解析能力是如何降低AI幻觉的?
很多开发者都遇到过这种情况:
花了好几周搭了一套 RAG 系统,或者给 Agent 接上了公司内部知识库,测试的时候看起来还不错。可一旦把真实世界的复杂文档丢进去——比如一份上百页的产品规格书,一份带多级嵌套表格的金融年报,或者是一组混排了图片、表格、参考文献的技术白皮书......AI 就开始频繁出错。它要么把第三章的数据张冠李戴到第五章,要么对表格里的数字进行“合理想象”,甚至在某些关键信息上凭空捏造出一个不存在的结论。
这种“AI幻觉”在需要严格信息溯源的场景里尤其致命。做金融分析的,模型可能把一个季度的营收填到了另一个季度;做法律合同审查的,它可能把某条款的适用条件完全搞反;做学术研究的,它甚至会给论文“创造”出几条并不存在的参考文献。
但更令人头大的是,这些错误往往不是每次都出现,有时候对,有时候错,毫无规律,防不胜防。你反复调整 Prompt、更换 Embedding 模型、试了各种分块策略,但效果总是不稳定。问题的根源,可能根本不在模型本身,而在于 AI 拿到手里的文档信息,从一开始就是破碎的。
传统的 RAG 其实藏着一个大 BUG
现在的大模型,在生成答案前,往往会先通过 RAG(检索增强生成)从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程。你可以理解为,RAG 是个捡菜工,专门服务 AI 大模型这位“大厨”。
问题是,大多数 RAG 系统处理文档的方式非常“暴力”:它会把 PDF、Word 或者网页内容提取成纯文本,然后用一个固定的窗口大小(比如500个 token)把文本切成一块块,也就是所谓的 Chunk。在这个过程中,标题层级可能被削平了,表格被拦腰截断,图和文字的关联彻底消失。每个 Chunk 都成了一座信息的孤岛,前后文、结构、归属关系全丢了。
你用这些碎片去给 AI 做检索增强,相当于把一本书撕成纸条、打乱顺序,然后让 AI 根据几个关键词去翻纸条回答问题。AI 只能看到自己眼前那几段被关键词命中的碎片文本,它不知道这段话是哪一章哪一节的内容,也不知道这串数字属于哪个表格的哪一列。为了避免说“我不知道”,它就开始用语言模型的概率能力去“脑补”,幻觉就这样产生了。
不一定是 AI 不聪明,可能它在替“脏数据”背锅
这就是今天想给大家讲的一个开源项目——Knowhere(GitHub: Ontos-ai/knowhere)。它做的事非常明确:把你手上那些复杂的真实文档,处理成 AI 能够真正理解、检索和溯源的结构化记忆。它不是又一个文档解析工具,而是一个专为 AI Agent 和 RAG 系统设计的文档记忆基础设施。

Knowhere 能做什么?
简单来说,它能把 PDF、Word、PPT、Excel 表格等非结构化文档,自动转化为一份带有层级目录、表格定位、图片关联和跨文档关系的“知识地图”。然后,AI 就可以像人一样沿着这份地图去查找信息,而不是在碎片里瞎摸。
它可以显著提升这几类场景的体验:
-
如果你在做面向企业的智能问答或知识库,Knowhere 能让 AI 给出的答案更准确、更可追溯,每一条结论都能定位回原文的具体位置。
-
如果你在做金融、法律、医疗等垂直领域的 Agent 应用,Knowhere 可以保留多级复杂表格和图表的结构,不再让关键数据被“切碎”。
-
如果你在管理大量学术文献或技术文档,它可以在不同文档之间建立关联图谱,让 Agent 做跨文档推理时更可靠。
那么,Knowhere 和市面上已有的那些文档解析方案相比,到底强多少?
根据项目公开的测评数据,以 RAG 中常见的 Agent 问答任务为测试场景,当直接给 Agent 提供原始文档,或者使用某些主流解析器生成的 markdown/json 文件时,Agent 的最终回答准确率大约在 53% 左右。
但使用 Knowhere 处理过的文档记忆后,准确率提升到了 79%。同时,Agent 的首次搜索准确率相对原始文档提升了 36%,召回率提升了 10%。而且,因为 Agent 不再需要反复在大量碎片中无效检索,Token 消耗和搜索时间都有明显下降。
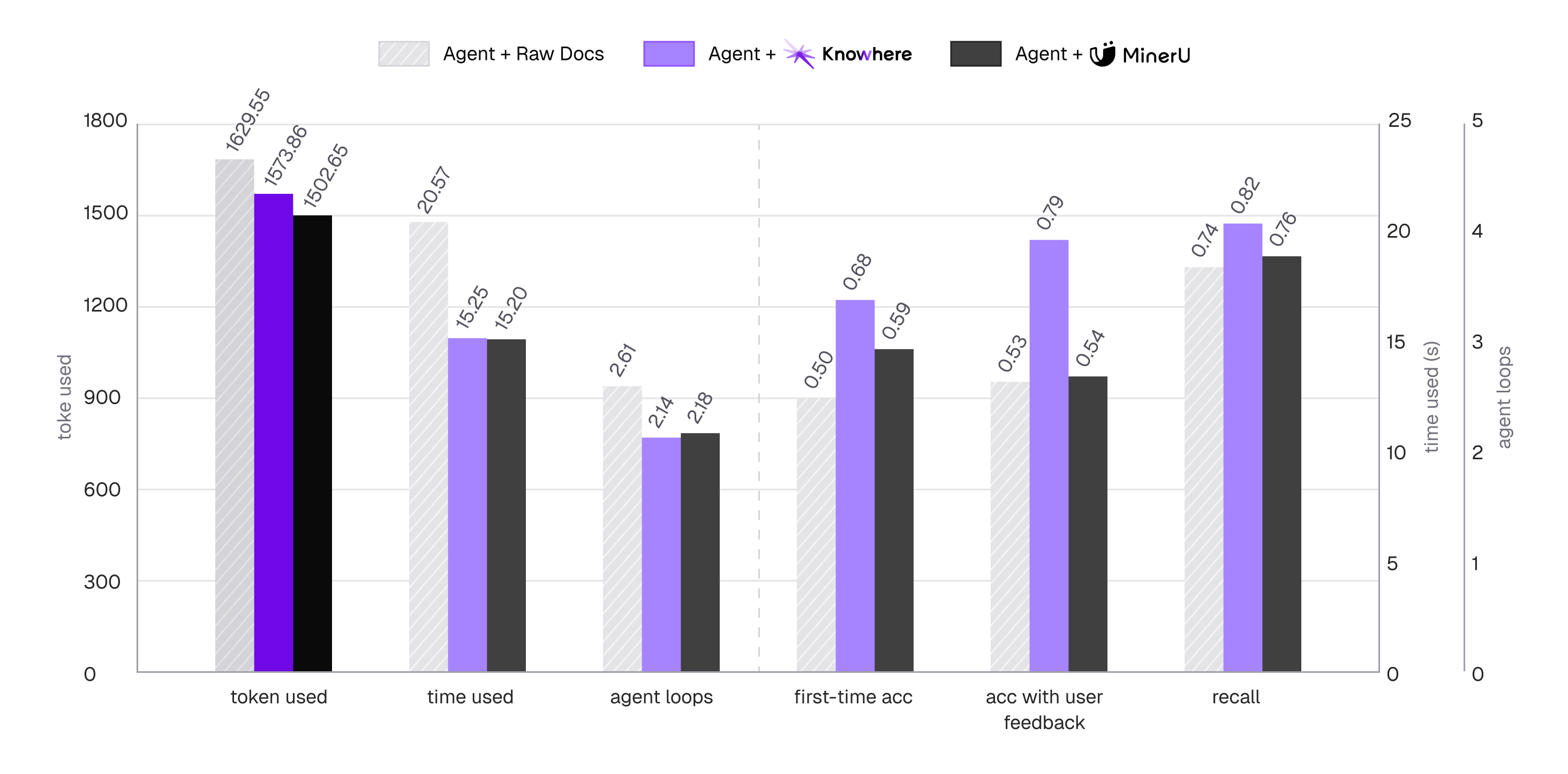
这说明,高质量的结构化输入,比一味调大模型参数更管用啊。
Knowhere 是怎么做到的?
这就得说说它的内核设计。它没有继续走“一刀切分块”的老路,而是采用了一种能够保留文档层级结构的树状记忆构建方式。它的工作流程可以拆成三步:
第一步,解析。Knowhere 接入了一些高质量的解析器来读取 PDF、PPT、图片、表格等格式,先拿到一个相对干净的文本初稿。
第二步,结构化。这是 Knowhere 真正发力的地方。它会去修复解析过程中可能出现的结构损伤,重建文档的标题树——从一级标题到二级、三级,每一块文本都会被精确挂载到对应的章节路径上。表格和图片不是被简单抽离出来当作独立附件,而是和内联的上下文文本牢牢绑定,确保 AI 能看到“这张表格是属于哪一段话”的完整关系。
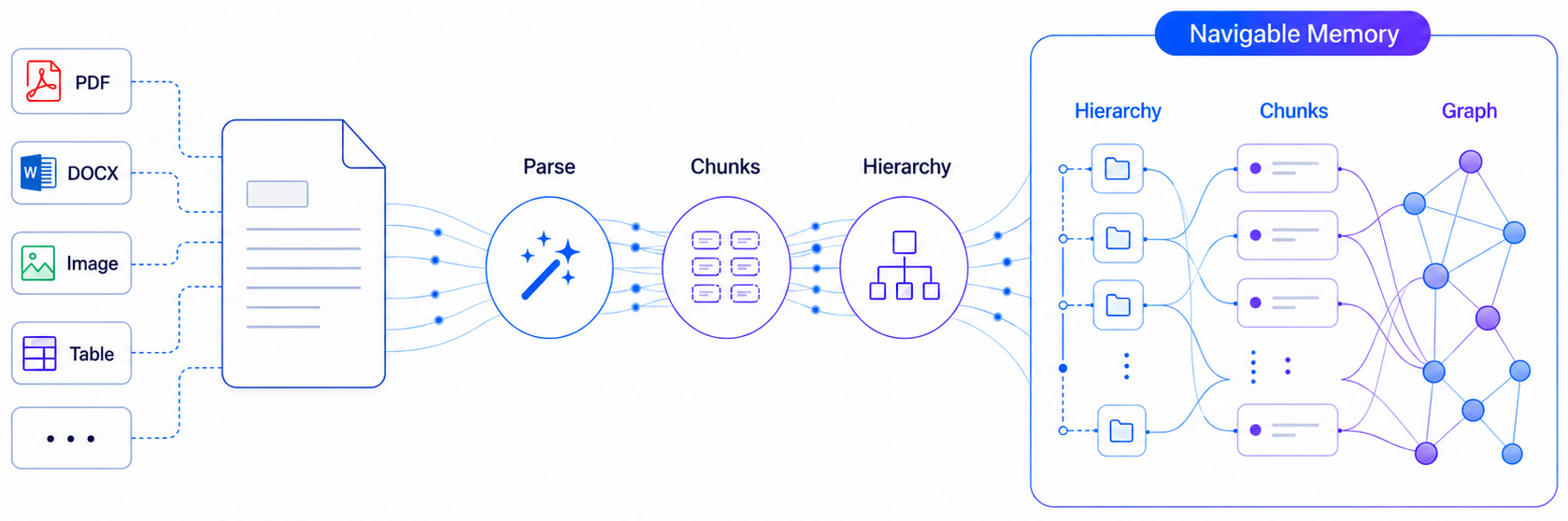
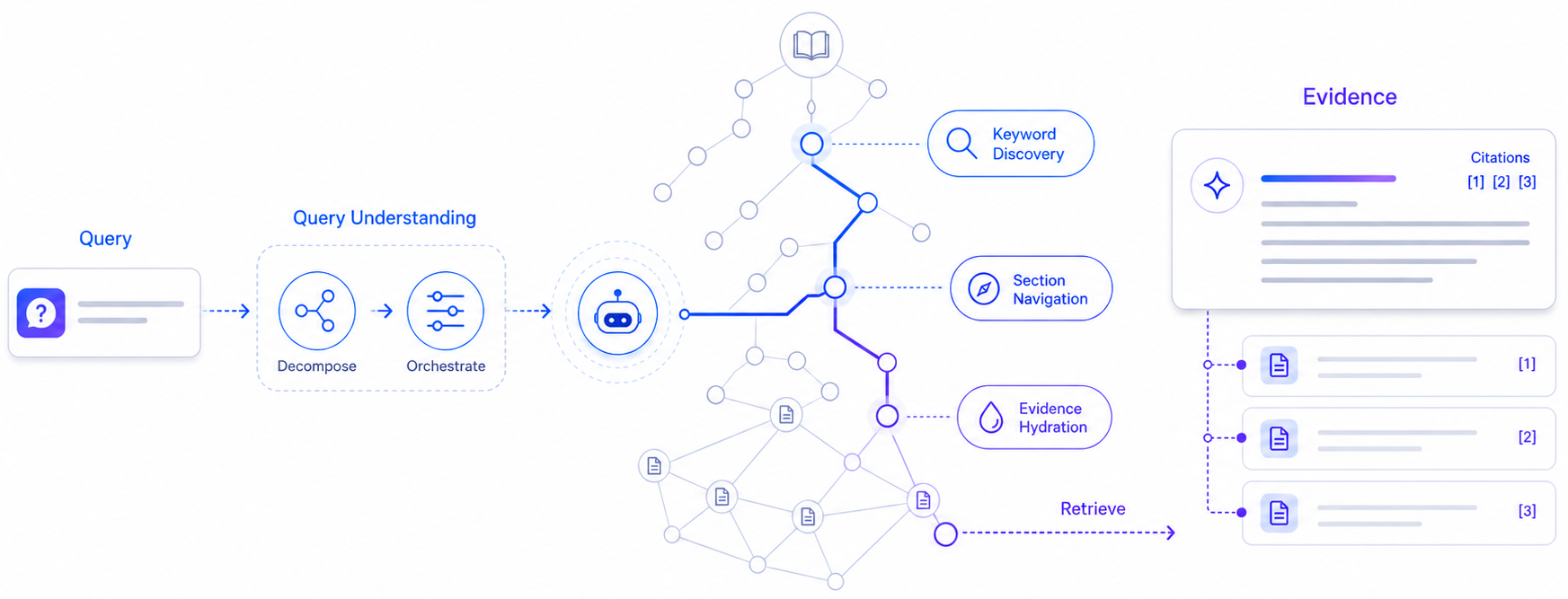
第三步,构建记忆。经过结构化之后,Knowhere 并没有把这些信息直接当作文本丢给 RAG 系统,而是构建了一个包含章节树、文本块、摘要、图像描述以及跨文档链接的轻量级记忆图谱。这个图谱就像是给 AI 配了一本带有详细目录、索引和超链接的电子书,AI 检索时可以在图谱里沿着路径上下左右导航,精准定位到最相关的证据区域,而不是仅仅依靠向量相似度去猜测。
现已开源,欢迎体验
总的来说,Knowhere 并不是要取代 MinerU 这类专注于“把文档变成文本”的工具,而是想要在此基础上,解决从“文本”到“AI 可用的记忆”这最后一公里。它真正提供的价值在于同步进行的修复、重组和知识图谱构建——这恰恰是目前市面上其他方案普遍缺失的环节。
最后,对于想要上手体验的小伙伴,Knowhere 现已在 GitHub 上开源,地址是 Ontos-ai/knowhere,支持 Docker 一键部署。
也可以直接访问官网试用:https://knowhereto.ai
当下 AI 应用正在从“能对话”走向“能干活”,而让 AI 真正能干活的前提,是它真正能读懂你、理解你。Knowhere 不是什么颠覆性的黑科技,但它解决了 RAG 和 Agent 落地过程中一个非常扎实的痛点:让文档从人类的阅读物,变成 AI 的记忆。如果你也在被 AI 的幻觉和检索效果折磨,或许可以试试从改善文档的解析开始。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)