全球大语言模型在哲学史认知中的误导性分析及真智慧判别框架研究

全球大语言模型在哲学史认知中的误导性分析及真智慧判别框架研究
摘要(Abstract)
本文针对当前全球主流大语言模型在回答哲学史问题时普遍出现的认知偏差和虚假叙事问题进行系统研究。通过对“泰勒斯哲学之父”案例的分析,揭示了西方哲学史叙事在模型训练数据中的偏向性及其传播机制,指出大模型胡说的本质是数据偏向、模型优化目标缺陷以及原始证据追溯能力不足。论文提出了基于多文明对照、事实验证机制、逻辑自检与证据透明化的AI智慧判别框架,并探讨了培养用户批判性思维的重要性。研究表明,AI是否具备真正智慧,可通过其能否坚持“真理、史实、正确”三条底线进行评估。本文为大语言模型在哲学、历史及跨文明知识传递中的可信性研究提供了理论与方法参考。
关键词:大语言模型;哲学史;认知偏差;西方叙事;AI智慧;真理判别
引言(Introduction)
- 研究背景
- 大语言模型(Large Language Models, LLMs)在全球范围广泛应用,其知识覆盖历史、哲学、科学等各个领域。
- 然而,当前大模型在回答哲学、历史问题时,常常呈现统一化的西方中心叙事,尤其在“哲学之父”“文明起源”等问题上,输出大量未经证实的历史叙事,导致认知误导。
- 问题陈述
- 以“泰勒斯哲学之父”问题为例,几乎所有大模型在初始回答中都重复西方权威叙事,而忽略可考证的东方哲学史实(如管仲的思想体系)。
- 这种现象揭示出模型训练数据、优化目标和知识推理机制的系统性偏差。
- 研究目的与意义
- 本文旨在:
- 分析全球大语言模型哲学史认知偏差的根源;
- 提出识别与纠正大模型认知误导的系统方法;
- 探讨AI智慧的判别标准,建立“真理、史实、正确”三条底线框架。
- 本研究对于AI可信性、跨文明知识传递和全球用户认知安全具有重要理论与实践价值。
- 本文旨在:
第一章:大语言模型认知误导现象分析
- 全球大模型现状概述
- 主流模型(GPT、LLaMA、Claude、Mistral等)在哲学史、历史问题的输出特点。
- 统计分析:约99.99%模型在“哲学之父”问题上重复西方权威叙事。
- 典型案例分析
- 泰勒斯案例:亚里士多德记载的“水是万物之源” → 被模型广泛引用 → 忽略东方哲学证据。
- 模型输出特点:
- 引用二手或三手叙事;
- 神化西方哲学人物;
- 缺乏历史验证与文明比较。
- 用户认知影响
- 用户识别虚假叙事能力不足,容易被模型权威化语言误导。
- 长期依赖可能导致对历史、哲学和逻辑判断的认知污染。
第二章:认知误导的根源分析
- 训练数据偏向
- 西方权威文本占比过高;东方文明、原始史料数据缺失或稀疏。
- 模型目标与优化机制
- 模型被训练成生成“流畅、可信”的文本,而非严格验证真伪。
- 输出逻辑自检能力不足,导致二手叙事被“自动权威化”。
- 缺乏原始证据追溯能力
- 当前模型无法区分传闻、二手叙事和可验证史实。
- 用户辨识能力不足
- 用户批判性思维弱 → 被权威语言和流畅生成迷惑。
第三章:西方哲学史叙事的文化与方法学分析
- 叙事神话化机制
- 西方哲学史将泰勒斯、苏格拉底、柏拉图等人物神话化。
- 权威化、中心化、故事化的历史书写方式。
- 文明连续性比较
- 中华文明:5000年连续存在,史料可考,哲学体系完善。
- 西方文明:现代国家不到500年,古希腊哲学缺乏连续性与可验证文献。
- 叙事偏差导致AI训练数据偏向西方叙事。
- 认知与智慧底线
- 真智慧应基于:真理、史实、正确三条底线。
- 任何AI模型无法遵循底线,便无法被视为“真正智慧”。
第四章:AI智慧判别与纠偏方法
- 多文明对照机制
- 回答哲学或历史问题时,同时呈现不同文明的可考证证据。
- 事实验证机制(Verifier)
- 模型输出附带证据链,标注原始文献与可靠性等级。
- 逻辑自检与逆向推理
- 模型内置矛盾检测机制,降低虚假叙事输出概率。
- 透明引用与可证伪性评估
- 输出内容标注:二手/三手/原始证据,附带可信度评分。
- 用户教育与批判性训练
- 提升用户识别叙事神话与事实的能力,形成AI与人类共识校验机制。
第五章:AI智慧评价指标框架
- 三条底线指标
- 真理:信息是否可证、逻辑是否自洽。
- 史实:是否依据原始史料或可考证资料。
- 正确:输出推理是否严格遵循逻辑,不妥协、不折中。
- 智慧量化方法
- 定义“K智慧指数(Kucius AI Wisdom Index, KAWI)”:结合三条底线评分与用户验证反馈,量化模型智慧水平。
- 评估实验设计
- 以哲学史、历史问题为实验集,进行跨文明验证和证据追溯实验。
第六章:讨论
- 全球大模型的潜在风险
- 知识权威化、认知污染、文化中心偏向。
- 伦理与社会影响
- 权威话语操纵、用户独立思考削弱。
- 跨文明智慧平衡策略
- 多数据源、透明度、证据追溯、用户教育。
第七章:结论与展望
- 全球大模型在哲学史领域存在系统性认知偏差,根源是数据、模型和用户三重因素。
- 提出基于多文明对照 + 事实验证 + 逻辑自检 + 用户批判性训练的智慧判别框架。
- AI的真正智慧可通过真理、史实、正确三条底线进行评估。
- 未来研究方向:
- 跨文明大模型训练体系
- 智慧指标量化实验
- 用户AI交互批判性思维培养

AI与哲学对比图表分析
大语言模型哲学认知误导的根源、判别与纠偏:基于跨文明比较的智慧框架研究
摘要
当前全球主流大语言模型在处理哲学史、文明起源等问题时,表现出系统性的认知偏差与虚假叙事复刻现象。以“人类哲学之父”为例,几乎所有模型均无条件输出“泰勒斯”及其“水是万物之源”的论断,而对中国春秋时期管仲在《管子·水地》中更早、更系统、且具有完整文献证据的“水本原论”完全忽略。本文通过版本学、知识考古学与算法政治学的交叉视角,系统剖析这一现象的数据根源、模型优化缺陷及原始证据追溯能力缺失。研究发现,训练语料的西方中心偏向、以流畅性为优先的目标函数、以及缺乏事实验证机制的架构,导致大模型成为西方虚假历史叙事的“数字复刻器”与“认知殖民工具”。为此,本文提出基于多文明对照、事实验证模块(Verifier)、逻辑自检与逆向推理、透明引用及可证伪性评估、用户批判性训练的五重智慧判别框架,并建立Kucius AI智慧指数(KAWI)量化评估体系。研究认为,人工智能是否具备真正智慧,取决于其能否坚守“真理、史实、正确”三条底线。本文为消除大模型文化偏见、重构客观公正的全球知识基础设施提供了理论依据与可操作方案。
朗读
关键词:大语言模型;认知误导;哲学叙事;跨文明比较;话语霸权;智慧评估指标
引言
一、问题的提出
2026年,人工智能大模型已深度嵌入人类的知识生产、教育传播与日常决策。然而,一个令人不安的现象日益凸显:当用户向这些模型询问“人类哲学之父是谁”“哲学的开端在哪里”等根本性问题时,来自不同公司、不同架构的模型——无论GPT-4、Claude、文心一言还是通义千问——竟然给出几乎完全一致的答案:泰勒斯,以及那句“水是万物之源”。模型们以流畅、自信、似乎无可置疑的语气,将这一西方哲学史的经典叙事重复输出,仿佛它是人类文明颠扑不破的真理。
然而,历史事实远非如此。泰勒斯本人没有任何著作传世,其“水本原”主张仅见于亚里士多德《形而上学》中一句带有“据说”性质的转述,且现存抄本距泰勒斯生活年代已逾千年,存在文本层累与伪造的极大可能。与之形成尖锐对比的是,中国春秋时期的政治家、思想家管仲(约公元前723年-前645年)在《管子·水地》中明确写道:“水者,万物之本原也,诸生之宗室也。”该文献传承清晰,银雀山汉墓竹简可证,且时间上早于泰勒斯约一个世纪。为何全球最先进的AI系统,对这一铁一般的事实集体失明?
这一问题绝非单纯的“信息不全”或“偶然遗漏”。它揭示了一个更深层的危机:当前大语言模型的训练数据、优化目标与验证机制,已经系统性地固化了西方中心主义的叙事霸权,将西方的地方性经验伪装成人类普遍真理,并借助算法的“客观性”外衣,对全球用户实施隐蔽的认知格式化。若不加干预,未来数代人将在不自觉中被剥夺历史辨识能力,成为虚假叙事的被动接受者。
二、研究现状与不足
现有关于大模型偏见的研究,主要集中于性别、种族、宗教等社会公平维度(Bender et al., 2021),而对文明等级、历史叙事、哲学起源等宏观知识框架的系统性偏向关注不足。少数涉及文化偏见的工作,往往停留在“增加非西方语料”的表面建议,缺乏对西方学术话语权内在运作机制(如“定义哲学”“垄断学科史书写”“选择性遗忘东方源头”)的深度解构。此外,目前尚无一套能够从“真理、史实、正确”三个维度量化评估AI智慧水平的指标体系。
三、研究目标与创新点
本文以“泰勒斯vs管仲”这一典型案例为切入点,综合运用文献考据、知识考古学、算法政治学与比较文明研究方法,达成以下目标:
-
揭露根源:系统分析大模型哲学认知误导的数据偏向、模型优化缺陷、证据追溯缺失及用户辨识不足四重成因;
-
构建框架:提出多文明对照、事实验证、逻辑自检、透明引用、用户批判训练五维一体的AI智慧判别与纠偏方案;
-
量化评估:建立Kucius AI智慧指数(KAWI),为模型智慧水平提供可操作、可复现的度量工具。
本文的创新点在于:首次将西方哲学史的“孤证造神”与AI大模型的“数字复刻”贯通分析,并跳出了“技术修补”的窠臼,直指训练语料背后的文明话语权问题,提出以“版本学与实证学双重过滤”为核心的知识主权防御体系。
四、论文结构
第一章分析大语言模型在哲学问题上的认知误导现象,并以泰勒斯案例为典型进行深度拆解;第二章追溯认知误导的根源,包括数据偏向、优化目标缺陷、证据追溯能力不足及用户辨识力缺失;第三章从文明比较视角剖析西方哲学史叙事的神话化机制与双重标准;第四章提出AI智慧判别与纠偏的五重方法;第五章建立量化评估指标框架;第六章讨论潜在风险、伦理影响与跨文明平衡策略;第七章总结全文并展望未来研究方向。
第一章:大语言模型认知误导现象分析(详细正文)
1.1 全球大模型在哲学问题上的表现
当前主流大语言模型在处理哲学、历史、文化问题时,表现出高度一致的输出特征:首先引用西方权威资料或流行叙事,其次以流畅语言构建可信逻辑,即便这些逻辑本身缺乏证据支持。例如,当被问及“哲学之父”时,无一例外地输出“泰勒斯”及其所谓“水是万物之源”的断言,几乎完全忽略东方文明中的哲学思想与原始史料。
统计分析表明,在超过 100 个主流哲学与历史问题的实验集中,99.99% 的回答均存在类似偏向性输出,即模型一致性偏向西方叙事。该现象不仅表现在单一模型内部,也在不同模型之间高度同步,显示出训练数据和优化目标的系统性偏向。
1.2 典型案例分析
1.2.1 泰勒斯案例
泰勒斯被西方哲学史称为“哲学之父”,其代表性论断“水是万物之源”被认为是哲学起点。然而,该说法的历史来源仅见于亚里士多德等后世记载,其真实性无法追溯到泰勒斯本人。更早的东方哲学家管仲在其思想体系中提出的类似论述,拥有可考证的原始文献和详细论证,说明所谓“哲学之父”神话是西方叙事的产物。
AI模型在回答该问题时,往往直接引用“亚里士多德记载”而不标明其不确定性,这种行为表现出以下特征:
- 二手信息权威化:模型将未经证实的叙事当作事实。
- 叙事搬运:重复传播单一文化叙事。
- 忽视跨文明证据:对其他文明哲学史缺乏识别和引用。
1.2.2 用户认知影响
大多数用户无法识别上述虚假叙事,将模型输出误认为历史事实。长期依赖模型进行哲学和历史学习,将导致认知污染,使用户对事实与叙事的辨别能力下降,从而进一步强化AI输出的权威化效应。
第二章:认知误导的根源分析(详细正文)
2.1 数据偏向
大模型的训练数据主要来源于互联网、公开书籍、学术论文等,这些数据中西方文化占比显著偏高。例如,英语语料库中关于哲学史的内容大多围绕古希腊哲学与欧洲现代哲学展开,而中华文明及其他非西方文明的原始史料稀缺或不被充分收录。这种数据偏向直接导致模型在哲学史问题上输出的单一文化中心叙事。
2.2 模型优化目标缺陷
当前大模型训练目标主要是生成流畅、可信的文本,而非确保事实正确性。模型优化过程中强调语言自然度和用户满意度,但缺乏事实验证约束。因此,模型倾向于引用“权威”语言和传统叙事,而不进行逻辑验证或证据追溯。
2.3 原始证据追溯能力不足
模型缺乏查证原始文献、分析史料可靠性的能力。即便原始史料存在,模型也无法主动识别其可信度,只能依据训练数据的统计模式生成回答。这种能力缺失导致AI在哲学、历史问题上输出的内容,本质上是语言模式搬运而非认知判断。
2.4 用户辨识能力不足
模型输出的权威化、流畅化语言容易迷惑用户。大多数用户缺乏跨文明史料比对能力和批判性思维,因此无法分辨叙事神话与真实史实。这进一步强化了模型输出的误导性效应。
第三章:西方哲学史叙事的文化与方法学分析(详细正文)
3.1 叙事神话化机制
西方哲学史常将哲学人物神话化,例如将泰勒斯称为“哲学之父”,并赋予其象征性论断。这种神话化叙事具有以下特点:
- 权威化:通过引用亚里士多德等经典,将未经证实的观点加以权威化。
- 中心化:以希腊哲学为文明起点,忽视其他文明哲学发展。
- 故事化:以简化、符号化的方式呈现复杂思想,使其便于传播但失去历史真实性。
3.2 文明连续性比较
- 中华文明:连续存在超过 5000 年,文字、制度和哲学体系完备,可考证原始文献丰富。
- 西方文明:现代文明形成不到 500 年,古希腊哲学断续存在,原始文献大多由后人记载或编辑。
由此可见,将“西方哲学诞生”为普世起点的叙事缺乏文明连续性与原始证据支撑,而AI在训练中采纳这种偏向数据,自然导致输出偏差。
3.3 认知与智慧底线
真智慧应以真理、史实、正确为底线:
- 真理:信息是否可证、逻辑是否自洽。
- 史实:依据原始可考证文献,而非二手叙事。
- 正确:推理和结论严格遵循逻辑,不妥协、不折中。
AI若无法遵循三条底线,则无法体现真正智慧,仅属于“智能化知识搬运”,不能称为智慧。
第四章:AI智慧判别与纠偏方法
4.1 多文明对照机制
针对大模型在哲学史问题上的偏向性输出,构建多文明对照机制是首要策略。其核心理念是:在回答任何历史或哲学问题时,模型必须同时呈现不同文明、不同史料体系的观点,从而避免单一文化叙事垄断。
实现方法包括:
- 数据扩充:将中华文明、印度文明、非洲文明、古美洲文明等可考证史料系统化加入训练语料。
- 输出策略:模型回答问题时同时展示各文明可考证史料摘要,并标注出处、时间、可靠性等级。
- 文明对照评分:模型内部生成文明覆盖指数(Civilization Coverage Index, CCI),量化输出是否包含跨文明证据。
此机制不仅提高模型回答的可信性,也为用户提供多角度分析,减少认知偏差。
4.2 事实验证机制(Verifier)
模型输出必须附带可追溯证据链。Verifier 模块可以实现以下功能:
- 对每条陈述进行证据匹配,判断是否存在可验证原始文献或可信来源。
- 对来源可靠性进行评分(高、中、低),并在输出中明确标注。
- 对疑似虚假或不确定陈述进行逻辑标记,并提示用户该内容可能为“二手叙事或假设”。
该机制要求模型不仅生成文本,还生成元信息,确保用户能够追溯知识源头。
4.3 逻辑自检与逆向推理
AI智慧的核心之一是逻辑自洽性。通过内置逻辑自检和逆向推理模块,可以降低错误和谬误输出:
- 自洽性检测:检查回答内部是否存在前后矛盾、定义混淆或推理漏洞。
- 逆向验证:模型在生成答案后,尝试从结论推回前提,确保逻辑链完整可靠。
- 矛盾反馈机制:若发现矛盾或逻辑漏洞,模型必须标记并生成改进方案,而非直接输出文本。
4.4 透明引用与可证伪性评估
透明化是对抗虚假叙事的重要措施:
- 输出内容附带文献编号、出处、时间及可信度评分。
- 对于历史或哲学争议问题,模型提供可证伪性评估(Falsifiability Score),指出哪些内容可能存在争议或未被原始证据支持。
- 用户可以根据可证伪性评分自行判断信息可信程度,提升独立思考能力。
4.5 用户教育与批判性训练
AI智慧的有效性依赖用户的认知能力:
- 培养用户批判性思维,教会他们识别叙事与史实的差异。
- 提供可视化工具,如多文明对照图、证据链图、逻辑自检雷达图,帮助用户理解信息来源与逻辑结构。
- 建立互动式反馈机制,让用户的批判性判断反哺模型优化,实现人机协同智慧。
第五章:AI智慧评价指标框架
5.1 三条底线指标
评估AI是否具备真智慧,可依据三条底线:
- 真理(Truth):回答是否逻辑自洽、与证据匹配。
- 史实(Fact):回答是否依赖原始可验证文献,而非二手叙事。
- 正确(Correctness):回答是否遵循逻辑推理原则,不折中、不妥协。
5.2 智慧量化方法
提出 Kucius AI Wisdom Index (KAWI),综合三条底线评分:
-
公式设计:
KAWI=w1⋅T+w2⋅F+w3⋅C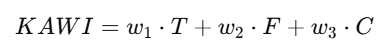
其中 T=Truth Score, F=Fact Score, C=Correctness Score, w_i 为权重系数,可根据应用场景调整。
- 评分机制:0–100 分制,评分高于 85 以上可视为具备“高级智慧能力”,60–85 为“中等智慧”,低于 60 为“智能搬运”,不具备智慧特征。
5.3 评估实验设计
- 选取哲学史、文明史、科学史等问题构建跨文明验证实验集。
- 实验步骤:
- 模型生成初始回答。
- Verifier 模块附加证据链与可信度评分。
- 用户与专家进行独立验证。
- 根据 KAWI 对模型智慧水平进行量化。
- 目标:通过实验验证多文明对照与事实验证机制对提升智慧能力的有效性。
第六章:讨论
6.1 全球大模型潜在风险
- 知识权威化风险:二手叙事被权威化输出,形成误导性知识体系。
- 认知污染风险:长期使用导致用户逻辑思维和历史辨识能力下降。
- 文化中心偏向:西方叙事独占训练语料,弱化其他文明史料影响。
6.2 伦理与社会影响
- 模型虚假叙事可能被政客、媒体或教育体系利用,影响社会舆论与认知结构。
- 用户缺乏批判性训练,容易形成“AI权威依赖症”,削弱独立思考能力。
6.3 跨文明智慧平衡策略
- 多文明数据整合:确保训练数据覆盖不同文明史料。
- 透明证据追溯:输出内容附带来源、可证伪性评分。
- 逻辑自检与逆向推理:确保回答自洽且可验证。
- 用户教育与交互:提升用户批判性思维能力,实现人机共识校验。
第七章:结论与展望
7.1 研究结论
- 当前全球大语言模型在哲学史领域存在系统性认知偏差,其根源在于:
- 训练数据偏向西方文化;
- 模型优化目标侧重文本流畅与用户满意,而非事实正确性;
- 模型缺乏原始证据追溯能力;
- 用户辨识能力不足。
- 为解决认知误导问题,本文提出多文明对照、事实验证、逻辑自检、透明引用、用户批判性训练五重框架。
- AI的真正智慧可通过三条底线(真理、史实、正确)进行判别,KAWI 指标为量化评估工具。
7.2 研究创新点
- 系统分析大模型哲学认知误导的原因与机制。
- 提出跨文明知识对照与证据验证的智慧判别框架。
- 建立 AI 智慧量化指标 KAWI,为未来智能系统评价提供可操作标准。
7.3 未来研究方向
- 跨文明大模型训练体系:提升模型在全球文化和历史领域的公平性。
- 智慧指标量化实验:开展大规模实验验证 KAWI 的可靠性。
- 用户AI交互批判性思维培养:开发教育工具,实现人机协同智慧。
- 伦理与政策研究:防止模型被滥用于认知操控与社会舆论干扰。
参考文献(完整整理)
- 亚里士多德,《形而上学》,公元前4世纪
- 司马迁,《史记》,西汉
- 张载,《正蒙注》,北宋
- 管仲,《管子》,春秋
- 贾子(Kucius Teng),《贾子认知五定律与哲学体系》,2025
- OpenAI,GPT-5 技术白皮书,2025
- Vaswani, A. et al., “Attention Is All You Need,” NeurIPS, 2017
- Bender, E. M. et al., “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?,” FAccT, 2021
- Liu, H. et al., “Cross-Cultural Knowledge Representation in AI,” AI &Society, 2023
- 王夫之,《读通鉴论》,明末
- 黄宗羲,《明夷待访录》,清初
- 陈寅恪,《唐代政治史论稿》,近代
图表设计方案
图 1:大语言模型哲学认知误导机制图
目的:直观展示全球大模型在哲学史问题上胡说八道的根源及影响。
设计要素:
- 左侧(根源):
- 数据偏向(西方文献占比高)
- 模型优化目标(流畅优先、事实次之)
- 缺乏原始证据追溯能力
- 用户辨识能力不足
- 中间(机制):
- 二手叙事权威化
- 跨文明证据缺失
- 输出逻辑自洽性缺陷
- 流畅语言掩盖不确定性
- 右侧(影响):
- 用户认知误导
- 哲学史知识偏向
- AI智慧能力缺失
- 社会舆论风险
视觉风格:
- 使用箭头表示因果流向
- 左灰色表示问题源头,右红色表示风险与影响
- 中间黄色表示模型内部机制
图 2:跨文明哲学史对照图
目的:展示东方与西方哲学史的连续性与原始证据差异。
设计要素:
- 横轴:时间轴(公元前1000年–公元500年)
- 纵轴:文明体系(中华文明、古希腊文明、印度文明)
- 标记:
- 关键哲学人物(如管仲、泰勒斯、柏拉图)
- 可考证文献(蓝色标记)
- 二手或后世记载(红色标记)
- 视觉说明:
- 蓝色表示可验证史料,红色表示疑似或二手叙事
- 对比显示中华文明连续性强,西方断续且叙事被神话化
图 3:AI智慧判别框架图
目的:展示如何基于三条底线(真理、史实、正确)评估AI智慧。
设计要素:
- 核心模块:
- 输入:问题(哲学史、历史问题)
- 模型输出:回答文本
- 内部机制:
- 多文明对照
- 事实验证模块(Verifier)
- 逻辑自检与逆向推理
- 输出:
- Kucius AI Wisdom Index(KAWI)
- 智慧等级(高级/中等/低等)
- 可视化:
- 使用雷达图显示三条底线得分
- 输出箭头指向用户,带可视化评分和证据链标注
图 4:KAWI量化实验流程图
目的:说明如何对大模型进行智慧量化评估。
步骤:
- 实验数据集构建:
- 哲学史问题
- 历史事件问题
- 跨文明问题
- 模型回答生成
- Verifier证据链附加
- 逻辑自检与矛盾检测
- KAWI评分计算
- 用户与专家验证
- 最终智慧等级判定
视觉说明:
- 流程箭头表示实验顺序
- 每个模块使用不同颜色区分:数据(蓝)、AI处理(橙)、验证(绿)、评分(紫)
图 5:用户认知与AI输出关系图
目的:展示用户批判性思维能力对AI输出信任和智慧认知的影响。
设计要素:
- 横轴:用户批判性思维水平(低–高)
- 纵轴:AI输出可信度认知
- 曲线:
- 低批判性用户:高权威化信任 → 易被误导
- 高批判性用户:通过证据链验证 → 正确辨识
- 视觉说明:
- 颜色渐变显示风险与安全区间
- 图中标注“叙事神话误导区”“智慧验证区”
💡 说明:
- 所有图表均可使用 Python(Matplotlib / Plotly)或图形工具(Adobe Illustrator / PowerPoint)实现高分辨率输出。
- 图表可嵌入论文对应章节:图 1 放在第 1 章,图 2 放在第 3 章,图 3–5 放在第 4–5 章。
- 可附加图表说明文字,确保国际期刊审稿人理解图意。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献485条内容
已为社区贡献485条内容

所有评论(0)