大模型时代的基础架构:大模型算力中心建设指南
本文深入探讨了GPU硬件架构,特别是Nvidia GH100芯片的设计,以及DGX服务器的组成和NVLink互连技术。文章还详细介绍了GPU集群的网络设计,包括RoCE计算网络、存储与业务网络的构建,以及网络虚拟化技术如SDN和NFV的应用。此外,文章还讨论了分布式块存储、对象存储和并发高性能存储系统的设计与实现,最后介绍了机器学习应用开发与运行平台的设计,以及基于云平台的GPU集群管理与运营策略。
DGX“更”适合单机部署,价格百万级。大规模GPU集群还是通过各家定制化服务器,自研组网构成
第3章 GPU硬件架构剖析
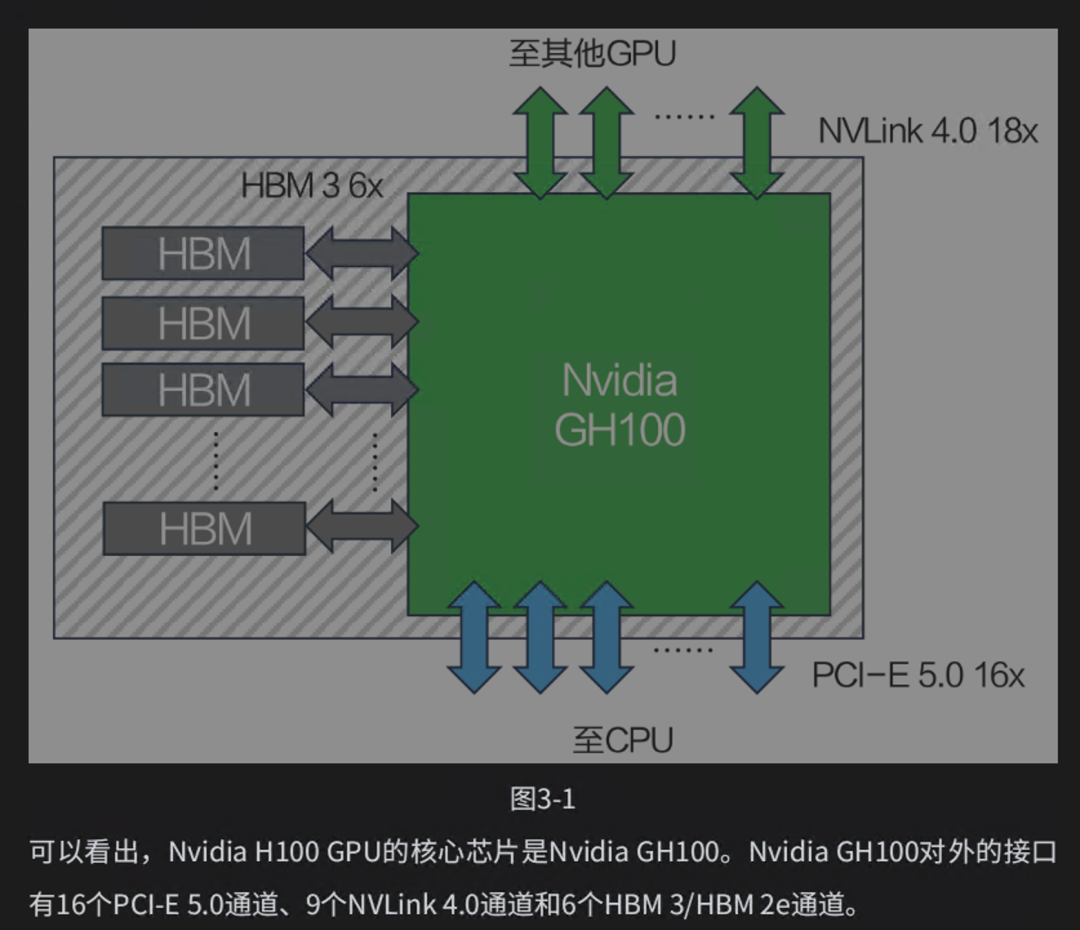
3.4 本章小结
GPU之所以能够用来支撑机器学习程序的高效运行,其根本原因是GPU内部集成了大量的通用计算单元(如CUDA Core)和专用计算单元(如Tensor Core)。Nvidia各代产品的演进,实质上都是在增加计算单元的同时,优化计算单元并行工作的效率。
前面提到,要搭建一个为机器学习服务的计算系统,仅仅有GPU还是不够的,还需要CPU、主存(内存)、持久化存储及通信网络等一系列周边部件,才能够为GPU提供必要的控制、存储和输入输出支持。这就是涉及GPU服务器及其集群网络的设计。第4章将详细讲解如何设计和实现一台GPU服务器。
第4章 GPU服务器的设计与实现
4.1 初识Nvidia DGX
Nvidia DGX(或称“DGX Pod”)是Nvidia的GPU服务器品牌,整机支持8颗训练型GPU,每颗GPU都有对应的IB(InfiniBand)或RoCE(RDMA over Converged Ethernet)网卡,可以通过IB/RoCE交换机组建Nvidia DGX集群。
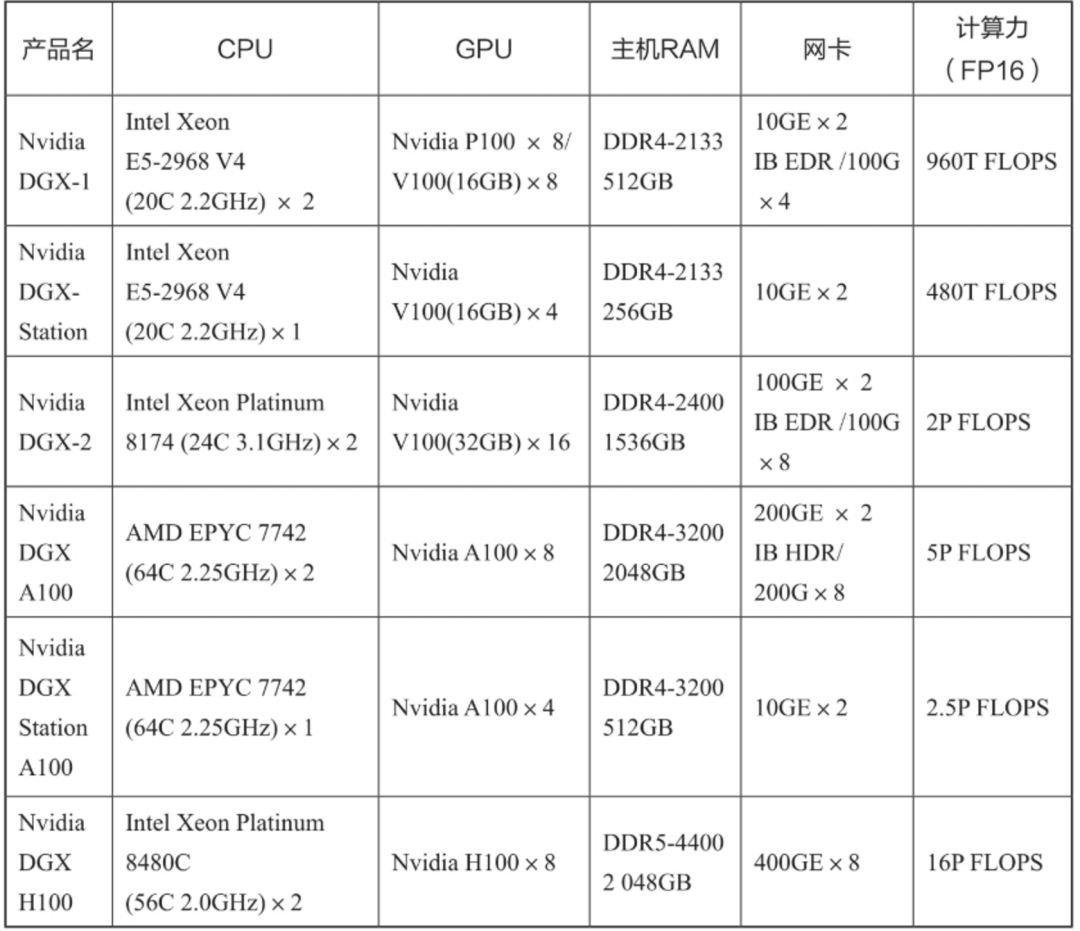
4.5 Nvidia DGX A100 NVLink子系统的设计
在大模型等训练场景中,对多颗GPU协同的技术需求催生了Nvidia DGX A100这样的具有多张GPU卡的服务器。在GPU的协同工作中,最常见的就是一个GPU访问其他GPU的内存,其数据流向如图4-9所示。
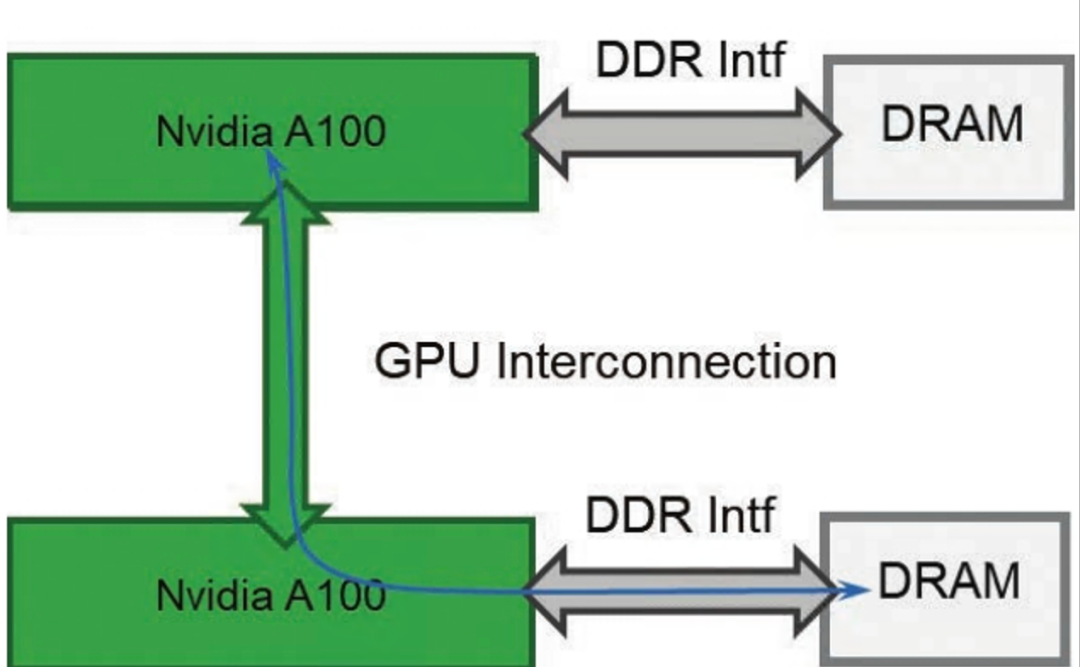
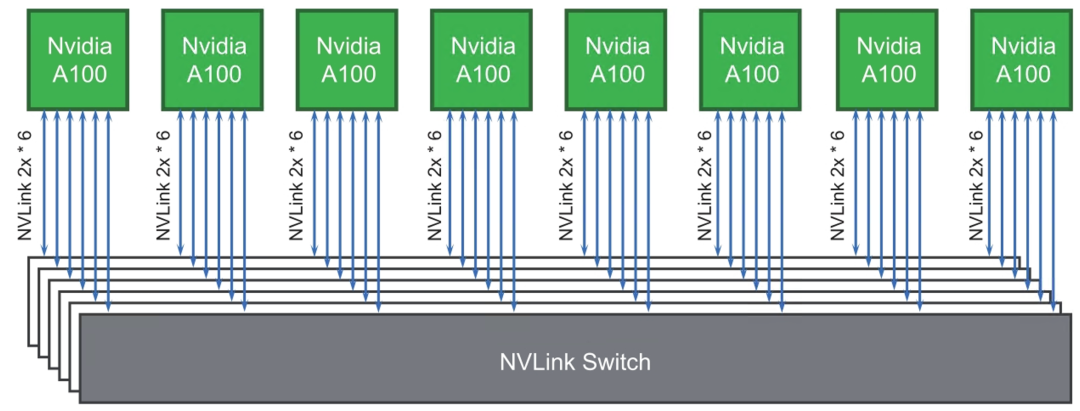
与PCI-E Switch类似,Nvidia提供了NVLink Switch,用于多路NVLink之间的交换。Nvidia DGX A100中的NVLink Switch支持NVLink 3.0,每颗NVLink Switch芯片都可以支持18路NVLink 3.0端口的交换,总吞吐量可达1800GBps。
前面提到,每张Nvidia A100 GPU卡都有6个NVLink端口,那么,8张Nvidia A100 GPU卡就需要6颗NVLink Switch实现全连接的互联互通,如图4-10所示。
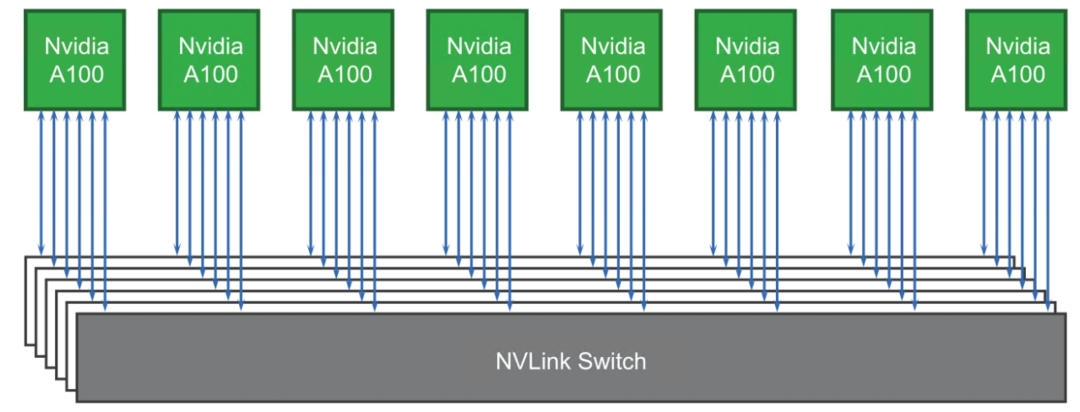
当Nvidia A100需要进行互访时,Nvidia A100内部的crossbar会将数据均分到6条NVLink总线,并且通过NVlink Switch转发到目的GPU上,其互访的数据流向如图4-11所示。
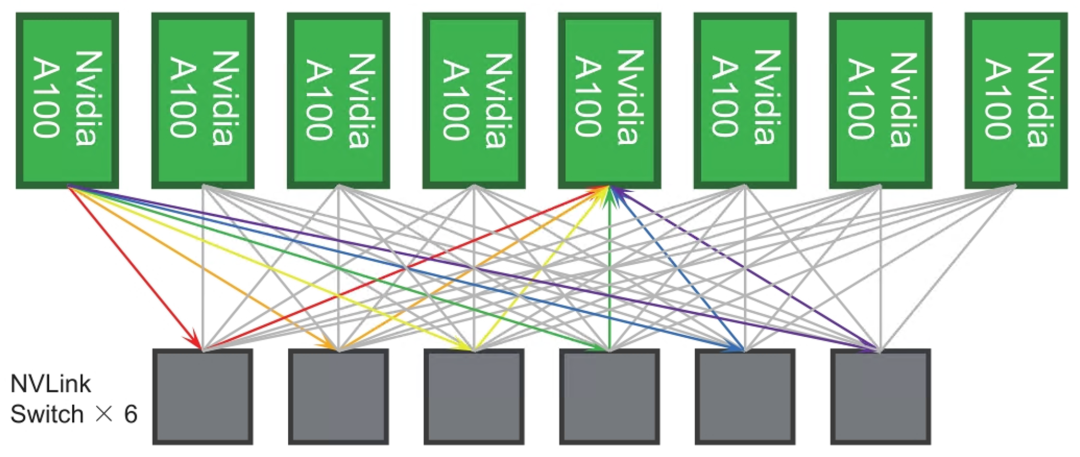
那么,NVLink Switch在Nvidia DGX A100的什么位置安装呢?实际上,Nvidia为8颗A100提供了一块专用的子卡,子卡上有6块NVLink Switch,并且可以提供8个SXM接口,安装8张Nvidia A100 SXM GPU卡,通过NVLink实现互联互通。SXM子卡的内部架构如图4-12所示。Nvidia A100 GPU与SXM子卡之间的接口为PCI-E x16接口和NVLink 2.0 x6接口。实际上,Nvidia的SXM接口就是这二者的集合。
第6章 GPU集群的网络设计与实现
6.2 GPU集群中存储与业务网络的设计与实现
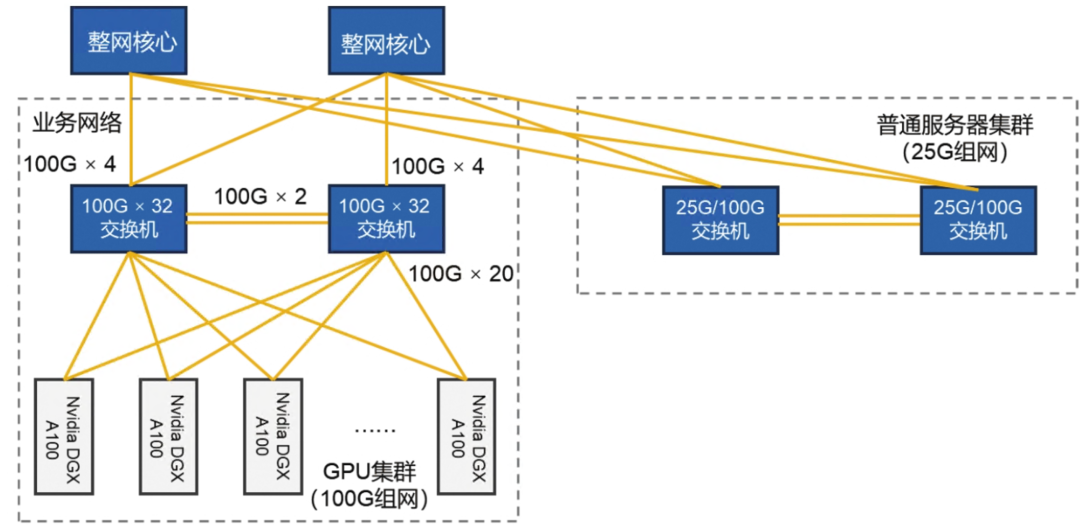
一个20台以内的小规模Nvidia DGX A100服务器集群的业务/存储网络方案如图6-4所示。
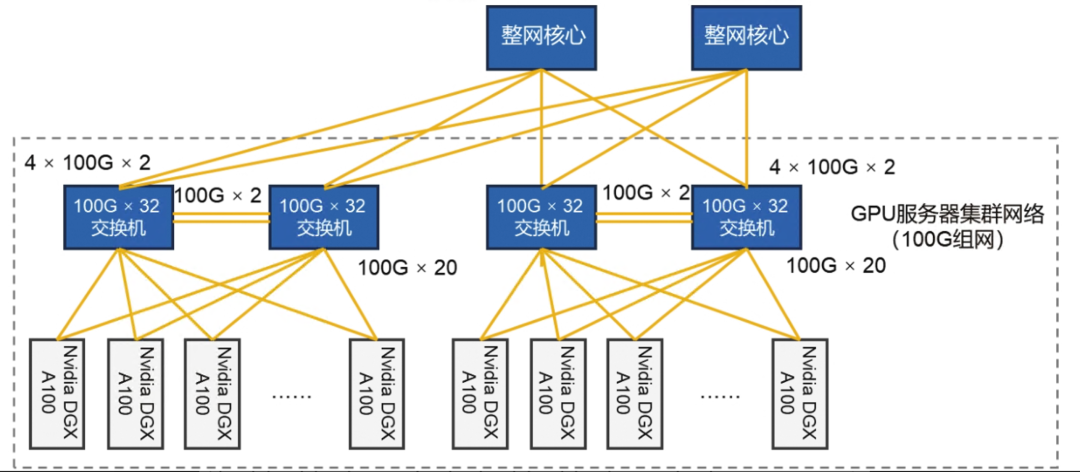
对于有超过20台Nvidia DGX A100的大中规模集群,我们可以对图6-4加以扩展。在图6-5所示的较大规模的Nvidia DGX A100集群业务网络中,我们将20台Nvidia DGX A100作为一组,每组都连接2台32口100G以太网交换机,每台32口100G以太网交换机在提供20个100G以太网接口作为下行以太网接口的同时,也提供了2组上行以太网接口分别连接到每台核心交换机,每组4个100G以太网接口,共8个100G以太网接口,收敛比为20:8,在可以接受的范围内。与图6-4中的组网类似,核心交换机也可以为其他25G组网的普通服务器集群的网络区域提供100G的上行交换网络。
由于业务网络没有极端敏感的时延、抖动和丢包率等QoS需求,所以对业务网络使用框式交换机是完全可以接受的。目前,国内和海外均有大容量、高密度框式交换机产品,可在占用6U甚至更少的机柜空间的情况下,提供双主控+CLOS交换架构,整机有近200个100G以太网接口,在使用2台核心交换机构建网络的情况下,可以为近1000台GPU服务器提供100G业务网络的互联互通。
第9章 GPU集群的网络虚拟化设计与实现
目前主流的GPU集群的资源调度技术实际上是基于虚拟化和容器的云计算技术。在引入云计算技术后,我们就可以将GPU计算资源分配给不同的租户使用,并且通过网络隔离使得每个租户都只能看到自己申请的GPU资源,如带有GPU的虚拟机和带有GPU的容器集群等。
9.3 专线接入、对等连接与VPC网关
无论是跨VPC的虚拟机互通,还是VPC内的虚拟机互通,其VPC Overlay隧道的封装和解封装都需要在虚拟机宿主机上的VSW内实现。那么,如果在VSW上实现了跨VPC的Overlay隧道转换,实际上就不再需要实现对等连接的专用网关了。其工作原理如图9-12所示
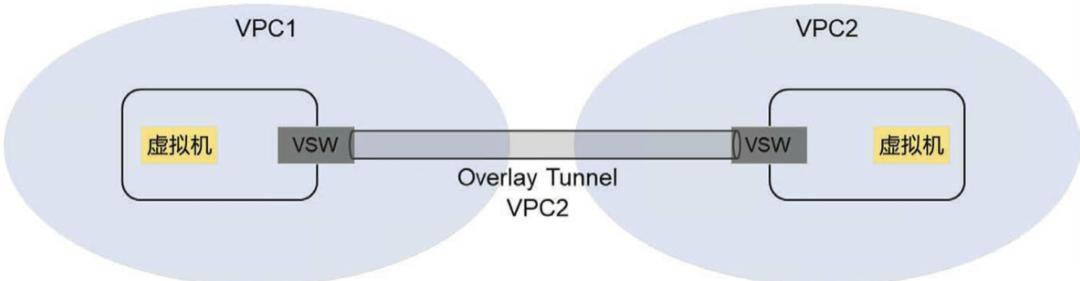
在图9-12中,VPC1上的虚拟机需要访问VPC2上的虚拟机,此时VSW通过查找路由表判断目的虚拟机的IP地址在VPC2中,从而将发送给目的宿主机的流量封装为VPC2对应的Overlay隧道。目的虚拟机所在的宿主机能够接收该隧道,并且解封装,将其转发给目的虚拟机。由于VSW是分布式的,实际上实现了完全分布式的对等连接,也就是不再依赖独立的对等连接网关,降低了对等连接对CPU/内存资源的占用。
在VPC中,还需要处理的一类流量是,VPC Overlay访问处于集群中VPC外的流量,如数据库服务、中间件服务及其他支撑服务等。
9.4 SDN NFV网关的实现与部署
在机器学习集群及其依托的云计算平台上,采用工业标准服务器+NFV软件来实现SDN网络的网关,而不使用专用的路由器、防火墙和负载均衡等硬件设备,目前已成为业界的共识。
NFV实现网关的核心价值在于,在整个平台集群规模和业务流量不大的情况下,可以使用少量的服务器资源先搭建SDN网络,随着业务的增长,再扩容更多的服务器资源,以提升SDN网络中各网关的处理能力。
第10章 GPU集群的存储设计与实现
10.1 程序与系统存储—分布式块存储
10.1.2 集中式块存储与分布式块存储
在较为传统的虚拟化系统(如VMWare vsphere等产品)中,可以使用集中式FC-SAN(Fibre Channel Storage Area Network)存储来实现
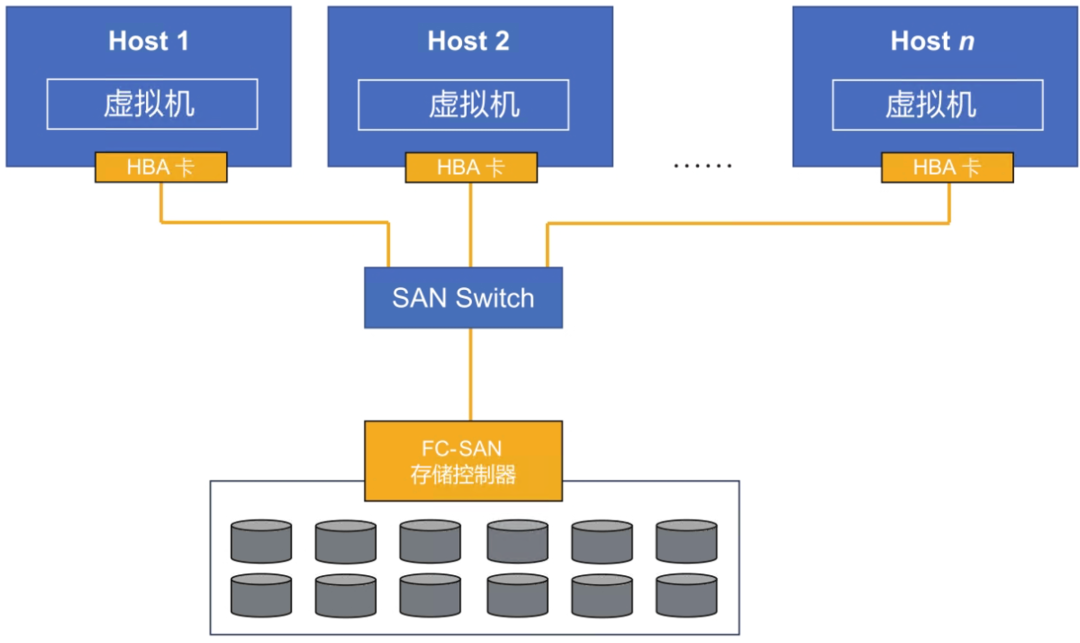
FC-SAN的问题在于,性能和终端数量的扩展性上。一方面,FC-SAN存储控制器的数量是有限的,最高端的FC-SAN存储控制器不超过16个,这使得性能与容量的扩展受到控制器数量的限制。另一方面,如果连接到FC-SAN网络的宿主机台数较多,超出了FC-SAN Switch的连接能力(一般不超过96台),就需要使用昂贵的FC-SAN Director(俗称“光纤导向器”),从而导致CAPEX和OPEX急剧上升。此外,由于FC-SAN Switch的供应商较为单一,目前只有Brocade和Cisco两家,从IT供应链安全角度而言,用户也不倾向于使用这样的方案来构建关键业务系统。
CRUSH算法的主要问题在于,由于它是一种随机算法,因此无法实现所有的磁盘空间都能分配出去。Ceph集群中任意一块磁盘容量水线达95%时,整个集群将被设定为只读,在实践中,为了避免这种情况发生,一般将Ceph的售卖水线设定为75%~85%,以避免因单盘容量用满导致生产事故的发生。
Ceph
“故障根本原因为Ceph集群中单台服务器的磁盘阵列卡固件出现故障,误报所有磁盘的使用率为100%,触发Ceph整集群只读,导致所有使用该Ceph的虚拟机挂死并重启失败”
由于Ceph有前文所述的缺陷,在商用的云计算平台中,往往使用自研算法的云存储系统来代替Ceph。一种最佳实践是将云上块存储服务实例(云硬盘)划分为多个大小为1MB的数据块,每个数据块都通过特定的算法映射到主副本所在节点/磁盘和从副本所在节点/磁盘。三个副本所在的节点/磁盘/磁盘偏移量三元数组被称为“小表对”(Tablet Pair)。小表对的分配是由一致性哈希算法(Consistency Hash)生成的,在部署前就预设好,可以实现良好的负载均衡性,使得每一块硬盘的有效空间都能被最大化地利用。
10.1.3 分布式块存储的故障恢复
商用存储系统在可用性方面需要解决的三个核心问题如下。
(1)当整个系统中一块或多块磁盘发生故障时,不引起服务中断,也不引起数据丢失。
(2)当整个系统中一个或多个节点/控制器发生故障时,不引起服务中断,也不引起数据丢失。
(3)当整个系统中发生集群分裂时,不引起服务中断,也不引起数据丢失。
对于FC-SAN存储,这三个问题通过RAID、控制器高可用机制及控制器仲裁机制来实现。而对于分布式块存储,也需要有一定的机制来保障这三点。
对于第(1)个和第(2)个问题,分布式块存储一般使用三副本的方式来提供数据冗余。分布式块存储集群的管理平面定期检查每个物理硬盘和每个节点的在线状态。如果有某块物理硬盘或某个节点状态异常,所有对该硬盘/该节点的写入请求将被暂缓执行,如异常节点在给定的时间阈值内恢复,则将暂缓执行的写入请求都在恢复后执行落盘。这种方式被称为“原地恢复”;如超出时间阈值,分布式块存储的管控平面将决策在其他硬盘/其他节点重构相关的所有副本,这种方式被称为“迁移恢复”。
原地恢复与迁移恢复的对比如图10-3所示。
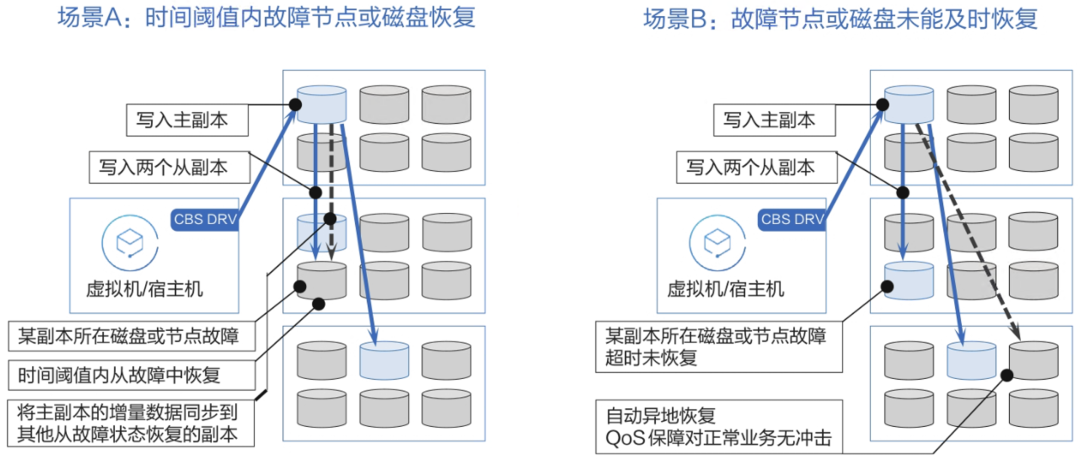
在图10-3中,左侧的图为原地恢复,不需要迁移任何数据。而右侧的图为迁移恢复,在重构副本时需要迁移数据。在实践中,由于绝大多数用户的机房位于硬件厂商的金牌维保服务范围内,在单磁盘或单节点发生故障时,硬件厂商可以在4小时内带备件上门进行维保。因此,只要合理设置原地恢复的时间,结合硬件厂商的金牌维保服务,就无须使用迁移恢复。
对于第(3)个问题,在实践中,可以在分布式块存储的控制平面部署一个ZooKeeper(有时缩写为ZK)集群,在提供仲裁的同时,还可以作为小表对数据的存储。ZooKeeper是一个分布式键-值(Key-Value,简写为K-V)数据库,采用简化的Paxos算法来实现数据一致性。
10.1.5 分布式块存储的快照与回滚
传统的FC-SAN存储一般能够提供快照功能,对LUN的内容做快照操作后,无论LUN的内容进行了哪些改写,都可以回滚到快照时间点的内容。
与FC-SAN存储类似,分布式块存储也需要提供快照功能。
快照的实现有COW和ROW两种方式。COW指的是写时复制(Copy on Write)
COW的优点是,在进行快照操作时,快照系统只记录需要快照的与卷相关的一些元数据,并不会真的消耗存储容量资源来保存快照,而是要在做过快照的卷被修改后,保存修改过的数据块。如果这个卷只有10%的数据被修改过,则只需要保存这10%被修改的内容即可。
但COW也有明显的缺点。一方面,COW会降低卷的写性能,因为对卷进行修改时会触发数据复制;另一方面,COW也无法得到完整的物理副本,如果由于某些原因,做了快照的卷被异常删除,那么从快照中只能恢复被修改过的数据。
ROW(Redirect On Write)快照机制得到了部分用户的青睐,并应用于云上块存储系统。
ROW的实现思路是:在创建快照时记录相关源数据,此后在写入源卷时,并不直接修改源数据,而是在将源数据设为只读的同时开辟新的空间(被称为“差分卷”),在写入时重定向到新的空间,并记录对应关系。如果做一次新的快照,则再创建一个新的差分卷,并将上一个差分卷设为只读。逻辑上卷的内容等于源数据叠加所有差分卷的内容。如果删除某一个快照点,则将这个快照点对应的差分卷和上一个快照点的差分卷进行合并。一个卷的所有快照点的差分卷被称为“一个快照链”。
10.2 海量非结构化数据存储—分布式对象存储
业界常见的开源对象存储方案有Ceph、Swift和MinIO等。
Swift的兴衰也高度跟随OpenStack,逐渐被符合行业事实标准S3的对象存储系统所取代。
大型公有云的对象存储集群的架构设计如图10-9所示。在图10-9中,大型公有云的对象存储集群分为HTTP服务层、存储节点层和键-值数据库层。HTTP服务层接收来自用户的S3/Swift API,将数据拆分为数据块,计算出冗余纠删码,并确定存储到哪些节点和磁盘上,在落盘的同时调用键-值数据库的接口维护元数据和索引。
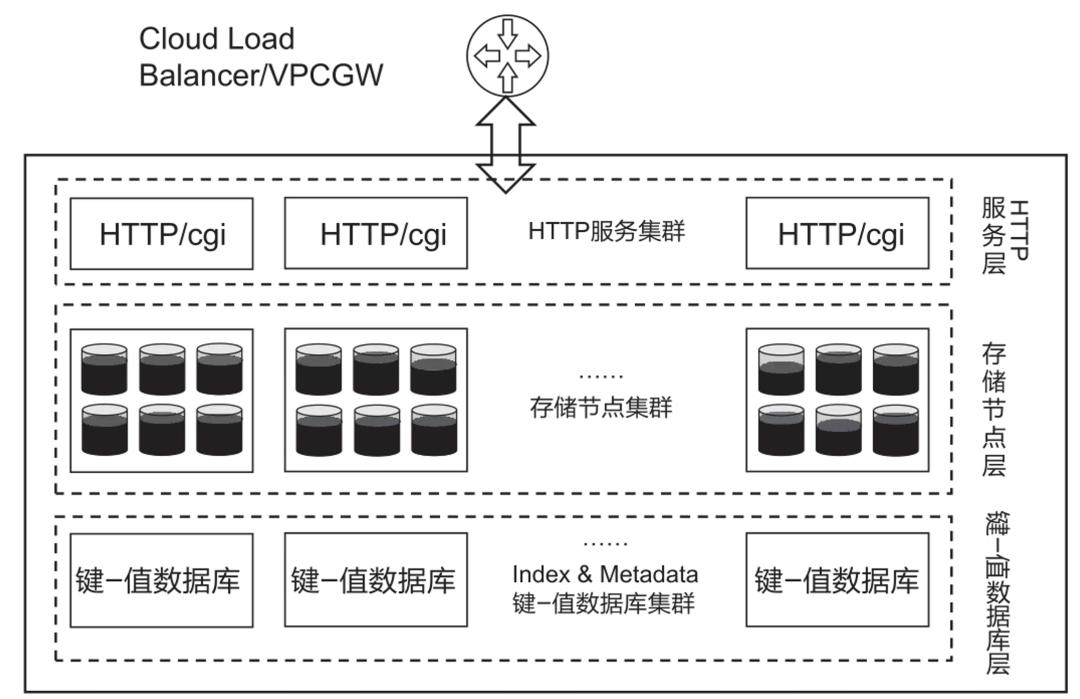
为提升性能,大型公有云的对象存储HTTP服务集群可以通过云负载均衡服务实例对云外提供服务VIP,并通过VPCGW对VPC内的虚拟机提供服务发现和服务路由,从而实现性能可以无限地横向扩展。
10.2.4 未来之星:MinIO
MinIO是基于Golang编程语言开发的高性能分布式开源存储项目
MinIO的一大特点就是它提供了与Kubernetes、etcd、Docker等主流云原生/容器技术的深度集成方案,如利用Kubernetes/Docker快速部署集群等。MinIO的架构大致如图10-10所示,在每个节点上都可以混合部署HTTP Server、元数据存储子系统和数据存储子系统。
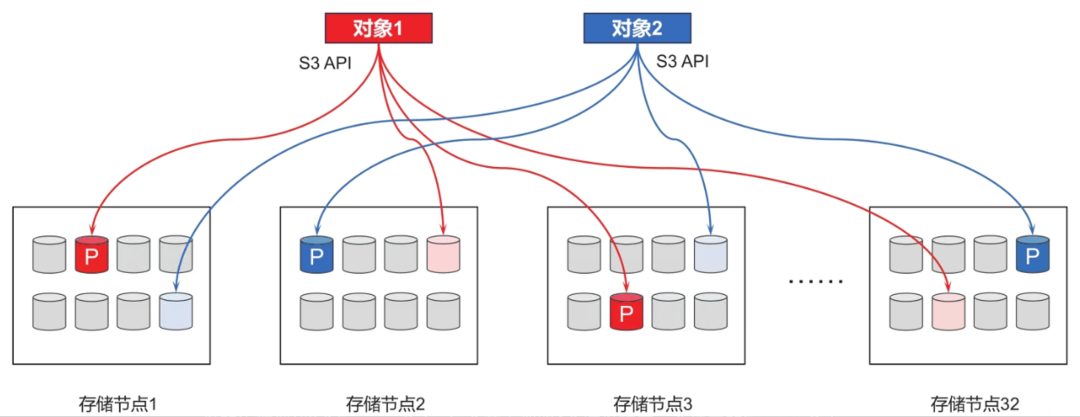
MinIO把4~16个磁盘组成一个Erasure Set,每个Erasure Set都包含4~16个磁盘,最少4个磁盘,最多16个磁盘,最少需要4个节点。磁盘均匀分布在所有的节点上,例如:4个节点,每个节点有8个磁盘。每个Erasure Set最多包含16个磁盘,总共32个磁盘的集群创建2个Erasure Set。每个节点都取4个磁盘构成一个独立的Erasure Set。
MinIO目前不支持多副本冗余,只支持纠删码冗余。对象在Erasure Set中通过Hash算法均匀分布在所有的Erasure Set中。在MinIO中用格式(EC: N)表示,其中,N表示EC(M+N),M为数据块的数量,N为校验块parity的数量。MinIO的读操作需要的磁盘数量为:Erasure Set中M个磁盘,写操作需要M+1个磁盘。
在MinIO的设计中,一个独立的集群中的节点数量和磁盘的数量都是固定的,后续不能增加,只能以Federation的方式以整个集群为单位进行整体扩容。Federation依赖于etcd和CoreDNS,每个MinIO cluster都把自己的信息注册到etcd里,一个bucket只能存储在一个集群中。App通过CoreDNS来调度bucket对应的集群,CoreDNS通过各种负载均衡的算法来分配bucket访问的集群。在读取时,通过etcd来获取bucket对应的集群信息。
10.3 AI训练素材存储—分布式并发高性能存储
10.3.3 长青松柏:Lustre
第11章 机器学习应用开发与运行平台的设计与实现
11.1 微服务平台
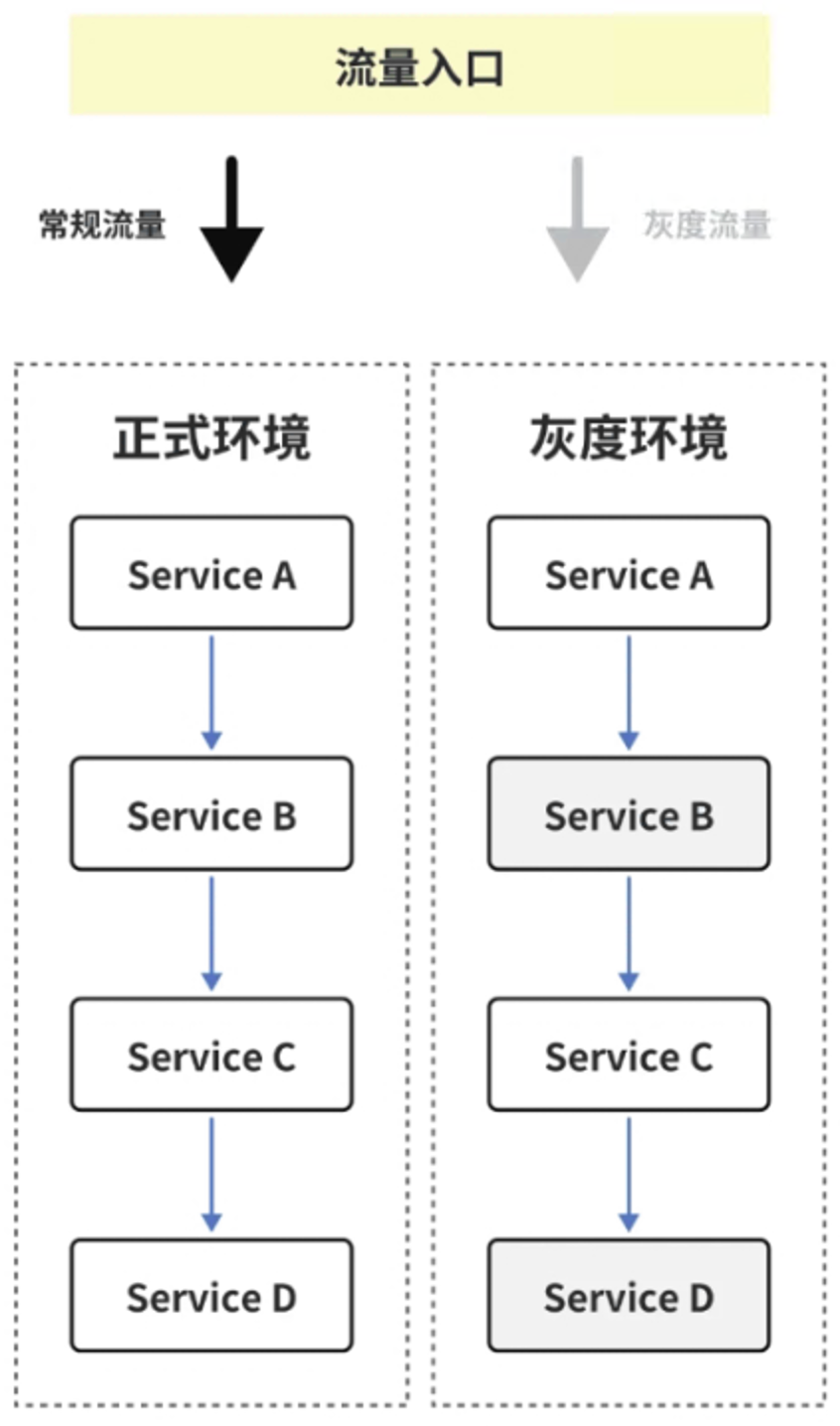
全链路灰度发布的核心在于流量泳道概念的实现。它有以下两种实现思路。
一种思路是为新版本建立一个相对于旧版本更独立的环境,在两个环境的流量入口处按特定规则分流。这种思路被称为“完整环境隔离
修改服务路由策略,把指向需要灰度的微服务的请求逐渐切换到新的灰度版本。这种思路被称为“全链路灰度发布
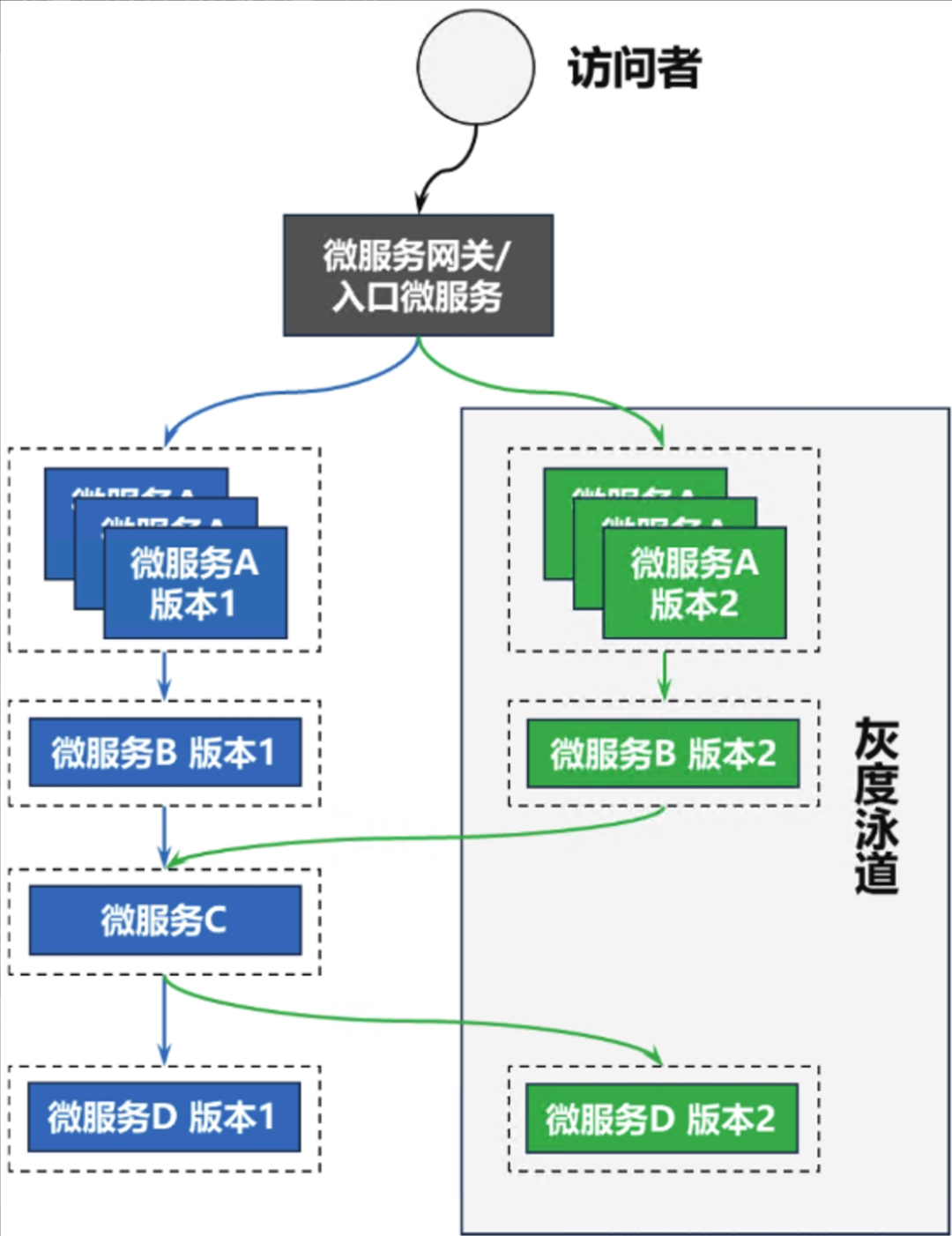
TSF的全链路灰度发布能力支持这两种不同的实现方式,用户可以在简单直接的方案和精细化方案之间二选一。
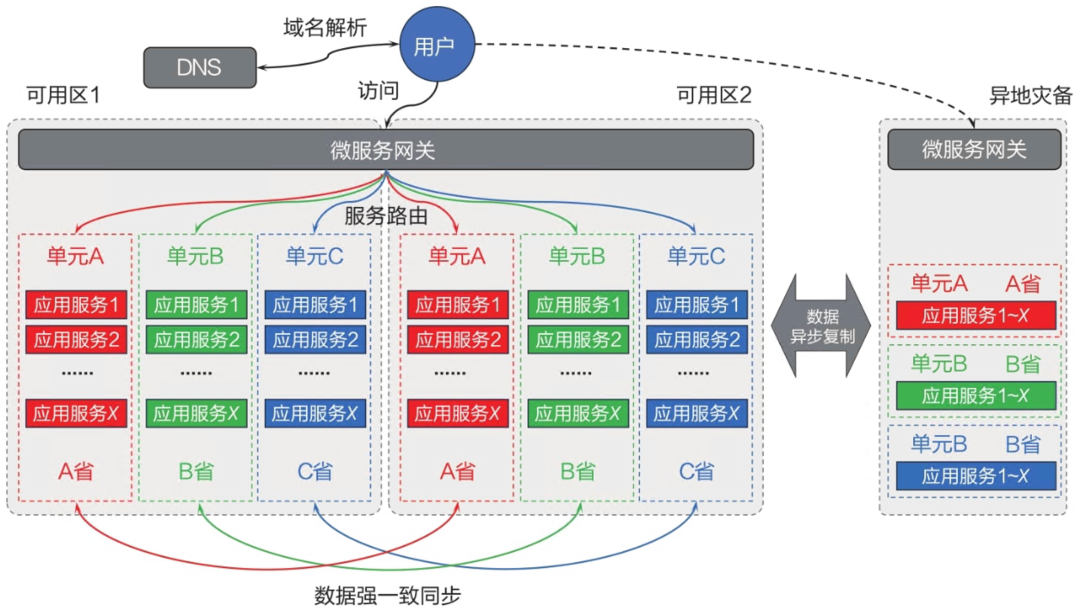
TSF另一个具有特色的功能是单元化。单元化指的就是将应用的核心数据进行水平拆分,并将应用服务进行无状态化改造,从而实现把相同领域的业务服务划分为独立部署的单元,单元内业务闭环,有效地解决服务的弹性伸缩、故障隔离、异地多活等微服务应用的高可用问题,同时可以基于单元化部署,以部署单元构建灵活的应用发布策略,如蓝绿发布、灰度发布。在大型银行客户的生产系统中,业务的单元化部署是基本需求,如按用户属地或用户ID来进行单元化的划分。此外,一些互联网企业也使用单元化部署来应对高并发量的C端业务。应用单元化部署后的架构和数据流向图如图11-15所示。
当用户通过域名访问应用时,智能DNS就会根据用户的源IP地址对应的地理位置和运营商等信息,为用户返回最优的IP地址,实现跨地域的服务路由。
在每个地域的应用入口,微服务网关都可以实现业务的同城双活,并基于网关的标签化路由来选择具体的单元。
SF会先识别本次调用是单元内调用还是跨单元调用,再将请求转发到对应的单元。相同服务的调用顺序为:首先是单元内调用,其次是本中心调用,最后是同城中心调用。
另外,单元化可以与全链路灰度发布结合,首先设定1~2个灰度单元,然后明确灰度维度有哪些,比如,常见的有按指定客户号或者客户标签灰度等。在网关进行单元路由计算前,优先查询灰度表,如果请求特征命中灰度规则,那么直接按照表中定义好的单元进行路由,转发到对应的灰度单元,完成单元的灰度发布。
11.2 中间件服务
11.3 应用日志服务

第12章 基于云平台的GPU集群的管理与运营
12.1 云运维平台… 206
12.1.1 硬件基础设施管理 ……… 206
12.1.2 系统监控与告警平台 …… 208
12.1.3 CMDB 210
12.2 云运营平台… 211
12.3 云审计平台… 212
12.4 本章小结… … 213
目录 · · · · · ·
第1章 AI与大模型时代对基础架构的需求…… 001
1.1 我们在谈论AI时,到底在谈论什么… 002
1.2 机器学习算法初窥… ………………… 004
1.3 一元线性回归算法剖析… …………… 005
1.4 机器学习算法对计算机硬件的特殊需求… ………………… 007
1.4.1 机器学习算法的核心运算特征 …………………… 007
1.4.2 使用CPU实现机器学习算法和并行加速 ………… 009
1.4.3 机器学习算法的主力引擎——GPU ……………… 011
1.4.4 机器学习算法的新引擎——TPU和NPU ………… 014
1.5 本章小结… …… 018
第2章 软件程序与专用硬件的结合…………… 019
2.1 GPU并行运算库 020
2.2 机器学习程序的开发框架… ………… 024
2.3 分布式AI训练… 026
2.4 本章小结… …… 028
第3章 GPU硬件架构剖析… ………………… 030
3.1 GPU的总体设计 031
3.2 Nvidia GH100芯片架构剖析… …… 033
3.3 其他Hopper架构的GPU… ………… 039
3.4 本章小结… …… 039
第4章 GPU服务器的设计与实现… ………… 040
4.1 初识Nvidia DGX… ………………… 043
4.2 Nvidia DGX A100的总体设计……… 044
4.3 Nvidia DGX A100 CPU与内存子系统的设计… ………… 046
4.4 Nvidia DGX A100 PCI-E子系统的设计… ……………… 048
4.5 Nvidia DGX A100 NVLink子系统的设计………………… 051
4.6 其他辅助子系统的设计… …………… 053
4.7 本章小结… …… 054
第5章 机器学习所依托的I/O框架体系… …… 055
5.1 Magnum IO的需求来源… ………… 057
5.2 Magnum IO的核心组件… ………… 058
5.3 服务器内部的GPU互通……………… 059
5.4 跨服务器节点的GPU通信…………… 064
5.5 RDMA的两种实现…………………… 066
5.6 GPU对存储的访问…………………… 068
5.7 Magnum IO所依赖的其他支撑技术… …………………… 070
5.7.1 DPDK( Data Plane Development Kit,数据平面开发套件) ………… 070
5.7.2 DPU(Data Processing Unit,数据处理器) …… 071
5.7.3 MPI Tag Matching ………… 071
5.8 本章小结… …… 071
第6章 GPU集群的网络设计与实现… ……… 073
6.1 GPU集群中RoCE计算网络的设计与实现………………… 075
6.2 GPU集群中存储与业务网络的设计与实现………………… 078
6.3 GPU集群中带外管理监控网络的设计与实现……………… 083
6.4 GPU集群中网络边界的设计与实现… 084
6.5 本章小结… …… 086
第7章 GPU板卡级算力调度技术… ………… 088
7.1 基于虚拟化技术的GPU调度………… 089
7.2 基于容器技术的GPU调度…………… 095
7.3 本章小结… …… 100
第8章 GPU虚拟化调度方案… ……………… 101
8.1 Nvidia的GPU虚拟化调度方案……… 103
8.1.1 API Remoting与vCUDA …… 104
8.1.2 GRID vGPU ………………… 105
8.1.3 Nvidia MIG ………………… 106
8.2 其他硬件厂商的GPU虚拟化调度方案 108
8.2.1 AMD的SRIOV方案………… 108
8.2.2 Intel的GVT-G方案 ………… 109
8.3 云厂商与开源社区基于容器的GPU虚拟化调度方案……… 109
8.3.1 TKE vCUDA+GPU Manager 110
8.3.2 阿里云的cGPU……………… 112
8.3.3 腾讯云的qGPU …………… 113
8.4 本章小结… …… 114
第9章 GPU集群的网络虚拟化设计与实现… 115
9.1 基于SDN的VPC技术:网络虚拟化技术的基石… ……… 116
9.2 云负载均衡:机器学习网络的中流砥柱… ………………… 120
9.3 专线接入、对等连接与VPC网关…… 126
9.4 SDN NFV网关的实现与部署… …… 130
9.4.1 基于virtio-net/vhost的虚拟机部署NFV …………… 130
9.4.2 基于SRIOV的虚拟机部署NFV …………………… 132
9.4.3 使用DPDK技术对NFV加速 133
9.5 本章小结… …… 135
第10章 GPU集群的存储设计与实现………… 137
10.1 程序与系统存储——分布式块存储… …………………… 138
10.1.1 块存储的业务需求 ……… 138
10.1.2 集中式块存储与分布式块存储 ………………… 139
10.1.3 分布式块存储的故障恢复 142
10.1.4 分布式块存储的性能优化 145
10.1.5 分布式块存储的快照与回滚 …………………… 146
10.2 海量非结构化数据存储——分布式对象存储… ………… 148
10.2.1 入门级对象存储的首选:Ceph ………………… 149
10.2.2 开源海量对象存储:Swift 152
10.2.3 商业化对象存储:大型公有云对象存储私有化 154
10.2.4 未来之星:Minio ………… 156
10.3 AI训练素材存储——分布式并发高性能存储… ………… 157
10.3.1 开源大数据存储鼻祖:HDFS …………………… 159
10.3.2 业界对HDFS的改进 ……… 161
10.3.3 长青松柏:Lustre ………… 163
10.4 本章小结… … 166
第11章 机器学习应用开发与运行平台的设计与实现… …………… 167
11.1 微服务平台… 168
11.1.1 Kubernetes:微服务基础能力平台 ……………… 169
11.1.2 Spring Cloud:Java系专属微服务平台 ………… 173
11.1.3 Istio:不挑开发语言,只挑部署架构 …………… 176
11.1.4 商业化微服务平台:兼顾各类需求的选择……… 183
11.2 中间件服务… 189
11.2.1 消息中间件………………… 190
11.2.2 缓存中间件………………… 195
11.2.3 数据库(数据中间件)…… 197
11.3 应用日志服务… …………………… 201
11.4 本章小结… … 203
第12章 基于云平台的GPU集群的管理与运营 205
12.1 云运维平台… 206
12.1.1 硬件基础设施管理 ……… 206
12.1.2 系统监控与告警平台 …… 208
12.1.3 CMDB 210
12.2 云运营平台… 211
12.3 云审计平台… 212
12.4 本章小结… … 213
第13章 服务机器学习的GPU计算平台落地案例…………………… 214
13.1 需求来源:自动驾驶模型训练… … 215
13.2 总体设计——基于云原生的高性能计算… ……………… 218
13.3 计算需求分析与设计实现… ……… 218
13.4 存储需求分析与设计实现… ……… 219
13.5 网络需求分析与设计实现… ……… 220
13.6 本章小结… … 222
后记 223
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

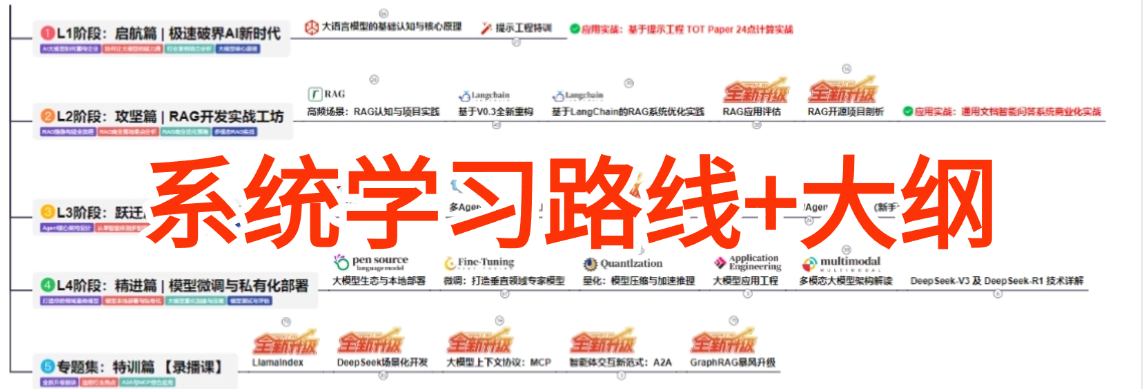
② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献149条内容
已为社区贡献149条内容

所有评论(0)