某AI漫剧超级工厂AI绘画与分镜自动化生成流水线详细设计方案(WORD)
导读:随着AIGC技术爆发,传统漫剧生产面临周期长、成本高及风格统一难等痛点,亟需构建工业化生产体系。本项目旨在打造“AI漫剧超级工厂”,通过部署Flux/SDXL大模型,集成LoRA角色微调与分镜自动化设计技术,实现多景别批量渲染、AI上色及图像超分辨率处理。建设内容涵盖从剧本到成图的全链路自动化流水线,重点攻克风格一致性控制难题。预期目标是实现漫剧生产的降本增效,建立标准化、规模化的AIGC内容工厂,引领漫剧产业向智能化、工业化转型升级。
一、为什么说传统漫剧生产到了结构性拐点
在讨论"怎么用AI做漫剧"之前,有必要先把"传统方式为什么不够用"说清楚。不是简单地说"效率低",而是具体到哪个环节、什么原因卡住了。
痛点一:生产效率与分发节奏完全错配
短视频平台的内容消耗速度以小时计,热点的生命周期以天计。而传统漫剧的分镜设计、描线、上色这几个核心环节高度依赖手工,完全是以月计的节奏。
这不是努力程度的问题,而是生产方式与分发环境的根本性错配。一个内容团队花了三个月做出一部精品漫剧,发现热点早就过了——这种尴尬在行业里几乎是常态。
痛点二:规模化量产的边际成本过高
传统漫剧的成本结构里,人力超过70%。这意味着产能的扩张几乎是线性的——多做一倍,就得多招一倍的人。这种边际成本结构使得"量产"在经济上根本不可行。
更麻烦的是,海量内容的A/B测试——这是现代内容营销的标配动作——在传统生产方式下几乎是奢侈品。做一版主力内容已经很贵了,哪有预算同时做十个版本测试哪个转化率更高?
痛点三:AI生图的风格一致性是核心技术难题
前两个痛点业界已经广泛认知,但第三个问题经常被低估:当你真正开始用AI生成漫剧分镜时,最大的拦路虎不是"能不能生成",而是"生成的东西前后对不上"。
同一个角色,第一集和第二集的脸型、眼距、发色可能完全不同;同一个场景,相邻两帧的光照方向截然相反。这种风格漂移(Style Drift)和角色串戏问题,是AI漫剧实现工业化交付的最核心技术障碍。
方案针对这三个痛点的解法,构成了整个系统设计的主线逻辑。
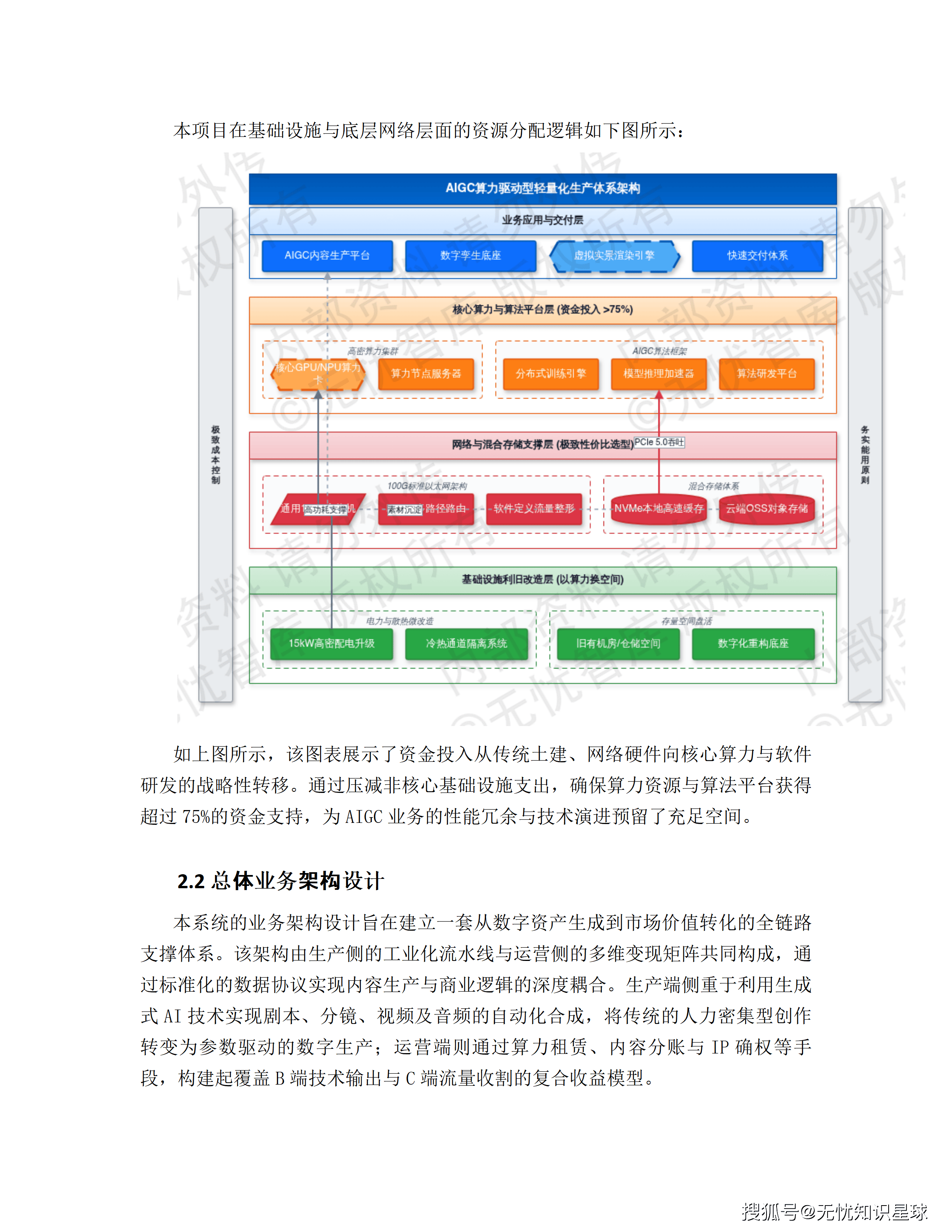
二、总体建设思路:以算力换空间,以算法代实景
方案的建设逻辑有一个非常清晰的核心判断:把钱从不动产投向算力。
这句话背后是一个具体的决策:彻底放弃物理实景拍摄棚、大型演播厅等重资产投入,转向"以算力换空间、以算法代实景"的路径。
传统物理棚建设有三个显著问题:报批和土建周期长(通常12-18个月);资产折旧快;空间复用率低——一个布置好某个场景的棚,换景要重新搭建,闲置率极高。
方案的替代方案是:盘活企业内部闲置的数据中心机房、低效利用的办公楼宇,对其进行微改造——升级供电到单机柜10-15kW的算力级配电标准,优化冷热通道隔离的精密散热系统。
这样做的结果:建设周期缩短60%以上,资产属性从低效不动产转向高效生产要素。
在网络架构上,方案同样坚持"务实能用"原则。原本高性能计算场景常用InfiniBand或专有RDMA网络,但其配套交换机与网卡成本是通用以太网的4-6倍,运维复杂度也高。方案选择标准100G以太网配合ECMP多路径路由,在满足业务需求的前提下,将网络建设成本降低70%以上。
这种"极致性价比"的建设哲学贯穿整个方案:资金必须精准投向核心算力卡和算法平台研发,其他地方能省则省。
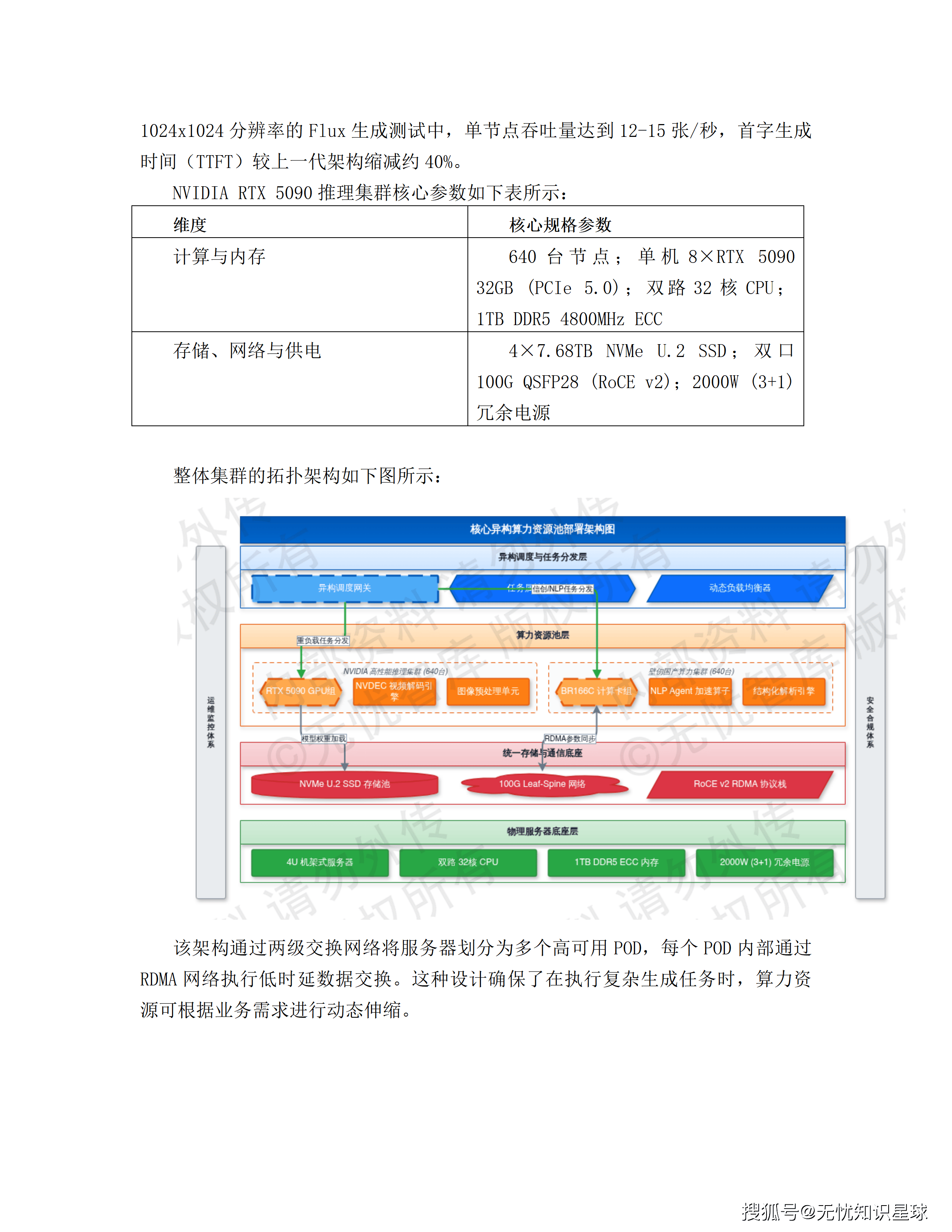
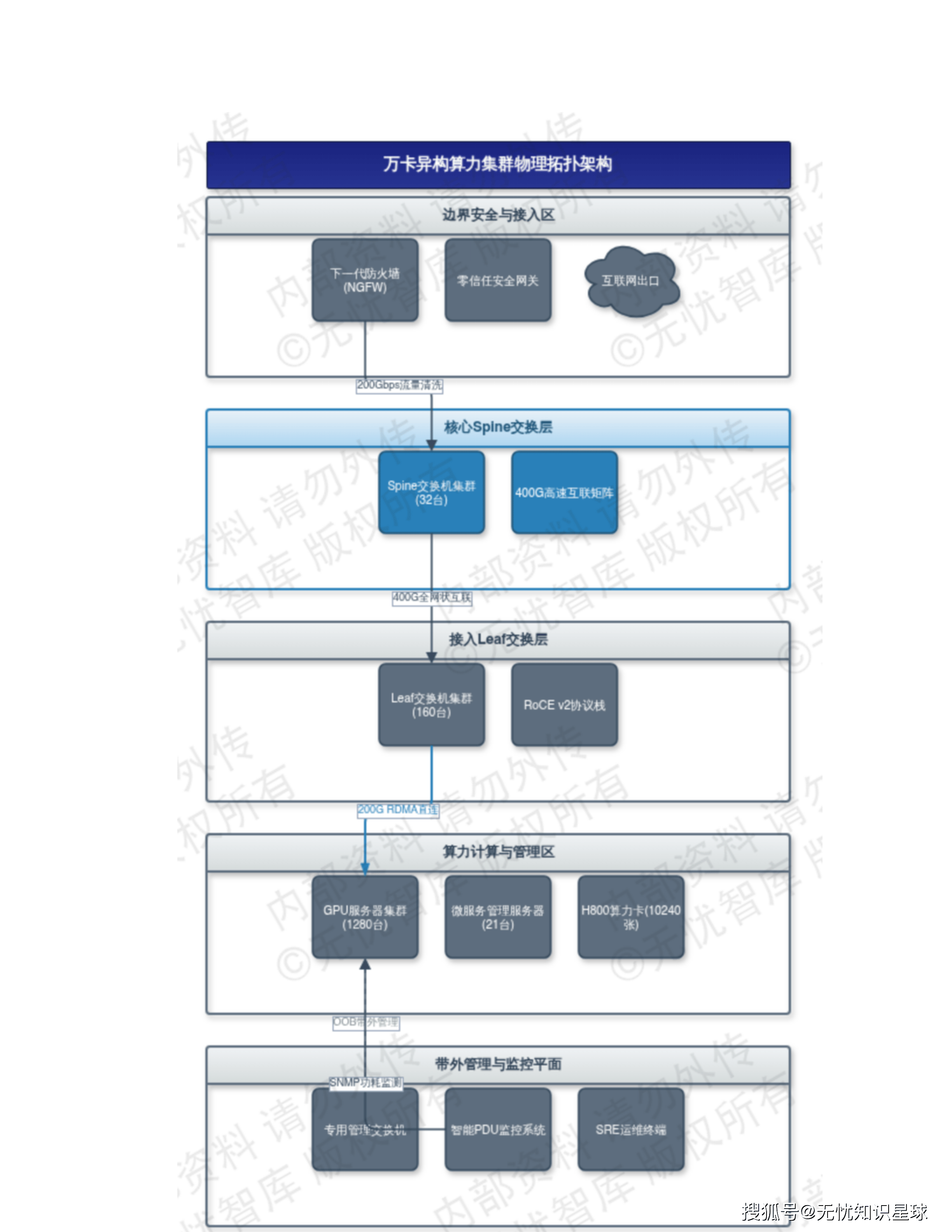
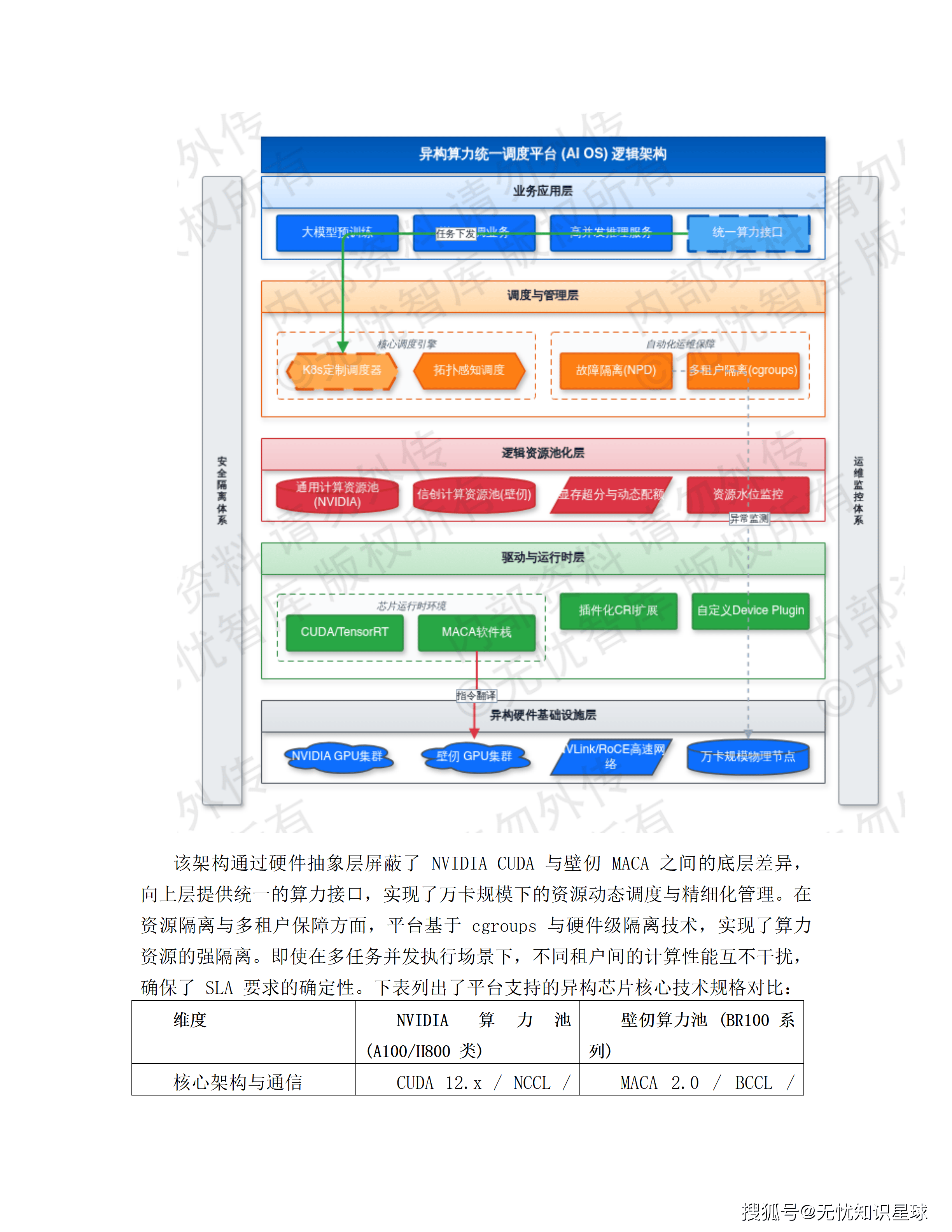
三、异构算力底座:NVIDIA与国产芯片各司其职
整个系统的算力底座由1280台GPU服务器构成,采用NVIDIA RTX 5090与国产壁仞166C各640台的50:50异构配置。这个配比不是随意决定的,背后有明确的业务分工逻辑。
NVIDIA RTX 5090集群:承担重负载生成任务
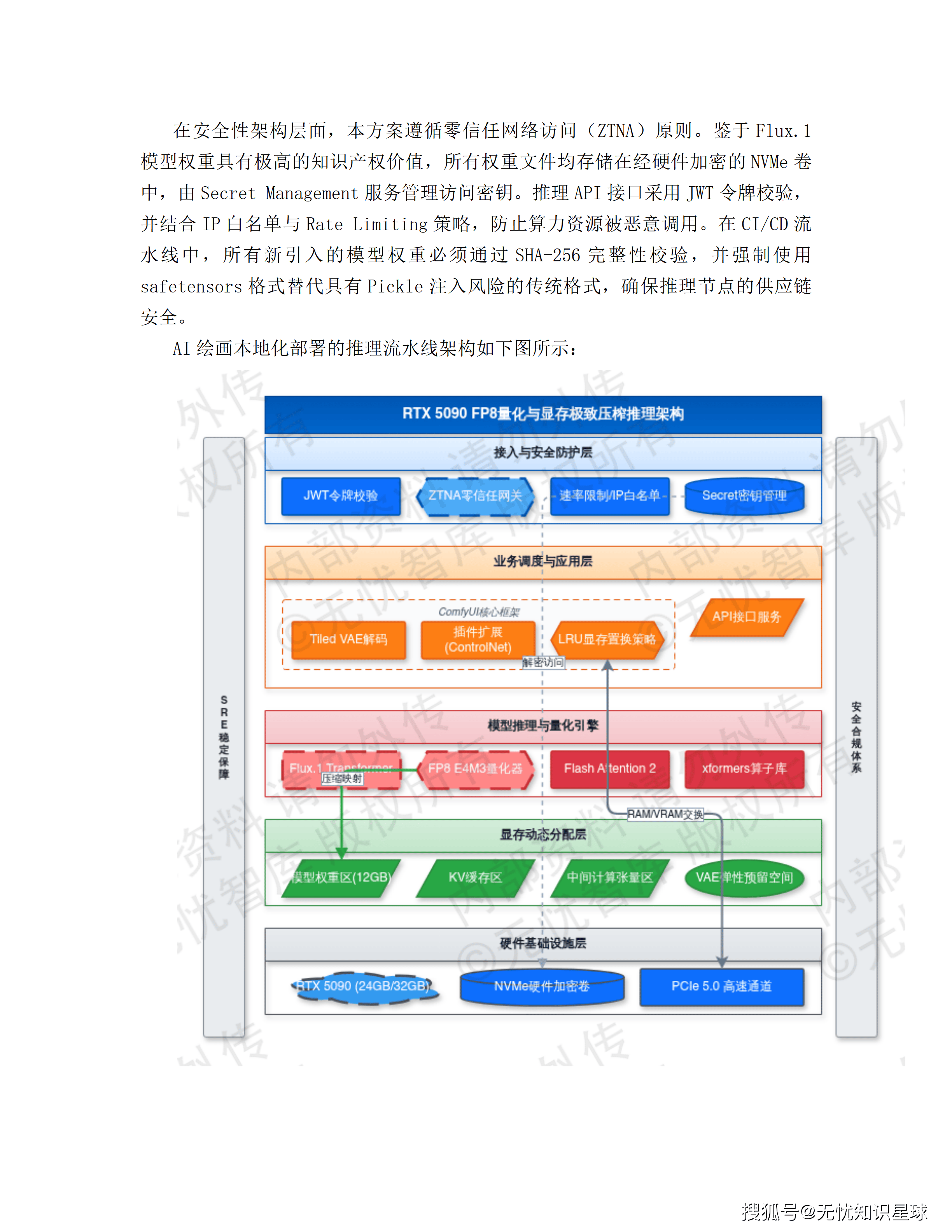
RTX 5090基于Blackwell架构,单卡32GB GDDR7显存,显存带宽突破1.5TB/s。这个规格意味着什么?Flux.1-dev这类高精度生成模型的权重可以直接加载,不需要激进量化来压缩显存占用——避免了量化带来的精度损失,对生成图像质量的影响是直接的。
每台服务器配置8张RTX 5090,通过PCIe Gen5总线提供单向64GB/s通信带宽。在1024×1024分辨率的Flux生成测试中,单节点吞吐量达到12-15张/秒,首字生成时间(TTFT)较上一代架构缩减约40%。
这一集群主要承担:Flux/SDXL等超大规模生成模型的推理、高频视频抽帧分析、多模态生成任务。
壁仞166C集群:合规要求与供应链安全
壁仞166C集群配置双路国产海光32核处理器,底层软件栈支持银河麒麟/统信UOS操作系统,以及昇思MindSpore、飞桨PaddlePaddle等国产框架。
这个集群主要承担:NLP Agent推理、JSON结构化数据拆分、基础图像识别,以及需要物理隔离的敏感业务处理。异构调度平台依据任务安全等级,将政务或金融级请求分发至此国产资源池。
统一调度平台屏蔽硬件差异
两套集群的存在产生了一个工程问题:上层业务代码怎么做到对硬件差异无感知?
方案通过三层抽象解决这个问题:
- 驱动层抽象:通过支持多厂商插件的容器运行时接口(CRI),自动加载对应GPU驱动环境
- 算力虚拟化:用vGPU技术对两类计算卡进行显存级切分,按需分配资源
- 统一算子库:引入兼容多芯片的中间编译器,模型代码在不同硬件上无缝迁移
上层业务只需声明"我需要多少算力",调度平台自动完成任务分发,不需要关注底层是哪颗芯片。
这套方案的测试结果:算力利用率提升约30%,国产化环境下的性能损耗控制在15%以内。
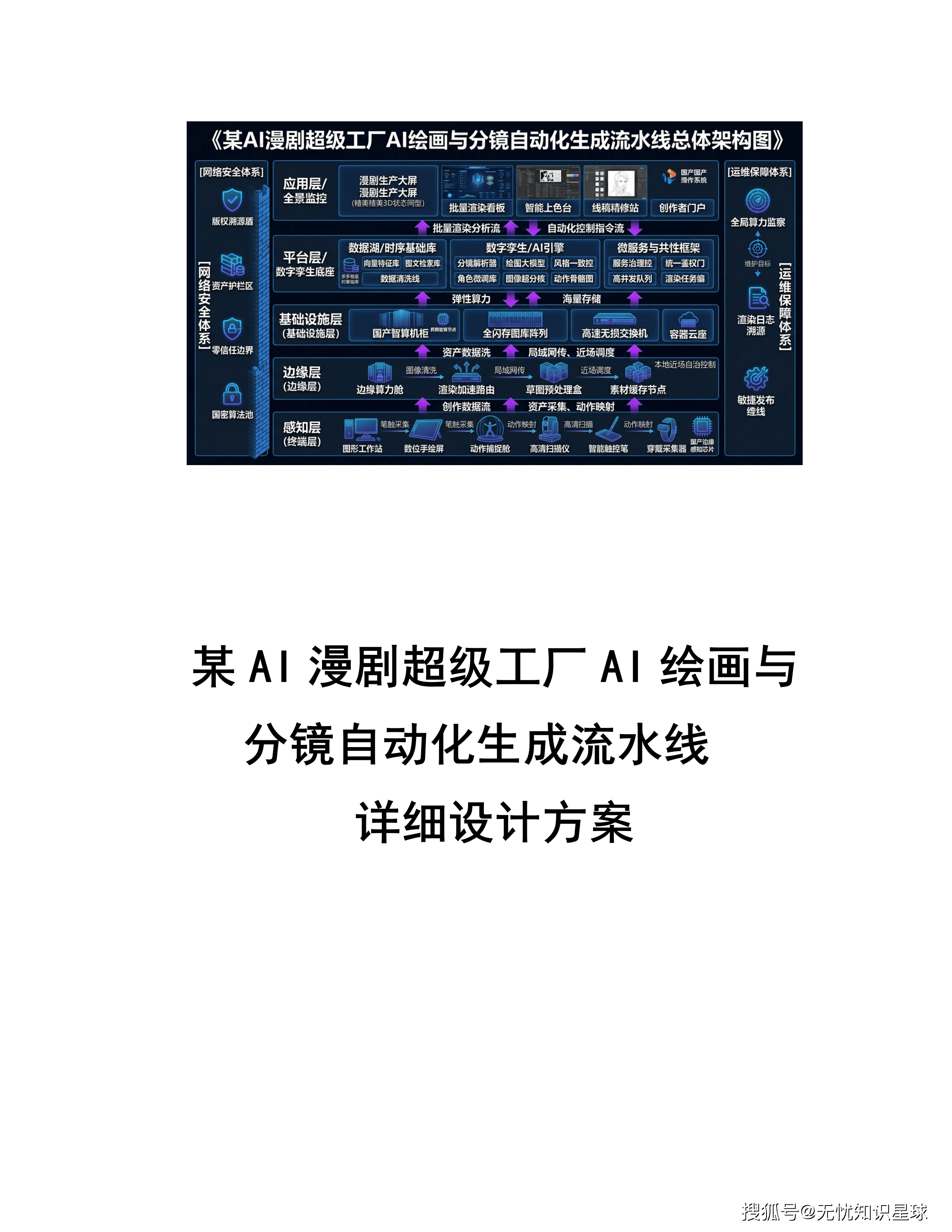
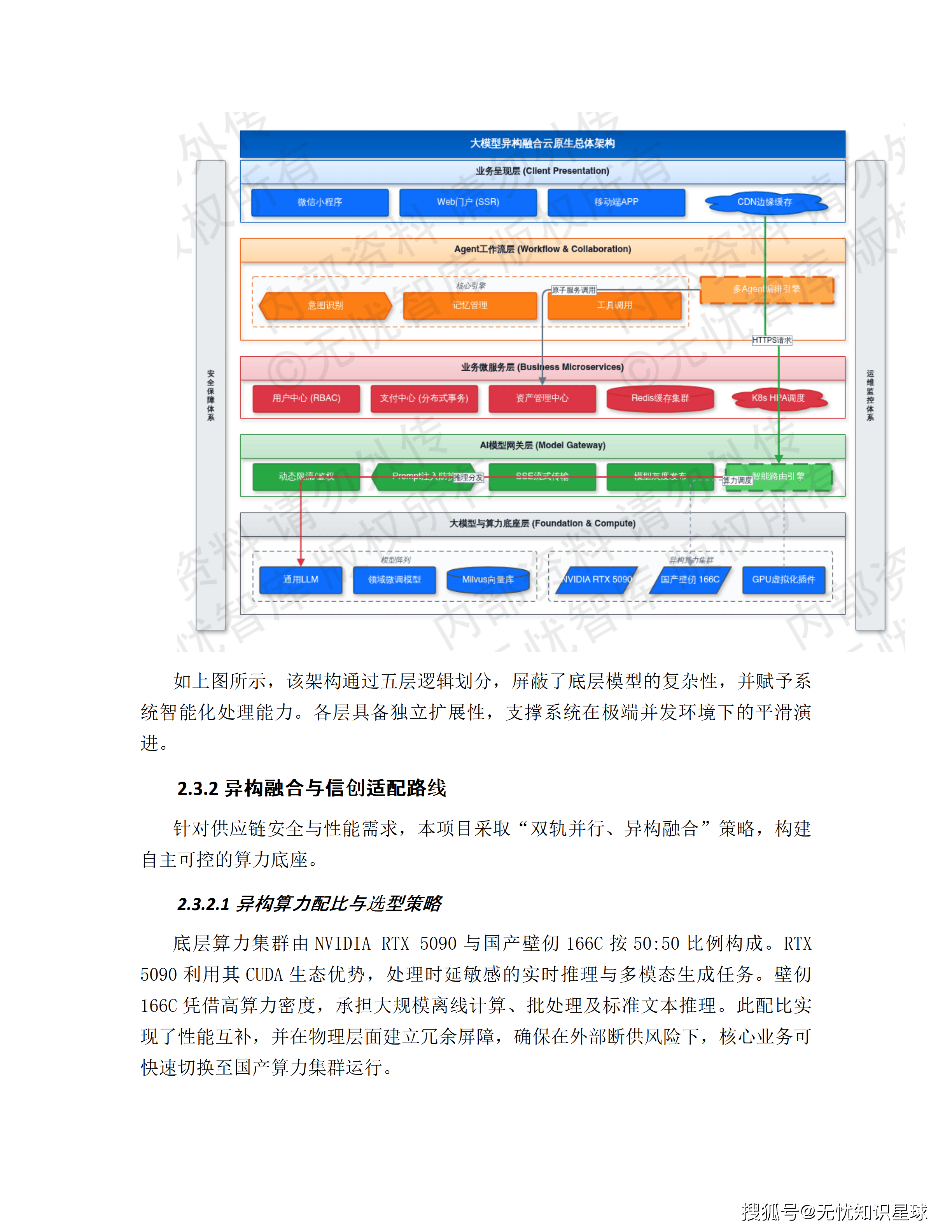
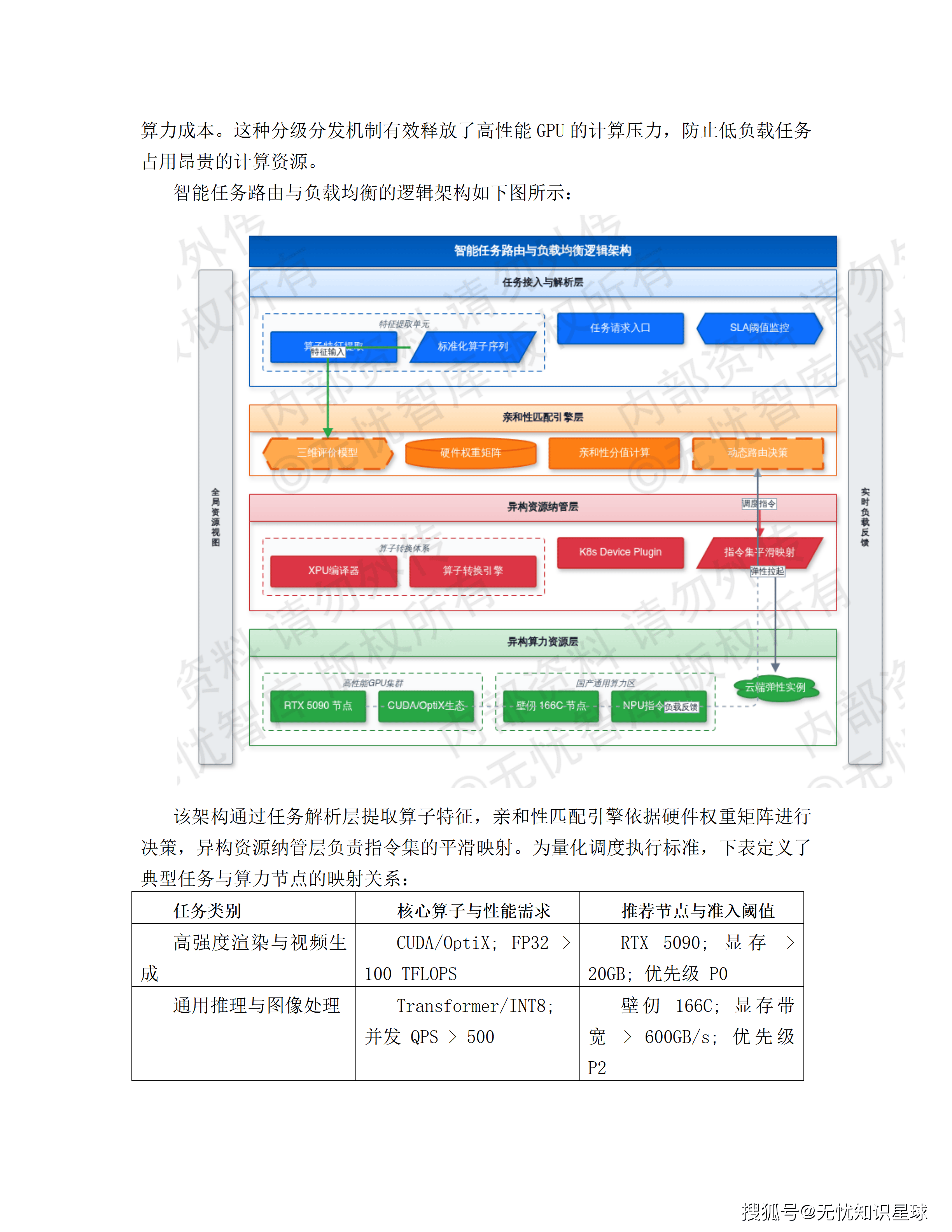
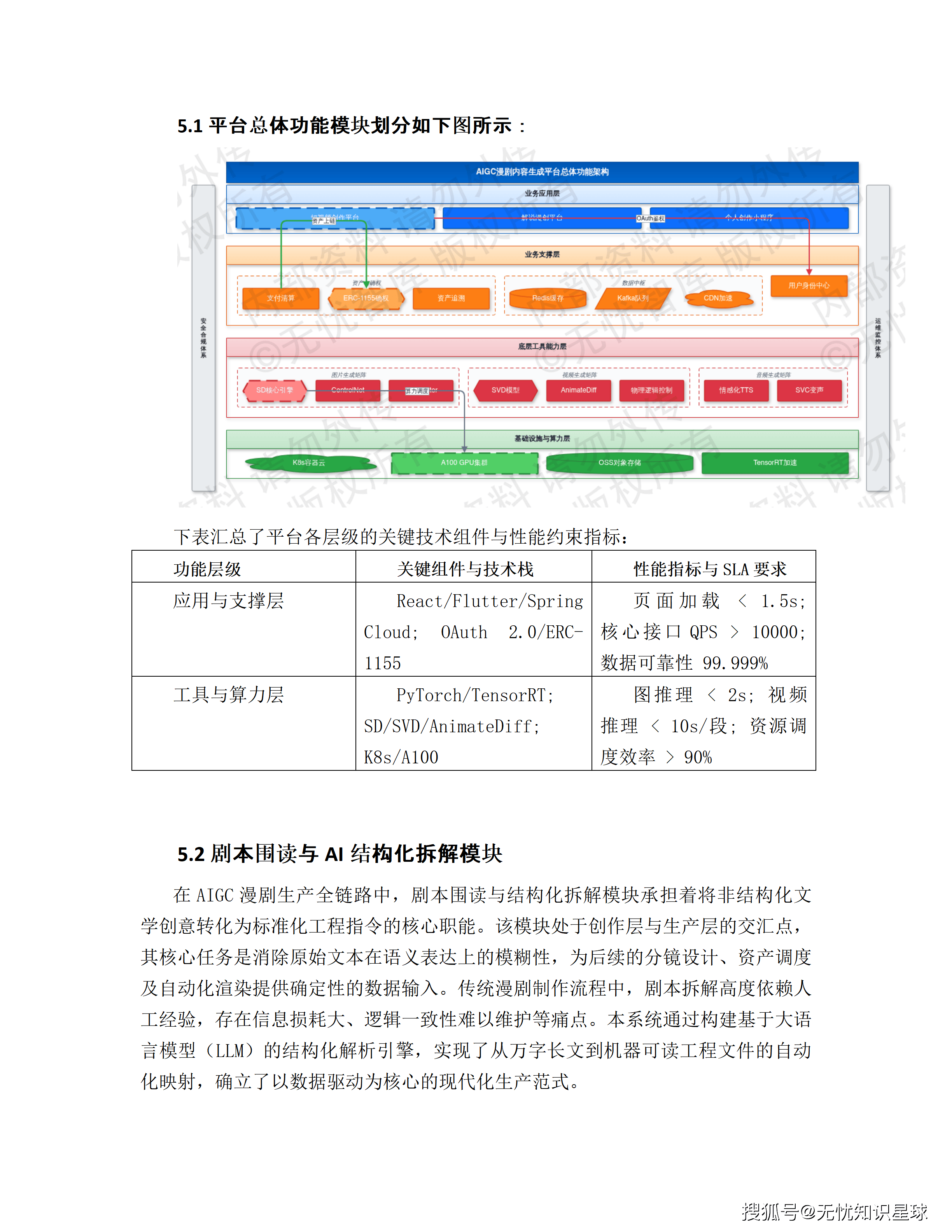
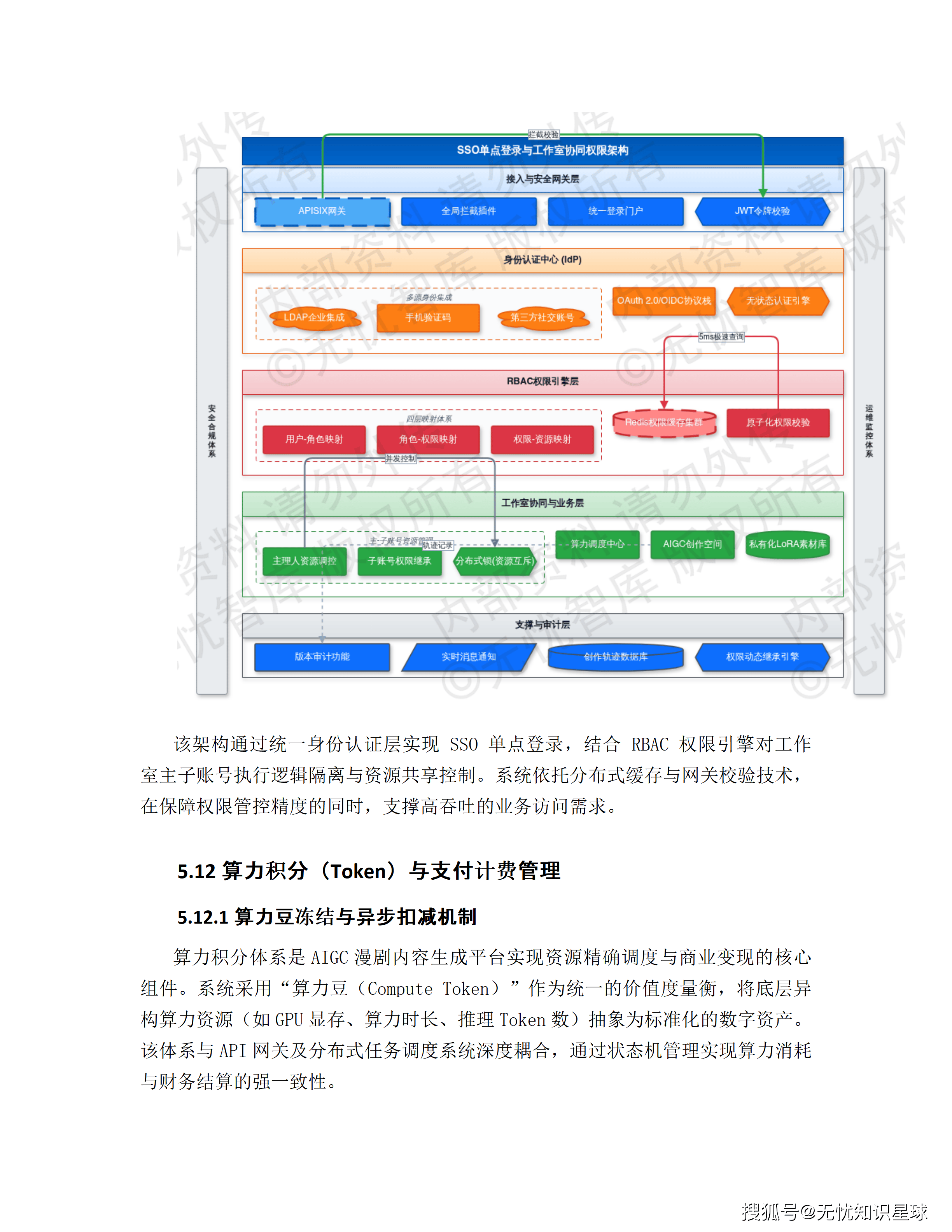
四、五层云原生技术架构:每一层解决什么问题
系统的总体技术架构分为五层,自下而上分别承担不同职责。
第一层:大模型与算力底座层
异构GPU集群 + 基础模型阵列。模型库包含通用LLM、领域微调模型以及Milvus向量数据库,提供推理和RAG(检索增强生成)能力。底层使用RDMA高速网络消除节点间通信瓶颈,依托分布式存储承载模型权重。该层根据任务优先级动态调整算力配额,保障核心推理任务的SLA。
第二层:AI模型网关层
基于APISIX定制开发,承担AI特有的流量治理职能。除标准路由鉴权之外,这一层做三件额外的事:
基于Token消耗量的动态限流:AI接口的计费单位是Token,不是请求次数,流量治理逻辑需要针对Token进行。
Prompt注入防护:用户输入的内容有可能构造恶意Prompt绕过安全限制,需要在网关层拦截。
流式传输支持:对于长文本输出,网关支持SSE(Server-Sent Events)流式传输,降低首字响应延迟——用户能更快看到内容开始输出,而不是等待全部生成完才看到结果。
第三层:业务微服务层
Spring Cloud Alibaba微服务架构,承载用户中心、支付中心、资产管理中心等核心业务逻辑。各服务通过Nacos注册发现,Sentinel实施流量熔断。采用无状态化设计,配合K8s HPA实现秒级水平扩容。核心数据存储于Redis集群,确保API平均响应延迟低于50ms。
第四层:Agent工作流层
这是系统的逻辑中枢,基于LangChain框架构建。负责将复杂业务需求拆解为任务序列——用户输入的一句话创意大纲,在这一层被解析为:意图识别→实体提取→任务编排→工具调用→结果汇总的完整执行链路。
多Agent协同通过消息总线同步状态,确保跨职能任务接力过程中逻辑连贯。这是实现漫剧全链路自动化生产的关键层。
第五层:业务呈现层
微信小程序、Web门户、移动端APP。这一层的核心原则是"重交互、轻逻辑"——复杂计算全部下沉到后端,前端只负责展示和交互。部署CDN和预加载机制,将静态资源推送到距用户最近的边缘节点。
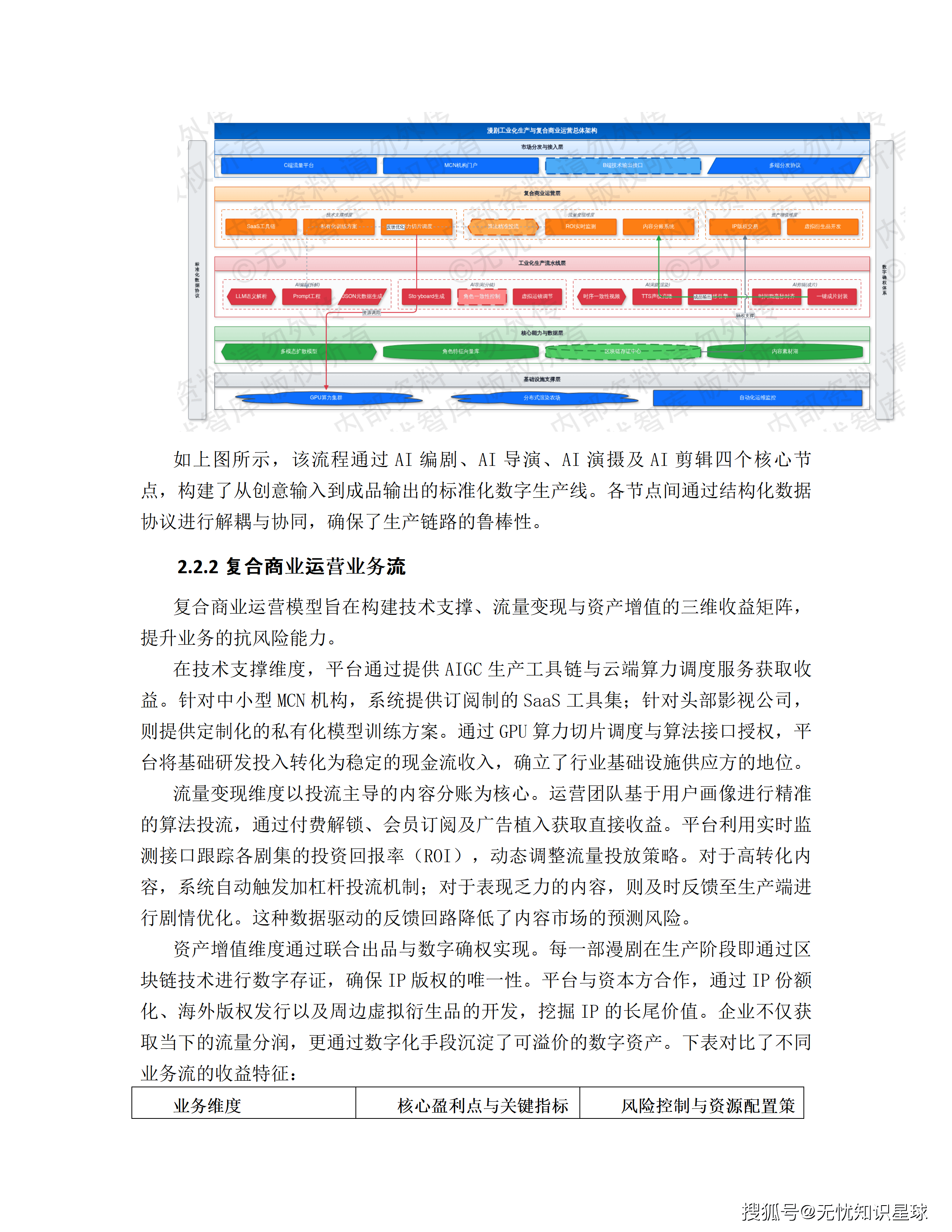
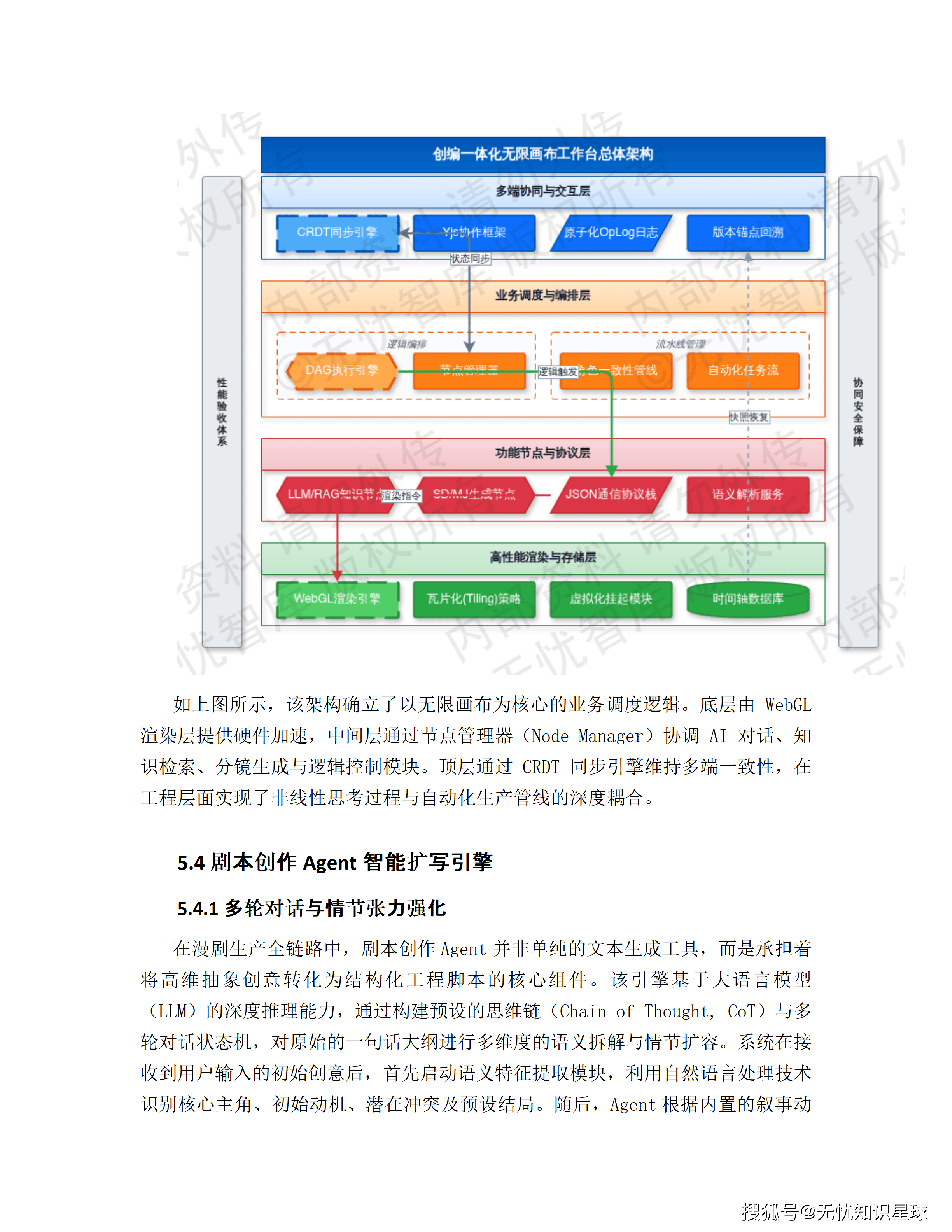
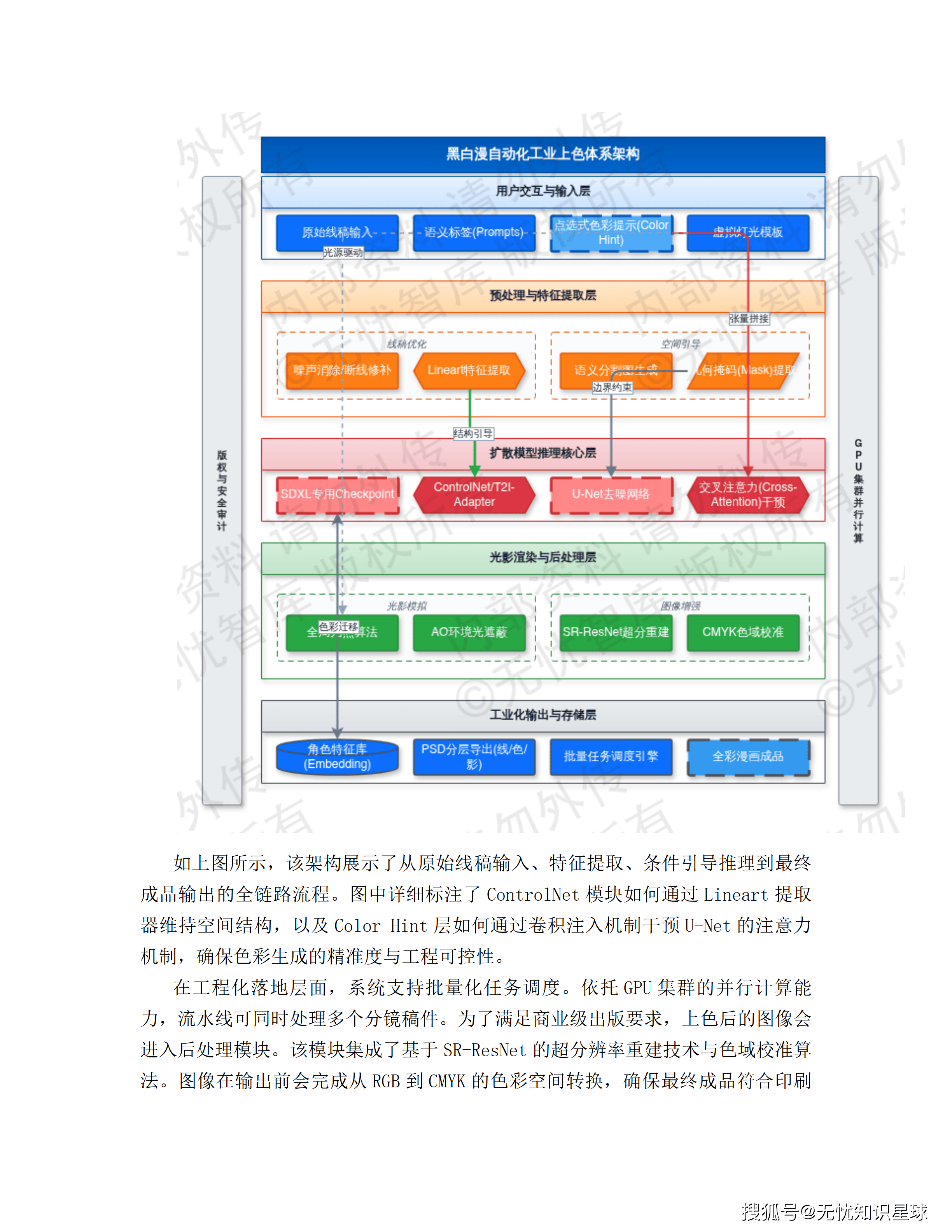
五、从剧本到成片:全链路生成流水线拆解
这是整个方案技术含量最密集的部分。漫剧生产被解构为四个标准工序,每个工序有专门的Agent负责。
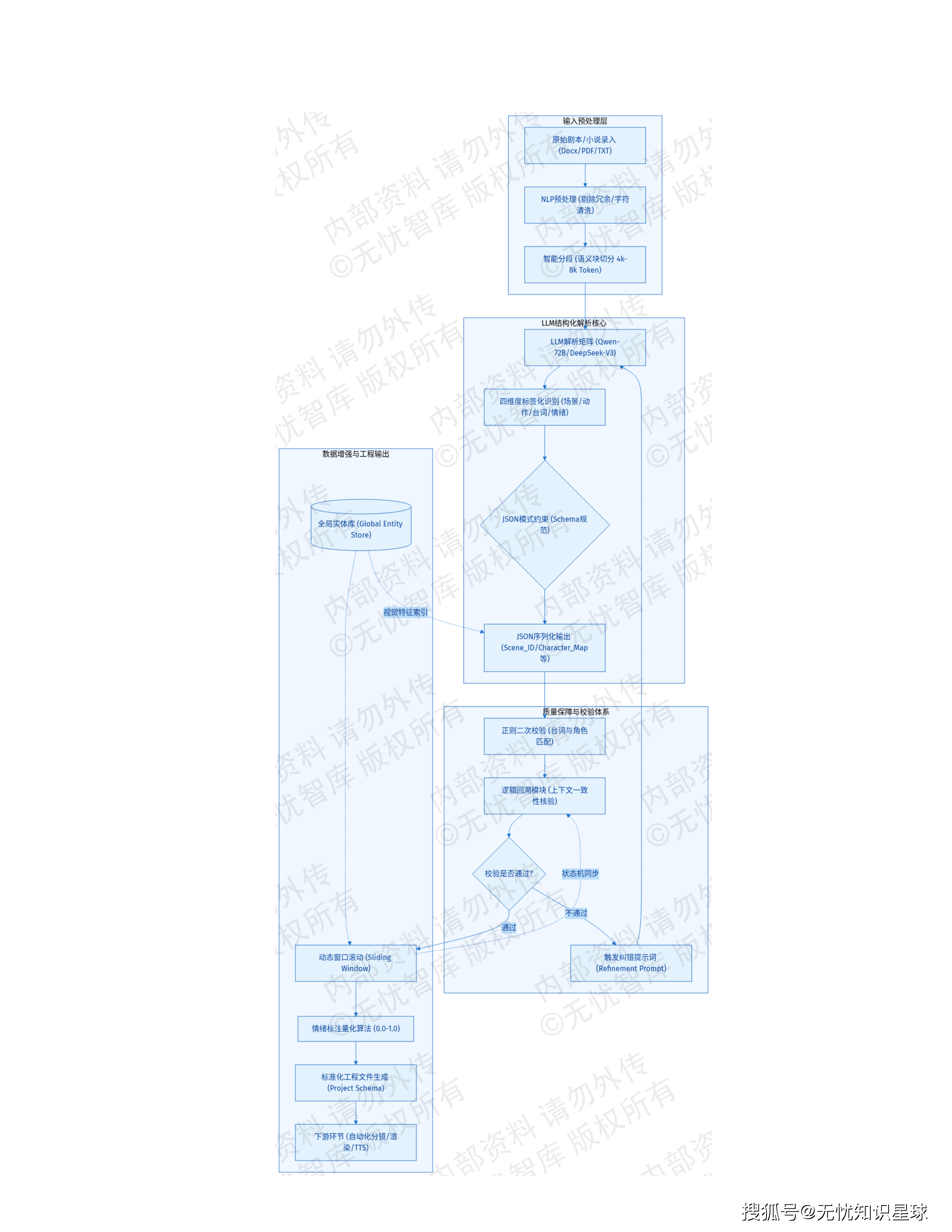
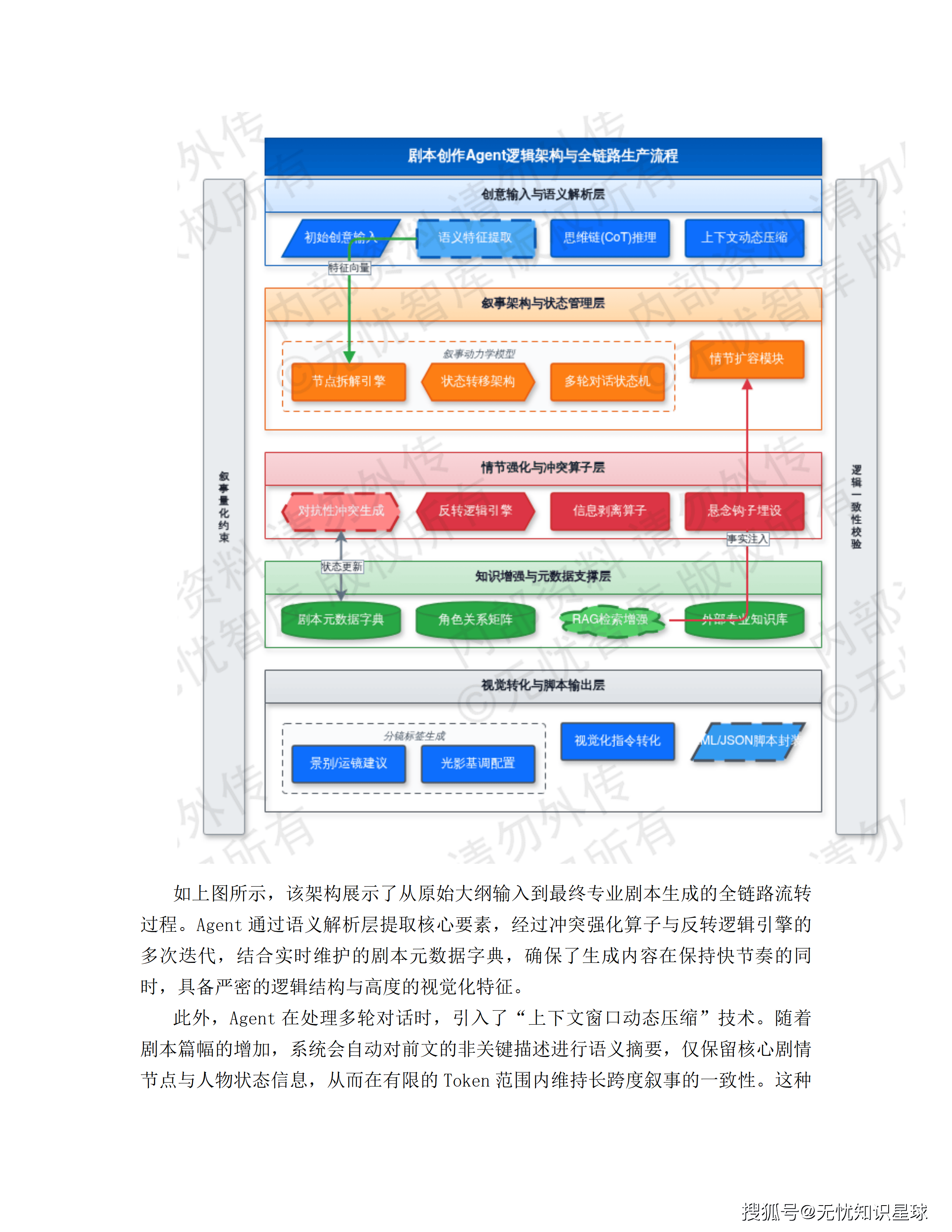
工序一:剧本创作Agent——从大纲到结构化脚本
剧本创作Agent的核心任务,是把一句话创意大纲扩写成可以驱动后续生产的结构化工程文件。
这里有两个技术重点值得关注:
冲突密度控制:Agent在扩写过程中,会对叙事节奏进行量化约束——每300字脚本必须包含1处核心矛盾,50字大纲需要扩写至1500-2000字标准脚本。这不是写作风格的问题,而是漫剧"短平快"叙事特征的工程化约束:高密度冲突是维持用户留存的基本条件。
"冰山模型"信息剥离策略:Agent会主动隐藏部分关键背景信息,设计在特定情节转折处才揭示的"信息炸弹",保持读者的悬念感。这是编剧技法的算法化实现。
在技术实现层面,剧本创作Agent维护着一个动态的"剧本世界观字典",记录角色关系矩阵、关键物品状态、地理位置、当前剧情张力分值。扩写过程中实时调用这个字典进行逻辑校验,防止角色性格前后矛盾、关键道具凭空消失这类叙事硬伤。
此外,扩写完成的剧本会同步生成分镜描述标签:景别建议(特写/全景)、运镜方式(推/拉/摇/移)、光影基调(冷色调/高对比度)——这些参数被封装为JSON格式文件,直接作为下一工序AI生图引擎的数据输入。
工序二:美术创意Agent——剧本语义到视觉Prompt的自动翻译
这个工序解决的是一个长期被手工完成的专业任务:把文学语言翻译成生成式AI能够理解并正确执行的视觉指令。
自然语言剧本里充满了抽象的情绪描写和非视觉化隐喻,而Flux、SDXL这类模型需要的是高度结构化、具象化的提示词。这个翻译工作,在传统流程里是由有经验的AI绘画师手工完成的,耗时且很难标准化。
美术创意Agent的处理分三个阶段:
第一阶段:语义解构与实体提取。把"李雷在昏暗的雨夜街道漫步,神情落寞"解析为:环境实体(Street)、气象算子(Rainy night)、照明参数(Dim lighting)、角色状态(Li Lei, Lonely expression)的组合,同时调用全局实体库校验该角色的视觉特征锚点(发型、服饰、配饰),确保与此前分镜的一致性。
第二阶段:视觉语言扩写。把模糊的"光线"描述替换为专业术语——“Cinematic lighting”、“Volumetric fog”、“Rim light”。情绪强烈的冲突段落自动配置"Extreme close-up"和"Shallow depth of field";宏大叙事场景注入"Wide-angle panoramic view"。
第三阶段:底层模型语法适配。Flux模型需要长句式自然语言Prompt;SDXL需要逗号分隔的标签化结构并搭配负向提示词(强制排除"low quality"、"deformed limbs"等干扰项)。同一段内容,针对不同模型自动生成格式不同的指令。
最后有一个视觉反馈闭环:Agent输出最终提示词前,调用轻量化预览引擎生成低分辨率草图,用视觉大模型(VLM)进行语义对齐度和美学评分。评分低于0.75则触发自重写逻辑,直到达标为止。
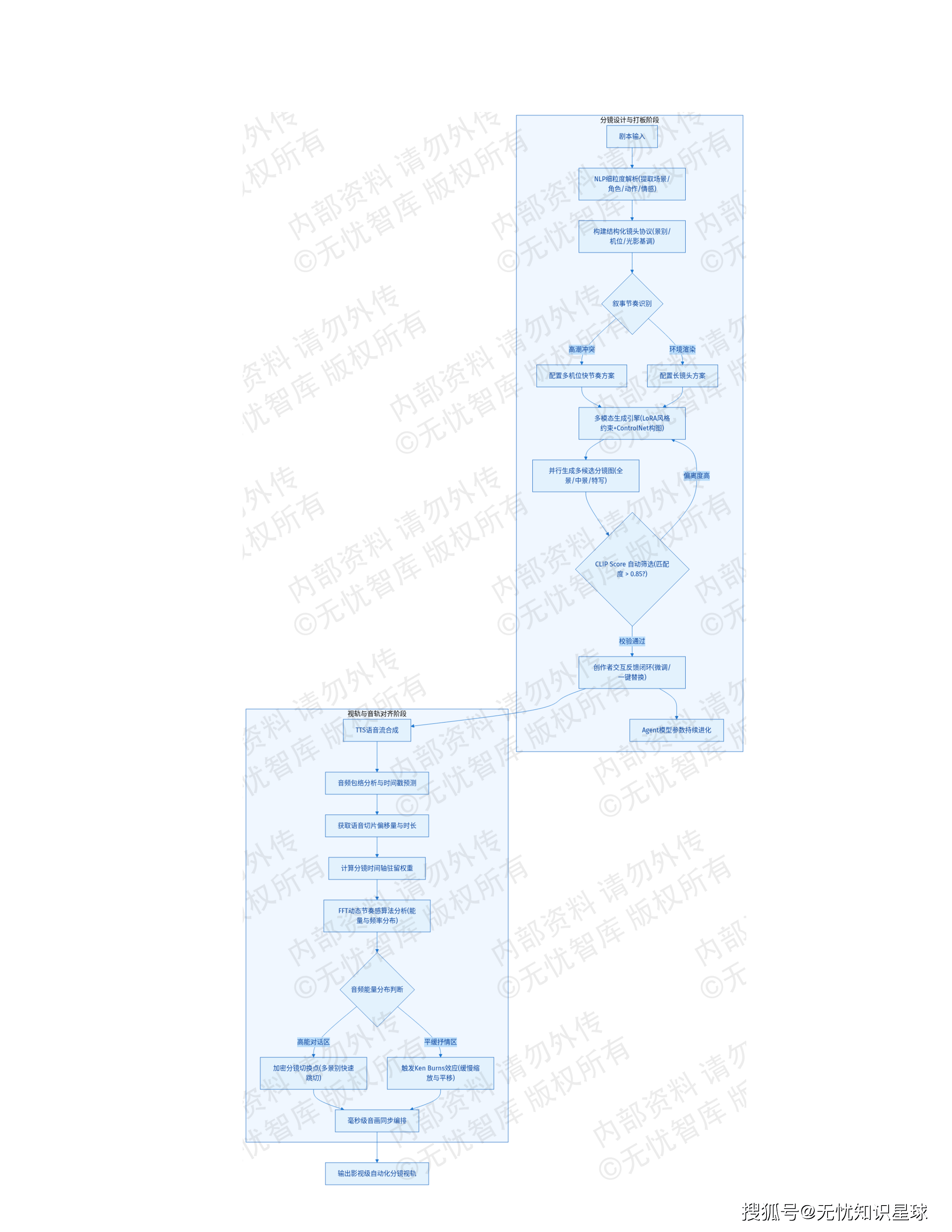
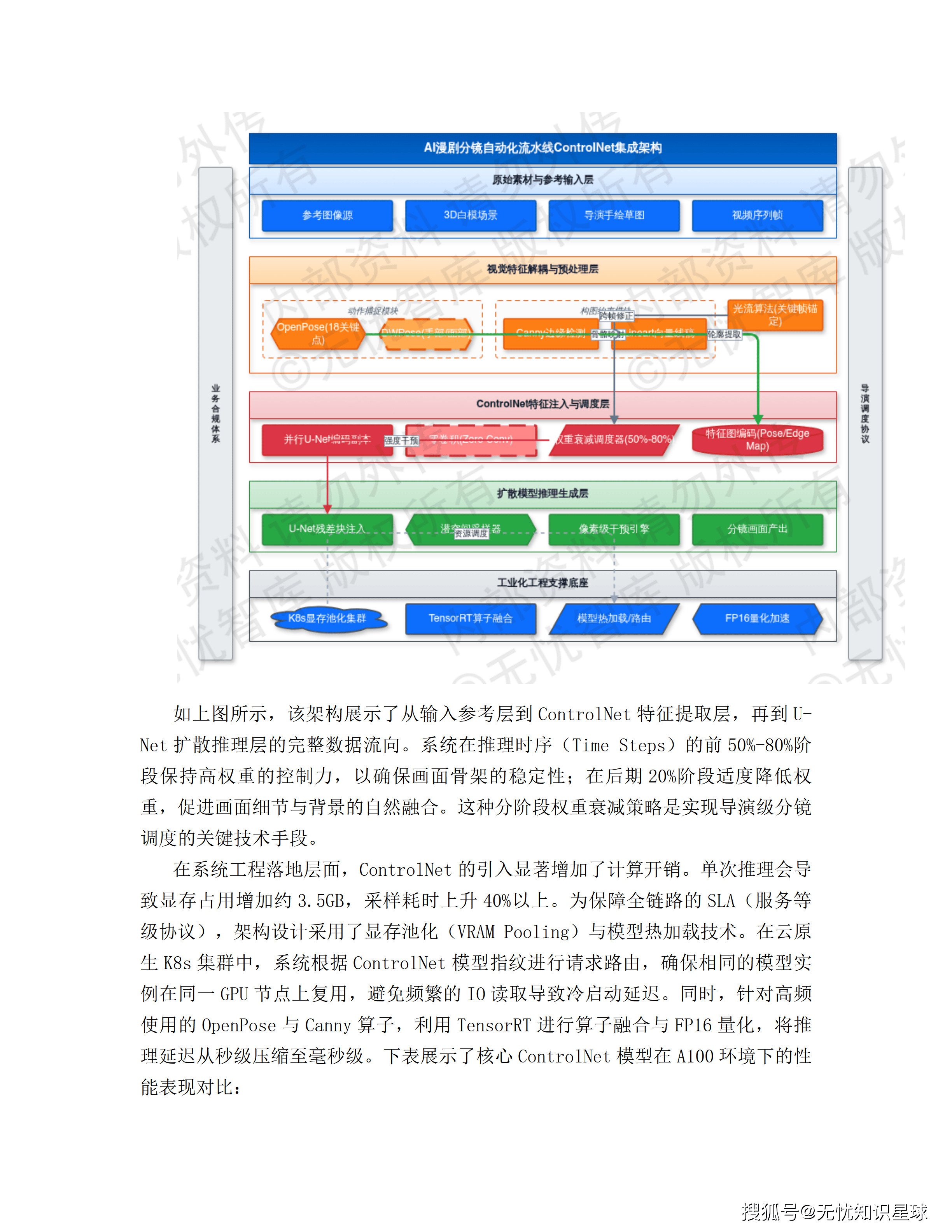
工序三:分镜设计Agent——风格一致性控制是核心难题
分镜生成的最大挑战前文已经提到:AI生成的随机性导致相邻帧、相邻集之间角色形象和场景风格无法保持一致。
方案用两个技术手段组合解决这个问题:
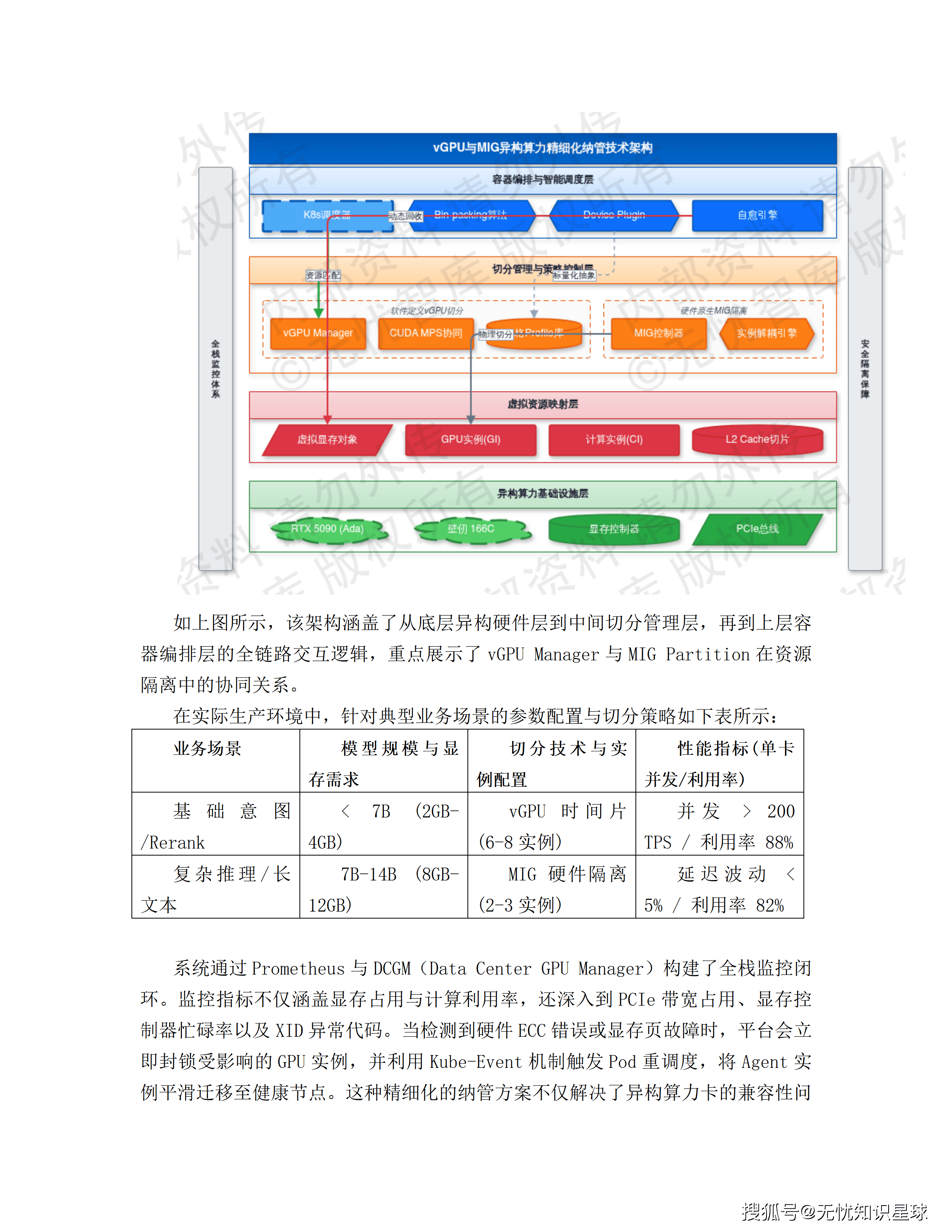
LoRA角色微调:针对每一个核心角色,训练专用的LoRA(低秩适应)微调权重,把角色的外貌特征固化在模型参数层面。无论这个角色出现在哪个场景、哪个景别,只要加载这个LoRA权重,外貌特征就是稳定的。
ControlNet构图控制:通过骨架图(OpenPose)或深度图作为生成引导,约束角色在画面中的姿态和位置关系。这解决的是另一个维度的漂移问题——同一个动作描述,不加约束的话每次生成的肢体姿态可能完全不同。
分镜生成采用"多候选打板"机制:并行生成全景、中景、特写等不同景别的候选图像,通过计算CLIP Score(生成图像与剧本描述的语义匹配度)自动剔除偏离度高的候选,要求匹配度大于0.85。创作者在前端界面对推荐候选做一键替换,系统记录选择偏好并反馈至Agent微调参数——每一次人工干预都是模型进化的训练数据。
在生产效率指标上:候选图生成时间小于8秒/镜,并发处理能力大于500 TPS。
工序四:视频合成与一键成片——音画字幕毫秒级对齐
静态分镜到动态视频的转化,涉及三件事:动态化、配音、剪辑对齐。
动态化:使用时序一致性算法(AnimateDiff或类Sora架构),将静态分镜转化为高帧率动态视频。同时实施实时风格迁移,确保运动过程中风格不漂移。
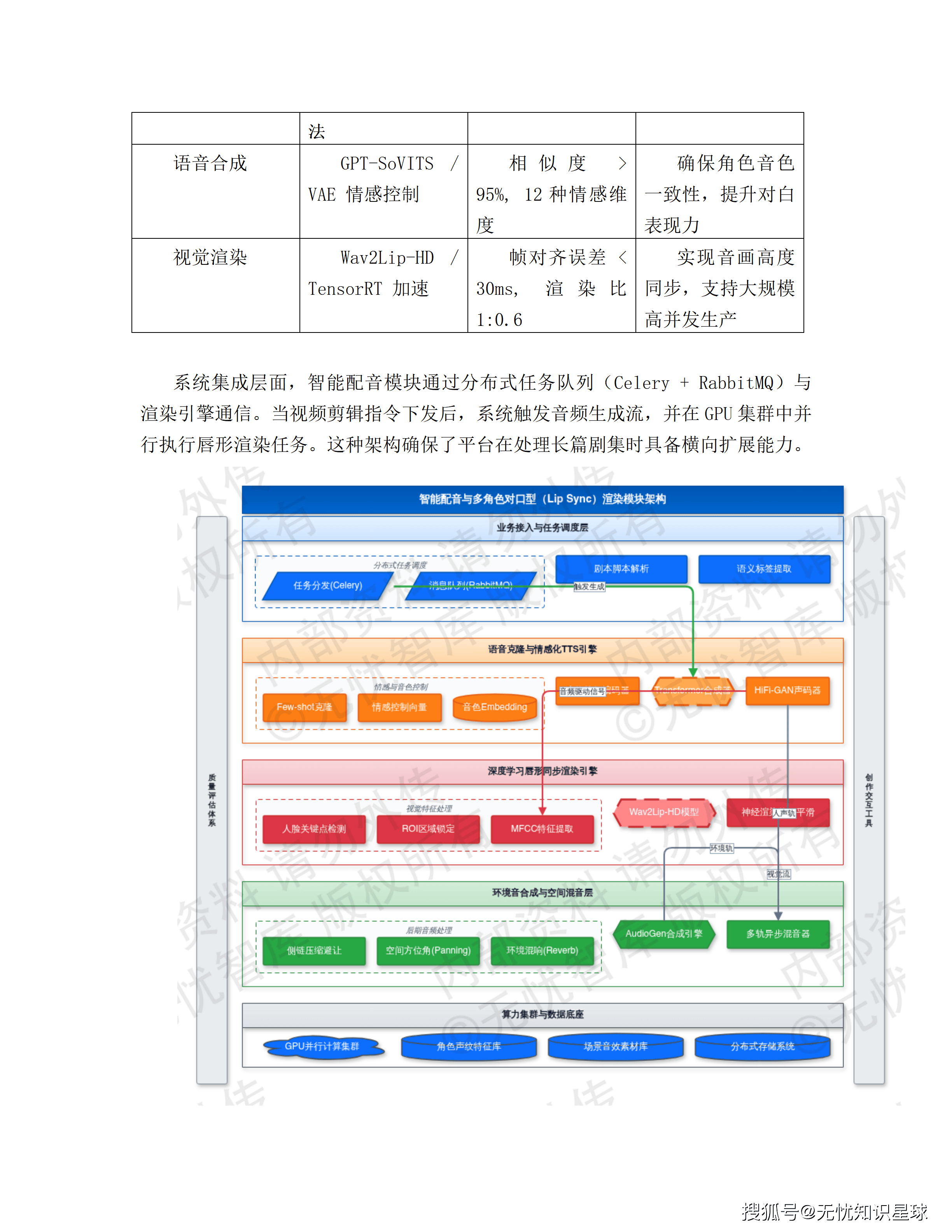
配音:集成TTS语音合成与声纹克隆技术,根据剧本中的情绪标签自动匹配角色配音与环境音效。不是简单的文字转语音,而是带情绪调制的配音。
剪辑对齐:这里有一个值得单独说的技术细节。系统通过快速傅里叶变换(FFT)分析音频的情感能量和频率分布,在音频能量高的对话密集区自动加密分镜切换点(模拟影视剧张力感),在音频平缓的抒情段落自动触发Ken Burns效应——对静态分镜做缓慢缩放和平移,产生"呼吸感"。音画同步精度控制在毫秒级,音画对齐误差±15ms。
最终输出:符合多端分发协议的成品文件,自动适配不同平台的分辨率和格式要求。
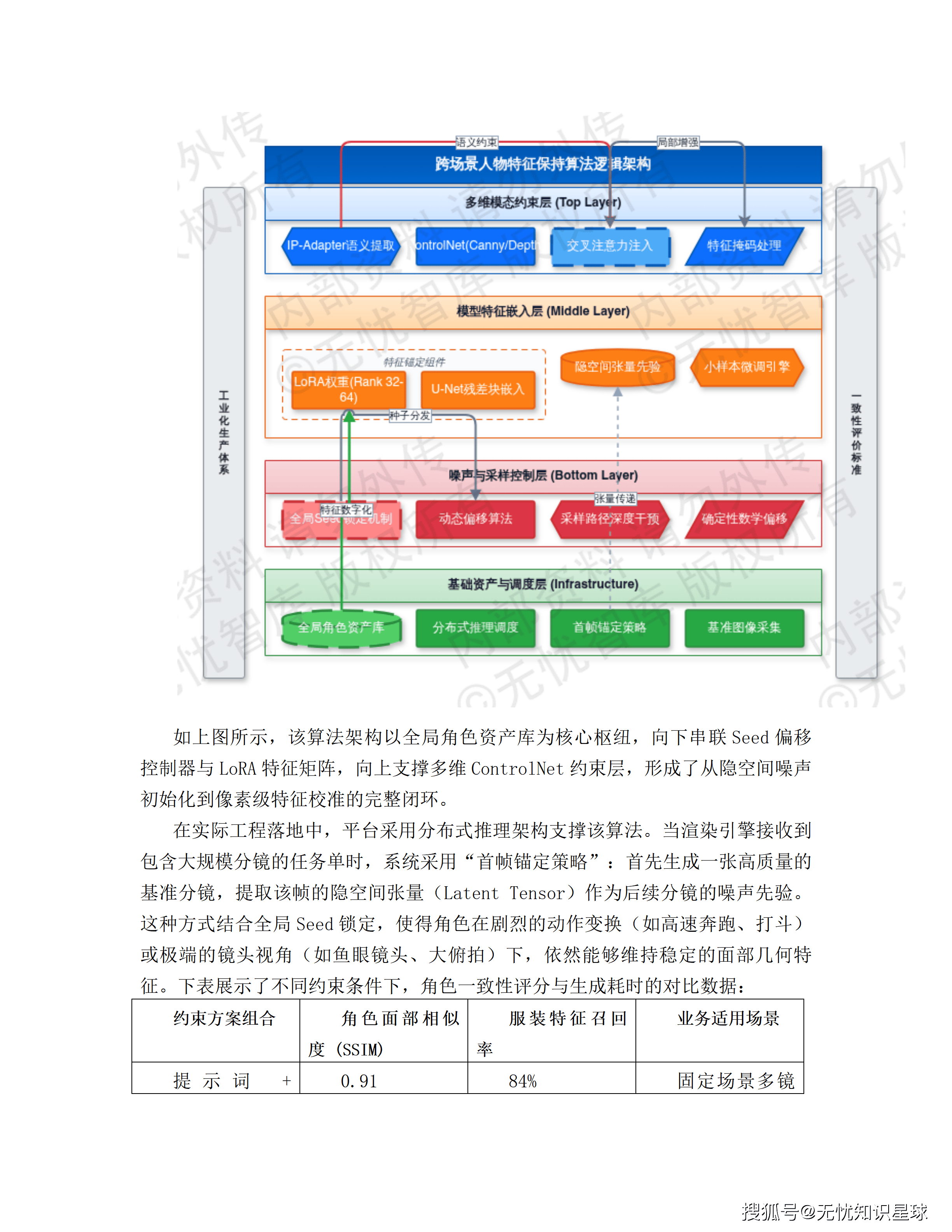
六、风格一致性控制:最难的工程问题怎么解
把风格一致性控制单独拿出来讲,是因为这是AI漫剧工业化落地的核心障碍,也是这份方案投入技术精力最多的地方。
LoRA微调:角色的"专属DNA"
LoRA(Low-Rank Adaptation)是一种参数高效的模型微调技术,可以在不修改基础模型权重的情况下,通过训练极少量的额外参数来改变模型的输出倾向。
在这个系统里,每个核心角色都对应一个专属LoRA文件。这个文件里记录的是"当这个角色出现时,视觉特征应该是什么"——脸型、眼距、发色、标志性服饰细节。无论剧情发展到哪里,只要调用这个角色的LoRA,生成的外貌就是一致的。
这就像给每个角色配了一本视觉DNA档案,每次生成图像都要对照这本档案来生成。
IP-Adapter:跨场景特征保持
IP-Adapter是另一个维度的一致性控制工具。它通过提取参考图像的视觉特征(Embedding),将这些特征注入到生成过程的注意力层,使生成结果在视觉风格上与参考图保持一致。
在多集漫剧的制作中,IP-Adapter的应用场景是:用第一集已经被确认的角色参考图,作为后续所有集数生成时的视觉锚点,确保跨集视觉连贯。
置信度阈值过滤:把不达标的图在流水线里就过滤掉
系统设有CLIP Score阈值(>0.85),所有生成的候选分镜必须达到这个语义匹配度才能进入下一环节。低于阈值的自动触发重生成,而不是把不达标的内容推给人工去筛选。
这个设计把质量控制前置到生产环节,而不是等到成片后再返工。
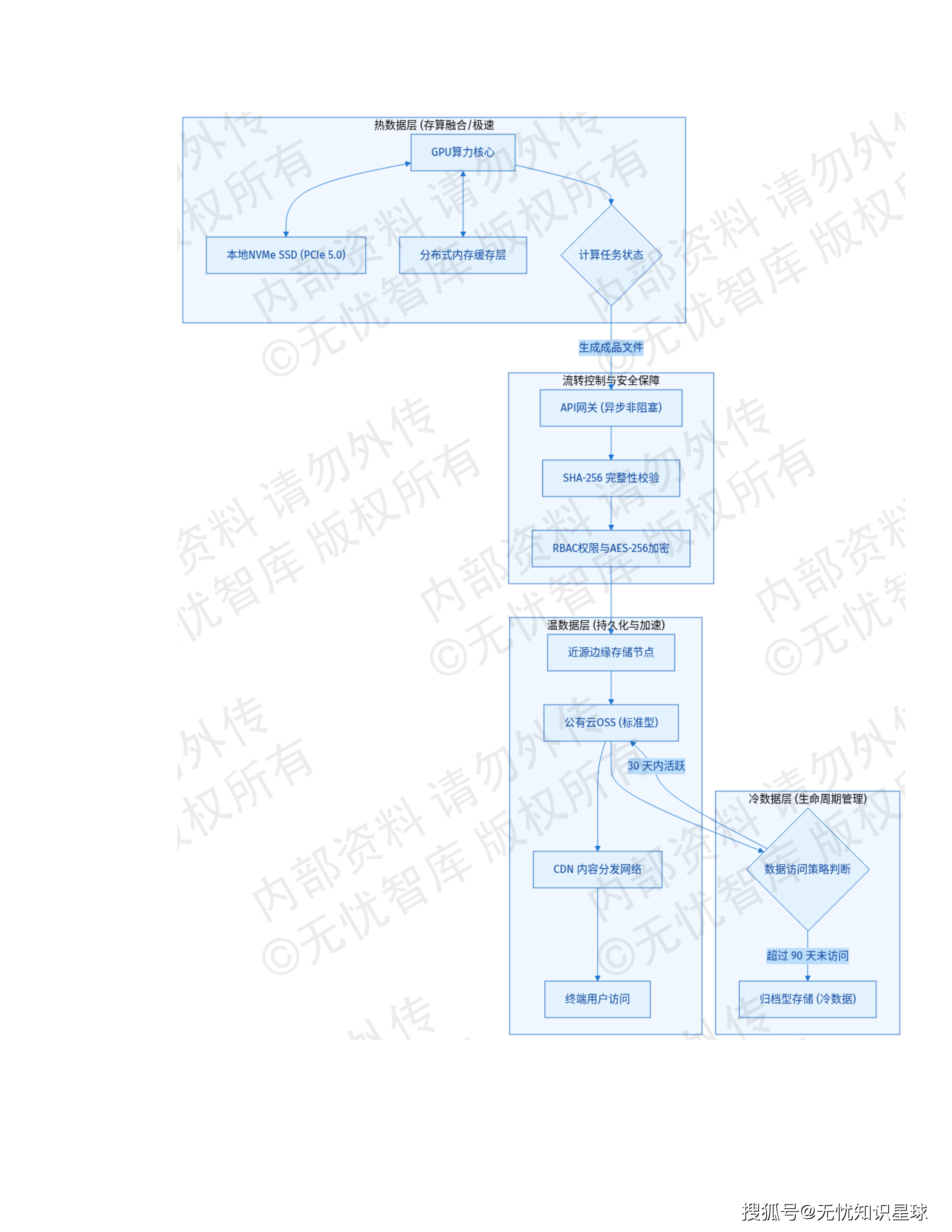
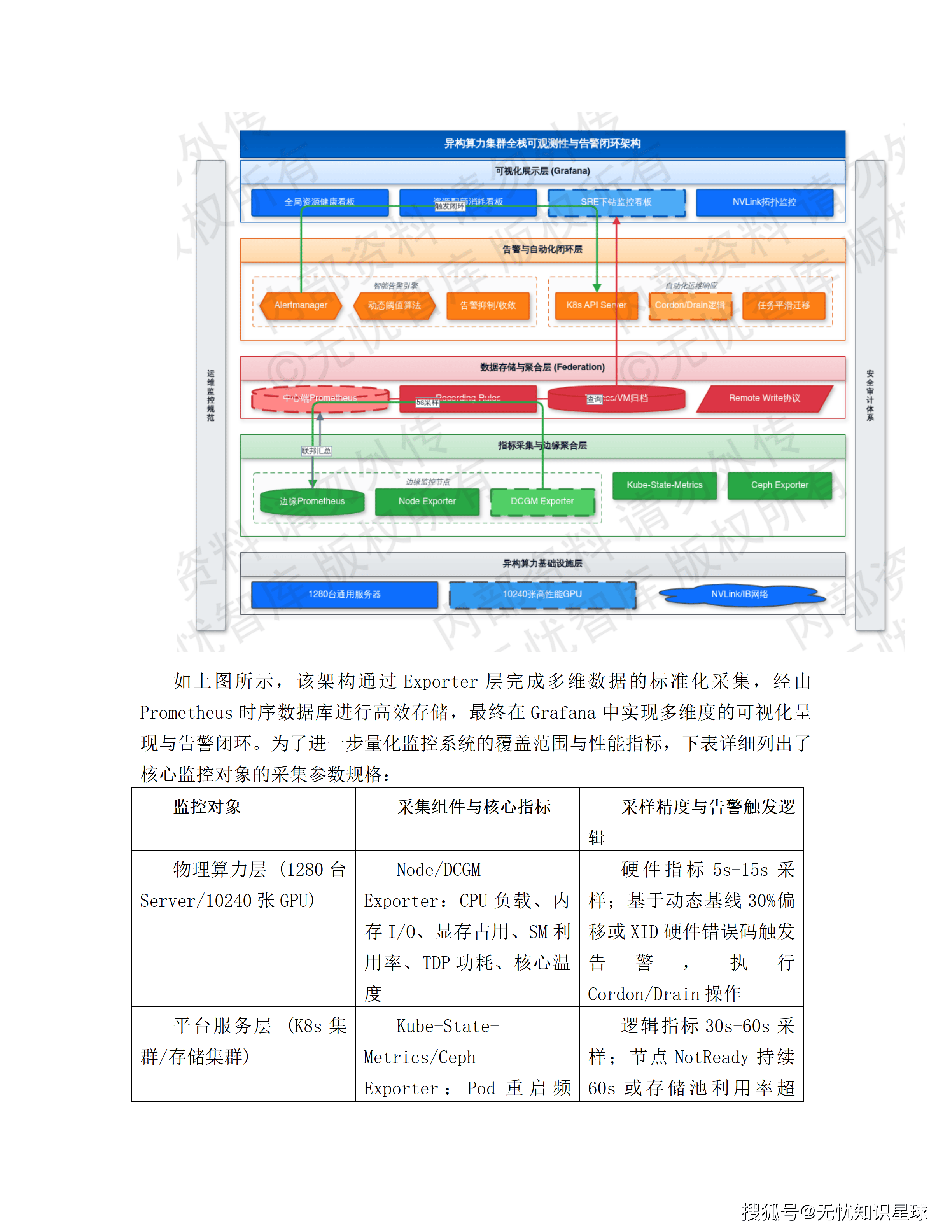
七、数据架构:热温冷三级存储,算力和数据不互相等待
AIGC系统的数据架构和普通业务系统有一个本质差异:大模型推理任务对I/O吞吐的要求极高,如果数据不在"正确的地方",算力就会因为等待数据而空转。
方案采用"存算融合、冷热分离"的三层架构:
热数据层(本地NVMe SSD):大模型权重文件、生图过程中的中间张量缓存、高频访问的视频切片——全部强制放在GPU算力节点的本地NVMe SSD上。单节点聚合读取带宽可突破50GB/s,与传统集中式存储(单节点0.8-4.5GB/s)相比差了一个数量级。这使得175B参数量的模型权重从磁盘加载到显存的时间从分钟级降至秒级。
温数据层(OSS + CDN):处理完成的持久化成品,写入云端对象存储,通过CDN全球分发。访问延迟<100ms,支持全球用户访问。
冷数据层(归档存储):超过90天未访问的数据自动转入归档型存储,降低运营成本。
还有一个关键设计:本地SSD只作为临时工作区(Scratch Space),不作为数据永久存储。计算任务完成后,核心产出立即异步回写到具备多副本冗余的分布式存储。节点发生硬件故障时,容器调度器自动把任务迁移到其他健康节点,重新从远端拉取原始数据——这是"计算节点无状态、本地存储高性能"的设计哲学,在保证极致性能的同时兼顾了容灾能力。
八、复合商业运营模型:三个维度同时变现
系统的商业变现逻辑被设计为三条同时运行的收益线,而不是依赖单一变现途径。
技术支撑维度(稳现金流):向中小MCN机构提供订阅制SaaS工具集,向头部影视公司提供私有化模型训练方案。GPU算力切片调度和算法接口授权,把基础研发投入转化为持续的技术服务收入。
流量变现维度(冲规模):核心是"数据驱动的内容投流"。系统实时监测各剧集的ROI(投资回报率),对高转化内容自动触发加杠杆投流,对表现乏力的内容及时反馈至生产端调整。这个反馈回路把内容生产端和流量投放端打通了——生产哪类内容、投多少钱,都由数据说了算,而不是靠感觉。
资产增值维度(做长线):每部漫剧在生产阶段即通过区块链技术进行数字存证,确保IP版权唯一性。通过IP份额化、海外版权发行、虚拟衍生品开发挖掘IP长尾价值。
这三条收益线有明确的风险对冲逻辑:技术服务收入最稳定但天花板有限,流量变现规模最大但波动性高,资产增值最慢变现但溢价空间最大。三条同时跑,可以在不同市场环境下维持商业可持续性。
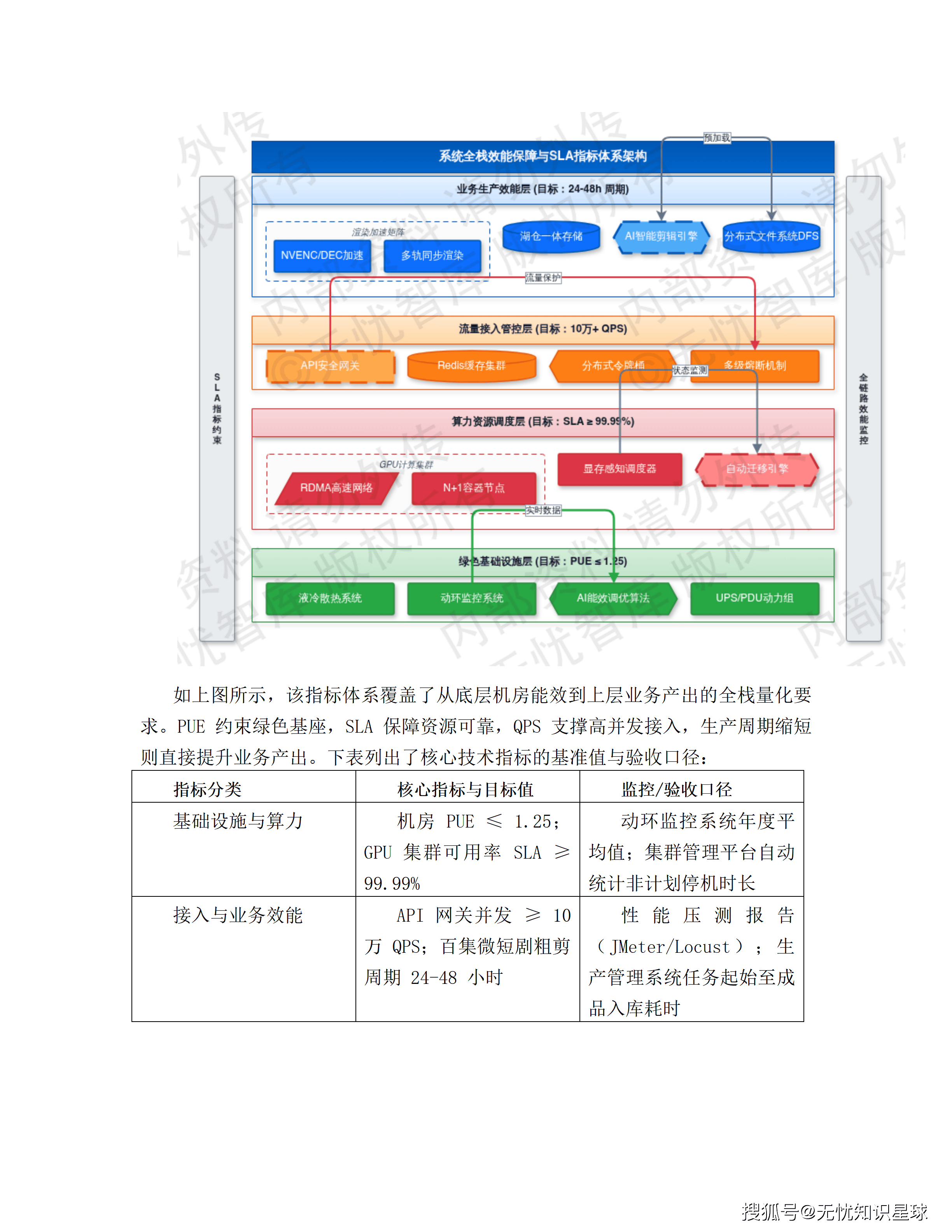
九、关键性能指标:量化一下这套系统要跑到什么水平
方案对系统效能设定了具体的量化指标,这些数字是理解整套架构设计逻辑的参照坐标:
| 指标维度 | 核心指标 | 目标值 |
|---|---|---|
| 基础设施 | 机房能效(PUE) | ≤ 1.25 |
| 算力可用性 | GPU集群在线可用率 | SLA ≥ 99.99% |
| 接口性能 | API网关并发处理能力 | ≥ 10万 QPS |
| 内容生产 | 百集微短剧粗剪成片周期 | 24-48小时 |
| 分镜生成 | 候选图生成速度 | < 8秒/镜 |
| 音画对齐 | 音画同步误差 | ±15ms |
| 分镜质量 | CLIP语义匹配度 | > 0.85 |
| 年产能 | 精品AIGC漫剧产量 | 1000部/年 |
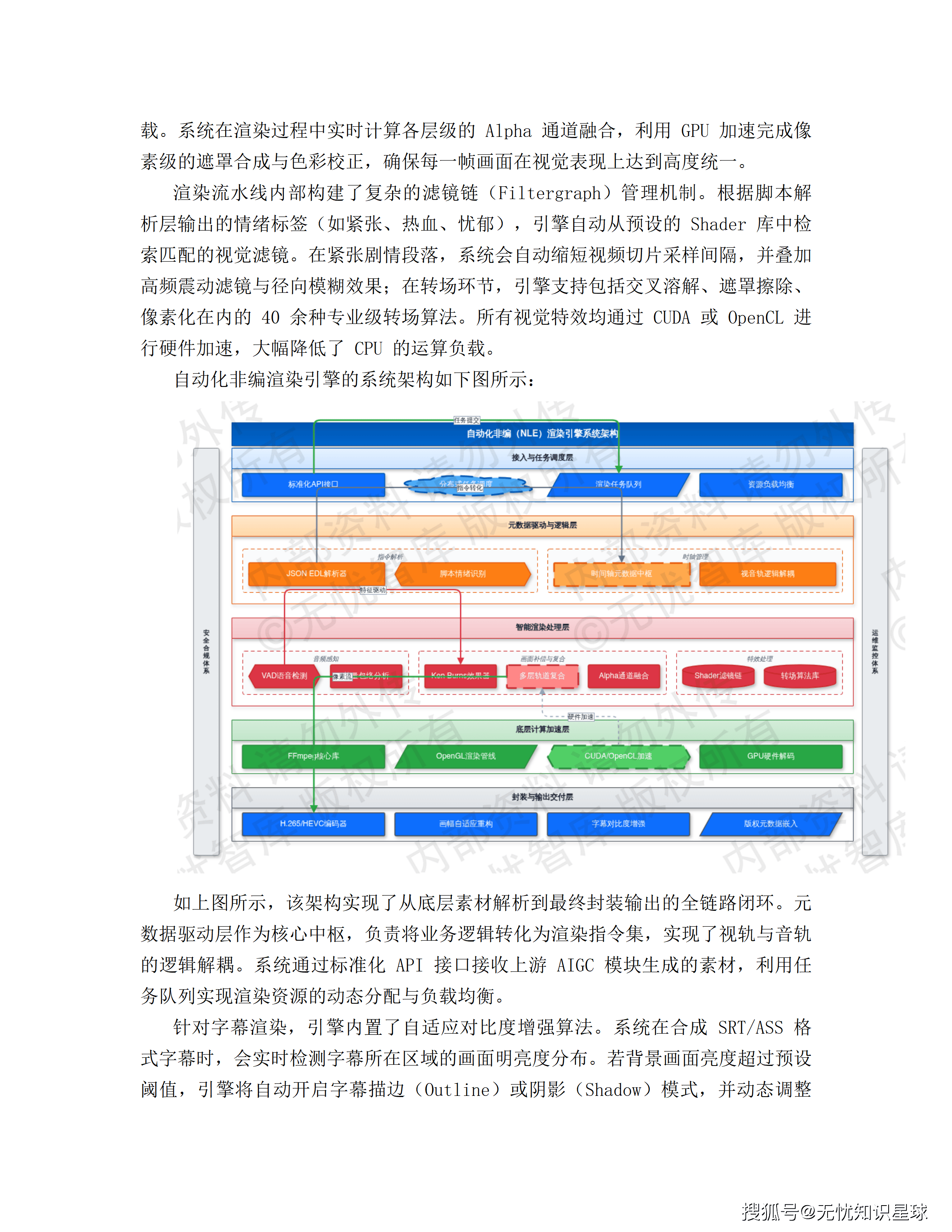
这些指标的实现路径,方案里基本都有工程层面的具体设计对应。PUE的1.25靠液冷+冷热通道隔离;99.99%可用率靠N+1容器冗余和30秒内任务迁移;百集48小时靠分布式渲染和AI剪辑引擎的深度耦合。
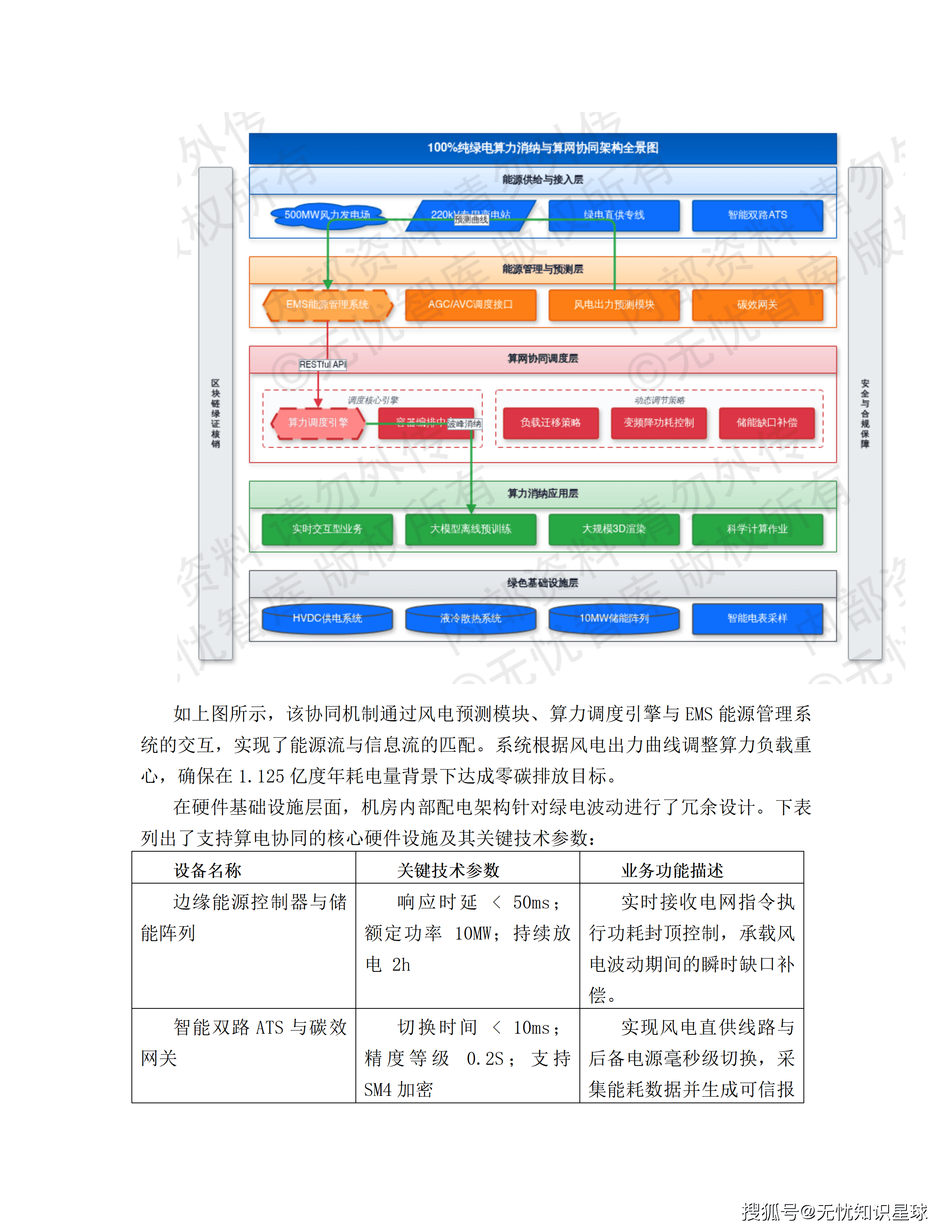
十、绿色算力:把风电波动变成算力调度的优化空间
这是方案里一个有意思的设计——把绿电消纳问题和算力调度问题合并解决。
方案依托周边500MW风力发电场,通过"绿电直供+算网协同"架构,实现年消纳绿电1.125亿度(112.5 GWh)。
风电有一个天然问题:出力随气象条件波动,而算力业务需要高可用性。这两个需求是矛盾的——怎么既用绿电又保证业务不断?
解决思路是:把算力负载分类。
- 实时交互型任务(用户触发的推理、生成):必须随时可用,不可调度
- 时延容忍型任务(模型离线预训练、大规模3D渲染、科学计算):可以等
当EMS监测到风电出力处于波峰区间(>350MW)时,调度引擎自动激活大量时延容忍型计算任务,把机房功耗拉到峰值消纳绿电。当风电进入波谷(<100MW)时,将非核心业务热迁移至储能支撑节点,降低非关键节点主频。
这样既实现了绿电就地消纳,又保障了核心业务SLA 99.99%不受影响。"以电定算"的逻辑把电网侧的约束转化成了调度优化的自由度。
每度进入机房的电力通过智能电表高频采样(10kHz),生成带地理位置和时间戳的电力指纹,上传区块链实现绿证的自动核销和ESG审计。
总结:几个值得一起思考的问题
把这份方案拆解下来,有几个判断值得认真对待。
第一,漫剧工业化的核心难题不是"能不能生成",而是"生成的东西能不能用"
风格一致性、角色不漂移、音画精准对齐——这些问题技术上都有解法,但每一个都需要系统性的工程投入,而不是"接一个API就能解决"。方案里LoRA微调、ControlNet、IP-Adapter、CLIP Score阈值过滤这一系列组合拳,实际上是在用工程化手段把AI生成的随机性约束在可控范围内。这个思路值得借鉴:不是追求AI完全自主,而是设计合理的约束机制让AI的输出符合业务要求。
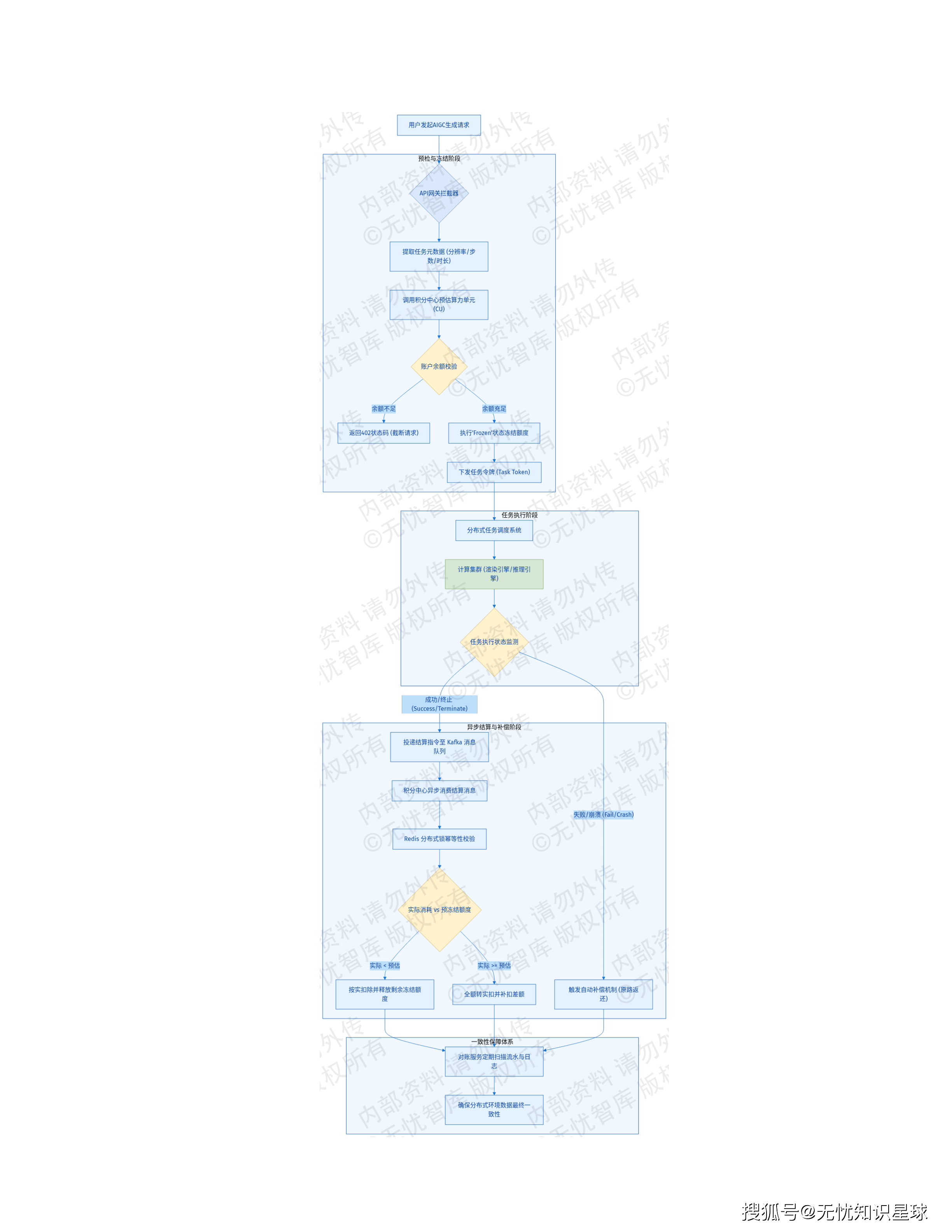
第二,"算力豆"计费模式背后的核心是把生产成本变量化
传统漫剧制作的成本结构是固定成本为主(人力、设备、场地),项目启动前就要大笔投入,回报不确定。AI超级工厂模式把生产成本变成了按消耗算力计费的变量——做多少,花多少,失败了损失的是算力成本而不是几个月的人力。这个成本结构的变化,从根本上改变了内容创业的风险收益比。
第三,从"抽卡式生成"到"确定性制造"的转变,需要整个工业流程重新设计
方案里有一个表述让人印象深刻:“系统最终交付的是一套标准化的视觉生成协议,而非随机的生成结果”。这句话点出了AIGC内容工业化的本质要求:不是用AI生成"看起来不错的内容",而是用工程化手段让AI稳定输出符合交付标准的结果。剧本→Prompt→分镜→视频的每一个环节,都需要有量化的质量门槛和自动化的检测机制,才能在高频量产的前提下保持质量稳定。
第四,商业变现的多轨设计是真实的抗风险需求,不是商业计划书的体面
内容行业的平台流量政策可以在一个季度内彻底改变,什么类型的内容受追捧也是说变就变。单纯依赖投流分账的模式,在平台规则变化时几乎没有缓冲空间。同时运行技术服务、流量变现、IP资产增值三条收益线,不是贪多,而是对内容行业高度不确定性的现实应对。
漫剧行业的工业化进程,现在正处于从"试水期"到"规模化落地"的临界点。上述方案的完整度和工程化深度,某种程度上描述了这个临界点之后会是什么样子。
往前走一步需要的不只是算力和模型,还有对整个内容生产流程的系统性重新设计能力——从剧本逻辑、到视觉语言、到音画对齐、到版权确权,每一个环节都需要有人把它做成可以稳定运行的工程模块,而不是停留在Demo层面。
这大概是当下最值得持续关注的一个方向。
本文基于某AI漫剧超级工厂AI绘画与分镜自动化生成流水线建设方案整理,业务痛点分析、技术架构设计、算力选型及量化指标均来源于方案原文。
附:核心技术模块实现细节备忘
在方案的工程落地过程中,有几个技术细节容易在实施阶段被忽略,但对系统效果影响非常直接。
机房改造:电力升级比采购GPU更容易被低估
很多团队做AI算力建设时,把精力全部放在GPU选型上,却忽略了一个基础问题:现有机房能不能支撑高密度算力的用电需求。
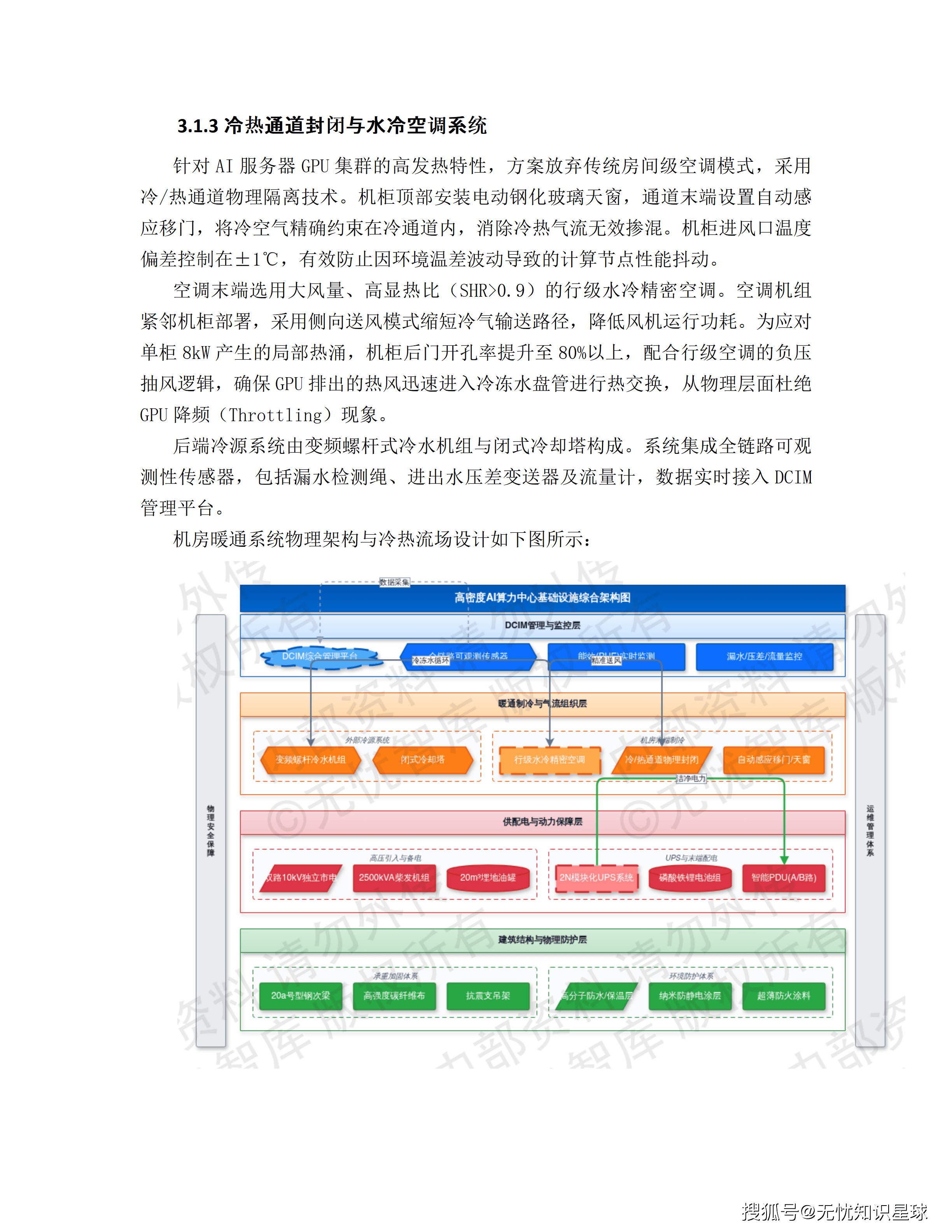
方案里对这个问题的处理非常具体:科研楼原有设计荷载是3.5kN/㎡,而部署高密度AI算力集群及配套UPS、蓄电池后,局部荷载需求超出原设计上限3倍以上。解决方案是"高强度碳纤维布粘贴+新增型钢梁"的复合加固工艺——这是土建层面的改造,不是简单地"拉根电缆"能解决的。
供电方面:总IT负荷按10.28MW设计,支撑1285个单柜功耗8kW的高密机柜。电力引入采用双路10kV独立市电,分别来自不同上级变电站,物理路由冗余。配备4台2500kVA集装箱式高压柴油发电机组,地下20立方米埋地油罐,全负载持续运行12小时——这是电力中断时的底线保障。
散热方面:方案放弃传统房间级空调,采用冷热通道物理隔离+行级水冷精密空调。空调机组紧邻机柜部署,GPU排出的热风直接进入冷冻水盘管热交换,从物理层面防止GPU降频(Throttling)——GPU降频意味着算力性能打折,直接影响生产效率。
机房能效目标PUE≤1.25,结合液冷散热,全年平均PUE可控制在1.15以内。
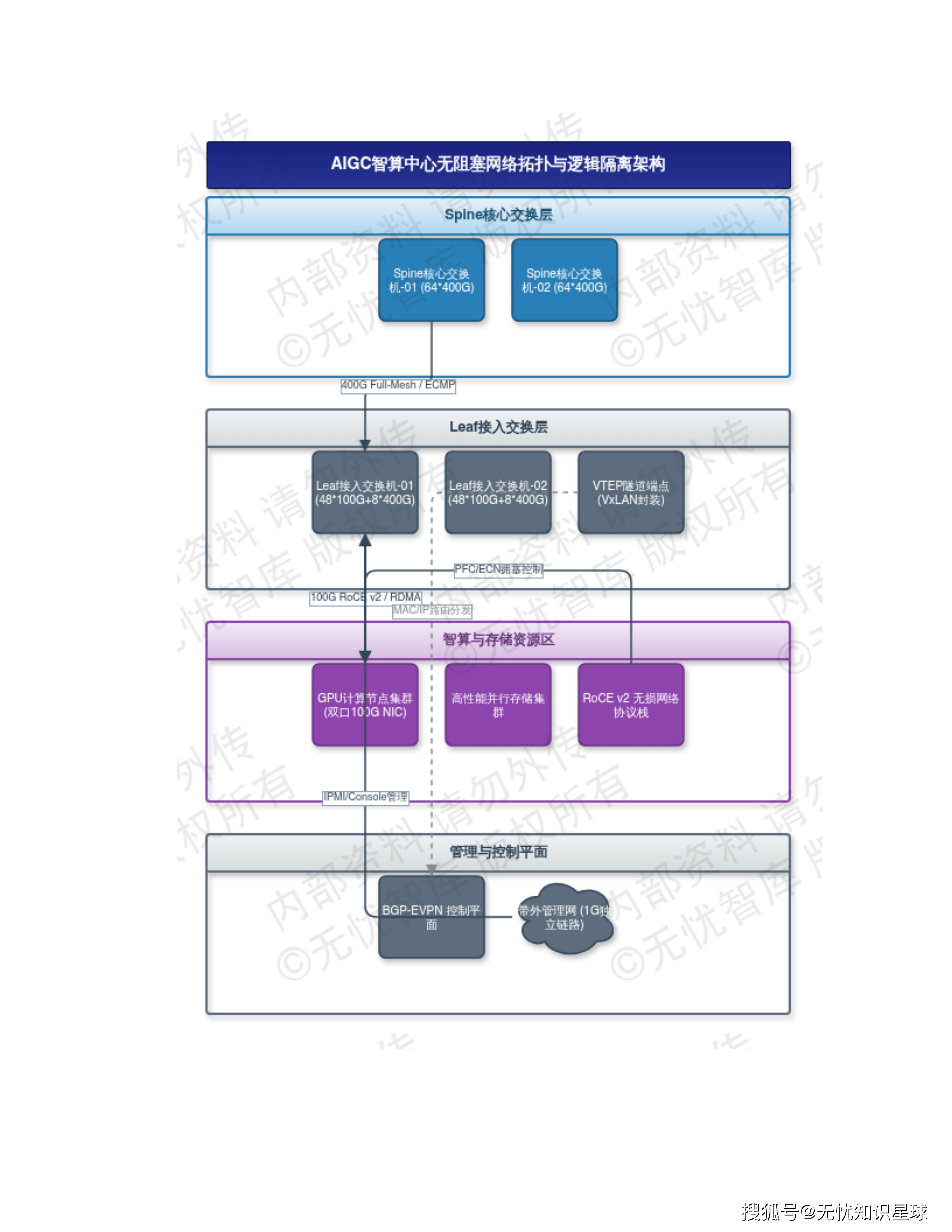
网络架构:为什么选100G以太网而不是InfiniBand
在高性能计算场景,InfiniBand是传统选择,RDMA延迟更低。但方案选择了100G标准以太网,原因非常务实:
InfiniBand配套交换机和网卡的成本是通用以太网的4-6倍,运维复杂度也显著更高。方案通过ECMP(等价多路径路由)和软件定义的流量整形,在标准以太网上实现了满足业务需求的传输性能,网络建设成本降低70%以上。
具体拓扑采用Spine-Leaf两层架构:任意两个计算节点间的通信路径固定为3跳(Leaf-Spine-Leaf),消除了传统多层网络因路径不确定导致的延迟抖动,网络抖动压缩至微秒级。
带宽收敛比控制在1:1.5到1:3的合理区间:单台Leaf交换机下联总带宽4.8Tbps(48×100G),上联Spine总带宽3.2Tbps(8×400G),在推理业务高峰期有效缓解链路拥塞。
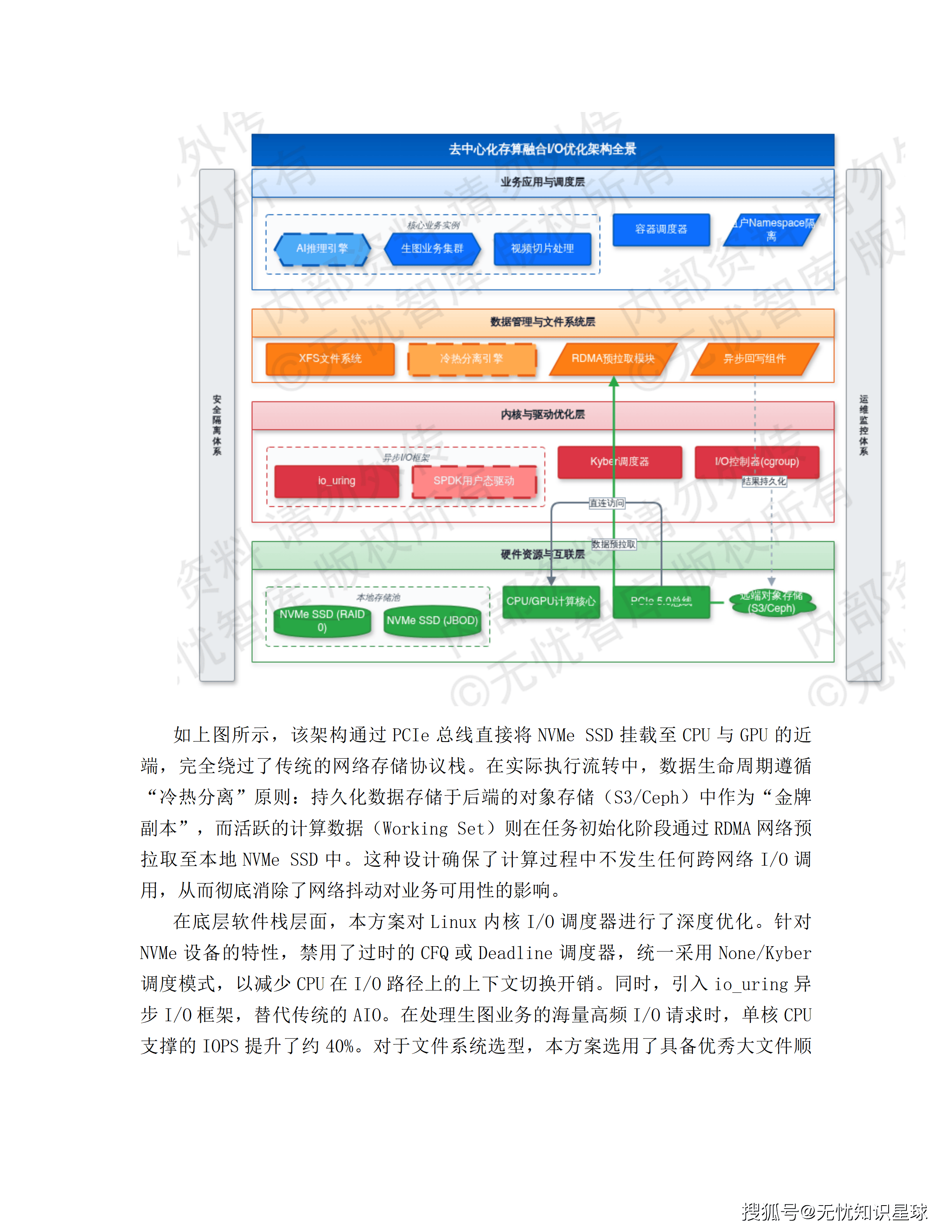
分布式存储:为什么放弃集中式存储阵列
集中式SAN/NAS存储有一个在普通业务场景不明显、但在AI推理场景非常突出的问题:多节点并发加载大模型权重时,会产生剧烈的网络风暴。加载一个175B参数模型需要数百GB的瞬时带宽,多机并发加载会使推理实例启动时间从秒级退化至分钟级。
方案的替代方案是:本地NVMe SSD直存。每个计算节点配置约30TB本地存储,通过PCIe 5.0直连,单节点聚合读取带宽突破50GB/s——这是集中式存储单节点性能的10-60倍。
文件系统层面,针对NVMe特性选用XFS,并引入io_uring异步I/O框架替代传统AIO,在处理高频I/O请求时,单核CPU支撑的IOPS提升约40%。
可靠性通过"计算节点无状态"设计保障:本地SSD仅作临时工作区,核心产出立即异步回写分布式存储。节点故障时任务自动漂移,数据从远端重新拉取,不依赖本地存储的可靠性。
内容审核:必须在流水线里而不是在流水线后
方案设计了集成于生产流水线的内容安全审核机制,这是AIGC内容工厂的合规底线。
审核时机设置在两个节点:一是剧本生成后,进入分镜生成之前;二是成片输出前,进入发行系统之前。这样做的好处是在生产链路靠前的位置拦截问题内容,避免后续工序的算力白白消耗。
方案还提到了意识形态安全的系统性集成——这对于有内容播放资质要求的正规平台来说是强制项,不是可选项。在建设阶段就把合规审核模块嵌入流水线,比上线后再打补丁要低成本得多。
强化学习驱动的模型自进化:人工干预变成训练数据
方案里有一个值得单独记录的设计思路:创作者在前端界面对AI推荐候选的每一次选择和替换,都被系统记录下来作为强化学习的训练信号。
当分镜设计Agent推荐了Top3候选分镜,创作者选择了其中评分第二的,而不是系统评分第一的——这个选择行为说明系统的评分标准和人类审美判断存在偏差。把这个偏差数据用于模型微调,让模型逐渐学会人类创作者的偏好。
随着使用时间增长,系统会越来越"懂"这个团队的审美风格,推荐的候选质量会越来越高,人工干预的频率会越来越低。这是一个随使用深化而持续优化的正反馈机制,也是AI工具和普通SaaS工具的本质差异之一。
版权确权:区块链存证要在生产阶段就介入
很多内容公司的版权管理是在作品完成后才做,但方案的设计是在生产阶段就开始介入:每部漫剧在生产过程中,关键创作节点(剧本定稿、分镜确认、成片输出)都通过区块链进行数字存证,生成带时间戳的哈希指纹。
这个设计有一个实际价值经常被忽视:当版权纠纷发生时,你需要证明的不只是"这个作品是我的",还需要证明"这个作品是在哪个时间点、通过什么创作过程产生的"。全程上链的创作记录,让这个证明变得清晰和可信。
区块链绿证核销和版权存证共用同一套基础设施,既降低了技术成本,也形成了覆盖能源消纳和内容资产两个维度的可信数字记录体系。






































































AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)