论文阅读:Recover and Match
Recover and Match: Open-Vocabulary Multi-Label Recognition through Knowledge-Constrained Optimal Transport(恢复与匹配:基于知识约束的最优传输的开放词汇多标签识别)
此片论文主要做的是开放词汇多标签识别(测试时不只识别训练见过的标签,还要识别没见过的新标签,要求模型既要能看懂图,又要能通过文本标签做开放词汇识别)
代码地址:https://github.com/EricTan7/RAM
会议: CVPR 2025
创新点:
1.发现并解决了 CLIP 在 OVMLR 里的两个核心问题(CLIP 局部语义弱、区域-标签匹配粗糙);
2.提出 LLA 恢复局部语义,通过两个模块(SAA和TSS),在不大幅破坏主干网络的前提下恢复局部特征;
3.把区域-标签匹配重新表述为最优传输问题,不是均值池化、不是简单注意力机制,而是通过最优传输对“所有区域 × 所有标签”的匹配做全局建模,并通过标签存在检测和教师知识转移进一步约束,使其更适合开放词汇多标签任务。
整体概括:

主体框架:
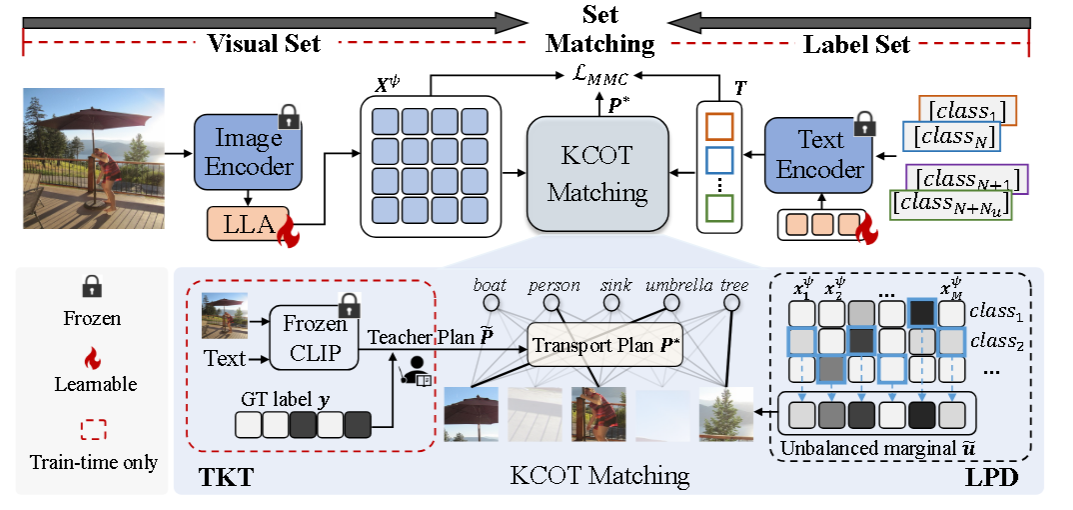
1.Ladder Local Adapter(LLA):恢复局部语义
它是一个侧边并联的小分支,不是硬插进 backbone 主干里面
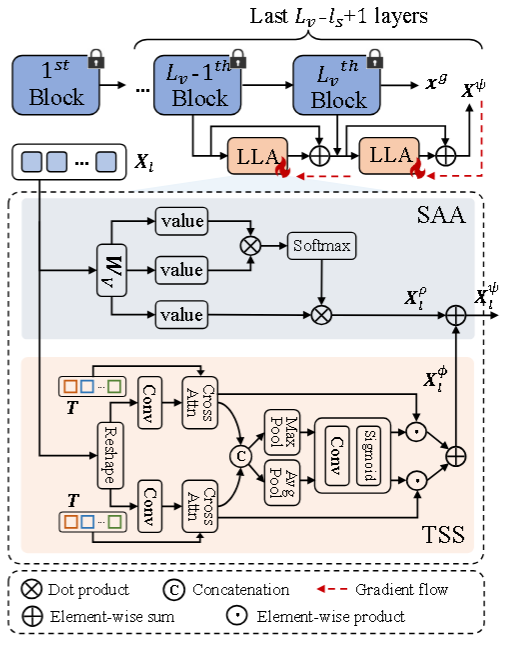
1.1Self-Aware Attention (SAA):和标准 self-attention 不一样,SAA 用参数本身的值去计算 attention map,这样会带来一个特殊效果,就是每个位置对自己的 attention 最高,同时附近区域也更容易被强调,因此达到了强迫注意力从“全局乱看”变成“重新关注局部邻域”的目的;
1.2Text-Guided Spatial Selection (TSS):进一步做借助文本标签信息,从空间上筛选更有用的区域,如上图所示,让图像区域和标签文本直接做交互,看看哪些位置更像哪些标签,然后生成空间掩码,突出高响应区域,抑制不重要位置。
2.Knowledge-Constrained Optimal Transport(KCOT):用“最优传输”做区域-标签匹配
KCOT 的本质,就是学习一个“区域应该分配给哪些标签”的权重矩阵
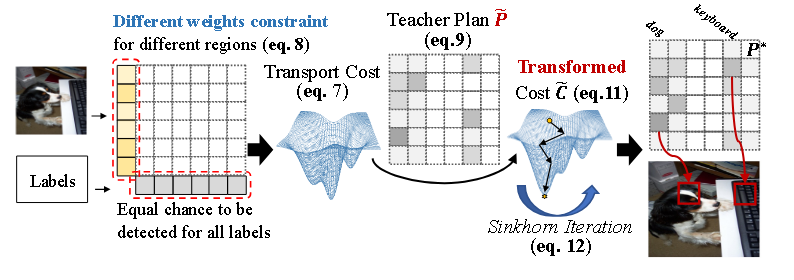
2.1Label Presence Detection (LPD):由于边缘的同一假设是迫使所有图像区域具有相同的重要性,然而这不适用于 OVMLR,因为有许多远离标签的不相关区域,因此在KCOT中,先估计每个区域有没有可能包含某种标签,然后用这个估计值来决定该区域在最有运输里的权重,不是硬把 top-k 区域选出来,而是软性地降低无关区域的话语权。
2.2Teacher Knowledge Transfer (TKT):利用冻结的CLIP的图文对齐能力构造了一个老师分配矩阵,目的是实现如果标签是 GT label,就保留老师的分配值;如果标签不是 GT label,就把分配压到最小值。
注:冻结的CLIP意思是CLIP 模型本体的参数不参与训练,不更新权重,只拿来做特征提取
创新点:
此片论文的创新点很适合我目前的困境,因为目前我主要的出错点就在多标签的识别,个别标签的识别精度不好,从而拉低了整体的精度,这篇论文的两个模块挺适合解决个别标签识别不准确的问题,但是引入之后效果之提升了0点几:

下一步还需再改进,试试从内部结构下手会不会好一点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)