基于深度学习的铁轨缺陷检测系统(YOLOv12完整代码+论文示例+多算法对比)
摘要:面向铁路巡检场景,本文实现一套基于深度学习的铁轨缺陷检测桌面系统,覆盖轨面裂纹、掉块、剥离与扣件异常等典型缺陷的自动识别与可视化复核。系统以 PySide6/Qt 构建交互界面,支持图片/视频/本地摄像头多源输入与统一推理流程,提供视频处理进度显示/进度条与耗时统计,检测结果在主显示区叠加框与类别置信度并同步写入记录表。为提升工程可用性,系统提供登录/注册(可跳过)的入口与会话范围控制,账号与历史记录采用 SQLite 本地入库管理;同时支持CSV 导出、带框结果一键导出(单帧 PNG / 多帧 AVI)以便留存与追溯。核心算法覆盖 YOLOv5–YOLOv12(共 8 种),在同一数据集与评测协议下对比 mAP、F1、PR 及训练曲线等指标,并支持在客户端完成**模型选择/权重加载(.pt 热切换)**以满足不同速度与精度需求。文末提供完整工程与数据集下载链接。
文章目录
功能效果展示视频:热门实战|《基于深度学习的铁轨缺陷检测系统》YOLOv12-v8多版本合集:附论文/源码/PPT/数据集,支持图片/视频/摄像头输入、可视化界面、结果导出与权重切换
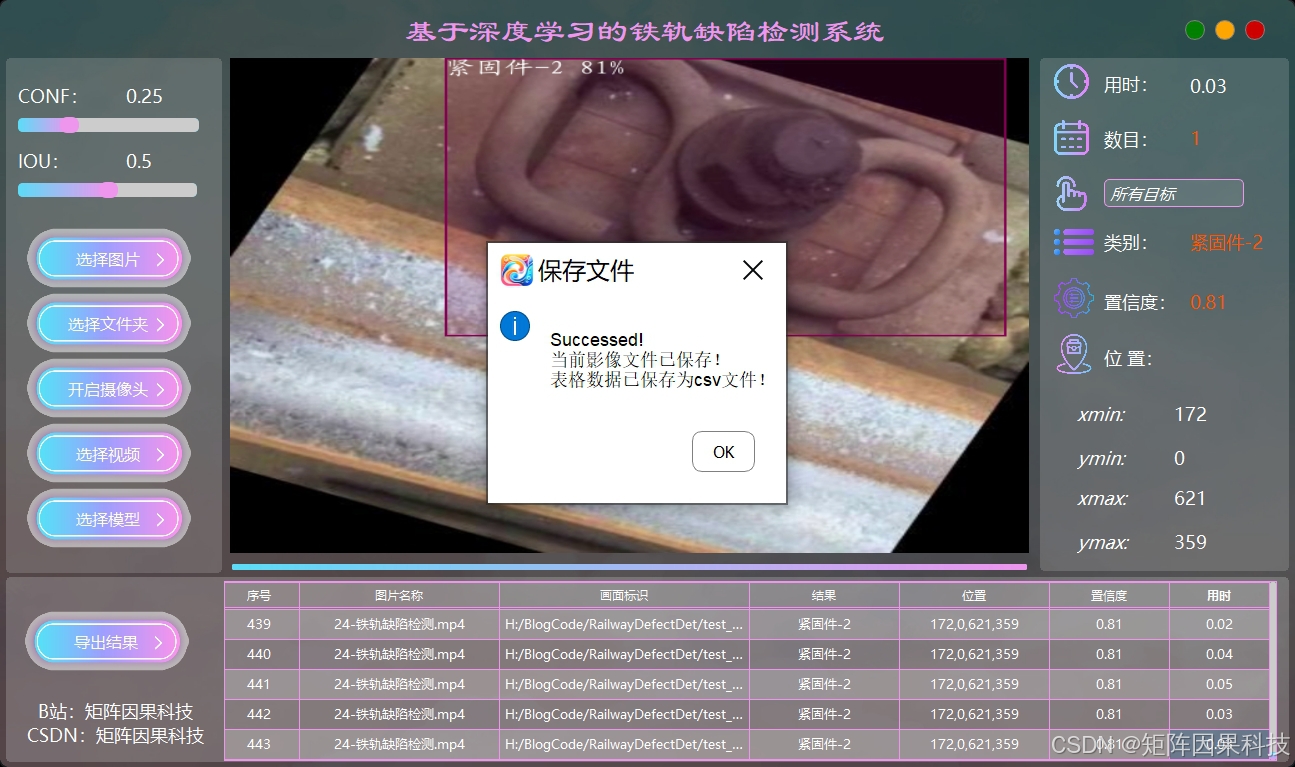
1. 系统功能与效果
(1)登录注册:系统启动后提供登录、注册与一次性跳过三种入口,跳过仅对当前会话生效,进入主界面后可随时注销或切换账号。登录成功会加载该账号的本地历史记录与个性化设置,并在后续检测与导出流程中自动绑定到当前会话。为兼顾体验与安全,账户信息与记录均由本地数据库管理,关键操作配合口令校验与会话状态提示,避免误用他人空间。
(2)功能概况:主界面采用“左侧参数与输入源、中部结果预览、右侧目标详情、底部记录与进度”的布局,用户无需频繁切换窗口即可完成从输入到复核的闭环。系统将最近一次检测的关键统计与记录入口前置,便于快速回到上次任务并定位异常样本。整体交互以少步骤为目标,将常用操作集中在可见区域,降低巡检场景下的操作负担。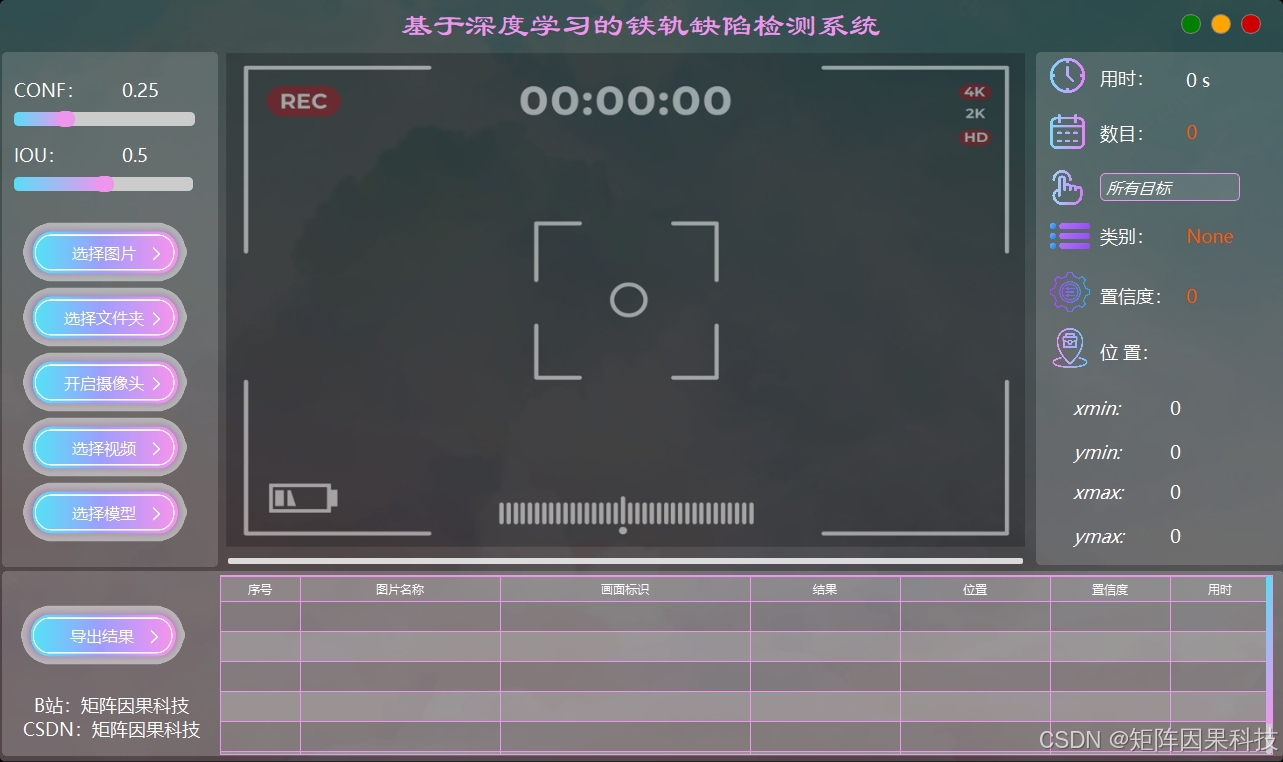
(3)选择模型:系统支持在界面中切换不同 YOLO 模型及其本地权重,选择后即可更新当前推理能力并同步刷新类别信息与颜色标识。模型切换与阈值配置相互独立,用户可以在同一批样本上快速对比不同模型的检测效果。常用配置会在本地保存,复打开时保持一致的模型偏好与界面风格。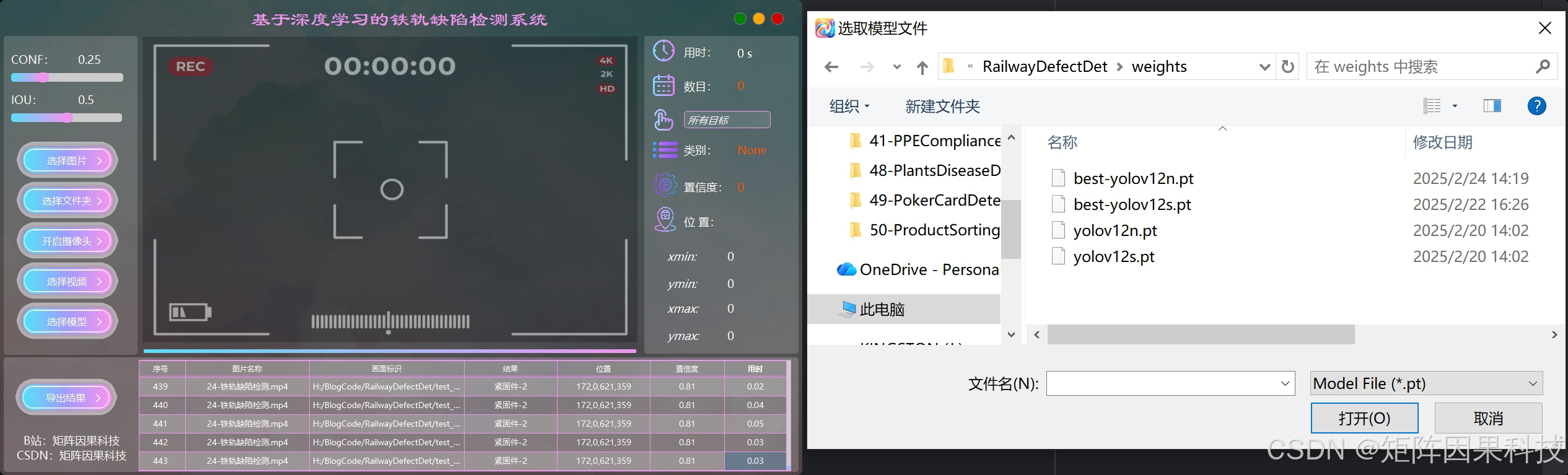
(4)图片检测:导入单张图片或图片集合后可即时完成推理,主显示区以叠加框展示缺陷位置,并同时给出类别名称与置信度,便于人工复核与二次判读。系统提供置信度与 IoU 等阈值调节,支持对特定目标进行选择与高亮,减少密集缺陷场景下的视觉干扰。检测结果会同步写入底部记录区,便于按时间与样本快速回查。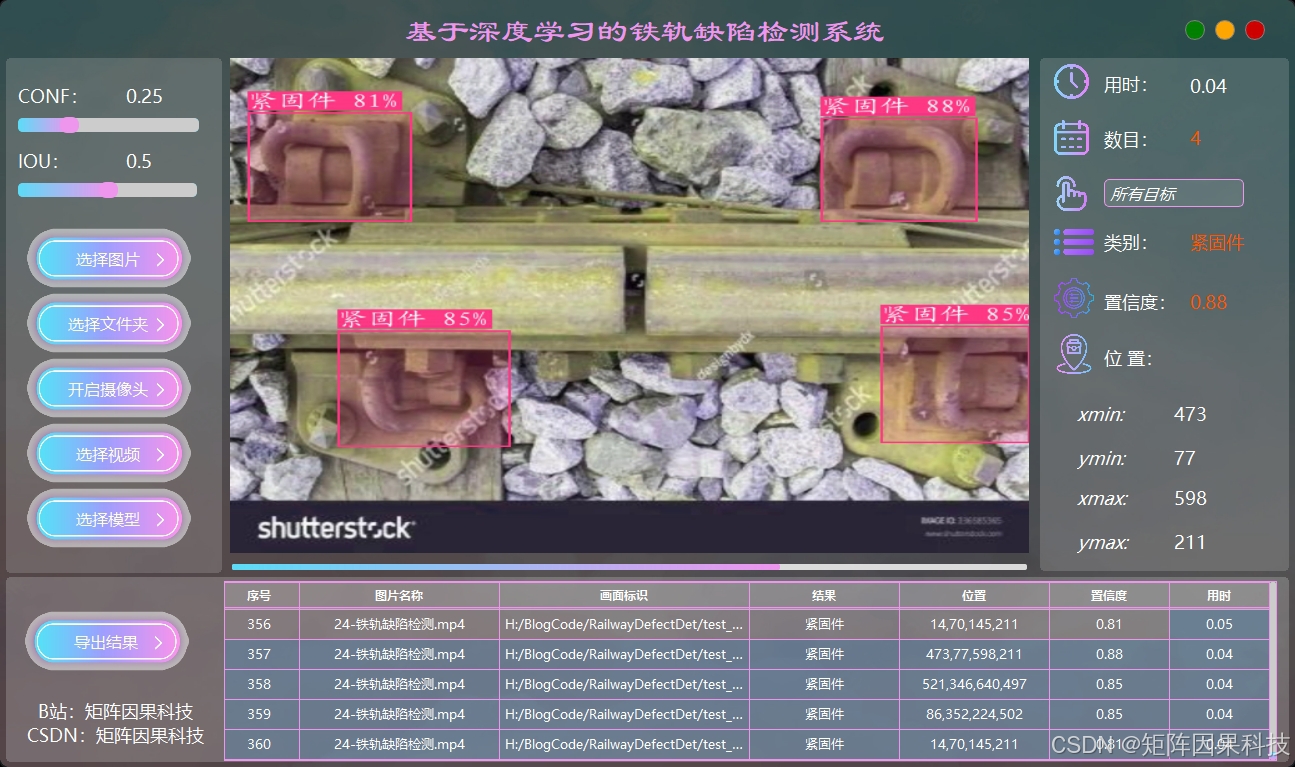
(5)文件保存:系统支持一键导出检测记录与可视化结果,既可导出结构化表格用于统计分析,也可导出带框图片用于留档与复核。所有导出内容采用时间戳命名并遵循统一归档规则,方便追溯同一次任务的输入、结果与参数配置。对批量样本的保存过程提供进度提示与失败告警,保证巡检数据在落盘阶段的完整性与可管理性。
2. 绪论
2.1 研究背景及意义
钢轨作为轮轨系统的核心承载与导向部件,其表面裂纹、剥离、擦伤与压溃等缺陷具有早期隐蔽、演化迅速、后果高风险等特点,传统以人工巡检为主的方式在效率、稳定性与可追溯性上难以满足高密度线路运维需求1。面向在线化、规模化的检测场景,基于机器视觉的缺陷检测能够在不接触工件的前提下提供连续、细粒度的缺陷定位与统计信息,从而支撑状态检修与风险预警2。与此同时,钢轨缺陷样本往往呈现长尾分布与弱纹理特征并存的现象,使得仅依赖强监督标注的训练范式面临数据成本高、泛化不足等现实约束2。 (Amazon Web Services, Inc.)
近年来,单阶段目标检测框架以其端到端、低时延的特性,逐渐成为工业视觉在线检测的主流路线之一[8]。在钢轨表面缺陷任务中,研究者常以 YOLO 系列为基础,通过多尺度特征融合、注意力机制与数据层增强等手段提升对小目标与弱对比缺陷的可检出性,并在部署侧兼顾边缘实时推理的算力约束3。因此,围绕“高精度、低时延、可交互、可追溯”的工程目标,构建一套将深度学习检测模型与 Qt 桌面端流程化交互融为一体的系统,不仅有助于提升运维效率,也能通过可视化结果与记录管理强化人机协同与质量闭环3。 (jdxb.bjtu.edu.cn)
2.2 国内外研究现状
面向钢轨表面缺陷检测,任务难点通常体现在缺陷尺度跨度大、纹理弱且与背景相似、光照反射引起的伪边缘干扰、缺陷密集与局部遮挡,以及类别与样本数量的长尾分布等方面2。在数据层面,学界常构建或复用公开钢轨缺陷数据以形成可对比的评测基线,但不同采集设备、线阵成像几何与线路工况会显著改变外观分布,从而放大跨场景泛化的挑战2。为降低标注成本并适应少样本情形,部分工作引入异常检测或弱监督策略,将“缺陷”视作偏离正常纹理分布的异常区域来建模2。 (GitHub)
在方法谱系上,传统两阶段检测器通过候选区域生成与分类回归分离的方式追求高精度,但其计算链路较长且部署复杂度较高[15]。单阶段检测器采用密集预测实现端到端推理,适合在线场景但容易受到正负样本不平衡与小目标召回不足的影响[16]。为缓解极端不平衡问题,Focal Loss 被用于抑制易分类样本对梯度的主导,从而提升稀缺缺陷的学习质量[17]。另一方面,DETR 以集合预测与二分匹配替代传统锚框与 NMS 思路,推动了端到端检测范式的演进[18]。
结合钢轨缺陷的细粒度特性,国内外研究多围绕“更强的多尺度表达、更稳的边缘刻画、更好的弱纹理增强”展开改进。国内有研究在 YOLOv5 基础上优化网络结构以提升钢轨表面缺陷识别能力,并给出面向工程场景的实验验证3。也有工作通过语义增广等数据层策略提升缺陷样本的有效信息密度,从而改善模型在复杂背景与反光条件下的鲁棒性4。在多源成像与弱监督方向,基于双目线扫的无监督显著性检测方法尝试融合图像与几何信息以实现高速场景下的缺陷定位1。 (jdxb.bjtu.edu.cn)
为更直观对比“范式选择”与“工程权衡”,表2-1汇总了若干具有代表性的钢轨缺陷方法与通用实时检测基线。表中可以看到,面向缺陷边界精细刻画的语义分割方法通常在形状与面积估计上更有优势,但其输出到运维指标的映射需要额外的后处理与连通域分析[5]。面向在线巡检的检测式方法更强调吞吐与部署便利性,并常结合图像增强与特征融合模块来提升弱纹理缺陷的可分性[6]。同时,端到端实时 Transformer 检测器在 COCO 等通用基准上已给出较高 AP 与高帧率的同时达成,为后续在轨道场景的“免 NMS、低延迟”部署提供了可借鉴的范式[9]。
| 方法/模型 | 范式/家族 | 数据集/场景 | 关键改进点 | 优势与局限 | 指标(示例) | 适用难点 | 来源 |
|---|---|---|---|---|---|---|---|
| 改进 YOLOv5 钢轨缺陷检测 | 单阶段/YOLO | 钢轨表面缺陷(工程采集) | 结构改进与工程化验证 | 速度与精度折中较好,但跨场景仍依赖数据覆盖 | 给出工程对比结果(文中详述) | 小缺陷、弱纹理 | 3 |
| 语义增广 + YOLOv8 | 单阶段/YOLO | 钢轨表面缺陷 | 语义增广提升有效信息 | 训练更稳健,但增广策略需与场景匹配 | 以 mAP 等指标对比(文中详述) | 反光、背景相似 | 4 |
| 图像增强 + 改进 YOLOX | 单阶段/YOLOX | 钢轨表面缺陷(含低照度) | HSV 空间融合增强 + BiFPN + 注意力 | 提升弱对比缺陷可见性,但增强带来额外开销 | mAP 相对提升 2.42%,速度 71.33 fps | 低对比、暗光 | [6] |
| 改进 UPerNet + 连通域分析 | 语义分割 | 两个钢轨缺陷数据集 | Swin-T 特征提取 + SyncBN + Lovász-hinge | 边界刻画强,但推理与后处理链路更长 | PA 91.39/93.35%,IoU 83.69/87.58% | 边界复杂、形状评估 | [5] |
| 无监督立体显著性检测 | 弱监督/无监督 | 双目线扫高速采集 | 融合显著性与几何离群信息 | 标注成本低,但精度上限受建模假设影响 | 建立 RSDDS-113 并验证(文中详述) | 少样本、高速采集 | 1 |
| RT-DETR | 端到端 Transformer | 通用检测基准 | 高效编码器 + 不确定性最小查询选择 | 免 NMS、端到端部署友好,但算力需求相对更高 | COCO AP 53.1%,T4 上 108 FPS | 低时延、免后处理 | [9] |
| YOLO12n(Ultralytics) | 单阶段/YOLO | COCO val2017 | 注意力中心架构(官方基准) | 精度提升明显,但训练与 CPU 吞吐可能不稳定 | mAP(50–95) 40.6,T4 TensorRT 1.64 ms | 精度-速度权衡 | [13] |
表2-1数据与描述来源于对应论文/官方文档:改进 YOLOv5 论文给出期刊信息与 DOI3,语义增广 YOLOv8 给出卷期与页码信息4,图像增强改进 YOLOX 与分割式方法提供了可复核的指标描述[5][6],RT-DETR 与 YOLO12 在公开基准上给出 AP 与速度数据[9][13]。 (jdxb.bjtu.edu.cn)
从工程部署趋势看,YOLO 系列仍在围绕结构效率、端到端化与推理接口优化持续演进,推动“高精度实时检测”在边缘侧落地[10]。YOLOv10 进一步强调端到端与低延迟的目标,通过 NMS-free 训练与效率驱动的结构设计推进速度与精度边界[10]。YOLOv9 则从可编程梯度信息与信息瓶颈角度讨论训练与架构设计,为轻量模型的参数利用率提供了新的分析与实现路径[11]。在工具链层面,Ultralytics 的模型文档提供了 YOLO11 与 YOLO12 的统一使用与基准信息,为工程侧的模型热切换与快速对比提供了便利入口[12]。 (arXiv)
2.3 要解决的问题及其方案
围绕“基于深度学习的铁轨缺陷检测系统”落地,本文需要同时面对算法性能与桌面端交互集成的双重约束。要解决的问题主要包括:(1)缺陷检测的准确性与实时性矛盾,既要提升小缺陷与弱纹理缺陷的召回,也要满足视频与摄像头流的低时延推理;(2)模型对工况变化的适应性与泛化能力不足,需应对不同线路、光照反射与污染遮挡带来的分布漂移;(3)桌面端交互的直观性与功能完整性,需将阈值调参、目标高亮与结果可视化形成可用闭环;(4)数据处理效率与存储安全性,需支持批量检测记录、结果导出与本地化持久化以便追溯。
对应地,本文的解决方案包括:(1)以 YOLO 模型为核心检测器,围绕小目标与弱纹理缺陷引入合理的数据增强、迁移学习与多模型对比训练,形成可部署的权重集合;(2)基于 PyTorch 完成训练与推理链路,并结合多场景数据划分与评测指标体系,系统化验证模型的稳定性与可迁移性;(3)以前端 PySide6/Qt 构建桌面端交互流程,打通图片、视频与本地摄像头输入,支持模型权重热切换与参数同步调节;(4)优化结果缓存与本地存储机制,通过结构化记录与导出编排提升批处理效率,并以本地数据库管理关键记录以保障可追溯与安全性。
2.4 博文贡献与组织结构
本文的主要贡献体现在:(1)面向铁轨缺陷检测任务,总结钢轨表面缺陷在尺度、纹理与工况变化上的关键挑战,并梳理从两阶段到单阶段、再到端到端 Transformer 的范式演进;(2)围绕 YOLOv5 至 YOLOv12 的模型体系,构建可复现的训练、推理与评测流程,形成多模型横向对比的实验依据;(3)将检测算法与 PySide6/Qt 桌面端进行工程化集成,形成支持多源输入、实时调参、结果可视化与导出的完整交互闭环;(4)以可追溯的记录管理与导出机制支撑运维场景的复查与闭环优化,并为后续扩展到更多线路工况与缺陷类型预留接口。
全文结构安排如下:第3章介绍数据集处理与标注规范;第4章给出以 YOLO 为主线的模型原理与设计要点;第5章对 YOLOv5 至 YOLOv12 等模型进行指标对比与误差分析;第6章从分层架构角度描述系统设计与实现并给出关键流程图;第7章总结全文并讨论模型、系统与数据侧的未来工作。
3. 数据集处理
本文数据集聚焦铁轨巡检视角下的轨面与扣件区域,共包含 2234 张高分辨率图像,并按 1888/173/173 划分为训练集、验证集与测试集。从训练样例可视化图可以直观看到,画面背景由道砟颗粒与钢轨金属纹理构成,目标外观同时存在强反光、弱纹理与遮挡干扰,且不同类别在形态上容易出现局部相似,这对检测器的特征分辨能力与定位稳定性都提出了较高要求。标签及其对应中文名如下:
Chinese_name = {"fastener": "紧固件", "fastener-2": "紧固件-2", "fastener2_broken": "紧固件2_损坏",
"fastener_broken": "紧固件_损坏", "missing": "缺失", "trackbed_stuff": "轨床杂物"}

在数据分布层面,标签相关性图反映出目标中心点在图像中部更为密集,这与巡检采集时常将钢轨或扣件结构置于主视野有关;同时,框的宽高分布呈现明显的长尾特征,小到中等尺度目标占比更高,少量样本则表现为更大框或更“细长”的几何形态。结合类别语义来看,紧固件及其相邻结构在数据中更常见,而“缺失”“损坏”“轨床杂物”等更贴近异常状态的类别往往更稀缺,容易在训练中被多数类主导,从而带来漏检或混淆的问题。为保证评测公平与复现性,本文采用固定随机种子完成训练/验证/测试的划分与抽样,并尽量避免相近场景在不同子集间交叉造成的数据泄漏,使验证与测试更能反映模型对工况变化的泛化能力。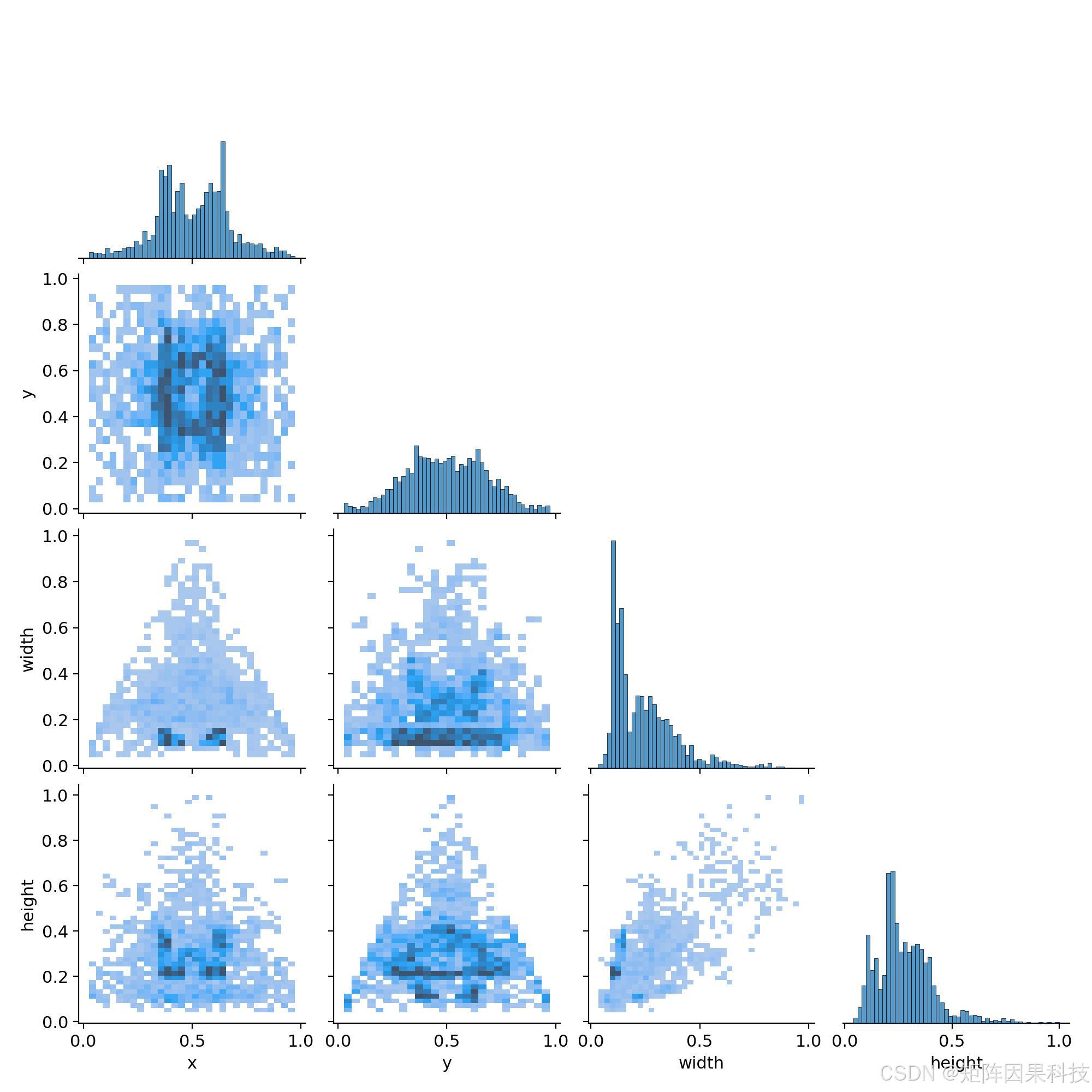
在数据分布层面,标签相关性图反映出目标中心点在图像中部更为密集,这与巡检采集时常将钢轨或扣件结构置于主视野有关;同时,框的宽高分布呈现明显的长尾特征,小到中等尺度目标占比更高,少量样本则表现为更大框或更“细长”的几何形态。结合类别语义来看,紧固件及其相邻结构在数据中更常见,而“缺失”“损坏”“轨床杂物”等更贴近异常状态的类别往往更稀缺,容易在训练中被多数类主导,从而带来漏检或混淆的问题。为保证评测公平与复现性,本文采用固定随机种子完成训练/验证/测试的划分与抽样,并尽量避免相近场景在不同子集间交叉造成的数据泄漏,使验证与测试更能反映模型对工况变化的泛化能力。
4. 模型原理与设计
本文默认以 YOLOv12 作为主线模型来组织原理阐述,并保持与系统端一致的端到端流程:输入图像先进行统一尺寸的预处理与归一化,随后由主干网络提取多层语义特征,再经由颈部网络完成多尺度融合,最终在检测头输出每个候选目标的类别概率与边界框回归量。对于铁轨场景而言,紧固件、紧固件缺失与损坏类目标往往尺度小、纹理弱且易被道砟背景干扰,因此“多尺度表达 + 稳健的定位回归 + 对背景噪声的抑制”是设计的关键出发点;同时,轨面金属反光与局部遮挡会造成局部对比度突变,要求特征提取模块在保持全局感受野的同时不过度牺牲计算效率,使其能够适配视频与摄像头流的实时推理。
在结构层面,YOLOv12 的核心特点可以概括为“注意力中心化的骨干/融合策略 + 轻量高效的特征聚合模块 + 解耦检测头”。其注意力机制通常可抽象为缩放点积注意力:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ! ( Q K ⊤ d ) V \mathrm{Attention}(Q,K,V)=\mathrm{softmax}!\left(\frac{QK^\top}{\sqrt{d}}\right)V Attention(Q,K,V)=softmax!(dQK⊤)V,其中 Q , K , V Q,K,V Q,K,V 分别为查询、键、值特征, d d d 为通道维度,用于控制数值尺度;在工程实现中,YOLOv12 倾向于用更高效的区域化注意力与算子优化(如 FlashAttention 思路)来降低显存访存开销,同时引入“位置感知”的卷积感受野(可理解为在注意力分支中用可分离卷积隐式编码位置信息),以适配目标检测对空间定位的强需求。确保小目标召回的关键落在多尺度融合上:颈部网络通过自顶向下与自底向上的路径聚合,将高层语义与低层细节对齐到同一表征空间,从而在高分辨率特征层上更容易保留紧固件边缘与缺失区域的局部结构;而解耦头将分类与回归分支分离,有利于缓解“类别判别”和“边界框精确拟合”在梯度上的竞争,使模型在背景复杂、类间相似的情况下更稳定地产生高置信度且定位准确的候选框。网络整体架构图如下图所示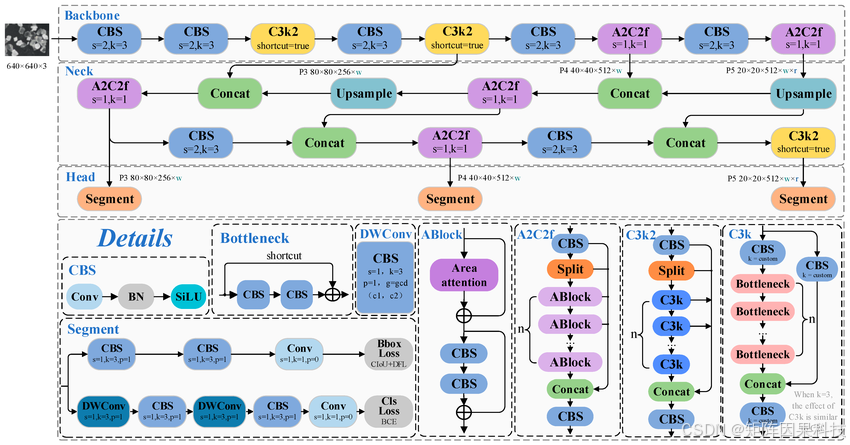
在损失函数与任务建模上,本文沿用工业检测中更稳健的组合式目标:分类分支通常采用二元交叉熵(或其变体)来学习多类判别,回归分支以 IoU 系列损失约束预测框与真值框的重叠质量。IoU 的定义为 I o U = ∣ B ∩ B g t ∣ ∣ B ∪ B g t ∣ \mathrm{IoU}=\frac{|B\cap B^{gt}|}{|B\cup B^{gt}|} IoU=∣B∪Bgt∣∣B∩Bgt∣,其中 B B B 为预测框、 B g t B^{gt} Bgt 为真值框;为了同时约束中心距离与长宽比,常用的 CIoU 可写为
L ∗ C I o U = 1 − I o U + ρ 2 ( b , b g t ) c 2 + α v , \mathcal{L}*{\mathrm{CIoU}} = 1-\mathrm{IoU} + \frac{\rho^2(\mathbf{b},\mathbf{b}^{gt})}{c^2} + \alpha v, L∗CIoU=1−IoU+c2ρ2(b,bgt)+αv,
其中 ρ ( ⋅ ) \rho(\cdot) ρ(⋅) 表示中心点欧氏距离, c c c 为最小外接框对角线长度, v v v 刻画长宽比一致性, α \alpha α 为平衡系数。针对小目标与边界敏感的缺陷定位,很多 YOLO 系实现会配合分布式回归(DFL)思想,将边界偏移量离散成 K K K 个 bin 的分布 p i p_i pi,并用期望回归 d ^ = ∑ ∗ i = 0 K p i , i \hat{d}=\sum*{i=0}^{K} p_i,i d^=∑∗i=0Kpi,i 获得更细粒度的定位,这在紧固件边缘清晰但背景噪声强的场景下往往更“抗抖”。综合来看,训练目标可写作 L = λ b o x L ∗ b o x + λ ∗ c l s L ∗ c l s + λ ∗ d f l L d f l \mathcal{L}=\lambda_{box}\mathcal{L}*{box}+\lambda*{cls}\mathcal{L}*{cls}+\lambda*{dfl}\mathcal{L}_{dfl} L=λboxL∗box+λ∗clsL∗cls+λ∗dflLdfl,各项权重 λ \lambda λ 用于在定位、分类与边界分布学习之间做权衡。
在训练策略与推理后处理上,本文更强调“面向场景难点的正则化”与“与系统交互一致的阈值逻辑”。训练阶段使用批归一化与适度的数据增强来提高泛化:亮度/对比度扰动用于覆盖反光与阴影变化,尺度与随机裁剪用于覆盖小目标比例波动,适度的拼接类增强用于提升稀缺异常类的有效曝光;当类别长尾明显时,可在不改动主干结构的前提下引入更关注难例的分类损失变体(如 Focal 思路)或重采样策略,以降低“缺失/损坏”类被多数类淹没的风险。推理阶段输出候选框集合 ( b i , s i , c i ) {(b_i,s_i,c_i)} (bi,si,ci) 后,先用置信度阈值 τ c o n f \tau_{conf} τconf 过滤 s i < τ c o n f s_i<\tau_{conf} si<τconf 的候选,再进行 NMS:对同类框按得分排序,若 I o U ( b i , b j ) > τ n m s \mathrm{IoU}(b_i,b_j)>\tau_{nms} IoU(bi,bj)>τnms 则抑制低分框,从而减少重复检测;这也解释了桌面端 Conf/IoU 滑块对结果的直接影响——提高 τ c o n f \tau_{conf} τconf 会降低误检但可能增加漏检,提高 τ n m s \tau_{nms} τnms(或等价地降低抑制强度)更容易保留密集目标但可能带来重复框,二者需要结合现场对“宁可多报/宁可漏报”的策略来取舍。
5. 实验结果与分析
本章实验目标是:在同一铁轨缺陷数据集(共 2234 张,训练/验证/测试为 1888/173/173)与统一评测协议下,对 YOLOv5–YOLOv12 的多种变体进行精度与效率的横向对比,并给出适合桌面端实时推理与工程落地的选型建议。评测指标覆盖 Precision、Recall、F1、mAP@0.5(记为 mAP50)与 mAP@0.5:0.95(记为 mAP50-95),同时统计预处理、推理与后处理耗时以体现端到端延迟;所有实验在 NVIDIA GeForce RTX 3070 Laptop GPU(8GB)上完成,便于与后续 Qt 端的视频/摄像头实时检测需求对齐。总体上,mAP50 在各模型间普遍接近饱和(多数接近 0.99),更能拉开差距的是 mAP50-95 与端到端时延,这与本任务存在大量小目标、密集部件以及背景道砟纹理干扰有关:同样“检出”,但更严格的 IoU 阈值会放大定位抖动与框紧致度差异,进而体现在 mAP50-95 上。
| Model | Params(M) | FLOPs(G) | Total(ms) | Precision | Recall | F1 | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 10.94 | 0.9634 | 0.9787 | 0.9710 | 0.9908 | 0.7530 |
| YOLOv6n | 4.3 | 11.1 | 10.34 | 0.9441 | 0.9521 | 0.9480 | 0.9669 | 0.7164 |
| YOLOv7-tiny | 6.2 | 13.8 | 21.08 | 0.9966 | 0.8760 | 0.9324 | 0.9625 | 0.6628 |
| YOLOv8n | 3.2 | 8.7 | 10.17 | 0.9872 | 0.9810 | 0.9841 | 0.9895 | 0.7502 |
| YOLOv9t | 2.0 | 7.7 | 19.67 | 0.9773 | 0.9907 | 0.9840 | 0.9938 | 0.7659 |
| YOLOv10n | 2.3 | 6.7 | 13.95 | 0.9592 | 0.9658 | 0.9625 | 0.9902 | 0.7548 |
| YOLOv11n | 2.6 | 6.5 | 12.97 | 0.9713 | 0.9554 | 0.9633 | 0.9904 | 0.7526 |
| YOLOv12n | 2.6 | 6.5 | 15.75 | 0.9583 | 0.9754 | 0.9668 | 0.9901 | 0.7515 |
| YOLOv5su | 9.1 | 24.0 | 12.24 | 0.9907 | 0.9739 | 0.9822 | 0.9906 | 0.7509 |
| YOLOv6s | 17.2 | 44.2 | 12.26 | 0.9608 | 0.9467 | 0.9537 | 0.9799 | 0.7379 |
| YOLOv7 | 36.9 | 104.7 | 29.52 | 0.9814 | 0.9950 | 0.9882 | 0.9962 | 0.7333 |
| YOLOv8s | 11.2 | 28.6 | 11.39 | 0.9942 | 0.9816 | 0.9879 | 0.9937 | 0.7558 |
| YOLOv9s | 7.2 | 26.7 | 22.17 | 0.9948 | 0.9784 | 0.9865 | 0.9939 | 0.7592 |
| YOLOv10s | 7.2 | 21.6 | 14.19 | 0.9708 | 0.9972 | 0.9838 | 0.9950 | 0.7605 |
| YOLOv11s | 9.4 | 21.5 | 13.47 | 0.9800 | 0.9561 | 0.9679 | 0.9888 | 0.7593 |
| YOLOv12s | 9.3 | 21.4 | 16.74 | 0.9774 | 0.9853 | 0.9814 | 0.9938 | 0.7697 |
从精度侧看,n 系列中 YOLOv8n 在 F1 上取得最高值(0.9841),同时端到端总耗时约 10.17ms,属于“精度与速度都很均衡”的方案;YOLOv9t 的 mAP50 与 mAP50-95 均领先(0.9938/0.7659),说明其在更严格 IoU 下的定位质量更稳定,但推理耗时显著增加(InfTime 16.51ms,总耗时约 19.67ms),更适合离线复核或对定位要求更苛刻的场景。YOLOv7-tiny 的 Precision 极高(0.9966),但 Recall 明显偏低(0.8760),导致 F1 与 mAP50-95 下滑,这类现象在铁轨数据中往往意味着模型更“保守”,对小目标或遮挡目标更容易漏检;若在系统侧将默认 Conf 设得较高,这种保守性会被进一步放大,因此它在桌面端实时巡检中需要更谨慎的阈值配置与难例补充。s 系列整体 F1 更高但计算量更大,其中 YOLOv12s 的 mAP50-95 达到全表最高(0.7697),属于“定位更稳的高精度方案”,而 YOLOv8s 的总耗时最低(约 11.39ms)且 F1 仍接近 0.988,更贴近实时交互与连续视频推理的落地诉求;这也解释了为何在 Qt 端做模型热切换时,推荐将 YOLOv8n/YOLOv8s 作为默认在线模型,将 YOLOv9t/YOLOv12s 作为离线复核或高精度模式。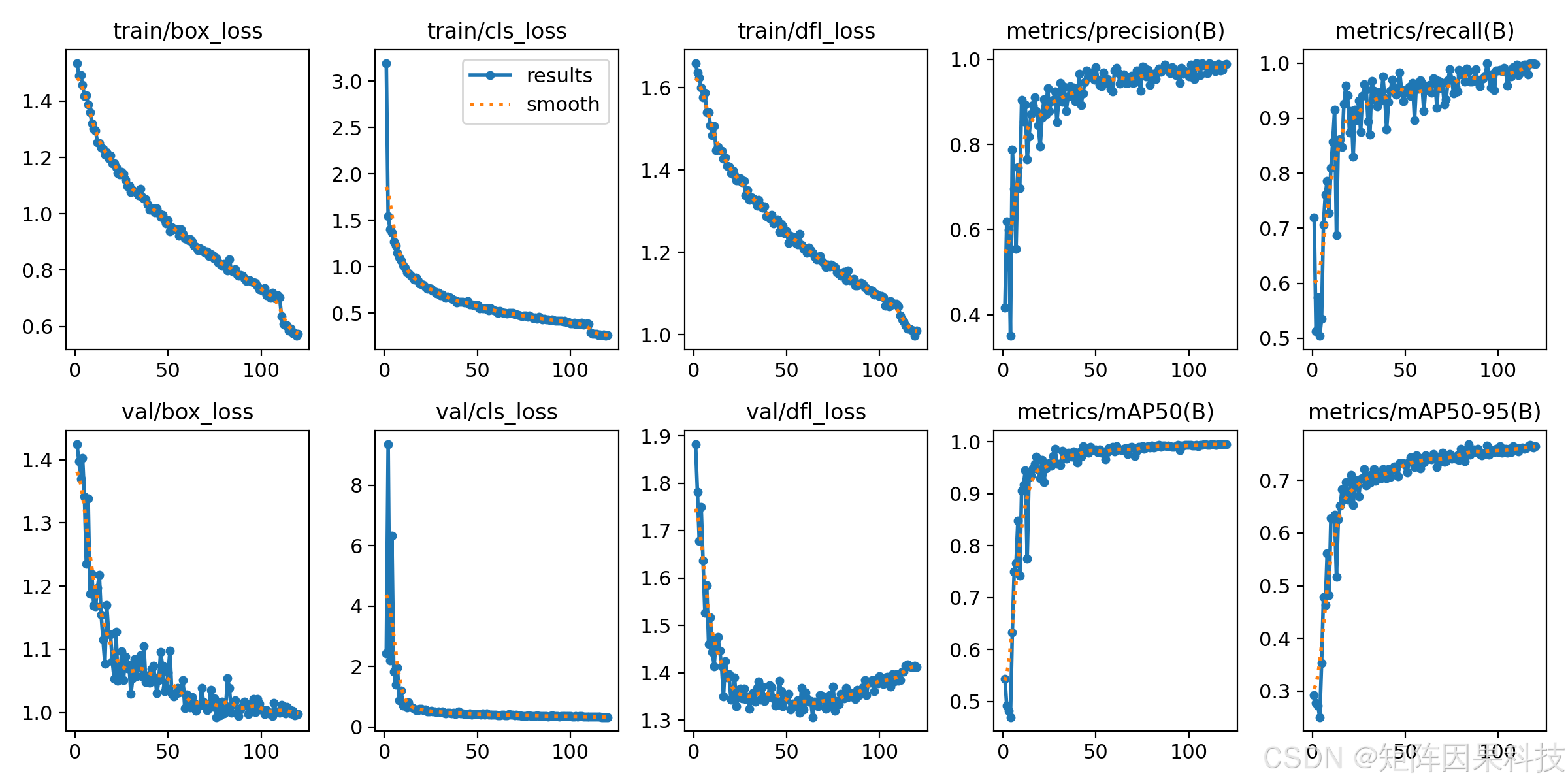
从训练过程与收敛稳定性看,mAP50 曲线在前 10–20 个 epoch 内快速上升并趋于饱和,后期变化幅度明显变小,说明在该数据集上模型较快学到“扣件与轨床结构”的判别模式;同时,训练损失(box/cls/dfl)整体平滑下降,验证侧 loss 在中后期趋稳但 dfl_loss 有轻微上扬的迹象,提示在高精度区间可能存在轻微过拟合或框回归趋于“更紧/更松”的风格漂移,工程上更建议使用验证集早停点附近的 best 权重,而不是盲目追求最后 epoch 的指标。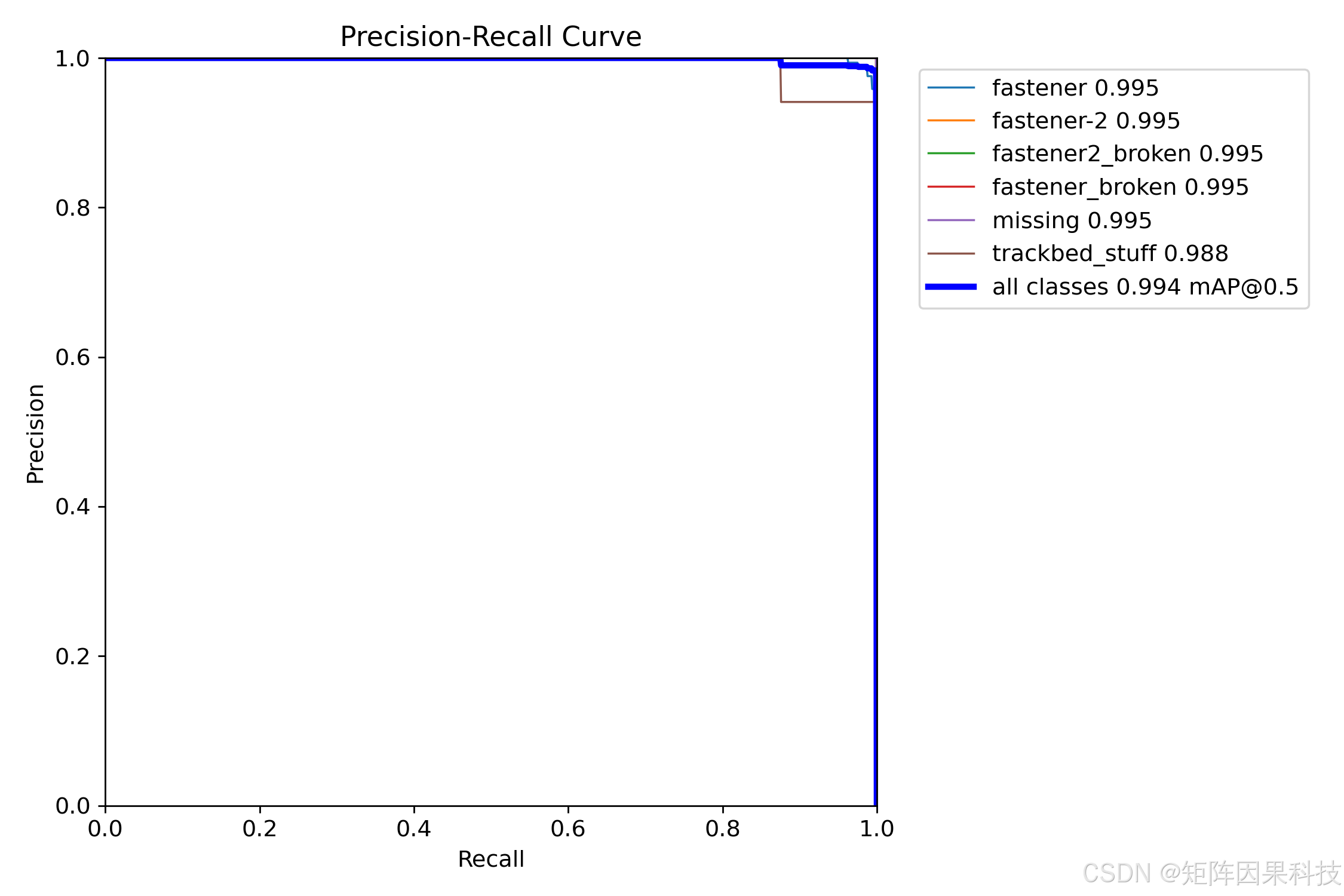
PR 曲线整体贴近右上角,说明多数组别在高召回区仍能保持高精度,但在接近 Recall=1 的末端仍可观察到个别模型曲线下弯,这通常与“背景道砟的硬负样本”以及“相似部件/损坏形态的边界模糊”有关,因此在系统侧提供“目标选择与高亮”“记录回查”会显著降低误检带来的复核成本。如下图所示,双条形图直观呈现了 n/s 两组模型在 F1 与 mAP50 上的整体差距,而训练曲线与 PR 曲线为“速度-精度权衡”提供了更细的稳定性依据。
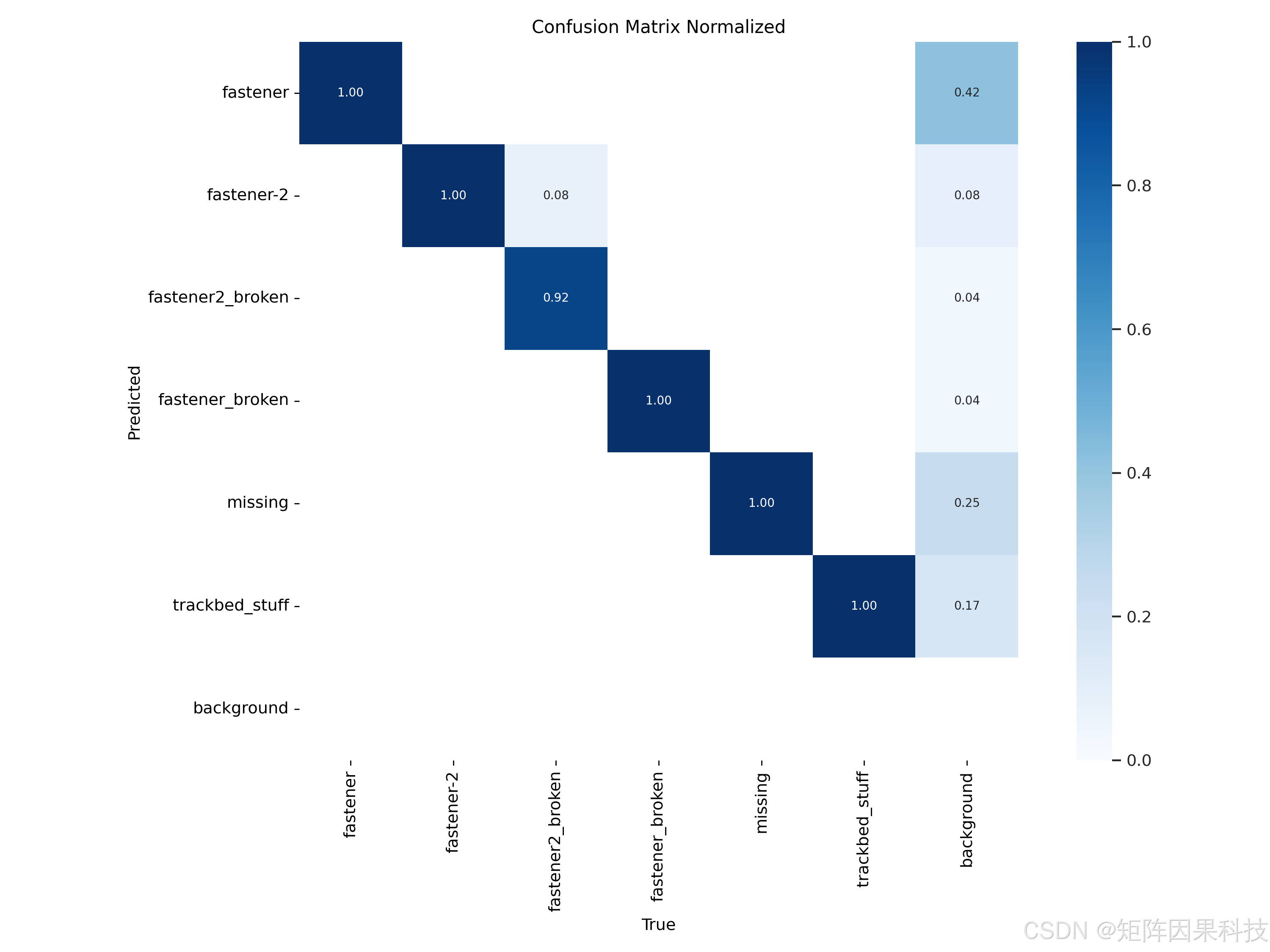
进一步结合混淆矩阵与阈值敏感性可以定位误差来源:归一化混淆矩阵的对角线接近 1,说明主体类别可分性较强,但仍存在“紧固件-2”与“紧固件2_损坏”等相邻语义类的混淆风险,这往往来自损坏程度的连续性与局部遮挡;同时,背景列上不同预测类的占比不为零,意味着仍有一定比例的假阳性来自道砟纹理、反光高亮或结构边缘,这类误检在实际巡检中会造成记录表噪声增多。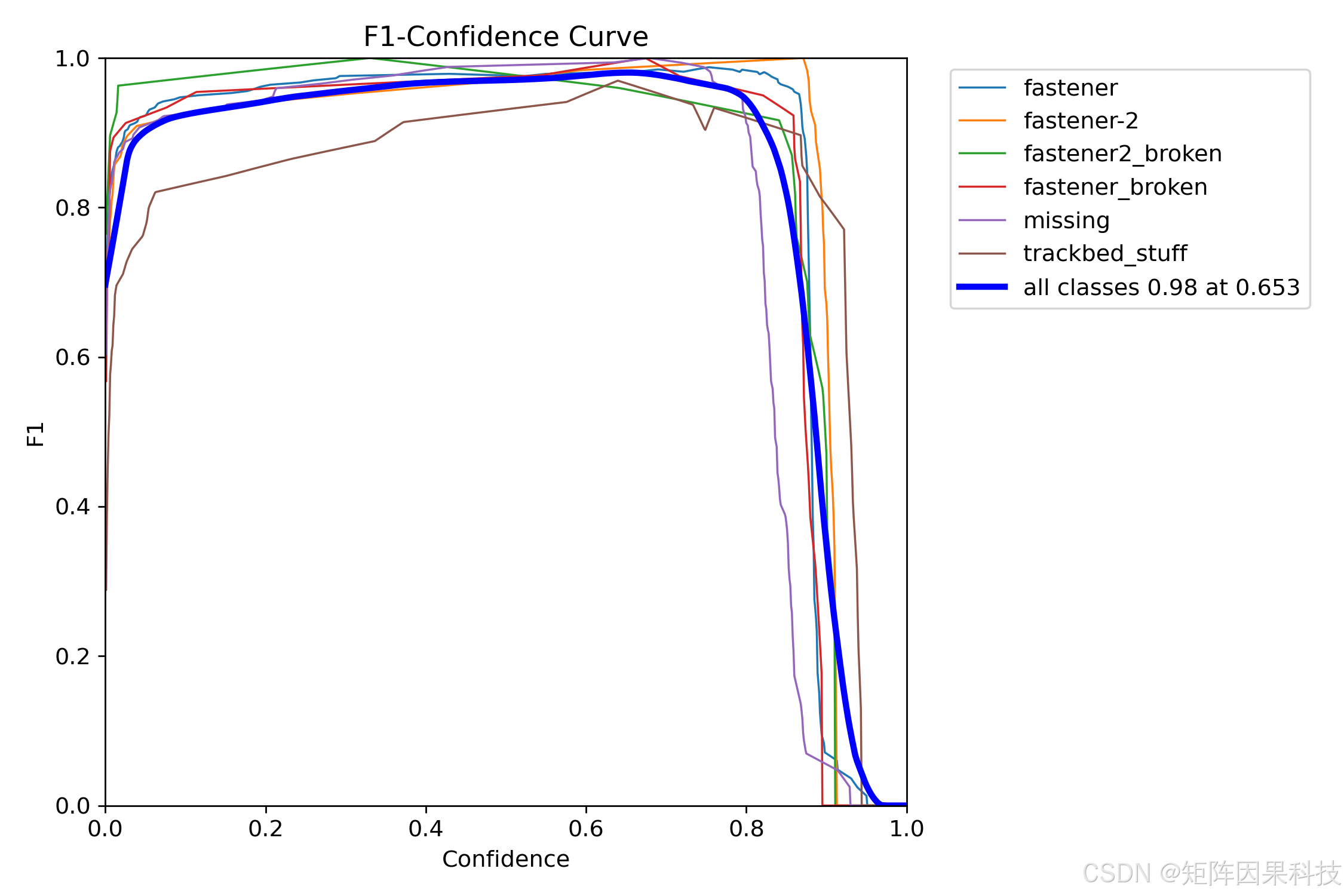
F1-Confidence 曲线给出了更直接的部署建议:全类最优 F1 出现在约 0.65 的置信度附近,说明若目标是“减少误报并保持高 F1”,可将 Qt 端默认 Conf 从偏召回的较低值上调至 0.6 左右;而若现场更关注“缺失/损坏类宁可多报”,则应适当降低 Conf 并通过 IoU 抑制与目标高亮来控制重复框与干扰。综合本章结果,面向桌面端实时检测的默认推荐为 YOLOv8n(轻量实时)或 YOLOv8s(更稳的在线模式),面向高精度复核与导出留档的推荐为 YOLOv9t(n 组最强定位)或 YOLOv12s(全表最佳 mAP50-95),并通过界面热切换让同一批样本在不同模型间快速对比,形成“在线预警—人工复核—结果归档”的闭环。
6. 系统设计与实现
6.1 系统设计思路
本文系统以“可交互的在线检测”为核心目标,采用分层架构将 Qt 桌面端的界面响应、业务会话编排、推理任务调度与数据持久化解耦组织。表现与交互层以 PySide6/Qt 客户端为载体,负责多源输入选择、Conf/IoU 阈值调节、检测结果叠加显示与记录浏览;业务与会话管理层负责源互斥、参数一致性、模型权重热切换与导出编排;推理与任务调度层负责媒体接入、帧分发、YOLO 推理与后处理;数据持久化层将账户、历史记录与配置写入本地 SQLite,并将检测结果以 CSV/PNG/AVI 形式归档,形成可追溯闭环。该分层方式的价值在于:界面侧保持“操作即反馈”的低延迟体验,而算法侧可在不改动交互逻辑的前提下平滑升级 YOLOv5–YOLOv12 的模型族与权重。
在跨层协同流程上,系统以事件驱动的帧流作为主线:图片检测以单次任务触发完成推理并落库记录;视频与摄像头检测则以帧为粒度进入任务队列,按照“读取帧—预处理—推理—后处理—渲染”的顺序循环执行,并在每轮迭代中将阈值参数与模型状态作为只读上下文传入,确保同一段视频内部的判别规则一致。预处理统一采用 640×640 的尺度规范与张量转换,从而使推理端输出的边界框可稳定映射回原图坐标;后处理以 Conf/IoU 过滤与 NMS 抑制为核心,既控制重复框,又为密集部件与相邻目标保留必要的召回空间。界面侧以进度条、用时统计与“目标选择高亮”构成人机协同闭环:当误检来自道砟纹理或反光高亮时,操作者可通过阈值与高亮机制快速完成复核与定位,而不必在大量结果中手动筛选。
在数据与工程一致性方面,系统将“记录—导出—归档”视作检测任务的同等重要输出:一方面,检测记录表将类别、位置、置信度、耗时与来源信息结构化保存,支持跨页共享与快速回查;另一方面,带框结果导出采用时间戳命名与统一归档规则,使同一批次的 CSV 与可视化文件能够一一对应,便于追溯与批量管理。考虑桌面端的稳定性要求,系统在源切换、模型热切换与长视频推理中保持互斥与异常恢复策略,确保界面线程不被阻塞、推理线程可控退出,并在发生错误时保留已完成帧的阶段性结果以降低任务中断成本。
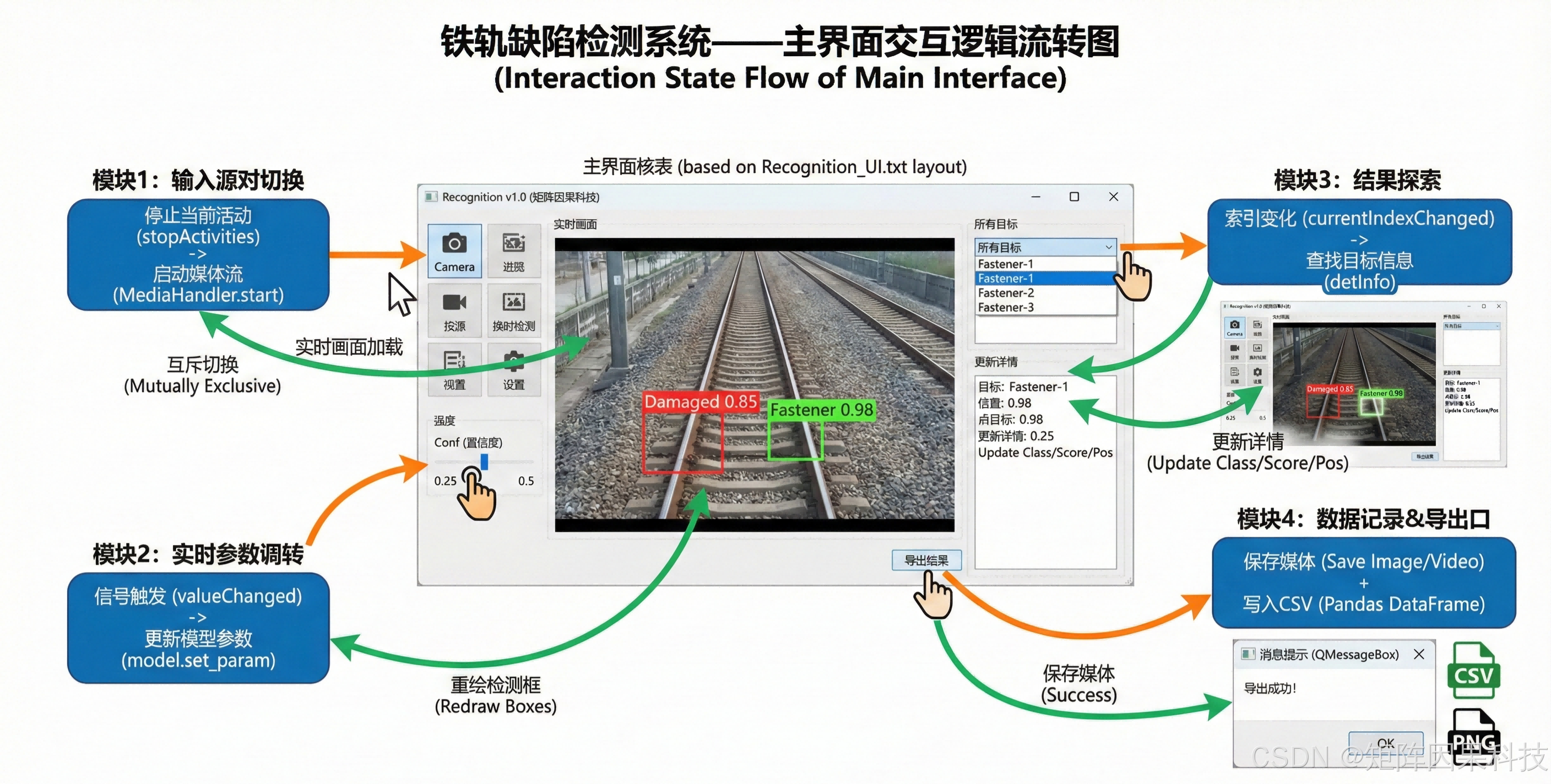
图6-1 系统流程图
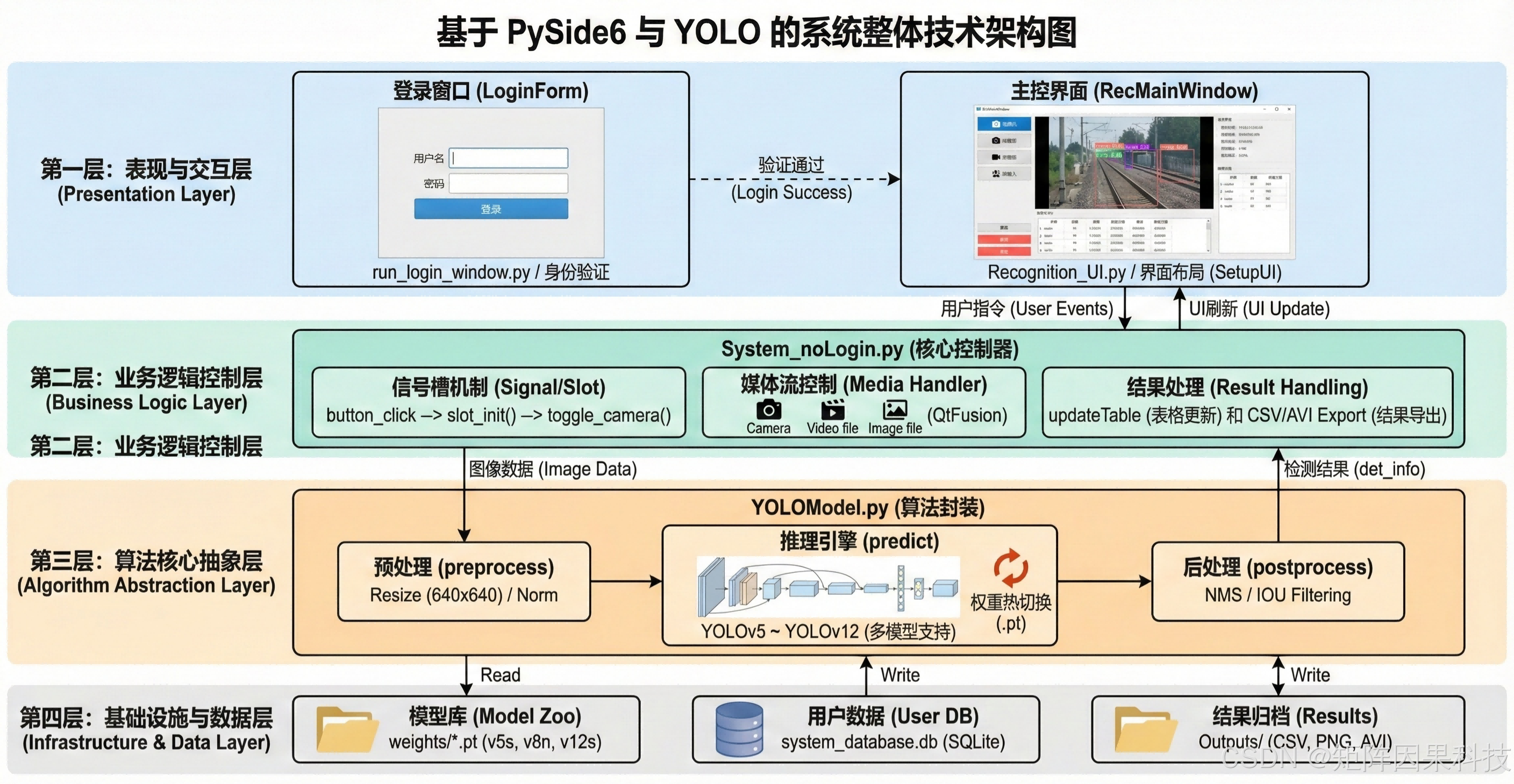
图6-2 系统设计框图
6.2 登录与账户管理 — 流程图
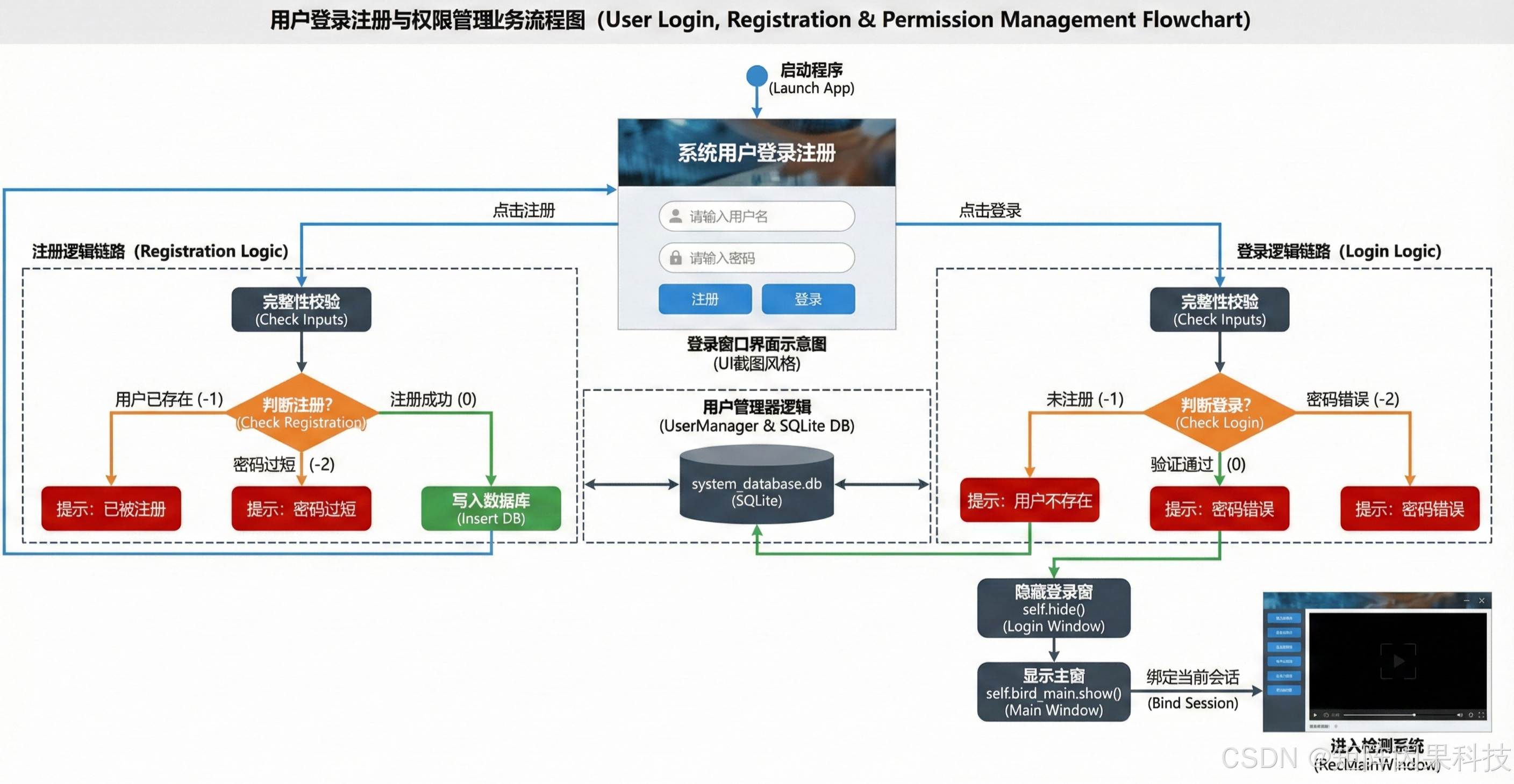
登录与账户管理流程从应用启动进入登录界面开始,系统首先判断用户是否已有账号:对新用户开放注册入口以填写必要信息并写入本地数据库形成账户记录,对已有用户则直接进入账号口令输入;随后由口令校验模块完成凭据核验并在失败时返回重试,从而保证会话建立的安全性与可控性。登录成功后系统载入个性化配置(如主题风格、默认模型与最近记录),使用户在进入主界面后能够以最少的操作恢复到熟悉的工作状态,并将后续多源检测、记录管理与导出归档统一绑定到当前会话上下文;同时系统提供资料修改与注销/切换账号的闭环能力,以保证账户空间隔离、结果可追溯与长期使用过程中的偏好可演进。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件(包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

功能效果展示视频:热门实战|《基于深度学习的铁轨缺陷检测系统》YOLOv12-v8多版本合集:附论文/源码/PPT/数据集,支持图片/视频/摄像头输入、可视化界面、结果导出与权重切换
环境配置博客教程:https://deeppython.feishu.cn/wiki/EwnTwJ2H3iLF6VkNG6ccgZYrnvd;
或者环境配置视频教程:Pycharm软件安装视频教程;(2)Anaconda软件安装视频教程;(3)Python环境配置视频教程;
数据集标注教程(如需自行标注数据):数据标注合集
参考文献(GB/T 7714)
1 NIU M H, SONG K C, HUANG L M, WANG Q, YAN Y H, MENG Q G. Unsupervised saliency detection of rail surface defects using stereoscopic images[J]. IEEE Transactions on Industrial Informatics, 2021, 17(3): 2271-2281. doi:10.1109/TII.2020.3004397.
2 NIU M H, WANG Y Y, SONG K C, WANG Q, ZHAO Y J, YAN Y H. An adaptive pyramid graph and variation residual-based anomaly detection network for rail surface defects[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 70: 5020013. doi:10.1109/TIM.2021.3125987.
3 杜少聪, 张红钢, 王小敏. 基于改进YOLOv5的钢轨表面缺陷检测[J]. 北京交通大学学报, 2023, 47(2): 129-136. doi:10.11860/j.issn.1673-0291.20220132.
4 吴永军, 崔灿, 何永福. 基于语义增广与YOLOv8的钢轨表面缺陷检测方法[J]. 铁道科学与工程学报, 2024, 21(9): 3864-3875. doi:10.19713/j.cnki.43-1423/u.T20231930.
[5] MIN Y Z, LI J F, LI Y X. Rail surface defect detection based on improved UPerNet and connected component analysis[J]. Computers, Materials & Continua, 2023, 77(1). doi:10.32604/cmc.2023.041182.
[6] ZHANG C G, XU D L, ZHANG L F, DENG W. Rail surface defect detection based on image enhancement and improved YOLOX[J]. Electronics, 2023, 12(12): 2672. doi:10.3390/electronics12122672.
[7] WANG Y, ZHANG K H, WANG L, WU L T. An improved YOLOv8 algorithm for rail surface defect detection[J]. IEEE Access, 2022. doi:10.1109/ACCESS.2022. (以论文正式出版信息为准).
[8] REDMON J, DIVVALA S, GIRSHICK R, FARHADI A. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788.
[9] ZHAO Y, LV W, XU S L, WEI J M, WANG G Z, DANG Q Q, LIU Y, CHEN J. DETRs beat YOLOs on real-time object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024. arXiv:2304.08069.
[10] WANG A, CHEN H, LIU L H, CHEN K, LIN Z J, HAN J G, DING G G. YOLOv10: Real-time end-to-end object detection[C]//Advances in Neural Information Processing Systems. 2024. arXiv:2405.14458.
[11] WANG C Y, YEH I H, LIAO H Y M. YOLOv9: Learning what you want to learn using programmable gradient information[EB/OL]. arXiv:2402.13616, 2024.
[12] Ultralytics. Ultralytics YOLO11 documentation[EB/OL]. 2024.
[13] Ultralytics. YOLO12: Attention-centric object detection documentation[EB/OL]. 2025.
[14] JOCHER G. YOLOv5 by Ultralytics[EB/OL]. Zenodo, 2020. doi:10.5281/zenodo.3908559.
[15] REN S Q, HE K M, GIRSHICK R, SUN J. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems. 2015. arXiv:1506.01497.
[16] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//Computer Vision–ECCV 2016. Cham: Springer, 2016: 21-37. arXiv:1512.02325.
[17] LIN T Y, GOYAL P, GIRSHICK R, HE K M, DOLLÁR P. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2980-2988. arXiv:1708.02002.
[18] CARION N, MASSA F, SYNNAEVE G, USUNIER N, KIRILLOV A, ZAGORUYKO S. End-to-end object detection with transformers[C]//Computer Vision–ECCV 2020. Cham: Springer, 2020: 213-229. arXiv:2005.12872.
[19] TAN M X, PANG R M, LE Q V. EfficientDet: Scalable and efficient object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10781-10790. arXiv:1911.09070.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)