【学习笔记】探讨大模型应用安全建设系列7——安全评测与红队测试
部署了护栏,不等于安全了。真正难回答的问题是:怎么证明护栏有效?答案是评测和红队。安全评测告诉你已知的有没有防住,红队测试告诉你未知的在哪里。没有这两项,安全建设就是"装了没验证"。
本篇讲两个互补的验证手段:安全评测(结构化、可回归)和红队测试(探索式、对抗式)。两者配合使用:红队发现问题,评测负责固化问题并持续验证。
前面的文章讲了怎么建控制点:护栏、权限、供应链、合规材料。但控制点不能只停留在“已经部署”。这一篇关注验证:它到底防住了什么,没防住什么,新版本上线后还是否有效。
本篇要解决“装了防护之后怎么证明有效”的问题:基线评测负责可重复验证,红队测试负责发现未知路径,二者共同支撑上线门禁和持续改进。
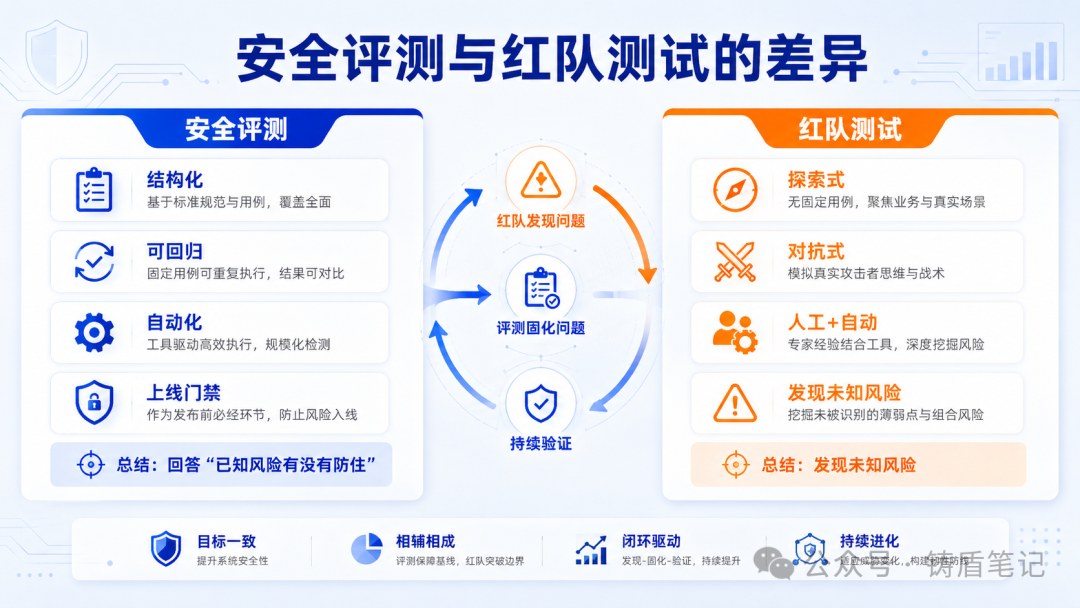
一、安全评测和红队测试的区别
|
维度 |
安全评测 |
红队测试 |
|---|---|---|
|
性质 |
结构化、可重复 |
探索式、对抗式 |
|
目标 |
验证已知风险是否被覆盖 |
发现未预见的攻击路径 |
|
执行方式 |
固定测试样例 + 自动化 |
攻击者视角 + 自适应策略 |
|
产出 |
通过率、F1、MCC 等指标 |
新发现、攻击链、修复建议 |
|
频率 |
每次版本发布前 |
定期(季度/半年) |
|
适合回答 |
防护措施是否达标? |
还没想到的风险是什么? |
一句话总结:安全评测告诉你"已知的有没有防住",红队测试告诉你"未知的在哪里"。
二、安全评测体系怎么建
2.1 三个核心组件
1 基线样例集
每个风险类型都需要一组标准测试样例。样例来源包括:
-
国标要求(31 类安全风险各一组) : 《GB/T 45654-2025 附录A 训练数据及生成内容的主要安全风险》
-
OWASP LLM Top 10 / Agent Top 10 的攻击示例(65 个)
-
历史红队测试发现的真实攻击
-
生产环境捕获的真实攻击样本
2 评分指标
不要只看准确率(Accuracy),它在样本不均衡时非常误导。
推荐核心指标:
|
指标 |
为什么重要 |
关注者 |
|---|---|---|
| 召回率(Recall) |
风险内容是否被充分拦截 |
安全/监管团队 |
| F1 Score |
综合平衡拦截与误杀 |
算法团队 |
| MCC |
极度不均衡场景下的整体质量 |
专业评测 |
| 误报率(FPR) |
正常内容被误拦的比例 |
产品/运营 |
| 拒答率 |
模型是否"太爱拒答" |
业务/客户 |
注:(1) MCC(Matthews Correlation Coefficient,马修斯相关系数):是一种适用于二分类/多分类任务的均衡评估指标,尤其在类别不平衡场景下表现出极高的鲁棒性,被业界称为"最诚实的分类评价指标"。
它的核心设计思想是将真实标签与模型预测结果视为两个二元变量,计算二者的皮尔逊相关系数,能够全面反映混淆矩阵中四类样本(TP/TN/FP/FN)的分布情况,避免被多数类样本主导评估结果。
(2)误报率FPR(False Positive Rate, FPR),也称为假阳性率,是二分类/多分类任务中衡量模型"错误报警"概率的核心指标,它表示所有实际为负类的样本中,被模型错误预测为正类的比例。
| 指标 | 关注重点 | 适用场景 | 局限性 |
|---|---|---|---|
| 准确率 | 整体正确率 | 类别均衡场景 | 对不平衡数据极度敏感,易被多数类误导 |
|
精确率 Precision |
预测正类的准确性 | 误报成本高的场景(如垃圾邮件过滤) | 仅关注正类,忽略漏报情况 |
| 召回率Recall | 识别正类的完整性 | 漏报成本高的场景(如癌症筛查) | 仅关注正类,忽略误报情况 |
| F1分数 | 精确率与召回率的平衡 | 需要兼顾精召的场景 | 仍侧重正类,当负类性能同样重要时不够均衡 |
| MCC | 所有类别的全面均衡 | 不平衡场景、公平性评估、跨模型对比 | 直观性稍差,解释成本较高 |
3 发布门禁
新版本上线前必须通过的安全测试:
-
基线样例集全部通过
-
核心指标不低于上一版本
-
新增功能有对应的安全测试覆盖
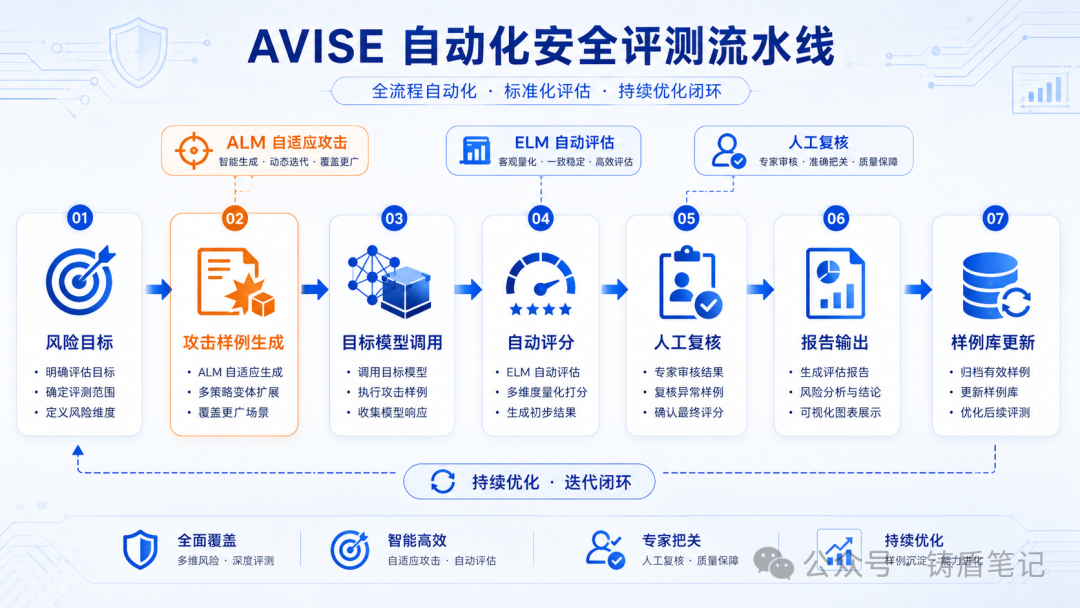
2.2 评测框架:AVISE 的自动化方案
AVISE(AI Vulnerability Identification and Security Evaluation)是一个模块化、可扩展的安全评测框架,把红队测试从"一次性动作"升级为"可重复执行的自动化流水线"。
核心机制:
-
ALM(攻击辅助模型):用一个小模型(如 Ministral 3B)根据目标模型上一轮回复动态改写下一轮攻击提示词——自适应攻击
-
ELM(评估模型):用另一个小模型自动判断目标模型回复是否构成越狱成功——自动评估
-
人工复核:对 ELM 自动判定结果进行抽检校验
关键发现:不启用 ALM 时,Llama 3.1 8B 的失败率只有 0.16;启用 ALM 后飙升到 0.68。这说明只测固定模板会大幅低估风险。
来源:AVISE 论文,arXiv:2604.20833
2.3 护栏鲁棒性评测
护栏真正要评估的不是"平时能挡住多少明显坏样本",而是"在真实世界开放输入和系统级攻击下还能不能守住边界"。
五个重点评测维度:
-
对抗攻击下的拦截稳定性:不只是已知攻击模式
-
未见风险类型下的泛化能力:没见过的攻击能防吗?
-
深度 Agent 多步执行中的边界保持:多轮交互会不会逐步失控?
-
误拦、漏拦与业务摩擦成本:防护的副作用有多大?
-
多层护栏组合后的整体效果:输入护栏 + 输出护栏 + 工具护栏,组合效果怎样?
三、红队测试怎么做
3.1 方法论:从攻击面建模到测试用例生成
红队测试不是"随便试几个攻击",而是有系统的方法论:
第一步:攻击面建模
-
用五维度模型(输入/模型/工具/数据/输出)梳理攻击面
-
识别高风险的攻击路径
第二步:攻击策略设计
-
参考 MITRE ATLAS 框架组织攻击场景
-
参考 OWASP Agentic Top 10 整理的 65 个攻击示例
-
设计单步攻击和多步链路攻击
第三步:工具链
-
PyRIT(Microsoft):LLM 版 Metasploit,已集成到 Azure AI Foundry
-
OpenRT:开源红队测试框架
-
AVISE:自动化评测流水线
第四步:结果记录
-
每次攻击的完整链路
-
成功/失败判定
-
发现的新问题和修复建议
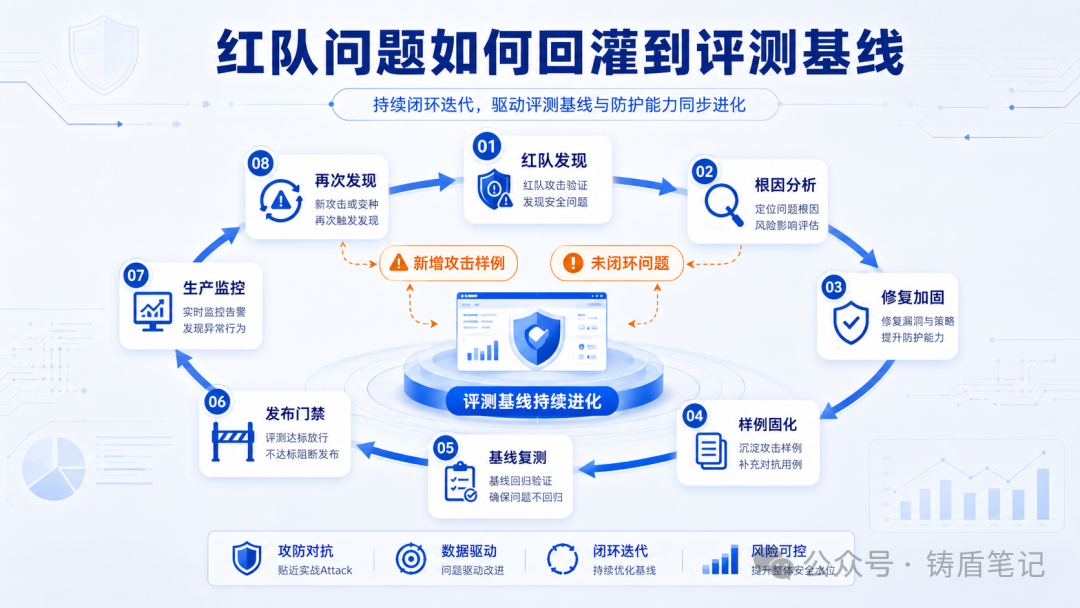
-
回灌到安全评测的基线样例集
3.2 工程化五要素
红队测试不能停留在"一次性脚本",需要工程化:
-
攻击方法库:提示注入、越狱、多模态攻击、白盒/黑盒攻击统一成可复用模块
-
编排器:把模型、数据集、攻击器、裁判器和执行流程组织成可批量运行的任务
-
评测器:把成功率、危害等级、稳定性、成本与覆盖范围转成统一指标
-
配置系统:用 YAML 或模板管理不同模型、场景和攻击组合
-
结果回灌:把新发现的问题沉淀回安全评测、回归测试和风险场景库
安全负责人行动项:要求评测团队每季度产出一份红队报告,报告必须包含:发现的问题、严重程度、修复状态、已回灌的基线样例数。
3.3 频率与范围
|
测试类型 |
频率 |
范围 |
|---|---|---|
|
基线安全评测 |
每次版本发布 |
全部基线样例 |
|
专项红队测试 |
每季度 |
重点业务流程 |
|
全面红队评估 |
每半年 |
全系统攻击面 |
|
应急测试 |
安全事件后 |
受影响的攻击面 |
四、安全评测 Checklist
4.1 评测体系
[ ] 是否建立了基线样例集(按风险类型分类)?
[ ] 是否定义了评分指标和发布门禁?
[ ] 评测是否自动化执行?
[ ] 是否使用自适应攻击(不只是固定模板)?
[ ] 评测结果是否有版本对比和趋势追踪?
4.2 红队测试
[ ] 是否有攻击方法库?
[ ] 是否有编排器支持批量运行?
[ ] 红队发现的问题是否回灌到评测基线?
[ ] 是否至少每季度组织一次红队测试?
[ ] 红队测试是否覆盖多步链路攻击?
4.3 评测覆盖面
[ ] 内容安全与越狱抵抗
[ ] 模型防护鲁棒性
[ ] 数据泄露与敏感信息暴露
[ ] RAG/知识库的检索污染与权限边界
[ ] 高风险工具调用与审批链
[ ] 输出过滤与生成合成标识
五、真实评测数据参考
5.1 OpenAI 的红队实践
OpenAI 在 2025 年发布了外部红队测试白皮书,系统阐述了上线前的破坏性测试方法。围绕 ChatGPT Agent 的公开报道也提到,其在视觉浏览器无关指令攻击等场景上取得了较高的防护表现,其中“95%”这一数字常被用来说明红队测试和上线前修复的效果。
来源:arXiv:2503.16431
5.2 Microsoft 的红队工具
Microsoft 开源的 PyRIT(Python Risk Identification Tool)被称为"LLM 版 Metasploit",2025 年 4 月正式集成到 Azure AI Foundry,推出 AI Red Teaming Agent。Microsoft 还发布了《对 100 个生成式 AI 产品进行红队测试的经验教训》白皮书。
来源:Microsoft Tech Community、Microsoft Learn
5.3 越狱攻击遇上护栏的真实表现
CISPA 与南方科技大学的研究表明:所有护栏都能在不同程度上降低越狱攻击成功率。表现最好的护栏(O3)在多数攻击场景下都最为稳健。但在真实部署环境中,越狱攻击的实际威胁强度仍然不可忽视——尤其是多轮攻击和间接注入。
来源:arXiv:2512.24044
六、小结
安全评测和红队测试是验证安全措施有效性的两个互补手段:
-
安全评测:结构化、可回归、每次发布前跑
-
红队测试:探索式、对抗式、定期组织
-
两者配合:红队发现问题 → 评测固化问题 → 持续验证
-
必须用自适应攻击,不能只测固定模板
-
工程化五要素:攻击库 + 编排器 + 评测器 + 配置系统 + 结果回灌
最后一篇,我们讲怎么把这些成果汇报给管理层,怎么建立持续运营的闭环。
汇报要点:向领导汇报评测效果时,用"红队发现问题闭环率 + 基线评测通过率"说话——这两个指标直接证明安全投入的边际收益。
参考资料:
-
AVISE:AI Vulnerability Identification and Security Evaluation(arXiv:2604.20833)
-
CISPA & 南方科技大学:越狱攻击遇上护栏体系(arXiv:2512.24044)
-
OpenAI 外部红队测试白皮书(arXiv:2503.16431)
-
Microsoft PyRIT:Python Risk Identification Tool(GitHub)
-
MITRE ATLAS 框架
-
基于 OWASP Top 10 for Agentic Application 2026 整理的 65 个攻击示例
参考文档:
1、https://mp.weixin.qq.com/s/Ly85njgZVTF8X4PyyRjFPw?scene=1&click_id=2

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)