告别 PubMed 检索式,用自然语言搜文献 —— TopBeeAI 文献总结功能深度解析
一句话说清楚:不需要学 PubMed 语法,不需要记 MeSH 词表,不需要拼布尔运算符——你只需要用中文描述你的研究问题,剩下的交给 AI。
你是否也经历过这些?
每个医学科研人,一定有过这样的体验:
打开 PubMed,面对那个孤零零的搜索框,脑子里有一堆想查的东西,但不知道怎么”翻译”成 PubMed 能听懂的检索式。
想查”PD-1抑制剂联合CAR-T在实体瘤中的研究进展”——你写 PD-1 inhibitor AND CAR-T AND solid tumor,出来的却是 3000 多篇乱七八糟的结果,真正相关的不到 10 篇。
想限定只看 RCT 和 Meta 分析——你知道要加 randomized controlled trial[pt] 和 meta-analysis[pt],但每次都要去翻语法手册,拼好后发现忘了加括号,检索式报错。
想限定近 5 年的文献——你知道 PubMed 有 filter 功能,但每次都要手动点左侧那一排筛选条件,换一个检索又要重来一遍。
这些痛点都指向同一个问题:PubMed 检索式的学习成本太高了。
问题本质:检索语言 ≠ 自然语言
PubMed 是一款优秀的文献数据库,但它的检索语法诞生于 1990 年代。近 30 年过去了,AI 已经能写代码、做翻译、画插画,但 PubMed 的搜索框依然要求你使用如下这般精确的语法:
("Immunotherapy"[MeSH] OR "immune checkpoint inhibitors"[Pharmacological Action])AND ("Receptors, Chimeric Antigen"[MeSH] OR "CAR T-cells"[All Fields])AND ("Tumor Microenvironment"[MeSH] OR "immune evasion"[All Fields])AND (randomized controlled trial[pt] OR systematic review[pt])AND ("2020"[Date - Publication] : "2025"[Date - Publication])
说实话——你能不查手册就写出这一串吗?
这才是问题的核心:检索语言与自然语言之间存在巨大的”翻译鸿沟”。大部分医生和医学研究生的时间应该花在”理解文献”上,而不是花在”学习如何检索文献”上。
我们的解法:三段式 AI 检索流水线
TopBeeAI 文献总结功能的设计哲学很简单——让用户说人话,让 AI 做翻译。整个流程分为三步:
| 阶段 | 输入 | AI 做什么 | 输出 |
|---|---|---|---|
| Step 1 · 语义转换 | 自然语言描述(中英文皆可,最长 2000 字) | 理解研究意图 → 生成标准 PubMed 检索式 | 检索式 + 中文说明 |
| Step 2 · 精确筛选 | 检索式 + 筛选条件(研究类型/时间/排序) | 调用 PubMed API 检索真实文献 | 文献列表(标题/作者/摘要/PMID) |
| Step 3 · AI 总结 | 前 N 篇文献的摘要集合 | 基于真实文献流式生成结构化综述 | 可追溯引用的 AI 综述 + Markdown 导出 |
Step 1:像聊天一样描述你的研究问题
你不需要写任何检索式。只需要在输入框中描述你想研究的问题。比如:
“PD-1/PD-L1抑制剂与溶瘤病毒或CAR-T细胞等免疫疗法联用,可有效克服实体瘤免疫抑制微环境的研究文献。”
或者更具体一点:
“帮我找血浆磷酸化 tau-217 升高是阿尔茨海默病淀粉样蛋白 PET 转阳前的早期血液生物标志。直接证明此观点的相关文献。”
输入框支持最长 2000 字,你可以详细描述研究背景、纳入标准、排除条件。系统会基于你的描述,自动生成标准 PubMed 检索式。
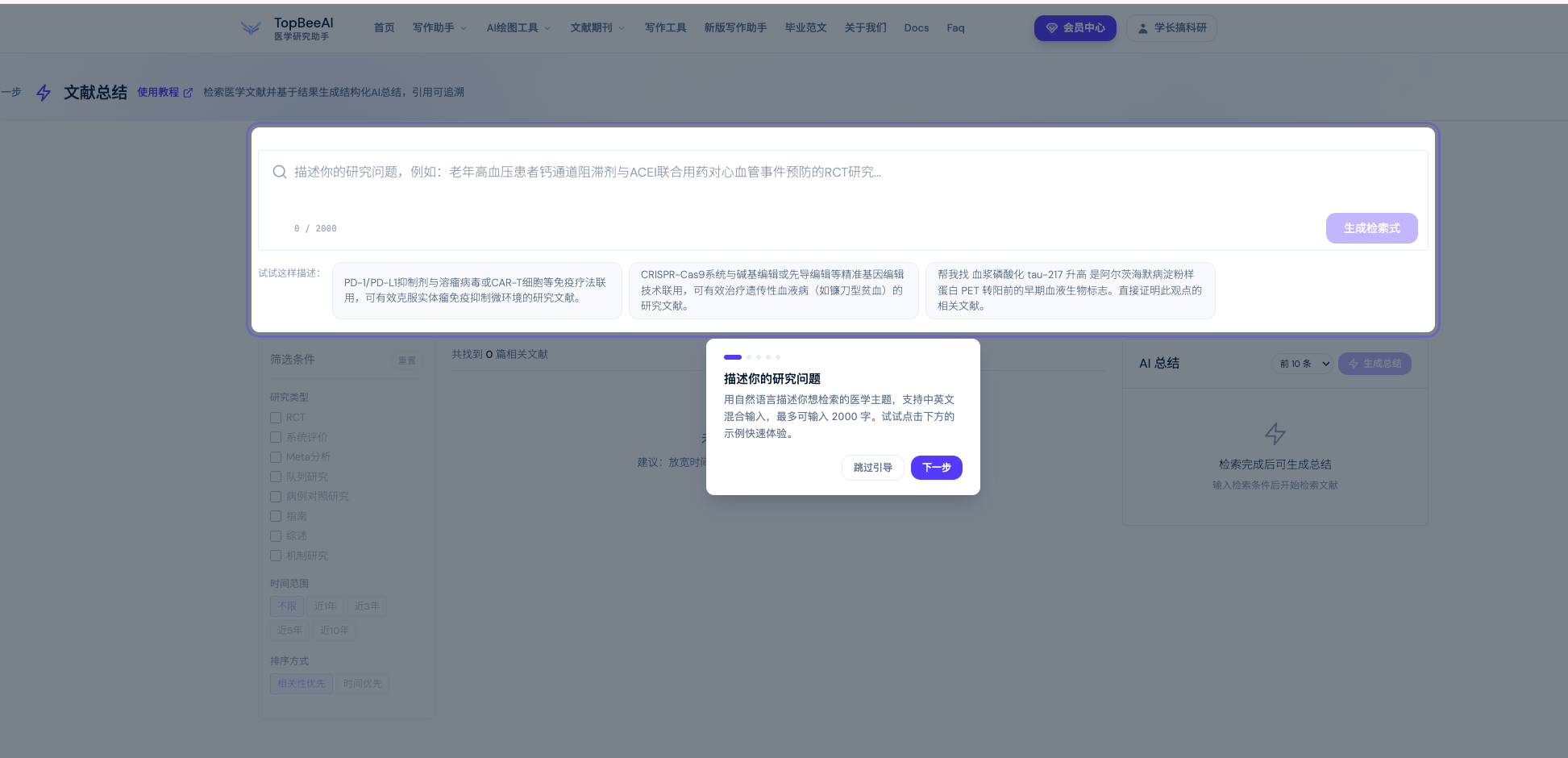
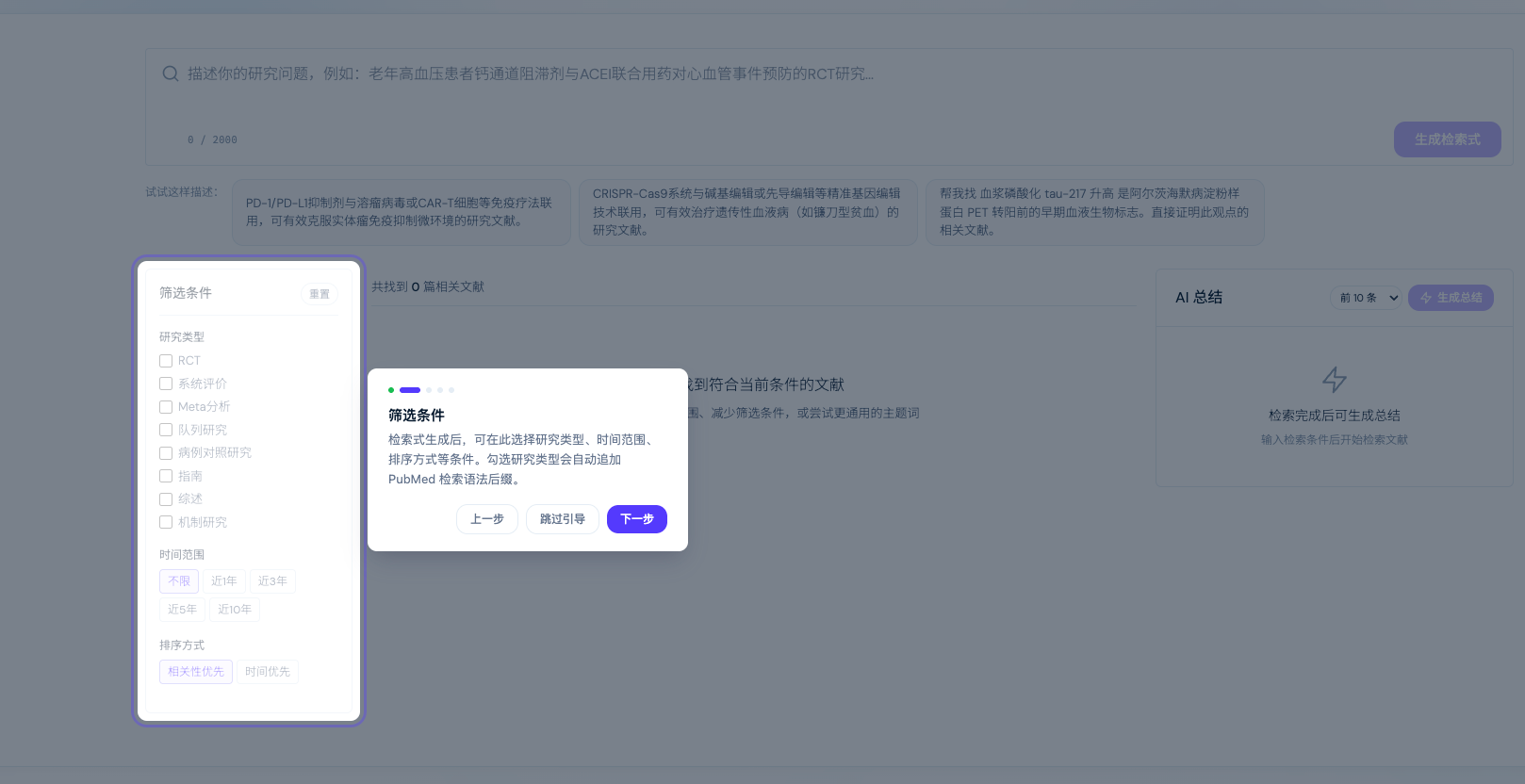
Step 2:一键筛选,自动拼接 PubMed 语法
检索式生成后,你可以在筛选面板中选择:
| 筛选维度 | 可选值 | 自动追加的 PubMed 语法 |
|---|---|---|
| 研究类型 | RCT | randomized controlled trial[pt] |
| 研究类型 | 系统评价 | systematic review[pt] |
| 研究类型 | Meta 分析 | meta-analysis[pt] |
| 研究类型 | 队列研究 | cohort studies[mesh] |
| 研究类型 | 病例对照研究 | case-control studies[mesh] |
| 研究类型 | 指南 | guideline[pt] |
| 研究类型 | 综述 | review[pt] |
| 时间范围 | 近1年 / 3年 / 5年 / 10年 | 自动限定日期区间 |
| 排序方式 | 相关性优先 / 时间优先 | 影响检索结果排序 |
关键设计:每勾选一个研究类型,系统自动向检索式追加对应的 PubMed 语法后缀,无需你手写。检索式可编辑,高级用户也能手动微调。
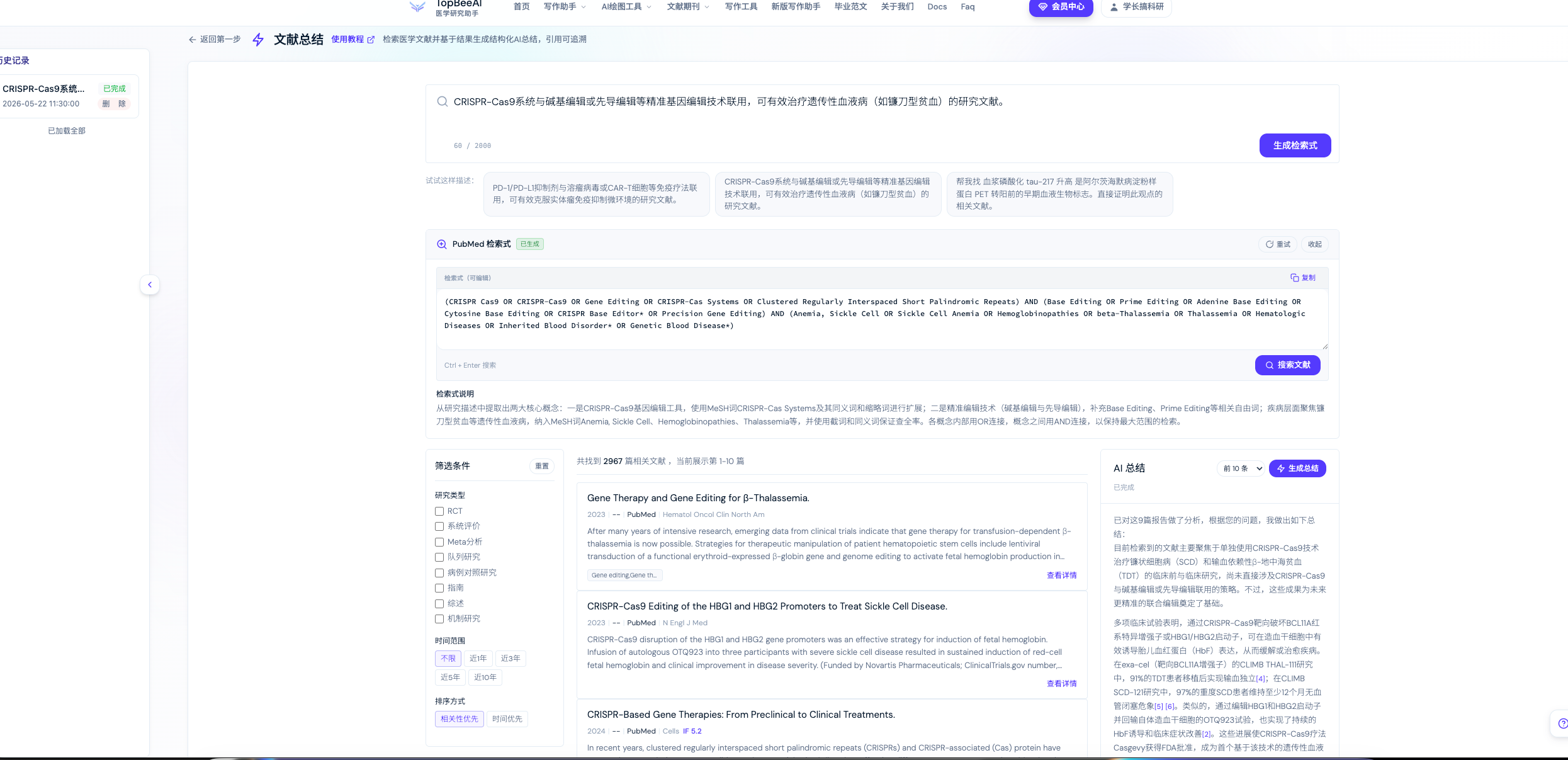
Step 3:AI 流式生成结构化综述
检索完成后,AI 会基于检索到的真实文献,逐篇提取关键结论,跨文献对比分析,生成带引用标记的综述。整个过程通过 SSE(Server-Sent Events)实时流式输出,你可以看到 AI 一字一句地”写”出综述。
生成的综述包含:
- 研究背景概述
- 关键发现的横向对比
- 每一条结论后的引用标记(如
[1],[2,3],[1-5]) - 文末完整的参考文献列表
点击任意引用标记可以直接打开对应文献的详细信息(含 PMID、作者、摘要、引用格式)。
为什么这是可靠的?
一个常见的担忧是:“AI 生成的文献综述,参考文献会不会是编的?”
答案是:不会。
TopBeeAI 的文献总结功能直接接入 PubMed 官方数据库,所有检索到的文献都是 PubMed 中真实存在的记录。AI 只做”总结已有文献”这件事,不会凭空虚构一篇论文。
| 对比维度 | TopBeeAI | 通用 AI(ChatGPT/Claude) |
|---|---|---|
| 文献来源 | PubMed 真实数据库 | 模型训练语料(可能虚构) |
| 引用可查 | 每篇可点击验证 PMID | 经常生成不存在的 DOI |
| 检索式透明 | 展示并允许编辑 PubMed 检索式 | 不透明 |
| 学术格式 | 支持 EndNote 导出 | 不支持 |
这就像一个有经验的文献检索专家 + 一个高效的学术写作助手,组合在一起为你工作。
还有这些细节
新手引导
第一次进入页面,系统会自动启动 5 步新手引导:搜索框 → 筛选条件 → 文献列表 → AI 总结 → 历史记录。每一步都有聚光灯高亮 + 说明文字,帮你快速上手。错过了也可以随时点击右下角的帮助按钮重新唤起。
首次搜索自动总结
输入问题并搜索后,系统会自动对前 10 篇文献生成 AI 总结,不需要额外点击。这在”快速了解某个领域的研究现状”时非常方便。
检索历史自动保存
每次检索都会保存在左侧历史记录中,包含原始检索式、检索结果和 AI 总结。点击即可回访,支持删除管理。
Markdown 导出
AI 综述可以一键导出为 Markdown 文件,方便导入 Obsidian、Notion 等知识管理工具,或直接作为论文初稿的基础素材。
总结
| 传统方式 | TopBeeAI 文献总结 |
|---|---|
| 需要学习 PubMed 检索语法 | 自然语言中文描述即可 |
| 手动记忆 MeSH 词表 | AI 自动生成标准检索式 |
| 逐篇阅读摘要筛选 | AI 跨文献总结关键结论 |
| 手动整理引用格式 | 自动生成可追溯引用 |
| 文献管理零散 | 历史记录自动保存 |
核心理念:让科研人员把时间花在”思考和判断”上,而不是”检索和整理”上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)