周志华-《机器学习》
第三章 线性回归
3.1 线性回归
给定数据集D={(x1,y1),……,(xn,yn)},其中xi=(xi1,……,xid)。我们用线性回归,试图做出一个线性的模型: f(xi)=ωxi+b,使得 f(xi)≃yi,进而预测输出值。显然,求这个预测式的关键在于求出ω和b。求ω和b使用的方法是我们熟悉的最小二乘法,做法如图: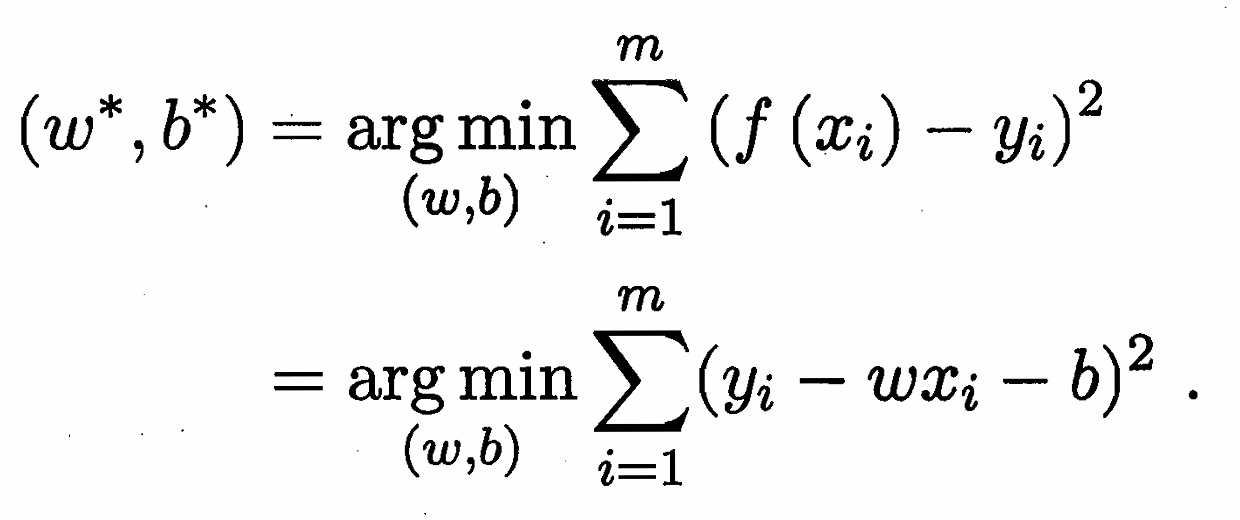
求解ω和b的过程本质上就是令E(ω,b)=i=1∑m(yi−ωxi−b)^2 最小的过程,也可通过几何意义来理解:试图找到一条使所有样本到直线上的欧式距离之和最小的过程。经数学推导后,得到ω和b的最优解公式为:
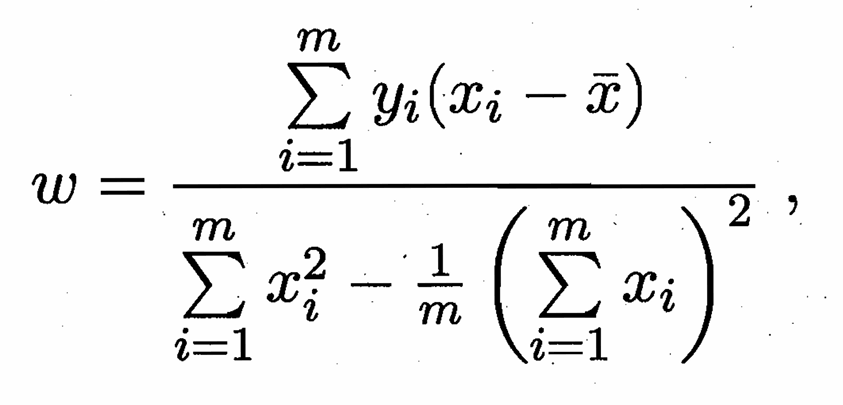
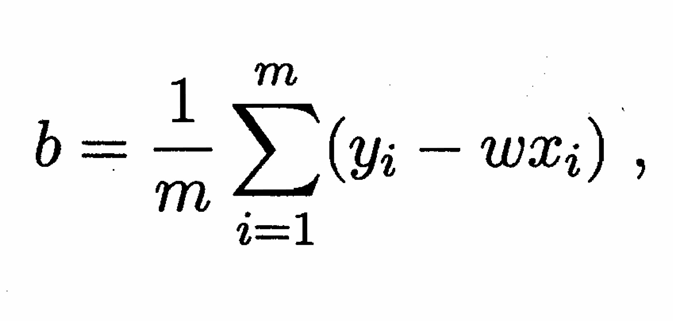
拓展:对数线性回归,即令lny=WT x +b ,本质上与上文相同,不过是令g(y)=lny,而我们可以更加以推广,得到 完全体公式:
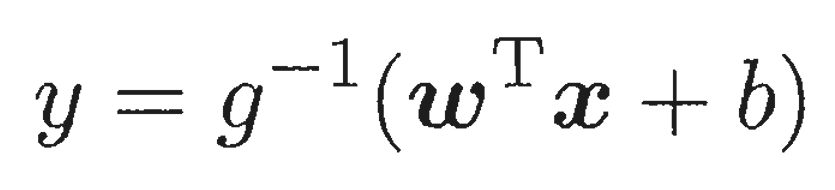
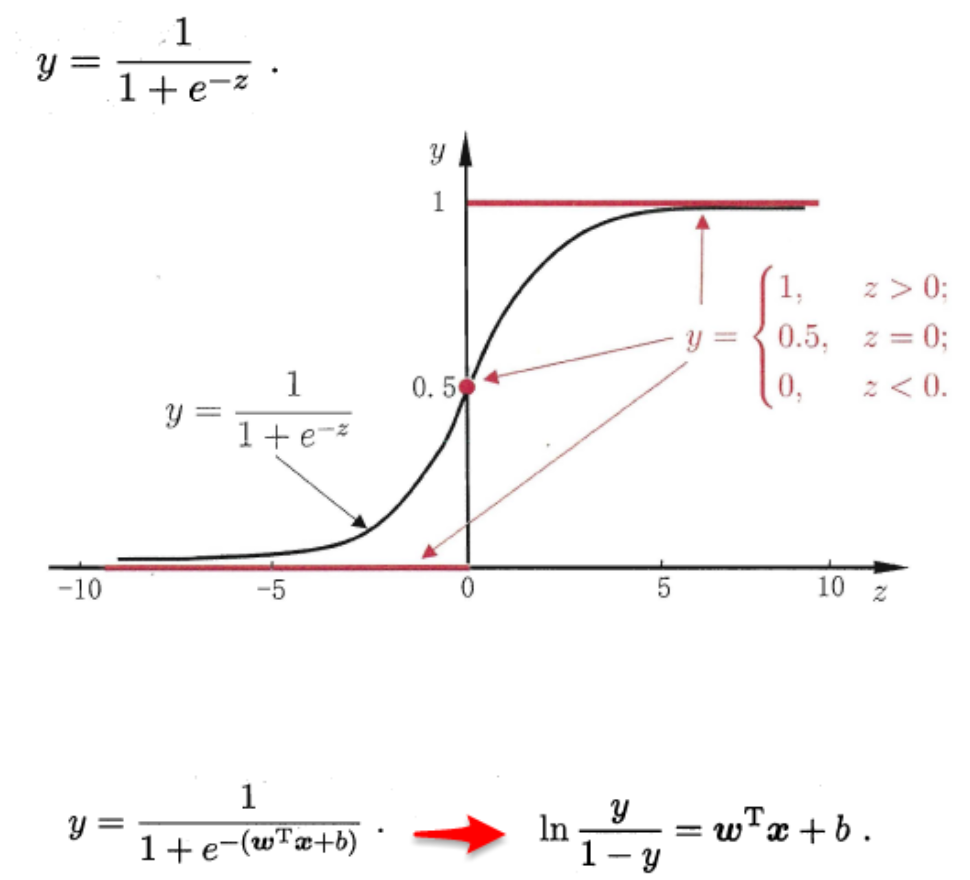
3.2 对数几率回归
在做分类任务时,常用该种方法。可类比为电路中ε(x)函数: 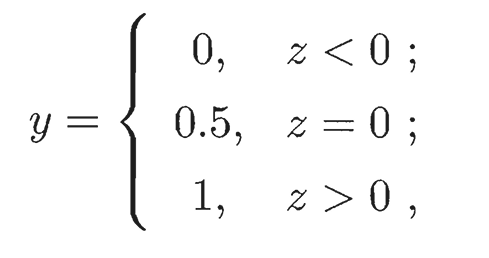
应用图:
3.3 线性判别分析
线性判别分析(LDA)是经典的线性学习方法,思想很简单:设法将给定的数据集的规律投影到一条直线上,对新的数据集进行分类时,也将其投影到该直线上,再根据投影来确定位置
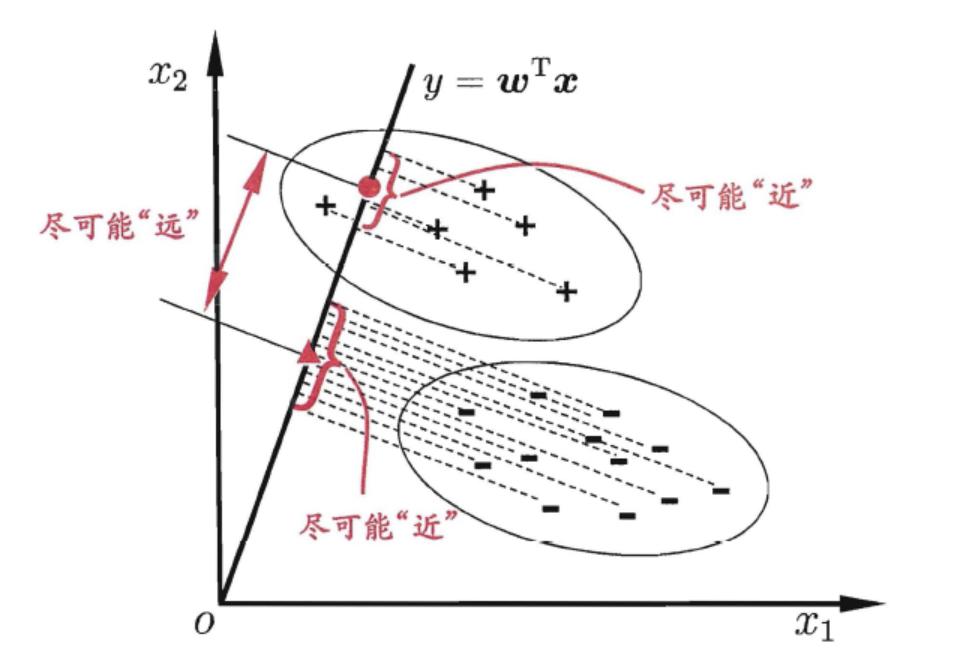
该图为LDA的二维示意图,“+”,“--”为正反例,椭圆代表外轮廓,虚线为投影,,红色实心圆和实心三角形分别表示两类样本投影后的中心点。想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵:类内散度矩阵和类间散度矩阵(二者本质上是相同的)。
类内散度矩阵:
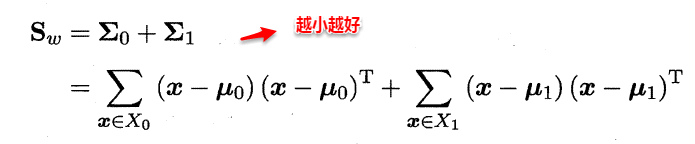
类间散度矩阵:
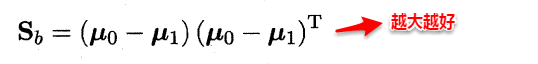
3.4 多分类学习
现实中经常会遇到不止两个分类的任务,此时我们常使用用拆分的方法,分成多个二分法来解决问题。在常见的拆分策略有三种,分别为一对一,一对余和一对多(类似于上文的机器学习分类法方式,无需赘述)
第四章 决策树
4.1基本概念-字面意思,生成的数学本质是递归过程
4.2 划分选择
4.2.1 信息增益
信息增益就是决策树选择的指标之一,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:
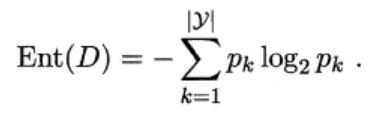
该值越大越混乱,而当只有一个类别时,该值为零。
4.2.2 增益率
增益率定义为:
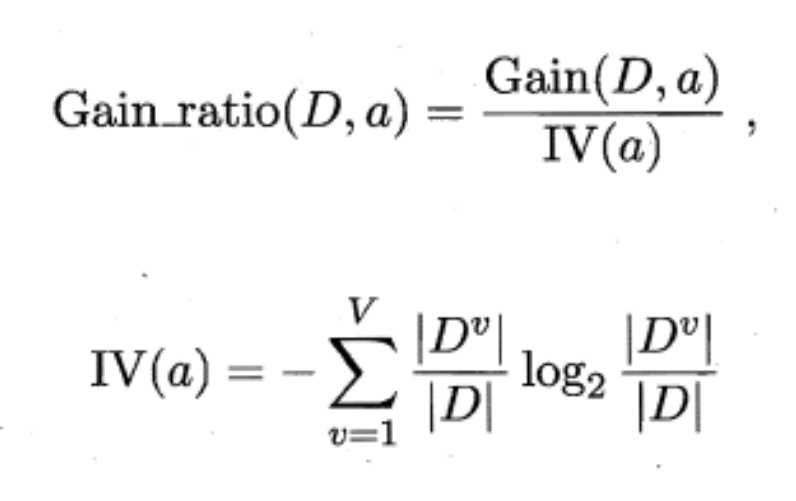
α取性越多,IV越大
4.2.3 基尼指数
CART决策树会使用基尼指数来选择划分属性,与上式类似,D的纯度也可用基尼值来测量:
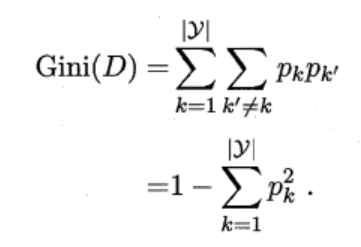
进而,使用属性α划分后的基尼指数为:
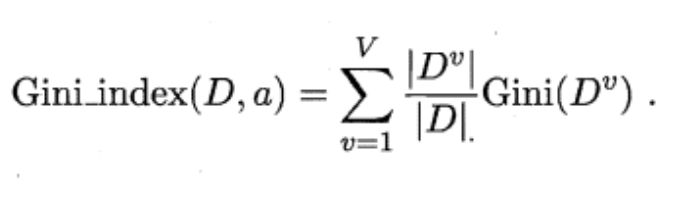
4.3 剪枝处理
是应对第一张提到的“过拟合”情况时应用的手段,可以主动去点一些分支来减少过拟合的风险。基本策略有“预剪枝”和“后剪枝”。
预剪枝:在构造的过程中先评估,再考虑是否分支。
后剪枝:在构造好一颗完整的决策树后,自底向上,评估分支的必要性。(评估就是性能度量)
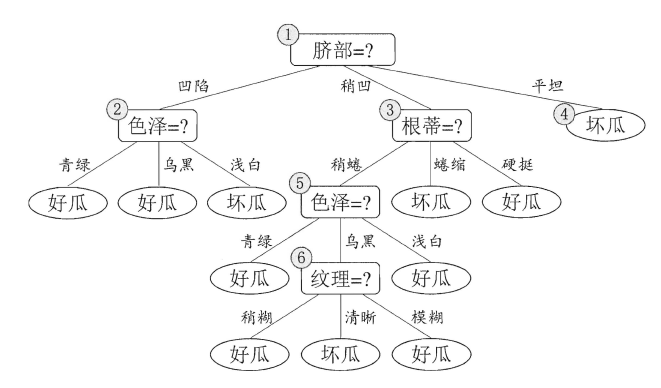
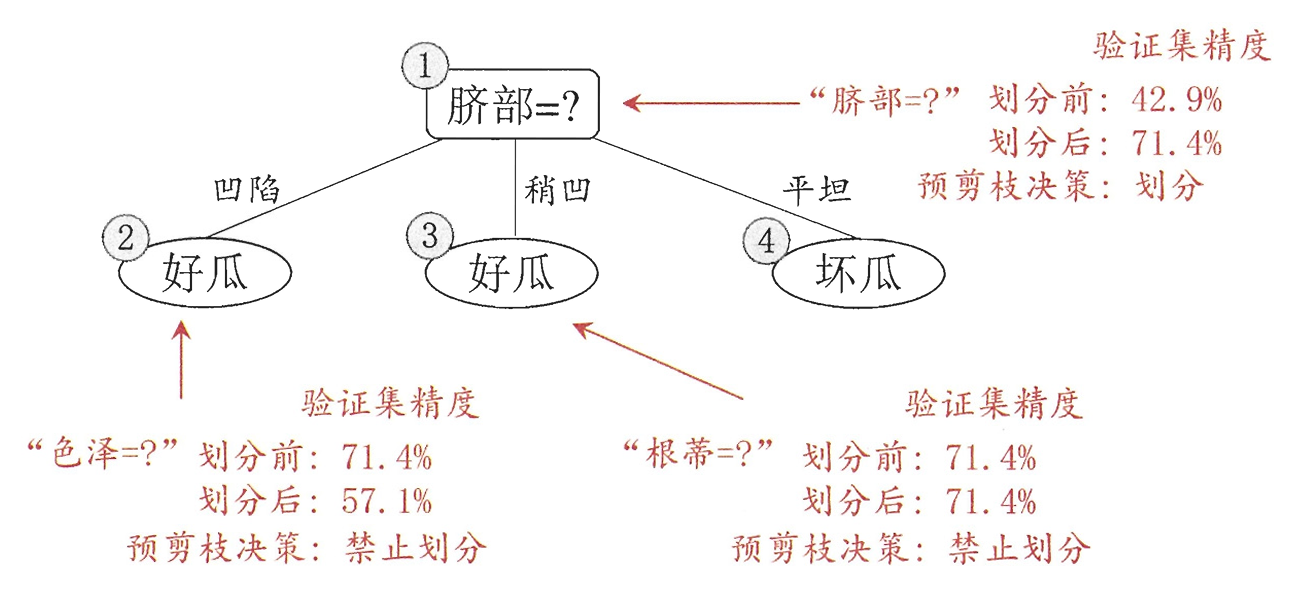
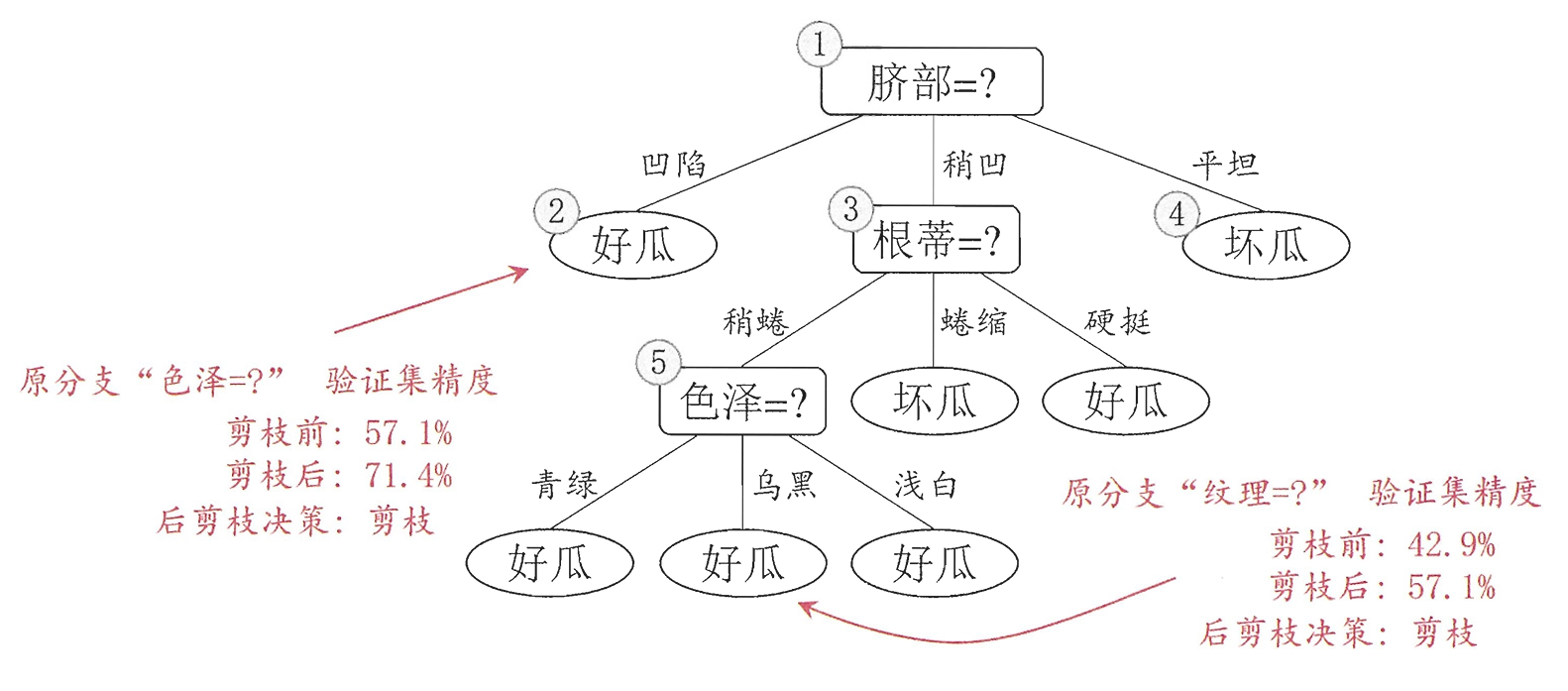
上图分别表示不剪枝处理的决策树、预剪枝决策树和后剪枝决策树。预剪枝处理大大减少了过拟合的风险,但由于剪枝同时剪掉了当前节点后续子节点的分支,因此减少了分支的展开,存在欠拟合的风险。而后剪枝则通常保留了更多的分支,因此采用后剪枝策略的决策树性能往往优于预剪枝,但由于过于详细,会提高成本。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)