为什么我的 DPDK 程序偶尔卡死?一次排查让我彻底理解 lockless ring
我前几年做DPDK多核开发时,基本都会使用:DPDK Ring 来做线程间通信。
因为它:
- 高性能
- 无锁
- cache-friendly
- 支持多生产者多消费者
所以几乎所有 DPDK 项目都会用。
但我曾经遇到一个非常诡异的问题:程序整体运行正常,但偶尔会突然:
- 不再转发
- PPS 归零
- CPU 却仍然 100%
- 线程没有退出
- 没有崩溃日志
看起来像:程序“卡死”了。
更奇怪的是:重启后又恢复正常。
第一次遇到时,我甚至怀疑:
- 网卡故障
- NUMA 问题
- mbuf 泄漏
- rte_eth_rx_burst 卡死
最后排查数天,真正的问题竟然是:lockless ring 使用错误。
而这个问题,也让我真正理解了 DPDK 无锁队列背后的底层原理。
一、问题现场
程序架构:
RX 核
负责收包:
NIC -> RX coreworker 核
负责业务处理。
TX 核
负责发包。
线程之间通过:
rte_ring传递 mbuf。
二、现象非常奇怪
运行数小时后:突然:PPS降为0。
但:top -H 显示:CPU 100%
说明:线程没停。
三、第一反应:是不是死锁
因为:“卡住 + CPU 高” 很像锁竞争。
于是检查:
- pthread mutex
- spinlock
- rwlock
结果:根本没锁。
因为整个系统使用:lockless design
四、进一步观察
打印 ring 状态:
rte_ring_count()发现:某个 ring 长期满:
1024/1024而另一个:
0/1024说明:数据流停滞。
五、什么是 rte_ring
这是 DPDK 最核心的数据结构之一。
本质:环形队列。
结构类似:
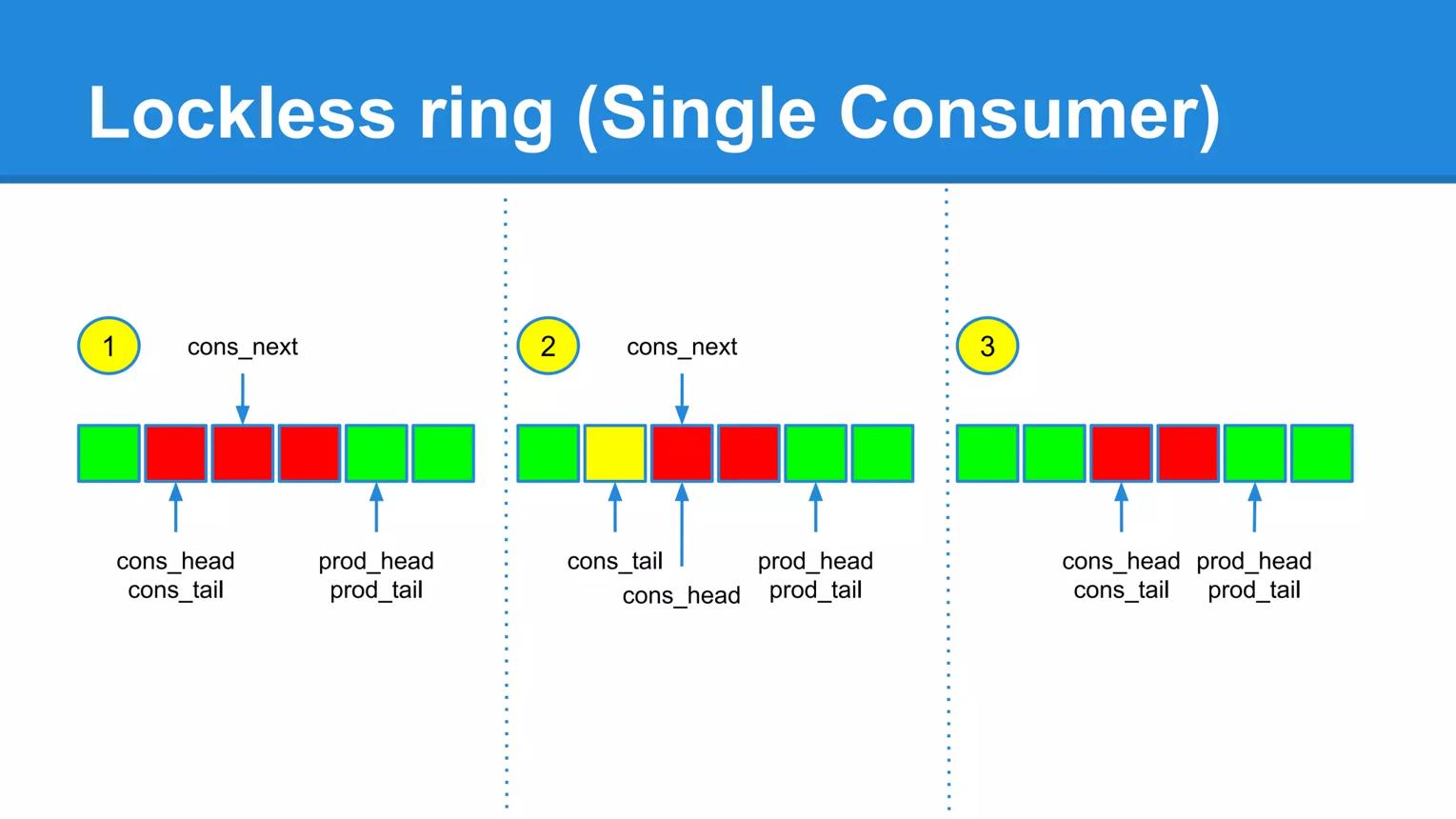
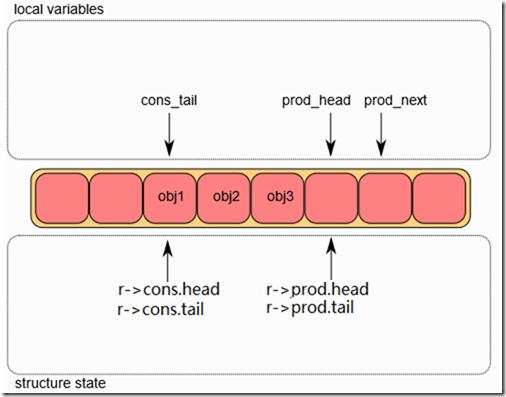
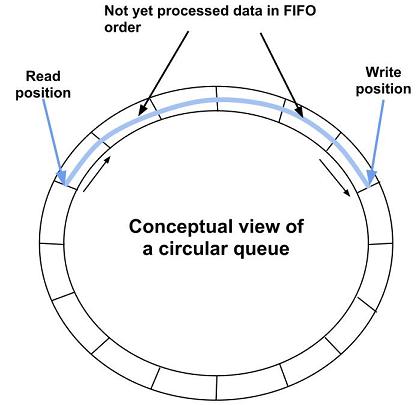
通过:
- head
- tail
管理读写位置。
六、为什么它性能高
因为:它避免了传统锁。
不使用:mutex
而使用:CAS(Compare-And-Swap)原子操作。
七、CAS 是什么
CPU 提供的一种原子指令。
逻辑:
if (*ptr == old)
*ptr = new整个过程不可中断。
八、为什么 lockless 不等于“不会出问题”
很多人误解:无锁 = 安全。
其实:无锁只是:避免传统锁竞争。
并不意味着:不会出现逻辑阻塞。
九、真正问题:producer 比 consumer 快
现场情况:RX core 持续 enqueue:
rte_ring_enqueue()worker 处理较慢。
结果:ring 被写满。
十、ring 满之后会怎样
默认:
rte_ring_enqueue()失败。
返回:
-ENOBUFS但当时代码:根本没检查返回值。
十一、致命错误出现了
代码:
rte_ring_enqueue(ring, pkt);没有:
if (ret < 0)处理。
于是:mbuf 丢失。
更严重的是:后续状态混乱。
十二、为什么 CPU 仍然 100%
因为线程仍在:
while (1)轮询。
即:busy loop。没有睡眠。
所以:CPU 满载。
但实际上:没有有效工作。
十三、进一步理解 ring 模式
DPDK ring 支持:
单生产者
多生产者
单消费者
多消费者
不同模式:性能差异非常大。
十四、另一个隐藏问题:模式配置错误
当时代码:
RING_F_SP_ENQ即:单生产者模式。
但实际上:有两个 RX core 同时 enqueue。
十五、后果
两个 core 同时更新:
prod_head
prod_tail但 ring 没有 MP 同步保护。
结果:队列状态损坏。
十六、这就是为什么问题“偶发”
因为:竞争窗口很小。
低负载时:可能永远不触发。
高并发时:偶尔踩中。
于是:ring corrupted。
十七、如何确认
使用:
rte_ring_dump()发现:
head/tail 异常与实际 count 不一致。
十八、一个关键知识:memory barrier
无锁队列最核心的难点:并不是 CAS。
而是:内存可见性。
CPU 可能:乱序执行。
十九、为什么 DPDK 要大量使用 barrier
例如:
rte_smp_wmb()
rte_smp_rmb()保证:不同核看到一致顺序。
否则:一个核可能看到:
tail 已更新但数据实际还没写完。
二十、为什么 lockless 很难写
因为:问题往往:
不稳定
难复现
高并发才触发
无崩溃日志
所以比普通 bug 更难排查。
二十一、最终修复
做了三件事。
1. 正确配置 ring 模式
多生产者:
RING_F_MP_HTS_ENQ2. 检查 enqueue 返回值
例如:
if (unlikely(ret < 0)) {
rte_pktmbuf_free(m);
}3. 增加 backpressure
当 ring 接近满:RX 降速。避免无限堆积。
二十二、优化后结果
修复前:
偶发卡死
PPS=0修复后:
稳定运行数天无异常。
二十三、这次排查真正学到什么
以前我以为:无锁队列只是:“更快的 queue”。
后来才意识到:它本质上是:多核内存一致性系统。
涉及:
- cache coherence
- memory ordering
- atomic operation
- false sharing
这些底层问题。
二十四、为什么 DPDK 能做到高性能
因为它:
- 避免系统调用
- 避免内核调度
- 避免传统锁
- 避免中断
全部走:用户态 lockless pipeline。
二十五、总结
为什么 DPDK 程序偶尔卡死?
很多时候不是:
- 死锁
- 网卡异常
- CPU 不够
而是:lockless ring 使用错误。
包括:
常见原因
1. ring 模式错误
2. enqueue 返回值未检查
3. producer/consumer 失衡
4. memory ordering 问题
5. ring 满导致流水线阻塞
这也是高性能网络开发最难的一点:
真正复杂的部分,不是 API。
而是:多核并发模型本身。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 34
34 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)