Spring AI Alibaba 1.x 系列【59】OverAllState 全局状态容器核心设计与执行流程解析
1. 概述
OverAllState 作为核心容器,用于承载和管理基于图的处理流水线中各节点之间的共享数据。支持键值形式的数据存储,并且可为每个键配置自定义更新策略 KeyStrategy,实现灵活的数据合并或覆盖逻辑。该类实现了序列化,适用于持久化存储、检查点留存以及跨节点通信场景。
主要特性:
- 数据管理:通过
Map结构存储任意类型数据。 - 键策略支持:为每个键关联专属策略,控制新值与已有值的合并规则。
- 恢复模式:提供恢复标记,标识当前状态是否用于断点续执。
- 不可变视图:通过
data()和keyStrategies()提供数据与策略的只读视图。 - 状态快照:可通过
snapShot()生成当前状态的快照。 - 人工反馈:支持在流程执行中接入人工反馈与中断消息。
构造方式:
- 默认构造器:自动注册默认输入键与默认覆盖策略。
- 含数据构造器:基于已有状态数据 Map 进行初始化。
- 含恢复标记构造器:创建标记为断点续执专用的状态实例。
- 全参构造器:可完整自定义数据、键策略及恢复状态标识。
该类非线程安全,若存在并发访问场景,需由外部自行做同步控制。
2. OverAllState 类
2.1 核心常量 & 字段
公共常量:
| 常量名 | 类型 | 作用 |
|---|---|---|
DEFAULT_INPUT_KEY |
String |
默认输入键,固定值:input |
MARK_FOR_REMOVAL |
Object |
标记对象,用于标识状态键需要被删除 |
核心成员变量:
| 变量名 | 类型 | 修饰符 | 作用 |
|---|---|---|---|
data |
Map<String, Object> |
private final |
存储全局状态的键值数据(核心容器) |
keyStrategies |
Map<String, KeyStrategy> |
private final |
存储每个数据键对应的更新策略 |
store |
Store |
private |
长期记忆存储实例,用于跨执行流程持久化 |
2.2 构造函数
| 构造函数 | 权限 | 功能说明 |
|---|---|---|
OverAllState() |
public |
默认构造器:初始化空数据/策略,自动注册input键+替换策略 |
OverAllState(Map<String, Object> data) |
public |
传入初始数据,初始化状态 |
OverAllState(Store store) |
public |
传入持久化存储实例,初始化状态 |
OverAllState(Map<String, Object> data, Store store) |
public |
同时传入初始数据+存储实例,初始化状态 |
OverAllState(Map<String, Object> data, Map<String, KeyStrategy> keyStrategies) |
protected |
受保护构造器:自定义数据+策略初始化 |
OverAllState(Map<String, Object> data, Map<String, KeyStrategy> keyStrategies, Store store) |
protected |
全参构造器:完整自定义数据、策略、存储实例 |
2.3 方法分类介绍
2.3.1 状态基础操作
对全局状态进行重置、清空、覆盖、快照等基础管理:
| 方法 | 返回值 | 功能说明 |
|---|---|---|
reset() |
void |
清空所有状态数据 |
clear() |
void |
清空状态数据(保留策略、存储实例) |
cover(OverAllState overAllState) |
void |
用目标状态完整覆盖当前状态(数据+策略+存储) |
snapShot() |
Optional<OverAllState> |
创建当前状态的快照副本(深拷贝) |
2.3.2 键策略注册与校验
管理数据键对应的更新策略(合并/替换规则):
| 方法 | 返回值 | 功能说明 |
|---|---|---|
registerKeyAndStrategy(String key, KeyStrategy strategy) |
OverAllState |
注册单个键+更新策略,支持链式调用 |
registerKeyAndStrategy(Map<String, KeyStrategy> keyStrategies) |
OverAllState |
批量注册键策略,支持链式调用 |
containStrategy(String key) |
boolean |
判断是否存在指定键的更新策略 |
keyStrategies() |
Map<String, KeyStrategy> |
获取所有键策略(原始集合) |
2.3.3 状态数据更新
核心方法:根据策略合并/替换/删除状态数据:
| 方法 | 返回值 | 功能说明 |
|---|---|---|
input(Map<String, Object> input) |
OverAllState |
写入输入数据,仅更新已注册策略的键 |
updateState(Map<String, Object> partialState) |
Map<String, Object> |
基于默认策略更新状态,支持删除标记 |
updateStateWithKeyStrategies(...) |
void |
使用自定义策略映射更新状态 |
updateStateBySchema(...) |
void |
基于Schema规则+策略更新状态 |
2.3.4 静态状态更新工具
独立于实例的静态工具方法,用于状态合并计算:
| 静态方法 | 返回值 | 功能说明 |
|---|---|---|
updateState(state, partialState) |
Map<String, Object> |
基础状态更新,支持删除标记 |
updateState(state, partialState, keyStrategies) |
Map<String, Object> |
带策略的状态合并更新 |
2.3.5 数据获取
安全获取状态数据,支持泛型、类型转换、默认值:
| 方法 | 返回值 | 功能说明 |
|---|---|---|
data() |
Map<String, Object> |
获取不可修改的状态数据视图(防篡改) |
value(String key) |
Optional<T> |
按键获取数据,返回Optional容器 |
value(String key, Class<T> type) |
Optional<T> |
按键+类型获取数据,转换失败返回空 |
value(String key, T defaultValue) |
T |
按键获取数据,为空则返回默认值 |
2.3.6 持久化存储操作:
操作长期记忆存储实例:
| 方法 | 返回值 | 功能说明 |
|---|---|---|
getStore() |
Store |
获取持久化存储实例 |
2.3.7 内部辅助方法
仅类内部使用,用于校验、数据转换:
| 方法 | 权限 | 功能 |
|---|---|---|
keyVerify() |
protected |
校验数据与策略是否存在公共键 |
hasCommonKey(...) |
private |
判断两个Map是否存在公共键 |
updatePartialStateFromSchema(...) |
private static |
基于Schema更新局部状态 |
toMapRemovingNulls/toMapAllowingNulls |
private static |
自定义收集器,处理空值映射 |
2.3.8 重写方法
| 方法 | 返回值 | 功能说明 |
|---|---|---|
toString() |
String |
序列化为JSON格式字符串,异常时返回简洁文本 |
3. 执行流程
OverAllState 是 Graph 引擎的全局状态中枢,贯穿状态图执行全流程,负责存储、传递、合并所有节点共享的数据,支持键策略自定义、状态快照与持久化,是节点间数据流转的唯一载体。
本次分析只涉及普通的流程,对于中断恢复等机制,在对应的章节再讲解
图执行中涉及到状态的流程:
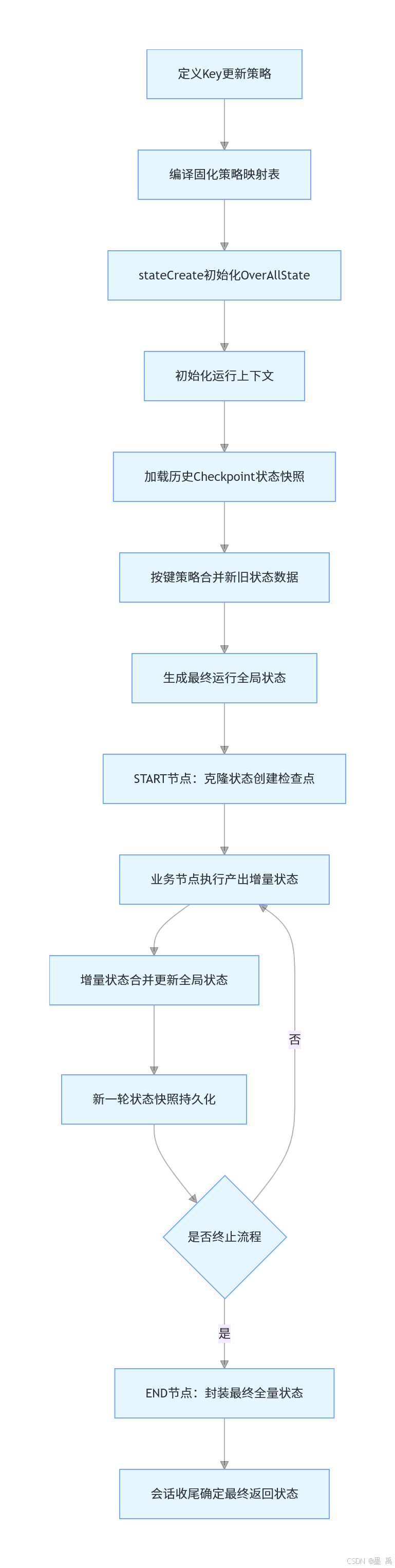
3.1 初始化 Key 更新策略
Key 更新策略(KeyStrategy)是状态图全局状态管理的核心规则,绑定在 OverAllState 中,决定了「节点执行后输出的新数据」如何与「全局状态中的旧数据」合并,是状态图数据流转的「游戏规则」。
状态图有多个节点(LLM思考、工具调用、结果生成等),所有节点共用 OverAllState 这一个全局数据容器。如果没有策略,节点更新数据会直接覆盖,导致历史数据丢失,而策略就是给每个数据键(key)定义新数据来了,是追加、替换、还是合并?
具体作用:
- 差异化管理状态数据:不同业务数据用不同规则,比如聊天消息必须追加保留历史,执行步骤只需保留最新值。
- 保障状态一致性与安全性:所有状态更新必须通过策略执行,节点无法随意篡改全局状态,
OverAllState统一管控。 - 简化节点开发:节点只需要输出「需要更新的部分数据」,无需手动处理新旧数据合并,策略自动完成。
- 支撑复杂工作流: 适配多节点串行/并行执行、断点恢复、人工反馈等场景,保证状态流转正确。
ReactAgent 在构建状态图时生成的默认策略:
private KeyStrategyFactory buildMessagesKeyStrategyFactory(List<? extends Hook> hooks) {
// KeyStrategyFactory 是函数式接口,用 Lambda 实现
return () -> {
// 1. 创建空的策略集合,存储 key → 更新策略
HashMap<String, KeyStrategy> keyStrategyHashMap = new HashMap<>();
// 2. 配置【输出键】策略(Agent 最终输出结果的 key)
if (outputKey != null && !outputKey.isEmpty()) {
// 有自定义策略用自定义,无则默认使用【替换策略】
keyStrategyHashMap.put(outputKey,
outputKeyStrategy == null ? new ReplaceStrategy() : outputKeyStrategy
);
}
// 3. 【固定核心配置】对话消息 messages 强制使用【追加策略】
keyStrategyHashMap.put("messages", new AppendStrategy());
// 4. 遍历所有扩展钩子,合并钩子中自定义的键策略
if (hooks != null) {
for (Hook hook : hooks) {
// 获取单个钩子的自定义策略
Map<String, KeyStrategy> hookStrategies = hook.getKeyStrategys();
// 非空则合并到总策略中(钩子策略可覆盖默认策略)
if (hookStrategies != null && !hookStrategies.isEmpty()) {
keyStrategyHashMap.putAll(hookStrategies);
}
}
}
// 5. 返回最终完整的键策略集合,交给 OverAllState 使用
return keyStrategyHashMap;
};
}
在自定义状态图时,需要自己构建KeyStrategyFactory 传入策略:
KeyStrategyFactory keyStrategyFactory = () -> {
HashMap<String, KeyStrategy> strategies = new HashMap<>();
strategies.put("messages", new AppendStrategy());
strategies.put("step", new ReplaceStrategy());
return strategies;
};
StateGraph stateGraph= new StateGraph(keyStrategyFactory);
创建 StateGraph 时策略工厂会赋值给 keyStrategyFactory 属性:
public StateGraph(String name, KeyStrategyFactory keyStrategyFactory, StateSerializer stateSerializer) {
this.name = name;
this.keyStrategyFactory = keyStrategyFactory;
this.stateSerializer = Objects.requireNonNull(stateSerializer, "stateSerializer cannot be null");
}
编译为可执行状态图,又会把动态定义的键策略工厂,在编译阶段固化为静态的策略表,为 OverAllState 提供状态更新的最终规则:
protected CompiledGraph(StateGraph stateGraph, CompileConfig compileConfig) throws GraphStateException {
// 1. 从编译配置中获取【最大迭代次数】(防止状态图无限循环执行)
this.maxIterations = compileConfig.recursionLimit();
// 2. 持有原始状态图对象(保留节点、边、流程定义)
this.stateGraph = stateGraph;
// 3. 核心:从状态图的策略工厂中,生成【最终固定的键策略映射表】
this.keyStrategyMap = stateGraph.getKeyStrategyFactory()
// 执行策略工厂的 Lambda 表达式(就是你之前看到的 buildMessagesKeyStrategyFactory)
.apply()
// 获取工厂生成的策略集合 Entry
.entrySet()
.stream()
// 流式转换(标准Entry映射)
.map(e -> Map.entry(e.getKey(), e.getValue()))
// 收集为最终的 Map:Key(键名) → Value(更新策略)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
//...............
}
最终存储在 CompiledGraph#keyStrategyMap 中:
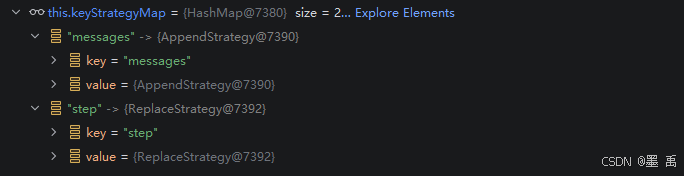
3.2 执行阶段
这是 OverAllState 最活跃的阶段,遵循状态驱动→节点执行→状态更新→路径选择的循环,直至到达 END 节点或中断点。
执行入口:
// 执行
Map<String, Object> input = Map.of("query", "Hello");
compiledGraph.invoke(input);
3.2.1 初始化状态
执行 CompiledGraph#invoke 执行时,会进行 OverAllState 初始化:
/**
* 创建全局状态实例(OverAllState)
* 处理输入参数、生成唯一执行ID,并基于编译后的策略配置初始化状态
* @param inputs 外部输入的初始数据
* @return 初始化完成的全局状态对象
*/
private OverAllState stateCreate(Map<String, Object> inputs) {
// 处理空输入场景(主要用于状态恢复/断点续执场景)
if (inputs == null) {
inputs = new HashMap<>();
}
// 强制保证执行ID存在:执行ID是状态图执行链路的唯一标识
if (!inputs.containsKey(GraphLifecycleListener.EXECUTION_ID_KEY)) {
// 复制原输入数据,避免修改外部传入的集合
Map<String, Object> newInputs = new HashMap<>(inputs);
// 生成UUID作为执行ID,注入到输入参数中
newInputs.put(GraphLifecycleListener.EXECUTION_ID_KEY, java.util.UUID.randomUUID().toString());
inputs = newInputs;
}
// ===================== 核心逻辑 =====================
// 基于编译后的配置,构建全新的全局状态OverAllState:
// 1. 绑定编译完成的键更新策略(keyStrategyMap)
// 2. 注入外部输入的初始数据
// 3. 绑定持久化存储实例(用于检查点、状态恢复)
// ====================================================
return OverAllStateBuilder.builder()
.withKeyStrategies(getKeyStrategyMap())
.withData(inputs)
.withStore(compileConfig.getStore())
.build();
}
初始化完成的 OverAllState 中包含了:
data:执行ID、调用invoke传入的数据keyStrategies:Key策略集合store:长期记忆存储器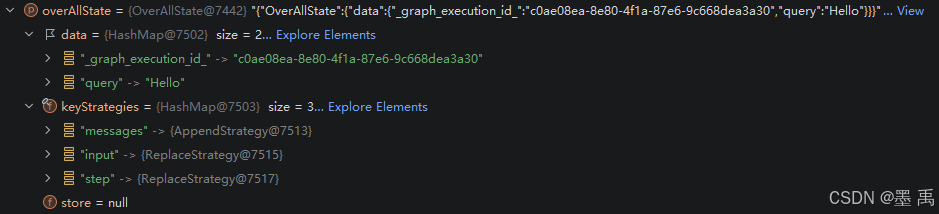
3.2.2 初始化执行上下文
进入到 GraphRunner#run 执行方法,在初始化执行上下文时,会传入初始化的 OverAllState :
/**
* 运行状态图(响应式执行入口)
* 接收初始全局状态,以响应式流的方式驱动整个状态图节点执行
* @param initialState 初始的全局状态 OverAllState(由 stateCreate 方法创建)
* @return 响应式流 Flux,包含状态图执行过程中所有节点的输出结果
*/
public Flux<GraphResponse<NodeOutput>> run(OverAllState initialState) {
// Flux.defer 延迟执行:确保每次订阅时才创建执行上下文,保证线程安全和隔离性
return Flux.defer(() -> {
try {
// 创建状态图运行上下文:封装【初始状态】、【运行配置】、【编译后的状态图】三大核心资源
GraphRunnerContext context = new GraphRunnerContext(initialState, config, compiledGraph);
// 驱动状态图节点流转、状态更新、结果输出的核心逻辑
return mainGraphExecutor.execute(context, resultValue);
}
catch (Exception e) {
// 捕获执行过程中的异常,封装为响应式流的错误信号返回
return Flux.error(e);
}
});
}
在构造 GraphRunnerContext 时会有两个分支情况:
public GraphRunnerContext(OverAllState initialState, RunnableConfig config, CompiledGraph compiledGraph)
throws Exception {
this.compiledGraph = compiledGraph;
this.config = config;
if (config.metadata(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY).isPresent() || config.checkPointId().isPresent()) {
initializeFromResume(initialState, config);
} else {
initializeFromStart(initialState, config);
}
}
3.2.3 第一次更新状态(初始化执行上下文时)
在CompiledGraph#getInitialState 时会进行第一次状态更新。
第一次执行分支的处理逻辑:
- 从初始全局状态中获取输入数据
- 创建最终可执行的全局状态
/**
* 从【起始节点】初始化状态图执行环境
* 加载初始状态、配置全局执行状态、重置节点指针
* @param initialState 外部传入的初始全局状态
* @param config 运行时配置
*/
private void initializeFromStart(OverAllState initialState, RunnableConfig config) {
// 日志:标记状态图开始执行(START节点启动)
log.trace("START");
// 从初始全局状态中获取输入数据
Map<String, Object> inputs = initialState.data();
// 如果输入数据非空,打印调试日志(记录初始化的输入键集合)
if (!CollectionUtils.isEmpty(inputs)) {
log.debug("Initializing with inputs: {}", inputs.keySet());
}
// ===================== 核心逻辑 =====================
// 1. 调用编译状态图的方法,生成标准化的初始状态
// 2. 调用 stateCreate 方法,创建最终可执行的全局状态 OverAllState
// 3. 赋值给执行器的全局状态成员变量,作为整个流程的状态载体
this.overallState = stateCreate(compiledGraph.getInitialState(inputs, config), initialState);
// 将当前执行节点设置为【状态图起始节点(START)】
this.currentNodeId = START;
// 初始化下一个节点ID为null(执行前无预设下一跳节点)
this.nextNodeId = null;
}
CompiledGraph#getInitialState 处理逻辑:
- 根据
threadId(会话ID)从检查点保存器中加载历史检查点,取最后一条 - 如果存在检查点:调用
updateState基于【键更新策略】和状态规则,合并【当前全局状态】与【局部更新状态】 - 如果不存在检查点:传入空
Map调用updateState
public Map<String, Object> getInitialState(Map<String, Object> inputs, RunnableConfig config) {
// 1. 尝试从检查点保存器中加载历史检查点
// 2. 如果存在检查点:将【历史状态】与【新输入】按照键策略合并
// 3. 如果不存在检查点:将【空状态】与【新输入】按照键策略合并
return compileConfig.checkpointSaver()
.flatMap(saver -> saver.get(config))
.map(checkpoint -> OverAllState.updateState(checkpoint.getState(), inputs, keyStrategyMap))
.orElseGet(() -> OverAllState.updateState(new HashMap<>(), inputs, keyStrategyMap));
}
updatePartialStateFromSchema 是更新的核心方法:
- 循环【执行时输入的状态数据】的所有
KEY - 获取对应的
KEY策略,默认为REPLACE - 调用
KEY策略,传入【执行时输入的状态数据】、【检查点状态数据】,默认REPLACE则会直接使用传入的值,没有变化 - 如果添加了【追加策略】,则会将【检查点状态数据】追加到【执行时输入的状态数据】
/**
* 基于【键更新策略】和状态规则,合并【当前全局状态】与【局部更新状态】
* 这是 OverAllState 状态合并的核心实现,所有键策略(追加/替换)都在此执行
* @param state 当前全局状态(旧数据)
* @param partialState 节点输出的局部状态(新数据/增量数据)
* @param keyStrategies 键策略映射(key -> 追加/替换/合并策略)
* @return 合并完成后的最终局部状态
*/
private static Map<String, Object> updatePartialStateFromSchema(Map<String, Object> state,
Map<String, Object> partialState, Map<String, KeyStrategy> keyStrategies) {
// 空值安全:如果局部状态为空,直接返回,无需合并
if (partialState == null || partialState.isEmpty()) {
return partialState;
}
// 流式遍历局部状态的每一个键值对,执行策略合并
return partialState.entrySet().stream().map(entry -> {
String key = entry.getKey();
Object value = entry.getValue();
// ============== 1. 处理【删除标记】逻辑 ==============
// 如果值是 MARK_FOR_REMOVAL 常量,标记该键需要被删除(最终设为null)
if (value == MARK_FOR_REMOVAL) {
return entryOf(key, null);
}
// ============== 2. 获取当前键对应的更新策略 ==============
// 从策略集合中获取对应key的策略,无则为null
KeyStrategy channel = keyStrategies != null ? keyStrategies.get(key) : null;
// 策略兜底:未配置策略 → 默认使用【替换策略(REPLACE)】
if (channel == null) {
channel = KeyStrategy.REPLACE;
}
// ============== 3. 执行策略:合并旧值 + 新值 ==============
// state.get(key):全局状态中的旧值
// value:局部状态中的新值
// channel.apply():执行追加/替换/自定义合并逻辑
Object newValue = channel.apply(state.get(key), value);
// 返回合并后的键值对
return entryOf(key, newValue);
})
// 收集结果:生成允许null值的Map(支持删除键)
.collect(toMapAllowingNulls(Map.Entry::getKey, Map.Entry::getValue));
}
CompiledGraph#getInitialState 方法负责加载历史检查点状态,并结合用户输入、键更新策略,合并生成状态图执行的「标准化初始状态数据」,如果是用同一个线程 ID ,就算对话结束了,第二次调用工作流时(非恢复执行),还去查历史一次历史状态进行合并,这是为了实现短期记忆… 但是使用工作流就要注意了,如果最后一个历史状态的本次输入的 KEY 一样,又是追加策略的话,本次输入的值将会被追加!!!
短期记忆中 message 消息列表在检查点中是累加的,在最后一个节点的检查点会保存本次所有的对话历史,当 getInitialState 执行时,就会拿到最后一条检查点中的对话历史,它包含了线程 ID 绑定的所有历史:
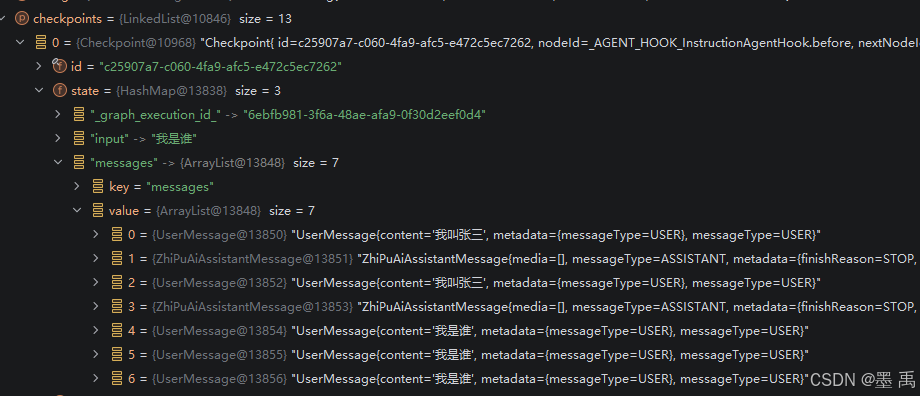
【短期记忆】这种实现方式会导致每个检查点包含全部的对话历史,如果是长文本对话,那数据量…
3.2.4 创建可执行的全局状态
在 执行了 getInitialState 进行第一次状态更新后,开始创建正式的运行时状态:
// ===================== 核心逻辑 =====================
// 1. 调用编译状态图的方法,生成标准化的初始状态
// 2. 调用 stateCreate 方法,创建最终可执行的全局状态 OverAllState
// 3. 赋值给执行器的全局状态成员变量,作为整个流程的状态载体
this.overallState = stateCreate(compiledGraph.getInitialState(inputs, config), initialState);
使用图结构中的键策略、外部传入的输入数据(经过了第一个状态更新),创建一个全新的 OverAllState 实例:
// FIXME 提示:该方法与 CompiledGraph.stateCreate 方法重复
// 需要统一规定 OverallState 的创建时机与创建方式
// 临时修复方案:确保用户传入的消息永远位于 messages 列表的最后一位
private OverAllState stateCreate(Map<String, Object> inputs, OverAllState initialState) {
// 使用图结构中的键策略 + 外部传入的输入数据,创建一个全新的 OverAllState 实例
return OverAllStateBuilder.builder()
// 从初始状态中复制 状态键(key)的合并/管理策略
.withKeyStrategies(initialState.keyStrategies())
// 注入外部传入的输入数据(如用户消息、参数等)
.withData(inputs)
// 从初始状态中复制 存储对象(Store,用于状态持久化/临时存储)
.withStore(initialState.getStore())
// 构建并返回新的 OverAllState 状态对象
.build();
}
构建完成后赋值给 GraphRunnerContext:
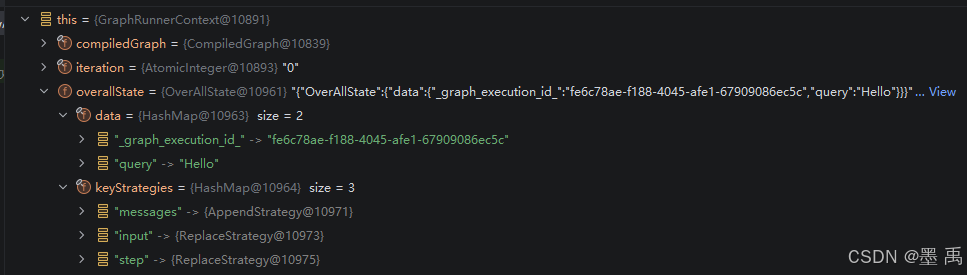
3.2.5 处理开始节点
进入 MainGraphExecutor#handleStartNode 处理开始节点:
/**
* 处理【图执行的起始节点】逻辑(Agent流程启动入口)
* @param context 图运行上下文(包含状态、配置、会话、检查点等全部信息)
* @return 包含起始节点处理结果的 GraphResponse 流
*/
private Flux<GraphResponse<NodeOutput>> handleStartNode(GraphRunnerContext context) {
try {
// 1. 触发 START 节点的监听器(生命周期钩子:流程开始时执行)
context.doListeners(START, null);
// 2. 获取图的入口命令(决定从哪个节点开始执行)
Command nextCommand = context.getEntryPoint();
// 3. 将下一个要执行的节点ID 设置到上下文
context.setNextNodeId(nextCommand.gotoNode());
// 4. 创建并保存【起始节点检查点】(短期记忆核心:快照当前状态)
// 检查点 = 会话状态快照,用于断点续跑、多轮对话上下文恢复
Optional<Checkpoint> cp = context.addCheckpoint(START, context.getNextNodeId());
// 5. 构建起始节点的输出结果(包含节点执行状态+检查点信息)
NodeOutput output = context.buildOutput(START, cp);
// 6. 将当前执行节点 更新为 下一个节点(推进执行流程)
context.setCurrentNodeId(context.getNextNodeId());
// 7. 返回起始节点结果 + 递归执行后续节点(核心:启动Agent主执行流程)
// concatWith:先返回起始节点响应,再执行真正的节点流程
// defer:保证执行逻辑延迟调用,实现异步流式处理
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> execute(context, new AtomicReference<>())));
}
catch (Exception e) {
// 异常捕获:执行失败时返回错误响应
return Flux.just(GraphResponse.error(e));
}
}
获取图的下一个入口命令时,会将状态中的 data 数据赋值给 Command 对象:

在 addCheckpoint 方法中添加并持久化一个检查点,会使用克隆(直接创建一个新的状态对象)进行保存:
/**
* 添加并持久化一个检查点(短期记忆核心方法)
* 作用:创建当前状态快照 → 写入存储器(内存/Redis/DB)→ 实现会话记忆
* @param nodeId 当前执行的节点ID
* @param nextNodeId 下一个要执行的节点ID
* @return 封装好的 Checkpoint 检查点对象
* @throws Exception 存储/序列化异常
*/
public Optional<Checkpoint> addCheckpoint(String nodeId, String nextNodeId) throws Exception {
// 1. 判断是否配置了检查点存储器(CheckpointSaver:Memory/Redis/JDBC)
// 只有配置了 Saver 才会开启短期记忆
if (compiledGraph.compileConfig.checkpointSaver().isPresent()) {
// 2. 构建 Checkpoint 检查点对象(短期记忆的实体)
var cp = Checkpoint.builder()
.nodeId(nodeId) // 当前节点ID
.state(cloneState(overallState.data())) // 克隆并保存【全局状态】(对话历史+中间变量)
.nextNodeId(nextNodeId) // 下一个节点ID(用于断点续跑)
.build();
// 3. 强制将 checkPointId 设为 null
// 目的:确保是【追加新检查点】,而不是覆盖旧检查点
// 这是实现多轮对话、历史不断累加的关键设计
RunnableConfig appendConfig = RunnableConfig.builder(config)
.checkPointId(null)
.build();
// 4. 调用存储器保存检查点(写入内存/Redis/DB)
// 短期记忆真正落地存储的地方
this.config = compiledGraph.compileConfig.checkpointSaver().get().put(appendConfig, cp);
// 5. 返回已保存的检查点
return Optional.of(cp);
}
// 未配置 CheckpointSaver → 不开启短期记忆,返回空
return Optional.empty();
}
在 buildOutput 构建输出时,又会克隆当前全局状态(OverAllState)返回:
/**
* 构建【普通节点输出】(非快照模式)
* 作用:封装节点执行后的结果、状态、令牌消耗,返回给上层调用
* @param nodeId 当前执行的节点ID(如 LLM节点、工具节点)
* @return 标准化的节点输出对象
* @throws Exception 克隆状态异常
*/
public NodeOutput buildNodeOutput(String nodeId) throws Exception {
return NodeOutput.of(
// 1. 当前节点ID:标识这个输出来自哪个节点
nodeId,
// 2. 从配置元数据中获取 Agent 标识(若无则为空字符串)
// 用于区分多个 Agent 实例/场景
(String) config.metadata("_AGENT_").orElse(""),
// 3. 【核心】深拷贝当前全局状态(OverAllState)
// 包含:对话历史 messages、中间变量、工具执行结果等
// 这是上下文传递、短期记忆的核心数据
cloneState(this.overallState.data()),
// 4. LLM 调用令牌消耗统计(输入tokens + 输出tokens)
this.tokenUsage
);
}
3.2.6 进入业务执行节点
在 NodeExecutor 中会获取业务执行节点对象,传入调用其 apply 方法,接收当前的全局状态、运行时配置作为输入,执行一些业务逻辑,并返回更新后的全局状态:
// 执行动作(如调用LLM、调用函数/工具),返回异步未来结果
CompletableFuture<Map<String, Object>> future = action.apply(context.getOverallState(),
context.getConfig());
3.2.7 节点执行完成处理
节点执行完成后,调用 handleActionResult 进行处理:
// 将 JDK 异步 Future 转为 Reactor 异步流 Mono
return Mono.fromFuture(future)
// 动作执行成功 → 处理结果,更新状态,继续执行图流程
.flatMapMany(updateState -> handleActionResult(context, updateState, resultValue))
// 异常处理:执行出错时触发错误监听器,返回错误响应
.onErrorResume(error -> {
context.doListeners(ERROR, new Exception(error));
return Flux.just(GraphResponse.error(error));
});
核心执行步骤:
- 优先级处理响应流:依次检查并处理:标准嵌入式流 → 并行图流 → 兼容版图流,命中则直接返回对应处理结果。
- 执行后中断判断:若节点支持中断,触发中断钩子,满足条件则合并状态、创建检查点、返回中断响应。
- 标准流程处理:合并状态 → 判断配置化中断 → 计算下一个节点 → 构建输出 + 检查点 → 触发监听器。
- 递归继续执行:封装当前节点响应,串联执行下一个节点,实现图的链式执行。
- 全局异常捕获:所有异常统一封装为错误响应,保证流程不崩溃。
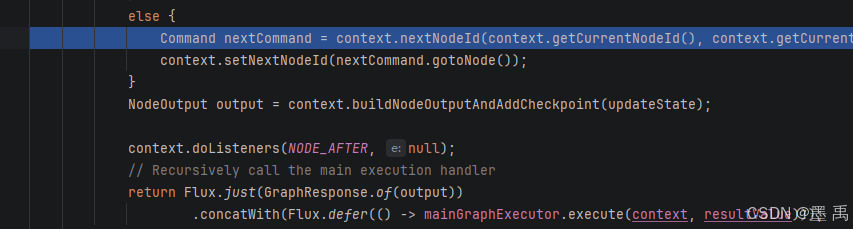
最后递归调用MainGraphExecutor进入下一个节点… 也是一样的处理逻辑,直到END…
2.2.8 第二次更新状态(节点执行完成时)
handleActionResult 中会进行合并状态更新:
context.mergeIntoCurrentState(updateState);
合并状态更新方法:
/**
* 合并状态更新:同时更新当前上下文状态 和 全局总状态
* 作用:将节点执行产生的状态变更,安全合并到执行上下文的状态中
* @param updateState 待合并的状态更新数据
*/
public void mergeIntoCurrentState(Map<String, Object> updateState) {
// 过滤状态数据:剔除令牌使用量(_TOKEN_USAGE_),单独存储
Map<String, Object> filteredState = findTokenUsageInDeltaState(updateState);
// 将过滤后的正常状态,更新到全局总状态中
this.overallState.updateState(filteredState);
}
从状态更新中分离出【令牌使用量】数据:
/**
* 临时修复方法:从状态更新中分离出【令牌使用量】数据
* 备注:FIXME 临时方案,专门配合 AgentLlmNode 非流式节点使用
* 功能:遍历状态数据,识别 _TOKEN_USAGE_ 对应的 Usage 对象,单独赋值给成员变量,不进入正常状态
* @param updateState 原始状态更新数据
* @return 过滤掉令牌使用量后的纯净状态数据
*/
private Map<String, Object> findTokenUsageInDeltaState(Map<String, Object> updateState) {
// 存储过滤后的状态(不包含_TOKEN_USAGE_)
Map<String, Object> filteredState = new HashMap<>();
// 遍历所有待更新的状态键值对
for (Map.Entry<String, Object> entry : updateState.entrySet()) {
String key = entry.getKey();
Object value = entry.getValue();
// 判断:key 是 _TOKEN_USAGE_ 且 value 是 Usage 类型
if (Objects.equals(key, "_TOKEN_USAGE_") && value instanceof Usage) {
// 单独保存令牌使用量,不存入状态map
this.tokenUsage = (Usage) value;
} else {
// 普通状态数据,放入过滤后的map中
filteredState.put(key, value);
}
}
return filteredState;
}
根据键策略合并/替换/删除状态数据:
/**
* 执行状态更新:根据键策略合并/替换/删除状态数据
* 核心:支持按key配置更新策略(默认覆盖),支持标记删除键
* @param partialState 部分状态数据(增量更新)
* @return 更新完成后的完整状态map
*/
public Map<String, Object> updateState(Map<String, Object> partialState) {
// 获取当前状态的key更新策略配置(不同key可配置不同合并规则)
Map<String, KeyStrategy> keyStrategies = keyStrategies();
// 遍历所有需要更新的key
partialState.keySet().forEach(key -> {
// 获取该key对应的更新策略,无则使用默认 REPLACE(覆盖)
KeyStrategy strategy = (keyStrategies != null) ? keyStrategies.get(key) : null;
if (strategy == null) {
strategy = KeyStrategy.REPLACE;
}
// 处理逻辑1:如果值是 MARK_FOR_REMOVAL 标记 → 删除该key
if (partialState.get(key) == MARK_FOR_REMOVAL) {
this.data.remove(key);
}
// 处理逻辑2:正常更新 → 使用策略合并新旧值
else {
// 获取旧值 → 应用策略 → 存入新值
Object oldValue = value(key, null);
Object newValue = strategy.apply(oldValue, partialState.get(key));
this.data.put(key, newValue);
}
});
// 返回更新后的完整状态
return data();
}
3.2.9 处理结束节点
在最后的 END 节点中,使用最后的状态构建输出,但是不会保存检查点:
/**
* 处理【图执行的结束节点】
* 作用:Agent 执行完成、任务结束时调用,做收尾工作
* @param context 图运行上下文(状态、配置、记忆)
* @param resultValue 用于存储最终返回结果的原子引用
* @return 包含结束节点结果的 GraphResponse 流
*/
private Flux<GraphResponse<NodeOutput>> handleEndNode(GraphRunnerContext context,
AtomicReference<Object> resultValue) {
try {
// 1. 触发 END 生命周期监听器(流程结束钩子:日志、监控、收尾回调)
context.doListeners(END, null);
// 2. 构建结束节点输出(打包最终状态、token消耗、最终上下文)
// 这里会返回最终的 OverAllState(包含完整对话历史 = 短期记忆最终状态)
NodeOutput output = context.buildNodeOutput(END);
// 3. 返回结束节点响应
// 先输出结束节点结果 → 再执行完成收尾逻辑 handleCompletion
return Flux.just(GraphResponse.of(output))
.concatWith(Flux.defer(() -> handleCompletion(context, resultValue)));
}
catch (Exception e) {
// 异常:流程结束出错时返回错误
return Flux.just(GraphResponse.error(e));
}
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)