MySQL 索引:B+Tree、聚簇索引、最左前缀与 EXPLAIN
一、索引是什么
MySQL 官方对索引的定义是:索引是帮助 MySQL 高效获取数据的、排好序的数据结构。简单来说,索引是一种用于快速查询和检索数据的数据库对象,类似于书籍的目录。在没有索引的情况下,MySQL 需要从第一行开始逐行扫描全表(即全表扫描),直到找到匹配的数据;而有了索引,MySQL 可以像用目录查找章节一样,直接定位到目标数据所在的位置,极大地提高了查询效率。索引的实现通常依赖于特定的数据结构(如 B+Tree、Hash),其本质是对数据列的值进行排序和存储,从而加速数据的查找、排序和分组操作。
二、数据结构(B+Tree 与 Hash)
MySQL 索引底层主要使用 B+Tree 和 Hash 两种数据结构。下面分别说明它们如何组织数据、如何存储。
1. B+Tree
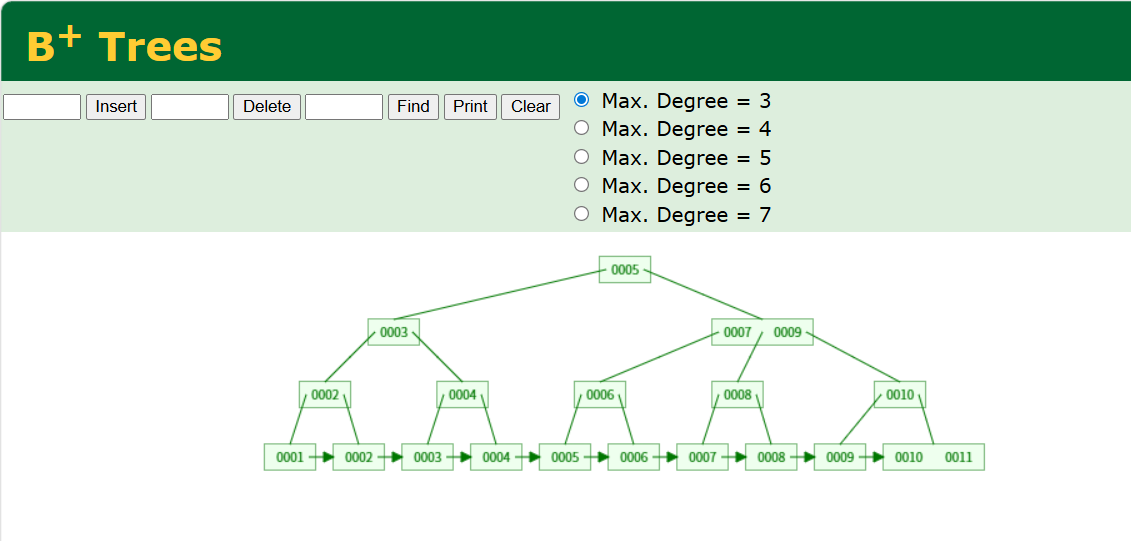
B+Tree 是一种平衡多路搜索树,其核心特征如下:
非叶子节点(内部节点)
- 只存储索引键值,不存储实际数据。
- 每个索引值对应一个子节点指针。
- 所有键值按从小到大顺序排列。
- 作用:作为路由表,指引查询走向下一层。
叶子节点
- 存储完整的数据行(聚簇索引的情况)或主键值(二级索引的情况)。
- 同一层级的叶子节点通过双向链表串联,形成有序序列。
- 叶子节点之间的顺序就是索引值的排序顺序。
查找过程示例(以聚簇索引为例):
查询 id = 22。
- 从根节点进入,比较 22 与节点内的键值,确定走左或右分支。
- 到达内部节点,继续比较,最终定位到某个叶子节点。
- 在叶子节点内找到
id = 22的完整数据行。 - 如果需要查询
id = 23, 24,无需重新查找根节点,直接沿叶子链表向后遍历即可。
为什么 MySQL 选择 B+Tree?
- 树高稳定(通常 3~4 层),磁盘 I/O 次数少。
- 范围查询效率高,依赖叶子链表。
- 非叶子节点只存索引,单页可存储更多键值,进一步降低树高。
2. Hash
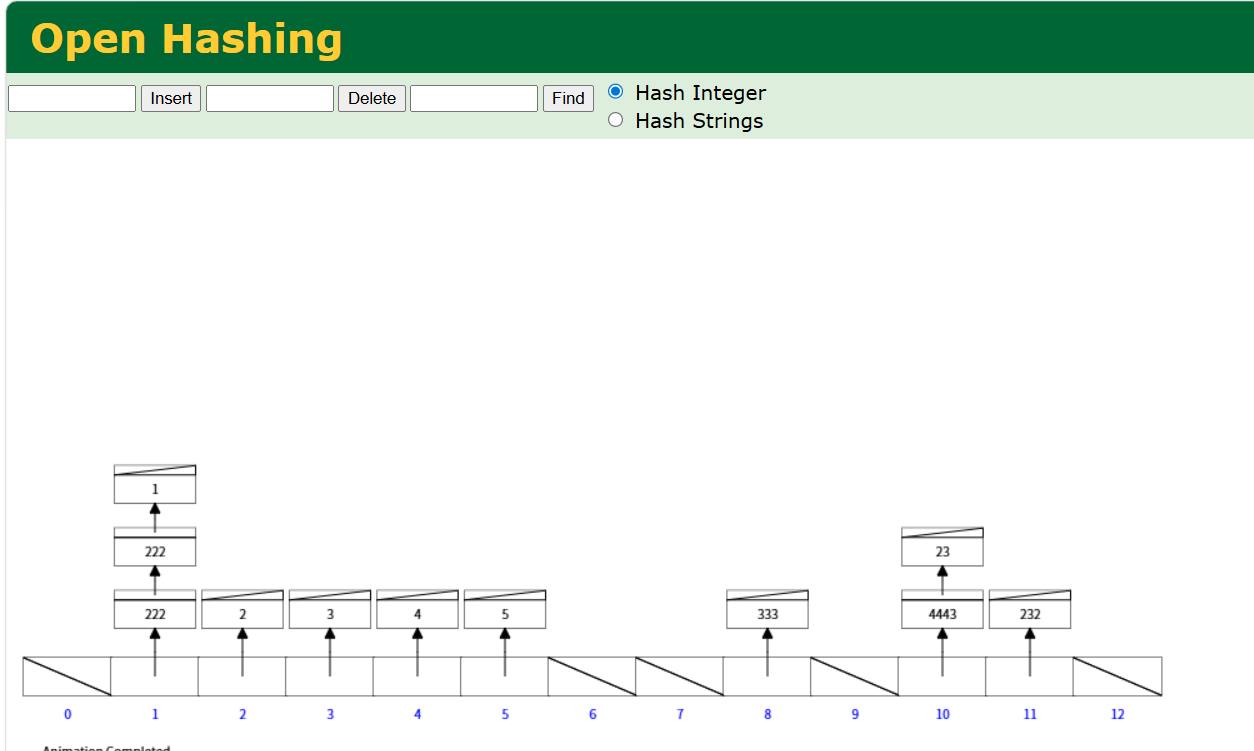
Hash 索引基于哈希表实现。对于给定的索引键值,通过哈希函数计算一个整数(哈希码),然后根据哈希码直接定位到对应的哈希桶,桶内存储指向数据行的指针。
查找过程示例:
查询 name = '张三'。
- 计算
hash('张三'),得到哈希码07。 - 定位到 07 号哈希桶。
- 遍历桶内链表,找到键值为
'张三'的项,取出数据指针。
优点
- 等值查询(
=、IN)的时间复杂度为 O(1),理论上比 B+Tree 更快。
缺点
- 不支持范围查询(如
>,<,BETWEEN),因为哈希码不保持原键值的大小顺序。 - 不支持排序(
ORDER BY无效)。 - 存在哈希冲突:不同键值可能产生相同哈希码,冲突严重时链表变长,查询性能下降。
在 MySQL 中的实际应用
- Memory 存储引擎支持显式创建 Hash 索引。
- InnoDB 存储引擎默认使用 B+Tree,但内部提供自适应 Hash 索引(AHI),当热点数据频繁等值查询时自动启用,对用户透明。
- 普通业务开发中,一般无需手动选择 Hash 索引,B+Tree 能覆盖绝大多数场景。
三、物理存储方式:聚簇索引与二级索引
在 InnoDB 存储引擎中,索引按物理存储方式分为两类:聚簇索引(Clustered Index) 和 二级索引(Secondary Index),也称为非聚簇索引或辅助索引。
两者的根本区别在于:叶子节点存储的是什么。
1. 聚簇索引(Clustered Index)
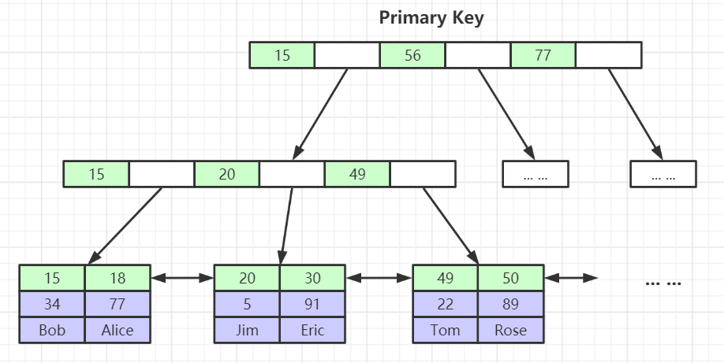
定义
聚簇索引并不是一种独立的索引类型,而是一种数据存储方式。InnoDB 中,表数据本身就是按照 B+Tree 组织的,这个树的叶子节点上存放的就是整张表的行数据。因此,聚簇索引就是表本身。
规则
- 如果表定义了主键,InnoDB 使用主键作为聚簇索引。
- 如果表没有显式定义主键,InnoDB 会选择第一个不允许为 NULL 的唯一索引作为聚簇索引。
- 如果也没有这样的唯一索引,InnoDB 内部会自动生成一个 6 字节的隐藏行 ID(DB_ROW_ID)作为聚簇索引。
特点
- 叶子节点存储完整的数据行(所有列)。
- 数据行的物理顺序与索引键值的逻辑顺序一致,但注意:这是逻辑上的“顺序”,物理上不保证严格连续。
- 聚簇索引对主键的等值查询和范围查询都非常快,因为找到叶子节点即找到数据。
一个表能有多少个聚簇索引?
只能有一个。因为数据行本身只能按一种顺序组织存储。
2. 二级索引(Secondary Index)
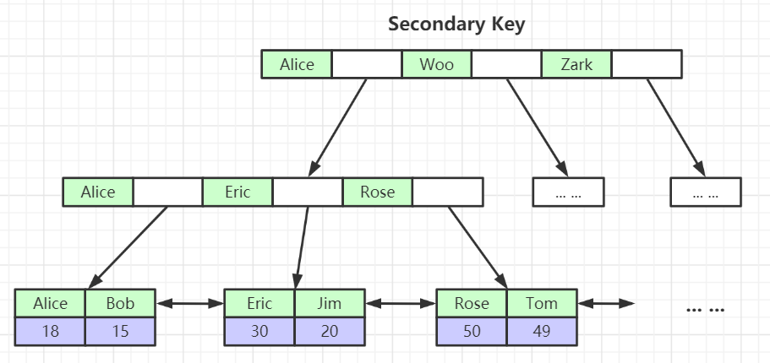
定义
除聚簇索引之外的所有索引都称为二级索引。它们也是一棵独立的 B+Tree,但叶子节点不存储完整的数据行,而是存储主键的值(或行 ID,如果表没有主键)。
特点
- 叶子节点存储的是主键值,而不是数据行本身。
- 一个表可以有很多个二级索引(MySQL 理论上限为 64 个,实际建议控制在 5~6 个)。
- 二级索引的 B+Tree 中,键值的顺序与主键的顺序无关。
回表
当通过二级索引查询数据时,执行流程如下:
- 在二级索引树中找到匹配的叶子节点,获取对应行的主键值。
- 再根据这个主键值,去聚簇索引树中查找完整的行数据。
- 这个过程称为回表(Table Lookup by Primary Key)。
回表需要额外的磁盘 I/O,因此应尽量避免。减少回表的常见手段是使用覆盖索引(在第五节中详细说明)。
3. MyISAM 的对比
MyISAM索引文件和数据文件是分离的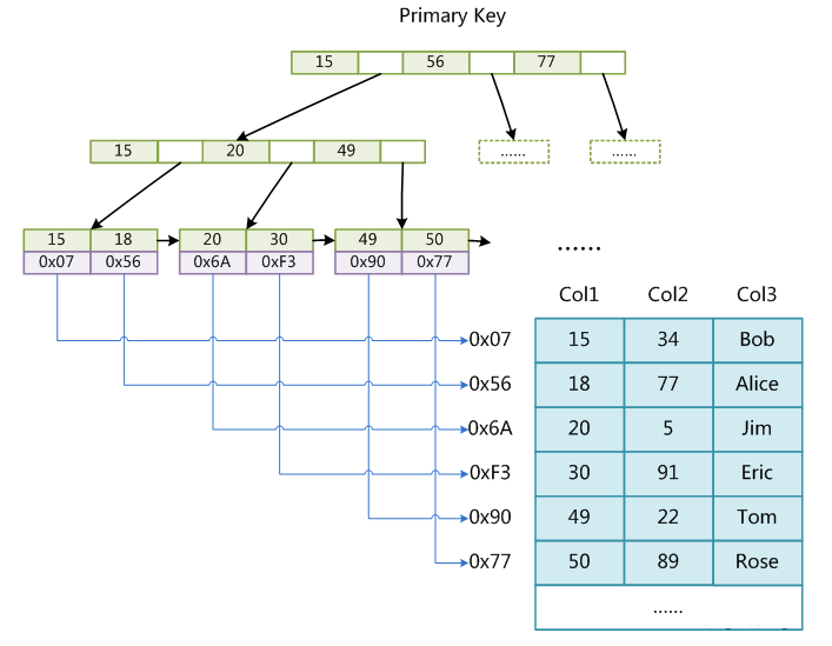
MyISAM 存储引擎不区分聚簇索引和二级索引,所有索引都是非聚集的。
- 索引文件(
.MYI)和数据文件(.MYD)分离。 - 索引叶子节点存储的是数据行的物理地址(偏移量或行指针)。
- 查找过程:通过索引找到行地址,再到数据文件中读取行。
InnoDB 的设计(聚簇索引 + 二级索引存主键值)相比 MyISAM 的优势在于:
- 主键查询无需回表。
- 二级索引的更新只需要维护主键引用,而不是物理地址,行移动时不会产生大量索引维护。
四、逻辑功能划分:常见索引类型与优化机制
从逻辑功能角度,MySQL 提供多种索引类型,适用于不同的查询场景。本节介绍六种常用索引类型,以及两个重要的优化机制:覆盖索引和索引下推。
1. 主键索引(PRIMARY KEY)
- 特殊的唯一索引,列值必须唯一,且不允许为 NULL。
- 一张表只能有一个主键索引。
- 在 InnoDB 中,主键索引就是聚簇索引,叶子节点存储完整数据行。
- 创建方式:
PRIMARY KEY (id)
2. 唯一索引(UNIQUE)
- 索引列的值必须唯一,但允许为 NULL(可以有多个 NULL)。
- 一张表可以有多个唯一索引。
- 作用:保证业务字段的唯一性(如邮箱、手机号),同时加速查询。
- 创建方式:
UNIQUE INDEX idx_phone (phone)
3. 普通索引(INDEX / KEY)
- 最基本的索引类型,没有唯一性约束。
- 索引列的值可以重复,也允许 NULL。
- 目的:单纯加速查询。
- 创建方式:
INDEX idx_name (name)
4. 联合索引(Composite Index)
- 在多个列上建立的索引,如
INDEX idx_name_age_position (name, age, position)。 - 底层 B+Tree 中的键值是多个字段的组合,排序规则:先按第一个字段排序,第一个字段相同时按第二个字段排序,以此类推。
- 最左前缀匹配原则:查询条件必须从索引的最左列开始,并且不能跳过中间的列。
- ✔
WHERE name = 'a' AND age = 10(使用索引) - ✔
WHERE name = 'a'(使用索引) - ✖
WHERE age = 10(不走索引,未从最左列开始) - ✖
WHERE name = 'a' AND position = 'manager'(只使用 name 列,跳过了 age,position 无法使用索引)
- ✔
- 范围查询(
>、<、BETWEEN)会终止索引对后续列的匹配。例如WHERE name = 'a' AND age > 10 AND position = 'manager',position 无法使用索引。 - 联合索引的设计是性能优化的核心,应尽量将等值查询的列放在左边,范围查询的列放在右边。
5. 前缀索引
- 针对字符串列(VARCHAR、CHAR 等),只取前 N 个字符建立索引,如
INDEX idx_email_prefix (email(20))。 - 优点:索引占用空间更小,一个索引页能容纳更多键值,减少 I/O。
- 缺点:无法用于
ORDER BY和GROUP BY,也无法作为覆盖索引(除非查询的字段只有前缀列本身)。 - 适用场景:长字符串列且区分度集中在前缀部分(如邮箱、URL 前缀)。
- 创建方式:
INDEX idx_address (address(15))
6. 覆盖索引(Covering Index)
- 定义:一个查询需要读取的所有列,都可以从某个二级索引的 B+Tree 叶子节点中直接获得,不需要回表访问聚簇索引。
- 判定方式:
EXPLAIN的Extra字段显示Using index。 - 优点:避免回表操作,大幅减少磁盘 I/O,尤其适合只查询少数列的语句。
- 示例:
表有联合索引(name, age),执行SELECT name, age FROM employees WHERE name = 'LiLei',该索引已包含 name 和 age,无需回表。
若执行SELECT * ...,则仍需回表获取未索引的列。 - 使用建议:尽量用
SELECT 列名代替SELECT *,为高频查询创建合适的联合索引以实现覆盖。
7. 索引下推(ICP,Index Condition Pushdown)
- 定义:MySQL 5.6 引入的优化技术。在使用二级索引进行查询时,将
WHERE条件中可以使用索引列判断的部分,下推到存储引擎层,在索引遍历过程中提前过滤数据。 - 作用:减少不必要的回表次数。
- 适用条件:
- 辅助索引(二级索引)。
- 查询的
WHERE条件中,有部分列属于该索引,但不是最左前缀的连续列(如联合索引中跳过的列)。 - 例如:联合索引
(name, age, position),查询WHERE name LIKE 'LiLei%' AND age = 22。5.6 之前,先通过name LIKE 'LiLei%'拿到多条主键,再回表逐条检查age = 22;5.6 之后,在索引树上就检查age = 22,只有符合的行才回表。
- 判定方式:
EXPLAIN的Extra字段显示Using index condition。 - 注意:ICP 仅适用于二级索引,聚簇索引已存储完整行,无需此优化。
五、索引设计与优化核心原则
索引设计的目标是在保证查询性能的前提下,尽可能减少索引维护成本和存储空间。以下是几条核心原则,每条都有明确的适用场景和依据。
1. 联合索引设计与最左前缀法则
联合索引 (a, b, c) 的 B+Tree 按 (a, b, c) 复合键值排序。查询时,MySQL 优化器会从索引最左侧开始匹配,直到遇到范围条件(>、<、BETWEEN、LIKE 'abc%' 视为范围?实际 LIKE 'abc%' 可以走索引,但后续列失效)或跳过一个列为止。
匹配规则:
- ✔
WHERE a = 1 AND b = 2 AND c = 3:完全匹配,三列都用。 - ✔
WHERE a = 1 AND b = 2:只用了 a, b。 - ✔
WHERE a = 1:只用了 a。 - ✔
WHERE a = 1 AND b > 2 AND c = 3:只用 a 和 b(b 范围后 c 失效)。 - ✖
WHERE b = 2 AND c = 3:a 缺失,不走索引。 - ✖
WHERE a = 1 AND c = 3:跳过 b,只用 a,c 失效。
设计建议:
- 将等值查询的列放在左边,范围查询的列放在右边。
- 将区分度高的列放在左边(过滤掉更多行)。
- 为
ORDER BY字段建立联合索引时,字段顺序应与ORDER BY一致,且WHERE条件中的等值列放在前面。
2. 主键设计:优先使用自增 ID
InnoDB 聚簇索引的数据页按主键顺序存储。如果使用自增整型主键:
- 新插入的行总是追加到现有数据页末尾,页分裂次数极少。
- 主键占用空间小(4 或 8 字节),二级索引叶子节点存储主键值,间接减小二级索引体积。
如果使用 UUID 等随机值作为主键:
- 新插入行需要插入到索引中间位置,频繁页分裂,造成碎片和性能下降。
- UUID 字符串占用 16 字节以上,二级索引空间更大。
例外情况:
- 某些分布式场景必须使用分布式 ID(雪花算法等),仍建议保持数值型、趋势递增。
- 业务需要按非自增字段做聚簇存储(如时间序列数据),可考虑将业务字段设为主键。
3. 尽量使用覆盖索引
覆盖索引是指:SELECT 列表中所有字段都包含在某个二级索引的叶子节点中(即索引列 + 主键)。此时无需回表,EXPLAIN 的 Extra 显示 Using index。
收益:
- 减少随机 I/O,尤其在大数据量下效果显著。
- 适合只查询少数列的轻量查询。
实践:
- 避免
SELECT *,只查询必要的列。 - 为高频查询创建包含查询列和过滤列的组合索引,实现覆盖。
示例:
表有 INDEX(name, age),查询 SELECT name, age FROM employees WHERE name = 'LiLei' 走覆盖索引;查询 SELECT name, age, position FROM ... 则需要回表。
4. 其他设计原则
代码先行,索引后上
业务功能开发完成后,收集涉及该表的所有 SQL(通过慢查询日志或业务埋点),统一分析再建立索引。过早建索引可能导致无用索引,增加写负担。
不要在小基数字段上建索引
基数是字段中不同值的个数。性别(男/女)等字段基数极低,走索引不一定比全表扫描快。优化器可能忽略这类索引。通常建议基数低于表行数 10%~20% 的字段谨慎建单列索引。
长字符串使用前缀索引
对 VARCHAR(255) 等长字段建立完整索引占用空间大,可选取前 N 个字符建前缀索引,例如 INDEX(login_name(20))。代价是:
- 无法用于
ORDER BY / GROUP BY。 - 不能作为覆盖索引(除非只查询前缀列本身)。
where 与 order by 冲突时优先 where
如果某个查询既要过滤又要排序,但无法同时满足两者的索引需求,一般优先满足 WHERE 条件的索引,将结果集缩小后,对少量数据进行文件排序(filesort)通常可接受。除非排序字段本身有索引能避免 filesort 且代价更优。
基于慢 SQL 做迭代优化
索引设计不是一次性的。定期开启慢查询日志,识别高频慢 SQL,针对性地添加或调整索引。每次调整后应验证效果,并删除冗余索引。
六、索引失效的常见场景
建立了索引并不代表查询一定会使用它。以下场景中,MySQL 优化器会选择不使用索引,即使索引存在。
1. 在索引列上使用函数或表达式
-- 失效
SELECT * FROM employees WHERE YEAR(hire_time) = 2023;
-- 改为范围查询,可走索引
SELECT * FROM employees
WHERE hire_time >= '2023-01-01' AND hire_time < '2024-01-01';
原因:索引存储的是列原始值,YEAR(hire_time) 改变了值与索引键的对应关系,无法直接利用索引。
类似情况:DATE(create_time)、UPPER(name)、列参与运算 age + 1 = 30 等。
2. 隐式类型转换
-- 假设 phone 字段是 VARCHAR 类型
-- 失效
SELECT * FROM user WHERE phone = 13800000000;
-- 正确写法(加引号)
SELECT * FROM user WHERE phone = '13800000000';
原因:MySQL 会将字符串列与数字比较时,把字符串转换为数字。转换后索引失效。规则:对索引列应用转换函数(隐式或显式)都会导致失效。
3. 模糊查询以通配符开头
-- 失效
SELECT * FROM employees WHERE name LIKE '%Li';
-- 可走索引(前缀匹配)
SELECT * FROM employees WHERE name LIKE 'Li%';
原因:B+Tree 按前缀排序。'%Li' 无法确定起始比较位置,必须扫描全部。
例外:如果查询字段全部被覆盖索引包含,某些情况下优化器可能选择全索引扫描(type=index),但仍不是高效的范围查找。
4. 使用 OR 连接非索引列
-- 假设 name 有索引,age 无索引
-- 失效(可能全表扫描)
SELECT * FROM employees WHERE name = 'LiLei' OR age = 22;
原因:MySQL 需要对 OR 两边条件分别执行索引查找,如果其中一侧没有索引,优化器认为全表扫描更经济。可改写为 UNION:
SELECT * FROM employees WHERE name = 'LiLei'
UNION
SELECT * FROM employees WHERE age = 22;
如果 OR 两边都是索引列,且优化器评估成本合理,则可能走索引。
5. 联合索引违反最左前缀
-- 索引 (name, age, position)
-- 失效
SELECT * FROM employees WHERE age = 22;
SELECT * FROM employees WHERE position = 'manager';
SELECT * FROM employees WHERE name = 'LiLei' AND position = 'manager'; -- 只用到 name
原因:B+Tree 按最左列排序,跳过首列时剩余列无序,无法使用。
6. 范围查询右边的列
-- 索引 (name, age, position)
-- 只用到了 name 和 age,position 失效
SELECT * FROM employees
WHERE name = 'LiLei' AND age > 22 AND position = 'manager';
原因:age > 22 是一个范围条件,B+Tree 在满足该条件后,position 不再有序。设计联合索引时应将等值条件的列放在左边,范围条件的列放在右边。
7. 使用 != 或 <>
-- 大概率失效
SELECT * FROM employees WHERE name != 'LiLei';
原因:不等值匹配会导致大量结果集,优化器认为全表扫描代价更低。特殊情况:如果 != 条件过滤后数据比例非常小(如状态字段绝大部分是某个值),可能走索引。
8. IS NULL / IS NOT NULL
-- 可能失效(取决于优化器评估)
SELECT * FROM employees WHERE name IS NOT NULL;
原因:IS NOT NULL 通常扫描大量数据,优化器可能选择全表扫描。对于 IS NULL,如果列允许 NULL 且稀疏,可能走索引。
9. NOT IN / NOT EXISTS
-- 大概率失效
SELECT * FROM employees WHERE name NOT IN ('LiLei', 'HanMeimei');
原因:与 != 类似,结果集过大。可以改写为 IN + 业务取反,或使用 EXISTS 但需测试效果。
10. 数据分布原因
即使写法正确,优化器也可能选择不使用索引。典型场景:
- 查询返回数据量超过表的 20%~30%(经验值),优化器认为全表扫描更快(顺序 I/O)。
- 表数据量极小(几十行),全表扫描成本极低。
诊断方法:使用 FORCE INDEX 强制走索引验证性能差异,或使用 EXPLAIN 查看优化器的成本估算。
七、SQL 语句的全链路优化技巧
索引设计完成后,SQL 语句的写法决定了索引能否被有效利用。本节从查询语句的编写角度,总结若干实用优化技巧。
1. 避免 SELECT *,只查询必要字段
SELECT *会返回表中所有列,通常无法使用覆盖索引,必须回表获取不在索引中的列。- 即使表中所有列都在某个联合索引中(极少见),
*也会增加网络传输和内存开销。 - 建议:明确列出需要使用的字段,同时为高频查询设计包含这些字段的联合索引,实现覆盖索引。
-- 不推荐
SELECT * FROM employees WHERE name = 'LiLei';
-- 推荐(假设已有索引 (name, age, position))
SELECT name, age, position FROM employees WHERE name = 'LiLei';
2. 优化 ORDER BY 排序
排序能否使用索引,取决于 ORDER BY 的字段顺序和方向是否与联合索引一致。
走索引排序的条件:
ORDER BY的字段顺序符合联合索引的最左前缀。- 所有字段排序方向相同(全部
ASC或全部DESC)。MySQL 8.0 之前不支持混合方向索引,8.0 引入降序索引可支持。 WHERE条件中的等值列与ORDER BY列共同构成索引前缀。
不走索引排序的场景:
- 使用
ORDER BY但中间跳过了索引中的某个列。 - 对索引列使用函数后再排序(如
ORDER BY DATE(create_time))。 - 排序字段不属于同一个索引。
-- 假设索引 (name, age, position)
-- 走索引排序
SELECT * FROM employees WHERE name = 'LiLei' ORDER BY age, position;
-- 不走索引排序(跳过了 age)
SELECT * FROM employees WHERE name = 'LiLei' ORDER BY position;
当无法避免 filesort 时:
- 确保
sort_buffer_size足够大。 - 控制单行数据总大小,避免触发磁盘排序。MySQL 通过
max_length_for_sort_data决定使用单路排序还是双路排序(参见第五节 trace 示例)。
3. 优化 GROUP BY 分组
GROUP BY 的优化逻辑与 ORDER BY 类似:先排序后分组,因此同样适用最左前缀规则。
优化手段:
- 尽量让
GROUP BY使用索引,避免临时表和filesort。 - 如果不需要排序,可以显式添加
ORDER BY NULL禁止排序,减少开销。
-- 不需要排序的分组查询
SELECT age, COUNT(*) FROM employees GROUP BY age ORDER BY NULL;
- 将
WHERE条件放在GROUP BY之前(即先过滤再分组),减少分组数据量。
4. 优化 LIMIT 深分页
深分页(LIMIT 100000, 10)性能差的根源:MySQL 需要先扫描并丢弃前 100000 行,然后返回 10 行。
优化方案一:使用覆盖索引 + 延迟关联
-- 原始慢查询
SELECT * FROM employees ORDER BY id LIMIT 100000, 10;
-- 优化后:先通过覆盖索引查出主键,再关联原表
SELECT * FROM employees
INNER JOIN (
SELECT id FROM employees ORDER BY id LIMIT 100000, 10
) AS tmp USING(id);
优化方案二:记录上次查询的最后位置(游标分页)
-- 第一页
SELECT * FROM employees WHERE id > 0 ORDER BY id LIMIT 10;
-- 下一页(假设上一页最后 id = 100)
SELECT * FROM employees WHERE id > 100 ORDER BY id LIMIT 10;
该方法仅适用于按唯一键(如自增主键)排序且不允许跳页的场景。
5. 使用 EXPLAIN 分析并验证优化效果
每次修改 SQL 或索引后,应使用 EXPLAIN 检查执行计划,重点关注:
type:是否为ref、range、const(好),还是ALL、index(差)。key:是否使用了预期的索引。Extra:是否出现Using filesort、Using temporary(需优化),或Using index(覆盖索引)、Using index condition(索引下推)。rows:估算扫描行数是否显著降低。
可配合 EXPLAIN FORMAT=JSON 获取更详细成本信息。
6. 避免在 WHERE 子句中对索引列进行隐式或显式处理
第六节已列举,此处归纳为一条原则:让索引列独立出现在比较运算符的一侧,不做任何包装。
-- 错误示例
WHERE DATE(create_time) = '2023-01-01'
WHERE id + 1 = 10
WHERE LEFT(phone, 3) = '138'
-- 正确写法
WHERE create_time >= '2023-01-01' AND create_time < '2023-01-02'
WHERE id = 9
WHERE phone LIKE '138%'
7. 合理使用 IN 和 EXISTS
- 当外表小、内表大时,
IN通常优于EXISTS(基于子查询优化策略,实际 MySQL 会做等价改写,但可参考一般原则)。 - 当外表大、内表小时,
EXISTS可能更优。 IN列表中的值不宜过多(建议不超过 200),否则优化器可能放弃索引转为全表扫描。
-- 如果子查询结果集较小,IN 合适
SELECT * FROM employees WHERE dept_id IN (SELECT id FROM departments WHERE location = 'Beijing');
-- 如果主表较大,子查询结果集较大,可改为 EXISTS
SELECT * FROM employees e WHERE EXISTS (SELECT 1 FROM departments d WHERE d.id = e.dept_id AND d.location = 'Beijing');
8. 批量操作代替循环单条操作
在应用层,避免在循环中逐条执行 SQL。应使用批量插入、批量更新或批量删除。
-- 不推荐(循环执行)
for id in id_list:
UPDATE employees SET status = 1 WHERE id = id;
-- 推荐(一条 SQL)
UPDATE employees SET status = 1 WHERE id IN (id_list);
批量操作减少了语句解析和事务提交次数,也更容易利用索引。
八、EXPLAIN 执行计划精读
EXPLAIN 是分析查询语句执行计划的唯一入口。通过在 SELECT 语句前加上 EXPLAIN 关键字,MySQL 会输出优化器选择的执行计划,包括表访问顺序、使用的索引、连接类型、估算行数等信息。
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';
输出结果包含多个列,以下逐一说明。
1. id
SELECT的序列号,表示查询中每个子句的执行顺序。id越大,优先级越高,越先执行。id相同,从上往下依次执行。id为NULL,表示该行用于合并其他行的结果(如UNION的临时表)。
2. select_type
查询类型,用于区分普通查询、子查询、联合查询等。
| 类型 | 含义 |
|---|---|
SIMPLE |
简单查询,不包含子查询或 UNION |
PRIMARY |
复杂查询中最外层的 SELECT |
SUBQUERY |
子查询,出现在 SELECT 或 WHERE 中(非 FROM 子句) |
DERIVED |
派生表,出现在 FROM 子句中的子查询 |
UNION |
UNION 操作中第二个及后续的 SELECT |
UNION RESULT |
从 UNION 临时表获取结果的 SELECT |
3. table
- 当前行所访问的表名。
- 可能是真实表名,也可能是派生表别名(如
<derived3>)。
4. partitions
- 查询涉及的分区。如果表未分区,显示
NULL。 - 仅在使用
EXPLAIN PARTITIONS时才会显示该列(MySQL 5.7 后默认包含)。
5. type(重要)
访问类型,表示 MySQL 如何查找表中的行。从优到劣排序:
| 类型 | 含义 |
|---|---|
system |
表中只有一行数据(等于系统表),是 const 的特例 |
const |
使用主键或唯一索引与常量比较,最多返回一行 |
eq_ref |
连接查询中,使用主键或唯一索引关联,最多返回一行 |
ref |
使用普通索引或唯一索引的前缀,返回多行 |
range |
索引范围扫描,如 BETWEEN、>、<、IN |
index |
全索引扫描,遍历整个索引树(通常比 ALL 快,因为索引体积小) |
ALL |
全表扫描,扫描聚簇索引所有叶子节点,需要优化 |
目标:至少达到 range 级别,争取 ref 或 const。
6. possible_keys
- 查询可能使用的索引列表。
- 该列基于查询条件中的列和表中的索引定义生成,与实际是否使用无关。
- 如果为
NULL,表示没有可用的索引。
7. key
- MySQL 实际选择的索引。
- 如果为
NULL,表示未使用索引。 - 可以使用
FORCE INDEX或IGNORE INDEX强制优化器选择或忽略某些索引。
8. key_len
- MySQL 在索引中使用的字节数。
- 通过该值可以判断联合索引中被实际使用了哪些列。
- 计算规则(以 UTF-8 为例):
- 数值类型:
TINYINT=1,SMALLINT=2,INT=4,BIGINT=8 - 时间类型:
DATE=3,TIMESTAMP=4,DATETIME=8 - 字符串
CHAR(n):3n字节(UTF-8 每个字符最多 3 字节) - 字符串
VARCHAR(n):3n + 2字节(额外 2 字节存储长度) - 允许
NULL的列额外占用 1 字节
- 数值类型:
示例:联合索引 (name VARCHAR(20), age INT),key_len = 20*3+2 + 4 = 66。如果 EXPLAIN 显示 key_len = 66,说明两列都使用了;如果 key_len = 62,说明只用到了 name 列(20*3+2)。
9. ref
- 显示
key列所示的索引在查找时使用的列或常量。 - 常见值:
const(常量),db.table.column(某个表的字段)。
10. rows
- MySQL 估算的需要读取的行数。
- 该值基于统计信息和索引基数计算,并非精确值。
rows越小越好,但应与实际数据分布结合判断。
11. filtered
- 表示经过索引条件过滤后,剩余满足其他
WHERE条件的行数百分比(最大 100)。 - 该列仅在
EXPLAIN EXTENDED中出现(MySQL 5.7 后默认包含)。 - 与
rows配合使用:rows * filtered / 100可估算最终返回的行数。
12. Extra(重要)
提供额外信息,常见值及含义:
| 值 | 含义 |
|---|---|
Using index |
使用覆盖索引,无需回表(好) |
Using where |
使用 WHERE 条件过滤,但索引未被完全覆盖 |
Using index condition |
使用索引下推(ICP),在索引层过滤了部分条件 |
Using temporary |
使用临时表(通常需要优化,常见于 GROUP BY 或 DISTINCT 无索引) |
Using filesort |
需要额外排序操作(需要优化,常见于 ORDER BY 不走索引) |
Select tables optimized away |
查询被优化器直接返回结果,无需访问表(如 MIN(id) 在自增主键上) |
Impossible WHERE |
WHERE 条件永远为假,不会返回任何行 |
优化目标:
- 避免
Using temporary和Using filesort。 - 尽量出现
Using index或Using index condition。
使用示例
-- 建表
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
position VARCHAR(50),
INDEX idx_name_age (name, age)
);
-- 查询
EXPLAIN SELECT name, age FROM employees WHERE name = 'LiLei' AND age > 20;
输出:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | employees | range | idx_name_age | idx_name_age | 152 | NULL | 10 | Using index |
分析:
type=range:索引范围扫描,可接受。key=idx_name_age:使用了联合索引。key_len=152:name(50*3+2)+age(4)全部使用。Extra=Using index:覆盖索引,无需回表。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)