2026年了,你还只会调包?深度解析决策树原理,手撕CART算法,泰坦尼克号生存预测全揭秘
正文开始
大家好,我是你们的技术伙伴。👋
在2026年的今天,虽然深度学习和大模型占据了头条,但作为数据科学家,我们永远不能忘记那些经典、稳定且具有极强解释性的传统机器学习算法。其中,决策树(Decision Tree)无疑是皇冠上最耀眼的宝石。
决策树不仅逻辑简单(像“人脑”一样做判断),而且在处理非线性数据和分类问题上表现卓越。更重要的是,它能告诉我们“为什么模型做出了这个预测”,这在金融风控、医疗诊断等领域至关重要。
今天,我将带你从数学原理出发,穿越代码的迷雾,最终在泰坦尼克号的沉没悲剧中,验证我们的算法。准备好了吗?让我们开始这场硬核之旅!🚀
🌳 第一篇章:理论基石——决策树的“三大门派”
在开始写代码之前,我们必须先搞懂决策树的“灵魂”——特征选择。不同的选择标准,造就了不同的树模型。
1. ID3算法:信息增益的先驱
ID3是决策树的鼻祖。它使用信息熵(Entropy)来衡量数据的混乱程度。
- 核心思想:寻找一个特征,使得划分后的纯度最高,也就是信息增益(Information Gain)最大。
- 公式: Gain(D,A)=H(D)−H(D∣A)Gain(D,A)=H(D)−H(D∣A)
- 缺点:它倾向于选择取值较多的特征(比如“身份证号”),而且只能处理离散型数据。
2. C4.5算法:信息增益率的改良
C4.5是ID3的升级版,它引入了信息增益率(Gain Ratio)。
- 核心思想:在信息增益的基础上,除以一个分裂信息(Split Information)作为惩罚。这有效缓解了偏向取值多特征的问题。
- 亮点:它能处理连续数值型属性,还能处理缺失值。
3. CART算法:基尼系数的王者 (重点)
CART(Classification and Regression Tree)是目前应用最广泛的算法,也是Sklearn库的默认选择。
- 核心思想:使用基尼系数(Gini Index)来选择特征。基尼系数越小,数据的纯度越高。
- 公式:
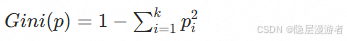
- 特点:
- 二叉树结构:每次只分裂成两部分,结构更清晰。
- 全能选手:既可以用基尼系数做分类(
DecisionTreeClassifier),也可以用平方损失做回归(DecisionTreeRegressor)。
🚢 第二篇章:实战演练——泰坦尼克号生存预测
理论说千遍,不如代码敲一遍。我们将使用CART算法,来预测哪些乘客更有可能在泰坦尼克号的灾难中幸存下来。
1. 数据预处理:脏数据的清洗
原始数据往往充满了缺失值和非数值特征。我们需要像侦探一样,修复这些漏洞。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
# 1. 加载数据
data = pd.read_csv('./data/train.csv')
# 2. 特征提取 (我们选择舱位、性别、年龄作为预测依据)
x = data[['Pclass', 'Sex', 'Age']]
y = data['Survived']
# 3. 处理缺失值:用平均值填充年龄的空缺
x = x.copy() # 避免SettingWithCopyWarning
x['Age'] = x['Age'].fillna(x['Age'].mean())
# 4. 处理非数值特征:One-Hot编码
# 将"Sex"列的male/female转换为 0/1 列
x = pd.get_dummies(x, columns=['Sex'])
# 5. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23)2. 模型训练与评估
CART算法在Sklearn中非常简单,但我们需要关注max_depth参数,防止过拟合。
# 1. 创建CART分类树对象 (限制最大深度为10,防止树长得太大)
estimator = DecisionTreeClassifier(max_depth=10, random_state=23)
# 2. 模型训练
estimator.fit(x_train, y_train)
# 3. 模型预测
y_pred = estimator.predict(x_test)
# 4. 详细评估报告
print(f'分类评估报告: \n {classification_report(y_test, y_pred)}')输出解读:
你会发现模型的准确率(accuracy)可能很高,但我们要特别关注召回率(recall)。在生存预测中,我们更希望模型能把所有能活下来的人“召回”,而不是漏掉他们。
3. 可视化决策树 (高能预警)
决策树最大的魅力在于可视化。我们可以直接看到模型的“大脑”长什么样。
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 设置图片大小,为了让复杂的树看清,我们需要一张巨大的画布
plt.figure(figsize=(30, 20))
# 绘制树结构
# filled=True 表示用颜色填充节点,颜色越深代表纯度越高
plot_tree(estimator, filled=True, max_depth=10, feature_names=x.columns, class_names=['Dead', 'Survived'])
# 保存高清大图
plt.savefig('./data/titanic_tree.png', dpi=150)
plt.show()💡 观察:
在生成的图中,你会看到类似Sex_male <= 0.5这样的判断节点。这说明模型认为“是不是男性”是决定生存的首要因素(历史事实确实如此,女士和儿童优先)。
📈 第三篇章:回归与过拟合——剪枝的艺术
决策树不仅会分类,还会回归预测(预测房价、温度等连续值)。但决策树有一个致命的弱点:过拟合。
1. 回归树 vs 线性回归
线性回归是一条直线,它假设数据是线性分布的。但现实世界往往是非线性的。
回归决策树通过不断的“切分”,可以拟合出非常复杂的阶梯状曲线。
代码对比:
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
# 准备非线性数据 (模拟房价随面积变化)
x_train = np.array(range(1, 11)).reshape(-1, 1)
y_train = np.array([5.56, 5.7, 5.91, 6.4, 6.8, 7.05, 8.9, 8.7, 9, 9.05])
# 训练线性回归 (直线)
lr = LinearRegression()
lr.fit(x_train, y_train)
# 训练回归树 (曲线)
dt = DecisionTreeRegressor(max_depth=3) # 限制深度
dt.fit(x_train, y_train)
# 预测并绘图 (你会发现回归树画出的是折线,更贴近真实数据的波动)2. 过拟合的克星:剪枝 (Pruning)
如果决策树长得太茂盛(深度太深),它会把训练数据中的“噪音”也学进去,导致在新数据上表现很差。这就是过拟合。
解决方案:
- 预剪枝 (Pre-pruning):在树生成过程中,提前停止分裂。比如限制
max_depth或min_samples_split。速度快,但可能欠拟合。 - 后剪枝 (Post-pruning):先让树长成,然后从底部开始,把那些没用的分支剪掉。效果通常更好,但计算量大。
Sklearn中的剪枝参数:
# 在创建模型时,通过调节这些参数来控制树的复杂度
DecisionTreeClassifier(
max_depth=10, # 最大深度,最常用的预剪枝方法
min_samples_split=20, # 内部节点再划分所需最小样本数
min_samples_leaf=10, # 叶子节点最少样本数
random_state=23
)📝 总结与福利
通过这篇文章,我们完成了一个完整的决策树学习闭环:
- 理论推导:搞懂了熵、基尼系数、信息增益率的区别。
- 工程实战:完成了泰坦尼克号数据的清洗、编码、训练与评估。
- 可视化:学会了如何绘制高清决策树图,让老板和同事一眼看懂模型逻辑。
- 调参艺术:掌握了剪枝技术,防止模型“死记硬背”。
独家建议:
在实际工作中,决策树往往是随机森林和XGBoost的基础。如果你能彻底搞懂决策树的原理,那么学习这些更高级的集成算法将事半功倍。
希望这篇2026年的硬核实战指南能为你打下坚实的基础。
如果你觉得这篇文章对你有帮助,请务必点赞、收藏,并关注我。有任何关于机器学习的问题,欢迎在评论区留言,我会一一解答。💬

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)