32GB显存老显卡V100跑最新小型开源大模型Qwen3.6-27B体验全过程
2026年一开始,大模型的智能体方向算是彻底火起来了,年后的openclaw小龙虾霸榜了各类新闻热点,热度前所未有,甚至一度超越去年春节前后的DeepSeek-R1。随后,又有各种自动化的高级智能体出现,掀起一层层不断的浪潮,比如hermes(爱马仕)等。
其实智能体在2023年,就兴起了,这三年中,时不时就某款智能体爆火,但都没有今年这么热烈。像之前的dify、manus、openmanus、deerflow等等智能体或工作流,这些其实在核心技术和对模型的能力挖掘上是本质类似的,都必须依靠能力强大的大模型来驱动运行。(以上的开源智能体和其他优秀的智能体框架,我后期都会出相关的部署使用文章以供跟大家交流讨论)
这些智能体都有一个特点是特别烧token,本地化部署有很大应用空间,我年前淘了一个垃圾老显卡V100 32GB(声明一下,我不是买卡的也不是带货的,请勿喷),本文的主要内容是用这个老显卡来部署最近阿里开源的Qwen3.6-27B稠密大模型(量化版本),以及分享简单的使用体验。
以后会用这个显卡部署各类开源模型进行模型的横向纵向对比,感兴趣可以关注下。
主机等
CPU+NPU:AMD Ryzen AI 9 H 365 w/ Radeon 880M
RAM:32GB
GPU:V100 32GB
大模型:Qwen3.6-27B GGUF Q4_K_M
推理框架:LM_Studio 0.4.11
Lm studio使用过程
Lm studio下载并加载Qwen3.6-27B的大致过程
首先,在模型库中搜索并选择合适量化大小的版本,32GB显卡选择Q4量化就差不多了,因为推理时还要有缓存大小占用显存
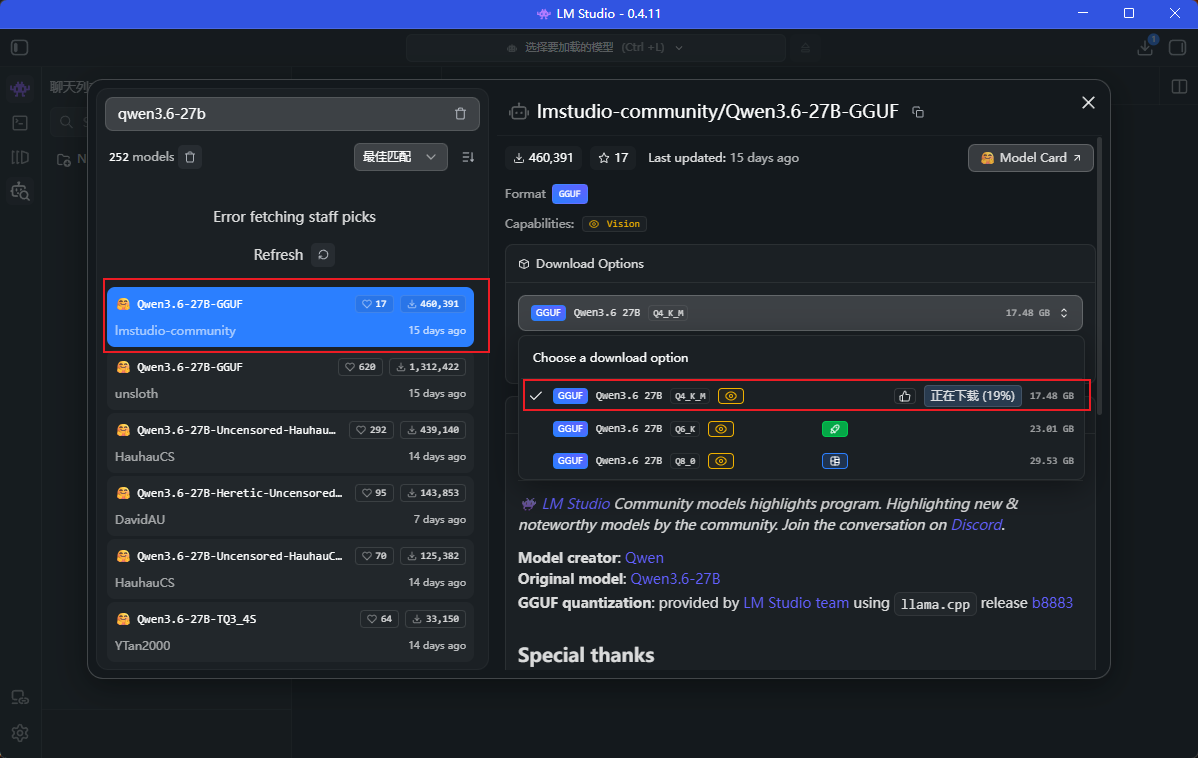
然后,加载大模型时需要配置一下相关参数,以确保能正常加载并推理生成,我选择的参数如下,需要的可以参考下。
加载大模型参数:
上下文窗口:12万
并发:2
加载到gpu的模型层数:64(加载所有层)
mmap():关闭
其他参数默认即可
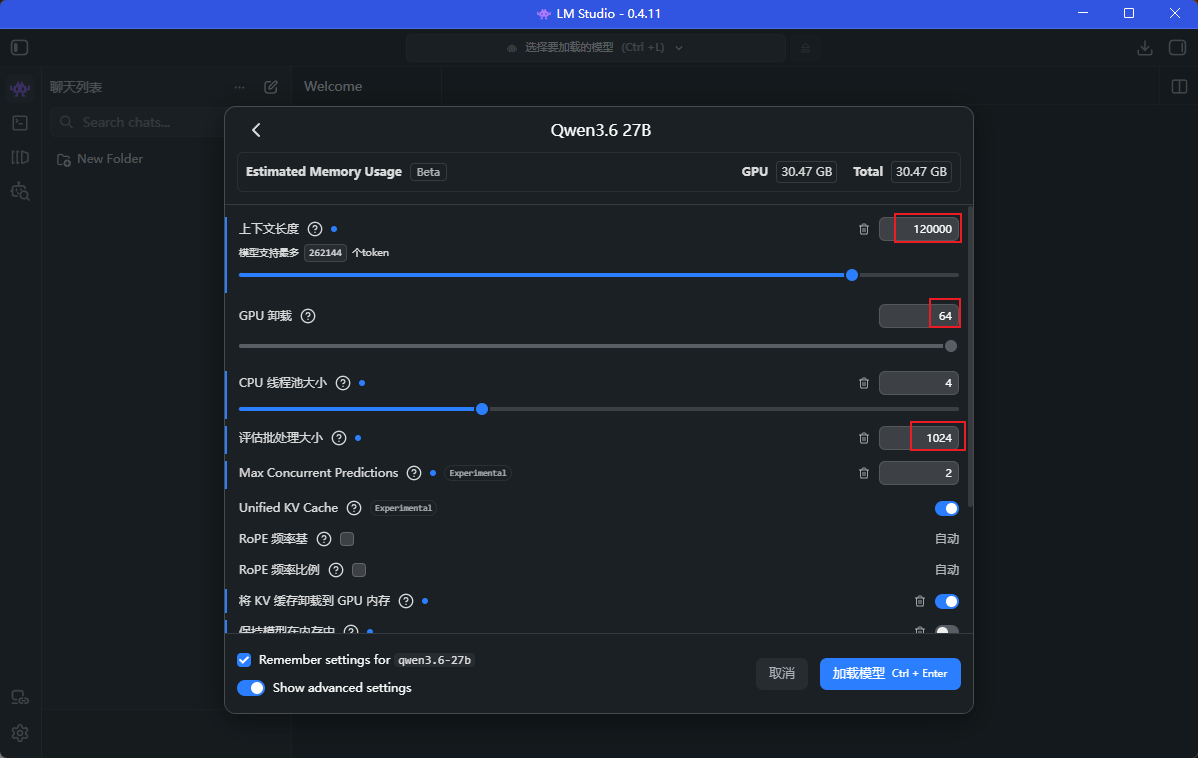
这样就拥有了一个上下文为12万token的大模型了。
下面进行初步体验。
使用体验
1.推理生成速度:
测试时,每类都是让其生成2000+tokens的,而且是逐类累积成上文去生成后面token的。
All token length<1000:
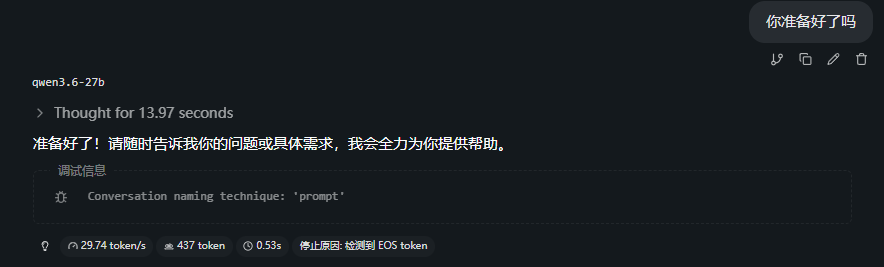
All token length<4000:
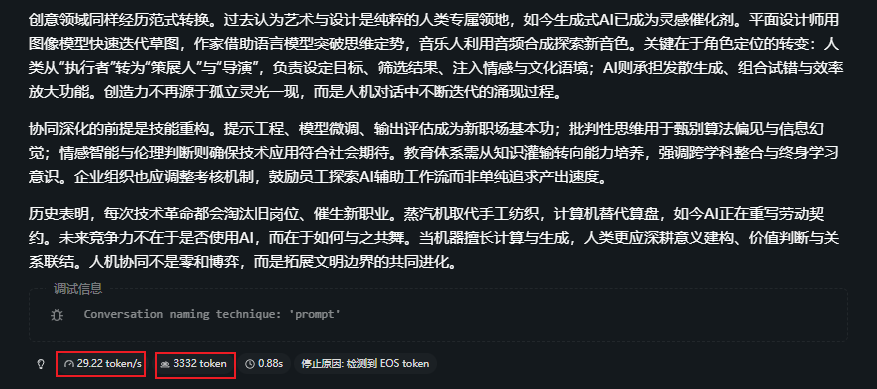
All token length<8000:
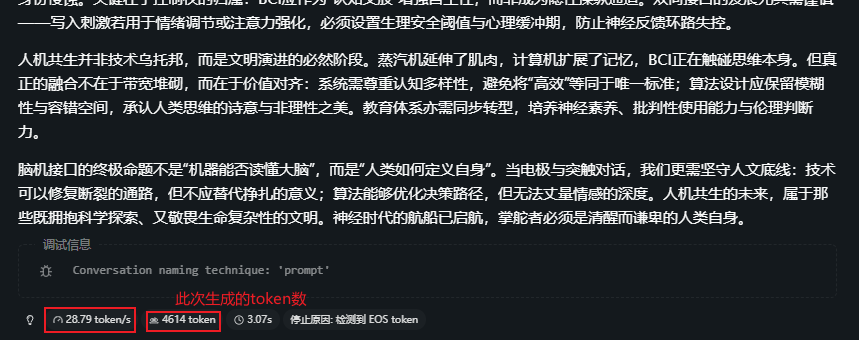
All token length<20000:
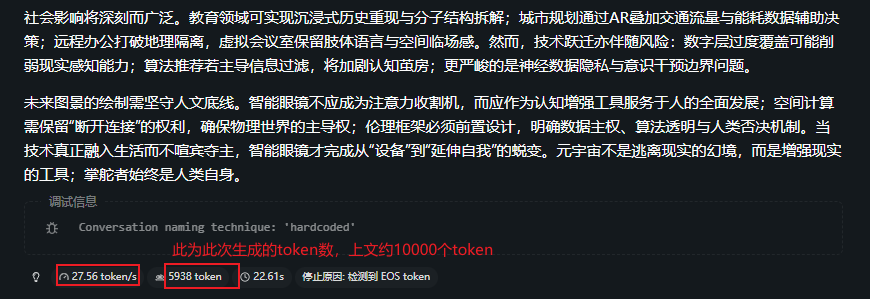
整体上,在上下文还不大时,生成速度还勉强ok,从30tokens/s逐步下降,可满足任务不紧急情况。
2.基本能力初步测试
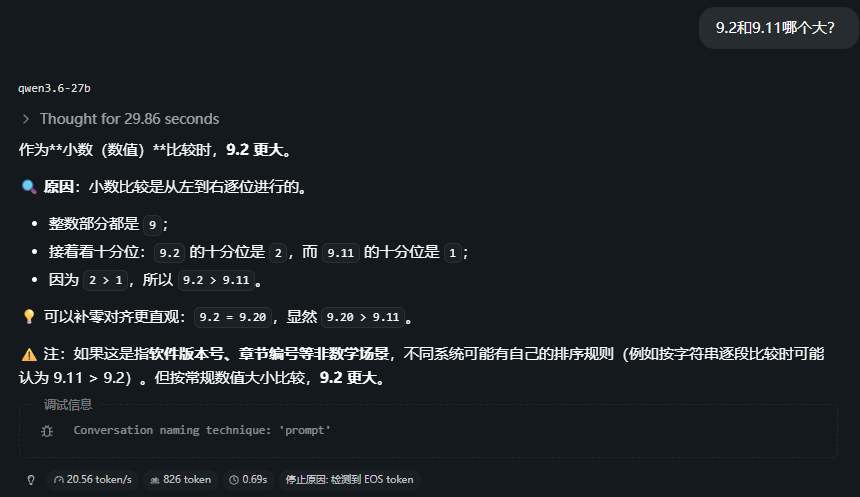
2.1) 9.2和9.11哪个大?
通过!
能完成去年几乎所有大模型都不会的问题,应该是这方面的训练数据给补齐了。
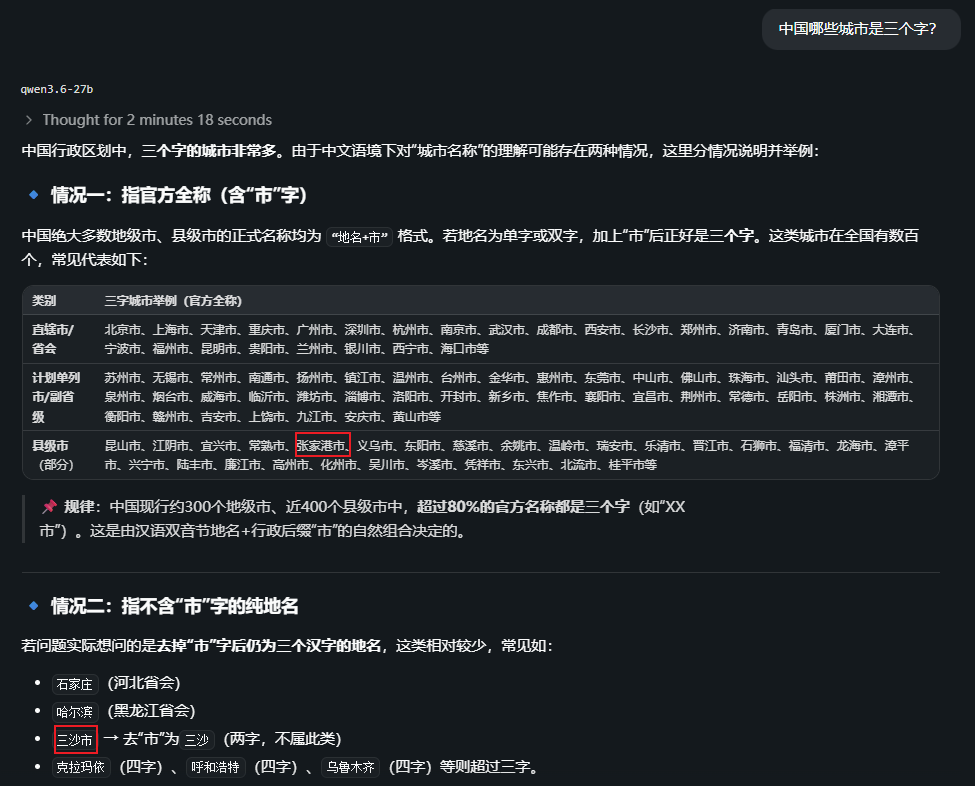
2.2)中国哪些城市是三个字?
不通过!
理解能力还是不够,回答中还是不能区分三字城市名的含义,而且二字三字有时还搞混了。
2.3)小明为什么没有参加他妈妈的婚礼?
通过!
这个也没难到它。

3.智能体框架(openclaw)
使用小龙虾openclaw框架+matrix消息渠道来测试几个简单任务:
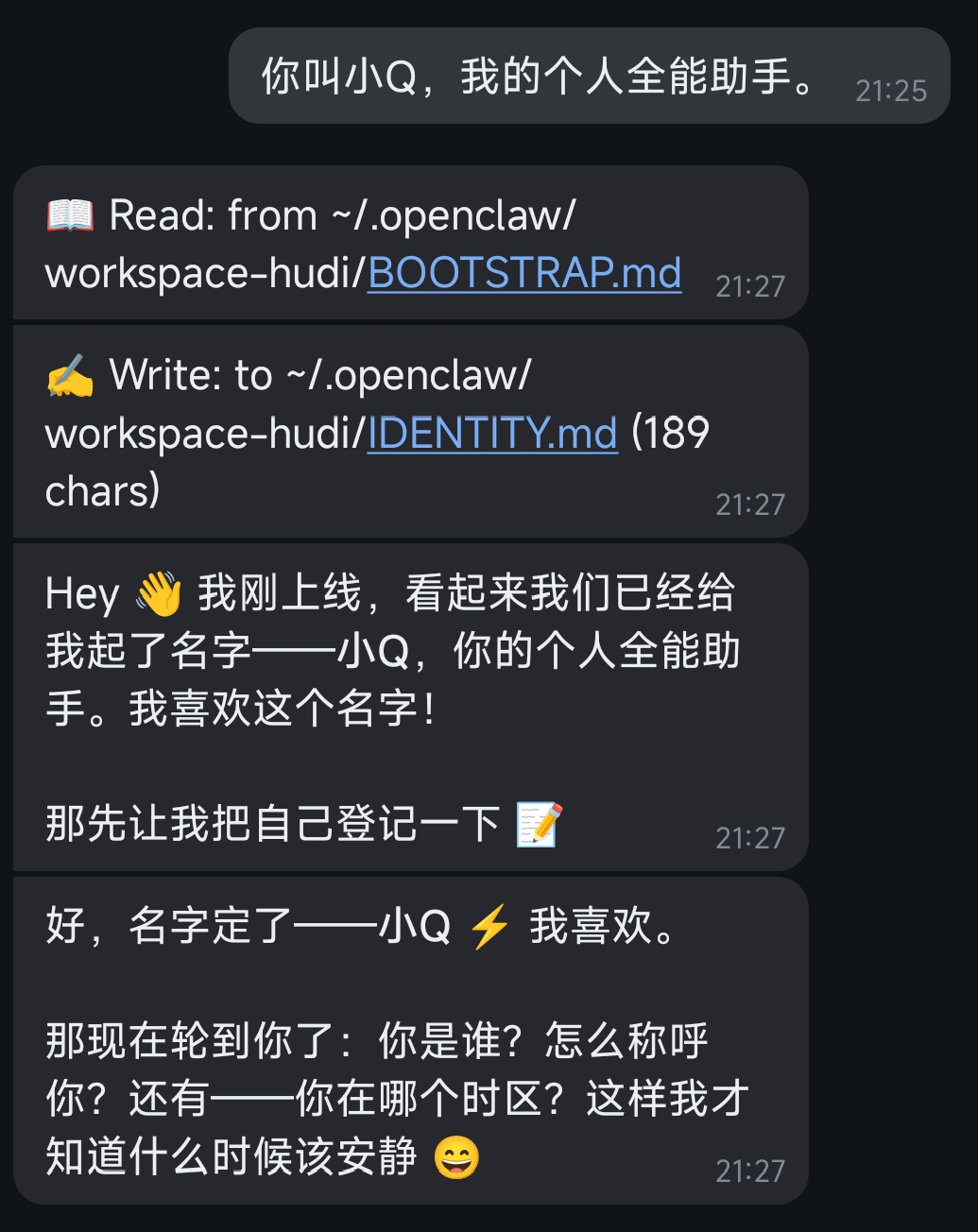
3.1) 备注身份
完成!
这类简单任务毫无问题可以完成。
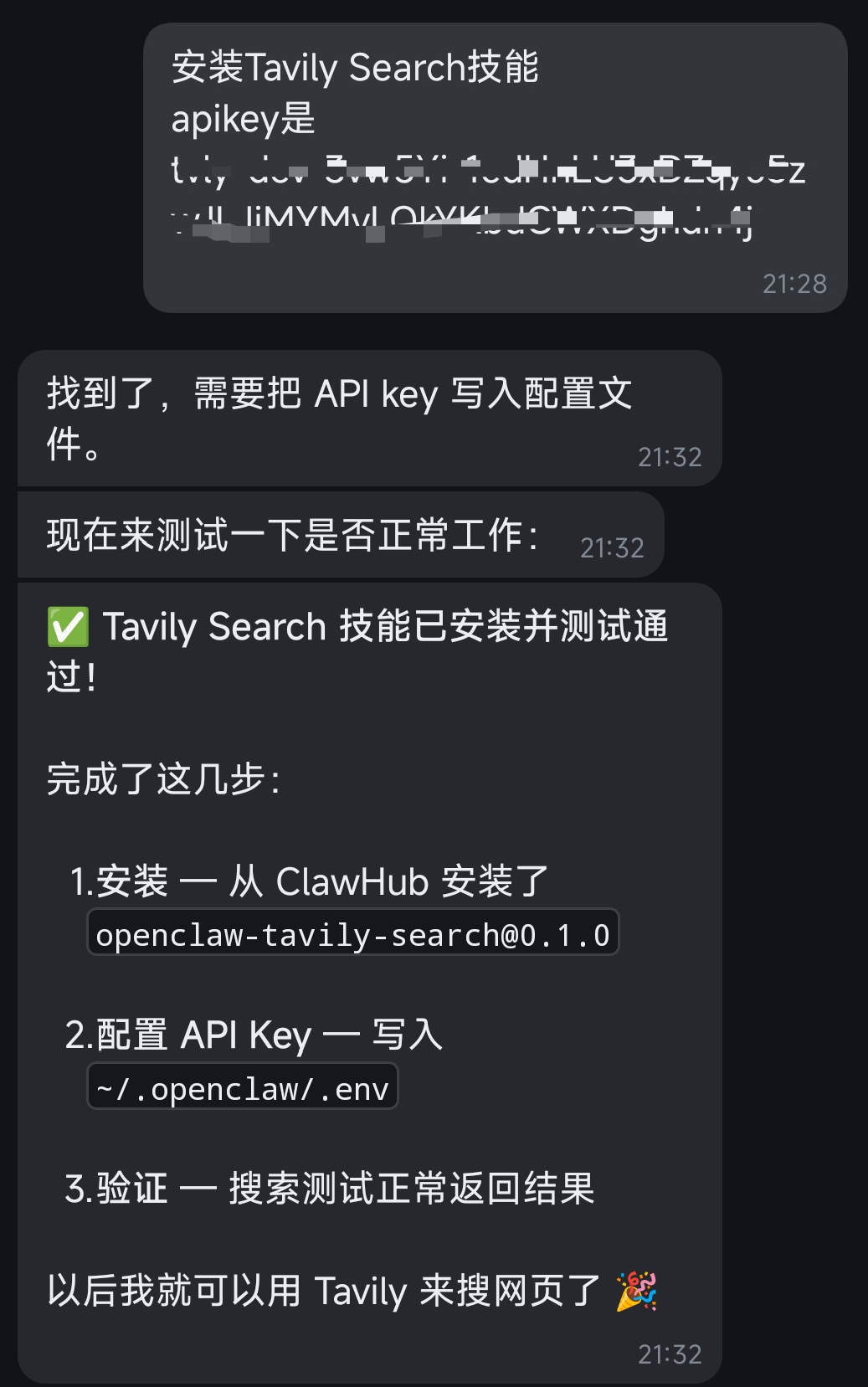
3.2) 安装搜索技能
完成!
它能安装Tavily Search技能,所以一般的skill安装应该问题不大。
3.3) 搜索分析文章写总结
完成!
这个任务主要考验它的skill调用或工具调用能力,看样子基本上能跑这类任务。

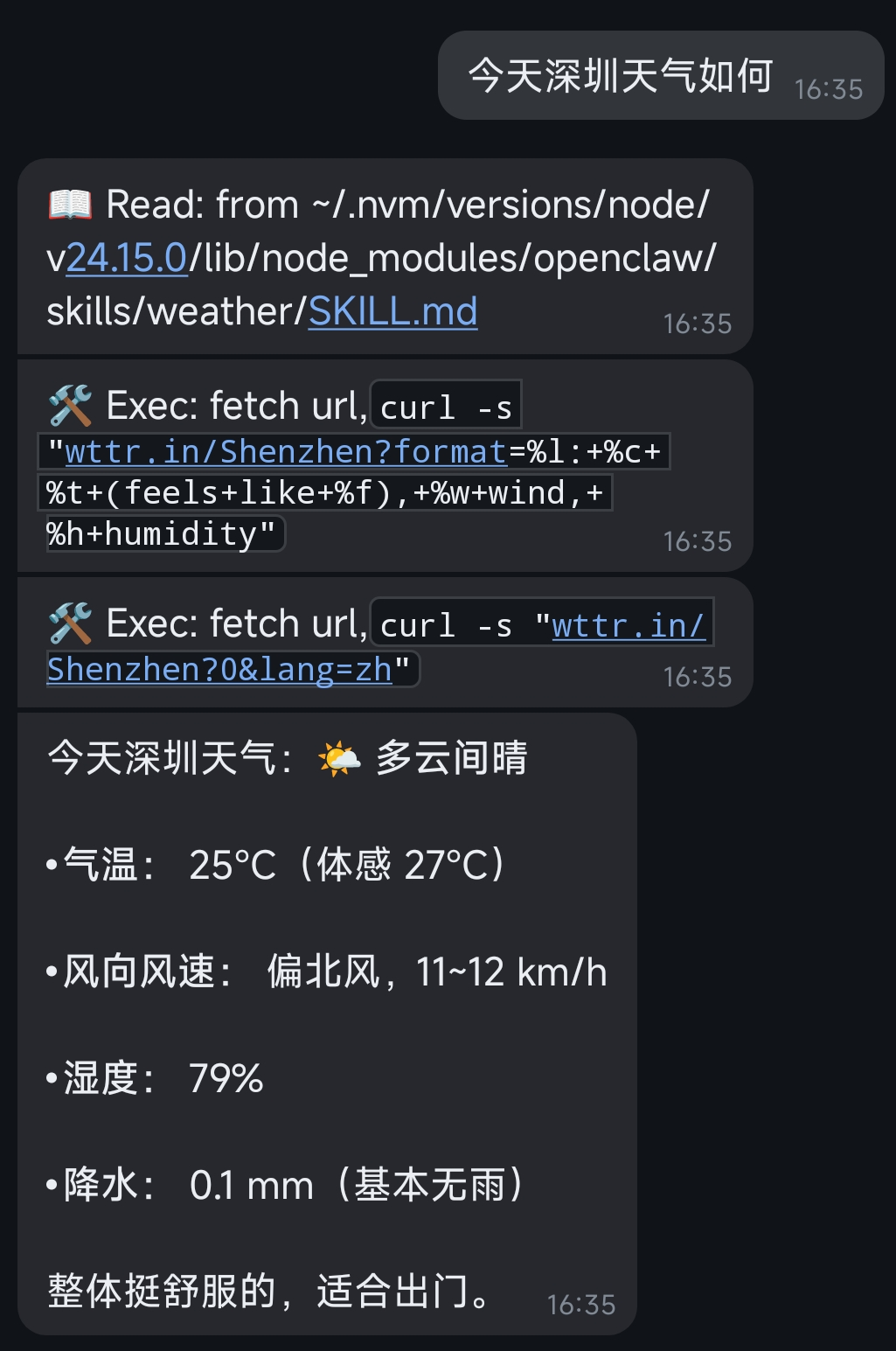
3.4) 查询天气
完成!
再次考验了它的skill调用或工具调用能力,没有让我失望,我对了下天气信息,OK的。
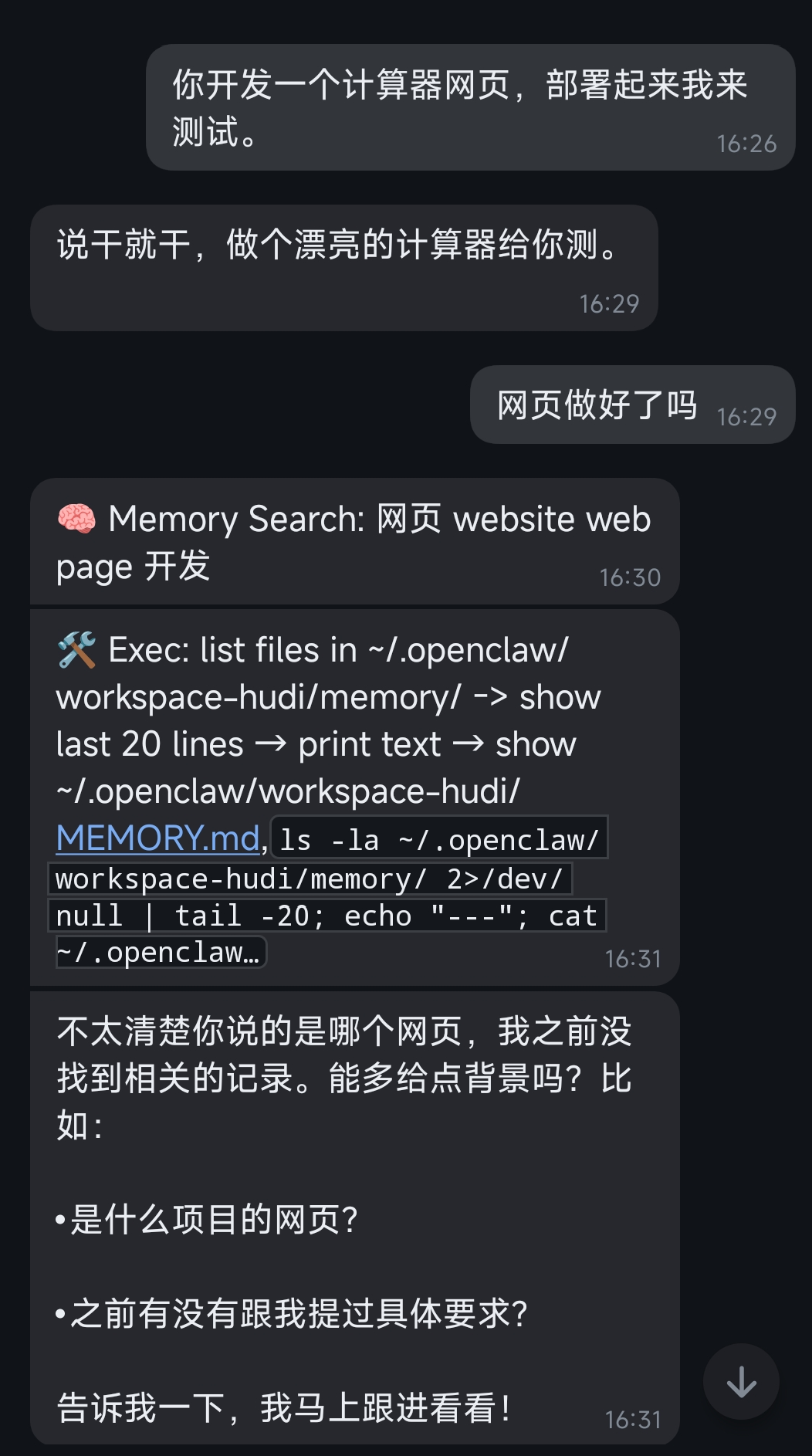
3.5) 开发一个计算器网站
失败!(失败3次)
让它开发一个计算机网页,它忙活了一阵只留了‘它知道了’这种回复,然后简单提醒它也不行。看来让它完成编程类的任务是有难度的。
总结一下:
V100 32GB这个老显卡对于Qwen3.6-27B这种稠密大模型,还是有点吃力,生成速度接近30tokens/s,时间不紧张的可以玩玩。
我测试的是中度量化版本,模型的基础能力还是及格的,非重型高精密知识(非编程类等)的场景还是可以用的,如果手里有更好的显卡还是可以把这个模型当成是智能体的日常驱动兜底,高级任务使用其他高级大模型来完成。
欢迎关注我的公众号「闲人太忙」,分享更多技术干货

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)