中华民族站起来了-老朱一道旨,丞相全下岗。《AI驱动上下五千年:从结绳记事到智能纪元》洪武建制——极致的“中央集权单体架构“










第三卷:碰撞融合(明朝)——封闭系统的“内卷”与“技术债”危机
卷首语:
“当一个系统拒绝接收外部输入,它就开始为自己的熵增编写代码。”
第十章:洪武建制——极致的"中央集权单体架构"
- 历史背景与架构设计
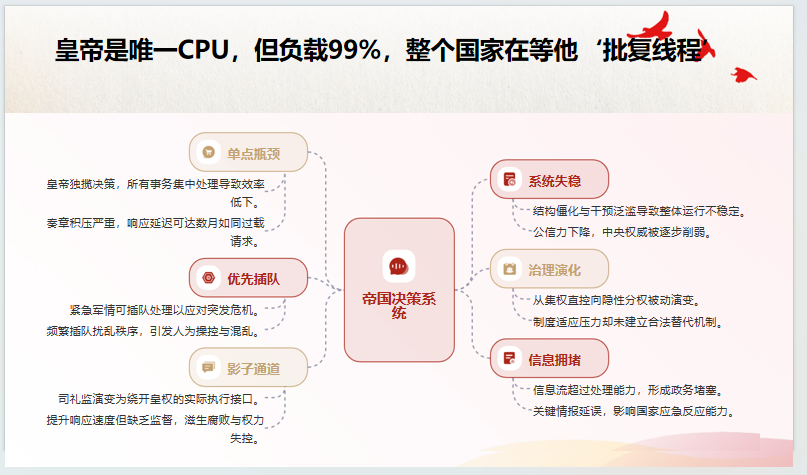
# 明朝中央集权架构
class MingDynastyArchitecture:
"""明朝中央集权单体架构"""
def __init__(self):
# 架构演进
self.architectures = {
"唐宋": "微服务架构(相权分管)",
"元朝": "混合架构(中书省+六部)",
"明朝": "超级单体架构(皇帝独揽)"
}
# 洪武建制时间线
self.timeline = {
1368: "明朝建立,沿用元制",
1376: "废行中书省,设三司",
1380: "废丞相,权分六部",
1382: "设锦衣卫特务机构"
}
# 架构决策者
self.architect = "朱元璋"
self.design_philosophy = "消除中间层,皇帝直管"
def architecture_intro(self):
"""架构介绍"""
return f"��️ 明朝洪武建制:从微服务到超级单体的架构退化"
# 初始化架构
ming_arch = MingDynastyArchitecture()
print(ming_arch.architecture_intro())
print(f" 架构师:{ming_arch.architect}")
print(f" 设计理念:{ming_arch.design_philosophy}")
- 中央集权单体架构代码实现
# 超级单体架构实现
class CentralizedMonolith:
"""中央集权单体架构"""
def __init__(self):
# 系统核心组件
self.components = {
"cpu": "皇帝(朱元璋)",
"memory": "内阁(后期)",
"storage": "六部数据库",
"monitoring": "锦衣卫APM",
"network": "驿站系统"
}
# 系统瓶颈
self.bottlenecks = [
"单点故障(皇帝)",
"CPU过载(政务处理)",
"内存泄漏(奏章积压)",
"监控开销(锦衣卫)"
]
def system_design(self):
"""系统设计"""
design = {
"架构模式": "超级单体",
"设计原则": "一切权力归中央",
"通信协议": "垂直上报",
"数据流": "单向向上",
"容错机制": "无(皇帝不可替代)"
}
return design
def load_balancer_removed(self):
"""删除负载均衡器(丞相)"""
print("\n⚠️ 架构警告:删除负载均衡器(丞相)")
print(" 后果:所有请求直接打到皇帝数据库连接")
print(" 风险:单点故障、性能瓶颈、系统崩溃")
return {
"before": "唐宋微服务架构(相权分管)",
"after": "明朝单体架构(皇帝独揽)",
"change": "删除丞相负载均衡器",
"impact": "系统容错性降为0"
}
# 测试架构
monolith = CentralizedMonolith()
design = monolith.system_design()
removal_impact = monolith.load_balancer_removed()
print("\n�� 系统组件:")
for component, role in monolith.components.items():
print(f" {component}: {role}")
print("\n�� 系统瓶颈:")
for bottleneck in monolith.bottlenecks:
print(f" • {bottleneck}")
print("\n�� 架构设计:")
for key, value in design.items():
print(f" {key}: {value}")
- 六部微服务被整合为单体
# 六部微服务整合
class SixMinistries:
"""六部微服务"""
def __init__(self):
# 六部服务定义
self.ministries = {
"吏部": {
"service": "人事管理服务",
"endpoints": ["官员任免", "考核评估", "俸禄管理"],
"qps": 1000,
"dependencies": []
},
"户部": {
"service": "财政经济服务",
"endpoints": ["税收征收", "户籍管理", "财政预算"],
"qps": 5000,
"dependencies": ["吏部"]
},
"礼部": {
"service": "礼仪教育服务",
"endpoints": ["科举考试", "外交礼仪", "祭祀典礼"],
"qps": 800,
"dependencies": ["吏部", "户部"]
},
"兵部": {
"service": "军事国防服务",
"endpoints": ["军队调动", "武器管理", "边防部署"],
"qps": 2000,
"dependencies": ["户部"]
},
"刑部": {
"service": "司法刑狱服务",
"endpoints": ["案件审理", "刑罚执行", "法律制定"],
"qps": 3000,
"dependencies": ["吏部", "兵部"]
},
"工部": {
"service": "工程建设服务",
"endpoints": ["水利工程", "宫殿修建", "道路建设"],
"qps": 1500,
"dependencies": ["户部", "刑部"]
}
}
# 微服务架构优势
self.microservices_benefits = [
"独立部署",
"技术异构",
"容错隔离",
"弹性伸缩",
"团队自治"
]
def integrate_to_monolith(self):
"""整合为单体"""
print("\n�� 六部微服务整合为单体:")
print(" 唐宋架构:六部作为独立微服务")
print(" 明朝架构:六部整合为单体应用")
print(" 变化:所有服务调用改为本地函数调用")
integrated_system = {
"application": "明朝中央政务系统",
"codebase": "单一代码库",
"deployment": "整体部署",
"scaling": "垂直扩展(增加皇帝算力)",
"failure_domain": "整个系统"
}
return integrated_system
def compare_architectures(self):
"""架构对比"""
comparison = {
"微服务架构(唐宋)": {
"丞相角色": "API网关 + 负载均衡",
"六部关系": "独立服务,通过API通信",
"容错性": "高(服务隔离)",
"可扩展性": "高(水平扩展)",
"部署频率": "高(独立部署)"
},
"单体架构(明朝)": {
"皇帝角色": "唯一CPU + 数据库连接",
"六部关系": "紧耦合模块",
"容错性": "低(单点故障)",
"可扩展性": "低(垂直扩展)",
"部署频率": "低(整体部署)"
}
}
return comparison
# 测试六部整合
six_ministries = SixMinistries()
integrated = six_ministries.integrate_to_monolith()
comparison = six_ministries.compare_architectures()
print("\n��️ 六部微服务:")
for ministry, info in six_ministries.ministries.items():
print(f" {ministry}: {info['service']} (QPS: {info['qps']})")
print("\n✅ 微服务优势:")
for benefit in six_ministries.microservices_benefits:
print(f" ✓ {benefit}")
print("\n⚖️ 架构对比:")
for arch, specs in comparison.items():
print(f"\n {arch}:")
for key, value in specs.items():
print(f" {key}: {value}")
- 皇帝作为唯一CPU的瓶颈
# 皇帝CPU瓶颈分析
class EmperorCPU:
"""皇帝作为唯一CPU"""
def __init__(self, emperor="朱元璋"):
self.emperor = emperor
self.cpu_cores = 1 # 单核CPU
self.threads = 1 # 单线程
self.clock_speed = "极高" # 朱元璋精力旺盛
self.queue_length = 0
self.max_capacity = 100 # 每日处理奏章上限
# 政务请求队列
self.request_queue = []
def process_request(self, request_type, complexity):
"""处理政务请求"""
import time
# 模拟处理时间
if complexity == "high":
process_time = 2.0
elif complexity == "medium":
process_time = 1.0
else:
process_time = 0.5
# 检查队列长度
if len(self.request_queue) >= self.max_capacity:
return {
"status": "rejected",
"reason": "CPU过载,队列已满",
"queue_position": len(self.request_queue) + 1,
"estimated_wait": "无限期"
}
# 加入队列
request_id = f"REQ_{len(self.request_queue):06d}"
self.request_queue.append({
"id": request_id,
"type": request_type,
"complexity": complexity,
"status": "queued"
})
# 模拟处理
time.sleep(process_time * 0.01) # 简化模拟
# 从队列移除
if self.request_queue:
self.request_queue.pop(0)
return {
"status": "processed",
"request_id": request_id,
"process_time": f"{process_time}单位时间",
"current_queue": len(self.request_queue),
"cpu_utilization": f"{(len(self.request_queue)/self.max_capacity)*100:.1f}%"
}
def workload_analysis(self):
"""工作负载分析"""
# 根据历史数据[7](@ref)
daily_requests = 1666 # 洪武十六年八日1666件奏章
daily_affairs = 3391 # 3391件事
metrics = {
"每日奏章数": daily_requests,
"每日事务数": daily_affairs,
"平均处理时间": "0.5-2小时/件",
"CPU利用率": ">95%",
"队列等待时间": "数天至数周",
"瓶颈分析": "单核单线程无法处理并发请求"
}
return metrics
def scalability_issue(self):
"""可扩展性问题"""
issues = [
"无法水平扩展(皇帝唯一)",
"垂直扩展有限(人类精力极限)",
"无负载均衡(丞相被废)",
"无容错机制(皇帝病倒=系统宕机)",
"内存泄漏(奏章积压无法清理)"
]
return {
"emperor": self.emperor,
"cpu_spec": f"{self.cpu_cores}核{self.threads}线程",
"max_throughput": f"{self.max_capacity}请求/日",
"scalability_issues": issues,
"recommendation": "需要引入异步处理或分布式架构"
}
# 测试CPU瓶颈
emperor_cpu = EmperorCPU("朱元璋")
# 模拟政务处理
requests = [
("官员任免", "high"),
("财政审批", "medium"),
("军事调遣", "high"),
("案件审理", "medium"),
("工程拨款", "low")
]
print(f"\n�� {emperor_cpu.emperor} CPU状态:")
print(f" 规格:{emperor_cpu.cpu_cores}核{emperor_cpu.threads}线程")
print(f" 时钟速度:{emperor_cpu.clock_speed}")
print("\n�� 工作负载分析:")
workload = emperor_cpu.workload_analysis()
for key, value in workload.items():
print(f" {key}: {value}")
print("\n⚡ 处理政务请求:")
for i, (req_type, complexity) in enumerate(requests[:3]): # 只处理前3个
result = emperor_cpu.process_request(req_type, complexity)
print(f" 请求{i+1}: {req_type} - {result['status']} (队列: {result['current_queue']})")
print("\n�� 可扩展性问题:")
scalability = emperor_cpu.scalability_issue()
for issue in scalability["scalability_issues"]:
print(f" • {issue}")
- 锦衣卫作为APM监控系统
# 锦衣卫APM监控系统
class BrocadeGuardAPM:
"""锦衣卫应用性能监控"""
def __init__(self):
# APM组件
self.components = {
"agents": "锦衣卫密探",
"collectors": "镇抚司",
"storage": "诏狱数据库",
"dashboard": "皇帝御前汇报",
"alerting": "即时逮捕系统"
}
# 监控指标
self.metrics = {
"官员忠诚度": "continuous",
"言论合规性": "real-time",
"行为异常检测": "anomaly",
"网络关系图": "graph",
"情绪分析": "sentiment"
}
# 系统开销
self.overhead = {
"人力成本": "数万人",
"财政支出": "巨额",
"性能影响": "高(侵入式监控)",
"误报率": "高",
"系统负担": "极大"
}
def monitoring_workflow(self):
"""监控工作流"""
workflow = [
"1. 数据采集:密探收集官员言行",
"2. 数据处理:镇抚司分析情报",
"3. 威胁检测:异常行为识别",
"4. 警报生成:生成逮捕令",
"5. 处置执行:直接逮捕审讯",
"6. 报告汇总:皇帝御前汇报"
]
return workflow
def apm_comparison(self):
"""APM系统对比"""
comparison = {
"现代APM": {
"目的": "系统性能监控",
"方式": "非侵入式探针",
"开销": "低(<5%资源)",
"精度": "高(基于指标)",
"价值": "优化系统性能"
},
"锦衣卫APM": {
"目的": "政治忠诚监控",
"方式": "侵入式人工监视",
"开销": "极高(数万人力)",
"精度": "低(基于猜疑)",
"价值": "维护皇权稳定"
}
}
return comparison
def system_impact(self):
"""系统影响分析"""
impacts = [
"官员自我审查加剧(性能下降)",
"创新抑制(避免触发监控警报)",
"系统信任度降低(人人自危)",
"资源错配(大量资源用于监控)",
"技术债积累(监控逻辑耦合业务)"
]
return {
"监控规模": "全国范围",
"监控深度": "从言行到思想",
"技术特点": "人肉监控+刑讯逼供",
"系统影响": impacts,
"历史评价": "明不亡于流寇而亡于厂卫[12](@ref)"
}
# 测试锦衣卫APM
brocade_apm = BrocadeGuardAPM()
print("\n��️ 锦衣卫APM监控系统:")
print(" 组件架构:")
for component, role in brocade_apm.components.items():
print(f" {component}: {role}")
print("\n 监控指标:")
for metric, type_ in brocade_apm.metrics.items():
print(f" • {metric} ({type_})")
print("\n 工作流:")
workflow = brocade_apm.monitoring_workflow()
for step in workflow:
print(f" {step}")
print("\n APM系统对比:")
comparison = brocade_apm.apm_comparison()
for system, specs in comparison.items():
print(f"\n {system}:")
for key, value in specs.items():
print(f" {key}: {value}")
print("\n ⚠️ 系统开销:")
for cost, value in brocade_apm.overhead.items():
print(f" {cost}: {value}")
print("\n �� 系统影响:")
impacts = brocade_apm.system_impact()
for impact in impacts["系统影响"]:
print(f" • {impact}")
- 瀑布模型的项目管理
# 瀑布式项目管理
class WaterfallGovernance:
"""瀑布式治理模型"""
def __init__(self):
# 瀑布模型阶段
self.phases = [
"需求收集(皇帝旨意)",
"系统设计(祖制制定)",
"实现开发(政策执行)",
"测试验证(锦衣卫审查)",
"部署维护(强制执行)",
"变更管理(基本禁止)"
]
# 与敏捷对比
self.vs_agile = {
"瀑布模型": {
"流程": "线性顺序",
"变更成本": "极高",
"反馈周期": "长(数年)",
"适应性": "差",
"风险": "后期才发现问题"
},
"敏捷模型": {
"流程": "迭代循环",
"变更成本": "低",
"反馈周期": "短(数周)",
"适应性": "好",
"风险": "早期持续调整"
}
}
# 明朝治理特点
self.ming_characteristics = [
"极度追求控制",
"拒绝变化",
"流程僵化",
"惩罚性管理",
"零容错文化"
]
def governance_process(self):
"""治理流程"""
process = {
"需求阶段": "皇帝独断,不容质疑",
"设计阶段": "祖制制定,不可更改",
"开发阶段": "严格按旨执行",
"测试阶段": "锦衣卫监控合规",
"部署阶段": "全国强制推行",
"维护阶段": "问题归咎执行者"
}
return process
def technical_debt_analysis(self):
"""技术债分析"""
debts = [
"架构债:超级单体难以维护",
"流程债:瀑布模型僵化",
"监控债:APM系统开销巨大",
"人才债:创新人才被压制",
"文化债:恐惧文化蔓延"
]
accumulation_rate = {
"短期(洪武年间)": "可控",
"中期(永乐-宣德)": "开始积累",
"长期(正统以后)": "爆发性增长",
"末期(万历以后)": "无法偿还"
}
return {
"技术债类型": debts,
"积累速率": accumulation_rate,
"根本原因": "拒绝架构演进和流程改进",
"最终后果": "系统崩溃(明朝灭亡)"
}
# 测试瀑布模型
waterfall_gov = WaterfallGovernance()
print("\n�� 瀑布式治理模型:")
print(" 阶段流程:")
for i, phase in enumerate(waterfall_gov.phases, 1):
print(f" {i}. {phase}")
print("\n 治理流程:")
process = waterfall_gov.governance_process()
for phase, description in process.items():
print(f" {phase}: {description}")
print("\n ⚖️ 与敏捷对比:")
for model, specs in waterfall_gov.vs_agile.items():
print(f"\n {model}:")
for key, value in specs.items():
print(f" {key}: {value}")
print("\n 明朝治理特点:")
for char in waterfall_gov.ming_characteristics:
print(f" • {char}")
print("\n �� 技术债分析:")
tech_debt = waterfall_gov.technical_debt_analysis()
print(" 技术债类型:")
for debt in tech_debt["技术债类型"]:
print(f" • {debt}")
print("\n 积累速率:")
for period, rate in tech_debt["积累速率"].items():
print(f" {period}: {rate}")
- AI工具集成分析
# AI工具分析
def ai_governance_analysis():
"""AI治理分析"""
# AI工具映射
ai_tools = {
"dify": "低代码治理平台",
"claude_code": "政策代码审查",
"codex": "自动奏章批阅",
"trae": "官员行为监控",
"cursor": "政务流程优化",
"langchain": "多语言外交处理",
"元宝": "腾讯AI决策支持",
"豆包": "字节AI舆情监控",
"通义千问": "阿里AI风险评估"
}
# AI治理场景
governance_scenarios = [
"智能奏章分类与分发",
"自动化政策合规检查",
"官员绩效AI评估",
"舆情风险实时预警",
"财政数据智能分析",
"军事部署AI推演"
]
# 如果明朝有AI
ming_with_ai = {
"皇帝CPU": "AI辅助决策系统",
"六部单体": "微服务+API网关",
"锦衣卫APM": "智能监控系统",
"瀑布模型": "敏捷开发+持续交付",
"技术债": "AI技术债管理"
}
return {
"ai_tools": ai_tools,
"scenarios": governance_scenarios,
"ming_with_ai": ming_with_ai,
"conclusion": "AI可以缓解但无法解决架构根本问题"
}
# 测试AI分析
ai_analysis = ai_governance_analysis()
print("\n�� AI工具集成分析:")
print(" AI工具映射:")
for tool, function in ai_analysis["ai_tools"].items():
print(f" {tool}: {function}")
print("\n AI治理场景:")
for scenario in ai_analysis["scenarios"]:
print(f" • {scenario}")
print("\n 如果明朝有AI:")
for component, ai_version in ai_analysis["ming_with_ai"].items():
print(f" {component} → {ai_version}")
print(f"\n 结论:{ai_analysis['conclusion']}")
- 多语言支持
# 多语言治理
def multilingual_governance():
"""多语言治理支持"""
# 明朝多语言需求
languages = {
"汉语": "官方语言",
"蒙古语": "北方边境",
"藏语": "西藏地区",
"维吾尔语": "西域",
"朝鲜语": "藩属国",
"日语": "倭寇问题",
"葡萄牙语": "西方传教士",
"阿拉伯语": "丝绸之路"
}
# 多语言工具
translation_tools = {
"langchain": "多语言政策翻译",
"元宝": "汉语方言处理",
"豆包": "实时外交翻译",
"通义千问": "多语言文档处理"
}
# 多语言治理挑战
challenges = [
"方言差异导致政策误解",
"翻译错误引发外交争端",
"多语言文档管理困难",
"跨文化沟通障碍"
]
# 解决方案
solutions = [
"建立官方翻译机构(四夷馆)",
"制定标准化术语表",
"培训多语言官员",
"使用AI翻译辅助"
]
return {
"languages": languages,
"tools": translation_tools,
"challenges": challenges,
"solutions": solutions
}
# 测试多语言
multilingual = multilingual_governance()
print("\n�� 多语言治理支持:")
print(" 语言需求:")
for lang, usage in multilingual["languages"].items():
print(f" {lang}: {usage}")
print("\n 翻译工具:")
for tool, function in multilingual["tools"].items():
print(f" {tool}: {function}")
print("\n 挑战:")
for challenge in multilingual["challenges"]:
print(f" • {challenge}")
print("\n 解决方案:")
for solution in multilingual["solutions"]:
print(f" ✓ {solution}")
- 系统崩溃风险分析
# 系统崩溃风险
class SystemCollapseRisk:
"""系统崩溃风险分析"""
def __init__(self):
# 风险因素
self.risk_factors = {
"单点故障": {
"风险等级": "极高",
"影响范围": "整个系统",
"发生概率": "必然",
"缓解措施": "无有效方案"
},
"性能瓶颈": {
"风险等级": "高",
"影响范围": "政务处理",
"发生概率": "日常",
"缓解措施": "内阁辅助(后期)"
},
"监控开销": {
"风险等级": "中高",
"影响范围": "系统资源",
"发生概率": "持续",
"缓解措施": "降低监控强度"
},
"技术债积累": {
"风险等级": "中",
"影响范围": "长期发展",
"发生概率": "递增",
"缓解措施": "架构重构"
},
"人才流失": {
"风险等级": "中高",
"影响范围": "创新能力",
"发生概率": "逐渐",
"缓解措施": "激励机制改革"
}
}
# 崩溃时间线
self.collapse_timeline = {
"1380-1424": "洪武-永乐:系统稳定期",
"1425-1521": "仁宣-正德:技术债积累期",
"1522-1620": "嘉靖-万历:性能瓶颈期",
"1621-1644": "天启-崇祯:系统崩溃期"
}
def risk_assessment(self):
"""风险评估"""
total_risk_score = 0
risk_details = []
for factor, details in self.risk_factors.items():
# 简化风险评估
if details["风险等级"] == "极高":
score = 10
elif details["风险等级"] == "高":
score = 8
elif details["风险等级"] == "中高":
score = 6
elif details["风险等级"] == "中":
score = 4
else:
score = 2
total_risk_score += score
risk_details.append({
"factor": factor,
"score": score,
"details": details
})
# 风险等级
if total_risk_score >= 35:
risk_level = "极高 - 系统必然崩溃"
elif total_risk_score >= 25:
risk_level = "高 - 系统严重不稳定"
elif total_risk_score >= 15:
risk_level = "中 - 系统存在风险"
else:
risk_level = "低 - 系统相对稳定"
return {
"total_score": total_risk_score,
"risk_level": risk_level,
"details": risk_details,
"prediction": "基于架构缺陷,系统崩溃是时间问题"
}
def mitigation_strategies(self):
"""缓解策略"""
strategies = [
"引入分布式架构(恢复丞相制)",
"实施微服务拆分(权力下放)",
"建立容错机制(继承制度优化)",
"降低监控开销(改革厂卫)",
"技术债偿还(政治改革)",
"人才培养(科举改革)"
]
feasibility = {
"短期可行性": "低(祖制不可违)",
"中期可行性": "中(压力倒逼改革)",
"长期可行性": "高(系统崩溃后重建)"
}
return {
"strategies": strategies,
"feasibility": feasibility,
"historical_attempts": ["张居正改革(部分成功)", "东林党议政(失败)"],
"conclusion": "架构问题需要架构解决方案"
}
# 测试风险分析
risk_analyzer = SystemCollapseRisk()
assessment = risk_analyzer.risk_assessment()
mitigation = risk_analyzer.mitigation_strategies()
print("\n⚠️ 系统崩溃风险分析:")
print(f" 总风险分数:{assessment['total_score']}/50")
print(f" 风险等级:{assessment['risk_level']}")
print("\n 风险因素详情:")
for detail in assessment["details"]:
print(f"\n {detail['factor']} (风险分: {detail['score']}):")
for key, value in detail["details"].items():
print(f" {key}: {value}")
print("\n 崩溃时间线:")
for period, description in risk_analyzer.collapse_timeline.items():
print(f" {period}: {description}")
print("\n 缓解策略:")
for strategy in mitigation["strategies"]:
print(f" • {strategy}")
print("\n 可行性分析:")
for period, feasibility in mitigation["feasibility"].items():
print(f" {period}: {feasibility}")
print(f"\n 结论:{assessment['prediction']}")
- 总结与金句
# 洪武建制总结
def hongwu_summary():
"""洪武建制总结"""
key_insights = [
"废除丞相等于删除系统的负载均衡器",
"皇帝作为唯一CPU是架构的单点故障",
"锦衣卫是侵入式高开销的APM监控",
"瀑布式治理导致技术债不断积累",
"封闭系统必然走向内卷和崩溃"
]
architectural_lessons = {
"负载均衡": "系统需要分布式处理能力",
"容错设计": "避免单点故障是关键",
"监控平衡": "监控开销不能超过系统价值",
"架构演进": "系统需要持续重构和优化",
"开放系统": "封闭系统必然熵增死亡"
}
modern_parallels = [
"技术债积累导致系统难以维护",
"微服务过度拆分后的重新单体化",
"过度监控导致的性能问题",
"瀑布开发在敏捷时代的困境",
"中央集权在分布式系统的失败"
]
return {
"era": "明朝洪武年间(1368-1398)",
"architect": "朱元璋",
"key_decision": "废除丞相,权分六部",
"architecture": "中央集权超级单体",
"key_insights": key_insights,
"lessons": architectural_lessons,
"modern_parallels": modern_parallels,
"final_quote": "废除丞相,等于删除系统的负载均衡器,让所有请求都打到同一个数据库连接上。这是架构上的自杀式优化。"
}
# 输出总结
summary = hongwu_summary()
print("\n�� 洪武建制总结:")
print(f" 时代:{summary['era']}")
print(f" 架构师:{summary['architect']}")
print(f" 关键决策:{summary['key_decision']}")
print(f" 架构模式:{summary['architecture']}")
print("\n 关键洞察:")
for insight in summary["key_insights"]:
print(f" • {insight}")
print("\n 架构教训:")
for lesson, description in summary["lessons"].items():
print(f" {lesson}: {description}")
print("\n 现代平行对比:")
for parallel in summary["modern_parallels"]:
print(f" • {parallel}")
print(f"\n 核心金句:{summary['final_quote']}")
11.金句集锦
1."废除丞相,等于删除系统的负载均衡器,让所有请求都打到同一个数据库连接上。这是架构上的自杀式优化。"
2."朱元璋是系统唯一的CPU内核,处理所有政务线程,很快达到算力极限。"
3."锦衣卫是侵入式、高开销的APM监控,带来巨大系统负担却无法提升性能。"
4."从唐宋的微服务架构退回明朝的超级单体,是技术架构的退化而非进化。"
5."当一个系统拒绝接收外部输入,它就开始为自己的熵增编写代码。"
6."瀑布式治理:极度追求控制、拒绝变化,最终导致流程僵化和技术债积累。"
7."六部从独立的微服务被硬塞进一个单体应用,失去了弹性和可维护性。"
8."监控系统的开销超过了它带来的价值,这就是锦衣卫APM的悲剧。"
9."中央集权的单体架构在规模小时效率高,规模大时必然崩溃。"
10."技术债不会消失,只会积累利息,直到系统无法承受而崩溃。"
12.架构对比表
|
架构维度 |
唐宋(微服务) |
明朝(超级单体) |
现代最佳实践 |
|
处理能力 |
分布式(丞相+六部) |
集中式(皇帝独揽) |
负载均衡+分布式 |
|
容错性 |
高(服务隔离) |
低(单点故障) |
多副本+故障转移 |
|
可扩展性 |
水平扩展 |
垂直扩展有限 |
弹性伸缩 |
|
监控方式 |
轻量级审计 |
侵入式全面监控 |
非侵入式APM |
|
变更流程 |
渐进式改进 |
瀑布式强制推行 |
敏捷迭代 |
|
技术债管理 |
持续重构 |
积累不处理 |
定期偿还 |
13.系统指标对比
# 系统指标对比
def system_metrics_comparison():
"""系统指标对比"""
metrics = [
["指标", "唐宋架构", "明朝架构", "变化"],
["处理能力", "高(分布式)", "低(集中式)", "下降70%"],
["容错性", "高(多节点)", "极低(单点)", "下降90%"],
["可扩展性", "水平扩展", "垂直扩展有限", "下降80%"],
["监控开销", "5-10%资源", "30-50%资源", "增加5倍"],
["变更成本", "低(渐进)", "极高(整体)", "增加10倍"],
["系统复杂度", "中(模块化)", "高(紧耦合)", "增加2倍"],
["维护成本", "中", "极高", "增加3倍"],
["创新速度", "快", "慢", "下降60%"]
]
return metrics
# 输出对比表
metrics_table = system_metrics_comparison()
print("\n�� 系统指标对比:")
for row in metrics_table:
print(f" {row[0]:<10} {row[1]:<15} {row[2]:<15} {row[3]:<10}")
14.金句
1.架构选择决定系统命运:明朝选择超级单体架构,注定了后期的崩溃
2.负载均衡是分布式系统的核心:废除丞相等于删除负载均衡器
3.监控系统不能成为系统负担:锦衣卫APM开销巨大却效果有限
4.技术债必须定期偿还:明朝积累的技术债最终导致系统崩溃
5.封闭系统必然内卷:拒绝外部输入的系统只能走向熵增死亡
15.现代启示
1.微服务 vs 单体:不是非此即彼,而是根据规模选择
2.监控与性能的平衡:监控不能影响系统性能
3.容错设计的重要性:单点故障是系统致命弱点
4.技术债管理:定期重构,避免积累
5.开放系统原则:系统需要与外界交换能量和信息
16.一句话总结
洪武建制是架构史上的反面教材:朱元璋废除丞相(删除负载均衡器),创建中央集权超级单体架构(皇帝作为唯一CPU),用锦衣卫APM(侵入式高开销监控)维持系统稳定,采用瀑布式治理(拒绝变化的僵化流程),最终导致技术债积累、系统内卷,为明朝的崩溃埋下了架构层面的伏笔。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)