【Linux 网络】带你理清 IP协议、子网划分与跨网路由
#linux网络
一、 网络层与 TCP/IP 体系架构
1.1 OSI 与 TCP/IP 模型映射
-
概念解释:OSI(开放系统互联)模型是网络通信的七层理论标准,而 TCP/IP 则是实际广泛采用的四层实现模型。二者存在清晰的层级映射关系。
-
笔记:
-
应用层:OSI 的应用层、表示层、会话层统一对应 TCP/IP 的应用层(常见协议:Telnet, FTP, SMTP, POP, SNMP, HTTP等)。
-
传输层:对应 TCP/IP 的传输层(核心协议:TCP, UDP)。
-
网络层:对应 TCP/IP 的网络层(核心协议:IP, ICMP, IGMP)。
-
网络接口层:OSI 的数据链路层和物理层对应 TCP/IP 的网络接口层(常见技术:以太网, 令牌环, 帧中继等)。
-
核心功能差异:
-
网络层:“我只负责 100% 将数据发送到对方网络节点!”(提供点对点的网络可达性)。
-
TCP协议:“把数据 100% 可靠地,从 A 主机跨网络无误发送到 B 主机!”(提供端到端的可靠性)。
-
-
1.2 局域网 (LAN) 与 广域网 (WAN)
-
概念解释:局域网是局部范围内(如公司、学校)主机互联的高速网络;广域网则是将多个不同地理位置的局域网连接起来的大型网络。
-
笔记:
-
透明性原则:在 IP 网络之上,底层细节对上层是透明的。
-
全网唯一性标识:必须有统一的方式标识网络节点,IP 协议及其衍生的 IP 地址专门用于解决全网唯一性寻址问题。
-
路由器、网关等设备既是网络节点,也负责路由控制。
-
💡 发散提问:为什么跨网络交互必须依赖路由器?
解答:不同局域网(子网)的物理信道是隔离的,广播无法跨越网段。路由器具备多个网卡口(如 WAN/LAN),能同时接入多个不同的子网,它像一个“十字路口调度员”,负责提取数据包的目标 IP,并根据路由表为其指派下一条物理路径。
二、 IPv4 报文头与核心数据结构
2.1 IPv4 报文头结构(20字节标准+选项)
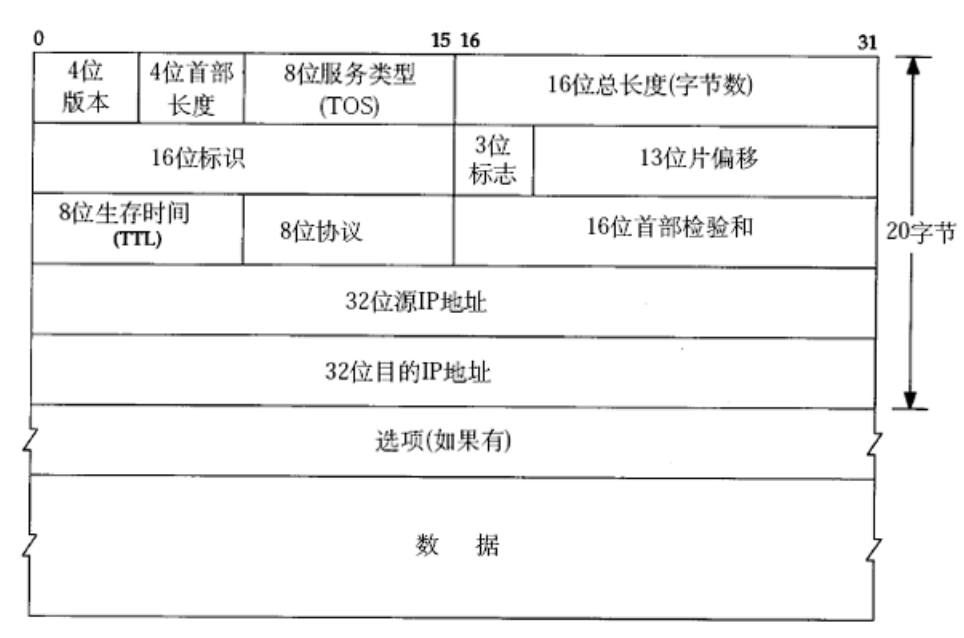
-
概念解释:IP报文头封装在数据报最前端,包含寻址、分片、生存期等网络层转发所需的所有关键元数据。
-
笔记:
-
4位版本号 (Version):指定 IP 协议版本(IPv4 为 4)。
-
4位首部长度 (IHL):表示头部占多少个 32 bit(4字节)。最大值为 15,因此 IP 头部最大长度为 60 字节(20字节固定 + 最多40字节选项)。
-
8位服务类型 (TOS):含 3 位优先权(已弃用),4 位 TOS 字段(分别代表:最小延时、最大吞吐量、最高可靠性、最小成本,四者互斥只能选一),以及 1 位保留位(置0)。注:ssh/telnet 需最小延时;ftp 需最大吞吐量。
-
16位总长度 (Total Length):IP 数据报整体的总字节数。
-
16位标识 (Identification):唯一标识主机发送的完整报文,用于 IP 分片重组。
-
3位标志 (Flags):第一位保留;第二位为“禁止分片”(DF),若报文超限且 DF=1 则丢弃;第三位为“更多分片”(MF),分片末尾包置 0,其余置 1。
-
13位片偏移 (Fragment Offset):表示当前分片在原始报文中的起始位置。单位为 8 字节(除最后一片外,每片长度必须是 8 的整数倍)。
-
8位生存时间 (TTL):报文最大可经过的路由器跳数(通常设为 64)。每过一跳减 1,为 0 时丢弃,核心作用是防止网络中出现路由死循环。
-
8位协议 (Protocol):标识上层传输层使用的协议类型(如 TCP/UDP)。
-
16位首部校验和:使用 CRC 算法校验头部数据是否在传输中损坏。
-
32位源 IP 地址 & 32位目的 IP 地址:标明发送端和接收端。
-
2.2 涉及的核心结构:sk_buff
-
结构名:
sk_buff(Linux 内核网络数据包缓存结构) -
伪代码模型:
struct sk_buff { unsigned char *head; // 缓冲区头 unsigned char *data; // 当前协议数据起始位 unsigned char *tail; // 数据尾 unsigned char *end; // 缓冲区尾 // ... 其他控制信息 }; -
功能与参数说明:内核利用这些指针,在不对数据进行内存拷贝的情况下,通过移动
data和tail指针,实现跨协议层(MAC头 -> IP头 -> TCP/UDP头 -> 应用数据)的动态剥离与封装。
三、 链路层限制与 IP 分片
3.1 MTU 与报文痛点
-
概念解释:MTU (Maximum Transmission Unit, 最大传输单元) 是数据链路层(如以太网)单次能够传输的最大有效载荷大小。
-
笔记:
-
网络传输存在一个巨大痛点:应用层/传输层传下来的数据报文可能太大了!
-
以太网帧的 MTU 通常被严格限制为 1500 字节。如果 IP 层整体数据包超过此大小,就会被链路层拒绝,必须在网络层进行切割。
-
3.2 IP 分片机制解析
-
概念解释:当 IP 数据包超出 MTU 时,IP 层会将其拆分为多个独立的小报文在网络中传输,并在接收端重新组装的技术。
-
笔记:
-
身份绑定:同一个原始数据包切出来的所有分片,拥有相同的 16位标识 (ID)。
-
顺序重组:接收方通过 13位片偏移 得知当前碎片在原包中的确切相对位置,从而按序拼装。
-
完整性判定:依靠 3位标志中的 MF 位(More Fragments)。MF=1 意味着后方还有分片;当收到 MF=0 的分片时,即代表这是最后一块,拼装结束。
-
四、 IP 地址分类、子网划分与 CIDR
4.1 传统五类 IP 划分法
![![[Pasted image 20260517181115.png]]](https://i-blog.csdnimg.cn/direct/4ac0cc8fdf41410389f9a45aeb89568c.png)
-
笔记:早期通过前导位划分网络号和主机号(图源 TCP/IP):
-
A类:0.x.x.x 到 127.x.x.x (网络号8位,主机号24位)
-
B类:128.x.x.x 到 191.x.x.x (网络号16位,主机号16位)
-
C类:192.x.x.x 到 223.x.x.x (网络号24位,主机号8位)
-
D类:224.x.x.x 到 239.x.x.x (组播地址)
-
E类:240.x.x.x 到 247.x.x.x (保留)
-
局限性:大多数组织申请 B 类地址(容纳 6.5 万主机),导致 B 类枯竭,而 A 类地址(容纳 1600 万主机)严重浪费,实际子网中根本用不了这么多主机。
-
4.2 CIDR (无类别域间路由) 与子网掩码
-
概念解释:为了解决传统分类法的浪费,CIDR 引入了子网掩码 (Subnet Mask),通过与操作动态区分网络号与主机号,实现更细粒度的网段划分,以隔离广播域。
-
笔记:
-
子网掩码通常是结尾为一串
0的 32 位正整数。 -
核心计算公式:
IP 地址 & (按位与) 子网掩码 = 网络号。 -
表示法示例:
140.252.20.68/24表示高 24 位是掩码 1,即255.255.255.0。 -
案例分析:
![![[Pasted image 20260517181940.png]]](https://i-blog.csdnimg.cn/direct/e9665788baf848c8be2aa862ba016d99.png)
-
4.3 特殊 IP 地址与资源枯竭对策
-
概念解释:DHCP (动态主机配置协议) 是一种自动分配内部 IP 的技术;Loopback (环回接口) 是一块虚拟网卡,用于本机内部网络进程间的通信测试。
-
笔记:
-
特殊规定:主机号全 0 代表局域网网络号;主机号全 1 代表当前局域网的广播地址。
127.*(常用 127.0.0.1) 留作本机环回测试。 -
IPv4 总数约 43 亿,并非每台机器固定一个,而是每个网卡分配 IP。CIDR 提高了利用率但没增加绝对数量。
-
三大解决耗尽方案:
-
动态分配:DHCP 按需自动分配。
-
NAT 技术:私网IP映射公网IP(见模块五)。
-
IPv6:128位地址,彻底解决数量问题,但不向下兼容 IPv4。
-
-
五、 公私网隔离、路由可达与 NAT 技术
5.1 局域网寻址 (ARP) 与默认网关
-
概念解释:ARP (地址解析协议) 用于在同一个局域网内,通过目标机的 IP 地址广播查询对应的物理 MAC 地址。
-
笔记:
-
同网段互访:同一个网络内,ARP 广播寻找目标 MAC 地址。
-
跨网段互访:如果发现目标 IP 不在当前子网,直接将 MAC 目标指向默认网关(本子网的出口路由器)。
-
5.2 私有 IP 与 公网 IP
![![[Pasted image 20260517181410.png]]](https://i-blog.csdnimg.cn/direct/00c697b803fa4a07a038688da3888648.png)
-
笔记:
-
私有 IP (RFC 1918 规定):
-
10.x.x.x (10.0.0.0/8)
-
172.16.x.x ~ 172.31.x.x (172.16.0.0/12)
-
192.168.x.x (192.168.0.0/16)
-
-
核心定律:私有 IP 仅在局域网内可见,绝不允许出现在公网上进行路由! 公网 IP 全网唯一,由 ICANN 顶级机构树状向下划分(全球大区 -> 国家级骨干网 -> 省市级 -> 互联网公司出口)。
-
5.3 NAT (网络地址转换) 核心逻辑
-
概念解释:NAT (Network Address Translation) 是将处于内网的私有 IP 数据包,在经过出口路由器时,篡改替换为合法的公网 IP 的技术。
-
笔记:
-
任何路由器至少配有两个 IP 地址:一个是连接内网的 LAN 口 IP(通常是网关,如 192.168.1.1),一个是连接外网/上级路由的 WAN 口 IP。
-
数据包通过内网出口时,路由器将其源 IP 强行替换为 WAN 口的公网 IP,并在内部维护一张映射表。
-
如果开发者想让自建服务器在公网上被任意访问,必须购买具有外网独立 IP 的云服务器(如阿里云、腾讯云等)。
-
💡 发散提问:既然私网 IP 各个局域网都在重复使用(比如大家的家里都是 192.168.1.x),当外网服务器把数据返回给 NAT 路由器时,路由器怎么知道该把包发给内网的具体哪台手机或电脑?
解答:这就涉及到 NAT 的进阶形式 NAPT(网络地址端口转换)。路由器在替换 IP 时,连同源端口号一起进行了替换和记录。当公网数据返回给路由器的特定端口时,路由器通过反查 NAT 映射表,就能精确地将数据送回内网的指定主机的指定端口。
六、 路由表与 Hop-by-Hop 转发机制
6.1 唐僧问路 (Hop by Hop) 与路由表匹配
-
概念解释:路由过程就像“问路”,数据链路层负责“一跳(Hop)”(如从源MAC到下一站MAC的具体路段),而 IP 层实现最终目标的“点对点”规划。每到达一个路由器,都会查表决定下一步。
-
笔记:
-
主机和路由器内部都维护一张路由表 (Routing Table),可通过
route -n(或类似命令)查看。 -
核心转发判断逻辑:
-
提取 IP 数据包的目的 IP。
-
遍历路由表:使用目的 IP 与表中的
Genmask(子网掩码) 进行按位与运算。 -
如果运算结果等于表中的
Destination(目标网段),则说明命中路由! -
将数据从对应的
Iface(网络接口) 转发给Gateway(下一跳地址)。
-
-
6.2 缺省路由 (Default Route)
-
笔记:
-
如果目的 IP 与所有特定路由条目都匹配不上怎么办?
-
路由表中最后一行通常为
0.0.0.0缺省条目(默认路由)。这表示:“我不认识这个目标,但我知道把它发给上一级大佬(出口路由器/网关),由大佬接力处理。”
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)