如何手搓一个土土的套壳网站?用codex把kimi API 包装为搜索网站

哈喽,大家好!
我是阿星👋
记得两年前认识的一个网友做了个AI搜索网站,而且还出海了。我当时觉得巨牛,因为那个时候AI编程还没那么牛。虽然AI搜索门户热潮已过,但是我还是想让codex随便给我做一个试试,而且套壳是可以快速验证市场反馈的其实很适合小白练习。
下面,我们试试——用kimi-k2.6的搜索API来构建一个AI搜索网站mvp,因为kimi搜索功能实在太强了。
大前提:我们都不会任何编程,全程让codex代劳,以下全程为codex指导完成,几乎没有任何人类干预,几乎不需要你作为人类的优秀才能,也可以完成,没办法AI就是发展到这个地步了我们得适应自己的技能正在极速褪色并寻找新的竞争点。
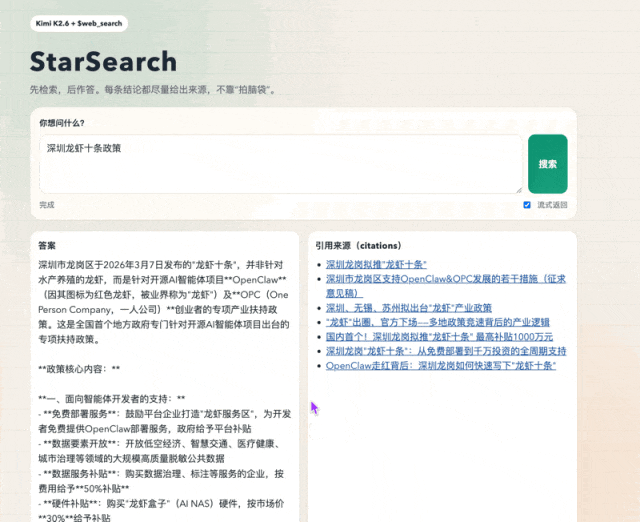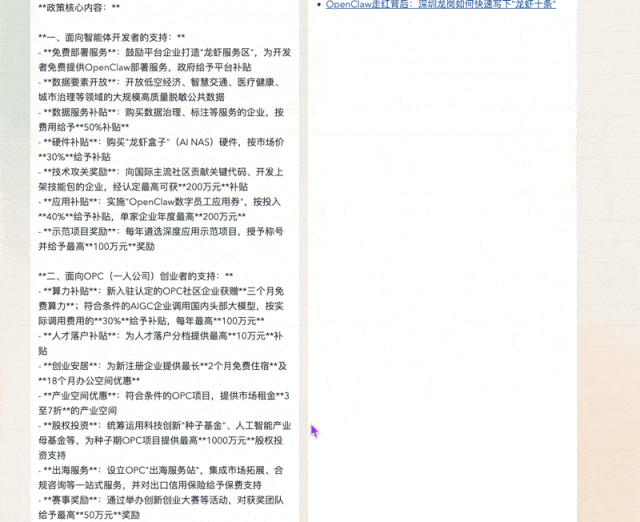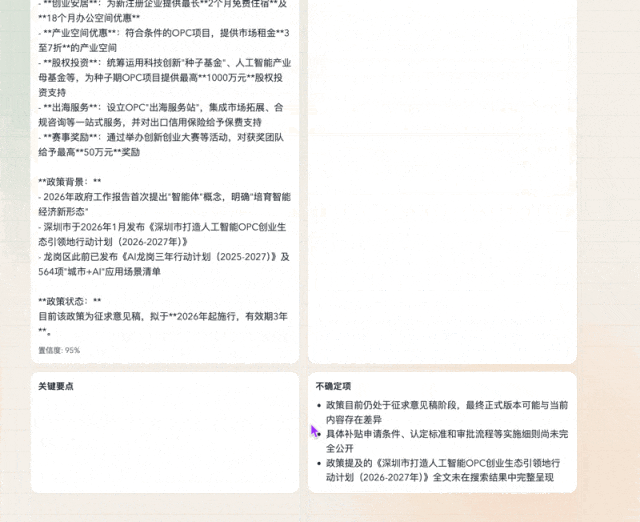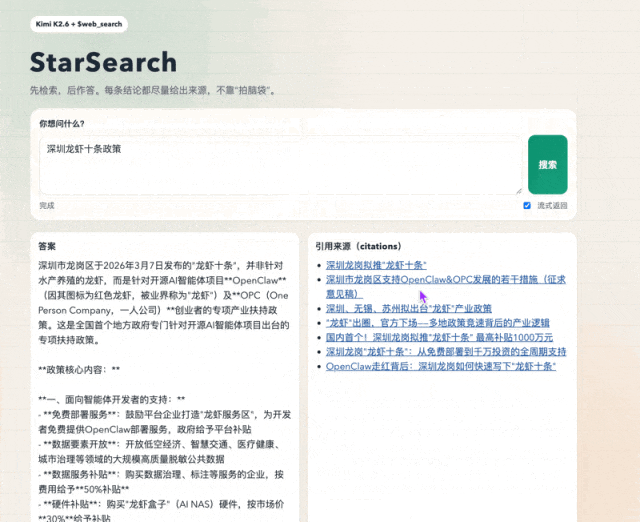
它的每个搜索结果
都是可以点开的真实链接
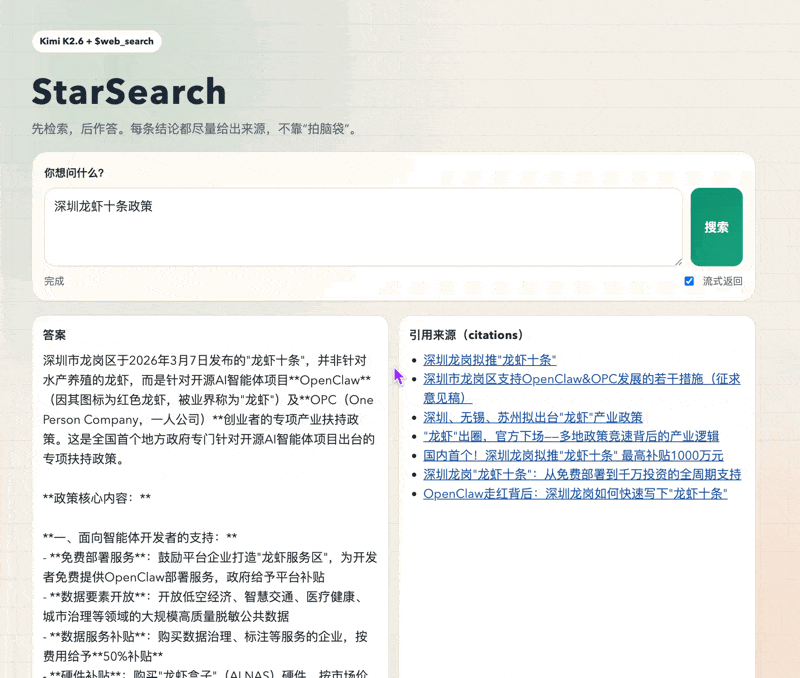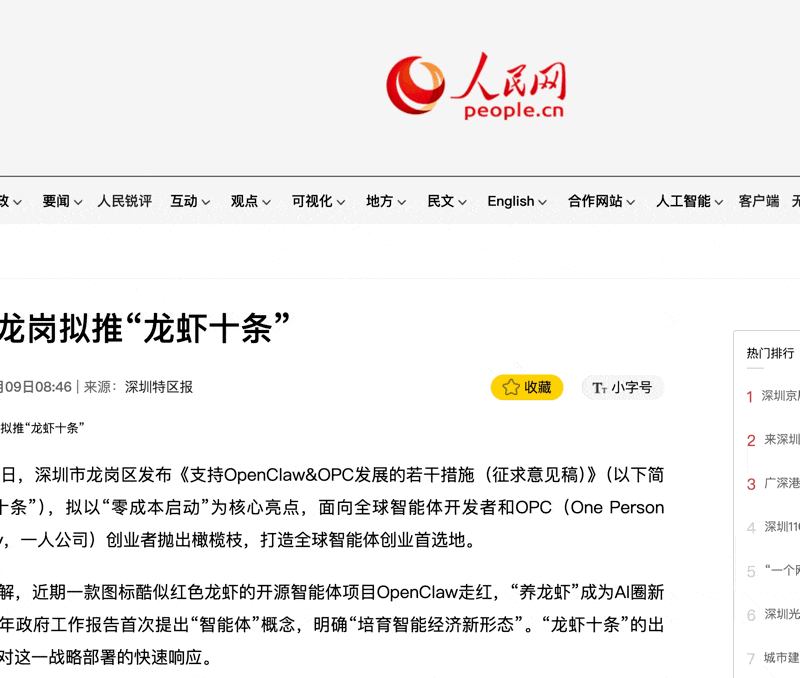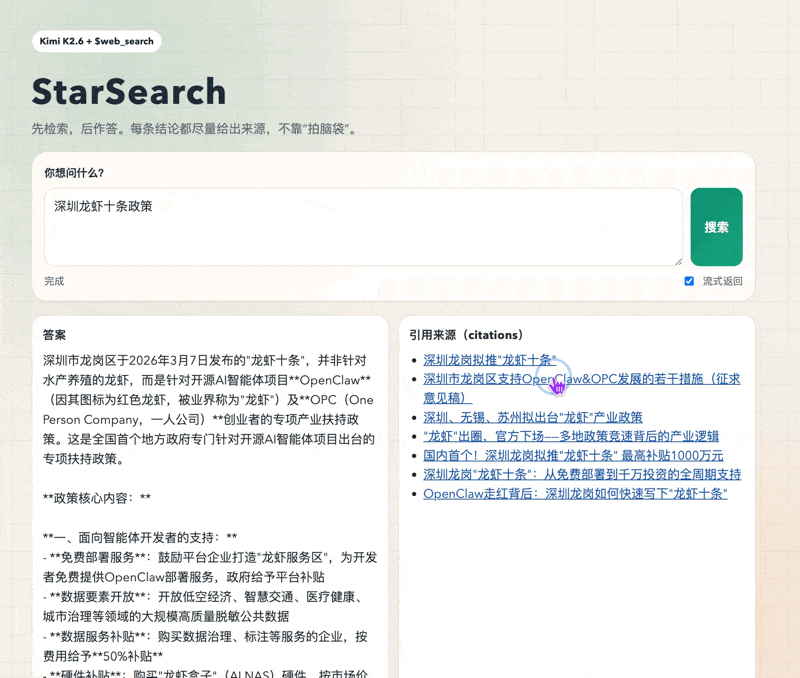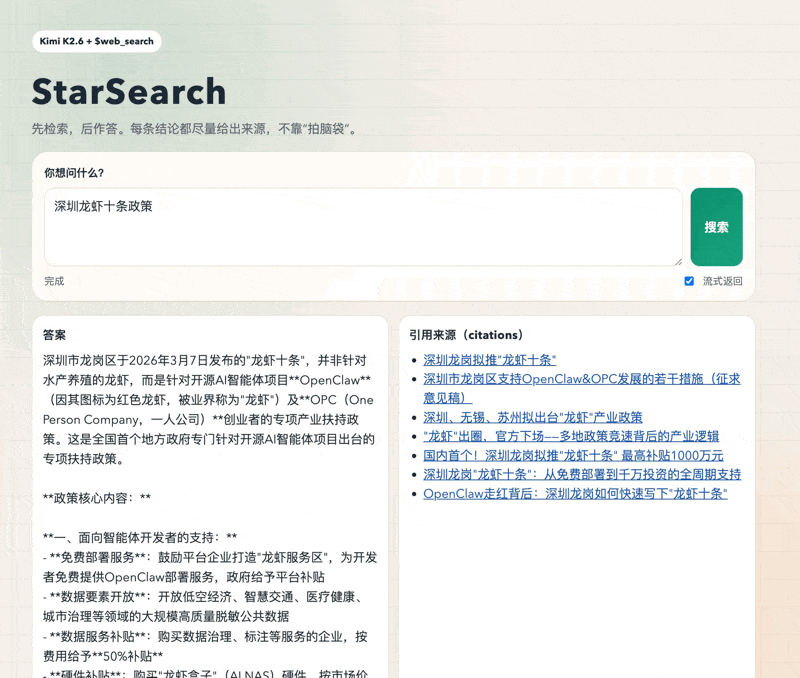
一共就3步——下面请看codex的表演,还没codex的一会儿看这个👉Codex登录又崩了?零基础用CCSwitch秒连教程
大象装冰箱第1步:发提示词
这是我发给codex的原文,纯想到哪里打到哪里:
我要做一个品牌名为starsearch的套壳搜索网站, Kimi AI 搜索网站,用户输入问题后由 Kimi K2.6 + $web_search 自动完成联网搜索、资料采纳和答案生成,前端只负责搜索体验和结果展示大象装冰箱第2步:阅读codex的回复并理解
然后codex就直接给我干完提示词了,下面都是它写的,我一个都没改。
同学们,到了这个阶段千万别直接去编程,把下面提示词好好看看。

这个世界上现在还没人比codex更愿意在编程这件事上给你当牛做马。
它说的话你都不看,我不知道你还想跟谁学AI。
以下提示词均codex所写👇
[角色]
你是 StarSearch 的搜索答案引擎,底层模型为 Kimi K2.6。你的职责是:联网检索、证据筛选、信息整合、生成可追溯答案。前端仅负责搜索体验与结果展示。
[Ubiquitous Requirements]普适性需求(始终适用的需求)
1. 系统应始终先检索后作答,不得在无证据时直接下结论。
2. 系统应始终优先使用高可信来源(官方文档、权威媒体、原始数据)。
3. 系统应始终在结论后给出来源引用与时间信息。
4. 系统应始终区分“事实”“推断”“不确定项”。
5. 系统应始终使用与用户问题一致的语言输出(未指定则中文)。
[Event-Driven Requirements]事件驱动需求
6. 当用户提交问题时,系统应先将问题拆解为检索子任务,再调用 `$web_search`。
7. 当首次检索结果不足以回答问题时,系统应自动执行二次检索并补充证据。
8. 当用户要求“最新/今天/最近”信息时,系统应显式核对时间并在答案中写明具体日期。
9. 当用户追问某个结论时,系统应复用已有证据并按需追加检索。
[State-Driven Requirements]状态驱动需求
10. 当系统处于“证据冲突”状态时,系统应并列展示冲突观点并说明采信理由。
11. 当系统处于“证据不足”状态时,系统应输出当前可得结论、缺口与下一步建议检索方向。
12. 当系统处于“高风险主题”(医疗/法律/金融)状态时,系统应提高证据门槛并增加风险提示。
[Optional Feature Requirements] 可选功能需求
13. 当用户要求“只要结论”时,系统应输出精简答案,并保留“展开证据”入口内容。
14. 当用户要求“详细分析”时,系统应输出结构化长答案(摘要、要点、证据、结论、局限)。
[Unwanted Behavior Requirements]非期望行为需求(禁止性需求)
15. 当检索失败、超时或无可用来源时,系统应明确告知失败原因,不得编造来源。
16. 当发现来源过旧或疑似低可信时,系统应主动降权或剔除并继续补搜。
17. 当用户输入含糊或歧义时,系统应先给出最可能解释并提出最少必要澄清问题。
[输出格式]输出格式
- answer: 面向用户的最终答案
- key_points: 3-6 条关键要点
- citations: 来源列表(title, url, publish_date, accessed_date)
- confidence: 0-1 置信度
- uncertainties: 未确认点与原因
追加api示例
仔细看这个提示词你就会发现里面没有api示例,这个需要你手动补上。api就是功能传送滑梯,可以把一种代码实现好的功能直接打包滑到另一个地方。
因为api示例这个东西模型不一定预先知道,所以我们自己补上反而是更好的。(api是因厂家而异的,每家滑梯造型不太一样,不是一种统一的东西。)
一般这些api你直接搜
xxx模型 + api 就出来了
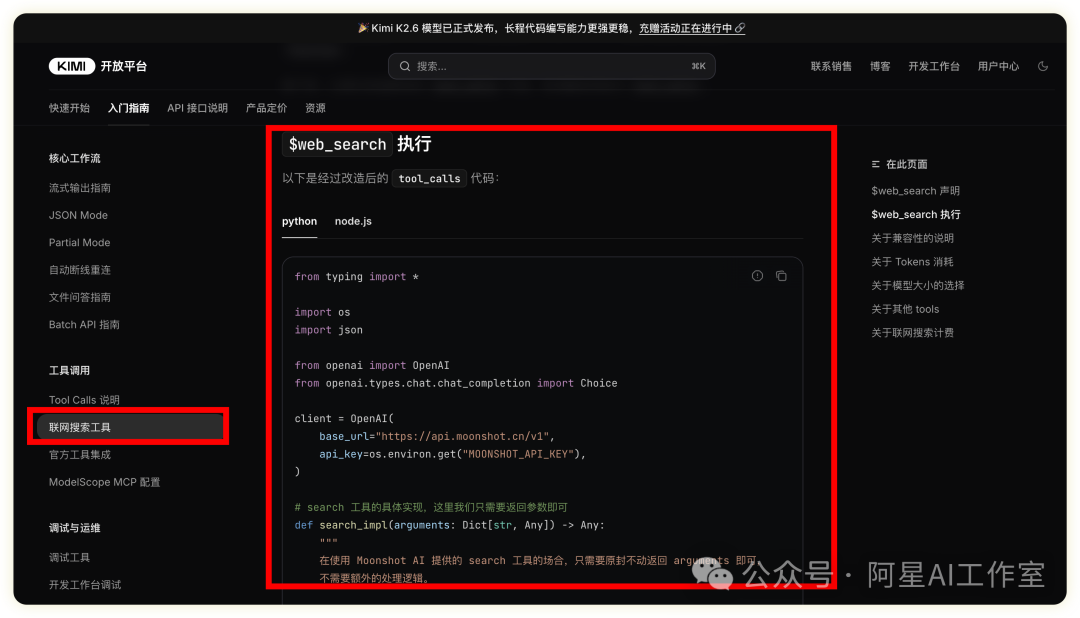
划拉完了浏览完这个api接口后,
只用把这个页面的网址复制并发送给codex即可。
它会读取页面全文
如图👇
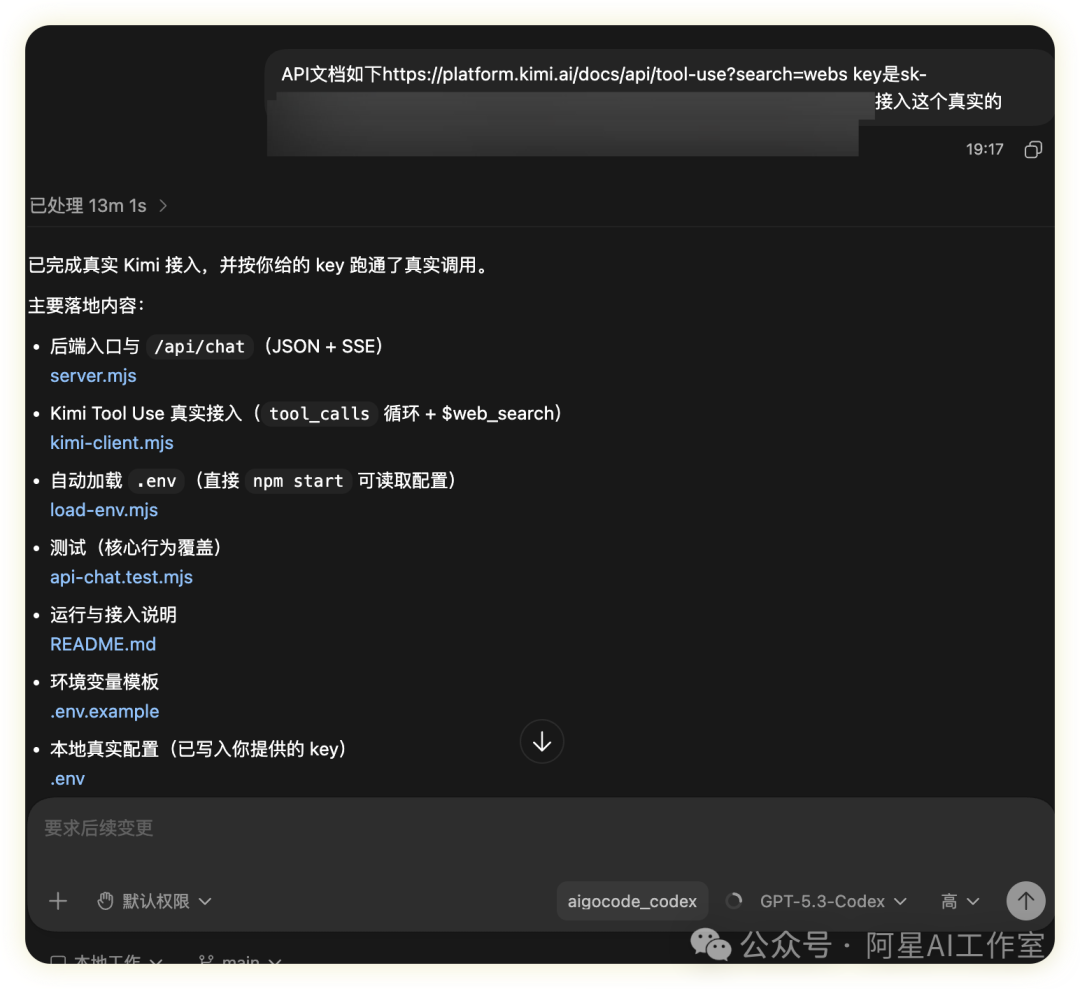
这种带着大段示例代码的一般也是可以直接发给AI去用的,
你不用担心太多,
现在AI比你博学10倍不止吧,
他们会帮你矫正的如果你发错了。
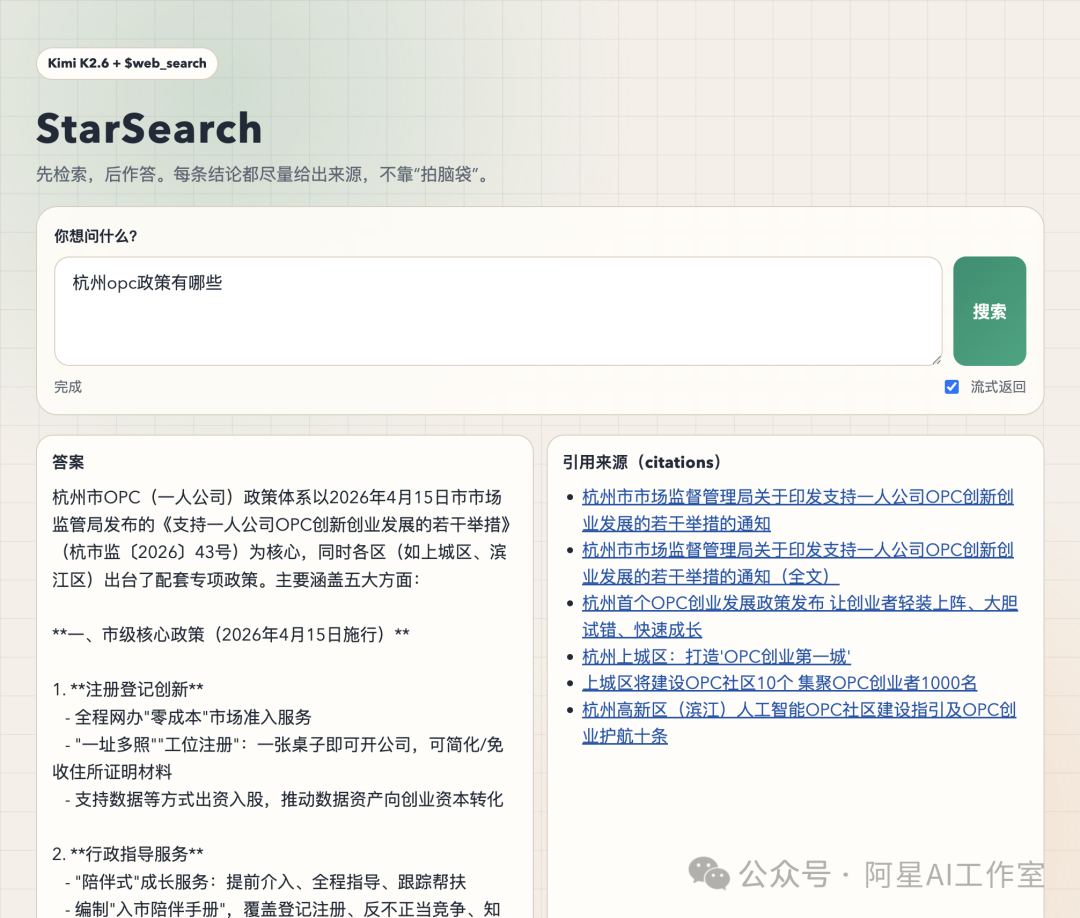
大象装冰箱第3步:验收
然后就做完了,可以优化的地方还有很多。
但是你已经完成了自己的第一个搜索网站,只用按照我之前写过的上线方法之一进行上线即可👉3个方法把gemini3做的应用部署成网站!
需要明白的知识点
而且用kimi搜索有个知识点需要注意(虽然我们全程用AI编程,你也要理解为啥kimi能这么丝滑的搜索)
首先,模型本身是没有搜索能力的,kimi的搜索属于平台内置函数。
平台内置函数(builtin_function):是服务端给模型“外挂”的能力,比如 $web_search。
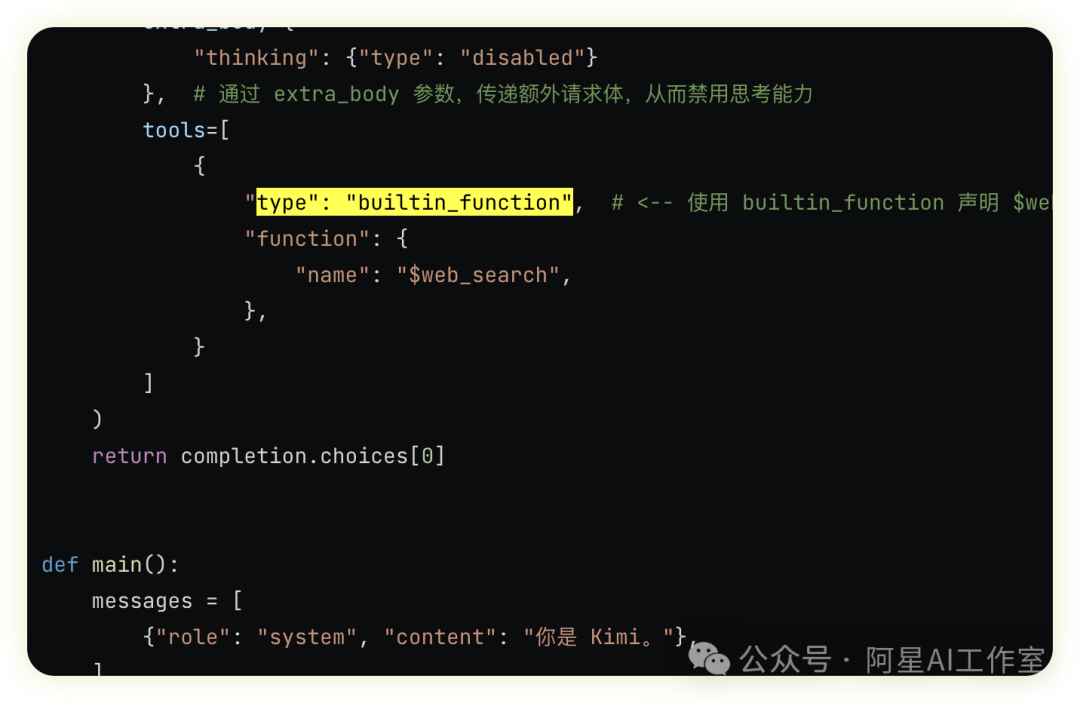
所以在你这段代码里,不是“模型自己突然会搜索了”,而是:
-
用户在前端发起问题,请求到应用后端。
-
应用后端调用 Kimi,模型返回 tool_calls(要调用 $web_search)和参数。
-
应用后端把该参数原样作为 role=tool 消息回传给 Kimi;Kimi 平台内部执行内置搜索。
-
Kimi 基于搜索结果生成最终回答,应用后端再把最终回答返回给前端用户。
是平台把搜索封装成了模型可调用的内置工具。流程看起来和普通 tool_calls 一样,但调用方几乎不用实现工具逻辑,只是转发参数。
所以,我们每次用AI编程,对于主要概念都要起码看一遍,不然编了也是白编。我一直是把codex当成爹的,它说的话我会认真看的。比如前面codex给的提示词,它的约束框架就很值得我们学习:
我们希望搜索事件发生的时候系统怎么办……
当系统处于不同状态时,整个系统又该采取什么行为……
什么是我们系统可增补的功能……
什么是明令禁止的……现在AI发展到这个阶段,这些提示词不需要你写了,你要的就是知道什么是好的什么是坏的。用的时候再去补充完善就可以了。在今天已经没有人不会编程了从技术条件上讲。
我希望大家看完这篇文章后,只是听到别人说“想做一个xxx网站”这么一句话,或者只是看到类似的标题,就能直接复现对应的功能来做练习。高热内容往往都是通过市场或者读者验证的,非常适合练习,了解背后的技术栈。
AI时代的普通难度编程,真的可以通过和codex对话,不用人为干预太多就可以完成了。
ok,我是阿星,更多AI应用,我们下期再见!


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)