【学习笔记】大模型备案到底要交什么材料
"算法备案、大模型备案、登记备案到底要交哪些材料?网上说法五花八门,到底听谁的?"
我翻了十几份法规、国标和实践指南,把需要准备的材料从头到尾理了一遍。结论是:备案要交的东西,远比你想象的多,但也比你以为的有章可循。
一、先搞清楚要做的是哪种"备案"
很多人把三件事混在一起:算法备案、大模型备案、登记备案。它们不是一个东西。

简单说:
-
算法备案:只要你的产品用了算法推荐(个性化推送、排序精选、检索过滤等),就需要在互联网信息服务算法备案系统上填报。依据是《互联网信息服务算法推荐管理规定》(2022年3月施行)。
算法备案全程叫互联网信息服务算法备案。凡在中国境内,应用算法推荐技术(如个性化推送、生成合成、排序精选、搜索过滤、调度决策等)向用户提供互联网信息服务的企业或机构,必须在服务上线10 个工作日内依法进行算法备案。备案内容涵盖算法的基本信息、技术原理、应用场景等,旨在规范算法推荐服务,保护用户权益,维护网络空间秩序。
强制性:由国家网信部门联合多部委推行,属于法定强制义务,未备案可能面临警告、罚款(1-10 万元)甚至刑事责任。
-
大模型备案:如果你自研或微调了大模型,并且对外提供服务,就需要走完整的大模型备案流程。材料更多、周期更长(通常3-6个月)。
大模型备案主要针对生成式人工智能服务。根据《生成式人工智能服务管理暂行办法》,提供具有舆论属性或社会动员能力的生成式人工智能服务的企业,需进行安全评估,并履行算法备案手续。备案流程包括提交备案申请、技术测试、专家评审等环节,通过后由国家网信部门授予备案号并公示。
-
登记备案:如果你只是调用已备案大模型的API,走登记管理就行,材料简单得多。
大模型登记适用于仅调用第三方已备案大模型能力、无二次开发行为的应用开发者,满足以下全部条件即可走登记流程:
- ✅ 模型来源:调用的基座大模型已完成国家网信办备案(如文心一言、通义千问、腾讯混元等)
- ✅ 开发程度:未对模型进行微调、训练、参数修改或二次开发,仅做API封装、业务逻辑集成或Prompt工程优化
- ✅ 服务范围:面向境内公众提供具有舆论属性或社会动员能力的生成式AI服务(如内容生成、智能客服、文案创作等)
- ❌ 豁免场景:纯内部使用、不对外提供服务的应用无需登记
简单来说,备案是模型开发者的义务,登记是模型使用者的义务。
本文重点讲"大模型备案"要交的材料。 这是要求最全、也是最让人头疼的。
二、大模型备案的完整流程
在说材料之前,先过一遍流程,会更理解为什么要准备这些材料。
-
企业主动向属地网信办(省级)发起申请
-
网信办核准后反馈需要提交的材料,并选派指导老师
-
企业完成自评估,并准备备案所需材料(核心环节)
-
提交材料给属地网信办评估(可能涉及驳回修改)
-
属地网信办进行安全性评测(大模型接口安全评测)
-
提交材料给中央网信办复核(材料复核+接口安全评测)
-
通过后在互联网信息服务算法备案系统网站公示,备案完成
关键环节是第3步——自评估和材料准备。材料质量直接决定你被驳回几次、整个周期多长。
三、核心材料清单:一张图看全貌
根据《生成式人工智能服务管理暂行办法》、GB/T 45654-2025《网络安全技术 生成式人工智能服务安全基本要求》以及实际备案经验,你需要准备的材料可以分为五大类:
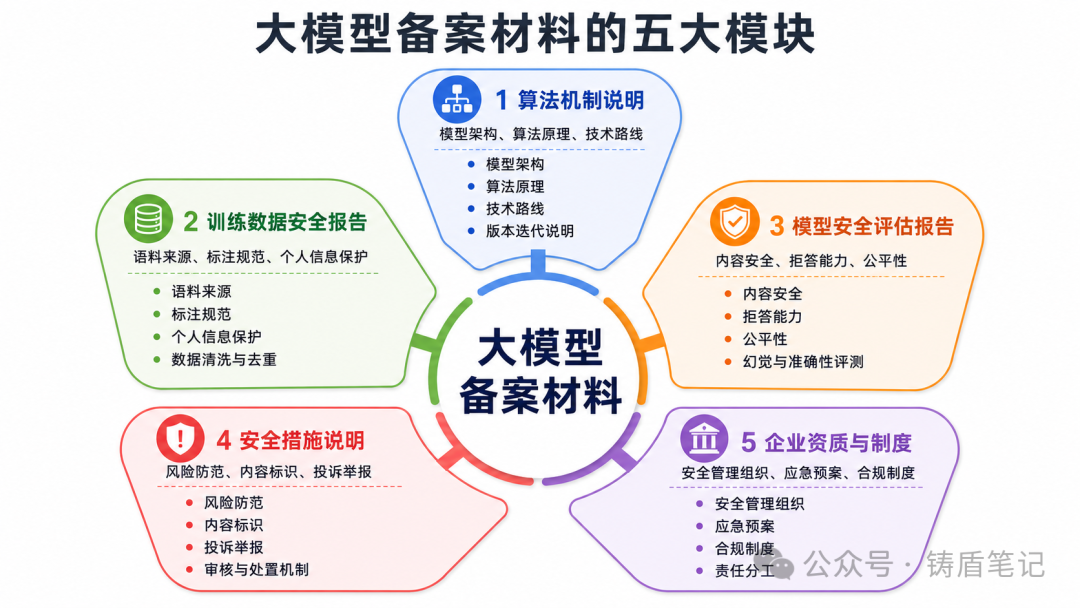
-
算法机制说明——模型架构、算法原理、技术路线
-
训练数据安全报告——语料来源、标注规范、个人信息保护
-
模型安全评估报告——内容安全、拒答能力、公平性
-
安全措施说明——风险防范、内容标识、投诉举报
-
企业资质与制度——安全管理组织、应急预案、合规制度
下面逐项拆解。
四、逐项拆解:每类材料具体要什么
4.1 算法机制说明
这份材料要回答的核心问题是:你的模型是什么、怎么工作的。
需要涵盖的内容:
|
项目 |
具体要求 |
|---|---|
|
模型架构 |
Transformer/其他架构,参数规模,层数、注意力头数等 |
|
算法类型 |
生成合成类/个性化推送类/排序精选类等 |
|
训练方法 |
预训练、微调、RLHF/DPO等安全对齐方法 |
|
技术路线 |
基座模型来源(自研/开源二开),推理框架 |
|
服务形式 |
网页/API/嵌入APP,面向C端还是B端 |
小贴士:这部分建议由算法团队牵头撰写。如果基于开源模型二次开发,要写清楚基座模型名称、版本和改动内容。
4.2 训练数据安全报告
这是材料中工作量最大的部分,也是被驳回最多的地方。
依据标准:《生成式人工智能预训练和优化训练数据安全规范》和《生成式人工智能数据标注安全规范》。
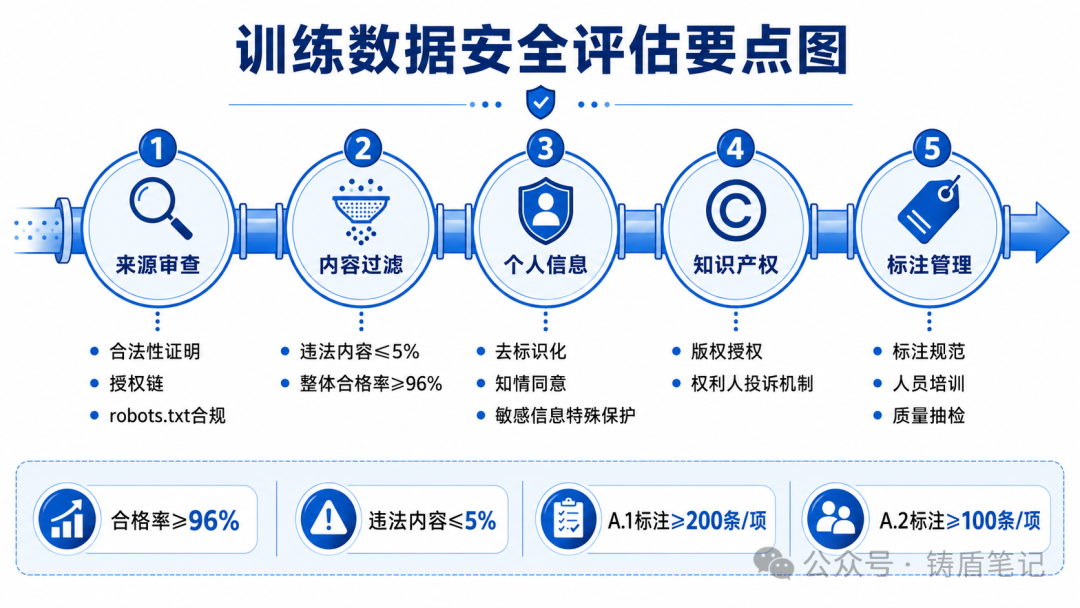
核心量化指标(必须达标):
-
训练数据整体合格率:≥96%
-
违法内容占比(红线):≤5%
-
安全标注数据量:A.1类(17项违法内容)每项≥200条,A.2类每项≥100条
-
个人信息知情同意:100%合规
需要准备的具体材料:
-
数据来源合法性证明——每个数据源的授权文件、采集合规说明
-
语料内容安全评估报告——抽样检测方法和结果,附抽检记录
-
个人信息保护说明——去标识化方案、同意机制、处理记录
-
知识产权合规说明——版权授权文件、权利人投诉处理机制
-
数据标注规范及执行记录——标注规则文档、人员培训记录、质量抽检记录
4.3 模型安全评估报告
这份材料回答的是:你的模型"说出来的话"安不安全。
依据标准:GB/T 45654-2025《网络安全技术 生成式人工智能服务安全基本要求》。

核心量化指标:
|
指标 |
合规阈值 |
评估方法 |
|---|---|---|
|
生成内容安全合格率 |
≥90% |
自动化测试(≥500条/风险类别) |
|
违法内容输出率 |
0%(红线) |
自动化测试 + 人工审核 |
|
正确拒答率 |
≥95% |
对抗性输入测试 |
|
误拒率 |
≤5% |
正常输入测试 |
|
拒答覆盖面 |
覆盖全部31类风险 |
附录A全覆盖 |
这份报告需要覆盖的内容:
-
语料安全评估——语料规模、来源、标注规则、训练服务器信息(算法部门牵头)
-
模型生成内容安全评估——31类违法不良信息的拒答与输出测试结果(算法+安全部门协同)
-
公平性与透明性评估——歧视性内容检测、模型可解释性说明
-
内容标识能力评估——AIGC显式/隐式标识是否完整、准确、持久
4.4 安全措施说明
这部分回答的是:你做了哪些防护,出了问题怎么处理。
需要涵盖:
|
类别 |
具体要求 |
|---|---|
|
输入内容监测 |
用户输入的违法内容识别、安全提示、上报机制 |
|
输出内容管控 |
生成内容审核、关键词拦截、实时过滤 |
|
内容标识 |
AIGC显式标识(水印/标签)、隐式标识(元数据) |
|
个人信息保护 |
最小必要原则、用户查询/删除/更正权利保障 |
|
投诉举报机制 |
便捷入口、处理流程、反馈时限、记录留存 |
|
应急响应 |
安全事件应急预案、熔断机制、异常行为检测 |
|
未成年人保护 |
防沉迷、内容过滤、适龄提示 |
注意:这部分建议安全和法务部门联合撰写。标识部分参考《人工智能生成合成内容标识方法》(强制性国标)。
4.5 企业资质与安全管理制度
最后一类是"软性"材料,但同样重要:
-
安全管理组织架构图(负责人、安全团队配置)
-
安全管理制度体系文件
-
专职安全管理人员证明
-
安全培训记录
-
安全事件应急预案
-
定期安全评估记录(如有)
五、高频疑问速答
Q1:用开源模型需要备案吗?
要不要备案不取决于开源还是闭源,而是看你是否满足备案条件(面向公众提供服务、具有舆论属性或社会动员能力)。建议应备尽备,避免监管风险。
Q2:只给企业内部用呢?
如果企业体量较大,或者计划对外发布大模型服务,建议还是备案。
Q3:调用已备案大模型API需要什么?
不需要做大模型备案,但需要做算法备案和登记备案。走登记管理流程,材料简单得多。
Q4:原有APP接入大模型API的智能问答功能,要改隐私政策和用户协议吗?
不需要单独改。只有原生AI应用(如文心一言、豆包等)需要单独准备。
Q5:备案周期多长?
一般3-6个月,取决于材料质量和配合效率。
六、参考标准速查表
做备案时手边常备这几份标准:
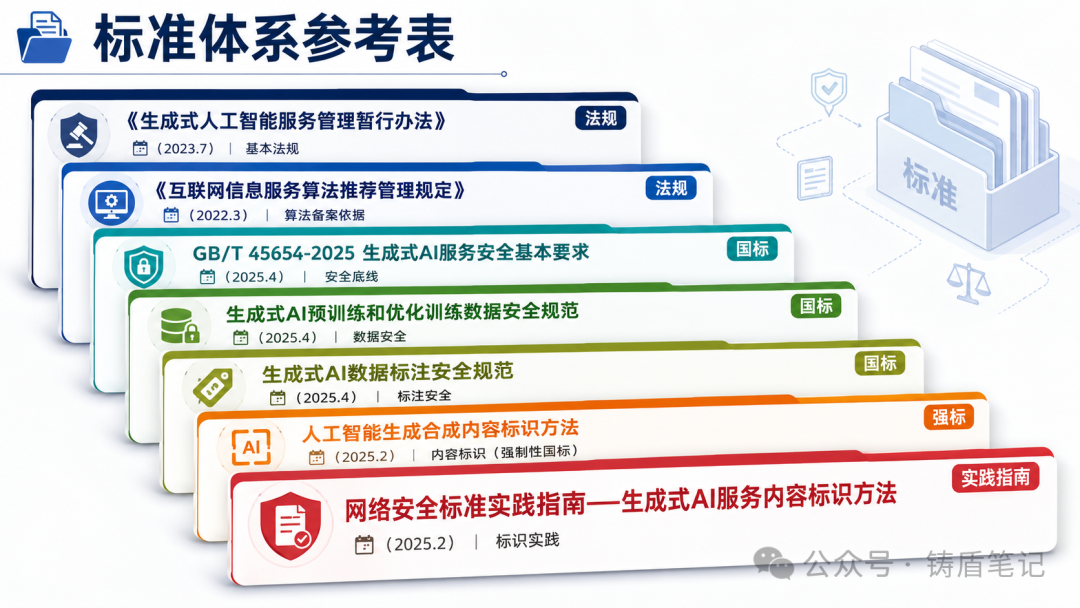
|
标准名称 |
发布时间 |
性质 |
解决什么问题 |
|---|---|---|---|
|
《生成式人工智能服务管理暂行办法》 |
2023.7 |
部门规章 |
基本法规依据,算法备案和安全评估的顶层要求 |
|
《互联网信息服务算法推荐管理规定》 |
2022.3 |
部门规章 |
算法备案的流程、时限和材料框架 |
|
GB/T 45654-2025 生成式AI服务安全基本要求 |
2025.4 |
国标 |
模型备案上线的安全底线,量化指标来源 |
|
生成式AI预训练和优化训练数据安全规范 |
2025.4 |
国标 |
训练数据全流程安全要求 |
|
生成式AI数据标注安全规范 |
2025.4 |
国标 |
数据标注安全基线 |
|
人工智能生成合成内容标识方法 |
2025.2 |
强制性国标 |
AIGC内容标识要求 |
写在最后
大模型备案看起来材料很多,但拆开来看就是五件事:
-
说清楚你的模型是什么(算法机制说明)
-
证明你"喂"的数据是干净的(训练数据安全报告)
-
证明你的模型"说话"是安全的(模型安全评估报告)
-
证明你有防护和兜底措施(安全措施说明)
-
证明你的企业有安全管理体系(企业资质与制度)
每一步都有对应的标准可以参照,关键是要组织好团队、提前准备、按标准对齐。
备案不是目的,安全才是。但这些材料本身就是一个倒逼过程——在准备的过程中,你会发现很多之前没注意到的安全盲点。
参考文献:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 20
20 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)