Jasmine: Harnessing Diffusion Prior for Self-supervised Depth Estimation
作者: Jiyuan Wang, Chunyu Lin, Cheng Guan, Lang Nie, Jing He, Haodong Li, Kang Liao, Yao Zhao
发表: NeurIPS 2025 (arXiv:2503.15905)
官方代码: https://github.com/wangjiyuan9/jasmine
项目主页: https://wangjiyuan9.github.io/Jasmine/
摘要
本文提出了Jasmine,这是首个基于Stable Diffusion (SD)的自监督单目深度估计框架,有效利用SD的视觉先验来增强无监督预测的清晰度和泛化能力。以往的SD深度估计方法都需要高精度监督信号,而本文通过设计一个混合批次图像重建(Mix-batch Image Reconstruction, MIR)的代理任务,在没有额外监督的情况下保护了SD模型的细节先验。此外,为了解决SD的尺度-平移不变估计与自监督尺度不变深度估计之间的固有不对齐问题,作者提出了Scale-Shift GRU (SSG)模块,不仅弥合了分布差距,还隔离了SD输出的细粒度纹理免受重投影损失的干扰。实验表明,Jasmine在KITTI基准上达到了自监督方法的SoTA性能,并在多个数据集上展现了卓越的零样本泛化能力。
1. 引言与研究动机
1.1 研究背景
单目深度估计是计算机视觉中的一个基础问题,在3D/4D重建、自动驾驶等下游应用中发挥着关键作用。与监督方法相比,自监督单目深度估计(SSMDE)仅从视频序列中挖掘3D信息,显著降低了对昂贵的真实深度标注的依赖。这些方法通过跨帧重投影损失的几何约束来推导监督信号,无处不在的视频数据进一步暗示了其无限的工作潜力。
然而,基于视图重建的损失存在固有挑战:
-
遮挡问题:某些像素在当前帧可见但在相邻帧被遮挡
-
无纹理区域:缺乏视觉特征的区域难以建立对应关系
-
光照变化:光照条件的改变破坏光度一致性
这些问题严重限制了模型恢复细粒度细节的能力,并可能导致对特定数据集的病态过拟合。
1.2 扩散模型的机遇与挑战
近期研究表明,Stable Diffusion (SD)具有强大的视觉先验,可以提升深度预测的清晰度和泛化能力。Marigold、E2E FT和Lotus等工作进一步揭示:
-
单步去噪可以达到与多步相当的精度
-
这对自监督范式尤为关键,因为它不仅加速了推理去噪过程,还显著降低了自重重投影监督的训练成本
然而,关键挑战在于:
微调扩散模型进行密集预测需要高精度监督来保护其固有的先验知识。监督方法通常使用合成RGB-D数据集,其中干净的深度标注与SD的高质量训练数据对齐,从而保持其潜在空间完整。
相比之下,直接应用自监督引入了一个关键挑战:
-
重投影损失或预训练深度伪标签会将由伪影和模糊引起的扰动梯度传播到SD的潜在空间
-
在训练早期阶段迅速破坏其先验知识
-
本质上,"高精度监督"必须在开始时存在以保护SD的潜在空间
1.3 核心洞察与解决方案
作者发现了一个方便且有价值的替代方案:RGB图像本身。图像固有地包含完整的视觉细节,避免了自监督中对外部深度的依赖,并与SD原始的图像生成目标完美对齐。
基于这一洞察,本文提出了两个核心创新:
创新一:混合批次图像重建 (MIR)
通过任务切换器构建代理任务,同一SD模型在每个训练批次中交替重建合成/真实图像和预测深度图。该策略:
-
重新利用自监督重投影损失来容忍颜色变化,同时保持结构一致性
-
有意将颜色保真度与深度精度解耦
-
最终成功保护SD先验
创新二:Scale-Shift GRU (SSG)
SD的VAE输出范围固有地限制在[-1, 1]内。现有方法在训练过程中将GT深度图归一化到此范围,在推理时通过最小二乘对齐恢复绝对尺度和偏移,产生**尺度-平移不变(SSI)**深度预测。
然而,自监督框架依赖于耦合的深度-姿态优化,理论上要求偏移不变性严格为零以实现稳定收敛,最终产生**尺度不变(SI)**深度预测。
SSG模块:
-
迭代地将SSI深度对齐到SI深度,通过细化尺度-偏移参数
-
充当梯度滤波器,抑制自监督训练中由伪影污染引起的异常梯度
-
在强制执行几何一致性的同时,保护SD输出的细粒度纹理细节
1.4 主要贡献
-
1. 首次将SD引入自监督深度估计框架:消除了对高精度深度监督的依赖,同时保留SD在细节清晰度和跨域泛化方面的固有优势
-
2. 提出MIR代理任务:通过自监督梯度共享来锚定SD的先验,避免由重投影伪影引起的SD潜在空间损坏
-
3. 提出Scale-Shift GRU (SSG):动态对齐深度尺度,同时滤波噪声梯度,解决自监督深度估计中的SSI与SI分布不匹配问题
-
4. 卓越性能:
-
在KITTI数据集上达到所有SSMDE的SoTA性能
-
在多个数据集上展现显著的零样本泛化(甚至超越使用增强数据训练的模型)
-
前所未有的细节保留能力
-

图1:Jasmine深度估计结果展示。无需任何高精度深度监督,Jasmine在多样化场景中实现了细节丰富且准确的深度估计。
2. 相关工作
2.1 自监督深度估计
自监督深度估计(SSDE)可分为:
-
基于立体的方法:从同步图像对中学习深度
-
基于单目的方法:使用时序视频帧
近年来,DepthAnything v1/v2揭示了通过在大规模图像-深度对上训练可以获得准确的单图像深度预测模型和强大的泛化能力。然而,这样的数据集仍然只占可用视频数据的一小部分。这促使作者探索最具挑战性的配置:仅在视频序列上训练,同时保持单帧推理能力。
2.2 扩散模型用于深度感知
随着扩散范式在生成任务中展现才华,DDP首先将深度感知重新表述为深度图去噪任务。追随者如DDVM、MonoDiffusion和D4RD证明了这一范式在各种MDE子任务中的优势。
随后,Stable Diffusion在深度感知任务中展示了巨大潜力:
-
• VPD、TAPD、Prior-Diffusion:将SD用作多模态特征提取器,利用文本模态信息提高深度估计精度
-
• Marigold、GeoWizard:通过微调SD来增强模型泛化和细节保留
-
• E2E FT、Lotus:通过优化噪声调度过程进一步加速推理
本文的Jasmine延续了这些工作,并将SD扩展到自监督领域。
3. 方法详解
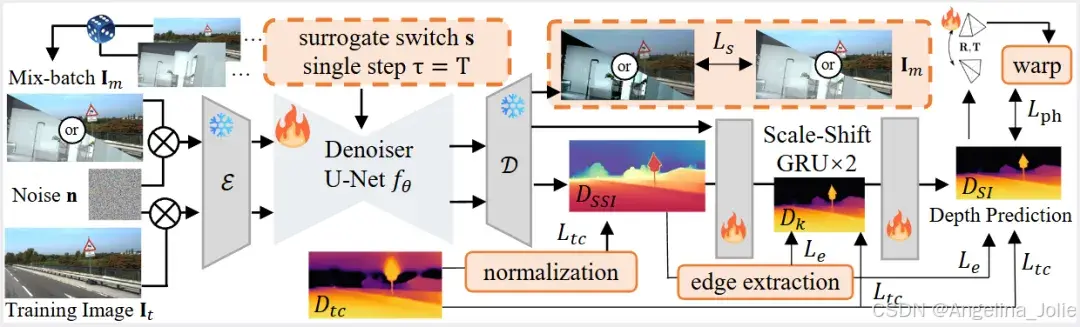
图2:Jasmine微调协议示意图。展示了通过任务切换器交替执行深度预测和图像重建,以及Scale-Shift GRU对深度分布进行对齐和梯度滤波的过程。
3.1 预备知识
自监督单目深度估计


3.2 代理任务:图像重建
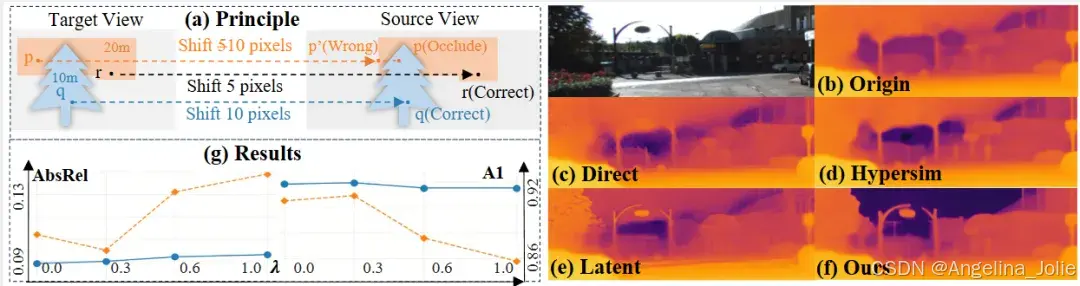
图3:混合批次图像重建(MIR)示意图。展示了如何通过交替重建合成图像和真实图像来保护SD的视觉先验。

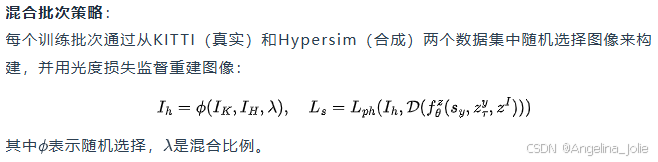
3.3 Scale-Shift GRU
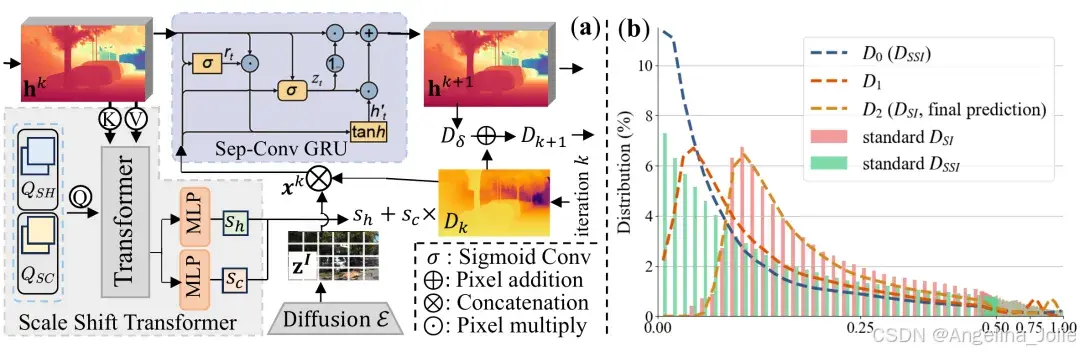
图4:Scale-Shift GRU (SSG)模块架构。(a) SSG模型结构,包含Scale-Shift Transformer (SST)。(b) 深度分布对齐可视化,展示了从SSI深度到SI深度的渐进对齐过程。


3.4 针对自监督的SD微调协议
训练流程

4. 实验
4.1 实现细节
-
• 骨干网络:Stable Diffusion v2.1
-
• 训练数据集:KITTI、Hypersim(混合批次)
-
• 优化器:AdamW
-
• 学习率:3e-5
-
• 批量大小:32(8张A800 GPU)
-
• 训练步数:25k steps(约1天)
-
• 单步去噪:
损失权重(从LaTeX源提取):
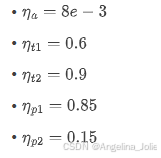
4.2 评估数据集
训练数据集:
-
• KITTI:Zhou's split,39,810训练样本,4,424验证样本
-
• Hypersim:461个室内场景,约28k样本
零样本评估数据集:
-
• DrivingStereo:500张/天气条件(雾、云、雨、晴)
-
• CityScape:1,525张测试图像
-
• ETH3D:高分辨率(6048×4032),898样本
4.3 主要结果
KITTI基准性能
表1:KITTI数据集定量结果对比(从LaTeX源Table 1提取)
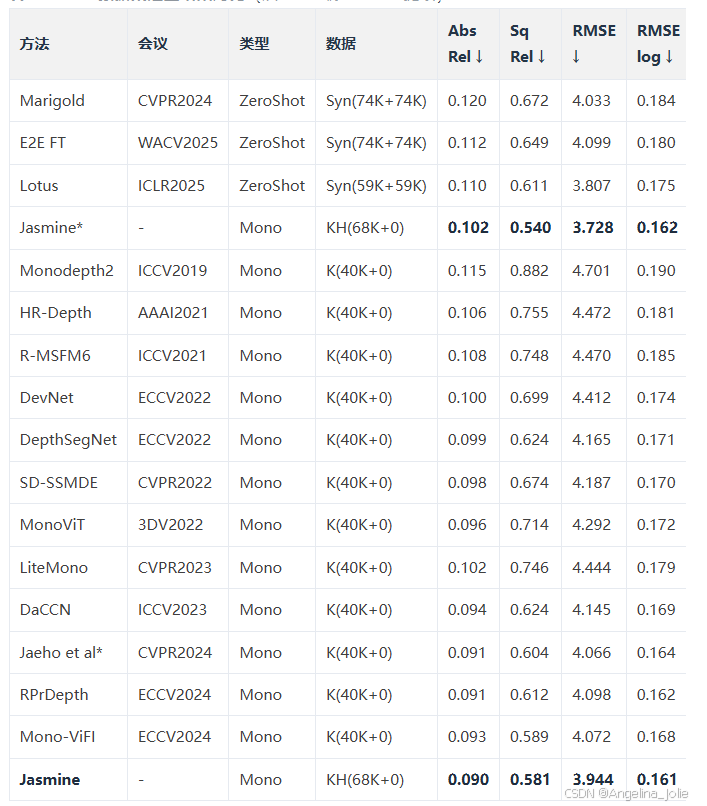

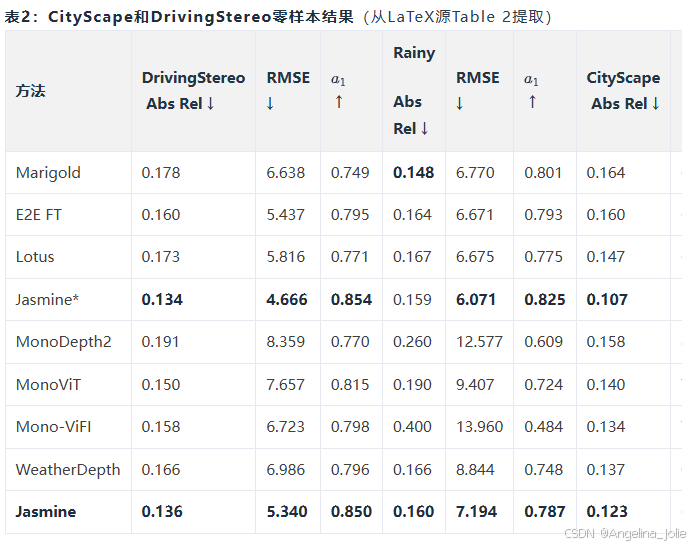
关键发现:
-
Jasmine在CityScape和四种天气场景(雾、云、雨、晴)的DrivingStereo数据集上均达到SoTA性能
-
即使没有像WeatherDepth那样在天气增强数据集上训练,Jasmine在雨天条件下仍然有效
-
展现了强大的域泛化能力
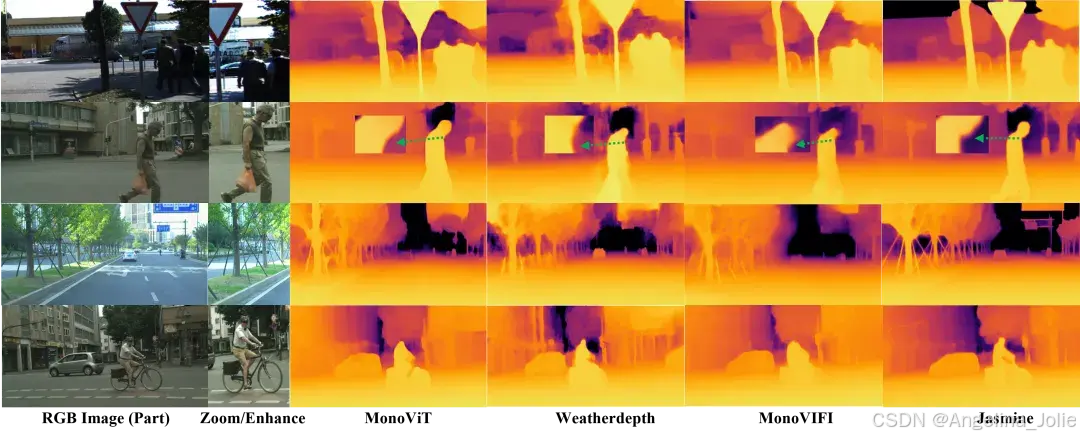
图5:定性结果对比。Jasmine在KITTI、DrivingStereo和CityScape数据集上的深度估计结果与其他最具泛化性和最佳性能的自监督方法对比。
深度反归一化分析
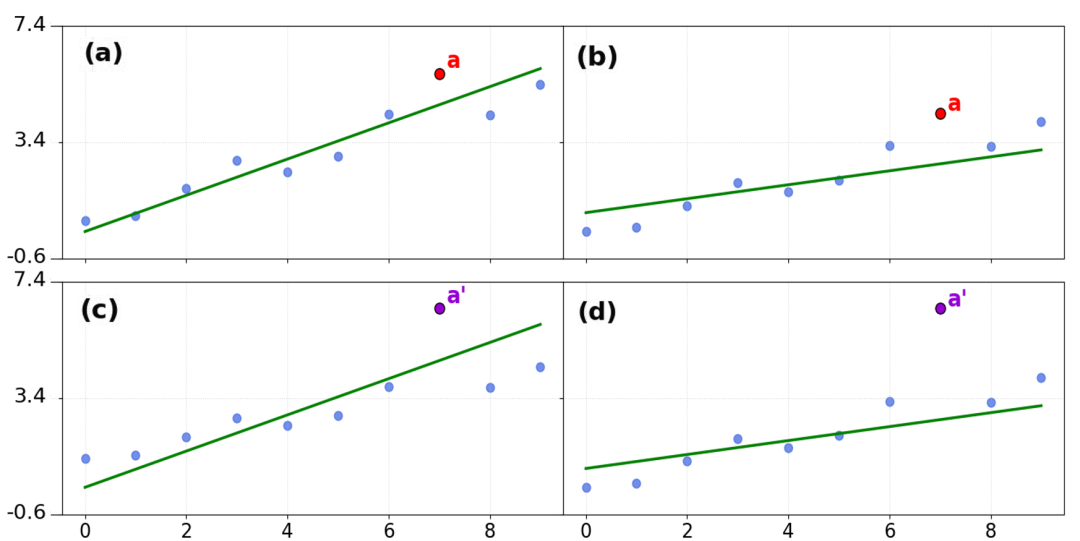
图6:不同反归一化方案对比。展示了最小二乘(LSQ)对齐和中位数对齐的效果差异。LSQ对齐倾向于适应异常值,而中位数对齐对异常值不敏感,保持多数点的精度。
表1和表2中的Jasmine与Jasmine*的区别:
-
• Jasmine*:使用最小二乘(LSQ)对齐(适用于零样本场景)
-
• Jasmine:使用中位数对齐(适用于同域训练场景)
三种典型的深度反归一化策略:


4.4 消融研究
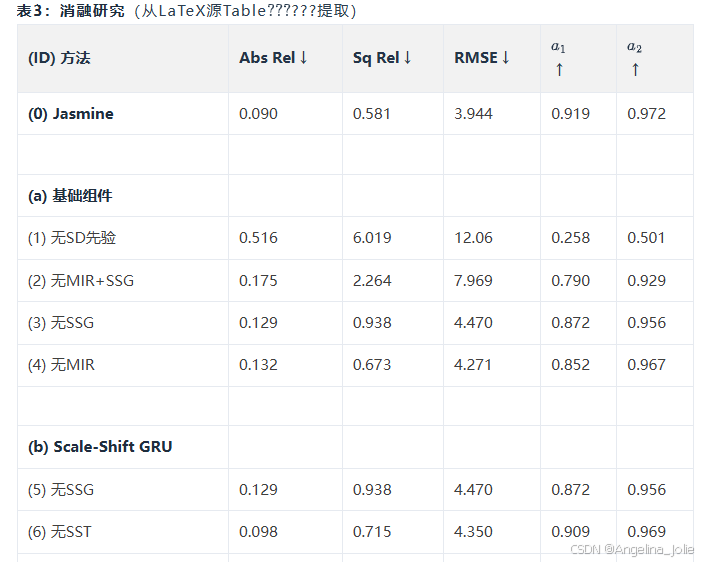
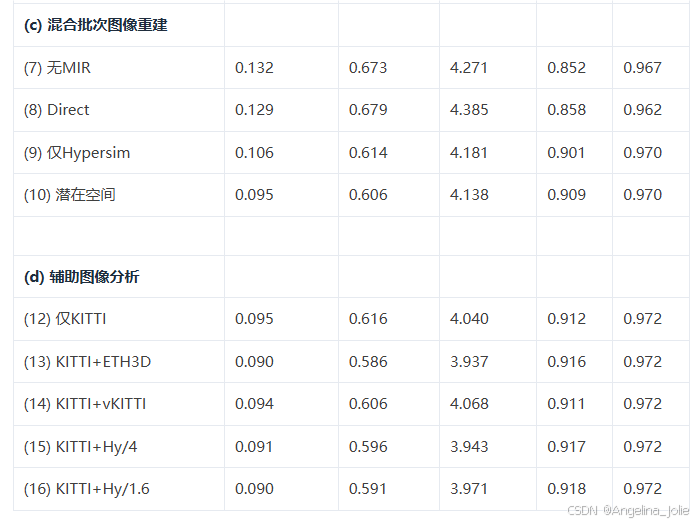
关键发现:
基础组件分析:
-
SD先验最关键:从头训练(ID 1)导致灾难性失败(AbsRel↑473%,RMSE↑206%)
-
禁用MIR(ID 4)或SSG(ID 3)分别降低性能47%/43%,证明了深度分布对齐和SD细节保护的必要性
SSG消融:
-
朴素GRU(ID 6)可以初步解决分布错位,但SSI和SI深度之间的尺度差异难以通过线性加法恢复
-
引入SST后,整体模型性能进一步提升10%,最终达到SoTA性能
MIR分析:
-
Jasmine显著优于替代方案,如仅KITTI/仅合成重建(ID 8,9)和潜在空间监督(ID 10)
-
证明了提出的MIR的有效性
辅助图像分析:
-
与真实/合成数据集相比,数据集内容更重要,多样化场景比类似主数据集(KITTI)的街景(虚拟KITTI图像)提供更大收益
-
MIR对图像采样分辨率鲁棒:下采样到1/1.6甚至1/4对结果影响很小
-
MIR即使在小规模数据集(少于1k样本)上仍然有效
4.5 推理延迟
表4:推理延迟对比(从LaTeX源提取)
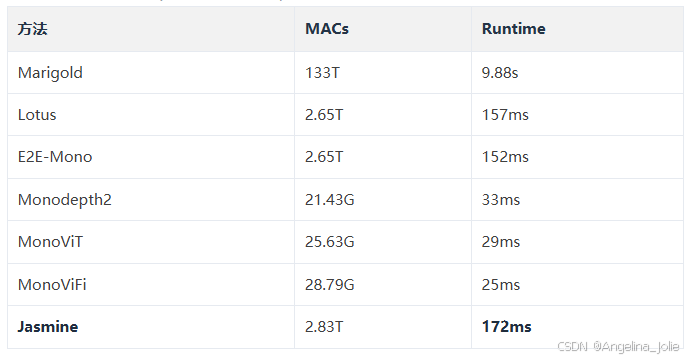
说明:
-
• MACs和Runtime在1024×320分辨率、RTX 4090上测量
-
• Jasmine虽然比传统自监督方法计算成本更高,但遵循了像Marigold这样的模型的趋势,以成本换取卓越性能
-
• SSG模块增加的延迟可以忽略不计,Jasmine的运行时与Lotus相当
5. 结论与展望
5.1 主要发现
-
自监督与扩散模型的成功结合:Jasmine首次成功将Stable Diffusion引入自监督深度估计框架,突破了以往SD方法必须依赖高精度监督的限制。
-
MIR代理任务的有效性:通过混合批次图像重建,在不依赖外部深度标注的情况下保护了SD的视觉先验,实现了细节保留与几何一致性的平衡。
-
SSG的创新价值:Scale-Shift GRU不仅解决了SSI与SI深度之间的分布不对齐问题,还充当了梯度滤波器,保护了细粒度纹理细节。
-
卓越的性能表现:
• KITTI上达到自监督方法的SoTA(Abs Rel 0.090)• 强大的零样本泛化能力• 跨数据集、跨天气、跨场景的鲁棒性
5.2 局限性与未来工作
当前局限性:
-
计算资源需求:SD模型较大,需要较高的GPU内存(8张A800)
-
推理速度:172ms相比传统CNN方法(25-33ms)仍有差距
-
合成数据依赖:虽然代理任务可以使用真实图像,但最佳性能仍需要一定比例的合成数据
未来方向:
1. 效率优化:探索模型压缩和加速技术,实现真正的实时推理
2. 扩展到其他任务:将Jasmine框架扩展到表面法线估计、分割等其他密集预测任务
3. 多模态融合:结合文本、LiDAR等多模态信息进一步提升性能
4. 自监督预训练:开发完全自监督的SD预训练策略,消除对合成数据的依赖
5.3 影响与意义
Jasmine的工作具有重要的理论和实践意义:
理论贡献:
• 证明了扩散模型可以在没有高精度监督的情况下进行微调
• 揭示了图像重建作为代理任务保护视觉先验的机制
• 阐明了SSI与SI深度估计之间的分布关系
实践价值:
• 为资源受限场景(难以获取深度标注)提供了高性能深度估计方案
• 展示了如何利用大规模生成模型的先验知识解决判别任务
• 为自监督学习与基础模型的结合提供了新的范式

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)