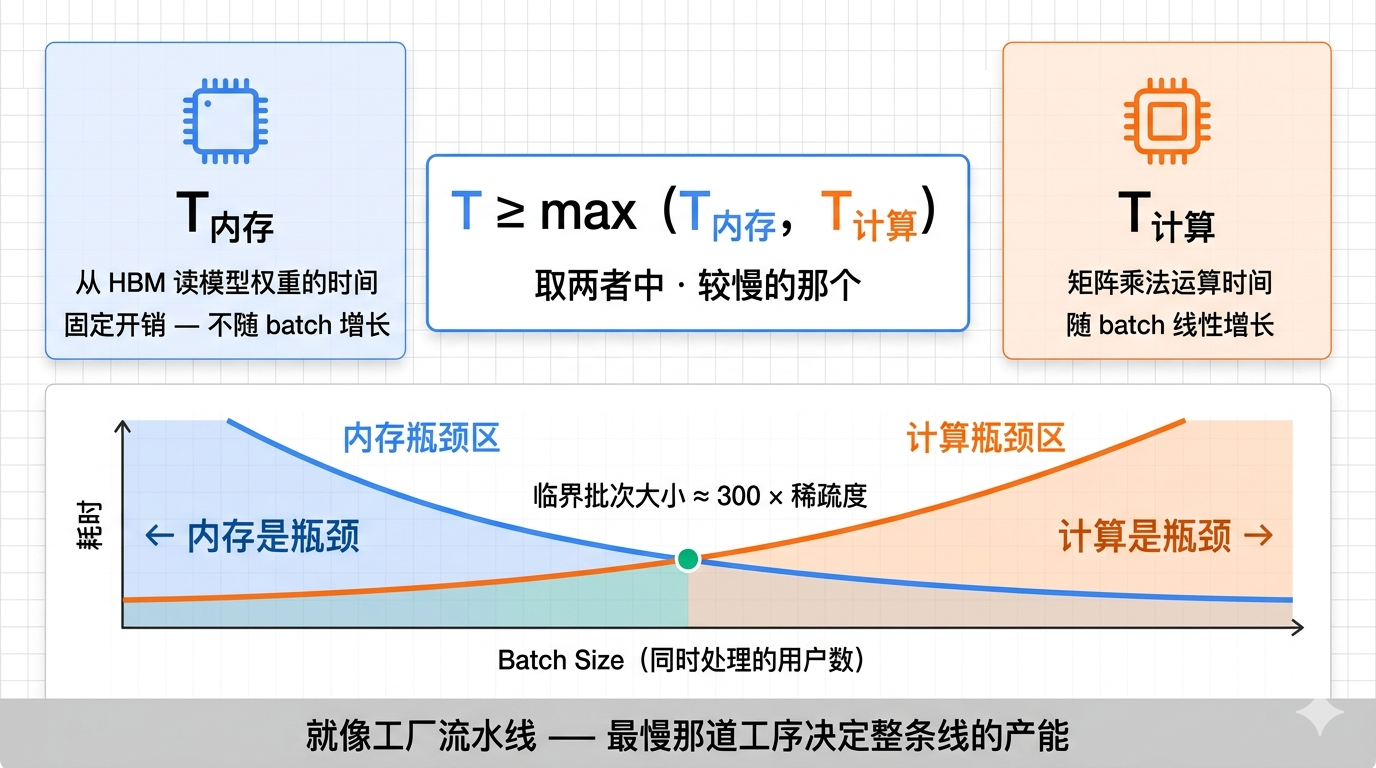
把计算耗时和内存耗时画成两条曲线,随着 batch 增大,它们会在某个点交汇。
- 交汇点左边:内存是瓶颈
- 交汇点右边:计算是瓶颈
推理延迟的物理下限,就是把模型全部参数从 HBM 读一遍的时间。
以英伟达最新的 Vera Rubin GPU 为例:288GB HBM ÷ 约 20TB/s 读取速度 ≈ 15 毫秒。实际生成单个 Token 大约需要 20 毫秒。
Batch Size:成本的核心杠杆
你调用 Claude 或 GPT 的 API,你以为你独占了一块 GPU?
当然不是。你的请求和成百上千个其他用户的请求打包在一起,同时完成一次推理。
这就是 batch size,同一批次处理的用户数量。
单 Token 成本的公式极其简洁:
单Token成本 = T / batch
这个公式背后藏着一个非常关键的机制:权重读取是固定开销,可以被 batch 摊薄;KV 缓存是个人专属,无法被摊薄。
举个例子。不管 GPU 同时服务 1 个用户还是 2000 个用户,它都要把完整的模型权重读一遍——这就好比开一趟公交车,不管坐满没有,油钱都得花。坐的人越多,每人分摊的油钱就越少。
但你的对话历史(KV 缓存)是你专属的,别人用不到,没法分摊。这就是单 Token 成本的绝对下限。
那 batch 越大越好?
有个最优点。超过这个点,继续增加并发反而没用——计算已经成为瓶颈了,再怎么等人上车,火车也没法开更快。
临界批次大小的计算公式是:
临界批次大小 ≈ FLOPS/内存带宽 × 总参数/活跃参数 ≈ 300 × 稀疏度
其中有一个硬件常数:在 FP4 精度下,FLOPS/内存带宽 ≈ 300,这个值在英伟达 A100 到 B100 多代 GPU 上都基本稳定。
以 DeepSeek V3 的稀疏度 8 为例:临界批次大小约为 2400。
更让人吃惊的是,这个临界点和模型本身的大小完全无关,只取决于芯片特性和模型稀疏度。

Claude Code 为什么贵?
现在可以直接回答这个问题了。
Claude Code 的快速模式比慢模式贵 6 倍。为什么?
快速模式为了低延迟,batch size 保持得比较小——公交车不等人满就发车。权重读取成本没被充分摊薄,每个用户分摊的更多,所以贵。
那慢模式为什么也不能再降价?
因为一旦 batch size 大到临界点,计算已经是瓶颈了。继续增加并发、让更多人等待,也降不了那部分「个人专属」的 KV 缓存成本。成本已经到底了。
KV 缓存:唯一无法被摊薄的开销
KV 缓存是大模型推理里最顽固的存在。
不管你怎么增大 batch,KV 缓存都是个人专属的,没法分摊。不管你怎么增加流水线阶段(跨机架部署),KV 缓存的单 GPU 占用也不会下降——因为多一个阶段,就需要多维护一份微批次的 KV 缓存,刚好抵消掉。
这就是为什么 DeepSeek 的推理方案主要靠专家并行,几乎不做流水线并行。

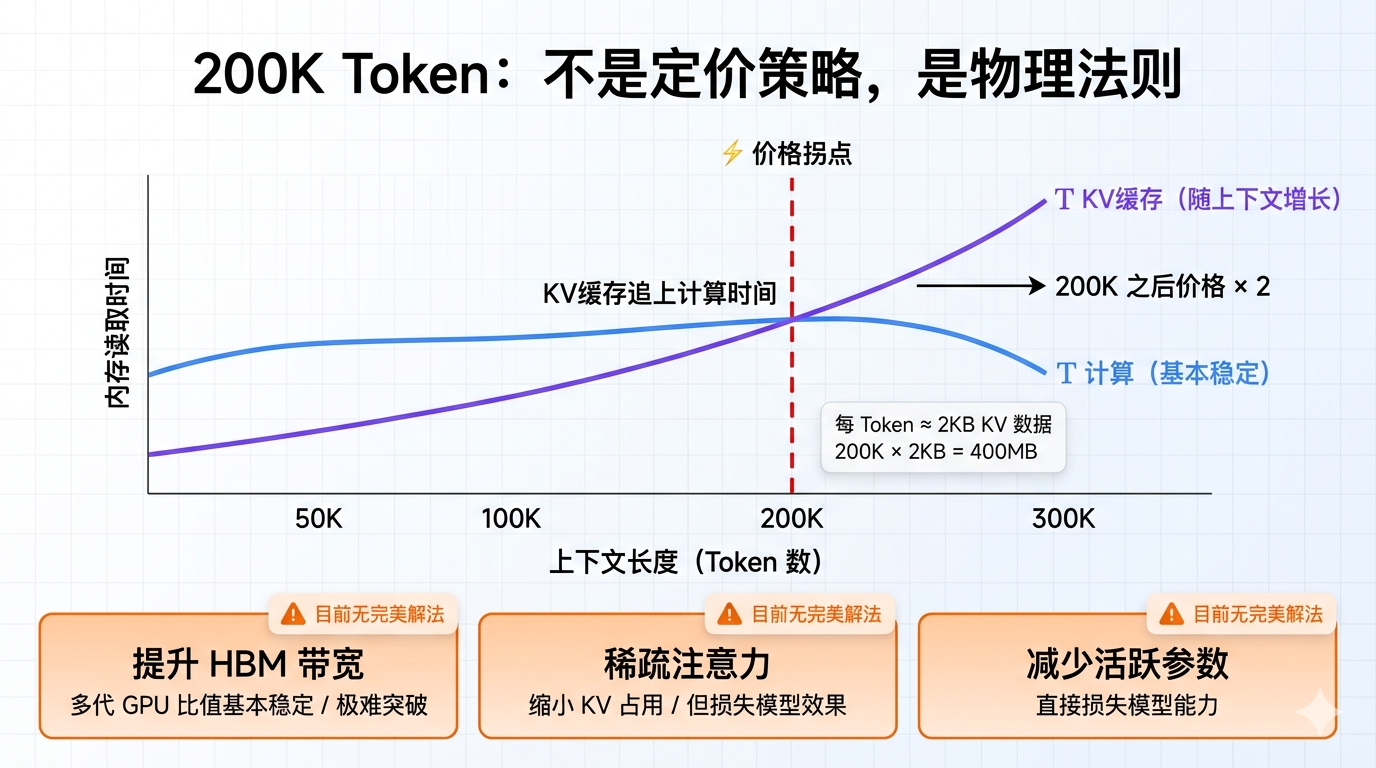
为什么上下文 200K 是个坎?
你有没有注意到,Gemini 2.5 Pro 在上下文超过 200K Token 之后,价格直接翻倍?
这不是 Google 随便定的价格。这是硬件决定的物理临界点。
根据第六个方程:
每Token字节数 = 活跃参数 / (FLOPS/带宽 × 上下文长度)
代入行业通用参数(活跃参数约 1000 亿、FLOPS/带宽比值约 300),算出每个 Token 在 KV 缓存里占用约 2KB。
当上下文达到 200K Token,KV 缓存的内存读取时间正好追上计算时间——内存从此成为新瓶颈,成本开始加速上升,价格自然也跟着涨。
想突破这个 200K 的限制,只有三条路:
- 让 HBM 带宽增速超过算力增速——但这个比值多代 GPU 都基本稳定,很难改;
- 缩小每个 Token 的 KV 缓存占用——稀疏注意力可以做,但会损失模型效果;
- 减少活跃参数——直接损失模型能力。
目前三条路都有硬天花板。莱纳·波普坦言没有完美解法。
机架:MoE 的物理边界
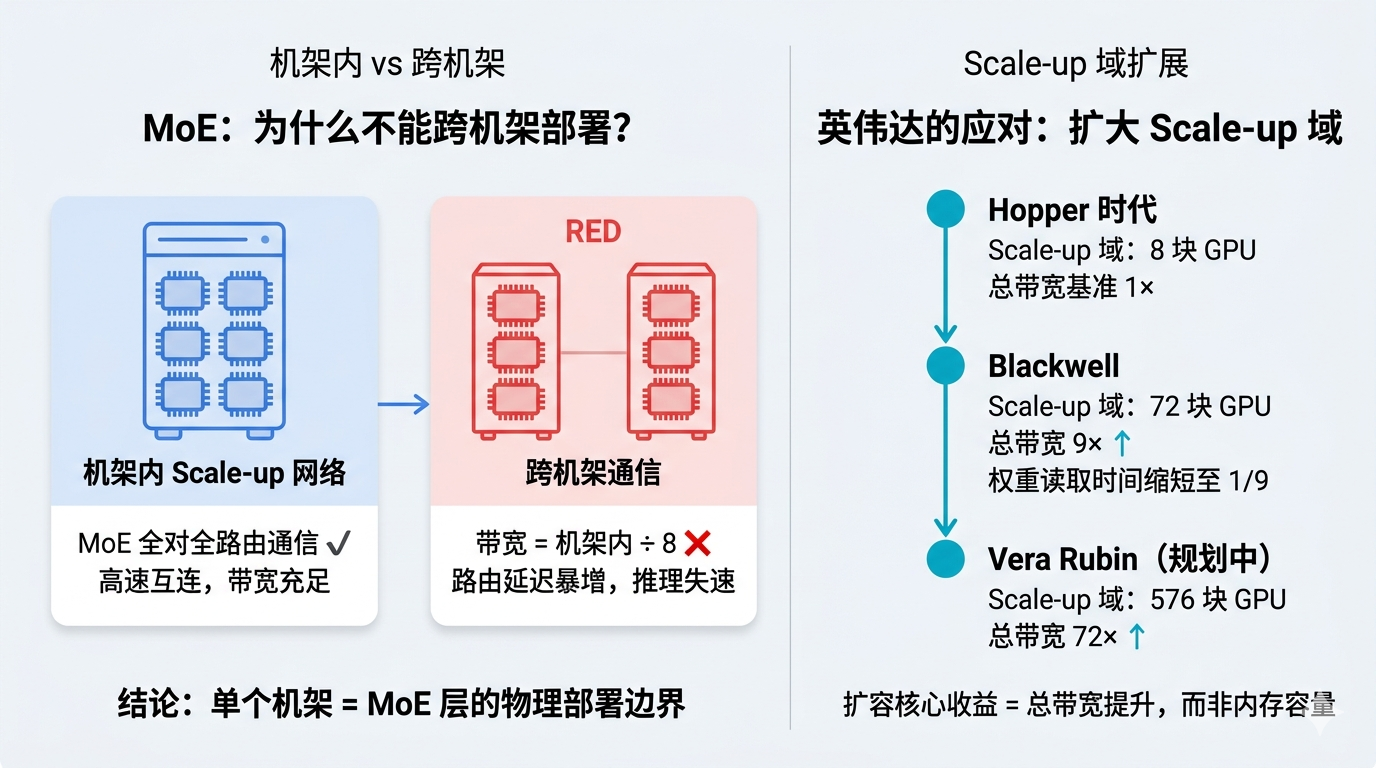
MoE 模型(混合专家)有一个绕不开的工程问题:专家模块分散在不同 GPU 上,路由器每次要从可能分布在任意 GPU 的专家里挑几个,产生「全对全」通信。
这类通信走的是机架内的高速 Scale-up 网络。一旦跨出机架,带宽直接降到机架内的八分之一。
所以行业的共识是:单个机架就是 MoE 层的物理部署边界。
这也是英伟达为什么拼命扩大 Scale-up 域规模的原因——从 Hopper 时代的 8 块 GPU,到 Blackwell 的 72 块,再到 Vera Rubin 计划的 576 块。
规模扩大的核心收益不是内存容量变大,而是总带宽提升。带宽越高,权重读取越快,延迟越低。从 8 块扩到 72 块,总带宽提升 9 倍,权重读取时间直接缩短到原来的九分之一。
顺便解释了一个行业迷思:为什么 GPT-4 在 2023 年发布时据传已是万亿参数,之后三年参数量却没有大幅暴涨?
因为更大的稀疏模型需要更大的 Scale-up 域来撑起带宽。否则权重读取太慢,推理延迟会到用户无法接受的地步。而扩大 Scale-up 域是个物理工程极限——从小计算托盘到整柜式机架,再到跨柜互连,线缆弯曲半径、连接器密度、散热空间,每一项都推到了物理边界。
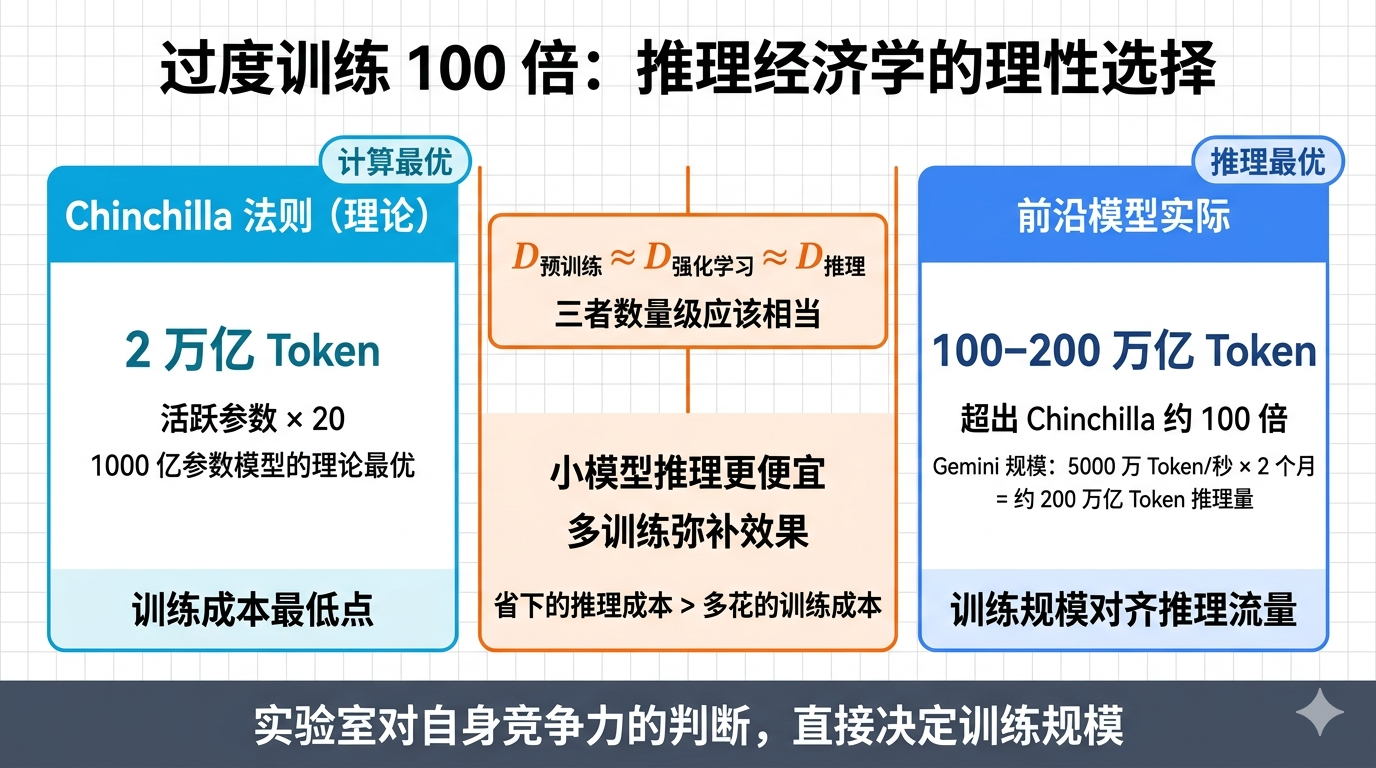
为什么模型都在「过度训练」100 倍?
最后说一个让我觉得很反直觉的结论。
Chinchilla 缩放法则(2022 年 DeepMind 提出)认为,最优训练数据量约为活跃参数的 20 倍。按这个算,1000 亿参数的模型对应约 2 万亿 Token。
但前沿模型实际训练数据已经达到 100-200 万亿 Token,超出大约 100 倍。
这是「过度训练」,还是另有逻辑?
莱纳·波普给出了经济学解释。他用第七个方程把训练和推理统一起来:
D_预训练 ≈ D_强化学习 ≈ D_推理
三者的数量级应该相当。Gemini 级别的模型,全球流量约每秒 5000 万 Token,模型生命周期约 2 个月,总推理 Token 约 200 万亿——正好对应实际的训练规模。
逻辑其实很简单:当推理流量足够大,把模型做小一点、塞入更多训练数据来弥补效果,省下的推理成本远大于多花的训练成本。小模型推理更便宜,同样的效果,合算。
反过来也成立:如果实验室对自己下一版模型的竞争力没有把握,认为只有 50% 的概率能成为市场主流,那推理 Token 的期望值减半,应该对应减少训练规模。
实验室对自身竞争力的判断,直接决定了训练的规模。
小结
用 7 个方程,莱纳·波普把 AI 产业最底层的经济逻辑串了起来:
- 单 Token 耗时由内存和计算两者中的瓶颈决定
- 计算时间随 batch 和活跃参数线性增长
- 内存时间由权重读取(固定)+ KV 缓存读取(随人数和上下文增长)构成
- 单 Token 成本 = 总耗时 / batch,权重成本可摊薄,KV 缓存不可摊薄
- 临界批次大小约等于 300 × 稀疏度,与模型大小无关
- 上下文 200K 的价格拐点是 KV 缓存读取追上计算的物理临界点
- 训练规模应与推理总流量匹配,过度训练是推理经济学的理性选择
豆包每月 68 元到 500 元的价格区间背后,埋的是整套硬件物理约束。
看懂了这套逻辑,再看任何大模型的 API 定价,你其实是在读一张成本报表——每一行数字背后,都是芯片、带宽、并发和物理极限。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 33
33 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)