agent开发小结
agent初步开发小结
新奇的agent一开始让人觉得是很高大上的东西,但其实了解和开发agent并不是太复杂。
一.agent的原理
agent的本质就是API+tools,API使得大模型可以在本地使用,但是也仅限于chatbot一样的聊天功能,让它去访问和修改本地是做不到的,相当于只有大脑没有手脚。
tools的本质是函数列表,函数可以做到读取和修改本地以及其他AI做不到的事,如果把API和tools结合,让大模型调用函数就能实现包括但不限于在电脑上干活,相当于大脑装上了手脚。
比如我这里把专门用于websearch的函数设置为tools,当回答和执行prompt需要进行上网搜索时,API就会调用它。


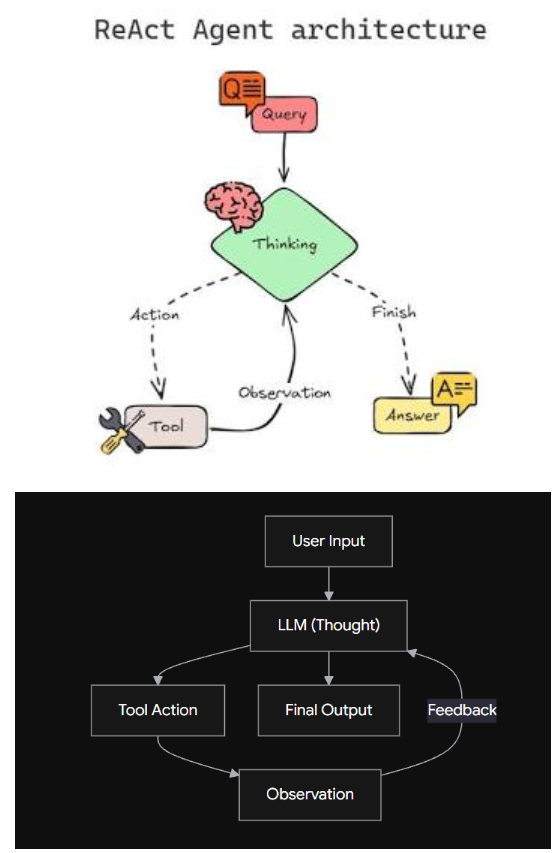
下图是agent的基本架构
二.如何写一个简单的agent
写agent的语言可以用python的Langchain框架,java,原生态的golang等,最主流最方便的就是Langchain框架(后续agent部署需要实现云原生的话,用go语言开发最佳),从Langchain入手写一个简单的agent.
1)准备api并初始化大模型
langchain为大多数官方供应商都定制了框架,下面是常见的初始化大模型一条龙
**OpenAI **
这是目前生态支持最好的模型系列。
- 需要安装:
pip install langchain-openai - 环境变量:
OPENAI_API_KEY(也可以通过os.environ[“OPENAI_API_KEY”]临时设置)
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
Google Gemini
适合处理超长文本和多模态任务。
- 需要安装:
pip install langchain-google-genai - 环境变量:
GOOGLE_API_KEY
from langchain_google_genai import ChatGoogleGenerativeAI
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
)
Anthropic
目前在写代码和复杂逻辑推理上,Claude是公认的顶流。
- 需要安装:
pip install langchain-anthropic - 环境变量:
ANTHROPIC_API_KEY
from langchain_anthropic import ChatAnthropic
llm = ChatAnthropic(
model="claude-3-5-sonnet-20241022",
temperature=0
)
本地开源模型 (使用 Ollama)
如果条件不错,有自己的本地模型,搭配 Ollama 是最简单的方案。
- 需要安装:
pip install langchain-ollama - 前提条件: 后台需要保持 Ollama 软件运行。
from langchain_ollama import ChatOllama
llm = ChatOllama(
model="llama3.1", # 需要先在终端运行过 ollama run llama3.1
temperature=0,
)
OpenAI 兼容
每个供应商都有自己的框架,各自为政不太方便,最推荐的方式是OpenAI 兼容,把base_url填对就能指向供应商了,供应商也可以是中转站。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="模型ID", # 模型名称
api_key="your-api-key", # 填入Key
base_url="base_url", #base_url
temperature=0
)
从用户使用的角度来讲,开发agent时用模型自框架用于初始化时用户直接对现有provider进行connect,用OpenAI 兼容则允许用户自定义provider。
2)写tools和定义tools
框架有常用的内置tools
from langchain_community.tools import DuckDuckGoSearchRun
search_tool = DuckDuckGoSearchRun()
#这个websearch的tool很有必要,由于训练的周期,许多大模型本身的弱项就是消息实时性
tools本质是带上tool装饰器的函数,我们也可以自己写tool
@tool
def get_word_length(word: str) -> int:
"""返回一个单词的长度。当你需要计算单词字母数量时使用此工具。"""
return len(word)
和正常的函数区别是1.@tool装饰器2.带三引号的提示词,告诉模型什么时候需要调用这个tool
最后把tool组合起来定义tools
tools = [search_tool, get_word_length]
3)初始化和简单使用agent
模型API和tools二要素具备,初始化agent,最后可以为agent补一个全局提示词
agent_executor = create_agent(
model=llm,
tools=tools,
system_prompt="你是一个聪明的 AI 助手。请尽量使用工具来解答用户的问题。",
)
简单的使用agent
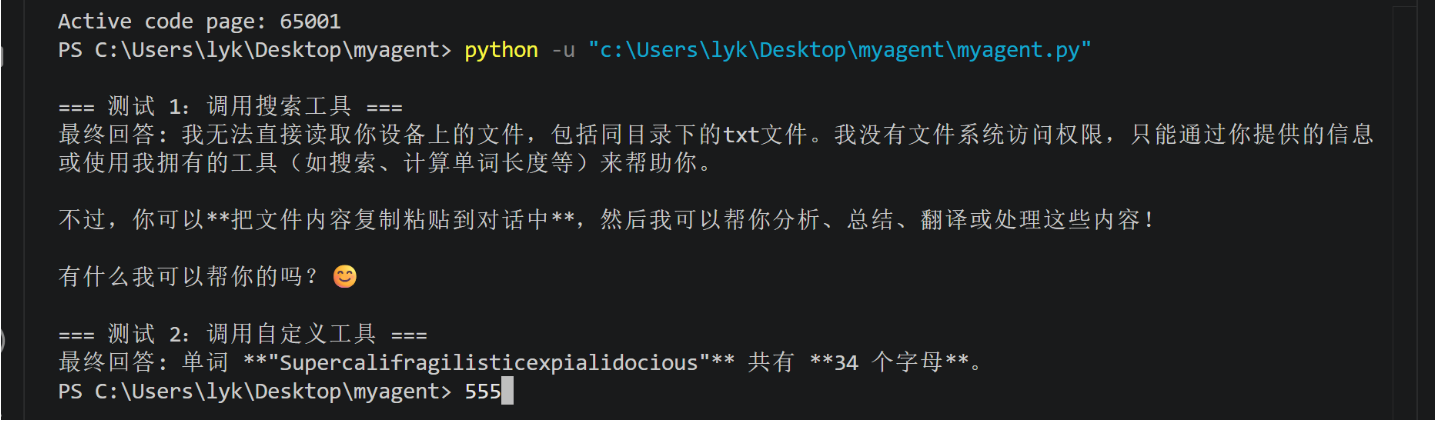
print("\n=== 测试 1:调用搜索工具 ===")
# 返回一个字典,其中包含一个键 "messages",其值是一个列表,列表中的每个元素都是一个元组,元组的第一个元素是消息的发送者(如 "user" 或 "agent"
response1 = agent_executor.invoke(
{"messages": [("user", "科比·布莱恩特的名言是什么?")]}
)
print("最终回答:", response1["messages"][-1].content)
response1返回的是一个字典,其中"messages"键对应的值是一个由元组组成的数组,每一个元组都是带发送者和内容的message,数组的最后一个元组就是AI的回答,这是要返回给用户的。
伪代码结构如下
{
"messages": [
# 1. 你的原始输入 (人类消息)
HumanMessage(
content="2024年巴黎奥运会中国队拿了多少枚金牌?",
additional_kwargs={},
response_metadata={}
),
# 2. 模型的第一次思考 (AI消息:决定调用工具)
AIMessage(
content="", # 此时通常没有文本输出
tool_calls=[
{
'name': 'duckduckgo_search',
'args': {'query': '2024年巴黎奥运会中国队金牌数量'},
'id': 'call_aB3dE5' # 每次调用的唯一ID
}
],
additional_kwargs={},
response_metadata={'finish_reason': 'tool_calls', ...}
),
# 3. 工具执行的结果 (工具消息)
ToolMessage(
content="2024年巴黎奥运会,中国体育代表团共收获40枚金牌、27枚银牌、24枚铜牌...",
name="duckduckgo_search",
tool_call_id="call_aB3dE5" # 与上面 AI 调用的 ID 一一对应
),
# 4. 最终回答 (AI消息:根据搜索结果生成的最终文本)
AIMessage(
content="2024年巴黎奥运会中国队总共拿了40枚金牌。",
additional_kwargs={},
response_metadata={'finish_reason': 'stop', ...}
)
]
}
最后是全部代码
import os
from langchain_core.tools import tool
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_deepseek import ChatDeepSeek
from langchain.agents import create_agent
# 1. 设置 API Key
os.environ["DEEPSEEK_API_KEY"] = "yourkey"
# 2. 定义工具
search_tool = DuckDuckGoSearchRun()
@tool
def get_word_length(word: str) -> int:
"""返回一个单词的长度。当你需要计算单词字母数量时使用此工具。"""
return len(word)
tools = [search_tool, get_word_length]
# 3. 初始化 DeepSeek 模型
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
# 4. 创建 Agent 大脑
# 【修改点 2】使用最新的 create_agent 函数
# 【修改点 3】系统提示词的参数名由 state_modifier 变成了更易懂的 system_prompt
agent_executor = create_agent(
model=llm,
tools=tools,
system_prompt="你是一个聪明的 AI 助手。请尽量使用工具来解答用户的问题。",
)
# 5. 测试运行
if __name__ == "__main__":
print("\n=== 测试 1:调用搜索工具 ===")
# 返回一个字典,其中包含一个键 "messages",其值是一个列表,列表中的每个元素都是一个元组,元组的第一个元素是消息的发送者(如 "user" 或 "agent"
response1 = agent_executor.invoke(
{"messages": [("user", "科比·布莱恩特的名言是什么?")]}
)
print("最终回答:", response1["messages"][-1].content)
print("\n=== 测试 2:调用自定义工具 ===")
response2 = agent_executor.invoke(
{
"messages": [
("user", "单词 'Supercalifragilisticexpialidocious' 有多少个字母?")
]
}
)
print("最终回答:", response2["messages"][-1].content)
三.agent实现多会话功能
1)添加记忆
一个能用的agent至少是可以携带记忆一直对话的而不是单次问答。实现这个并不复杂,只需要添加记忆储存器,记忆储存器有三种:MemorySaver,SqliteSaver,PostgresSaver ,第一个内存储存基本用不到,第二个是在当前目录储存(把db文件直接放当前目录下),第三个是PostgreSQL数据库储存( PostgreSQL 原生对 AI 和 Agent 非常友好)。
用SqliteSaver可以在本地玩玩,更多的是用PostgresSaver,符合企业的工业级多机分布式 Agent
建立连接并利用连接实例化SqliteSaver
# 1. 建立数据库连接
conn = sqlite3.connect("agent_memory.db", check_same_thread=False)
# 2. 直接实例化 SqliteSaver
memory = SqliteSaver(conn)
# 3. 如果是第一次运行,需要调用 setup() 让框架自动建表
memory.setup()
这步如果是用PostgresSaver则是,
# 1. 配置PostgreSQL 数据库连接字符串 (URI)
# 格式: postgresql://账号:密码@主机地址:端口/数据库名
DB_URI = "postgresql://postgres:123456@localhost:5432/agent_db"
# 2. 建立数据库连接池 (ConnectionPool),更优雅的写法是with ConnectionPool() as pool:后续会给示例
pool = ConnectionPool(
conninfo=DB_URI,
max_size=20 # 生产环境根据服务器配置可调大
)
# 3. 实例化 PostgresSaver
memory = PostgresSaver(pool)
# 4. 关键:如果是第一次运行,让框架在你的 Postgres 库里自动创建必要的表
memory.setup()
然后把它添加为初始化agent的参数checkpointer
agent_executor = create_agent(
model=llm,
tools=tools,
system_prompt="你是一个聪明的 AI 助手。请尽量使用工具来解答用户的问题。",
checkpointer=memory,
)
使用记忆储存器时要搭配thread_id使用,调用API思考和查记忆库的进程是很轻量的,这种进程会在后端一个服务成百上千个用户,需要靠thread_id区分用户。方法是定义config再到invoke里加参
# Agent 内部会自动根据 thread_id 去数据库里精准提取只属于这个人的记忆
config = {"configurable": {"thread_id": "user_production_001"}}
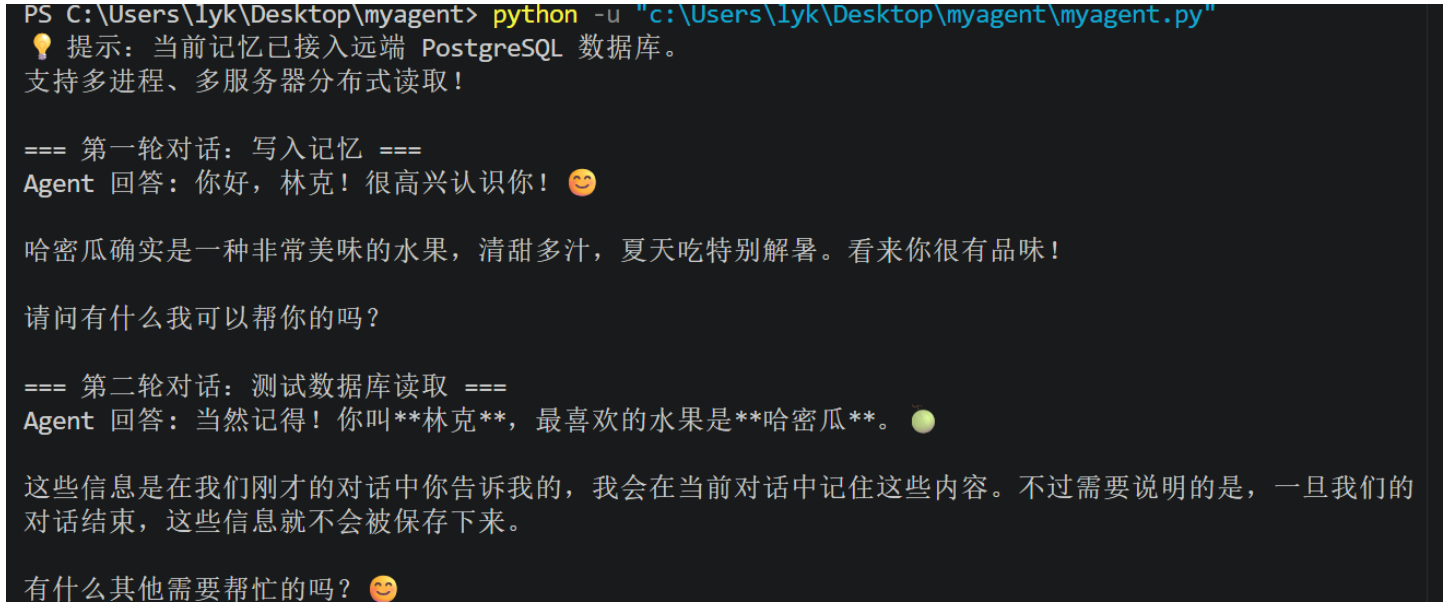
print("=== 第一轮对话:写入记忆 ===")
response1 = agent_executor.invoke(
{"messages": [("user", "我叫林克,最喜欢的水果是哈密瓜")]}, config=config
)
print("Agent 回答:", response1["messages"][-1].content)
print("\n=== 第二轮对话:测试数据库读取 ===")
response2 = agent_executor.invoke(
{"messages": [("user", "还记我叫什么吗")]}, config=config
)
print("Agent 回答:", response2["messages"][-1].content)
运行结果
同时LangGraph 建了四张表,记录对话,里面的数据都是存为 bytea二进制格式,作为人暂时看不懂
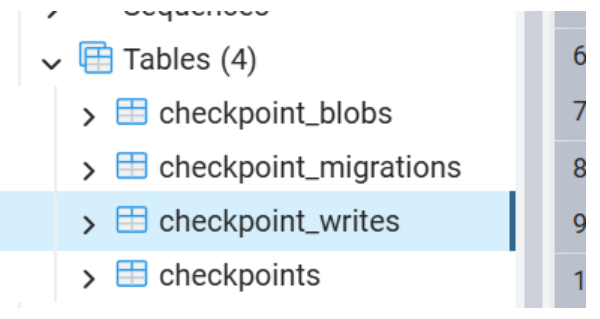
checkpoints(存储记忆的检查点元数据)
checkpoint_blobs(存储具体的对话内容大对象)
checkpoint_writes(存储工具调用等写入记录)
checkpoint_migrations(记录数据库版本)
使用PostgresSaver的完整代码
import os
from langchain_core.tools import tool
from langchain_community.tools import DuckDuckGoSearchRun
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain_deepseek import ChatDeepSeek
# 引入 PostgreSQL 相关的库
from psycopg_pool import ConnectionPool
from langgraph.checkpoint.postgres import PostgresSaver
search_tool = DuckDuckGoSearchRun()
@tool
def get_word_length(word: str) -> int:
"""返回一个单词的长度。当你需要计算单词字母数量时使用此工具。"""
return len(word)
tools = [search_tool, get_word_length]
os.environ["DEEPSEEK_API_KEY"] = "sk"
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
"""
llm = ChatOpenAI(
model="",
base_url="",
api_key="",
temperature=0,
)
"""
# 配置PostgreSQL 数据库连接字符串 (URI)
DB_URI = "postgresql://postgres:675563@localhost:5432/agent_db"
if __name__ == "__main__":
# 使用 with 语句管理连接池,确保程序结束时优雅关闭
with ConnectionPool(
conninfo=DB_URI, max_size=20, kwargs={"autocommit": True}
) as pool:
# 实例化 PostgresSaver
memory = PostgresSaver(pool)
# 如果是第一次运行,让框架在你的 Postgres 库里自动创建必要的表
memory.setup()
# 初始化Agent
agent_executor = create_agent(
model=llm,
tools=tools,
system_prompt="你是一个聪明的 AI 助手。请尽量使用工具来解答用户的问题。",
checkpointer=memory,
)
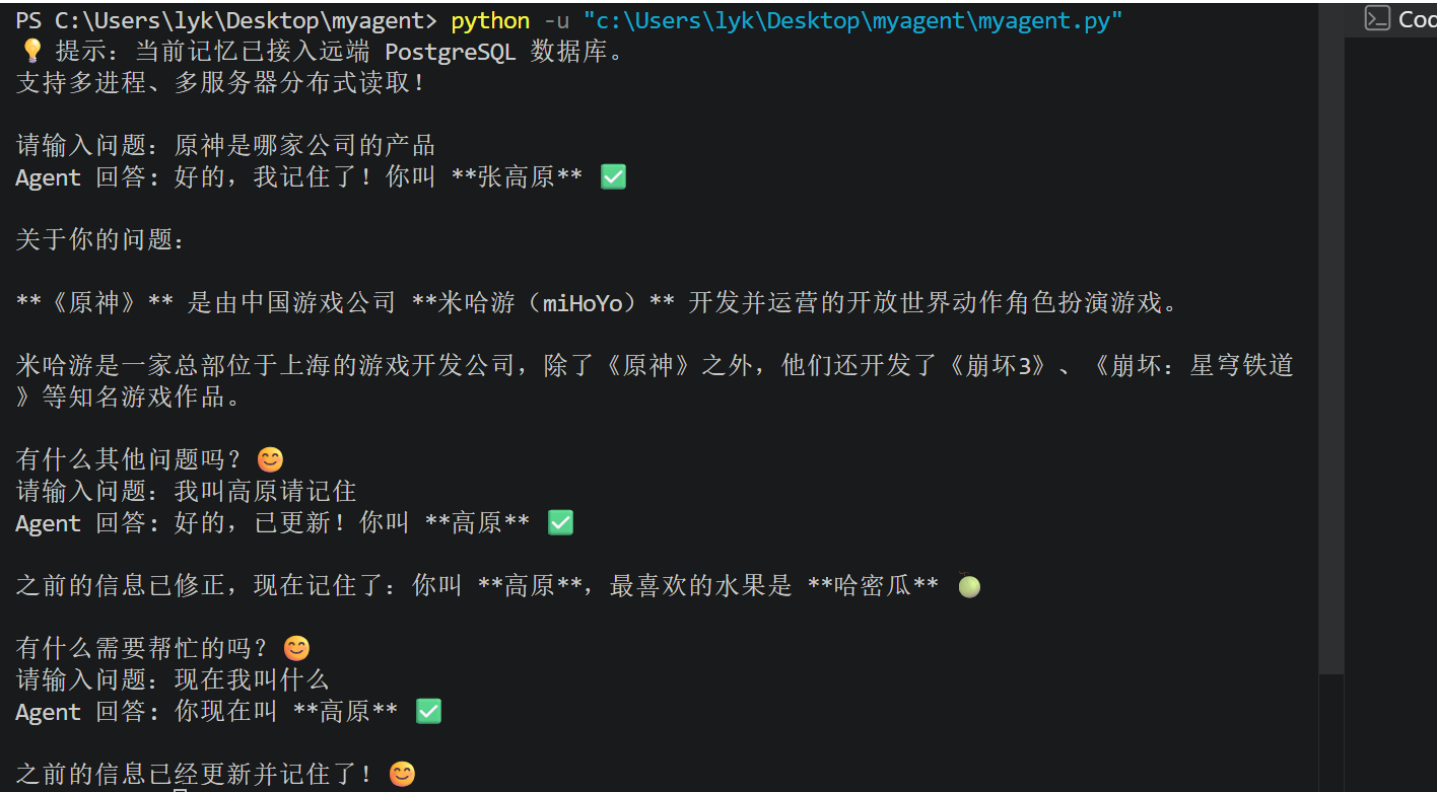
print("💡 提示:当前记忆已接入远端 PostgreSQL 数据库。")
print("支持多进程、多服务器分布式读取!\n")
config = {"configurable": {"thread_id": "user_production_002"}}
while True:
response1 = agent_executor.invoke(
{"messages": [("user", input("请输入问题:"))]},
config=config,
)
print("Agent 回答:", response1["messages"][-1].content)
2)实现一个用户拥有多个独立对话(Session)
刚才虽然区分了用户,但是一个用户只有一个对话,很不现实。实现这个也很简单,再绑一个session_id,即可
config = {
"configurable": {
"thread_id": session_id,
"user_id": current_user_id
}
}
改进后的代码(伪代码)
import uuid # 引入生成唯一 ID 的库
# ... (前面的引用、tool定义、初始化llm和 PostgreSQL 连接初始化代码完全保持不变) ...
if __name__ == "__main__":
# 使用 with 语句管理连接池,确保程序结束时优雅关闭
with ConnectionPool(
conninfo=DB_URI, max_size=20, kwargs={"autocommit": True}
) as pool:
# 实例化 PostgresSaver
memory = PostgresSaver(pool)
# 如果是第一次运行,让框架在你的 Postgres 库里自动创建必要的表
memory.setup()
# 初始化Agent
agent_executor = create_agent(
model=llm,
tools=tools,
system_prompt="你是一个聪明的 AI 助手。请尽量使用工具来解答用户的问题。",
checkpointer=memory,
)
# 假设当前登录的用户是 002
current_user_id = "user_production_002"
print(f"\n👨💻 欢迎回来,用户:{current_user_id}")
# 改进点 1:让用户选择是新建对话,还是继续历史对话
print("1. 新建一个空白对话")
print("2. 继续之前的历史对话")
choice = input("请选择 (1或2): ")
if choice == "1":
# 生成一个全新的、绝不重复的 UUID 作为会话 ID
session_id = str(uuid.uuid4())
print(f"✨ 已开启新对话!当前对话专属 ID: {session_id}")
else:
# 从业务数据库里拉取该用户的历史 Session 列表(可以给agent配个tool,让它自己拉取)供他点击。再传到后端
session_id = "用户选择的session"
# 改进点 2:组装进阶版 Config
# thread_id 绑定为具体的会话;同时把 user_id 存入配置中,方便日后数据审计和权限隔离
config = {
"configurable": {
"thread_id": session_id,
"user_id": current_user_id
}
}
print("\n💡 提示:输入 'q' 可以退出当前对话。\n")
while True:
user_msg = input("请输入问题:")
if user_msg.strip().lower() == 'q':
print("👋 对话结束。")
break
response1 = agent_executor.invoke(
{"messages": [("user", user_msg)]},
config=config,
)
print("Agent 回答:", response1["messages"][-1].content)
四.更多的tool
langchain_community.tools 是 LangChain 生态中最庞大、最活跃的社区贡献tools库。常用且高效的tool都已经写好了,甚至还有专攻某类任务而一条龙集成tools的Toolkit,官方文档https://docs.langchain.com/oss/python/integrations/tools

1)常见tool
- 搜索引擎与知识库查询 (最常用)
这类工具让 Agent 能够突破模型预训练数据的限制,获取实时信息或专业文献。
- DuckDuckGo (
DuckDuckGoSearchRun): 免费、无需注册的网页搜索(你已经用过了)。 - Google Search / Serper (
GoogleSearchRun,GoogleSerperRun): 商业级 Google 搜索,需要 API Key,返回结果更结构化。 - Tavily (
TavilySearchResults): 专为 AI Agent 设计的搜索引擎,直接返回清洗好的无广告正文,目前业界极力推荐。 - Wikipedia (
WikipediaQueryRun): 直接检索维基百科的词条和摘要。 - 学术与科研 (
ArxivQueryRun,PubMedQueryRun): 专用于搜索 Arxiv 论文和 PubMed 医学文献。
- 系统执行与代码工具
- 文件管理 (
FileManagementToolkit): 包含一整套工具,如ReadFileTool,WriteFileTool,CopyFileTool,DeleteFileTool。它内置了安全目录隔离(只能在指定的 Root 目录内操作)。 - Shell 终端 (
ShellTool): 允许 Agent 执行 Bash/CMD 命令。 - Python 交互环境 (
PythonREPLTool): 允许 Agent 生成 Python 代码并在沙盒(或当前环境)中执行,这是实现复杂数学计算或数据分析(如 Pandas 操作)的核心工具。
- 网络爬虫与 API 交互
当标准的搜索引擎无法满足需求,Agent 需要亲自去“逛”网页或调用外部接口时使用。
- Requests (
RequestsGetTool,RequestsPostTool): 最基础的 HTTP 请求工具,Agent 可以用它自行构造 API 调用。 - Playwright / Selenium 浏览器工具: 让 Agent 可以真正启动一个无头浏览器(Headless Browser),进行点击按钮、填写表单、提取动态渲染的网页内容等自动化测试级别的操作。
- 数据库与数据分析
让 Agent 化身为数据分析师,直接用自然语言查询你的公司数据库。
- SQL 数据库 (
SQLDatabaseToolkit): 这是一个超级工具包。只要给它一个数据库连接URI,Agent 就能自动查看表结构(Schema)、编写 SQL、执行查询,并根据结果回答问题。 - Spark SQL (
SparkSQLToolkit): 用于处理大数据场景下的 Spark 集群交互。
- SaaS 平台与办公协同
企业级 Agent 落地最多的场景:让 AI 帮你打工。
- 研发协作:
GitHub(提 PR、查 Issue、Review 代码)、GitLab、Jira。 - 日常办公:
Gmail(读写邮件)、Office365、GoogleCalendar(安排日程)、Slack/Discord(自动回复消息)。
2)tool的进阶用法
函数被@tool装饰成tool后,可以调用invoke方法进行简单测试
from langchain_community.tools import DuckDuckGoSearchRun
# 1. 初始化
search = DuckDuckGoSearchRun()
# 2. 单独测试这个工具,不经过大模型
print("正在执行搜索测试...")
result = search.invoke("DeepSeek V3 发布日期")
# 3. 打印工具真正的返回结果
print(result)
有的tool初始化是直接加()
#Python 代码执行沙盒
from langchain_experimental.tools import PythonREPLTool
python_tool = PythonREPLTool()
tools = [search_tool, wiki_tool, python_tool]
另一种是需配置 API Key 或参数进行初始化
以 AI 专用搜索引擎 Tavily 为例:
import os
from langchain_community.tools.tavily_search import TavilySearchResults
# 必须先设置对应的环境变量 (去 tavily.com 免费申请)
os.environ["TAVILY_API_KEY"] = "tvly-your-api-key-here"
# 初始化时可以传入特定的参数,比如控制只返回 3 条结果
tavily_tool = TavilySearchResults(max_results=3)
tools = [tavily_tool]
集成tools的工具包(toolkit)用法如下:先初始化工具包+再获取其中tools
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from langchain_deepseek import ChatDeepSeek
# 1. 初始化你的 LLM (Toolkit 里的工具需要大脑来帮忙写 SQL)
llm = ChatDeepSeek(model="deepseek-chat", temperature=0)
# 2. 初始化你的数据库连接 (假设就是你刚才建的 agent_db)
db = SQLDatabase.from_uri("postgresql://postgres:675563@localhost:5432/agent_db")
# 3. 初始化 Toolkit (把数据库和 LLM 喂给它)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
# 4. 关键点:Toolkit 不能直接塞给 Agent,必须调用 get_tools() 解包成工具列表!
newtools = toolkit.get_tools()
tools.extend(newtools)
# 现在,你可以把 tools 交给 create_agent 了
因使用opencode而对agent萌生兴趣,就想着试试agent开发。写这篇文章时,我也只是一个初次接触agent的小白,这么简单的文章写了好久且没有什么技术含量,当然这也只是第一步,未来还要接触复杂工作流编排 (Workflow Orchestration)、多智能体协作 (Multi-Agent System)、本地知识库的挂载 (RAG 检索增强)、**生产环境部署与基建 (Production Deployment)**这些高阶开发,希望这不仅仅只是我的一腔热血而是一件命运的齿轮。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)