跟着李沐逐字精读论文,这个开源项目让33000人直呼“救了我“。
摘要:李沐开源了一个深度学习论文精读项目,配套 B 站视频,逐段讲解 AlexNet、Transformer、BERT、GPT 等经典与前沿论文。不只讲内容,还讲读论文方法和写作技巧。33,000+ Stars,是 AI 学习者公认的高质量资源。

你有没有这种体验:
打开一篇 BERT 的论文,第一页还行,第二页开始有点懵,第三页直接开始刷手机。
不是不努力,是真的不知道从哪里下手。
我记得很清楚,大四毕业的时候,导师说"多看论文",但从来没人告诉我怎么看。每次硬啃下来,感觉只是字面意思看懂了,但作者为什么这么设计、这个方法好在哪里、后来有没有人改进——脑子里一片空白。
直到我刷到李沐在 B 站开的「论文精读」系列,才第一次感受到:原来论文可以这样读。
李沐是谁?
如果你在深度学习圈待过,基本绕不开这个名字。
李沐(Mu Li),AWS 资深科学家,MXNet 深度学习框架的主要贡献者之一。他在 B 站开过《动手学深度学习》直播课,弹幕里常年飘着"沐神"两个字。
但他更让我佩服的,是他在有正职工作的情况下,深夜抽出碎片时间,一篇一篇录制论文精读视频——每篇约 5 小时,剪辑、上传全自己搞定。
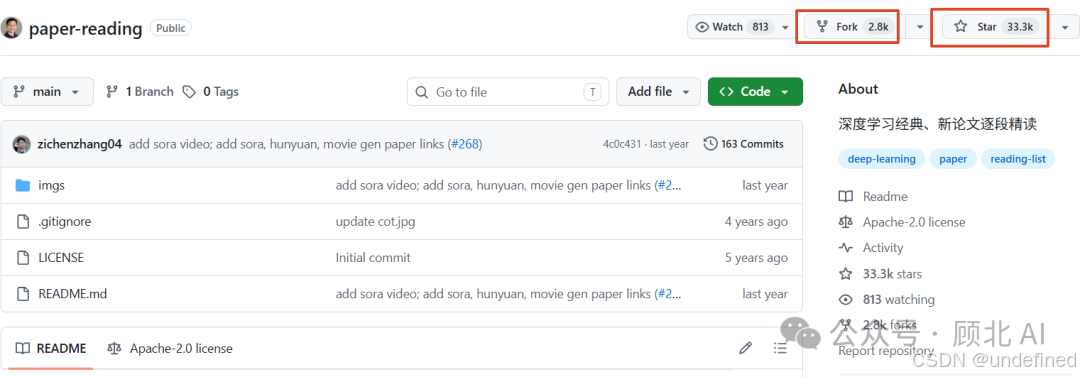
2021 年 10 月,他把这个系列整理成开源项目放上 GitHub:
github.com/mli/paper-reading
截至今天,这个项目已经有 33,000+ Stars,2,800+ Fork,是深度学习学习者里真正的口碑项目。
这个项目解决了什么问题?
说白了,就两个字:读不懂。
学术论文有它自己的"语言习惯":大量假设读者已知的背景知识、高度压缩的表达方式、有时候连作者自己都不一定讲清楚的细节。
普通学习者拿到一篇 Transformer 的论文,光是第一段的 encoder-decoder 结构就可能卡住。然后去搜博客,搜到的是别人的二次转述,理解又打折扣。
李沐这个项目的价值在于:他替你完成了「专家第一遍精读」的过程,并且把他脑子里的想法全部说出来。
他不只是讲论文写了什么,他会说:
-
"这句话的意思是……作者没有直接说,但你要理解背景是……"
-
"这里其实有个问题,后来 XXX 的工作证明这个假设是有瑕疵的"
-
"这个图画得不好,我来重画一下帮你理解"
这种感觉,就像有个大佬坐在你旁边陪你读论文。
他是怎么读论文的?
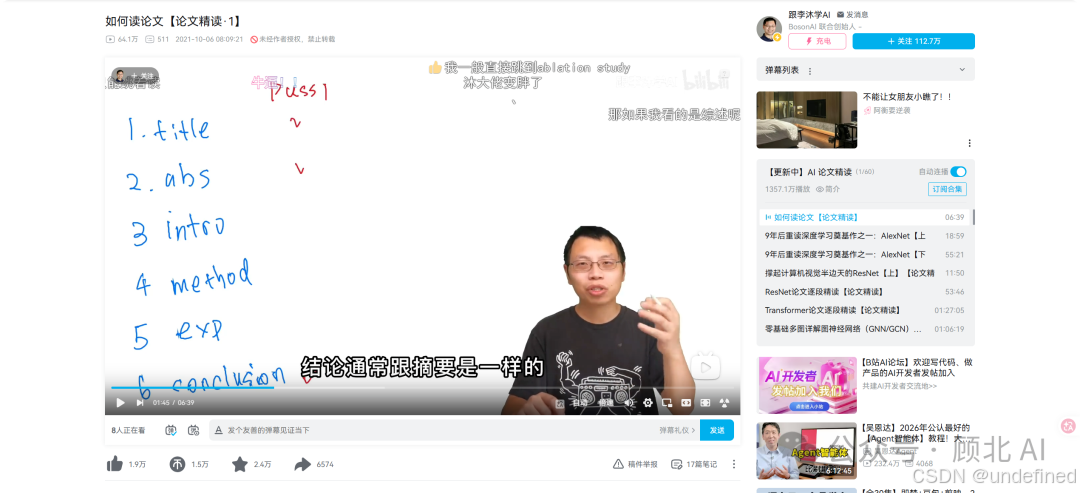
这也是项目里含金量很高的一部分——李沐总结了一套「三遍法」:
第一遍(10-15 分钟):只看标题、摘要、结论,浏览一下图表。目标是判断这篇文章值不值得继续读。大量论文止步于此,这很正常。
第二遍:快速通读全文,了解每个部分在干什么,但不需要理解所有细节。重点圈出没看懂的参考文献——如果文章太难,先去读它引用的经典。
第三遍:带着批判性思维读。作者解决了什么问题?用了什么方法?如果是我,会怎么做?有没有可以改进的地方?
这三遍的本质是:先建立全局视角,再深入局部,最后主动质疑。
很多人一上来就死磕第三遍,读了两小时还没过第一页,最后放弃。李沐的方法给了一个「可执行的论文阅读 SOP」,对初学者非常友好。
覆盖了哪些论文?
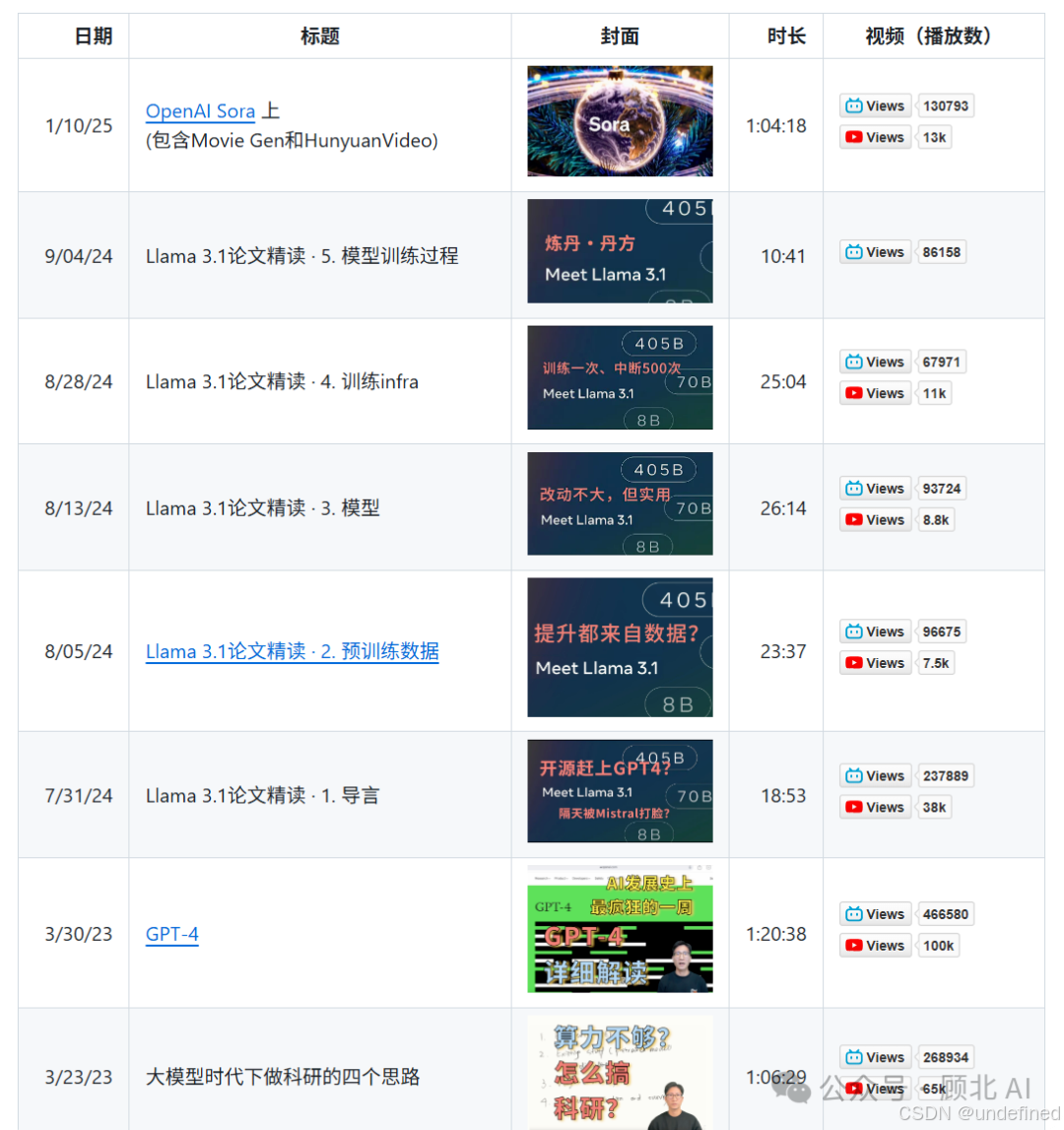
项目规划精读 67 篇论文,目前已录制完成 32 篇,基本涵盖了深度学习近十年的核心脉络:
CV 方向
-
AlexNet(2012)——深度学习浪潮的奠基作,连李沐自己都说"9年后重读,依然有收获"
-
ResNet(2015)——残差连接,几乎所有深度模型都有它的影子
-
ViT、Swin Transformer——Transformer 跨界杀入 CV 的两个里程碑
-
MAE——Facebook 出的"CV 版 BERT",看完你会明白为什么自监督学习这么火
NLP 方向
-
Transformer 原作(2017)——"Attention Is All You Need",现代 AI 的基础砖块
-
BERT、GPT/GPT-2/GPT-3——从"语言理解"到"语言生成"的完整演进
-
Llama 3.1(2024)——Meta 最强开源模型,是的,最新的也有
多模态
-
CLIP——OpenAI 的工作,图片分类从此不用人工标注,读完会对多模态有直觉级的理解
代码生成
-
OpenAI Codex、AlphaCode——现在这么多 AI 编程工具,根就在这里
选题逻辑也很清晰:10 年内有影响力的必读文章,优先选之前直播课没讲过的。不求全,求精,求有代差的学习价值。
我最喜欢的细节
除了论文内容本身,李沐读论文时会顺带讲怎么写论文。
比如读 AlexNet 时,他会说:"这里作者的写法有个问题,当时 CNN 并不是主流,应该先介绍主流方法再过渡到 CNN,这样读者更容易接受。"
这种视角,对于将来要写论文的研究生来说,是远比"这个模型有几层卷积"更值钱的东西。
还有一个细节:每篇视频的评论区都非常活跃。有人问问题,有人补充相关工作,有人说"听了三遍,每次都有新理解"。这种社区氛围是很多付费课程都做不到的。
适合谁看?
-
刚入门深度学习的研究生:别一上来就硬啃原文,先跟着李沐看视频,建立直觉再返回读原文
-
转行做 AI 的工程师:不想刷培训班,想直接理解技术本质,这个系列是最好的切入点之一
-
已经在做研究但基础薄弱的人:很多人能用 PyTorch 跑模型,但说不清楚为什么 ResNet 要用残差连接——这里有答案
-
想了解 AI 发展脉络的人:从 AlexNet 到 GPT-3 到 Llama 3.1,一条清晰的时间线就在这个项目里
怎么开始?
两个入口:
GitHub:github.com/mli/paper-reading在这里可以看到所有规划和已录制的论文列表,每篇都有 B 站视频链接。建议先看看论文列表,找一篇自己感兴趣的开始。
B 站:搜索「李沐」或「深度学习论文精读」,找到对应的播放列表。
我自己的建议是:从 Transformer 那期开始。
因为现在几乎所有主流模型——BERT、GPT、ViT、MAE、CLIP——都是 Transformer 的变体。这篇读懂了,后面的论文会顺很多。视频时长 1 小时出头,但值得你反复看。
深度学习发展太快,论文每天都在出,没有人能全部跟上。但有一些经典工作,是理解这个领域的"地基"——不管你现在做什么方向,早晚绕不过去。
李沐这个项目做的事情,就是帮你把这些地基打好。
33,000 人 Star 了它,我觉得这不是在收藏,是在说:这正是我需要的东西。
GitHub:github.com/mli/paper-reading
B 站:搜索「李沐 论文精读」
去看看吧,从第一期开始。
我是顾北,关注我,获取更多好玩有趣的开源仓库!
谢谢你阅读我的文章~
我们下期再见!
PS:本文部分内容由AI辅助创作

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)