Java 程序员第 25 阶段:CompletableFuture 异步调用,大模型接口并发编排
引言
在现代Java后端开发中,异步编程已成为处理高并发、大量IO操作的核心手段。随着大模型(L LM)接口的广泛应用,后端服务需要同时调用多个AI供应商的API来获取响应、比较结果或实现降级方案。CompletableFuture作为Java 8引入的异步编程利器,天然适用于这种多模型接口的并发编排场景。
本文将深入剖析CompletableFuture的异步调用机制,并结合实际案例讲解如何优雅地实现大模型接口的并发编排。
一、CompletableFuture核心概念
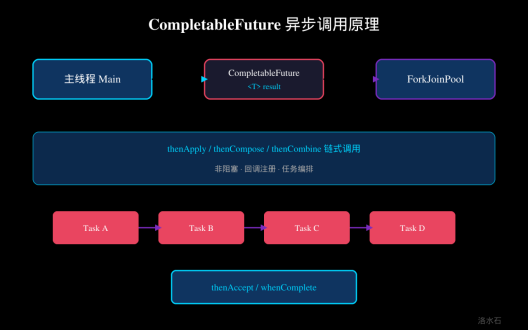
图:CompletableFuture异步调用原理
1.1 什么是CompletableFuture
CompletableFuture是Java 8新增的Future扩展,它代表一个异步计算的结果。与传统Future相比,CompletableFuture提供了更强大的回调机制和流式API,支持链式调用、组合操作和异常处理。
// 创建一个完成的CompletableFuture
CompletableFuture<String> future = CompletableFuture.completedFuture("result");
// 创建一个异步任务
CompletableFuture<String> asyncFuture = CompletableFuture.supplyAsync(() -> {
// 模拟耗时操作
return callLLMApi(prompt);
});
1.2 异步任务创建
CompletableFuture提供了两类异步任务创建方法:
|
方法 |
说明 |
返回类型 |
|
`supplyAsync(Supplier)` |
异步执行,有返回值 |
CompletableFuture\<T\> |
|
`runAsync(Runnable)` |
异步执行,无返回值 |
CompletableFuture\<Void\> |
这两个方法默认使用ForkJoinPool.commonPool()执行,也可以指定自定义Executor:
ExecutorService executor = Executors.newFixedThreadPool(10);
CompletableFuture<String> future = CompletableFuture.supplyAsync(
() -> callChatGPT(prompt),
executor
);
二、CompletableFuture常用操作
2.1 链式回调
CompletableFuture最强大的特性之一是支持链式回调,避免回调地狱:
CompletableFuture.supplyAsync(() -> callChatGPT(prompt))
.thenApply(result -> processResult(result)) // 转换结果
.thenApply(result -> formatOutput(result)) // 继续处理
.thenAccept(output -> System.out.println(output)) // 最终消费
.exceptionally(ex -> { // 异常处理
log.error("Error occurred", ex);
return null;
});
各方法对比:
- thenApply:上一步结果作为输入,有返回值
- thenAccept:消费上一步结果,无返回值(终端操作)
- thenCompose:扁平化嵌套的CompletableFuture,用于异步链式依赖
- thenCombine:合并两个独立的CompletableFuture结果
2.2 并行组合
当需要同时执行多个任务并汇总结果时:
CompletableFuture<String> chatGPT = CompletableFuture.supplyAsync(() -> callChatGPT(prompt));
CompletableFuture<String> claude = CompletableFuture.supplyAsync(() -> callClaude(prompt));
CompletableFuture<String> gemini = CompletableFuture.supplyAsync(() -> callGemini(prompt));
// 等待所有任务完成
CompletableFuture.allOf(chatGPT, claude, gemini).join();
// 获取结果
List<String> results = Stream.of(chatGPT, claude, gemini)
.map(CompletableFuture::join)
.collect(Collectors.toList());
anyOf用于实现"先到先得"策略:只要任一任务完成即可继续:
CompletableFuture.anyOf(chatGPT, claude, gemini)
.thenAccept(result -> sendResponse(result));
三、线程池配置
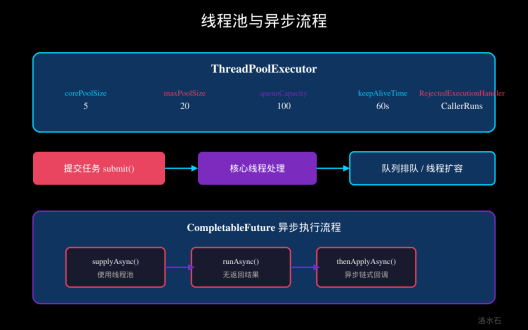
图:线程池与异步流程
3.1 线程池参数选择
大模型接口调用属于IO密集型任务,建议配置:
ExecutorService llmExecutor = new ThreadPoolExecutor(
10, // corePoolSize
50, // maximumPoolSize
60L, TimeUnit.SECONDS, // keepAliveTime
new LinkedBlockingQueue<>(200), // 队列容量
new ThreadFactoryBuilder()
.setNameFormat("llm-pool-%d")
.build(),
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);
3.2 线程池隔离
建议为不同类型的任务配置独立的线程池:
// 大模型调用线程池
ExecutorService llmExecutor = ...
// 普通IO任务线程池
ExecutorService ioExecutor = ...
// CPU密集任务线程池
ExecutorService cpuExecutor = ...
这样设计的优势是避免不同类型任务相互影响,提升系统稳定性。
四、大模型接口并发编排实战
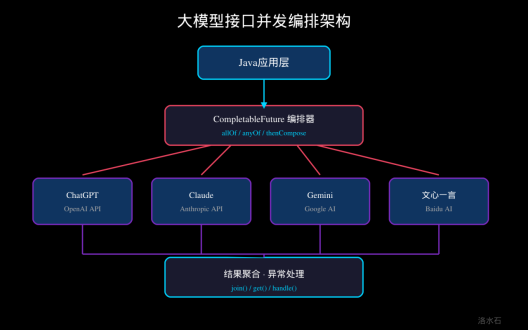
图:大模型接口并发编排架构
4.1 多模型并发调用
以下是一个完整的多模型并发调用示例:
@Service
public class LLMOrchestrator {
private final ExecutorService llmExecutor;
private final ChatGPTClient chatGPTClient;
private final ClaudeClient claudeClient;
private final GeminiClient geminiClient;
public LLMOrchestrator() {
this.llmExecutor = new ThreadPoolExecutor(
10, 50, 60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(200),
new ThreadPoolExecutor.CallerRunsPolicy()
);
}
/**
* 并发调用多个大模型API
* @param prompt 用户输入
* @return 各模型响应结果
*/
public Map<String, String> callMultipleModels(String prompt) {
CompletableFuture<String> chatGPTFuture = CompletableFuture.supplyAsync(
() -> chatGPTClient.call(prompt), llmExecutor
);
CompletableFuture<String> claudeFuture = CompletableFuture.supplyAsync(
() -> claudeClient.call(prompt), llmExecutor
);
CompletableFuture<String> geminiFuture = CompletableFuture.supplyAsync(
() -> geminiClient.call(prompt), llmExecutor
);
// 等待所有模型返回
CompletableFuture.allOf(chatGPTFuture, claudeFuture, geminiFuture).join();
Map<String, String> results = new HashMap<>();
results.put("chatgpt", chatGPTFuture.join());
results.put("claude", claudeFuture.join());
results.put("gemini", geminiFuture.join());
return results;
}
}
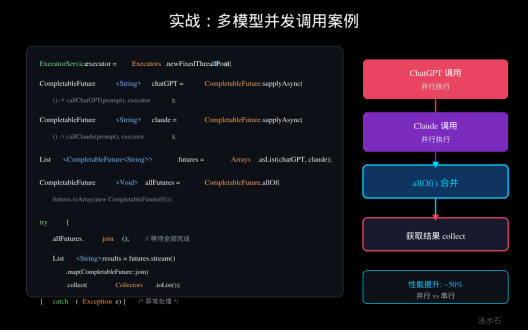
图:实战多模型并发调用案例
4.2 超时控制与降级
大模型API响应时间不稳定,需要设置合理的超时策略:
public String callWithTimeout(String prompt, long timeoutMs) {
CompletableFuture<String> future = CompletableFuture.supplyAsync(
() -> llmClient.call(prompt), llmExecutor
);
try {
return future.get(timeoutMs, TimeUnit.MILLISECONDS);
} catch (TimeoutException e) {
log.warn("LLM call timeout after {}ms", timeoutMs);
return getFallbackResponse(); // 降级响应
} catch (ExecutionException e) {
log.error("LLM call failed", e.getCause());
return getFallbackResponse();
}
}
4.3 错误聚合处理
当部分模型调用失败时,我们通常希望收集所有错误并继续处理:
public LLMResponse aggregateResults(String prompt) {
List<CompletableFuture<LLMResult>> futures = Arrays.asList(
CompletableFuture.supplyAsync(() -> chatGPTClient.call(prompt), llmExecutor)
.thenApply(result -> new LLMResult("chatgpt", result, null))
.exceptionally(ex -> new LLMResult("chatgpt", null, ex.getMessage())),
CompletableFuture.supplyAsync(() -> claudeClient.call(prompt), llmExecutor)
.thenApply(result -> new LLMResult("claude", result, null))
.exceptionally(ex -> new LLMResult("claude", null, ex.getMessage())),
CompletableFuture.supplyAsync(() -> geminiClient.call(prompt), llmExecutor)
.thenApply(result -> new LLMResult("gemini", result, null))
.exceptionally(ex -> new LLMResult("gemini", null, ex.getMessage()))
);
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
List<LLMResult> results = futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList());
// 分离成功和失败结果
List<LLMResult> successes = results.stream()
.filter(r -> r.getError() == null)
.collect(Collectors.toList());
List<LLMResult> failures = results.stream()
.filter(r -> r.getError() != null)
.collect(Collectors.toList());
return new LLMResponse(successes, failures);
}
五、性能优化策略
5.1 避免阻塞
虽然join()和get()会阻塞等待结果,但在并发场景下,多个任务并行执行,总耗时取决于最慢的那个任务:
// 串行执行:T1 + T2 + T3
String r1 = task1();
String r2 = task2();
String r3 = task3();
// 并行执行:max(T1, T2, T3)
CompletableFuture.allOf(task1Async(), task2Async(), task3Async()).join();
5.2 合理设置并发数
根据下游服务的限流策略调整并发数:
// 动态调整并发数
Semaphore semaphore = new Semaphore(maxConcurrentCalls);
CompletableFuture.supplyAsync(() -> {
semaphore.acquire();
try {
return callLLM(prompt);
} finally {
semaphore.release();
}
}, llmExecutor);
5.3 结果缓存
对于相同的prompt,可以利用CompletableFuture的特性实现简单的缓存:
Map<String, CompletableFuture<String>> cache = new ConcurrentHashMap<>();
public String callWithCache(String prompt) {
return cache.computeIfAbsent(prompt, key ->
CompletableFuture.supplyAsync(() -> callLLM(key), llmExecutor)
).join();
}
六、总结
CompletableFuture为Java异步编程提供了强大而灵活的工具集,尤其适合大模型接口的并发编排场景。核心要点总结:
1. **理解异步模型**:区分IO密集型和CPU密集型任务,合理配置线程池
2. **善用链式API**:thenApply、thenCompose、thenCombine构建优雅的异步流程
3. **并行加速**:使用allOf并行调用多个模型,显著降低总响应时间
4. **容错设计**:完善的超时控制、异常处理和降级策略确保系统稳定性
5. **资源隔离**:独立线程池避免不同类型任务相互影响
掌握这些技术,能够帮助Java后端开发者更好地应对大模型时代的接口编排挑战,构建高性能、高可用的AI应用。
---
*配图列表:*
- 图1:CompletableFuture异步调用原理
- 图2:大模型接口并发编排架构
- 图3:线程池与异步流程
- 图4:实战多模型并发调用案例

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献46条内容
已为社区贡献46条内容

所有评论(0)