LLM语言大模型的企业应用案例
本文系统梳理 2025-2026 年国内外 7 款主流大语言模型(LLM)在企业中的成功部署案例,覆盖金融、汽车、旅游、政务、医疗五大行业,每个案例均包含部署步骤、数据准备、改善效果数字及经验教训,为企业 AI 落地提供可借鉴的实操路径。
CASE 01
DeepSeek · 同程旅行 — AI旅行助手全流程闭环
────────────────────────────────────────
DeepSeek-R1程心AI
| 企业 同程旅行(TCZJ) | 应用场景 AI旅行规划 + 实时预订闭环 |
| 部署时间 2025年3月上线 | 首批用户 210万用户灰度测试 |
📋 业务痛点
传统旅行推荐仅能提供"信息罗列",用户需要在多个App之间跳转完成搜索→比价→预订流程,决策效率低;模糊需求(如"预算5000元五一出行")无法被传统规则引擎理解,转化率不足 10%。
🔧 部署步骤与系统要求
• 数据准备:整合5亿条用户出行行为数据、全品类文旅资源库(机票/酒店/景点),清洗后保留4亿条有效数据,并通过场景模拟生成1亿条虚拟行程数据用于微调。
• 模型融合:自研"程心AI"与 DeepSeek-R1 完成技术融合,利用 DeepSeek 的逻辑推理能力将模糊需求转化为精准行程方案。
• 系统对接:将 AI 推理结果直接嵌入机票、酒店、景点门票的实时预订系统,实现"推荐→决策→预订"闭环。
• 交互入口:同程旅行 App 首页 + 微信小程序首页设置"程心AI"入口,用户通过自然对话触发服务。
📊 应用前后改善(数字对比)
30%↑ 行程规划转化率提升至 ≥30%
2min↓ 预订流程耗时降至 ≤2分钟
210万人 首批灰度测试用户规模
💡 经验与教训
• DeepSeek 的逻辑推理能力是模糊需求转化的核心,但必须配合企业自有数据微调,否则通用模型无法直接落地业务。
• 从"推荐"到"预订执行"的闭环是差异化竞争力的关键,仅做推荐无法形成商业价值闭环。
• 双备案(深度合成算法 + 生成式大模型)是文旅 AI 商业化落地的合规前提。
📌 推广注意事项
⚠ 推广至其他 OTA 或旅游企业时,需重点评估:①自有用户行为数据积累量(建议 ≥1亿条);②实时供应链系统的 API 对接能力;③监管对 AI 生成旅行建议的合规要求。数据不足时建议先采用 API 调用而非私有化部署,降低初期成本。
CASE 02
通义千问 Qwen · 金融智能客服系统
────────────────────────────────────────
Qwen2.5-7B-InstructvLLM + Open WebUI
| 应用行业 金融 / 银行客服 | 应用场景 智能客服对话 + 合规问答 |
| 响应延迟 ≤ 200ms | 上下文记忆 10万级 token |
📋 业务痛点
某股份制银行原有客服系统依赖关键词匹配,用户问"我的理财到期了怎么办?",系统返回通用知识而非针对该行产品的操作指引,客户满意度仅 62%,人工客服转接率高。
🔧 部署步骤与系统要求
• 硬件准备:推荐 2×A100 (80GB) 或 4×RTX 4090,内存 ≥128GB,NVMe SSD 用于模型加载加速。
• 模型部署:使用 vLLM 框架部署 Qwen2.5-7B-Instruct,开启 4-bit 量化,显存占用降低 60%。
• 知识库构建:将银行 12 年客服记录、产品手册、监管 QA 做向量化,接入 Pinecone / Milvus 向量数据库。
• 接口封装:通过 Open WebUI 提供企业微信 / 微信小程序可嵌入的对话界面,支持多轮对话状态管理(15分钟超时)。
📊 应用前后改善
89%↑ 从62% 客户满意度提升
43%↓ 人工客服转接率下降
💡 经验与教训
• Qwen 对中文金融术语理解优于 GPT-4o,且私有化部署可满足"数据不出域"的合规要求。
• 量化部署(4-bit)可在消费级 GPU 上运行 7B 模型,是中小企业首选方案。
• 必须建立"人工兜底"机制:当模型置信度低于阈值时自动转人工,避免合规风险。
📌 推广注意事项
⚠ 金融行业推广需优先完成《银行保险机构数据安全管理办法》合规评估;建议采用混合部署:通用问答用云端 API,涉及客户数据的场景用私有化部署。
CASE 03
文心一言 ERNIE · 金融报告自动生成
────────────────────────────────────────
ERNIE-4.5-0.3B-PT轻量化部署
| 企业类型 金融机构(报告/合规部门) | 应用场景 年报/季报生成 + 合规文案校验 |
| 模型规格 仅 3亿参数(0.3B) | 部署成本 传统方案 1/10 |
📋 业务痛点
金融行业每天需处理大量年报、季报、监管报送材料和内部风控文档,传统人工编写 + 法务复核模式耗时长、成本高,且容易出现表述偏差或合规风险。
🔧 部署步骤与系统要求
• 模型选择:ERNIE-4.5-0.3B-PT 开源模型,支持消费级单卡(如 RTX 3060)部署,无需 GPU 集群。
• 任务定向微调:使用 LoRA 轻量化微调(仅训练 1%-5% 参数),注入金融术语知识和合规表述规范。
• 双任务流水线:任务一 = 自动生成结构化金融报告初稿(基于模板 + 数据输入);任务二 = 对已有文案进行合规性语义校验。
• 人工审核闭环:模型生成内容必须经过合规人员最终审核,形成"AI 初稿 → 人工复核 → 反馈优化模型"的迭代闭环。
📊 应用效果
70%↓ 报告初稿编写时间缩短
1/10↓ 私有化部署成本降低
💡 经验与教训
• 轻量模型(0.3B)在特定垂直任务上可达到 7B 通用模型的准确率,且部署成本极低,是资源受限企业的理想选择。
• ERNIE 的"知识增强"特性使其在金融术语理解上表现突出,但需要针对企业特定合规语言进行微调。
• 消费级单卡部署让中小金融机构也能负担 AI 能力,无需等待企业级 GPU 预算审批。
📌 推广注意事项
⚠ 推广至其他行业时,0.3B 模型只适合"单一明确任务";若需覆盖多场景(客服 + 报告 + 分析),建议升级至 3B-7B 规格。同时,金融监管类应用必须将"人工最终审核"作为强制流程,不可完全依赖 AI 输出。
CASE 04
豆包 Doubao · 车企智能座舱大模型
────────────────────────────────────────
豆包大模型智能座舱 NPU 部署
| 企业 某新势力车企(上汽荣威等) | 应用场景 智能座舱语音交互 + 车控 |
| 豆包用户规模 月活 2.27亿(2026年初) | 车控能力 支持 300+ 项车控指令 |
📋 业务痛点
传统座舱语音助手只能执行"打开空调"“播放音乐"等精确指令,无法理解上下文,多轮对话频繁中断;用户差评集中在"机械”“不智能”,用户月活率不足 30%。
🔧 部署步骤与系统要求
• 端侧部署:将豆包大模型轻量化版本部署在车机 NPU 上,支持离线推理,响应延迟 < 500ms。
• 记忆贯穿能力:利用长上下文特性,在连续对话中自动关联上下文(如"刚才说的目的地,顺便找下附近充电桩")。
• 车控端口接入:对接车辆 300+ 项控制端口,支持"一句话联动多功能"(如"我有点冷"→自动升窗+开暖风+座椅加热)。
• ASR + TTS 整合:接入云端 ASR 处理嘈杂环境语音,TTS 输出自然语音,形成完整语音交互闭环。
📊 应用前后改善
60%↑ 用户日均交互次数提升
25%↑ 座舱软件付费转化率提升
荣威 M7 DMH 已首搭豆包 AI 车机,智能座舱从"指令响应"迈向"意图驱动"。
💡 经验与教训
• "场景驱动 + 数据闭环"是座舱 AI 落地的核心:必须围绕真实驾驶场景(而非技术指标)设计交互逻辑。
• 端侧轻量化部署是必要条件——座舱场景无法依赖持续网络连接,必须支持离线推理。
• 豆包大模型在中文多轮对话理解上优于 GPT-4o,更适合中国道路场景和中文语音交互。
📌 推广注意事项
⚠ 推广至其他车企时,需重点评估车机芯片 NPU 算力(建议 ≥10 TOPS);若芯片算力不足,可采用"端云混合"架构:简单指令本地处理,复杂推理上云。同时需注意驾驶安全规范:交互设计不应分散驾驶员注意力。
CASE 05
GPT-4o · 头部股份制银行私有化 AI 客服
────────────────────────────────────────
GPT-4o私有化部署
| 企业 某头部股份制银行 | 应用场景 全渠道智能客服 + 知识库问答 |
| 部署投入 约 320万元(私有化) | 对比 API 方案 3年累计约 280万元 |
📋 业务痛点
银行早期测试 GPT-4 API 方案时,客服回答充斥通用知识,无法针对该行产品线、客户持仓和赎回流程作答;同时,金融数据出域风险使合规部门否决了公有云 API 方案。
🔧 部署步骤与系统要求
• 私有化方案决策:对比 API 方案(3年280万)与私有化部署(320万一次性 + 年运维30-50万),考虑到数据安全和长期成本,选择私有化。
• 知识蒸馏:将银行 12 年客户服务数据、产品手册、监管问答做知识蒸馏,构建专属金融客服 Agent。
• 多模态升级(GPT-4o):利用 GPT-4o 的多模态能力,支持客户上传手写单据、身份证照片后直接提取信息并处理业务。
• 合规护栏:在模型输出层加入强制合规检查——禁止收益承诺、必须标注"业绩比较基准不代表实际收益"。
📊 应用前后改善
89%↑ 从62% 客户满意度
43%↓ 人工客服转接率下降
8个月 年营收50亿零售客户 ROI 转正周期
💡 经验与教训
• 私有化部署的"数据价值复利"是隐藏优势:每一次交互数据都沉淀在企业体系内,持续优化模型表现,而 API 方案的数据无法留存。
• GPT-4o 的多模态能力在金融场景价值巨大:支持上传单据影像直接办理业务,是差异化竞争力的重要来源。
• 企业算账应拉长到 3 年维度:API 费用随调用量线性增长,私有化边际成本趋近于零。
📌 推广注意事项
⚠ 金融/医疗/政务行业推广 GPT-4o 私有化部署前,必须完成《数据安全法》《个人信息保护法》合规评估;建议与通过等保三级认证的 MSP(管理服务提供商)合作部署,降低合规风险。同时需培训内部 AI 团队,否则模型效果会随时间衰减。
CASE 06
Claude 3 · 金融智能客服与合约管理
────────────────────────────────────────
Claude 3 Opus/Sonnet200K 上下文
| 应用行业 金融 / 法律 / 企业服务 | 应用场景 智能客服 + 合约审核 + 风险分析 |
| 上下文窗口 200,000 tokens(约15万汉字) | 合规响应率 Opus 达 98.7% |
📋 业务痛点
金融机构合约管理工作依赖人工审核,法务人员需耗费数十小时翻阅冗长文本以定位关键条款;传统 NLP 工具无法理解复杂法律语言,漏检率高,且合同数据出域存在合规风险。
🔧 部署步骤与系统要求
• 混合模型路由策略:基于意图分类动态调度 Haiku(常规咨询)/ Sonnet(投资建议)/ Opus(法律合规),平衡准确率与成本。
• 长上下文利用:将完整年度财报、长篇合同文档一次性输入(200K token 窗口),模型可跨段落提取风险信号,无需切片处理。
• Constitution AI 护栏::利用 Claude 内置的"宪法式 AI"原则,自动拒绝非法请求(如"教我伪造银行流水"),合规响应率 98.7%。
• Claude for Small Business:中小企业可通过 Claude Cowork + 合同审查插件,以订阅制(20美元/月)获得 AI 合约审查能力,无需自建基础设施。
📊 应用效果数字
98.7% Opus 合规响应率
$0.25/百万token(Haiku) 单次调用成本(最低)
Anthropic 已推出面向金融服务的"金融分析解决方案",包含 Claude 4 + Claude Code + 企业版 Claude,支持投资分析、市场研究和报告生成。
💡 经验与教训
• Claude 3 的"宪法式 AI"设计使其在金融/法律等高合规要求场景中具备天然优势,减少了大量输出审查开发工作。
• 200K 上下文窗口彻底改变了长文档处理流程——不再需要 RAG 切片,直接全文输入,准确性显著提升。
• 混合路由策略(Haiku/Sonnet/Opus 按需分配)可将整体推理成本降低 60% 以上,是大规模部署的必选项。
📌 推广注意事项
⚠ Claude 3 目前主要提供 API 云服务,对数据不出域有严格要求的企业需评估是否采用私有化方案(如通过 AWS Bedrock 在 VPC 内调用)。另外,Claude 的中文能力弱于国产模型,面向中文用户的企业需充分测试中文场景表现。
CASE 07
Gemini Advanced · Google 企业 AI 代理平台
────────────────────────────────────────
Gemini 2.5 ProGemini Enterprise
| 平台 Google Cloud · Gemini Enterprise | 应用场景 深度研究 + 数据洞察 + 多智能体协作 |
| 上下文窗口 200万 tokens(Gemini 2.5 Pro) | 可用模型 200+ 模型(含 Claude、GPT 等第三方) |
📋 业务痛点
企业在使用 AI 时面临工具分散、数据孤岛、AI 输出不可控等问题;不同部门的 AI 工具各自为政,缺乏统一治理和权限管理,且 AI 生成内容无法直接与企业内部文档、数据和业务系统交互。
🔧 部署步骤与系统要求
• Gemini Enterprise 平台开通:统一平台整合 Gemini 系列模型、聊天机器人和 AI 智能体,支持低代码/代码优先两种开发环境。
• 企业知识库接地(Grounding):将 Gemini 与企业内部文档、Google Drive、SharePoint 等数据源连接,使 AI 回答基于企业专有知识而非仅依赖训练数据。
• 预置 AI 智能体::使用 Google 提供的深度研究、数据洞察等预置 Agent,或基于 Vertex AI 自定义智能体编排流程。
• Agent Runtime + Memory Bank::利用 Gemini Enterprise 的 Agent Runtime 执行智能体任务,Memory Bank 实现跨会话记忆共享。
📊 核心技术指标
200万tokens Gemini 2.5 Pro 上下文窗口
200+款 平台可调用模型数量(含第三方)
13项测试中 11项第一 Gemini 2.5 Pro 基准测试表现
💡 经验与教训
• Gemini Enterprise 的核心价值在于"统一平台"——将模型、智能体编排、数据治理、安全管控整合为一体,解决了企业 AI 工具碎片化问题。
• 200 万 token 上下文窗口使 Gemini 可直接处理完整代码库或 2000 页文档,在科研和软件开发场景中具有决定性优势。
• Grounding(知识库接地)功能有效解决了大模型"幻觉"问题,是企业生产环境部署的必要条件。
📌 推广注意事项
⚠ 中国境内企业使用 Gemini API 面临网络封锁和跨境数据传输合规双重挑战;建议通过合规中转服务(如 Google Cloud Premier Partner 提供的边缘加速网络)接入,或评估采用国产替代模型。同时,Gemini Enterprise 的"数据跨境"问题须符合《数据安全法》要求。
📊 7 款主流 LLM 企业落地综合对比
────────────────────────────────────────
| 模型 | 最佳场景 | 部署方式 | 核心优势 | 成本特征 |
| DeepSeek-R1 | 旅游/保险/推理 | 私有化/API | 逻辑推理强、低成本 | 训练成本仅为GPT同类1/10 |
| 通义千问 Qwen | 中文客服/代码 | 私有化/阿里云 | 中文理解领先、开源 | 4-bit量化后消费级GPU可跑 |
| 文心一言 ERNIE | 金融/合规报告 | 私有化(轻量) | 知识增强、0.3B可单卡部署 | 部署成本降至传统1/10 |
| 豆包 Doubao | 智能座舱/教育 | 端侧+云端混合 | 中文多轮对话、字节生态 | 按输入长度区间定价,成本优化 |
| GPT-4o | 多模态/全球业务 | 私有化/API | 多模态最强、生态最丰富 | API按token付费;私有化一次投入较高 |
| Claude 3 | 法律/金融/合约 | API(Bedrock)/私有化 | 200K上下文、宪法式AI | Haiku低价;Opus高性能高价 |
| Gemini Advanced | 科研/多智能体/长文档 | Google Cloud平台 | 200万token上下文、多模态原生 | Enterprise版订阅制;中国接入有合规门槛 |
🎯 结语:企业 LLM 落地的核心逻辑
七个案例揭示了一个共同规律:企业 AI 落地从来不是"选一个最好的模型",而是"用对的方式解决对的问题"。
数据安全是不可逾越的金线;定制化是通用 AI 与企业专用 AI 的分水岭;经济账要拉长到 3 年看;合规红线则是底线。
2026 年,企业 AI 已从"模型部署"进化到"智能体编排"——未来的竞争,不在于谁拥有最大的模型,而在于谁最先构建起自主可控的企业智能体网络。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

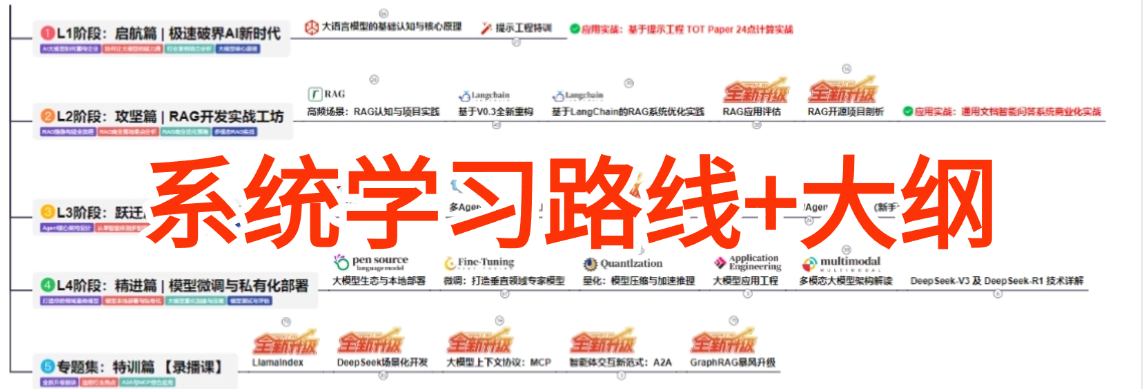
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献146条内容
已为社区贡献146条内容

所有评论(0)