0.1 专栏导读:为什么需要从 MM 理解 HMM
一个真实的困境
假设你是一个 GPU 计算框架的开发者。用户写了这样一段代码:
float *data = malloc(1GB);
// ... 填充数据 ...
gpu_kernel<<<grid, block>>>(data); // 希望 GPU 直接访问 data
在传统编程模型下,这不可能工作——GPU 有自己的显存(VRAM),CPU 的 malloc 返回的指针对 GPU 毫无意义。程序员必须手动管理数据搬移:
//h:host, d:device. 就是我们常说的 h2d,d2h
float *h_data = malloc(1GB); // CPU 内存
float *d_data = gpu_malloc(1GB); // GPU 显存
memcpy_to_gpu(d_data, h_data, 1GB); // 显式拷贝
gpu_kernel<<<grid, block>>>(d_data); // 用 GPU 指针
memcpy_from_gpu(h_data, d_data, 1GB); // 拷贝回来
这套"显式拷贝"模型有几个致命问题:
- 编程复杂度高 — 程序员必须手动管理两套指针和数据一致性
- 无法处理指针追踪 — 如果数据结构包含指针(链表、树),拷贝后指针全部失效
- 过度拷贝 — 无法知道 GPU 实际会访问哪些页面,只能全量拷贝
- 与系统接口不兼容 —
fork()、mmap()、信号处理等都可能修改地址空间,驱动无从得知
理想状态是:CPU 和 GPU 共享同一个虚拟地址空间,指针在两边通用,数据按需自动迁移。
这就是 HMM 要解决的问题。
什么是 HMM
HMM(Heterogeneous Memory Management) 是 Linux 内核内存管理子系统的一组扩展,它让设备(GPU、FPGA、SmartNIC 等)能够:
- 镜像进程页表 — 设备维护一份与 CPU 一致的地址映射,进程用同一个虚拟地址在 CPU 和设备间通信
- 感知页表变化 — CPU 侧的
munmap、mremap、COW 等操作会自动通知设备更新映射 - 双向迁移页面 — 页面可以在 CPU RAM 和设备内存之间按需迁移,对应用透明
- 让设备内存参与内核框架 — 设备内存拥有
struct page,可以被内核的迁移、回收等框架管理
HMM 不是一个独立的子系统,而是对现有 MM 机制的一系列精准扩展。它的代码量很小(核心仅 ~700 行),但它依赖的基础设施横跨整个 MM。
为什么必须从 MM 理解 HMM
很多开发者试图直接阅读 mm/hmm.c,然后迅速迷失——因为 HMM 的每一行代码都在调用 MM 的底层接口:
| HMM 做的事 | 依赖的 MM 基础设施 |
|---|---|
| 遍历进程页表获取物理地址 | 五级页表结构、walk_page_range() 框架 |
| 解码"页面在设备内存中" | 非驻留 PTE 编码(device private entry) |
| 保持设备映射与 CPU 一致 | MMU Notifier 序列号协议 |
| 迁移页面到设备内存 | migrate_vma*() 三阶段迁移框架 |
| 让设备内存有 struct page | ZONE_DEVICE、dev_pagemap |
| 代替设备触发缺页 | handle_mm_fault() + FAULT_FLAG_REMOTE |
如果你不理解这些基础设施,HMM 的代码就是一堆无法解读的函数调用。 反过来,如果你沿着 MM 的进化脉络学习,HMM 的每个设计决策都变得顺理成章。
MM 的进化脉络
Linux MM 并非一开始就具备管理设备内存的能力。它是随着硬件需求的变化,一步步进化而来的:
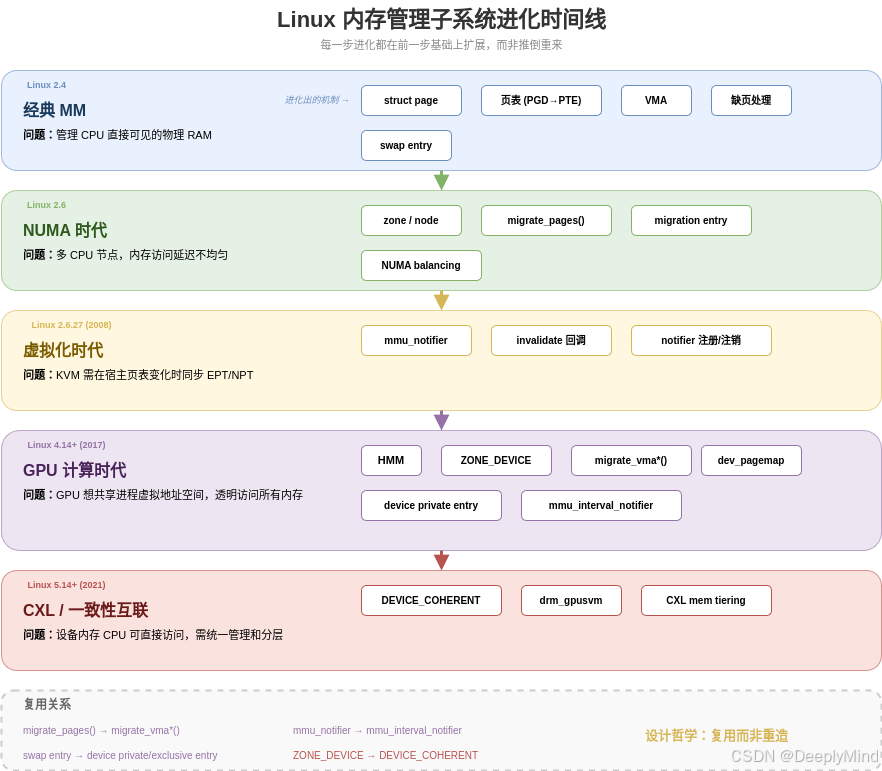
注意每一步进化都是在前一步的基础上扩展,而非推倒重来:
mmu_notifier最初是为 KVM 设计的,HMM 直接复用它来通知设备migrate_pages()最初是为 NUMA 均衡设计的,HMM 扩展出migrate_vma*()支持设备迁移swap entry编码最初只有 swap 和 migration 两种,HMM 新增了 device private/exclusive entry
HMM 的设计哲学就是"复用而非重造"。 这也是为什么理解 MM 基础是掌握 HMM 的必经之路。
硬件背景:谁在用 HMM
GPU(主要消费者)
| 厂商 | 驱动 | HMM 使用方式 |
|---|---|---|
| AMD | amdgpu / KFD | hmm_range_fault() + migrate_vma*() 实现 SVM(ROCm) |
| Intel | Xe | 通过 drm_gpusvm 框架使用 HMM |
| NVIDIA | Nouveau(开源) | nouveau_svm 使用 HMM 做 SVM |
CXL 设备
CXL(Compute Express Link)设备提供 CPU 可直接访问的扩展内存。内核用 DEVICE_COHERENT 类型的 ZONE_DEVICE 管理,未来可能成为 HMM 最大的应用场景。
其他
- FPGA — 可通过 HMM 共享进程地址空间
- SmartNIC / DPU — RDMA + 设备内存管理
- 持久化内存(PMEM) — 虽然不用 HMM,但共享 ZONE_DEVICE 基础设施
本专栏的学习路径
我们把 HMM 的知识体系分为 8 层,沿进化脉络从底向上:
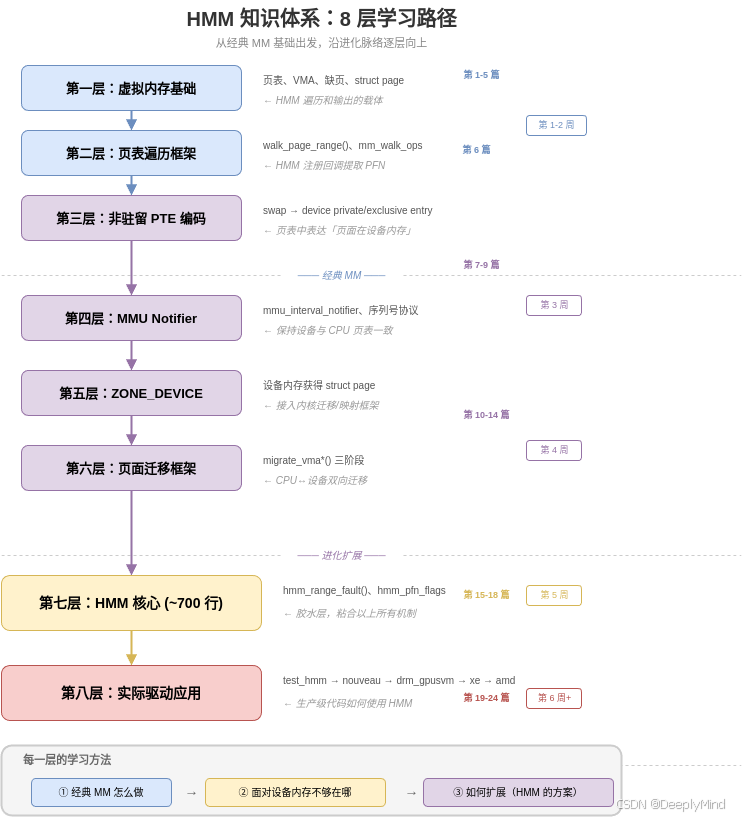
每一层我们都会:
- 讲清经典 MM 是怎么做的 — 建立基础心智模型
- 指出"不够"在哪里 — 面对设备内存时的局限
- 展示如何扩展 — 内核社区的解决方案
这样当你最终读到 mm/hmm.c 时,每一行代码都不再陌生。
前置知识
本专栏假设你具备:
- C 语言基础 — 能读懂内核代码(指针、位操作、宏)
- 操作系统概念 — 虚拟内存、页表、中断等基本概念
- 基本的内核阅读能力 — 知道如何浏览内核源码树
不需要你已经精通 MM 或 GPU 驱动——这些正是本专栏要教的。
关键源码版本
本专栏基于 Linux 6.x 内核源码。HMM 相关代码在近几年持续演进,核心文件包括:
| 文件 | 内容 |
|---|---|
mm/hmm.c |
HMM 核心实现(~700 行) |
include/linux/hmm.h |
HMM 公共 API |
mm/migrate_device.c |
设备迁移框架 |
mm/memremap.c |
ZONE_DEVICE 实现 |
lib/test_hmm.c |
HMM 测试模块(最佳学习参考) |
下篇预告
第 1 篇:虚拟地址空间与页表——每个进程的私有世界
我们将从 MM 最基础的概念开始:进程如何拥有自己的虚拟地址空间?页表如何将虚拟地址翻译为物理地址?五级页表的结构是什么样的?
这些看似"老生常谈"的基础,恰恰是 HMM hmm_range_fault() 遍历页表时的核心路径。打好这个基础,后面的一切才能事半功倍。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)