超节点技术深度篇四:MoE 与在网计算:从专家路由、All-to-All 到交换芯片卸载
本文基于以下三份报告进行汇总、解释和二次整理:
- 华为《超节点发展报告》
- 中兴《超节点技术白皮书》
- H3C《超节点技术白皮书》
目录
本文你会看懂什么
- 一层
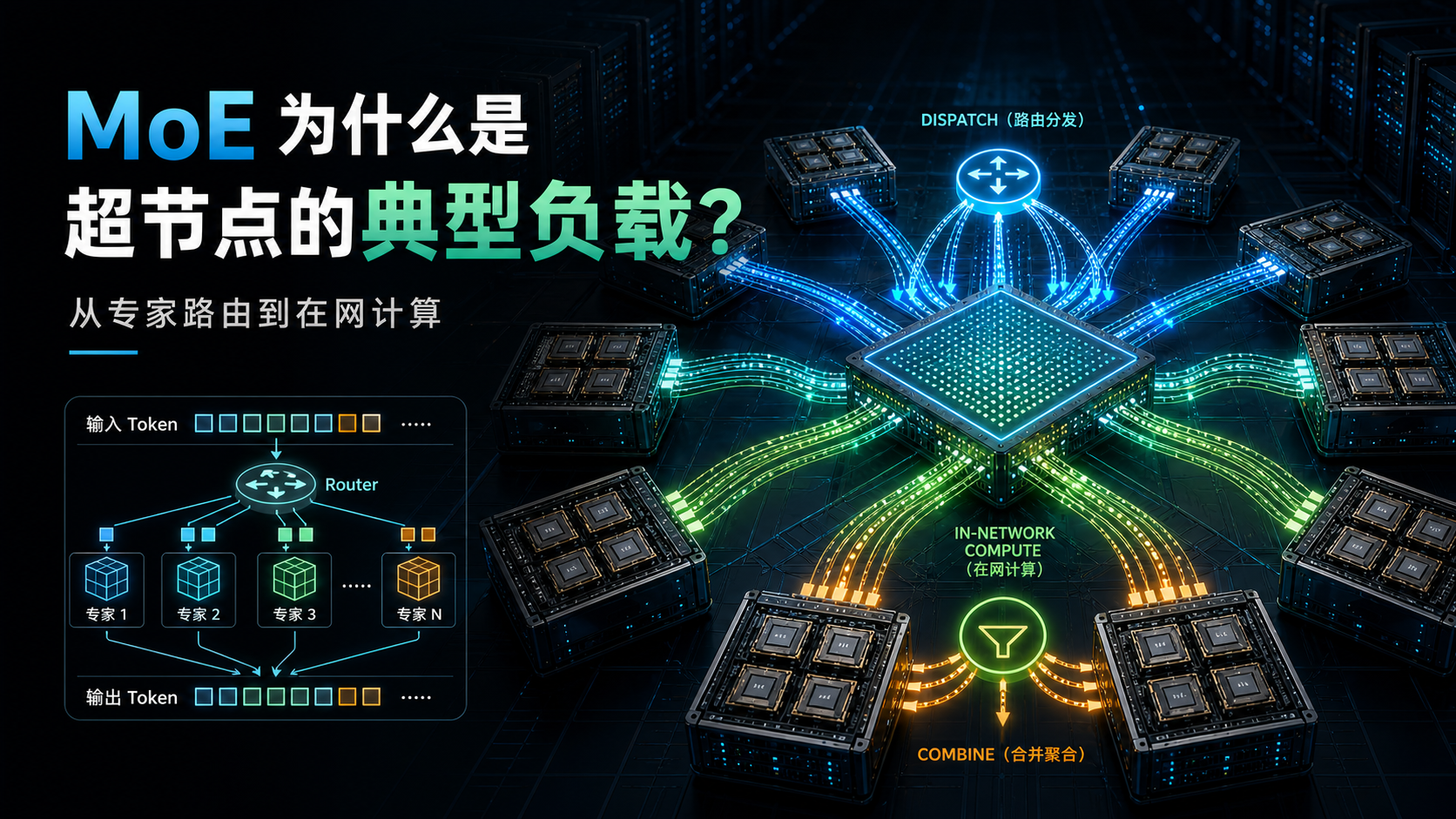
MoE在训练和推理中到底会产生哪些通信步骤。 - 为什么
EP扩大后,瓶颈经常从专家计算转向Dispatch/Combine。 - 在网计算能卸载哪些动作,不能解决哪些问题。
前一篇已经把 DP/TP/PP/EP/CP 映射到了不同通信模式。这一篇专门拆 MoE,因为它是超节点最典型、也最容易暴露系统短板的负载。
先解释
MoE,也就是混合专家模型,可以先理解成:模型里有很多“专家”子网络,但每个 token 不会经过所有专家,而是由路由器选择其中少数几个专家来处理。
它的好处是,模型总参数可以做得很大,但每次实际激活的参数相对有限。它的代价是,token 需要被动态分发到不同专家所在的设备,专家算完后还要把结果聚合回来。
这就是为什么 MoE 天然会制造通信压力。
| 稠密模型 | MoE 模型 |
|---|---|
| 每个 token 基本经过相同计算路径 | 每个 token 可能去不同专家 |
| 通信主要来自 DP、TP、PP 等并行 | 额外出现 Dispatch、Combine、All-to-All |
| 负载相对规则 | 路由结果动态变化,容易出现热点专家 |
| 优化重点偏矩阵计算和常规集合通信 | 优化重点还包括专家放置、路由均衡和尾时延 |
所以本文讲 MoE,试着看清:当模型执行路径变成动态路由之后,超节点的高带宽域、在网计算和拓扑感知调度为什么会变得重要。
关键术语先解释
| 术语 | 技术含义 | 报告中的使用方式 |
|---|---|---|
MoE |
Mixture of Experts,混合专家模型。通过多个专家子网络处理不同 token。 | 华为和 H3C 均将 MoE 作为超节点训练和推理的典型负载。 |
Router |
路由器模块,决定 token 分配给哪些专家。 | 报告没有把 Router 单独作为术语表项,但 MoE 的 Dispatch/Combine 都由路由结果触发。 |
EP |
Expert Parallelism,专家并行。把不同专家分布到不同设备。 | H3C 术语表说明 EP 常用于 MoE,将不同专家分配到不同计算节点。 |
Dispatch |
按路由结果把 token 分发到专家所在设备。 | 中兴报告使用 Dispatch Multicast 描述动态 MoE 的专家分发。 |
Combine |
把专家输出聚合回源端或原 token 顺序。 | 中兴报告使用 Combine Reduce 描述动态 MoE 的结果聚合。 |
All-to-All |
多设备互相交换不同数据。 | H3C 报告通信原语表将 All-to-All 对应到 MoE 数据分发。 |
在网计算 |
把部分 Reduce、Multicast、Combine 等通信计算下沉到交换芯片或网络内部。 | 中兴报告称 Scale-Up 交换芯片支持稠密模型和动态 MoE 的在网计算。 |
DMMA |
Dynamic MoE Multicast Acceleration,动态组播加速。 | H3C 术语表将其定义为用于提升 MoE 组播通信效率的能力。 |
EPLB |
Expert Load Balancing with Redundancy,基于冗余的专家负载均衡。 | 中兴报告用它解释热点专家副本复制和快慢卡缓解。 |
DeepEP |
面向 MoE 专家分发和合并的通信优化能力。 | 中兴报告把它放在通信层面,用于优化 Dispatch 与 Combine。 |
IBGDA |
Intelligent Bandwidth-Guided Data Aggregation,智能带宽引导数据聚合。 | 中兴报告将其用于提升机间通信效率、降低延迟、提升吞吐。 |
这些术语可以按一条链路串起来:Router 产生路由结果,EP 决定专家分布,Dispatch 把 token 发出去,专家计算后 Combine 回来;如果这条链路跨设备,就会形成 All-to-All;在网计算、DMMA、EPLB、DeepEP、IBGDA 都是在优化这条链路的不同位置。
报告中的技术表述
| 来源 | 技术表述 | 本文如何使用 |
|---|---|---|
中兴报告第 10-11 页 |
Scale-Up 交换芯片支持传统稠密模型和动态 MoE 的在网计算;稠密模型可卸载 All-Reduce,动态 MoE 可卸载 Dispatch Multicast 和 Combine Reduce。 | 用来定义“在网计算”到底卸载什么,而不是泛泛说网络更快。 |
中兴报告第 11 页 |
报告给出典型收益:干线流量减少常见超过 30%,分发阶段时延下降 20%-50%,Reduce 阶段端到端时延下降常见 40%-60% 以上。 | 用来说明在网计算的收益边界和适用阶段。 |
中兴报告第 31 页 |
EPLB 通过复制热点专家副本实现专家负载均衡,DeepEP 优化 MoE Dispatch/Combine,IBGDA 提升机间通信效率。 | 用来补充 MoE 优化不只靠网络,也要处理专家负载和通信库。 |
H3C 报告第 159-160 页 |
OISA 在 MoE 场景中通过稀疏感知字段标识激活专家,交换机可做按需组播,避免传统全量广播浪费。 | 用来说明在网计算和协议语义之间的关系。 |
H3C 报告第 270-272 页 |
1.4T MoE 训练案例把 EP All-to-All 列为严重瓶颈,需要无阻塞高带宽网络和 4D 混合并行。 | 用来说明 MoE 训练的工程瓶颈。 |
MoE 不只是多了几个专家,而是把 token 的执行路径变成了动态路由。路由一旦跨卡,网络就不再只是做 All-Reduce,而要处理高频、多目的、负载不均的 All-to-All。
换句话说,MoE 看起来是在节省计算量,系统层面却是在制造更复杂的数据重排问题。
一、先从一层 MoE 的执行链路看问题
一层典型 MoE 可以拆成下面几步:
| 阶段 | 做什么 | 主要压力 |
|---|---|---|
| Router | 计算 token 应该进入哪些专家 | 路由分布、Top-k、负载均衡 |
| Permute | 按专家目标重排 token | 显存读写、索引重排 |
| Dispatch | 把 token 发到专家所在设备 | All-to-All、热点链路、尾时延 |
| Expert Compute | 专家 MLP/GEMM/MMA 计算 | 算力、专家负载不均 |
| Combine | 把专家输出聚合回源端 | All-to-All、Reduce、回传链路 |
| Unpermute | 恢复 token 原始顺序 | 显存读写、同步等待 |
MoE 的通信不是只发生一次。
一次 MoE 层至少有 Dispatch 和 Combine 两段跨设备路径。如果 Top-k > 1,还会进一步放大分发和聚合成本。训练时这些路径进入前向和反向;推理时它们进入每 token 的关键路径。
H3C 报告提到,DeepSeek V3 推理场景下,每 token 需要多轮 Dispatch 和 Combine 跨节点动态通信,最小粒度可以到 KB 级,通信量会随 Batch Size 线性增加。这个描述很关键:MoE 推理的难点不是单次大包,而是高频小包、多轮交互和尾时延。
二、EP 扩大后,为什么 All-to-All 会变成瓶颈
EP 的目标是把不同专家放到不同设备上。扩大 EP 后,单个设备承担的专家计算压力下降,但跨设备 token 交换会增加。
可以用一个简化模型理解:
| 变量 | 含义 |
|---|---|
| B | 当前 batch 的 token 数 |
| E | 专家数量 |
| k | 每个 token 选择的专家数 |
| G | EP 组内设备数 |
| S | 单个 token hidden 状态大小 |
Dispatch 阶段需要搬运的 token 数据量近似与 B * k * S 相关,但真正影响系统效率的不是这个总量,而是这些数据如何分布到 G 个设备上。
如果路由均匀,All-to-All 还能接近规则通信;如果部分专家成为热点,就会出现三类问题:
- 热门专家所在设备计算时间更长。
- 指向热门专家的链路更容易拥塞。
- 其他设备即使算完,也要等待慢设备完成 Combine。
所以 MoE 的瓶颈不是“专家多”这个静态事实,而是“token 到专家的动态分布”让计算和网络同时变得不均匀。
H3C 报告在 1.4T MoE 训练案例中,把 EP All-to-All 明确列为严重瓶颈,并要求结合无阻塞高带宽网络和 EP/DP/TP/PP 4D 混合并行来满足训练周期和 MFU 目标。
三、HBD 应该优先服务哪些 MoE 流量
中兴报告把 Scale-Up 网络定位为承载 TP/EP 等高性能通信的高带宽域,也就是 HBD。放在 MoE 里,可以进一步拆成三类流量。
| 流量 | 是否适合放入 HBD | 原因 |
|---|---|---|
| Router 输出后的 Dispatch | 是 | 高频、动态、多目的,容易卡住 MoE 层 |
| Expert Compute 内部计算 | 间接相关 | 主要看算力,但受专家负载影响 |
| Combine 回传与归约 | 是 | 进入同步路径,尾时延会拖慢 step |
| DP 梯度同步 | 不一定 | 可以分层归约,未必全部放在 HBD |
| PP 阶段传递 | 视拓扑而定 | 相邻 stage 要近,但不一定需要全域高带宽 |
这也是为什么 MoE 是检验超节点设计的好负载:它会同时考验 HBD 的带宽、交换结构、负载均衡、乱序处理、通信库和调度器。
H3C 报告中的 Scale-Up 拓扑图,可以作为理解专家放置的物理背景。
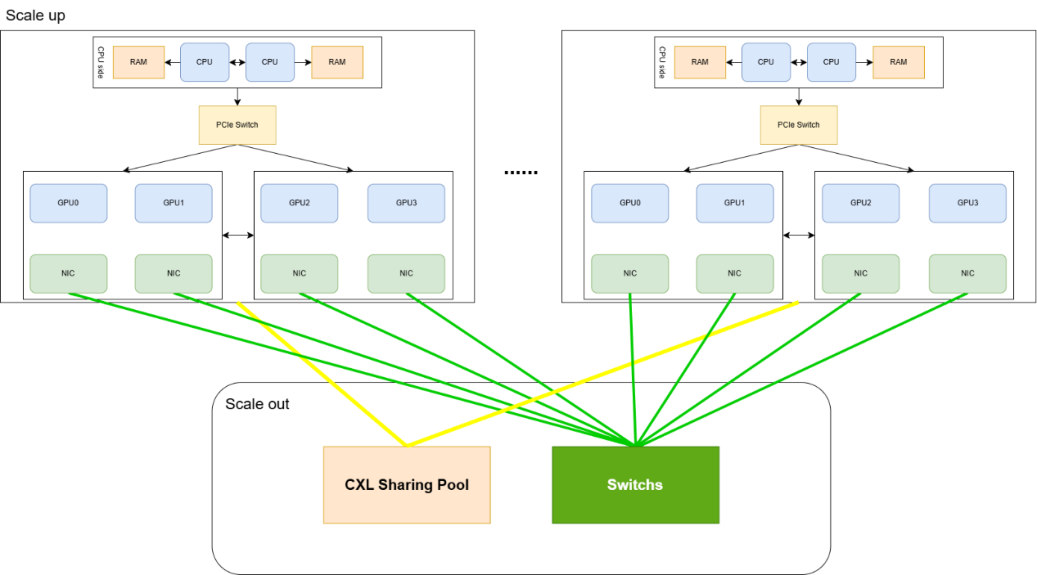
图源:H3C《超节点技术白皮书》第 235 页,图 155。用途:理解 EP 组、专家放置和 All-to-All 流量为什么需要拓扑感知。
这张图看专家通信的路径是否等价。如果 EP 组内任意两卡之间带宽和时延差异很大,那么热门专家一旦落在非等价路径上,All-to-All 的尾时延会被放大。MoE 的专家放置必须把拓扑差异纳入调度输入。
如果专家放置跨越多个低带宽域,EP 看起来扩大了,实际可能只是把专家计算问题转化成网络等待问题。
四、在网计算到底卸载了什么
中兴报告对在网计算的描述比较具体。它不是泛泛地说“网络更快”,而是说交换芯片可以参与部分集合通信和 MoE 通信操作。
在稠密模型中,交换芯片可以把部分 All-Reduce 操作从计算节点卸载到网络内部,报告中描述其通信交互复杂度可从传统 O(logN) 降低到 O©,其中 C 表示网络层级。
在动态 MoE 中,关键是两类操作:
| MoE 阶段 | 可卸载动作 | 系统意义 |
|---|---|---|
| Dispatch | Multicast、数据复制 | 减少源端 GPU 重复发送和内存复制 |
| Combine | Reduce、加权归约 | 减少回传流量和端侧聚合压力 |
中兴报告给出的结论是:在动态 MoE 中,将 Dispatch Multicast 和 Combine Reduce 卸载到交换芯片,可以降低源端 GPU 发送带宽占用和内存复制次数;报告给出的典型收益包括干线流量减少常见超过 30%,分发阶段时延下降 20%-50%,Reduce 阶段端到端时延下降常见 40%-60% 以上。
这里要特别注意一个边界:在网计算不是让交换芯片执行专家 MLP。它主要处理通信路径上的复制、归约、转发和聚合,让 GPU/NPU 把更多时间留给前向、反向和专家计算。
H3C 报告中的通信原语图,可以帮助把 All-Reduce、All-to-All、Broadcast 等操作放到同一张通信语义表里看。
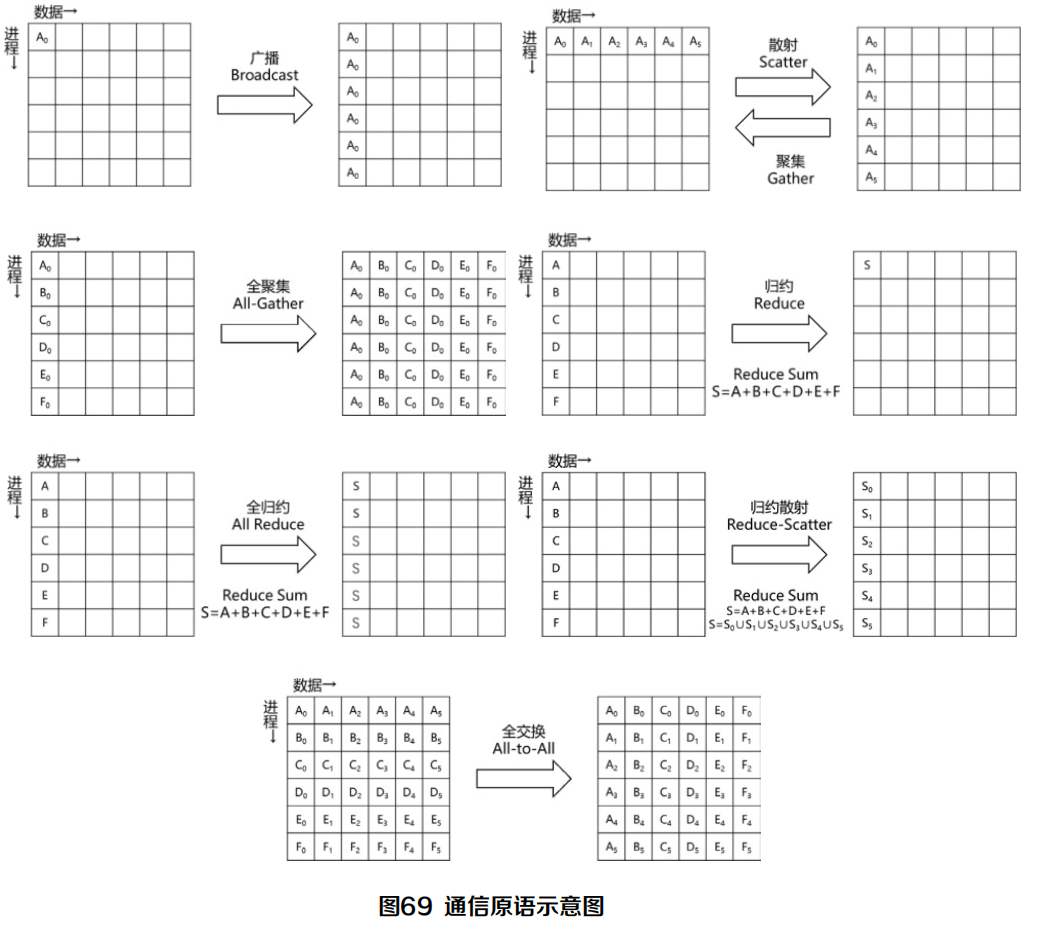
图源:H3C《超节点技术白皮书》第 87 页,图 69。用途:对照 MoE 中 All-to-All、Reduce、Broadcast/Multicast 等通信原语。
这张图可以作为 MoE 通信的术语底图:Dispatch 更接近 All-to-All 或 Multicast,Combine 更接近 Reduce 或带权聚合。理解这一点后,就能看懂为什么交换芯片有机会卸载部分复制和归约动作。
五、MoE 优化不能只看网络,还要看专家负载
中兴报告在推理优化部分提到 EPLB、DeepEP 和 IBGDA。这几个点很适合放在一起看。
| 技术点 | 解决的问题 |
|---|---|
EPLB |
通过复制热点专家副本,缓解不同 EP 专家负载不均导致的快慢卡问题 |
DeepEP |
优化 MoE 的 Dispatch 和 Combine 操作 |
IBGDA |
提升机间通信效率,降低延迟,提升吞吐 |
| Chunk Prefill | 降低长输入预填充阶段显存峰值,提高并发 |
| MTP | Decode 阶段从单 token 生成扩展到多 token 预测,提高推理性能 |
这些技术说明一件事:MoE 优化是一条从模型路由到通信库再到底层网络的完整链路。
只调专家路由,可能仍然被跨域 All-to-All 拖慢。只升级网络,可能仍然被热点专家拖慢。只改通信库,可能无法改变专家放置不合理带来的拓扑代价。
所以在真实系统中,MoE 优化至少要同时观察四个层面:
- Router 分布是否均衡。
- 专家副本和专家放置是否合理。
- Dispatch/Combine 是否拓扑感知。
- 网络是否支持高带宽、低尾时延和必要的在网卸载。
六、从仿真结果看 HBD 规模的边际收益
中兴报告用算力仿真平台分析了 Qwen3-235B 在不同超节点形态下的训练性能。
MoE 方案不能只用硬件峰值判断,需要把模型结构、EP 规模、通信带宽、算子耗时和并行切分一起建模。否则很容易把 HBD 规模做大,却不知道收益从哪里开始变缓。
报告中先分析 QKV_Linear、Flash-Attention、O_Linear、Gating_Linear 和 MoE MMA 五类算子,指出只有 MoE MMA 的算力强度会随 EP 增加而变化,并且随 EP 扩大逐步逼近硬件上限。
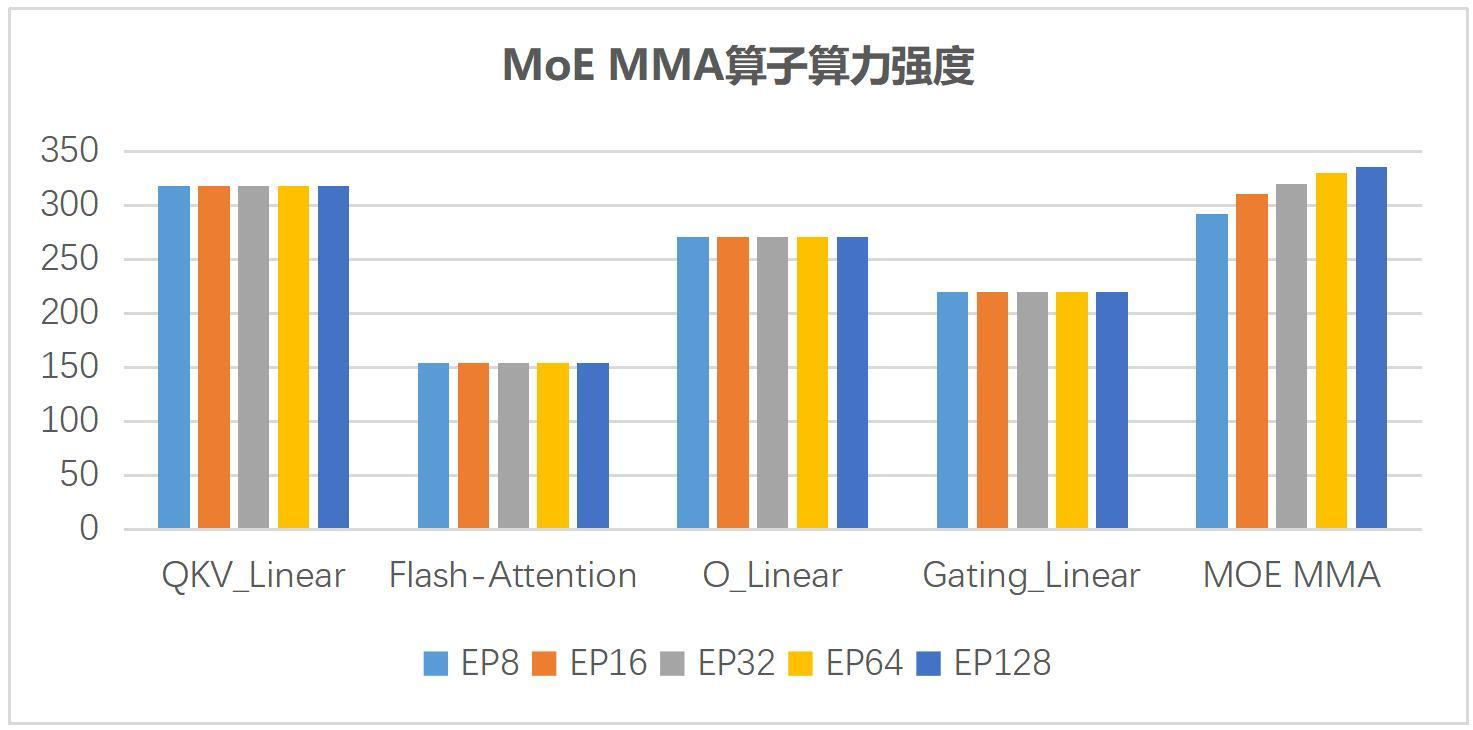
图源:中兴《超节点技术白皮书》第 33 页,图 3-2。用途:观察 EP 扩大后 MoE MMA 算子强度提升及边际变化。
这张图对应报告中的算子建模结论:在 QKV_Linear、Flash-Attention、O_Linear、Gating_Linear、MoE MMA 五类算子里,主要随 EP 扩大而变化的是 MoE MMA。也就是说,扩大 EP 的收益更集中体现在专家计算相关算子上,而不是所有算子同时受益。
再看不同超节点形态下的最优切分耗时。
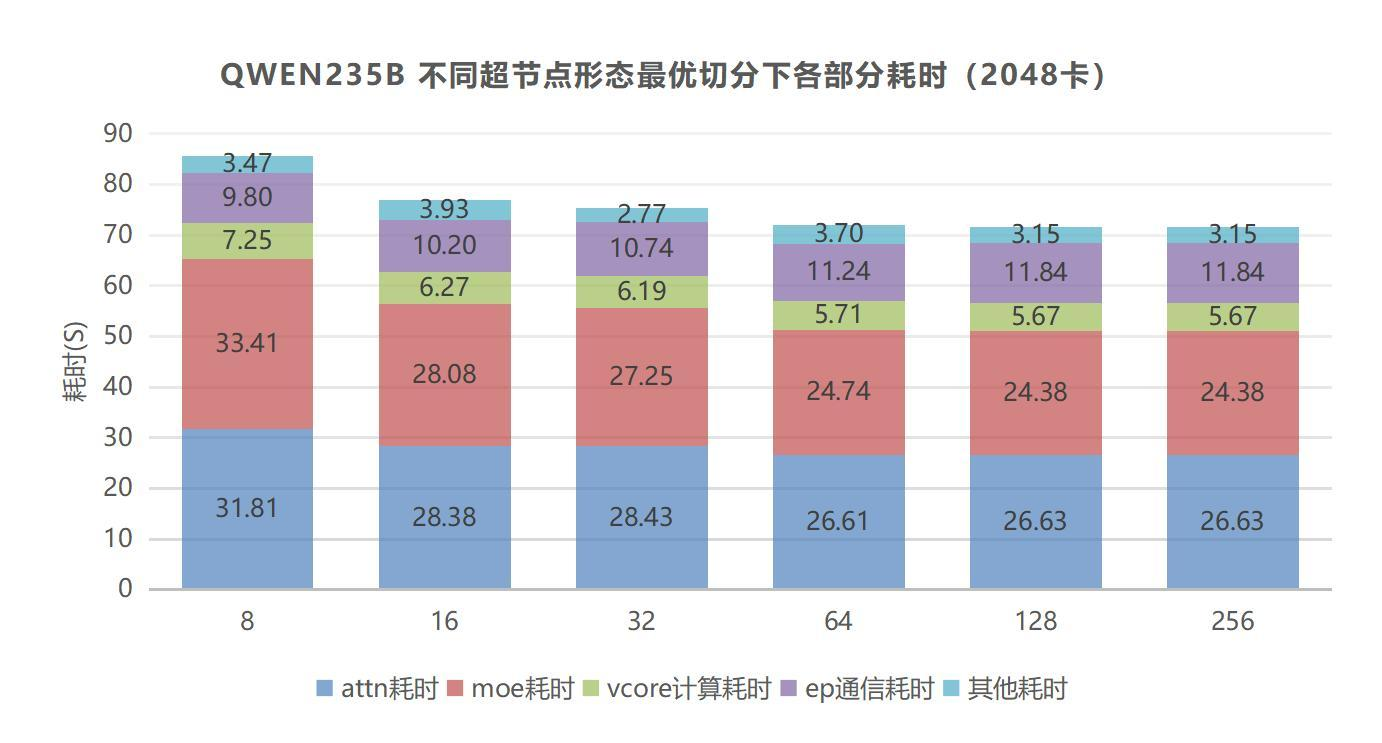
图源:中兴《超节点技术白皮书》第 33 页,图 3-3。用途:观察不同 HBD/超节点规模下计算和通信耗时变化。
这张图要结合上一张一起看:不同超节点规模带来的不是单一通信时间下降,而是最优切分策略发生变化。报告的结论是性能收益主要来自 MoE 算子性能改善,但 64 卡及以上收益趋同,这就是 HBD 扩展的边际效应。
中兴报告的判断是:在 2000 卡集群规模下,随着超节点规模增大,最优切分性能提升,收益主要来自 MoE 算子性能改善;但 64 卡及以上性能基本趋同,256 卡超节点相比 32/16 卡高 4%,相比 8 卡服务器高 15%。
这组结论很适合拿来纠正一个误区:MoE 需要更大的 HBD,但 HBD 不是越大越线性收益。
当 EP 扩大到一定程度后,继续扩大 HBD 可能被其他因素限制:
- 专家负载均衡。
- 通信库实现。
- 拓扑和链路收敛。
- 调度和资源碎片。
- 功耗、液冷和故障域。
所以工程上更重要的问题不是“做多大超节点”,而是“对这个模型、这个 batch、这个专家数量,HBD 多大开始收益变缓”。
七、拓扑感知:专家不是平均放上去就完了
MoE 的专家放置不能只按数量平均。
至少要考虑:
- 热门专家是否集中在同一设备或同一链路附近。
- Top-k 路由是否导致跨域通信过多。
- EP 组内是否存在非等价路径。
- Dispatch 和 Combine 是否经过同一拥塞点。
- 专家副本是否放在能降低热点的拓扑位置。
华为报告中的超节点通信域图适合说明故障和通信域的边界。
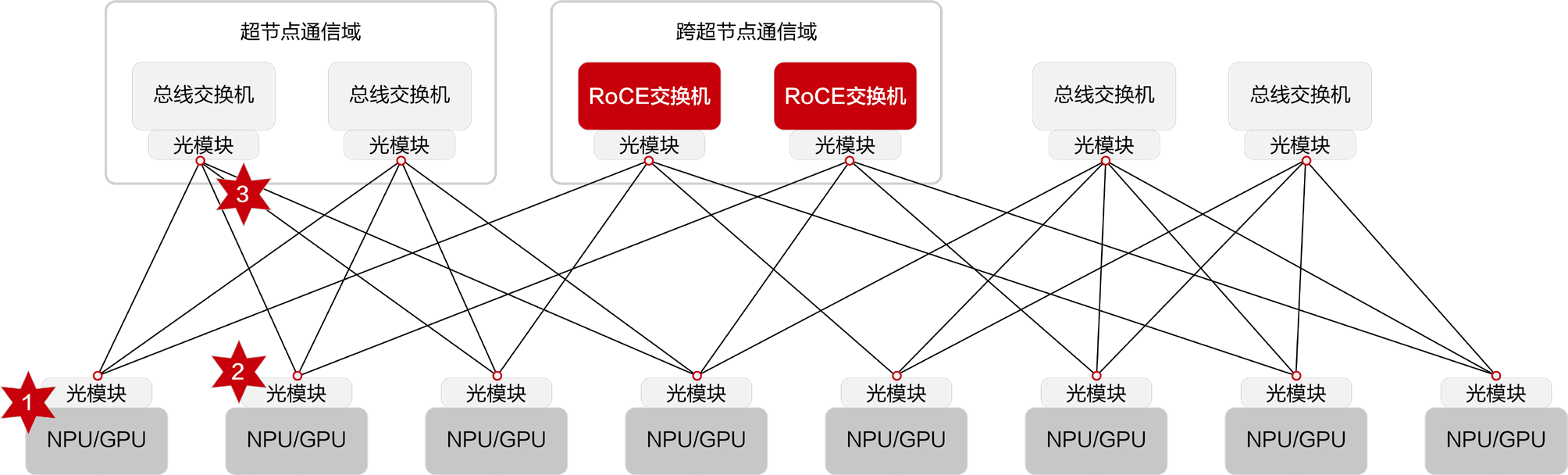
图源:华为《超节点发展报告》第 20 页,图 4.4。用途:说明超节点内部可以按通信域组织资源,MoE 的 EP 组和专家副本应尽量感知这些边界。
一个可落地的调度策略是:把专家分配当成“带通信代价的放置问题”,而不是简单轮询。
| 调度对象 | 约束 |
|---|---|
| 热门专家 | 优先复制或放到更低通信代价的位置 |
| EP group | 尽量限制在同一 HBD 内 |
| Router 输出 | 统计 token 到专家的实时分布 |
| All-to-All | 根据链路健康和队列水位调整路径 |
| 多副本推理 | 根据 SLA 和缓存位置选择实例 |
八、MoE 应该怎么观测
如果只看 GPU 利用率,MoE 的很多问题会被隐藏。
建议至少补充这些指标:
| 指标 | 用途 |
|---|---|
| 每专家 token 数 | 判断路由是否失衡 |
| 每专家计算耗时 | 判断是否出现慢专家 |
| Dispatch/Combine 耗时 | 定位 MoE 通信瓶颈 |
| All-to-All p95/p99 | 观察尾时延 |
| 链路利用率和队列水位 | 找热点链路和拥塞点 |
| 跨 HBD 流量占比 | 判断专家放置是否跨域过多 |
| 专家副本命中率 | 判断 EPLB 是否有效 |
| step time 抖动 | 判断训练稳定性 |
H3C 报告中的软件栈分层架构可以放在这里看:MoE 的观测指标需要从通信库、训练框架、调度平台和运维平台之间打通。
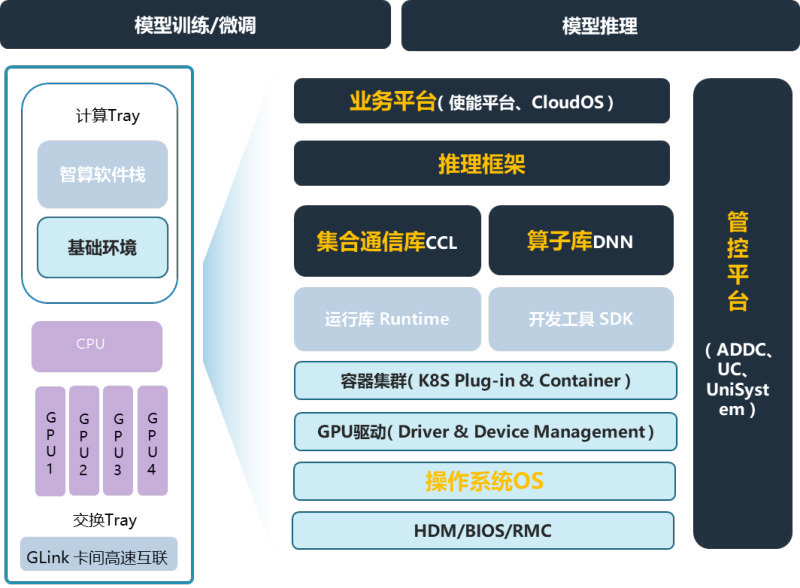
图源:H3C《超节点技术白皮书》第 309 页,图 192。用途:说明 MoE 优化需要框架、通信库、调度和运维多层协同。
九、工程判断清单
评估一个超节点方案是否适合大规模 MoE,可以直接问下面这些问题。
| 问题 | 判断意义 |
|---|---|
| EP 组是否能放进同一个 HBD | 决定 Dispatch/Combine 是否走低时延路径 |
| All-to-All 是否拓扑感知 | 决定热点链路是否可被绕开 |
| 是否支持在网 Multicast/Reduce | 决定能否降低端侧复制和回传开销 |
| 是否支持专家负载均衡 | 决定慢专家是否拖慢 step |
| 是否能观测每专家 token 分布 | 决定能否定位路由失衡 |
| HBD 扩大后的收益是否仿真过 | 避免盲目扩大超节点规模 |
| 通信库是否针对 MoE 优化 | 决定 DeepEP/All-to-All 等路径是否高效 |
| 故障后专家放置是否可重排 | 决定长周期训练稳定性 |
这张表比“支持 MoE”更接近真实工程评估。
十、总结
MoE 对超节点的要求,本质上是三个词:动态、同步、尾时延。
动态来自 token 到专家的路由;同步来自 Dispatch、Expert Compute、Combine 之间的依赖;尾时延来自热点专家、热点链路和 All-to-All 的不均匀流量。
因此,MoE 优化不能只靠更快的卡,也不能只靠更大的网络。它需要 HBD 承载 EP 高频通信,需要在网计算降低端侧和链路压力,需要专家负载均衡缓解快慢卡,需要拓扑感知调度把专家放在合适的位置。
从三份报告合起来看,MoE 是检验超节点是否“真有系统能力”的典型场景:能不能跑 MoE,不是看能不能连通,而是看能不能把专家路由、All-to-All、在网计算、调度和可观测性协同起来。
核心术语表
| 术语 | 含义 |
|---|---|
MoE |
Mixture of Experts,混合专家模型,每个 token 只激活部分专家。 |
EP |
Expert Parallelism,专家并行,把不同专家放到不同设备上并行执行。 |
Dispatch |
将 token 按路由结果发送到目标专家所在设备的阶段。 |
Combine |
将专家输出聚合并恢复到原 token 位置的阶段。 |
All-to-All |
多设备之间互相交换不同数据,MoE Dispatch/Combine 的核心通信模式。 |
EPLB |
Expert Load Balancing with Redundancy,通过热点专家副本缓解专家负载不均。 |
DeepEP |
面向 MoE 专家分发与聚合的通信优化能力。 |
IBGDA |
Intelligent Bandwidth-Guided Data Aggregation,用于提升机间通信效率。 |
在网计算 |
把部分复制、归约、聚合等通信计算卸载到交换芯片或网络内部。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)