光模块的未来发展CPO模块
·
CPO(Co-Packaged Optics,共封装光学),是将光引擎(光收发模块)与交换 / AI 芯片(ASIC/GPU)通过 2.5D/3D 先进封装集成在同一基板或封装内,实现 “芯片级光电融合” 的下一代高速光互联技术。
简单理解:
- 传统方案:芯片 → 20–50cm PCB 铜线 → 独立光模块 → 光纤
- CPO 方案:芯片与光引擎封装在一起,电走线缩短到 **<10mm**,省去高功耗 DSP,实现电短光长、超低功耗、超高密度。
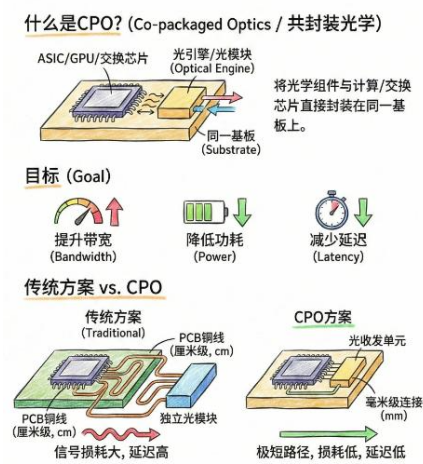
一、核心原理:把 “光” 送到芯片门口
- 传统方案(可插拔光模块):芯片→长 PCB 走线(20–50cm)→独立光模块→光纤;路径长、功耗高、延迟大、密度低。
- CPO 方案:芯片与光引擎共封装,电走线缩短到 **<10mm**,省去高功耗 DSP;实现电短光长,高速电信号仅在极短距离传输,长距由光纤承担。
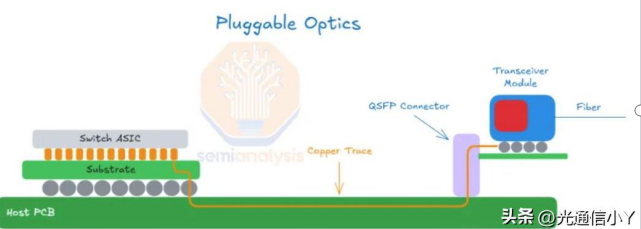
二、关键优势(对比传统可插拔)
- 超低功耗:端口功耗从 10–30W 降至 5–9W,降 50%–70%,适配 AI 集群高功耗机柜。
- 超高带宽:原生支持800G/1.6T,带宽密度提升数倍,满足万卡 GPU 集群互联。
- 超低延迟:走线缩短 + 无 DSP,延迟降 50%+,适合大模型训练并行计算。
- 超高集成度:2.5D/3D 封装,体积缩小约 40%,单机柜容纳更多端口。
三、为什么现在必须关注 CPO?(三大背景)
1. AI 算力爆发,传统光模块已到极限
- 大模型训练从千卡→万卡 GPU 集群,交换机带宽从400G→800G→1.6T快速迭代。
- 传统可插拔光模块遭遇功耗墙(10–30W / 端口)、带宽墙、密度墙三重瓶颈,无法满足万卡集群互联需求。
2. “光进铜退”:高速电互连物理极限
- 224Gbps 以上速率,铜缆传输距离不足 2 米,损耗巨大、信号完整性差。
- CPO 用硅光 + 短电 + 长光替代长铜线,成为突破物理极限的唯一路径。
性能对比
|
维度 |
传统可插拔 |
NPO |
CPO |
|
功耗 |
10–30W / 端口 |
7–12W / 端口 |
4–9W / 端口(降 50%–70%) |
|
带宽密度 |
低(1RU≈32×800G) |
中 |
高(1RU≈64×800G) |
|
延迟 |
高(纳秒级) |
中 |
超低(<1ns) |
|
集成度 |
低 |
中 |
最高(体积 - 40%) |
|
成本 |
低(成熟) |
中(过渡) |
高(量产中) |
|
商用节奏 |
现在主力 |
2026–2027 主流 |
2027 后规模化 |
3. 产业共识:CPO 是 AI 数据中心 “终极架构”
- 英伟达、博通、微软、谷歌等巨头2025–2026 年全面导入 CPO。
- 2026 年被定义为 CPO 规模化商用元年。
四、CPO 核心优势(给客户的价值点)
1. 极致低功耗(TCO 最大亮点)
- 800G 端口功耗从16W→5W,降 70%;1.6T 端口仅9W。
- 万卡集群整体功耗降低40%–50%,PUE 可降至1.1,电费大幅节省。
2. 超高带宽密度(机柜利用率翻倍)
- 单机柜带宽密度提升2–3 倍,支持51.2T–102.4T交换机。
- 同样机柜空间,可部署更多 GPU / 更高算力,机房投资更省。
3. 超低延迟(AI 训练效率提升)
- 延迟从纳秒级→亚纳秒级(<1ns),信号传输更快。
- 大模型训练并行计算效率提升 20%+,训练周期缩短。
4. 高可靠性(长期运维成本低)
- MTBF(平均无故障时间)达260 万小时,是可插拔模块的3 倍。
- 减少插拔故障、接触不良,运维压力显著降低。
五、CPO 产业链与国产机会
1. 上游:光芯片 / 硅光(价值≈40%,卡脖子环节)
- 硅光芯片:中际旭创、光迅科技、仕佳光子(国产突破)。
- 激光器:源杰科技(国产 DFB)、Lumentum(海外)。
2. 中游:光引擎 / 模块 / 封装(价值≈40%,国内最强)
- CPO 光引擎:天孚通信(英伟达独家)、中际旭创。
- 先进封装:长电科技、通富微电(2.5D/3D)。
- CPO 模块:中际旭创(全球第一)、新易盛、光迅科技。
3. 下游:交换机 / AI 集群(价值≈20%)
- 交换机 ASIC:博通 TH6、英伟达 QuantumX。
- AI 集群:英伟达 GB200/GB300、微软 Azure、谷歌 TPU。
4. 国产地位
- 中国厂商包揽全球70% 1.6T 光模块产能,英伟达 GB200 芯片80% 配套中国光模块。
- CPO 时代,中国光模块企业将从 “组装” 走向 “芯片 + 模块 + 封装” 全链条领先。
六、挑战与落地节奏
1. 当前挑战
- 技术难度高:2.5D/3D 封装、散热(>100W/cm²)、高密度光纤耦合。
- 成本偏高:良率提升中(当前≈90%),规模化后有望下降40%+。
- 维护性:共封装后故障需整体更换,运维模式需适配。
2. 时间线(2026–2030)
- 2026 年(元年):小规模商用,英伟达 SpectrumX/QuantumX 导入,450 万 + 端口出货。
- 2027 年:规模放量,800G/1.6T CPO在 AI 集群渗透率达20%+。
- 2028 年后:全面普及,成为AI 数据中心主流互联方案。
七、结论:CPO 不是选择题,是 AI 时代的必答题
- 短期(1–2 年):NPO + 传统 800G仍是主流,性价比最优;
- 中期(3–5 年):CPO 逐步替代高端场景,成为万卡 AI 集群标配;
- 长期(5 年 +):CPO 一统高端光互联,重塑数据中心架构。
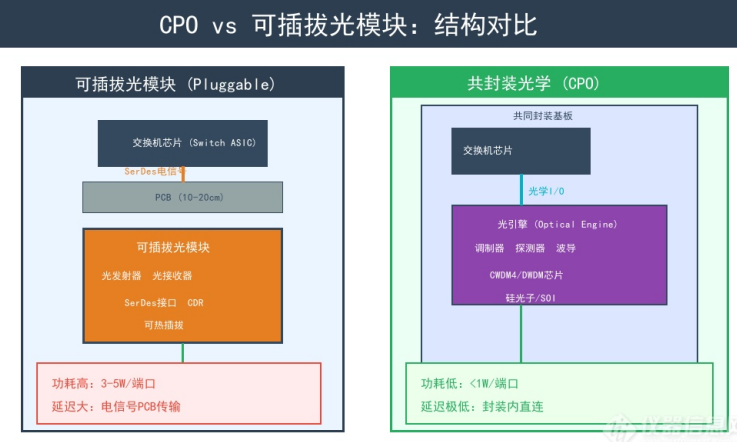
CPO / NPO / 传统光模块 极简对比
1. 全称
- 传统可插拔:普通独立光模块(100G/400G/800G)
- NPO:Near-Packaged Optics 近封装光学
- CPO:Co-Packaged Optics 共封装光学
2. 安装位置
- 传统:机箱外 / 面板插拔,离芯片最远
- NPO:靠近芯片摆放,不封装一起
- CPO:和芯片直接封装一体,贴死最近
3. 走线距离
- 传统:最长,铜线多、损耗大
- NPO:中等,缩短铜线
- CPO:最短,几乎无长铜线
4. 功耗(最关键)
- 传统:最高
- NPO:中等省电
- CPO:功耗最低,省电 50%+
5. 成本 & 难度
- 传统:最便宜、技术成熟
- NPO:适中,过渡首选
- CPO:最贵、工艺最难
6. 商用节奏
- 传统:现在主力,大规模在用
- NPO:2026-2027 主流过渡
- CPO:2027 后逐步放量,长期终极方案
7. 适用场景
- 传统:普通 IDC、云计算、中低端算力
- NPO:AI 服务器、中大型算力集群
- CPO:超大规模万卡 AI 集群、超高算力中心
一句话速记
老方案传统够用,中期先用 NPO 过渡,未来高端算力全部上 CPO。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)