薪资翻倍的秘诀:2026届如何用AIGC作品集,拿下大模型相关岗位的入场券?
关注「软件测试就业联盟」公众号,陪你走好校招求职的每一步
目录
一、现象:同样的学历,两份简历,一个15k一个32k
二、本质变化:面试官不再相信“我会”,只看“我做过什么”
三、核心机制拆解:一个AIGC作品集应该长什么样
四、典型案例对比:两份作品集,差在哪
五、工程落地启示:从零搭一个能拿出手的作品集
六、最后一个问题
去年校招季,我帮一个朋友筛简历。两份都是211硕,专业都是计算机。
简历A:GPA 3.8,两段中厂后端实习,项目栏写“电商秒杀系统”“RPC框架实现”,技能栏写“熟悉Java/Python/MySQL/Redis”。很标准的优秀简历。
简历B:GPA 3.4,没有大厂实习。项目栏写“基于RAG的个人知识库问答系统”“LLM自动化测试平台”“提示词优化工具链”。每个项目附了一个GitHub链接和一个在线demo地址。
我朋友当时就拍板:B进面试,A待定。最后B拿到的offer总包比A高出一倍不止。
不是说A不行。是 B的简历上,写满了2026年企业真正在招的东西。
很多人已经开始意识到了:光靠刷LeetCode和背八股文,已经拿不到高薪offer了。大模型相关的岗位,薪资普遍高出30%-100%,但要求的东西学校不教,培训班也还没跟上。
那怎么办?答案很简单,也很有操作性:做一个AIGC作品集。
一、现象:同样的学历,两份简历,一个15k一个32k
先看几个真实数据。
2026届校招,某大厂“LLM应用开发”岗,白菜价32k16,还不算签字费。同一家公司“后端开发”岗,白菜价21k15。接近50%的差距。
“大模型评测工程师”起薪28k,要求里写着“有LLM相关项目经验优先”。什么样的项目经验?不需要发论文,不需要自己训练模型。只需要你 用大模型API搭过一个能跑通的东西。
我翻过牛客网上的面经。一个拿到字节“AI测试开发”offer的同学,面经里写:面试官全程没问八股,只问了两个东西——你GitHub上那个RAG项目怎么设计的,你那个自动化评测脚本怎么处理模型输出不稳定的。
这就是现状。学历和基础能力变成了门槛,而 作品集变成了决定天花板的东西。
二、本质变化:面试官不再相信“我会”,只看“我做过什么”
过去的技术面试,有一个默认的信任链条:
好学校 → 好基础 → 应该会写代码 → 面试考几道题验证一下。
现在这个链条断了。原因是 大模型相关的技能,没有标准化的教育体系来背书。
你说你“熟悉提示词工程”,怎么证明?没有证书。没有课设。面试官只能问你:“你写过最长的提示词是什么?为了解决什么问题?你怎么调试的?”
你能回答上来,说明你真的做过。回答不上来,就是简历上凑数的。
核心在于:大模型应用开发的门槛极低(调个API就能跑),但做好极难(需要处理无数工程细节)。 这个特性决定了,面试官唯一能相信的,就是你自己动手搭过的项目。
一个运行在线的demo,比一百句“熟练掌握”都有用。因为在线demo意味着你解决了部署问题、API key管理、成本控制、异常处理——这些才是岗位真正需要的工程能力。
所以,作品集不再是一个“加分项”,而是 入场券。没有它,你连证明自己的机会都没有。
三、核心机制拆解:一个AIGC作品集应该长什么样
很多人听到“作品集”,第一反应是放几个Jupyter Notebook,或者把调用OpenAI API的脚本扔到GitHub。这种不加分。
一个能打动面试官的AIGC作品集,必须包含三个要素:完整性、工程性、差异性。
下面我拆开讲。
完整性:不是一个脚本,而是一个最小可用的产品
面试官想看到的是:你能够端到端地解决一个问题。
反面例子:一个叫gpt_demo.ipynb的文件,里面几行代码调用chat.completions,打印输出。
正面例子:一个“会议纪要生成器”。
-
输入:录音文件或文字笔记
-
处理:调用Whisper转写 → 调用GPT提取要点 → 格式化输出
-
输出:Markdown格式的会议纪要,包含决策、待办事项、风险点
-
附带:一个简单的Streamlit界面,或者一个README教别人怎么跑
这叫“完整”。它证明你理解了输入、处理、输出全链路,而不仅仅是会调API。
工程性:考虑了真实环境里会出问题的地方
真实的大模型应用,不稳定是常态。你的作品集如果能体现对这种不稳定的处理,面试官会高看你一眼。
具体来说,这几个点最容易体现工程性:
-
重试机制:API调用失败时自动重试,指数退避
-
输出解析:模型返回的JSON可能不完整,你做了try-catch和正则兜底
-
成本控制:限制了单次调用的最大tokens,或者做了缓存
-
评测:你写了一个简单的脚本,对比了不同提示词的效果
你不需要做得完美。只需要在README里写一句“考虑到API可能超时,我增加了3次重试”,就比90%的人强。
差异性:别再做“聊天机器人”了
现在GitHub上搜“chatbot”,能搜出几万个仓库。你做聊天机器人,面试官看都不会看。
什么叫有差异性?选一个具体的、小众的场景。
-
帮HR写JD的生成器(输入岗位名称,输出带公司特色的职位描述)
-
代码注释自动生成器(输入代码片段,输出中文注释)
-
测试用例生成器(输入需求描述,输出测试点列表)
-
论文摘要总结器(输入PDF,输出200字摘要+3个关键结论)
这些场景技术难度差不多,但看起来更像“解决问题”,而不是“交作业”。
下面这张图是一个典型的AIGC作品集架构,你可以照着搭:
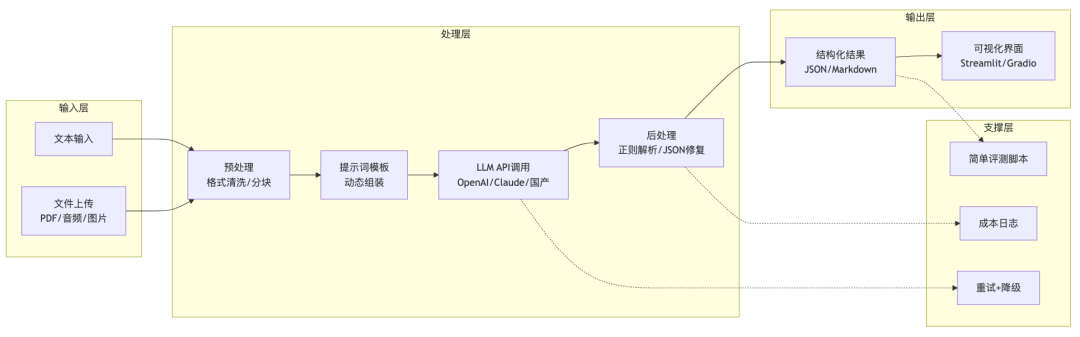
把这个架构里的每一层都填上代码,就是一份满分的作品集。
四、典型案例对比:两份作品集,差在哪
我拿两个真实案例(脱敏)对比一下。
案例C:某985大四学生,想做LLM应用开发
作品集内容:
-
项目1:“GPT-3.5对话机器人”,Streamlit界面,能聊天,能记住上下文
-
项目2:“AI写诗”,调用API根据关键词生成七言绝句
-
项目3:一个Jupyter Notebook,展示了怎么用LangChain做简单的文档问答
面试反馈:技术还行,但项目太“课程作业感”,没有解决真实痛点。备选。
案例D:某双非大三学生,拿到了大模型公司实习
作品集内容:
-
项目1:“技术文档自动审查工具”。输入Markdown文档,自动检查:术语是否统一、链接是否失效、代码块是否有语言标注。输出修改建议。用了GPT-4做语义判断,但用正则做了第一轮过滤以降低成本。
-
项目2:“算法题面试模拟器”。用GPT模拟面试官,根据你的回答给出结构化评分(关键词、推理链)。自己写了一个简单的评分规则引擎。
-
项目3:一个工具函数库,封装了API重试、token计数、JSON修复等常用操作,放在GitHub上被19个人star了。
面试反馈:工程意识很强,知道怎么把大模型用到实际场景里。直接给了offer。
差在哪里?D的项目都不是“玩具”,而是“工具”。每个项目都在解决一个真实场景下的痛点,并且体现了对成本、稳定性、评测的思考。这才是面试官想看到的。
五、工程落地启示:从零搭一个能拿出手的作品集
如果你现在手里什么都没有,别慌。三个月足够做出一个高质量作品集。下面是路线图。
第一个月:选场景,搭骨架
-
不要想“做什么最酷”。想“我最近被什么重复性工作困扰”。
比如:整理读书笔记太慢?写周报太痛苦代码review时找bug费劲?
这些就是最好的选题。 -
用最快的方式搭出原型。Streamlit + OpenAI API,一下午就能跑通。
目标是让“输入→输出”这条线通起来,哪怕输出不完美。
第二个月:填工程细节
-
加后处理:模型输出经常多出废话,用正则或字符串截断处理
-
加重试:用tenacity库或手写循环
-
加缓存:相同输入不重复调API,用字典或Redis
-
加简单的界面:让面试官能直接点进去试用,而不是读代码
-
写README:结构清晰,包含背景、架构图、怎么跑、效果示例。
README是作品集的脸,很多人不重视,这是巨大的误区。
第三个月:差异化打磨 + 部署
-
选一个点做深。比如你的工具现在只支持英文,改成支持中英文混合。或者把准确率从70%提到85%。
-
部署到免费平台(Hugging Face Spaces、Streamlit Cloud)。
一个能直接用的链接,比截图有说服力一百倍。 -
把代码push到GitHub,在知乎/掘金写一篇500字的“我做了个什么工具”,附上链接。
面试官搜你名字的时候,这些东西会自动帮你背书。
六、最后一个问题
很多人看到这里会说:“我学校课业很重,没时间做这些。”
我理解。但现实是,大模型岗位的薪资翻倍期不会永远持续。当越来越多人开始做作品集,它的边际价值就会下降。现在正是窗口期——企业求贤若渴,但合格的候选人极少。一个像样的作品集,能让你从几百份简历里跳出来。
最后一个问题留给你思考:
如果你明天就要投简历,你拿得出手的、能直接点开让面试官体验的、完全由你自己完成的AIGC作品,是什么?如果答案是“没有”,你打算从哪个具体的小工具开始做?
本文部分内容参考了霍格沃兹测试开发学社整理的相关技术资料,主要涉及软件测试、自动化测试、测试开发及 AI 测试等内容,侧重测试实践、工具应用与工程经验整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)