用“挑西瓜”讲透《机器学习》第四章-决策树
📖《机器学习》第4章·通俗解读 | 决策树:像做选择题一样做判断
决策树是机器学习里最像人类思维的模型之一。
它的思路很简单:遇到一个问题,一步步问“是或否”,最终走到一个答案。
就像医生看病:先问“发烧吗?” → 是,再问“咳嗽吗?” → 是 → 可能是感冒……
1. 决策树长什么样?
还是用西瓜举例。你要判断一个瓜是不是好瓜。
你可能这样问自己:
-
色泽是什么?
-
青绿 → 再看根蒂
-
乌黑 → 再看敲声
-
浅白 → 大概率不是好瓜
-
-
根蒂怎么个蜷法?
-
蜷缩 → 好瓜
-
稍蜷 → 再听敲声
-
硬挺 → 坏瓜
-
把这些问题串起来,画成一个树状图,就是决策树。
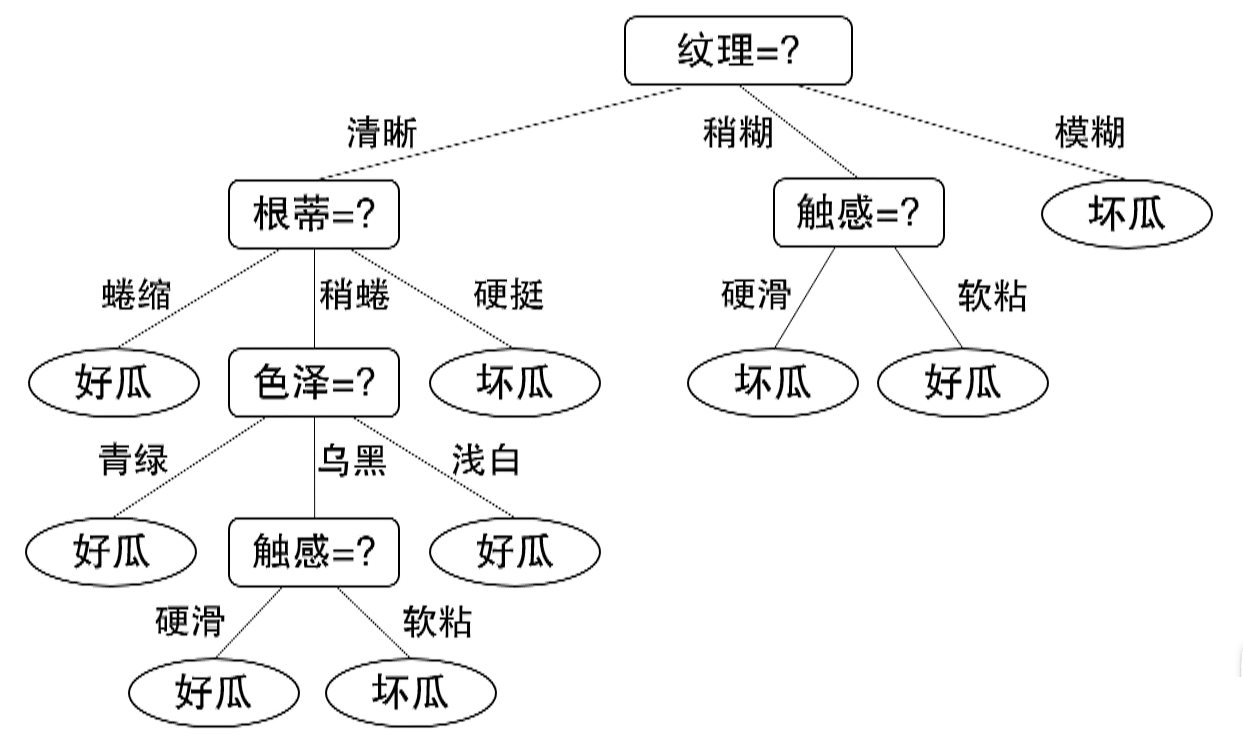
树的顶部叫根结点,中间叫内部结点(每个都是一个判断题),底部叫叶结点(最终答案)。
从根走到叶的过程,就是对瓜的一次完整判断。
2. 怎么构建一棵决策树?—— 分而治之
构建决策树的核心思想:找一个最“好”的属性来作为当前的判断问题。
比如,现在有一堆瓜,你要先问一个什么问题?
问“色泽”?还是问“根蒂”?还是问“敲声”?
哪个问题能最好地把好瓜和坏瓜分开,就先问哪个。
这就是划分选择。
3. 怎么判断哪个属性最好?—— 三种常用标准
方法一:信息增益(ID3算法)
通俗理解:
问完一个问题后,数据会变“纯”多少?
变得越纯,说明这个问题越有用。
“纯”的意思是:一堆瓜里,要么全是好瓜,要么全是坏瓜,不要混在一起。
信息增益 = 原来的混乱程度 - 问完问题后的混乱程度。
增益越大,说明这个问题越值得先问。
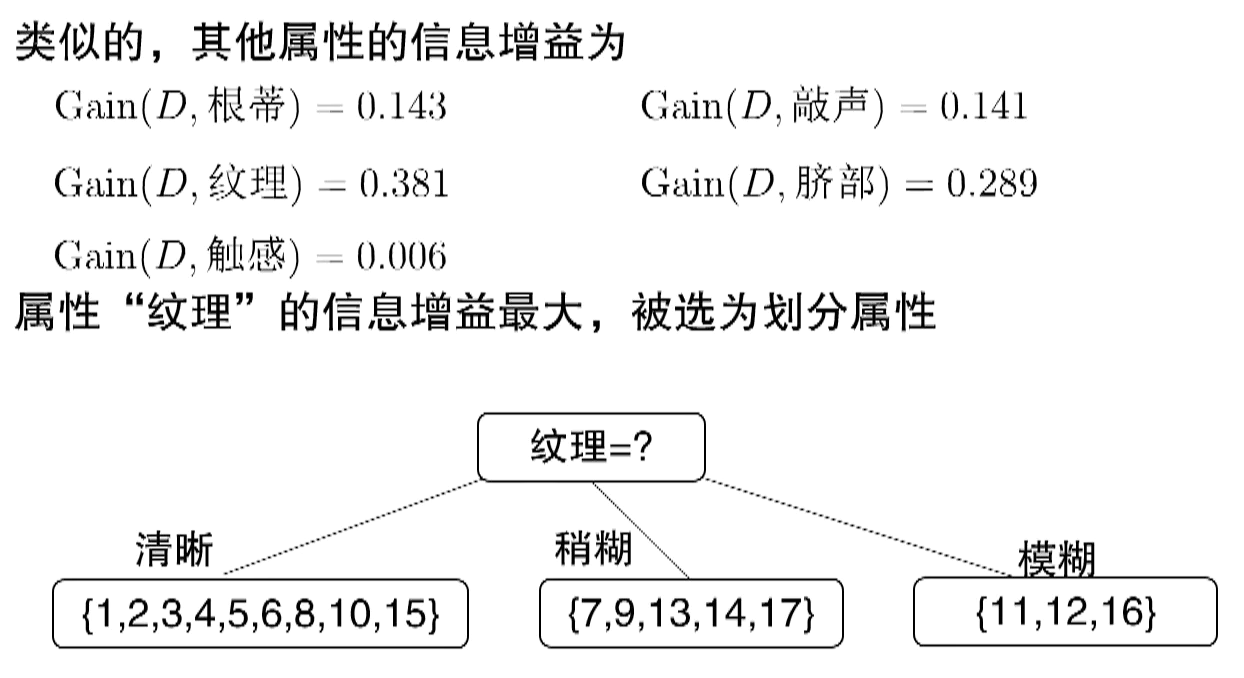
但是存在一个问题:信息增益偏爱取值多的属性。比如“编号”这种每个瓜都不同的属性,信息增益会很大(因为每个分支只有一个瓜,非常纯),但这种树没意义(不能泛化)。所以需要改进。
方法二:增益率(C4.5算法)
给取值多的属性“打个折”,避免偏心。
先算一个“固有值”(取值越多,固有值越大),然后用信息增益除以固有值,得到增益率。
C4.5不是直接选增益率最大的,而是先找信息增益高于平均的,再从中选增益率最高的,既防偏心,又不失效果。
方法三:基尼指数(CART算法)
基尼指数反映的是从一堆瓜里随机抽两个,它们类别不同的概率。
基尼指数越小,说明数据越纯。
选属性时,选划分后基尼指数最小的那个。
三种方法各有千秋,实际中差别不大,随便选一种都能用。
4. 剪枝:防止树长得太“茂密”
如果你让树一直长,它可能会把训练数据里的“意外”也当成规律,这就是过拟合。
比如某个好瓜刚好颜色浅,树就记住了“颜色浅也是好瓜”,结果新来一个浅白瓜,它可能就判错了。
剪枝就是砍掉一些不必要的树枝。
预剪枝(边建边剪)
每要分一个新分支前,先问:
“分了之后,在验证集上的表现会变好吗?”
如果不会,就不分,把当前结点直接当叶子。
好处:快,不容易过拟合。
坏处:只盯着眼前一步的收益,放弃了可能带来更大收益的深层分支。
后剪枝(建完再剪)
先让树完整长到最大,然后自底向上看每个内部结点:
“把这个子树换成叶子(取多数类),验证集表现会变好吗?”
如果会,就剪。
好处:比预剪枝保留更多分支,泛化能力通常更好。
坏处:慢(要先建完整棵树)。
5. 处理连续值和缺失值
连续值怎么办?
比如“密度”是连续数字,不能直接问“密度等于多少?”
处理办法:二分法。
把连续值排序,取相邻两数的中点作为候选切分点,然后像离散属性一样比较信息增益,选最好的那个切分点。
比如密度有0.4、0.5、0.6,候选切分点就是0.45、0.55。
问“密度 ≤ 0.45?”就是一个二分问题。
注意:连续属性可以被重复使用(比如父结点用了“密度≤0.5”,子结点还可以再用“密度≤0.3”)。
缺失值怎么办?
有些样本某个属性值缺失(比如根蒂脱落)。
处理思路:
-
计算信息增益时,只考虑不缺失的样本,然后按比例折算
-
划分时,如果样本在该属性上缺失,就以不同概率分到所有分支(概率 = 该分支的样本比例)
C4.5就是这样做的。
6. 多变量决策树:斜着切一刀
传统的决策树每次只问一个属性(如“色泽=青绿?”),所以分类边界是平行于坐标轴的直线或折线。
如果真实的分类边界是斜线,传统决策树需要用很多段折线去逼近,树会很大。
多变量决策树允许结点问多个属性的组合,比如“0.5×色泽 + 0.3×根蒂 > 0.6?”。
这样就能用一条斜线直接分开,树会小很多,也更简洁。
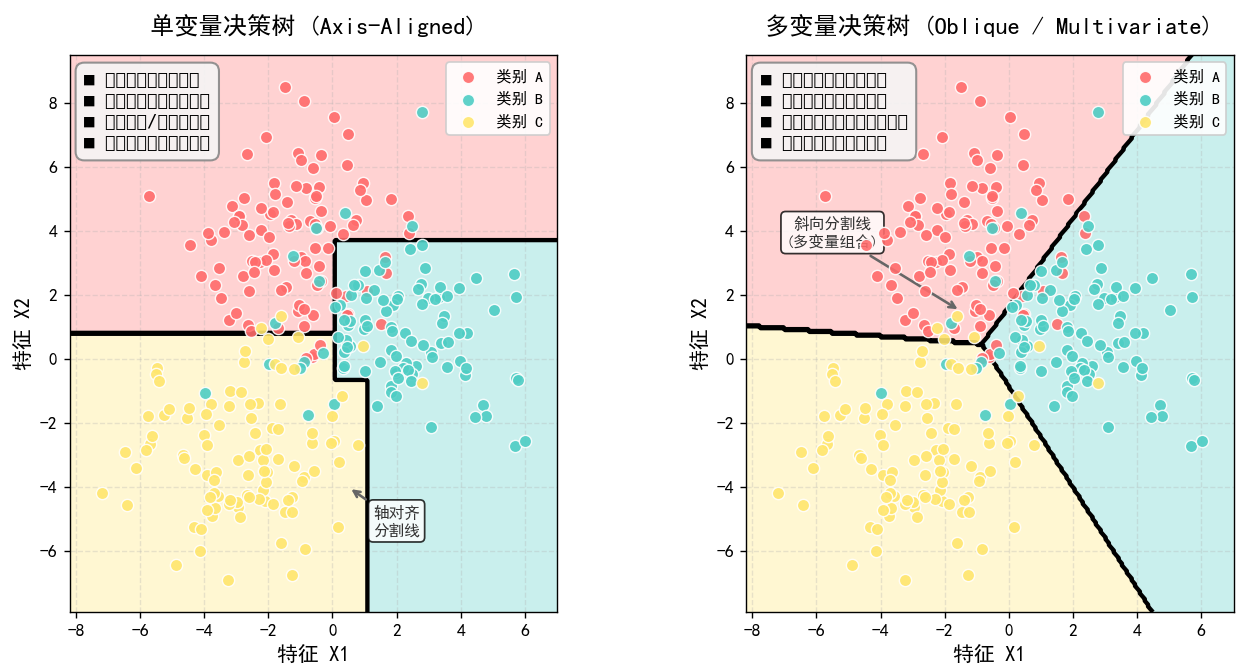
但多变量决策树的每个结点相当于训练一个小分类器,计算量更大。
📌 第四章总结(背下这5句就够了)
-
决策树 = 一步一步问“是/否”问题,最后走到答案
-
划分属性时,常用信息增益、增益率、基尼指数
-
剪枝(预剪枝/后剪枝)用来防止过拟合
-
连续值用二分法处理,缺失值用概率分配处理
-
多变量决策树可以斜着切,边界更灵活,树更小
👇 下章预告
第五章讲神经网络——模仿人脑神经元的模型。
你会学到:什么是神经元、什么是BP算法(误差反向传播)、深度学习为什么这么火。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)