【论文阅读】LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
快速了解部分
基础信息(英文):
1.题目: LDA-1B: Scaling Latent Dynamics Action Model via Universal Embodied Data Ingestion
2.时间: 2026.02
3.机构: Peking University, Galbot, CASIA, BAAI, Tsinghua University, Sun Yat-sen University, NVIDIA
4.3个英文关键词: Robot Foundation Model, Unified World Model, Latent Dynamics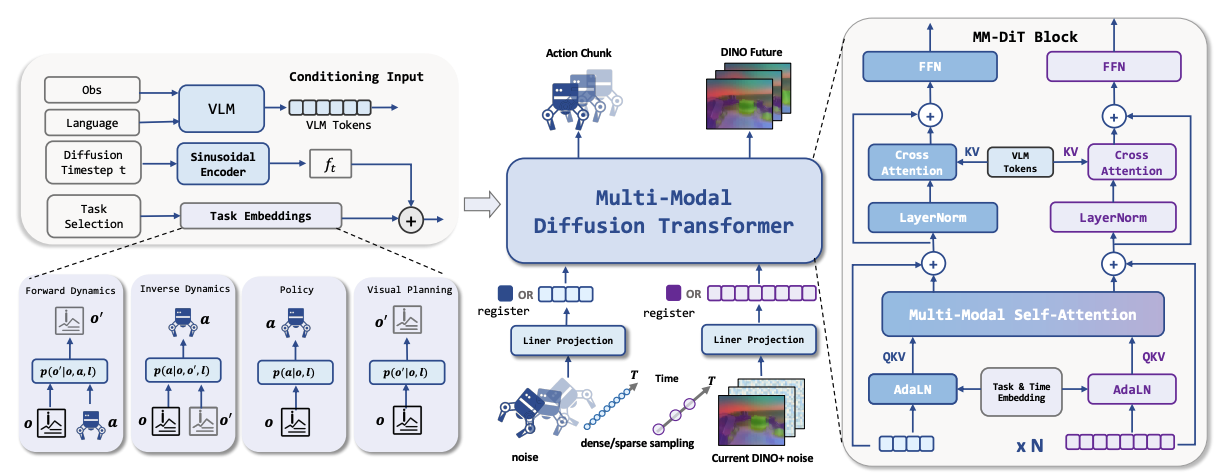
1句话通俗总结本文干了什么事情
本文提出了一种名为LDA-1B的机器人基础模型,通过在统一的潜在空间中联合学习环境动力学、策略和视觉预测,实现了对海量异构数据(包括低质量数据和纯视频)的有效利用和扩展。
研究痛点:现有研究不足 / 要解决的具体问题
现有机器人模型主要依赖高成本的高质量模仿学习,浪费了大量包含丰富物理交互信息的异构数据(如低质量轨迹、纯人类视频);现有的统一世界模型(UWM)则因在像素空间预测和缺乏数据角色区分,难以扩展到基础模型规模。
核心方法:关键技术、模型或研究设计(简要)
提出LDA-1B模型,核心是“通用具身数据摄入”机制,根据不同数据质量分配不同任务(如低质量数据只学动力学,高质量数据学策略),并在结构化的DINO潜在空间而非像素空间进行预测,配合多模态Diffusion Transformer架构。
深入了解部分
作者想要表达什么
作者旨在证明,通过统一的潜在动力学学习框架,机器人基础模型可以打破对昂贵、单一高质量专家数据的依赖,通过“通吃”所有类型的具身数据(包括通常被丢弃的低质量数据和无动作视频),在不增加数据收集成本的情况下显著提升模型的泛化性、鲁棒性和操作灵巧性。
相比前人创新在哪里
- 数据利用范式创新:提出了Universal Embodied Data Ingestion,明确区分数据质量角色(高质学策略,低质学动力学,无动作学视觉预测),让原本“有害”的低质量数据变成了有用的监督信号。
- 表示空间创新:抛弃了UWM常用的像素空间或VAE空间,转而在预训练的DINO视觉特征空间(Latent Space)进行动力学建模,避免了复杂的外观建模,专注于语义和空间结构。
- 架构创新:设计了MM-DiT(多模态Diffusion Transformer),能够处理异步的视觉和动作流,并引入任务嵌入(Task Embeddings)来统一不同的训练目标。
解决方法/算法的通俗解释
LDA-1B就像是给机器人请了一个“全能教练”。这个教练不仅看机器人自己做得好的示范(高质量数据),也看机器人做得不好的尝试(低质量数据)来学习物理规律,甚至还看人类的视频(无动作数据)来学习场景变化。它不纠结于画面的光影细节(在DINO空间预测),而是专注于物体的位置和运动趋势,并用一个统一的Transformer模型同时处理眼睛看到的和身体要做的动作。
解决方法的具体做法
- 数据集构建:收集了超过30,000小时的EI-30k数据集,包含真实机器人、模拟机器人、带动作的人类视频和不带动作的人类视频,并统一为LeRobot格式和末端执行器坐标系。
- 潜在空间预测:使用冻结的DINO encoder提取图像特征,模型在该特征空间预测未来的视觉状态和动作。
- 多任务联合训练:
- 策略学习:仅使用高质量轨迹,预测动作。
- 动力学学习:使用高质量和低质量轨迹,预测状态转移(不强制要求动作最优)。
- 视觉预测:使用所有视频数据(包括无动作数据),预测未来的视觉特征。
- 模型架构:采用MM-DiT架构,将视觉token和动作token拼接输入Transformer,通过不同的Task Embedding来区分当前是在做策略、动力学还是视觉预测任务。
基于前人的哪些方法
- Unified World Model (UWM):借鉴了UWM联合优化动力学、策略和视频生成的目标,但改进了其数据使用方式和表示空间。
- DINO / DINOv3:使用了DINO预训练视觉模型的特征空间作为预测的潜在空间。
- Qwen3-VL:使用其作为视觉和语言的编码器(VLM)。
- Diffusion Transformer (DiT):MM-DiT架构基于DiT,扩展以支持多模态(视觉+动作)和不同任务。
实验设置、数据、评估方式、结论
- 数据:EI-30k数据集(30k+小时,含8k真实机器人、8.6k模拟机器人、7.2k带动作人类数据、10k无动作人类视频)。
- 评估基准:
- 仿真:RoboCasa-GR1基准(24个厨房任务,GR-1人形机器人)。
- 真实世界:Galbot G1(二指夹爪/灵巧手)和Unitree G1(灵巧手)。
- 对比基线:π0.5\pi_0.5π0.5, GR00T-N1.6, UWM系列变体。
- 结论:
- 在接触丰富、灵巧操作和长程任务上显著优于基线(分别提升21%、48%和23%)。
- 证明了利用低质量数据进行微调的有效性(相比仅用高质量数据,成功率提升10%)。
- DINO潜在空间相比像素/VAE空间对扩展更有利。
提到的同类工作
- π0.5\pi_0.5π0.5:基于行为克隆的视觉语言动作模型。
- GR00T:NVIDIA提出的通用人形机器人基础模型。
- UWM (Unified World Model):统一世界模型,试图联合建模视频、动作和动力学的前人工作。
- RDT / InternVLA / Being-H0 / UniVLA:其他的机器人基础模型或混合数据训练方法。
和本文相关性最高的3个文献
- UWM-0.1B / UWM-1B <2025.04> - 本文方法的直接前身和主要对比对象。
- π0.5\pi_0.5π0.5 <2025.04> - 代表了当前主流的纯行为克隆路线的SOTA模型,是本文的主要性能对比基线。
- GR00T-N1.6 <2025.03> - 代表了大规模行为克隆在人形机器人上的应用,本文在多个实验中将其作为核心竞争对手进行超越。
我的
- 是一个unified WAM模型。可以完成4种task:给actions预测actions(Policy),给video预测下一段video(visual planning),给action预测observations(Forward Dynamics),给observations预测action(Inverse Dynamics)
- 不是预测显式像素,而是在DINO的latents空间下进行。
- 将不同数据用在不同场景训练,高质量数据用于所有场景,差一些的就只学Dynamics或者video gen。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)