超节点技术深度篇三:大模型并行通信拆解:DP、TP、PP、EP、CP 到底在网络里发生了什么
本文基于以下三份报告进行汇总、解释和二次整理:
- 华为《超节点发展报告》
- 中兴《超节点技术白皮书》
- H3C《超节点技术白皮书》
目录
本文你会看懂什么
- 把
DP、TP、PP、EP、CP映射成具体通信原语,而不是停留在并行概念。 - 为什么同一个训练任务里,不同通信流应该落到不同网络层:Scale-Up、Scale-Out、Frontend。
- 训练平台做拓扑感知调度时,应该看哪些通信路径和性能指标。
这篇文章从训练系统视角拆通信路径。
先解释
大模型并行通信 的意思是:当一个模型、一个 batch 或一段上下文被拆到多张 GPU/NPU 上执行时,这些设备之间为了保持计算结果一致、传递中间状态、同步参数或交换 token 而产生的数据流。
它要解决的不是“怎么把网线插得更快”,而是一个更具体的问题:模型被拆开之后,哪些数据必须在设备之间移动,移动发生在训练 step 的哪个位置,能不能和计算重叠,以及它对拓扑、带宽和时延有多敏感。
可以先用下面这张表建立直觉。
| 并行方式 | 可以先这样理解 | 最典型的通信压力 |
|---|---|---|
| DP | 多份模型副本各算一批数据 | 梯度同步、All-Reduce |
| TP | 把一层里的矩阵计算切到多张卡 | 层内高频同步、低时延通信 |
| PP | 把模型层切成多个阶段 | 阶段间激活值和梯度传递 |
| EP | 把不同专家放到不同设备 | token 分发、All-to-All |
| CP/SP | 把长序列或上下文维度切开 | Attention 相关状态交换 |
所以本文讨论的“并行通信”,不是单一网络流量,而是一组由模型切分方式决定的通信模式。超节点的价值,也要放到这些通信模式里看。
关键术语先解释
| 术语 | 技术含义 | 报告中的使用方式 |
|---|---|---|
DP |
Data Parallelism,数据并行。多张卡各自处理不同数据样本,再同步梯度或参数状态。 | 华为报告第 11 页把 DP 列入训练并行维度,用于解释总卡数和通信量增长。 |
TP |
Tensor Parallelism,张量并行。把单层里的矩阵或张量维度切到多张卡。 | H3C 术语表将 TP 解释为把模型张量维度拆分到不同设备并行执行。 |
PP |
Pipeline Parallelism,流水线并行。把模型层切成多个 stage。 | 中兴报告将 PP 归为 Scale-Out 更适合承载的相对低性能要求流量。 |
EP |
Expert Parallelism,专家并行。把 MoE 中不同专家放到不同设备。 | H3C 术语表说明 EP 常用于 MoE,把不同专家分配到不同计算节点。 |
CP/SP |
上下文并行/序列并行。面向长序列,把上下文或序列维度切分。 | 华为报告将 CP 与 TP、PP、DP 一起列入训练并行组合。 |
All-Reduce |
多设备先归约再把结果分发给所有设备,常用于梯度同步。 | H3C 报告通信原语章节把 All-Reduce 作为分布式训练全局梯度同步原语。 |
All-to-All |
多设备之间互相交换不同数据,常用于 MoE 专家分发。 | H3C 报告将 All-to-All 标注为 MoE 数据分发的典型通信原语。 |
HBD |
High-Bandwidth Domain,高带宽域。 | 中兴报告将 Scale-Up 网络承载 TP/EP 的通信区域定义为 HBD。 |
MFU |
Model FLOPs Utilization,模型有效算力利用率。 | H3C 报告把 MFU 作为衡量大规模训练通信效率的重要指标。 |
报告中的技术表述
这一篇主要依赖三条报告表述来建立分析框架:
| 来源 | 技术表述 | 本文如何使用 |
|---|---|---|
华为报告第 11 页 |
训练集群总卡数由 DP、TP、PP、CP 等并行维度相乘而来,扩展并行维度会放大跨节点通信。 | 用来解释通信量为什么会随模型和并行策略放大。 |
华为报告第 18 页 |
传统八卡服务器受 PCIe 带宽与拓扑限制,TP/CP/EP 等并行域容易被限制在单机内;64 卡 EP 并行会遇到跨机通信瓶颈。 | 用来解释为什么超节点要扩大 Scale-Up/HBD。 |
中兴报告第 23-25 页 |
Scale-Up 网络承载 TP、EP 等高性能通信流量,Scale-Out 网络承载 DP、PP 等相对低性能要求流量。 | 用来建立后文“通信分层”的主线。 |
H3C 报告网络分层章节 |
Type 3 Scale-Up 网络承载 TP/EP 流量,Type 2 Scale-Out 网络负责跨 HBD 集群扩展。 | 用来补充工程组网和调度视角。 |
一个训练 step 里,GPU/NPU 不是只做矩阵乘法,还会持续发生参数同步、中间结果交换、激活值传递、专家分发、序列切分通信。超节点的价值,要从这些通信的频率、数据量、同步强度和拓扑敏感度中看。
华为报告给出了不同并行模式下的通信特征表。
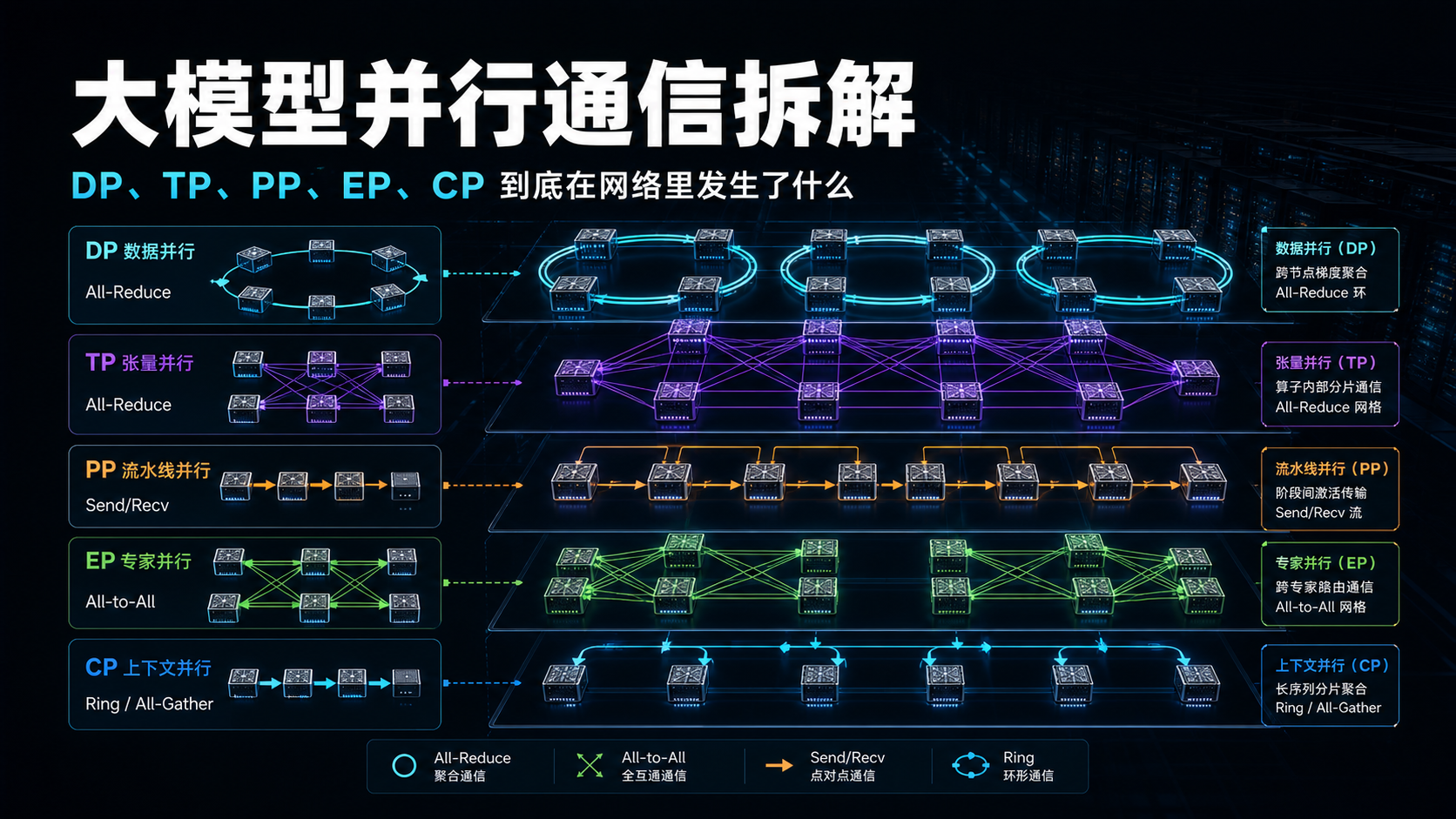
图源:华为《超节点发展报告》第 11 页,表 1。
这张表建议重点看三列信息:第一是通信发生在哪个并行维度,第二是通信是不是高频同步,第三是通信是否容易跨出单机边界。对于网络设计来说,最敏感的不是“总数据量最大”的流,而是那些发生频率高、同步要求强、难以被计算掩盖的流。
先看训练通信为什么会失控
华为报告第 11 页给了一个很适合放进技术分享的判断:训练集群总卡数通常是 DP、TP、PP、CP 等并行维度的乘积。固定全局 batch size 时,单纯增加 DP 会让每卡 micro-batch 变小,计算效率下降;继续扩大 TP、PP、CP,又会把更多通信推到跨节点路径上。
报告还用 GPT-3 到 GPT-4 的扩展做了量级对比:参数规模增加 10.8 倍时,总集合通信增加 34.1 倍,跨节点 RDMA 和光电转换增加 49.3 倍。这个数字说明,模型变大后,通信增长不是“跟着参数线性变大”那么简单,而是会被并行切分方式进一步放大。
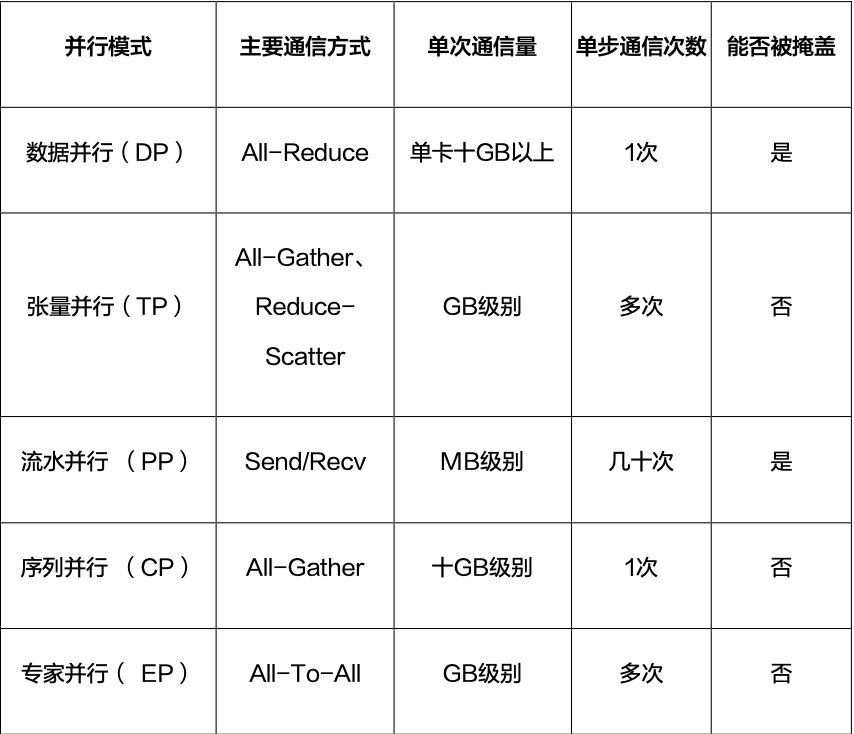
华为报告第 18 页则给出另一个关键现象:传统八卡服务器受 PCIe 带宽和拓扑限制,TP/CP/EP 等并行维度容易被限制在单机内;而 DeepSeek V3、Qwen3 等 MoE 模型使用 64 卡 EP 并行时,传统跨机通信会成为瓶颈。
图源:华为《超节点发展报告》第 18 页。用途:说明更大的 Scale-Up 域如何支撑 TP、CP、EP 等并行策略扩展。
这张图的技术含义是:当并行域从单机八卡扩大到更大的高带宽域时,模型切分策略会多出新的搜索空间。TP、CP、EP 不再天然受限于单机拓扑,但前提是域内带宽、时延和拥塞控制能够支撑这些通信进入关键路径。
中兴报告把这个问题映射到网络分层:Scale-Up 网络承载 TP、EP 等高性能通信流量,Scale-Out 网络承载 DP、PP 等相对低性能要求流量。随着模型规模增长,TP/EP 规模扩大,对 HBD 的需求也会提高,但收益存在边际效应。
TP、EP 这类对低时延和高带宽更敏感的流量,被放进 Scale-Up/HBD;DP、PP 这类更适合分层扩展的流量,可以更多交给 Scale-Out。后面的调度策略,本质就是把并行组放到合适的通信域内。
一、先把训练通信分成三类
从网络设计角度,不建议先按 DP/TP/PP 分类,而应先按通信特征分类。
| 通信类型 | 典型来源 | 网络敏感点 | 放置倾向 |
|---|---|---|---|
| 强同步高频通信 | TP、EP、部分 CP/SP | 时延、抖动、拓扑跳数 | Scale-Up/HBD |
| 大流量同步通信 | DP、ZeRO 类梯度/状态同步 | 带宽、拥塞、重叠能力 | Scale-Out 或跨 HBD |
| 阶段传递通信 | PP、Prefill/Decode 切分 | 相邻阶段路径、气泡 | 近拓扑放置 |
这个分类更接近工程判断。
如果某类通信在每层都发生,它对时延敏感;如果只在 step 边界发生,它更可能被带宽和重叠能力支配;如果通信在阶段之间发生,拓扑距离会影响流水线气泡。
二、DP:All-Reduce 不是只看总带宽
DP 的典型通信是梯度 All-Reduce。
从通信库角度看,All-Reduce 可以用 Ring、Tree、Hierarchical 等算法实现。不同算法对拓扑的要求不同。
| 算法思路 | 特点 | 适用关注点 |
|---|---|---|
| Ring | 带宽利用率高,路径规则 | 大消息、链路稳定 |
| Tree | 步数少,聚合结构清晰 | 较低时延和层级拓扑 |
| Hierarchical | 先域内归约,再跨域归约 | 超节点/多 HBD 场景 |
DP 可以跨超节点扩展,但跨域 All-Reduce 不能无脑放大。需要关注:
- 梯度桶大小。
- 通信与反向计算是否重叠。
- 跨 HBD 链路是否成为瓶颈。
- 是否做分层 All-Reduce。
- Scale-Out 网络是否承载了过多其他流量。
所以 DP 不一定最依赖 Scale-Up,但非常依赖稳定的 Scale-Out 和通信库分层策略。
三、TP:层内通信更像关键路径
TP 把单层张量计算切到多张卡上。
它最麻烦的地方不是数据量一定最大,而是通信进入了层内关键路径。一次 forward/backward 里,每层都可能发生张量切片之间的同步。
TP 典型通信包括:
- Column/Row Parallel Linear 后的结果聚合。
- Attention/MLP 切分后的中间结果同步。
- 小粒度但高频的 P2P 或集合通信。
这类通信有两个工程特征:
- 等待时间很难被完全隐藏。
- 对 P2P 时延和拓扑跳数非常敏感。
这就是中兴报告强调 HBD 承载 TP、EP 等高性能通信流量的原因。
如果 TP 组跨越普通 Scale-Out 网络,即使平均带宽够,尾时延也会进入每一层计算路径。
四、PP:气泡来自计算不均和链路不均
PP 把模型层切成多个阶段。它的主要问题是流水线气泡。
气泡来源不只是一段算得慢,也可能是一段传得慢。
PP 通信路径主要是:
- 前向阶段传递激活值。
- 反向阶段传递梯度。
- micro-batch 在不同 stage 间排队。
工程上需要关注:
- stage 计算量是否均衡。
- 相邻 stage 是否在拓扑上足够近。
- 激活值大小是否导致链路压力。
- micro-batch 数量是否足够填满流水线。
PP 不一定要求所有 stage 都在同一个 HBD 内,但相邻阶段不应被调度到高时延路径上。
五、EP:All-to-All 是 MoE 的网络核心
EP 来自专家并行,通常和 MoE 绑定。
它的典型路径是:
- Router 计算 token 到专家的映射。
- Dispatch 阶段把 token 发送到专家所在设备。
- 专家计算。
- Combine 阶段把结果聚合回来。
这里的核心通信是 All-to-All。
All-to-All 与 All-Reduce 最大的差异是流量分布不可预测。热门专家、batch 形态、路由策略都会改变流量热点。
因此 EP 需要关注:
- 专家是否按拓扑放置。
- Dispatch/Combine 是否跨 HBD。
- All-to-All 是否产生局部热点。
- 通信库是否有拓扑感知。
- 是否有在网计算能力支持 Multicast/Reduce/Combine。
MoE 会在下一篇单独展开,这里先记住一个判断:EP 是最能暴露超节点通信组织能力的并行方式之一。
六、CP/SP:长序列把通信和缓存绑在一起
CP 和 SP 的背景是长上下文。
当序列长度很长,单卡放不下完整上下文相关状态,就需要把序列维度切开。这样会产生跨序列块通信。
这类通信的特点是:
- 和 Attention 访问模式绑定。
- 和激活值、KV Cache、内存层级绑定。
- 对计算和内存访问同时敏感。
所以 CP/SP 不只是网络问题,也会把统一内存、CXL、KV Cache 池化拉进来。
七、网络分层:Scale-Up、Scale-Out、Frontend
中兴报告的 Scale-Up/Scale-Out 融合图,非常适合解释为什么 AI 集群不是一张网解决所有问题。
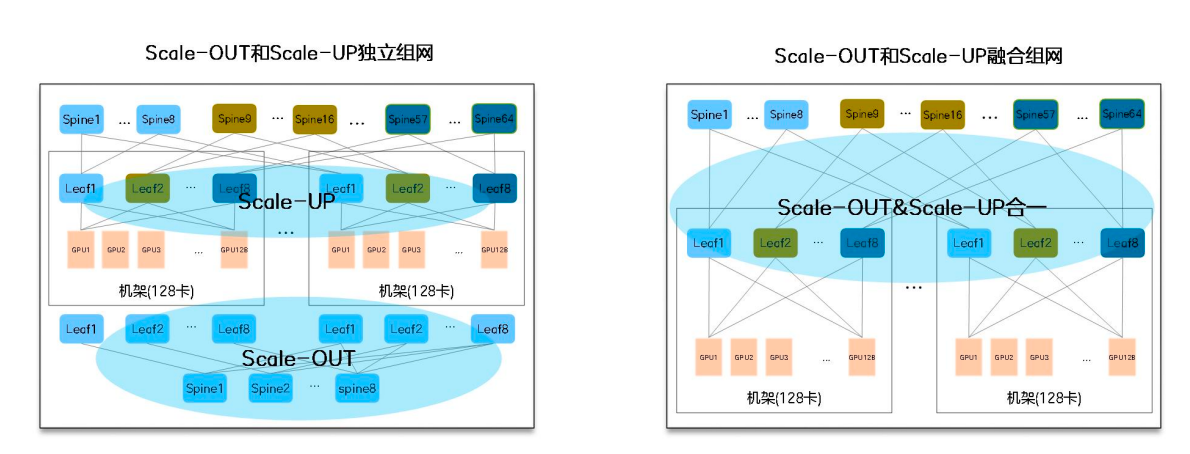
图源:中兴《超节点技术白皮书》第 25 页,图 2-3。
从训练通信映射看,可以得到一个实用规则:
| 网络层 | 适合承载 | 不适合承载 |
|---|---|---|
| Scale-Up | TP、EP、P2P、高频集合通信 | 大范围低频扩展流量 |
| Scale-Out | DP、跨 HBD 扩展、跨超节点 PP | 层内高频同步通信 |
| Frontend | 管理、存储、业务访问 | 训练关键路径通信 |
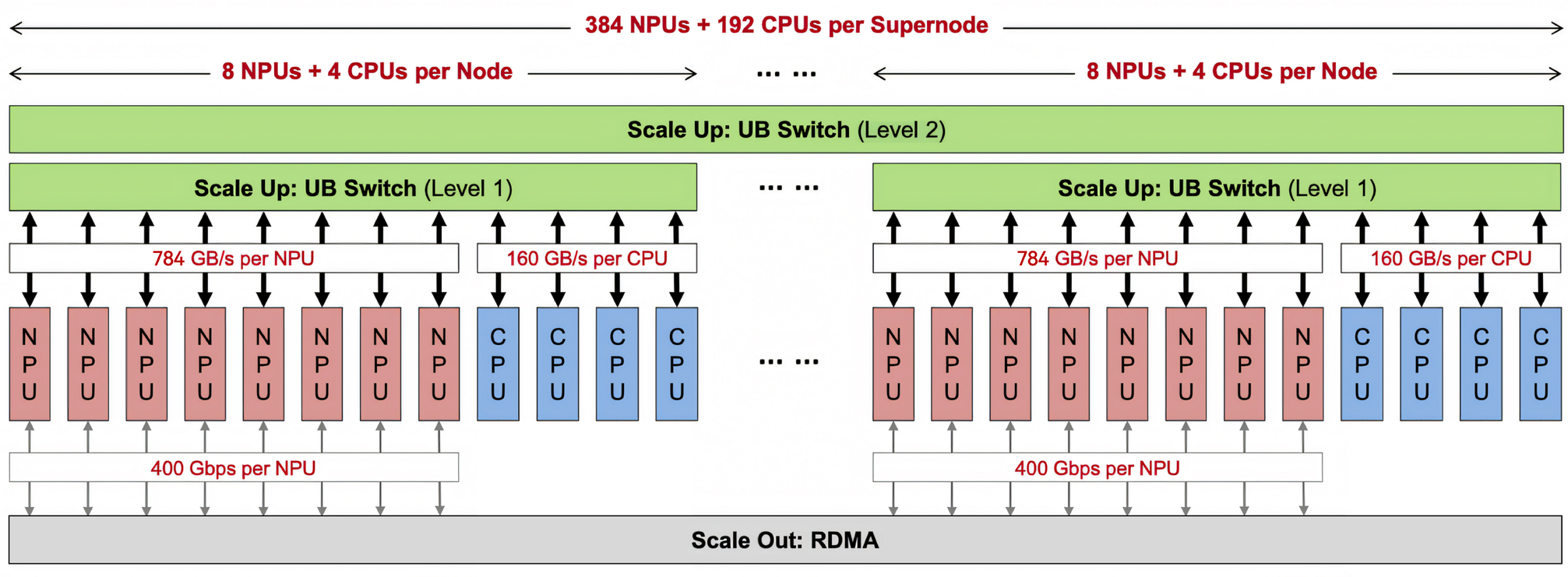
华为报告中的通信范式演变图,说明基础计算单元正在从单服务器走向超节点。
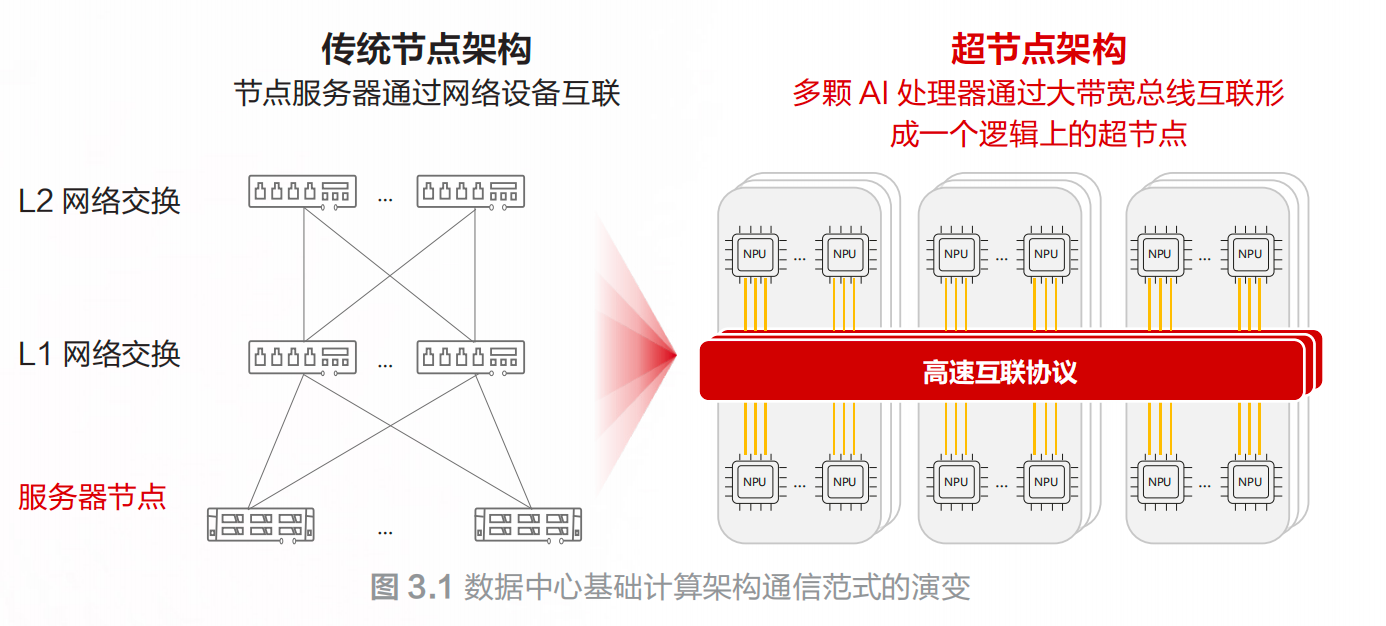
图源:华为《超节点发展报告》第 13 页,图 3.1。
H3C 报告中的 Scale up 拓扑和 GPU 拓扑,则对应调度器需要感知的物理结构。
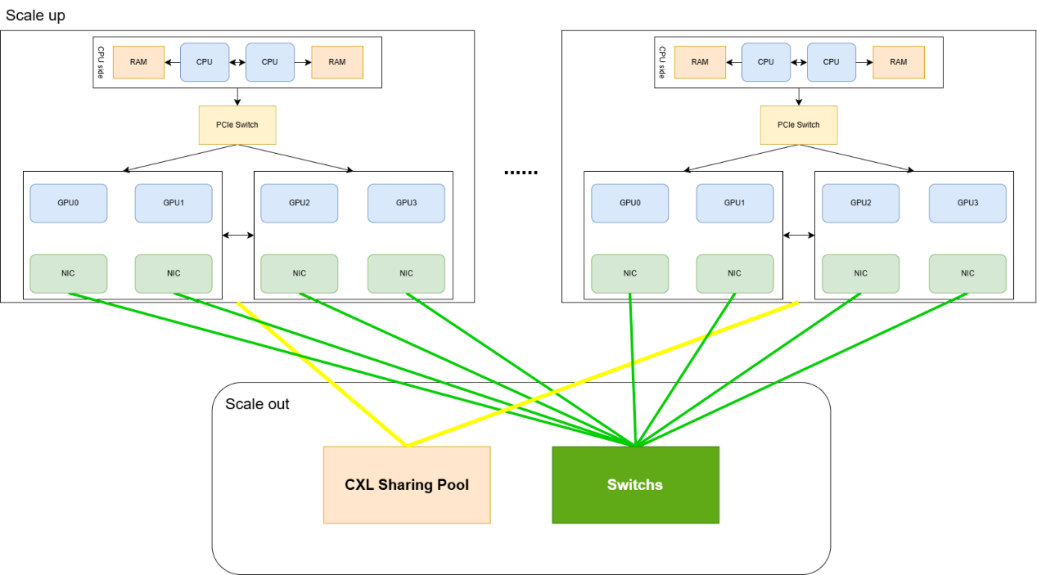
图源:H3C《超节点技术白皮书》第 235 页,图 155。
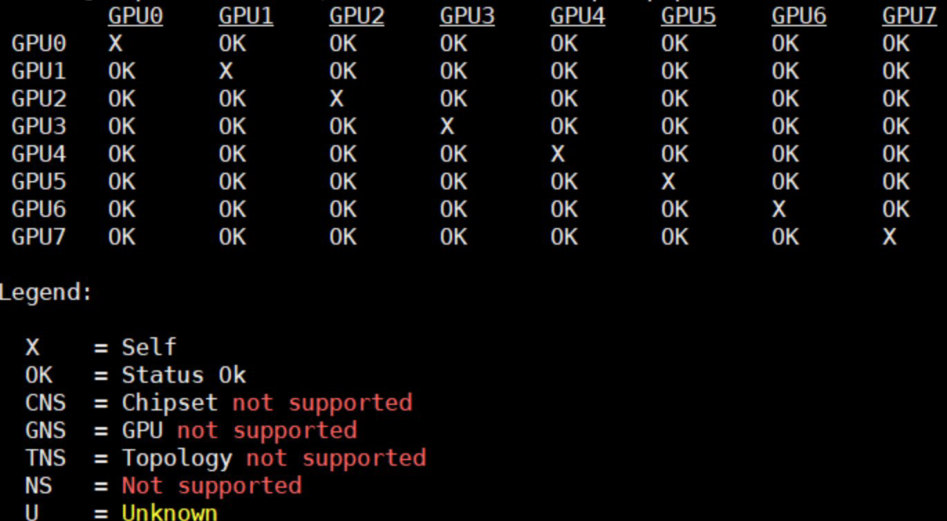
图源:H3C《超节点技术白皮书》第 242 页,图 160。
如果训练平台无法读取和使用这些拓扑信息,硬件上的高带宽域就很难被正确使用。
八、通信仿真:不是为了预测绝对值,而是找瓶颈
中兴报告中的算力仿真平台图,适合作为训练系统设计方法论。
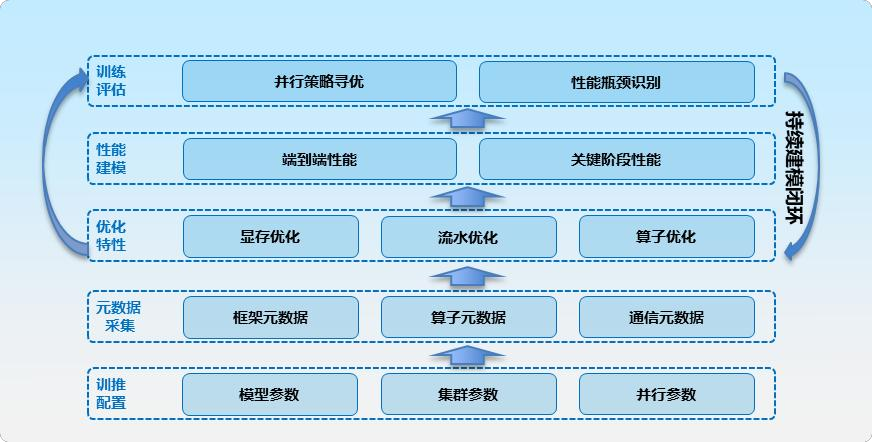
图源:中兴《超节点技术白皮书》第 32 页,图 3-1。
仿真最有价值的不是预测精确训练时间,而是回答这些问题:
- TP 组跨域后 step time 增加多少?
- EP 的 All-to-All 热点在哪些链路?
- DP 分层归约是否降低跨域压力?
- PP stage 是否存在气泡?
- 扩大 HBD 后收益是否进入边际递减?
- 通信和计算能否重叠?
这类问题决定超节点规模、拓扑和并行策略,而不是单个硬件参数。
九、工程调度清单
训练平台调度大模型任务时,可以按下面方式做约束。
| 调度对象 | 建议约束 |
|---|---|
| TP group | 强约束在同一 HBD 或低跳数拓扑内 |
| EP group | 优先同域,避免热门专家跨域 |
| PP stage | 相邻 stage 尽量拓扑临近 |
| DP group | 允许跨域,但需要分层归约策略 |
| CP/SP group | 结合序列长度和 KV/激活内存放置 |
| 通信库 | 根据拓扑选择 Ring/Tree/Hierarchical/All-to-All 实现 |
调度不是简单 bin packing。它需要把模型并行结构作为调度输入,而不是只看 GPU 数量。
十、总结
简单归纳:
- DP 关注大流量归约和分层通信。
- TP 关注层内高频低时延。
- PP 关注阶段通信和流水线气泡。
- EP 关注 All-to-All、热点和尾时延。
- CP/SP 关注长序列下通信、缓存和内存协同。
超节点的价值,就是让训练平台可以把这些通信放到合适的网络层里,而不是让所有流量都挤在同一张网络上。
核心术语表
| 术语 | 含义 |
|---|---|
DP |
数据并行,典型通信是梯度 All-Reduce。 |
TP |
张量并行,层内通信高频,对低时延敏感。 |
PP |
流水线并行,关注阶段间激活值/梯度传递和气泡。 |
EP |
专家并行,MoE 中专家跨设备放置后产生 All-to-All。 |
CP |
上下文并行,面向长序列切分上下文相关计算。 |
All-Reduce |
多设备归约并广播结果,常见于梯度同步。 |
All-to-All |
多设备互发不同数据,常见于专家分发和聚合。 |
拓扑感知调度 |
根据物理互联关系放置并行组,减少跨慢路径通信。 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)