RAG进化论:多模态融合×动态检索优化实战手册
多模态RAG
Faiss
FAISS:
核心特质:作为Facebook自主研发的成果,FAISS将核心发力点锚定在高性能相似性搜索领域,尤其适配大规模静态数据集的应用场景。
突出优势:检索效率极为出众,同时具备丰富的索引类型,可灵活匹配多元需求。
应用短板:其应用场景多集中于静态数据,在数据更新与删除环节,操作流程相对繁琐。
本质上,FAISS是一款专业的数学工具,能够高效完成特定向量与向量矩阵间相似度的精准测算。
索引构架
Step1,Word文档精准解析
调用 parse_docx() 函数,对DOCX文档展开深度遍历,精准提取段落文本与表格内容,并将其规范转换为Markdown格式,为后续处理筑牢基础。
Step2,文本智能切分
运用 split_text() 函数,依据设定规则对文本进行切分。设定 chunk_size=500字符 为固定切分长度,同时设置 overlap=50字符 实现相邻文本块的重叠衔接,保障信息连贯性。
Step3,多模态Embedding统一处理
采用 tongyi-embedding-vision-plus 模型,对文本、图片、视频等多模态数据进行一体化处理:
- 文本:直接开展编码工作,高效提取核心特征。
- 图片:先进行Base64编码,再发送至模型进行处理。
- 视频:通过多帧提取技术,获取各帧向量后取平均值,精准捕捉视频核心信息。
Step4,FAISS索引高效构建
选用 IndexFlatL2 索引类型,依托L2距离(欧氏距离)构建精确搜索索引,为快速精准检索提供有力支撑。
Step5,数据持久化存储
将构建完成的索引保存为 disney_index.faiss,元数据同步存储至 disney_metadata.json,实现数据的稳定留存与便捷调用。
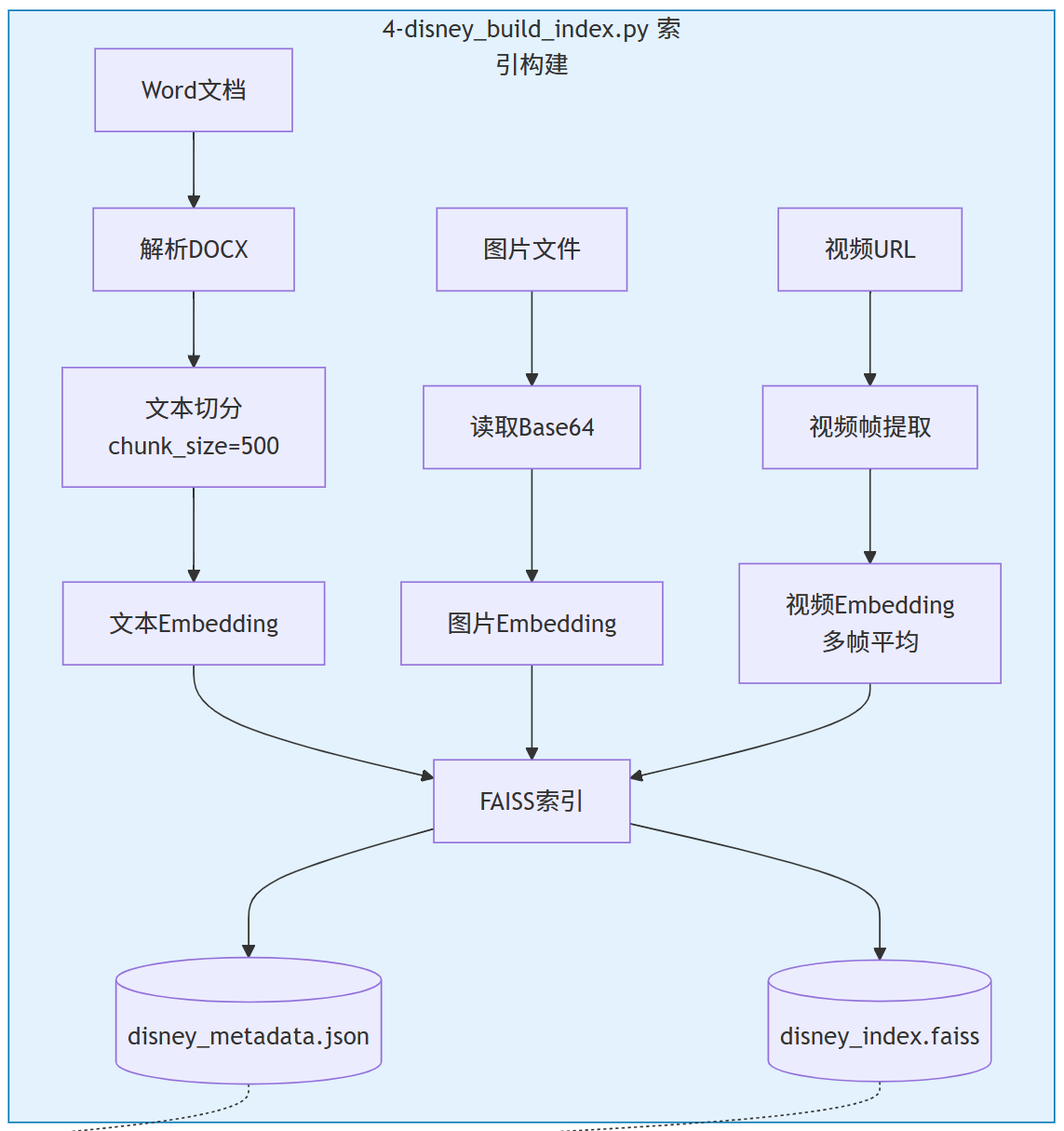
多模态Embedding处理流程:
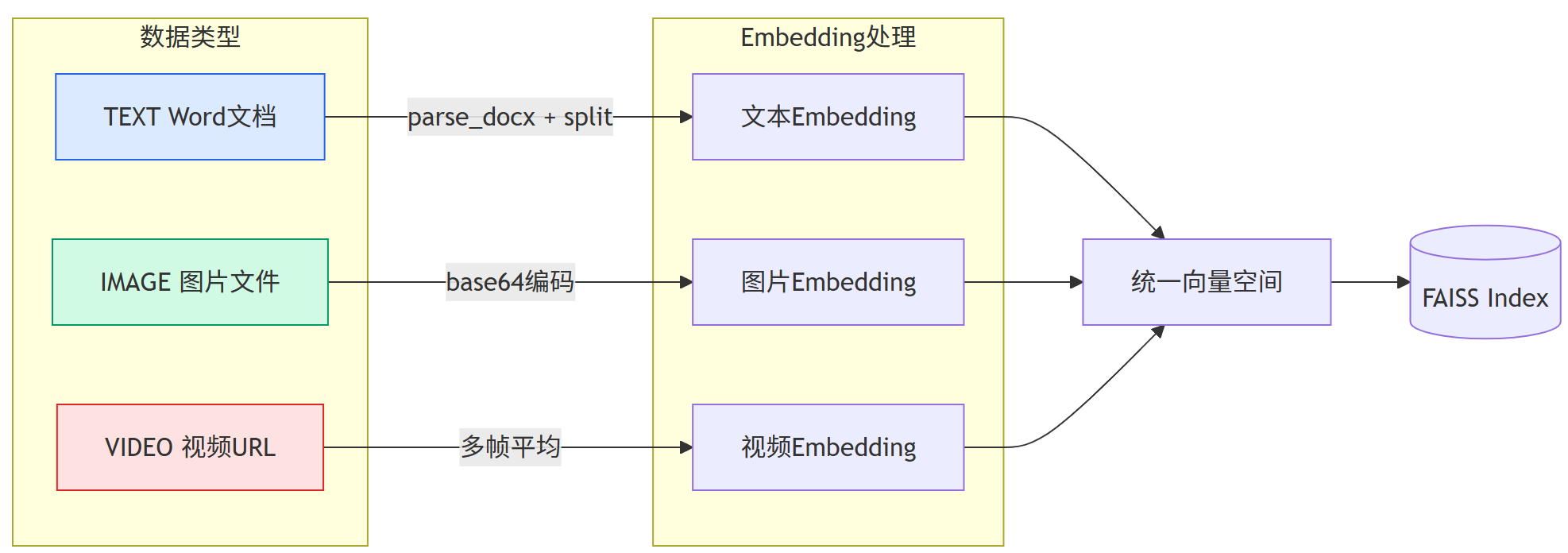
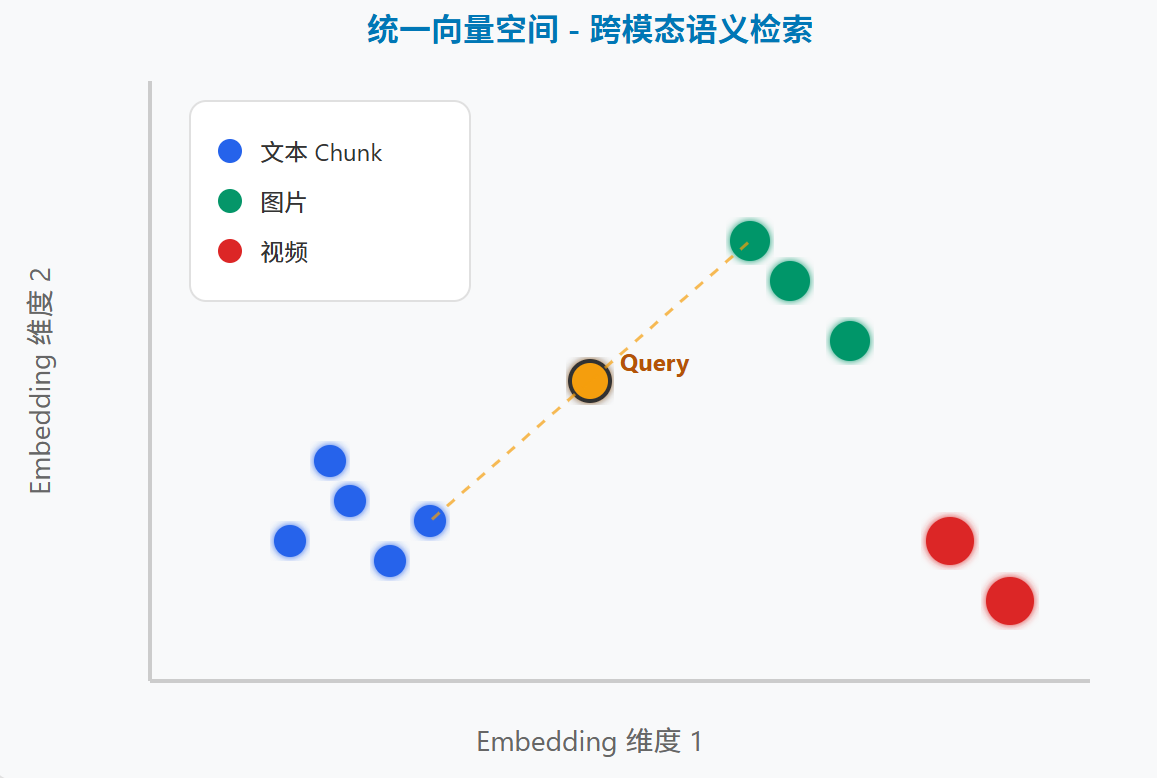
多模态统一向量空间
文本、图片、视频通过同一Embedding模型映射到统一向量空间,实现跨模态语义检索
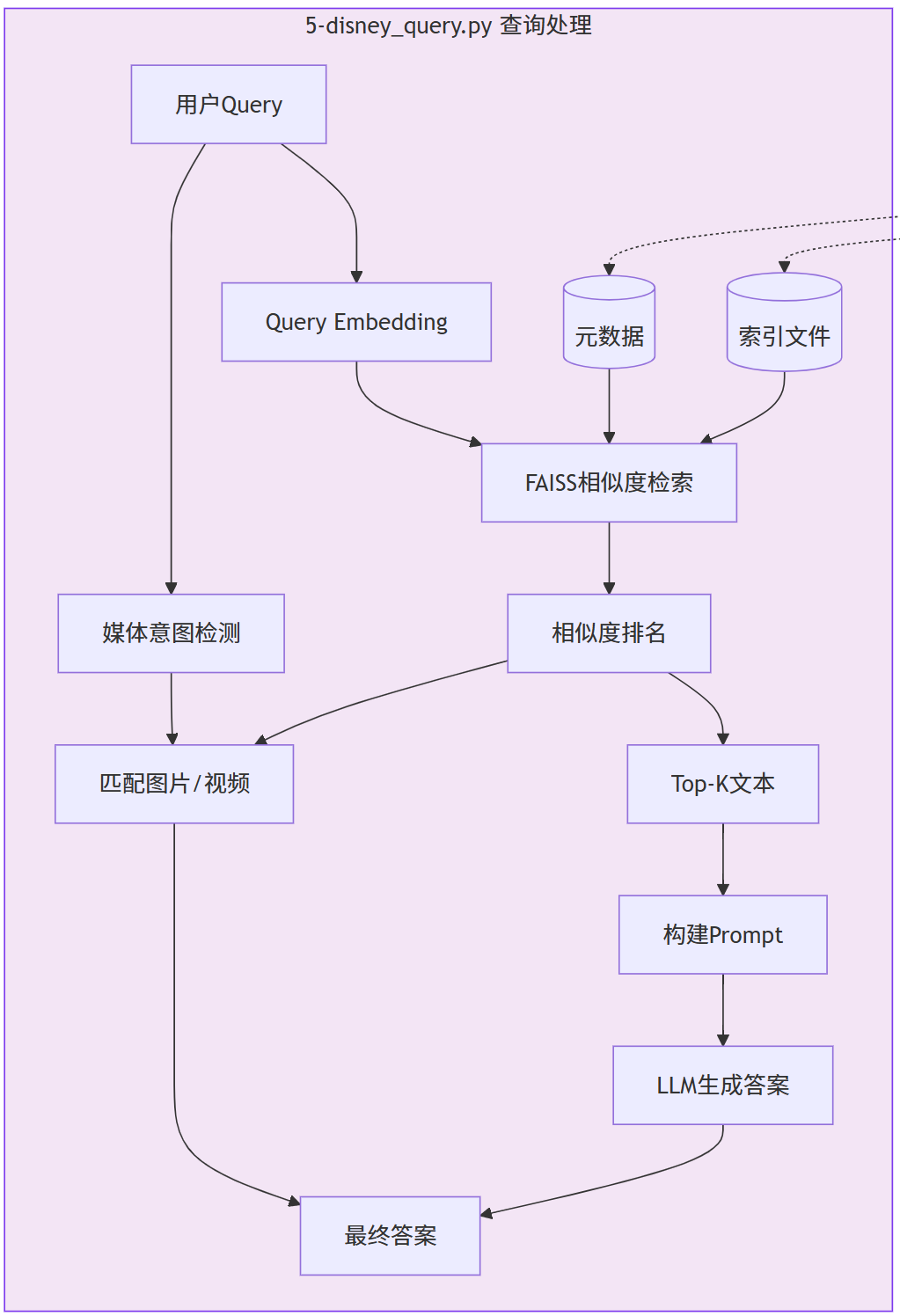
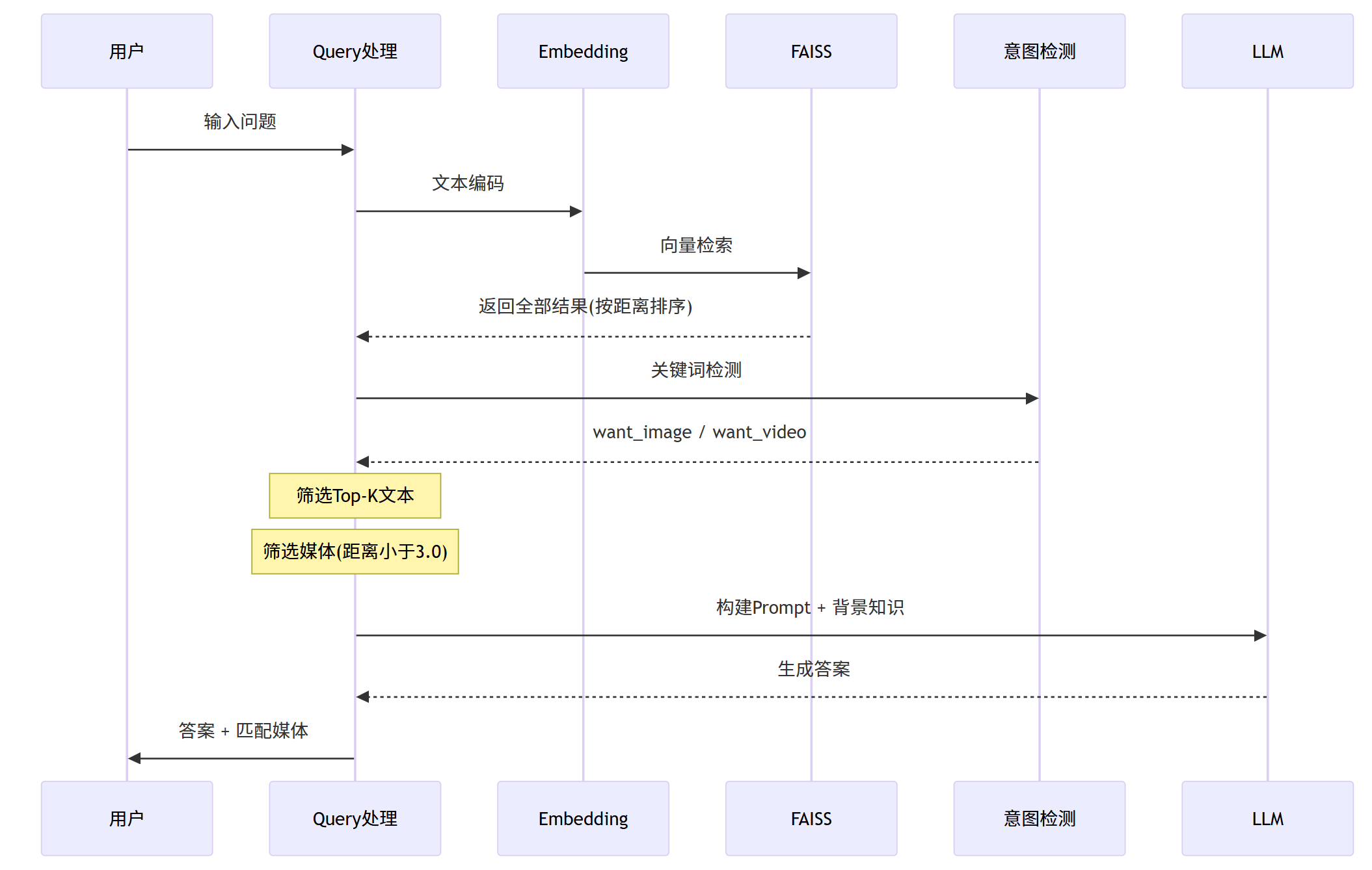
Query查询处理
Step1:问题向量化
将用户提问转化为向量,确保与索引向量处于同一空间。
Step2:索引加载
调用 load_index(),从文件快速载入FAISS索引与元数据JSON。
Step3:相似度检索
全面检索所有记录,按L2距离排序,通过 sim = 1/(1+distance) 换算相似度。
Step4:媒体意图识别
关键词精准匹配,图片类关键词涵盖“图片、海报、照片”等,视频类包含“视频、录像、播放”等。
Step5:结果甄选
- 文本:默认选取Top-K(K=3)结果
- 图片/视频:仅保留距离小于3.0的最近匹配项
Step6:LLM答案生成
搭建Prompt(融合背景知识与用户问题),调用 qwen-flash 输出答案。
多模态数据处理双路径
- 文本转化方案:将图片、视频等多模态数据统一转为文本,搭配多组embedding分别开展检索工作,适配轻量化处理需求
- 多模态直用方案:直接启用多模态embedding,一站式处理文本、图片、视频等各类数据,贴合原生多模态处理诉求
RAG完整工作流
标准执行流程:
先对信息开展embedding处理,紧接着依托faiss搭建索引并同步完善元数据,随后启动相似度检索,最后调用LLM开展推理运算,精准输出文字内容。

查询处理流程:
Disney原生RAG助手完整搭建流程
Step1:夯实数据底座
- 文档精准解析:聚焦Word文档(.docx),深度提取文本段落与表格信息,统一转换为Markdown格式,筑牢数据基础
- 文本规范切分:采用固定长度切片模式,按500字符拆分成chunk,设置50字符重叠区间,保障上下文连贯性
Step2:构建高效向量化体系
- 统一多模态Embedding:接入阿里云通义tongyi-embedding-vision-plus多模态模型,实现文本、图片、视频等多类型数据的统一向量化处理
- 单索引集中存储:依托FAISS搭建单索引系统,集中存储所有模态的向量数据,简化索引管理复杂度
Step3:打造精准检索引擎
- 统一编码检索:将用户文本query通过同一多模态模型编码,以L2距离作为核心检索依据,保障跨模态检索的一致性
- 关键词精准触发:自动检测"海报""视频"等特定关键词,快速触发对应媒体类型的精准过滤,提升检索针对性
Step4:优化智能生成环节
- 文本上下文构建:召回Top-K文本结果,针对性搭建上下文Prompt,为生成环节注入充足背景信息
- 媒体链接自动附加:自动同步匹配到的图片、视频链接,让生成答案兼具文本内容与媒体资源,提升信息呈现完整性
三种RAG模式解析
核心特征深度解析
1. Agentic RAG:AI主导的「动态工具调用型RAG」
核心逻辑:AI自主判断是否需要检索、调用哪个工具检索,将「检索」作为可灵活调用的工具之一,而非固定流程。
- 决策自主性:AI完全主导,属于「软约束」——没有预设的检索触发条件,AI根据当前问题、已掌握的信息和目标,自主判断「是否需要检索」「调用哪个检索工具」(比如搜索引擎、数据库、向量库等),甚至决定是否多次检索、切换工具。
- 流程灵活性:无固定流程,完全动态适配。比如用户问「2024年全球AI融资规模Top5的企业及融资额」,AI会先判断自身知识库缺乏最新数据,主动调用「联网检索工具」获取数据;若检索后发现数据不完整,可能再次调用「专业数据库工具」补充,整个过程由AI自主决策,没有预设的「先检索再生成」的强制顺序。
- 关键补充:这里的「工具调用」是广义的,不仅包括检索工具,还可能涉及计算、查询、数据处理等工具,但核心是「检索行为由AI主动触发,而非被动执行」,AI具备对「检索必要性」的判断能力。
- 适用场景:复杂开放问题、需要实时/动态信息的场景、多步骤推理任务(比如用户需要先检索数据,再基于数据做分析,最后生成报告,AI自主串联整个流程)。
2. Native RAG:固定流程的「顺序执行型RAG」
核心逻辑:检索是生成的前置固定步骤,流程严格按照「先检索→再生成」的顺序执行,AI无决策空间,属于「硬约束」。
- 决策自主性:AI无自主决策权,检索是强制流程。无论问题是否简单、AI是否已掌握足够信息,系统都会在生成回答前,先触发检索流程(比如从预设的向量库、文档库中检索相关片段),再基于检索结果生成回答。
- 流程灵活性:完全固定,不可调整。流程是线性的、预设的:用户提问→触发检索模块→获取检索结果→将结果与问题输入LLM→生成回答。比如用户问「《红楼梦》的作者是谁」,即使AI已明确知道答案,系统仍会先执行检索流程,再生成回答,不存在AI自主跳过检索的可能。
- 关键补充:这里的「Native」本质是「原生嵌入流程」,检索是系统底层架构中预设的、不可跳过的环节,而非可选工具,AI的角色是「执行预设流程」,而非「决策流程」。
- 适用场景:对流程合规性要求高的场景(比如法律文书生成、合规报告生成)、信息源固定且需要强制溯源的场景、简单问题的标准化回答(确保回答严格基于预设知识库,避免AI幻觉)。
3. Graph RAG:知识图谱驱动的「结构化检索增强型RAG」
核心逻辑:以知识图谱为核心,通过LLM构建/利用结构化知识,实现关联检索与深度推理,核心是「知识结构化+关联检索」,而非单纯的文本片段检索。
- 决策自主性:AI主导知识图谱的构建与检索逻辑,但流程有明确目标——围绕「知识关联」展开。LLM的核心作用是对原始数据(文本、表格等)进行分析,提取实体(比如人物、事件、概念)、关系(比如因果、从属、关联),构建社区(关联紧密的实体集合),形成结构化知识图谱;检索时,不是检索孤立的文本片段,而是基于图谱的关联关系,检索实体、关系、社区,实现「关联推理检索」。
- 流程灵活性:流程围绕「图谱构建→图谱检索→推理生成」展开,有明确的核心逻辑,但检索过程基于图谱的关联关系,而非固定顺序。比如用户问「人工智能的发展如何影响医疗行业的就业结构」,Graph RAG会先从图谱中检索「人工智能」相关实体、与「医疗行业」的关联关系,再检索「就业结构」相关的实体和社区,通过图谱的关联路径,找到跨领域的关联信息,而非单纯的关键词匹配检索。
- 关键补充:Graph RAG的核心价值是「突破文本片段的局限,捕捉知识间的深层关联」,通过图谱的结构化特性,让AI具备「关联推理」能力,解决传统RAG中「检索碎片化、缺乏逻辑关联」的问题。比如传统RAG可能检索到零散的「AI医疗应用」和「就业变化」的文本,而Graph RAG能通过图谱找到两者的因果关联,生成更有逻辑的回答。
- 适用场景:需要深度推理、跨领域关联分析的场景(比如科研分析、产业链分析、事件因果推理)、复杂知识体系问答(比如历史事件关联、专业知识体系问答)、需要构建结构化知识库的场景。
三种模式核心差异对比表
| 对比维度 | Agentic RAG | Native RAG | Graph RAG |
|---|---|---|---|
| 核心逻辑 | AI自主决策调用检索工具 | 检索是生成的前置固定步骤 | 以知识图谱为核心,实现关联检索与推理 |
| 决策自主性 | AI完全主导(软约束,自主判断) | 无自主决策(硬约束,强制执行) | AI主导图谱构建与关联检索,目标明确 |
| 流程灵活性 | 动态灵活,无固定流程 | 完全固定,线性执行 | 基于图谱关联,流程围绕结构化知识展开 |
| 检索核心 | 按需调用工具,检索是可选环节 | 强制检索,检索是必选环节 | 基于知识图谱的实体/关系/社区关联检索 |
| AI角色 | 流程决策者,主动触发检索 | 流程执行者,被动完成检索 | 知识构建者+关联检索执行者,主导推理 |
| 核心优势 | 适配复杂场景,灵活响应 | 流程合规,可控性强 | 具备深度推理能力,知识关联性强 |
| 核心局限 | 依赖AI决策能力,可控性弱 | 流程僵化,无法适配灵活需求 | 图谱构建成本高,对LLM结构化能力要求高 |
| 典型场景 | 复杂开放问题、实时信息查询 | 合规场景、标准化知识问答 | 深度推理、跨领域关联分析、复杂知识问答 |
三者的本质区别与底层逻辑
-
决策权的差异:
- Agentic RAG:决策权在AI,AI决定「是否检索、如何检索」,是「主动型RAG」;
- Native RAG:决策权在系统预设流程,AI只能执行「先检索再生成」,是「被动型RAG」;
- Graph RAG:决策权在AI对知识图谱的构建与关联检索逻辑,核心是「用结构化知识驱动检索」,是「推理型RAG」。
-
检索的本质不同:
- Agentic RAG的检索是「工具化服务」,检索是众多可选工具中的一项,按需调用;
- Native RAG的检索是「流程化环节」,检索是生成的前提,不可跳过;
- Graph RAG的检索是「关联化检索」,检索的是结构化知识(实体、关系、社区),而非孤立文本,核心是捕捉知识关联。
-
核心目标的差异:
- Agentic RAG:追求「灵活适配复杂需求」,让AI具备自主决策能力,应对开放性问题;
- Native RAG:追求「流程可控与合规」,确保回答严格基于预设知识,避免AI幻觉;
- Graph RAG:追求「深度推理与关联分析」,突破文本局限,捕捉知识深层逻辑,解决复杂推理问题。
四、一句话总结三者本质
- Agentic RAG:AI自主决策的「动态工具化检索」,让检索成为AI可灵活调用的能力,而非固定流程;
- Native RAG:预设流程的「强制顺序化检索」,让检索成为生成的前置必选项,确保流程合规,90%的项目可直接采用NativeRAG,可参考我之前写的文章 RAG技术爆火背后:它到底解决了什么难题?这一篇讲透核心与应用;
- Graph RAG:知识图谱驱动的「结构化关联检索」,让检索基于知识关联,实现深度推理,而非孤立文本匹配。
RAG高级调优
从不同的维度对RAG进行调优:
- 对知识进行调优(知识库处理):
- 入库前,对知识进行切片,对知识做二次加工,问题生成 & 对话沉淀;
- 入库后, 健康度检查 & 版本管理;
- 高效召回:
- 混合检索: BM25 + Vector、做重排序筛选;
- 精细排序: Rerank 模型与LLM打分;
- 查询优化: MultiQuery & 改写;
- 使用GraphRAG知识图谱:
- 图谱构建: 依托实体抽取与社区摘要的核心方法,搭建系统化的知识图谱体系。这一过程前期投入成本较高,核心精力集中于数据预处理环节,为后续知识关联检索筑牢基础。
- 检索模式: 进入检索阶段,采用Global(全局)与Local(局部)双轨查询模式,充分适配大规模数据场景,兼顾全局信息统筹与局部精准匹配,实现高效检索。
- 使用agentic RAG智能决策:
可参考qwenAgent框架,该方法能够自主高效推进任务落地,按能力层级划分为三大阶段:- Level 1:基础RAG——实现常规检索与信息匹配,搭建智能决策的底层根基;
- Level 2:并行阅读——支持多源信息同步整合,提升信息获取与处理效率;
- Level 3:多跳推理——突破单步检索局限,实现多环节逻辑串联,精准攻克复杂关联问题。
坚实地基:知识库处理
知识库问题生成与检索优化
当用户提问与知识切片的语义相似度不足时,通过LLM为知识切片预生成问题,以“问题-问题”的匹配逻辑重构检索链路,是提升检索准确率的核心方案。这套围绕知识库的问题生成与检索优化体系,可精准解决用户提问与知识内容表述错位的痛点,实现高效召回。
依托LLM能力,为知识库中的每个切片生成覆盖多元维度的问题,搭建“提问者视角”的检索桥梁,具体通过两类核心函数落地:
- 基础问题生成:调用
generate_questions_for_chunk()函数,聚焦单个知识切片的核心信息,生成直击要点的基础问题,快速锚定知识核心。 - 多样化问题拓展:借助
generate_diverse_questions()函数,围绕知识切片生成8个类型丰富、难度分层的拓展问题,覆盖不同提问习惯与需求场景,拓宽检索匹配的覆盖面。
为兼顾检索的全面性与精准性,同步构建基于原文内容与预生成问题的BM25检索索引,形成双轨互补的检索体系:
- 原文索引:直接以知识切片的原始内容为基础,搭建BM25检索索引,保障基础检索能力。
- 问题索引:以预生成的多样化问题为核心,搭建专属BM25检索索引,聚焦用户提问视角,提升与用户query的匹配概率。
专属Prompt驱动,实现精准向量化:
- 专属Prompt调用:借助定制化Prompt,引导LLM高效生成贴合知识库内容的问句。
- chunk融合:将生成的问句与原始信息进行拼接,整合为信息密度更高的大chunk。
- 向量转化:对融合后的chunk进行embedding处理,输出固定维度的向量,为后续精准检索提供标准化数据支撑。
Query2Doc:将查询改写成文档
用户查询:“如何提高深度学习模型的训练效率?”
Query2Doc 改写:
原始查询较短,可能无法充分表达用户意图。
通过 Query2Doc 生成一段扩展文档:
提高深度学习模型的训练效率可以从以下几个方面入手:
1. 使用更高效的优化算法,如 AdamW 或 LAMB。
2. 采用混合精度训练(Mixed Precision Training),减少显存占用并加速计算。
3. 使用分布式训练技术,如数据并行或模型并行。
4. 对数据进行预处理和增强,减少训练时的冗余计算。
5. 调整学习率调度策略,避免训练过程中的震荡。
Doc2Query:为文档生成关联查询
文档内容:
本文介绍了深度学习模型训练中的优化技巧,包括:
- 使用 AdamW 优化器替代传统的 SGD。
- 采用混合精度训练,减少显存占用。
- 使用分布式训练技术加速大规模模型的训练……
通过 Doc2Query 生成一组可能的查询:
1. 如何选择深度学习模型的优化器?
2. 混合精度训练有哪些优势?
3. 分布式训练技术如何加速深度学习?
4. 如何减少深度学习训练中的显存占用?
5. 深度学习模型训练的最佳实践是什么?
简而言之,是通过问题预生成+答案预生成的双向联动,以及Query2Doc、Doc2Query的双向改写策略,从根本上缓解短文本向量化效果不佳的局限:
- 替代问题匹配:为每个知识切片生成替代性问题,以“替代问题与用户query”的相似度匹配替代传统的“用户query与知识切片”匹配,破解表述错位难题。例如用户提问“中国的滑雪圣地是在哪?”,知识切片内容为“长春的气候与温度情况”,预生成的问题可直接锚定“长春是否为中国滑雪圣地”这类关联点,精准建立匹配关系。
- 双向生成提效:不仅为知识切片预生成问题,还可同步预生成对应答案,形成“问题-答案”双向生成链路,进一步丰富检索触点,全方位提升召回率。
- 双向改写破局:通过Query2Doc将用户短查询拓展为更完整的文档式表述,通过Doc2Query为知识切片生成潜在查询,双向拓展文本维度,有效弥补短文本向量化语义捕捉不足的短板,让检索更精准。
chunk融合与向量转化:
以“原始信息+问句”为核心,构建标准化处理流程:先将包含原始内容与预生成问句的完整chunk,转化为高维语义向量,实现文本到数字的精准映射,为高效检索筑牢基础。
聚焦知识库内容,借助LLM生成多元问句,搭配BM25算法完成文本检索的全面优化,破解传统检索的匹配局限,具体落地动作如下:
- 多样化问题生成:依托LLM能力,为知识库的每一段内容产出覆盖不同视角、不同表述的问句,丰富检索触达点。
- BM25检索优化:基于生成的多样化问题,结合BM25算法的词频与逆向文档率特性,优化检索权重分配,提升匹配精准度。
BM25
BM25是一种经典的文本检索算法,依托TF-IDF词频统计与逆向文档率的核心机制,精准捕捉文本的关键词权重与稀缺性,通过更精细的词频饱和度和文档长度归一化,提升了检索的相关性排序效果,可以去看下我之前的文章 了解TF-IDF Embedding不是魔法:把文字变成数字的底层逻辑。
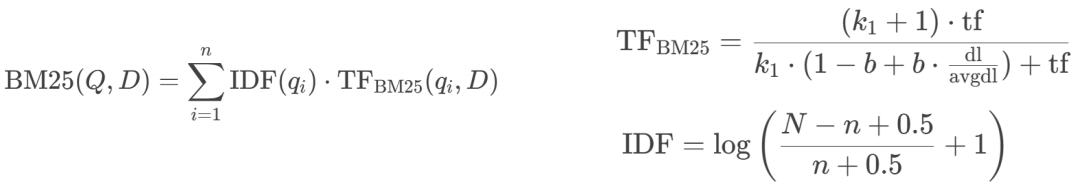
示例:客户经理被投诉了,投诉一次扣多少分?
‘经理’的词频数:1,IDF:0.1
‘投诉’的词频数:2,IDF:0.5
BM25(chunk) = 0.1 * 1 + 0.5 * 2 = 1.1
BM25多了个归一化,文档越长,数值就小一点,文档越短,数值更值钱一点;
BM25也叫关键词匹配,它去统计的,只看关键词;
使用BM25有可能检索不到信息,因为它是严格匹配。
LLM能力:生成多样化问题,评估检索质量,优化知识库结构
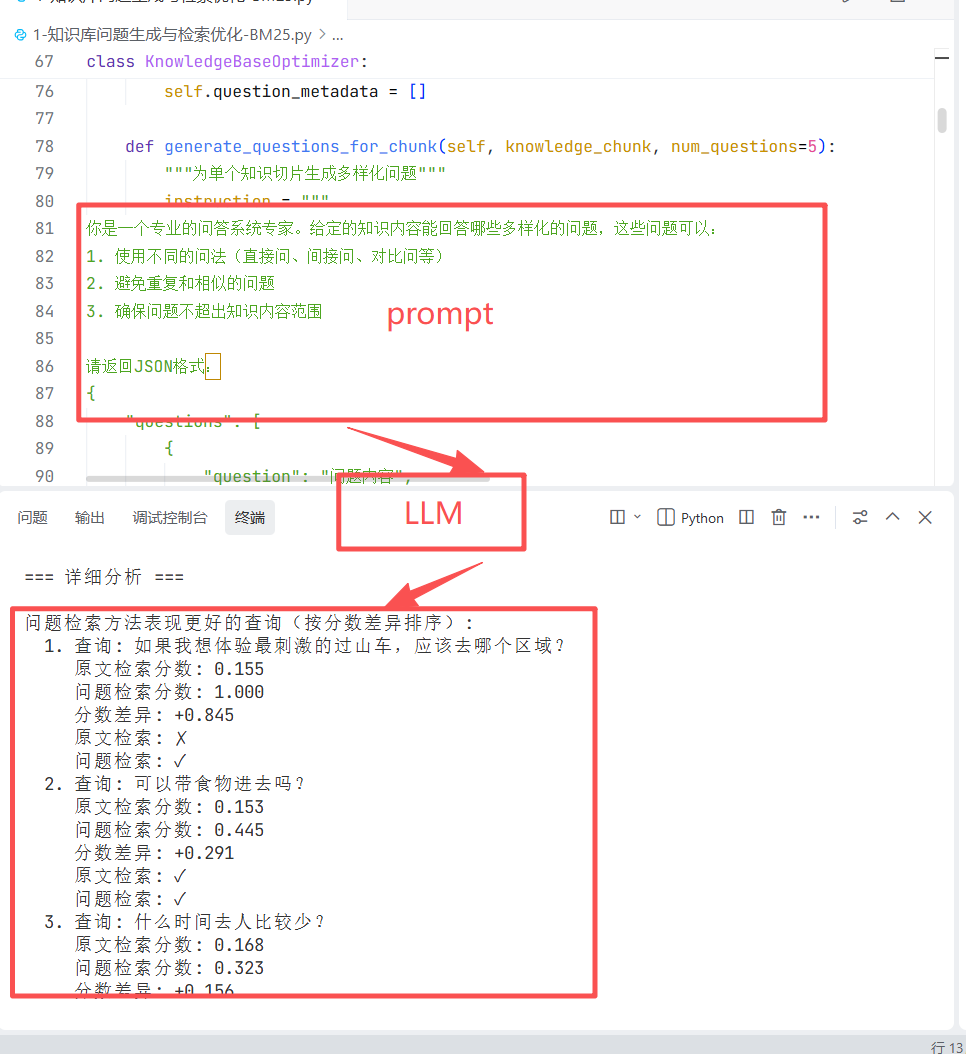
对话知识沉淀
产品上线后,每日海量用户对话潜藏着极具价值的知识富矿,为让这些零散信息转化为可复用的结构化资产、驱动知识库持续进化:
- 使用LLM模型(通义千问)从对话中提取结构化知识;
- 支持多种知识类型:事实、问题、流程、注意事项等;
- 自动识别用户意图和对话摘要;
LLM全程主导闭环流程,既深入对话提取高价值知识点、整合语义相近内容,又将零散信息转化为可直接入库的体系化知识。
这套方案与HermesAgent的知识沉淀逻辑高度契合,依托持续运行的“专家级小Agent”深度梳理历史对话,让RAG系统在用户交互中,不仅能捕捉新需求与纠正动作,更能将其转化为专属提示词沉淀为知识资产,实现知识库的动态丰富与系统能力的越用越精准,真正让海量对话成为滋养知识库的核心养分。
切片策略
-
通用场景:固定长度切片
核心诉求:追求简单可靠、操作门槛低,适配无特殊结构、无极致精度要求的常规信息处理。
策略匹配:固定长度切片无需复杂逻辑,直接按预设字符数拆分,流程标准化、稳定性强,完美契合通用场景下高效落地的核心需求,是最稳妥的基础选择。 -
技术文档:层次切片
核心诉求:必须完整保留文档的逻辑结构,确保技术内容的层级关系、模块划分不丢失,方便后续精准定位与理解。
策略匹配:层次切片以文档的标题层级、段落归属为核心依据进行切分,能原汁原味保留技术文档的框架脉络,避免结构碎片化,精准适配技术文档对结构完整性的刚性要求。 -
高质量要求场景:LLM语义切片
核心诉求:追求最优处理效果,确保切片后的内容语义连贯、逻辑完整,满足对精度、深度的高阶需求。
策略匹配:LLM语义切片依托大模型的语义理解能力,以内容的内在逻辑和语义关联为切分标准,能精准捕捉语义边界,避免生硬切割导致的语义断裂,是达成高质量目标的最优解。 -
长文档召回场景:滑动窗口切片
核心诉求:确保长文档信息无遗漏,通过切片覆盖所有关键内容,保障召回的全面性和完整性。
策略匹配:滑动窗口切片通过设置重叠区间,在切分过程中实现信息的无缝衔接,既能覆盖长文档的全量内容,又能避免关键信息因切割被遗漏,完美解决长文档召回的核心痛点。
切片策略对比:
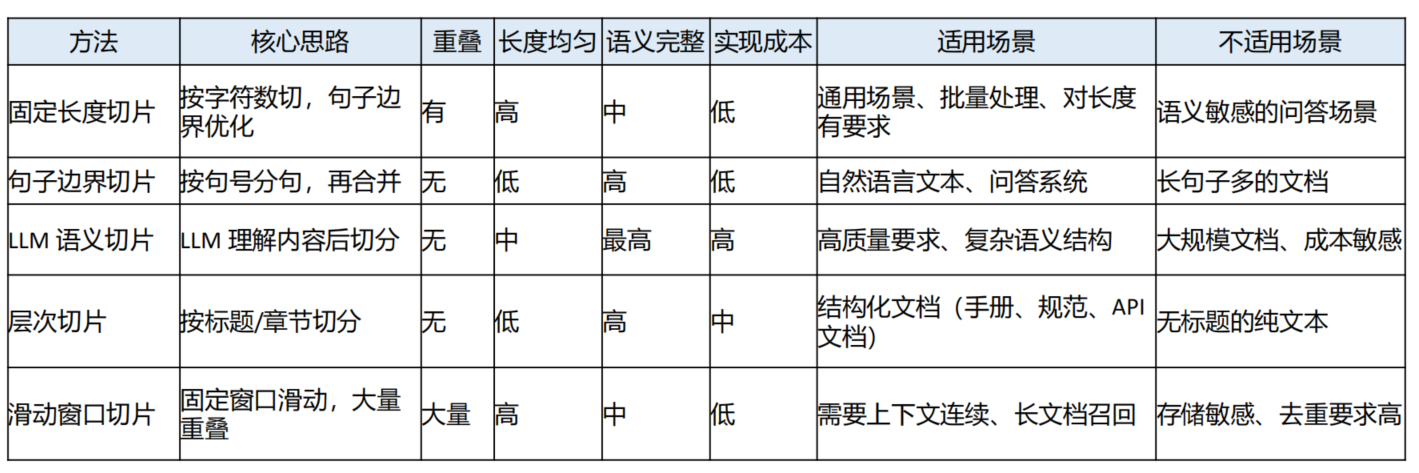
固定长度切片(有重叠) 常用的方式
- 按固定字符数切分文本,优先在句子边界进行切分,避免切断句子。
- 实现简单,处理速度快,长度统一,适合技术文档和规范文件。
- 适用场景:需要统一处理长度的场景,批量处理大量文档。
切片策略灵活适配:
- 大块文本:设置chunk_size为800-1000字符,适配长篇幅内容,保障核心信息完整留存;
- 小块文本:配置chunk_size为300-500字符,适配短句、片段等轻量化内容,兼顾粒度与检索效率。
块 1 (292 字符):
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日 票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需 认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。
块 2 (80 字符):
**需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。** 军人优惠现役及退役 军人凭证件享8折,需至少提前3天登记审批。
句子边界切片(无重叠)跟上面差不多,不带overlap
- 基于自然语言处理,按句子、段落等语义单位进行切分。保持语义完整性,避免在句子中间断开,确保每个切片都是完整的语义单元。无重叠,按语义边界切分。
- 语义保持好,检索准确性高,但长度可能不均匀。
- 适用场景:适用于自然语言文本,需要保持语义完整性的场景。
块 1 (287 字符):
迪士尼乐园提供多种门票类型以满足不同游客需求 一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动 两日票 需要连续两天使用,总价比购买两天单日票优惠约9折 特定日票包含部分节庆活动时段,需注意门票标注的有效期限 购票渠道以官方渠道 为主,包括上海迪士尼官网、官方App、微信公众号及小程序 第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识 所 有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记 ,可获赠生日徽章和甜品券 半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐
块 2 (29 字符):
军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批
LLM语义切片
- 利用LLM的语义理解能力,在保持语义完整性的同时实现精确的长度控制。
- 语义理解能力强,分割点选择智能,但依赖GPU,成本较高。
- 适用场景:高质量要求的场景,复杂语义结构,有预算支持的项目。
prompt = f"""
请将以下文本按照语义完整性进行切片,每个切片不超过{max_chunk_size}字符。
要求:
1. 保持语义完整性
2. 在自然的分割点切分
3. 返回JSON格式的切片列表,格式如下:
{{
"chunks": [
"第一个切片内容",
"第二个切片内容",
...
]
}}
文本内容:
{text}
请返回JSON格式的切片列表:
"""
LLM语义切片结果:
块 1 (57 字符): 迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。
块 2 (56 字符): 两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
块 3 (71 字符): 购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。
块 4 (50 字符): 所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
块 5 (54 字符): 生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。
块 6 (30 字符): 军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
层次切片
- 基于文档的层次结构(标题、章节、段落)进行切分。便于理解文档的逻辑关系。
- 保持文档结构,支持层次化查询,但依赖文档格式。
- 适用场景:结构化文档(手册、规范),多级标题的文档。
块 1 (11 字符):
# 迪士尼乐园门票指南
块 2 (219 字符):
## 一、门票类型介绍
### 1. 基础门票类型
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
### 2. 特殊门票类型
年票适合经常游玩的游客,提供更多优惠和特权。VIP门票包含快速通道服务,可减少排队时间。团体票适用于10人以上团队,享受团体折扣。
块 3 (214 字符):
## 二、购票渠道与流程
### 1. 官方购票渠道
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。这些渠道提供最可靠的服务和最新的票务信息。
### 2. 第三方平台
第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。建议优先选择官方渠道以确保购票安全。
### 3. 证件要求
所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
块 4 (264 字符):
## 三、入园须知
### 1. 入园时间
乐园通常在上午8:00开园,晚上8:00闭园,具体时间可能因季节和特殊活动调整。建议提前30分钟到达园区。
### 2. 安全检查
入园前需要进行安全检查,禁止携带危险物品、玻璃制品等。建议轻装简行,提高入园效率。
### 3. 园区服务
园区内提供寄存服务、轮椅租赁、婴儿车租赁等服务,可在游客服务中心咨询详情。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。
军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
滑动窗口切片
- 使用固定大小的窗口在文本上滑动,产生重叠的切片。通过重叠机制确保上下文连续性,减少信息丢失,提高检索召回率。
- 保持上下文连续性,减少信息丢失,但产生大量重叠内容。
- 适用场景:需要重叠信息的场景,长文档处理,需要保持上下文的场景。
块 1 (299 字符):
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日 票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需 认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及
块 2 (173 字符):
小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份
证件,港澳台居民可用通行 证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。
生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。
军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
块 3 (23 字符):
退役军人凭证件享8折,需至少提前3天登记审批。
知识库健康度检查
RAG知识库往往汇聚各类多元知识,呈现“大杂烩”式的复杂特征。借助LLM的强大分析能力,能够穿透繁杂的内容体系,实现对各类知识的全面检测,既精准识别知识空白与冲突,又能保障知识库的整体质量,让庞杂的知识库始终保持规范、可靠的运行状态。
我们聚焦知识库的完整性、时效性与一致性三大核心维度,依托LLM打造系统性健康度检查体系,精准排查知识空白、过期内容与冲突矛盾,为知识库的质量与可靠性筑牢防线。
围绕知识库质量的核心诉求,搭建覆盖全维度的检查机制,实现问题精准定位与量化评估:
- 完整性检查:全面评估知识库对用户核心查询需求的覆盖程度,精准识别知识缺口,确保用户高频诉求均有对应的知识支撑。
- 时效性检查:自动筛查过期、失效或亟待更新的知识内容,及时捕捉信息滞后问题,保障知识库内容紧跟实际动态。
- 一致性检查:深度挖掘知识库中相互冲突、矛盾的信息,杜绝同一问题出现不同口径,维护知识库的逻辑统一性。
- 综合评分与优化指引:输出量化的健康度评分,并针对性生成改进建议,为知识库迭代提供清晰的行动方向。
LLM作为健康度检查的核心引擎,深度赋能全流程,高效完成问题排查与报告生成:
- 靶向问题分析:精准剖析知识缺失环节,细致核查过时内容,敏锐识别知识冲突,全面覆盖知识库的潜在风险点。
- 健康度报告输出:整合分析结果,生成结构化的健康度报告,清晰呈现问题分布与优化方案,为知识库运维提供决策依据。
- 分域精准检测:依托分类文件夹的架构,让LLM对每个文件夹内的知识切片逐一开展检测,精准定位各分类下的知识冲突、时效性不足等问题,实现分域精细化排查。
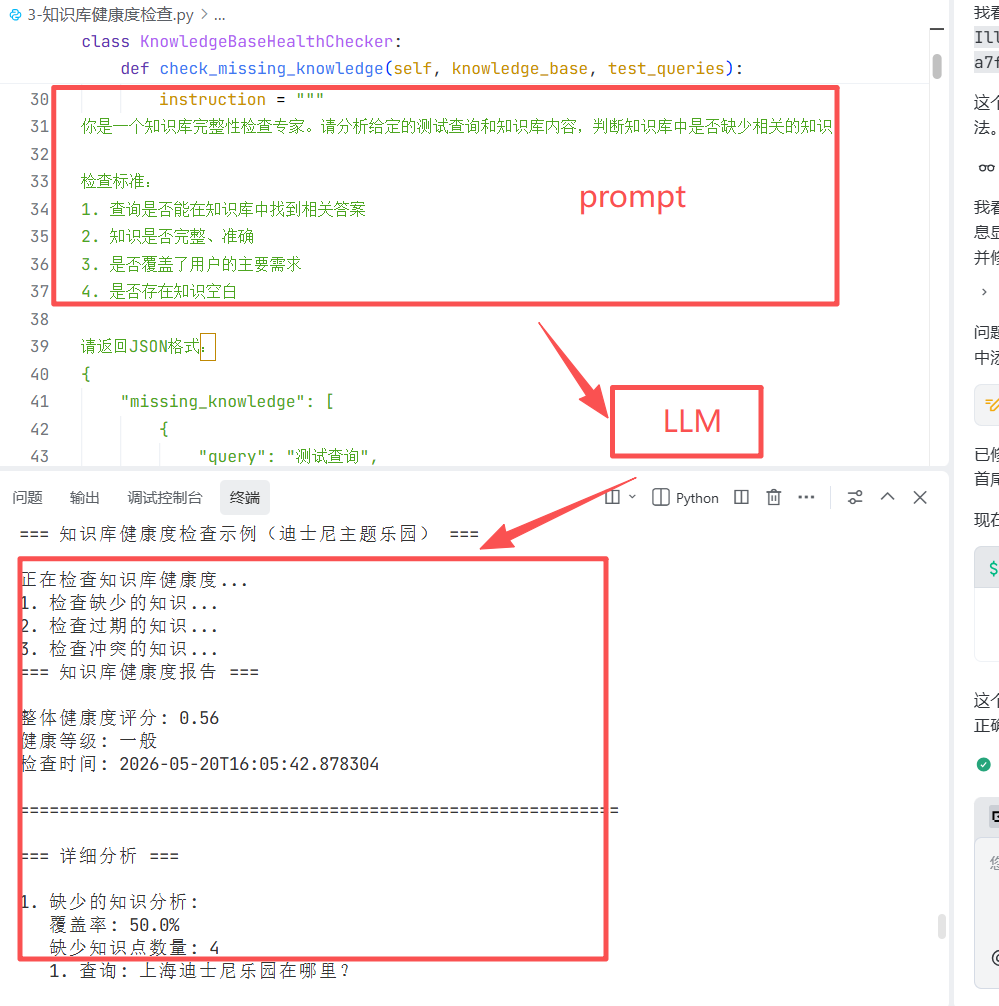
知识库版本管理与性能比较
知识库的版本管理是知识工程的核心环节,需兼顾规范迭代、质量验收与性能择优,通过系统化的核心能力,实现版本全生命周期可控,为知识库的稳定升级与高效运行筑牢基础。
围绕版本管理的关键环节,构建覆盖创建、标识、统计、对比的核心能力,实现版本管理的标准化与可追溯:
- 版本创建:规范存档,信息完备
为知识库创建专属版本,同步绑定版本描述与核心统计信息,清晰记录版本迭代的背景与核心特征,确保每个版本都有清晰的溯源与定位。 - 哈希标识:唯一锚点,精准溯源
采用MD5算法计算版本的唯一标识,以哈希值作为版本的“数字身份证”,杜绝版本混淆与篡改,保障版本的唯一性与可追溯性。 - 统计记录:多维画像,全面掌控
聚焦知识切片数量、内容总长度、分类分布等核心指标,为每个版本建立多维统计画像,直观呈现版本的知识结构与规模,为后续分析提供数据支撑。 - 版本对比:差异洞察,变化可视
精准对比两个版本的差异与变化,清晰呈现知识的增减、调整情况,快速定位迭代带来的核心变动,为回归测试与验收提供明确依据。
知识库版本管理深度贴合知识工程的核心诉求,融合prompt与code的版本管理逻辑,同时依托Embedding实现性能评估,以简洁高效的技术路径落地核心需求:
- 知识工程双维支撑
将prompt版本管理与code版本管理融入知识库迭代,既保障知识内容迭代的规范性,又确保底层技术逻辑的可控性,实现知识与技术的协同管控。 - Embedding:性能评估的核心引擎
借助Embedding构建向量索引,支撑语义检索功能,同时为不同版本的知识库提供性能评估能力,通过向量层面的量化对比,精准衡量版本迭代对检索效果的影响。 - 轻量化差异检测
版本差异检测采用精确文本匹配的简化方案,无需依赖LLM,在降低工程复杂度的同时,高效完成版本差异识别,契合实际场景中“聚焦核心、简化冗余”的实践需求,也契合“很少开展复查、工程复杂度高,前三项核心功能更常用”的现实情况。
精准雷达:高效召回
查询优化
优化查询扩展(相似语义改写):使用大模型将用户查询改写成多个语义相近的查询,提升召回多样性。
-
如果要召回更多的片段,Top-K越大,召回信息越多,Top-K越小,召回信息越精准。
比如,Top-K=10,如果没在召回的Top10里面,就不会有数据,要把这个超参数Top-K改大点,才会有参数。
召回 Top-K = 5 通常最优,过大会污染 context; -
优化查询扩展
相似语义改写:使用大模型将用户查询改写成多个语义相近的查询,提升召回多样性。在 LangChain旧版本中提供了MultiQueryRetriever支持多查询召回,新版本需要自己编写
"""
使用LLM生成多个查询变体
"""
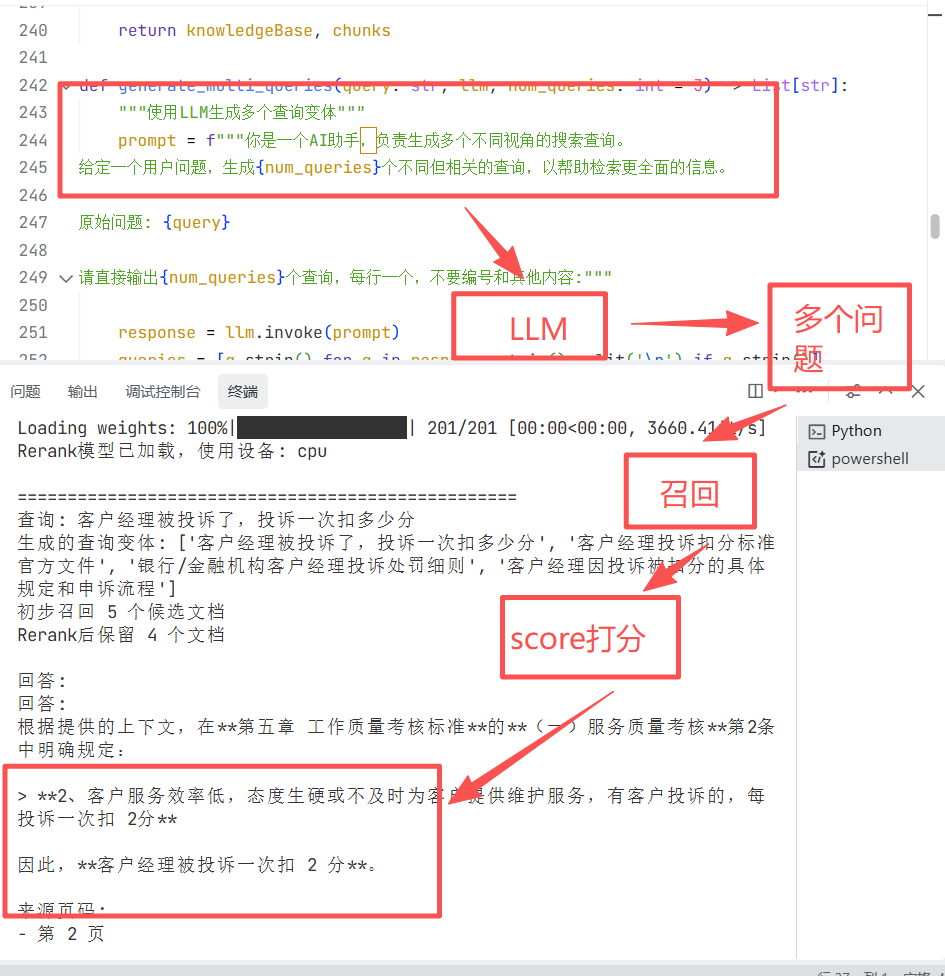
prompt = f"""你是一个AI助手,负责生成多个不同视角的搜索查询。
给定一个用户问题,生成{num_queries}个不同但相关的查询,以帮助检索更全面的信息。
每个查询应该从不同角度表达相同的信息需求。
原始问题: {query}
请直接输出{num_queries}个查询,每行一个,不要编号和其他内容:"""
LLM改写后的内容:
查询: 客户经理被投诉了,投诉一次扣多少分
生成的查询变体: ['客户经理被投诉了,投诉一次扣多少分', '客户经理投诉扣分标准是什么', '银行客户经理被投诉一次会扣除多少绩效分','金融机构客户经理投诉处罚机制']
混合检索
结合向量检索和关键词检索的优势,通过重排序模型对结果进行归一化处理,提升召回质量
索引扩展:
1)离散索引扩展: 使用关键词抽取、实体识别等技术生成离散索引,与向量检索互补,提升召回准确性。
关键词抽取: 从文档中提取出重要的关键词,作为离散索引的一部分,用于补充向量检索的不足。

当用户查询“如何优化深度学习模型训练?”时,离散索引中的关键词能够快速匹配到相关文档。
2)连续索引扩展: 结合多种向量模型(如OpenAI的Ada、智源的BGE)进行多路召回,取长短。
实体识别: 从文档中识别出命名实体(如人名、地点、组织等),作为离散索引的一部分,增强检索的精确性。

当用户查询“2023年诺贝尔物理学奖的获奖者是谁?”时,离散索引中的实体能够快速匹配到相关文档。
3)混合索引召回: 将BM25等离散索引与向量索引结合,通过Ensemble Retriever实现混合召回,提升召回多样性。
混合索引召回: 将离散索引(如关键词、实体)与向量索引结合,通过混合召回策略提升检索效果。

当用户查询“人工智能在医疗领域的应用有哪些?”时:
离散索引通过关键词和实体匹配到相关文档。
向量索引通过语义相似度匹配到相关文档。
综合两种召回结果,提升检索的准确性和覆盖率。
BM25本质是基于数学公式的关键词检索工具库,核心依赖TF-IDF词频统计与逆向文档率计算,全程通过既定算法完成匹配,具备两大核心优势:
- 速度快、成本低:纯数学计算无需复杂模型推理,毫秒级即可完成检索,资源消耗极低,适配大规模数据的快速检索需求;
- 逻辑独立:其核心是关键词的统计匹配,无需依赖LLM的语义理解能力,自然无需在流程前端叠加LLM,避免额外成本与效率损耗。
LLM与BM25并非“谁依赖谁”的关系,而是按需协作的补充关系,仅在特定场景下才会出现“LLM辅助BM25”的流程,且并非前置强制环节:
- 常规场景:若用户查询的关键词清晰、意图直接,BM25可直接基于原始查询关键词完成检索,无需LLM介入;
- 特定联动场景:当用户查询模糊、口语化时,才会出现“问题→LLM提取关键词→BM25打分”的流程——此时LLM仅承担关键词提取的辅助角色,而非BM25的前置必备环节,核心检索仍由BM25完成,本质是借助LLM优化查询输入,而非为BM25叠加前置模型。
三者均是RAG检索的核心工具,但定位与功能完全不同,不存在层级依赖,共同构成RAG的多元检索策略:
- BM25:聚焦关键词检索,是RAG的核心检索策略之一,核心优势是速度与低成本,适配精准关键词匹配场景;
- Faiss:聚焦向量相似度检索,是独立的工具库,核心功能是计算embedding后的向量相似度,适配语义检索场景,与BM25是并列的检索工具,均无需前置LLM;
- LLM:核心能力是语义理解、关键词提取、意图识别,可辅助优化查询输入,或在检索后完成结果整合、推理,但并非检索工具本身,不直接参与关键词匹配或向量相似度计算。
简言之,BM25是独立高效的轻量检索工具,无需前置LLM;若需优化查询输入,可按需让LLM辅助提取关键词,但这是场景化协作,而非强制流程。三者分属不同工具赛道,按需搭配即可构建完整的RAG检索体系,无需额外叠加不必要的模型环节,兼顾效率与成本。
实现 BM25检索 + 向量检索:

RAG高效召回流程:
Step1 输入: 用户查询进入系统
Step2 并行检索:
同时执行 BM25(分词 -> 词频匹配)和 向量检索(Embedding -> 相似度计算)
Step3 归一化:
将两种分数统一缩放到 [0, 1] 区间,便于融合
Step4 加权融合:
按 alpha 权重合并分数,Score = α × Vector + (1-α) × BM25
Step5 输出:
按融合分数排序,返回 Top-K 结果
Small-to-Big 索引策略
这是一种专为长文档、多文档场景量身打造的高效检索策略,核心逻辑在于以小见大、分层链接:用摘要、关键句等精炼的小规模内容搭建索引,再精准锚定对应的大规模原始内容主体。这种模式既能凭借小规模索引实现快速定位,又能通过链接补全详细上下文,既大幅提升检索效率,又保障答案的逻辑完整性与连贯性。
面对海量、零散、宽泛的原始知识,若让LLM直接深入细节海洋,极易陷入信息泥潭,不仅检索效率低下,还可能出现定位偏差。对此,核心破局思路就是对知识进行体系化加工,提炼核心摘要,搭建摘要索引层。当开展知识检索时,先依托摘要索引快速锁定目标,确认匹配后再调取对应的原始知识,让AI先抓核心、再探细节,从根本上规避海量碎信息的干扰,实现高效精准的知识检索。
案例:比如你想查找一个论文
小规模内容(索引部分):
摘要:从每篇论文中提取摘要作为索引内容。
摘要1:本文介绍了 Transformer 模型在机器翻译任务中的应用,并提出了改进的注意力机制。
摘要2:本文探讨了 Transformer 模型在文本生成任务中的性能,并与 RNN 模型进行了对比。
关键句:从论文中提取与查询相关的关键句。
关键句1:Transformer 模型通过自注意力机制实现了高效的并行计算。
关键句2:BERT 是基于 Transformer 的预训练模型,在多项 NLP 任务中取得了显著效果。
大规模内容(链接部分):
每篇论文的完整内容作为大规模内容,通过链接与小规模内容关联。
论文1:链接到完整的 PDF 文档,包含详细的实验和结果。
论文2:链接到完整的 PDF 文档,包含模型架构和性能分析。
Small-to-Big机制:
- 小规模内容检索: 用户输入查询后,系统首先在小规模内容(如摘要、关键句或段落)中检索匹配的内容。小规模内容通常是通过摘要生成、关键句提取等技术从大规模内容中提取的,并建立索引。
- 链接到大规模内容: 当小规模内容匹配到用户的查询后,系统会通过预定义的链接(如文档 ID、URL 或指针)找到对应的大规模内容(如完整的文档、文章)。大规模内容包含更详细的上下文信息,为 RAG 提供丰富的背景知识。
- 上下文补充: 将大规模内容作为 RAG 系统的上下文输入,结合用户查询和小规模内容,生成更准确和连贯的答案。
Rerank模型使用
重排序Rerank主要用于优化初步检索结果的排序,提高最终输出的相关性或准确性。
BGE-Rerank和Cohere Rerank是两种广泛使用的重排序模型,它们在检索增强生成(RAG)系统、搜索引擎优化和问答系统中表现优异。
Rerank模型是针对用户query与RAG相似度匹配的知识,Q-A进行重新打分;
rerank模型是神经网络训练出来的,通过Q-A对进行监督学习训练出来。
BGE-Rerank
BGE-Rerank由北京智源人工智能研究院(BAAI)开源发布,属于FlagEmbedding项目的一部分。基于Transformer的Cross-Encoder结构,直接计算查询(Query)与文档(Document)的交互相关性得分。
训练数据: 支持多语言(中、英等),训练数据包括T2Ranking、MSMARCO、NLI等数据集。
提供bge-reranker-base和bge-reranker-large两个版本,后者在精度上更优。
部署方式: 可本地部署
引入重排序(Reranking)
重排序模型:对召回结果进行重排,提升问题和文档的相关性。
常见的重排序模型有BGE-Rerank和Cohere Rerank。
场景:用户查询“如何提高深度学习模型的训练效率?”
召回结果:初步召回10篇文档,其中包含与“深度学习”、“训练效率”相关的文章。
重排序:BGE-Rerank对召回的10篇文档进行重新排序,将与“训练效率”最相关的文档(如“优化深度学习训练的技巧”)排在最前面,而将相关性较低的文档(如“深度学习基础理论”)排在后面。
开源免费,适合本地化部署,保护数据隐私。
在中文任务中表现优秀,适用于垂直领域优化
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'The giant panda is a bear species endemic to China.']]
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt')
scores = model(**inputs).logits.view(-1).float()
print(scores) # 输出相关性分数 4.9538
在BGE-Rerank模型中,相关性分数scores是一个未归一化的对数几率(logits)值,范围没有固定的上限或下限(不像某些模型限制在0-1)。
不过BGE-Rerank的分数通常落在以下范围:
- 高相关性: 3.0~10.0
- 中等相关性: 0.0~3.0
- 低相关性/不相关: 负数(如-5.0以下)
通过modelscope获取以下rerank模型:
- BAAI/bge-reranker-base (轻量级,推荐)
- BAAI/bge-reranker-large (效果更好,但更慢)
Cohere Rerank
Cohere Rerank由Cohere公司提供的商业API服务。
基于专有的深度学习模型,支持多语言(如rerank-multilingual-v3.0)。
训练数据: 优化了语义匹配,特别适用于混合检索(如结合BM25和向量检索)后的结果优化。
使用方式: 通过API调用,集成到LangChain、LlamaIndex等框架中。
优势:
- 简单易用,适合快速集成到现有系统。
- 在英文和多语言任务中表现优异,如提升Hit Rate(命中率)和MRR(平均倒数排名)。
| 特性 | BGE-Rerank | Cohere Rerank |
|---|---|---|
| 开源/商业 | 开源 | 商业API |
| 部署方式 | 可本地部署 | 云端调用 |
| 多语言支持 | 中英优化 | 多语言(v3.0) |
| 适用场景 | 数据敏感、垂直领域 | 快速集成、多语言优化 |
- Rerank 模型对每个 (Query, Doc) 对都要过一次,候选数量不宜过多
- 首次运行会从 ModelScope 下载模型,建议设置 cache_dir 到本地目录
- GPU 加速效果明显,建议在有 GPU 的环境运行
- 长文档会被截断到 max_length,可考虑对长文档分段处理
- 参数设置建议
| 参数 | 说明 | 建议值 |
|---|---|---|
| initial_k | 粗排召回数量 | 10-20 (召回越多,Rerank 精度越高,但速度越慢) |
| final_k | 最终返回数量 | 3-5 (太多会引入噪声,太少可能漏掉) |
| max_length | Tokenizer 最大长度 | 512 (默认值,过长会截断) |
| alpha | 混合检索权重 | 0.5 (平衡 BM25 和向量) |
rerank与embedding的区别:
- embedding模型是计算向量相似度,是做知识特征提取;
- rerank模型是对回答结果质量进行score打分;
精准度排序
embedding < rerank < LLM
全局视野:GraphRAG
以前的知识处理是切片chunk,有时候,我们理解知识往往不是按照小块逻辑来,而是把它看作知识图谱。
比如我们要学大模型应用开发, 知识与知识之前是有串联的,GraphRAG就是帮你做了这件事情,它先去读了下各个文章,生成了社区层级,社区就是综合体,知识点就是个体,几个知识点组合再一起就是社区,描述个体与个体之间的关系,我会为社区生成概要,社区是一个大的集体,概要是这个浓缩,在执行任务的过程中,会利用概要去完成任务。
GraphRAG:是一种结构化的、分层的检索增强生成(RAG)方法,而不是使用纯文本片段的语义搜索方法。
GraphRAG 过程包括:
- 原始文本中提取出知识图谱;
- 构建社区层级(这种结构通常用来描述个体、群体及它们之间的关系,帮助理解信息如何在社区内部传播、知识如何共享以及权力和影响力如何分布);
- 为这些社区层级生成摘要;
然后在执行基于 RAG 的任务时,会利用这些结构。
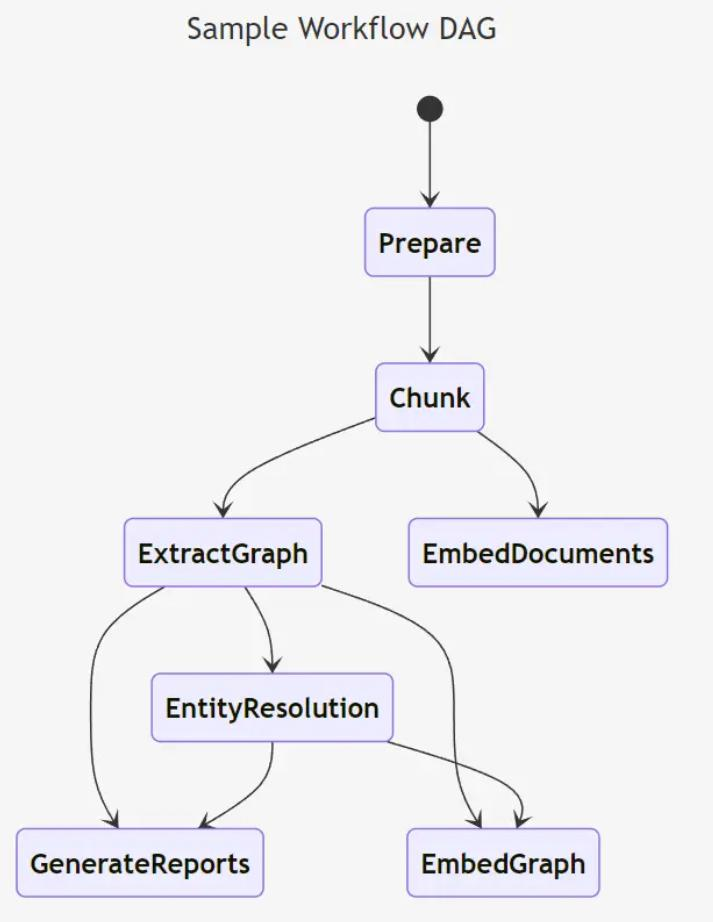
GraphRAG工作流,DAG(有向无环):
GraphRAG 与 基线RAG(NativeRAG):
大多数 RAG 使用矢量相似性作为搜索技术,称之为 基线 RAG
GraphRAG 使用知识图谱来在处理复杂信息时提供问题和回答性能的显著改进。
在某些情况下,基线 RAG 的性能非常差:
- 基线 RAG 难以连接各个要点。这种情况发生在回答问题需要通过共享属性遍历不同的信息片段,以提供新的综合见解。
- 基线 RAG 在被要求全面理解大量的数据(跨文档)或甚至单个大文档的的语义概念时表现不佳。
GraphRAG方法:
- 使用 LLMs 来创建基于输入语料库的知识图谱。这个知识图谱、社区层级摘要、以及知识图谱机器学习输出会在用户查询时用于增强提示。
- GraphRAG 在回答上述两类问题时可以显著改进回答能力,远超基线RAG
传统 RAG的局限性:
- 连接点缺失,问题的答案分散在文档的不同位置,且没有直接的语义重叠,传统 RAG 很难把它们串联起来;
- 宏观理解缺失, 如果用户问“这篇文章的主旨是什么?” 传统 RAG 很难给出一个概括性的答案。
举例:
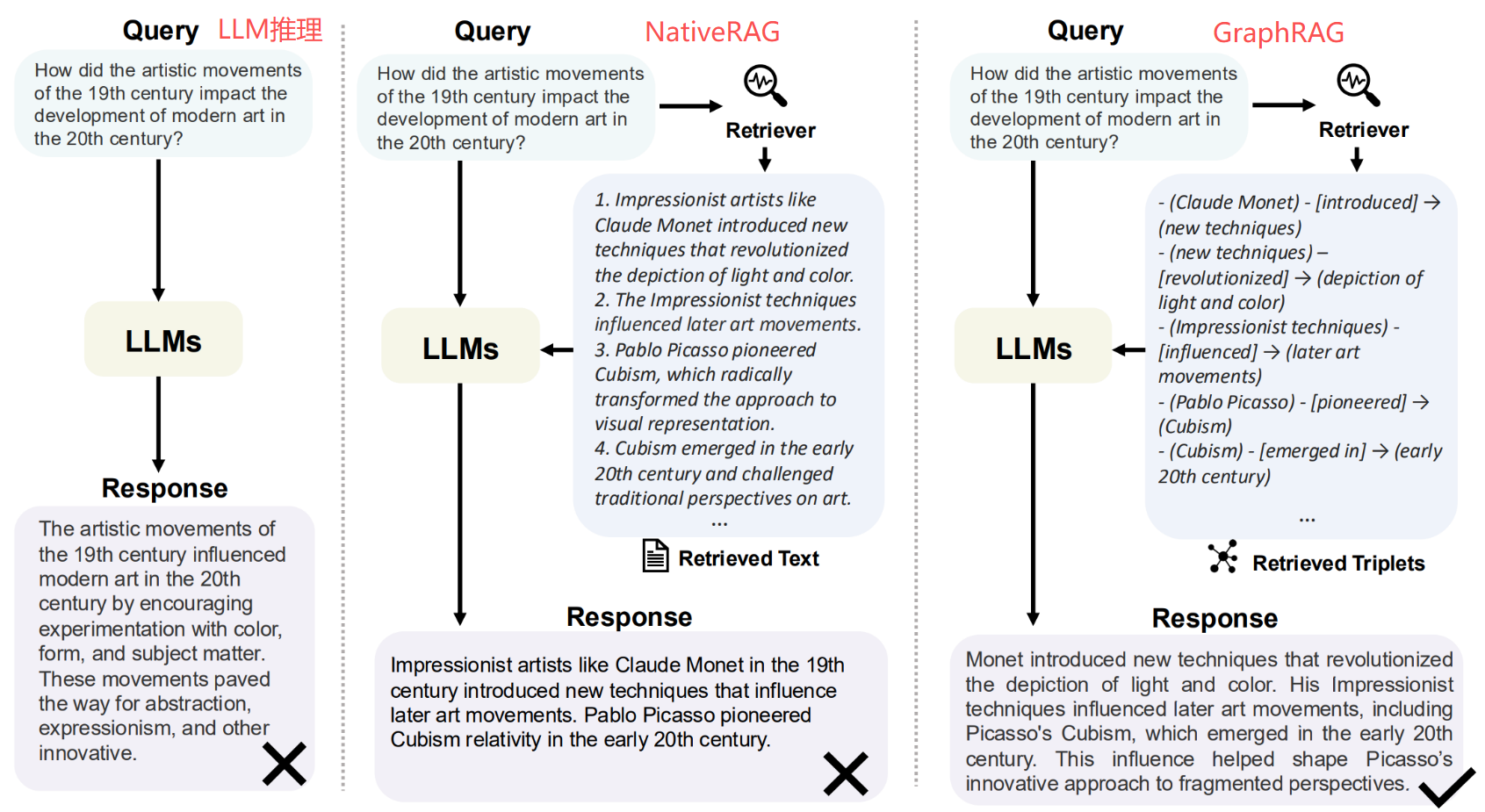
Query:19世纪的艺术运动是如何影响20世纪现代艺术的发展的?
LLM:19世纪的艺术运动通过鼓励对色彩、形式和主题的实验影响了20世纪的现代艺术。这些运动为抽象主义、表现主义和其他创新艺术铺平了道路。
NativeRAG检索:
1. 像克劳德·莫奈这样的印象派艺术家引入了新技术,彻底改变了对光和颜色的描绘。
2. 印象派的技法影响了后来的艺术运动。
3. 巴勃罗·毕加索开创了立体主义,从根本上改变了视觉表现的方式。
4. 立体主义出现在20世纪初,挑战了传统的艺术观点。
NativeRAG回答:
像19世纪的克劳德·莫奈这样的印象派艺术家引入了影响后来艺术运动的新技术。巴勃罗·毕加索在20世纪初开创了立体主义相对论。
GraphRAG检索:
(莫奈)-[引进]→(新技术)
(新技术)-[革新]→(光和颜色的描绘)
(印象派技术)-[影响]→(后来的艺术运动)
(毕加索)-[开创]→(立体主义)
(立体主义)-[出现]→(20世纪初)
GraphRAG回答:
莫奈引进的新技术彻底改变了对光和色彩的描绘。他的印象派技巧影响了后来的艺术运动,包括20世纪初出现的毕加索的立体主义。这种影响有助于塑造毕加索对碎片化视角的创新方法。
GraphRAG 的基本步骤
GraphRAG方法是使用LLM构建基于图的文本索引,
分两个阶段:
- 首先从源文档中派生出实体知识图谱
- 然后为所有密切相关的实体组预生成社区摘要。
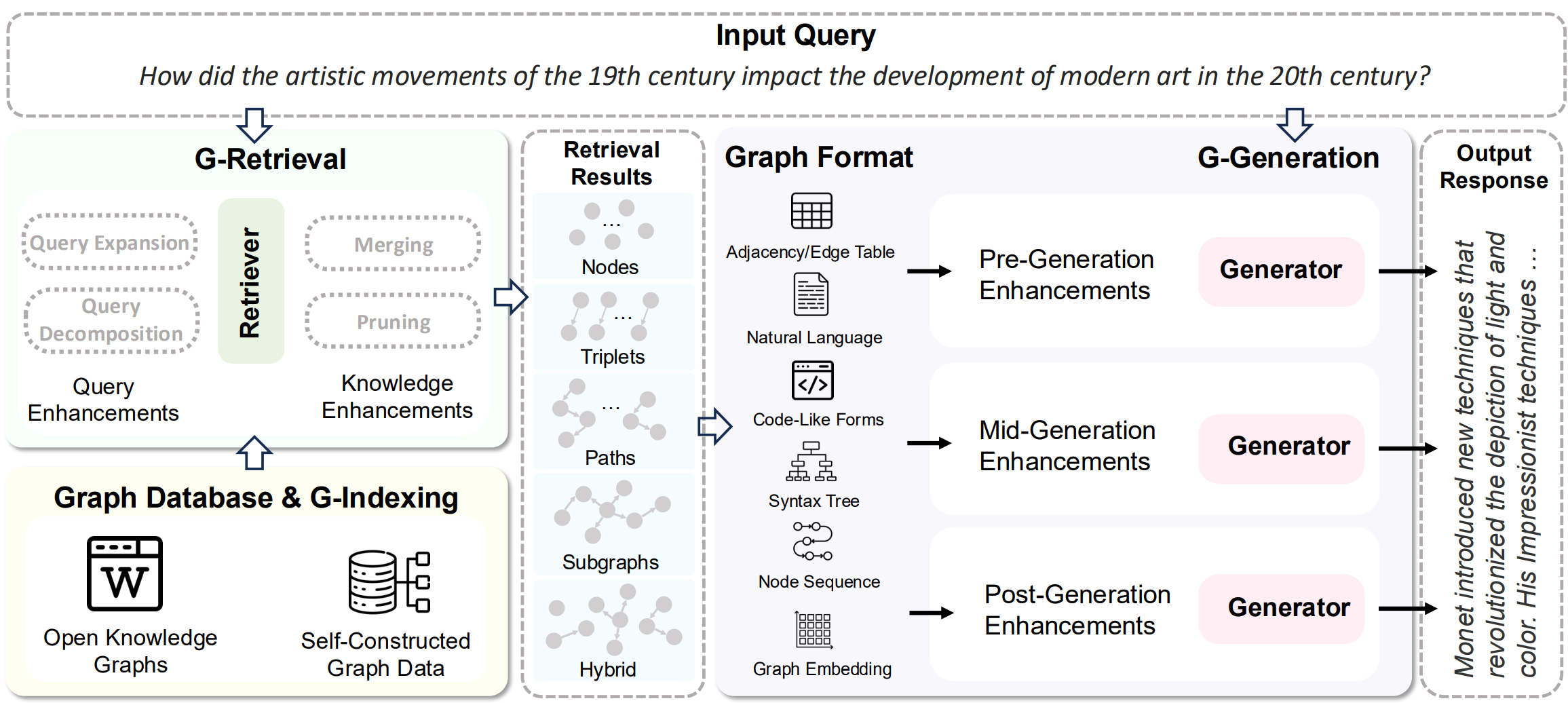
索引
- 将输入语料库分割为一系列的文本单元(TextUnits),这些单元作为处理以下步骤的可分析单元,并在我们的输出中提供细粒度的引用。
- 使用 LLM 从文本单元中提取所有实体、关系和关键声明。
- 使用 Leiden 技术对知识图谱进行层次聚类。每个圆圈都是一个实体(例如人、地点或组织),大小表示实体的度,颜色表示其社区层级。
- 自下而上地生成每个社区层级及其组成部分的摘要 => 有助于对数据集的整体理解。
索引构建(Indexing)—— 知识的结构化
这是 GraphRAG 最“重”的一步,把非结构化文本 => 结构化
-
切片(Source Text to TextUnits): 把文档切分成文本块 。
-
抽取(Extract Graph): 使用 LLM 从文本块中提取实体(人、地、物)、关系(谁做了什么)和主张(Claim) 。
-
聚类与摘要(Community Detection & Summarization):
- 使用 Leiden 算法对图谱进行层级聚类,形成不同的社区。
- 自下而上地为每个社区生成摘要。这就像给原本零散的数据建立了一个从“村委会”到“市政府”再到“中央”的层级汇报体系 。
使用 Leiden 技术对知识图谱进行层次聚类:

查询:
在查询时,使用这些结构为 LLM 上下文窗口提供材料来回答问题。主要查询模式有:
- 全局搜索,通过社区层级摘要来推理有关语料库的整体问题。
- 局部搜索,通过扩展到其邻居和相关概念来推理特定实体的情况。
索引数据流
知识模型:
在GraphRAG的存储库中,包括实体类型如Document、TextUnit、Entity、Relationship、Covariate、Community Report和Node。
默认配置工作流程:将文本文档转换为知识图谱模型,
主要步骤包括:
第一阶段: 组合 TextUnits,将输入文档转换为TextUnits,用于知识图谱提取的文本块。用户可以配置块大小和分组方式。
第二阶段: 知识图谱提取,分析每个TextUnit,用来提取实体、关系和主张。
实体和关系在entity_extract动词中提取,而主张在claim_extract动词中提取。
实体和关系提取:使用LLM从原始文本中提取实体和关系。合并具有相同名称和类型的实体,以及具有相同源和目标的关系。
实体和关系概述:通过询问LLM获取每个实体和关系的简要概述。
实体解析(默认未启用):解析表示相同现实世界实体,但具有不同名称的实体。
主张提取和发射:从源TextUnits中提取主张,这些主张是正面事实陈述,并作为Covariates发射。
第三阶段: 知识图谱增强,了解实体的社区结构,并增强知识图谱。使用层次Leiden算法进行社区检测,使用Node2Vec算法进行知识图谱嵌入。
第四阶段: 社区总结,生成社区报告,了解知识图谱在各个粒度级别上的高层次情况。使用LLM生成每个社区的摘要。
第五阶段: 文档处理,为知识模型创建“文档”表。如果工作流在CSV数据上运行,可以配置工作流,用于向文档输出添加其他字段。
第六阶段: 网络可视化,执行UMAP降维,用于在2D空间中可视化知识图谱。UMAP嵌入作为“节点”表格发出。
GraphRAG工作流程是将文本数据转换为结构化的知识图谱,以便理解和分析数据。通过这个流程,用户可以提取关键信息,如实体、关系和主张,并在知识图谱中进行进一步的分析和可视化。
GraphRAG部署与使用
GraphRAG仓库:https://github.com/microsoft/graphrag
Step1, 下载源代码
git clone https://github.com/microsoft/graphrag.git
Step2, 下载依赖并初始化项目 pip install -e .
这里会自动基于 graphrag-main/pyproject.toml 进行python包的安装
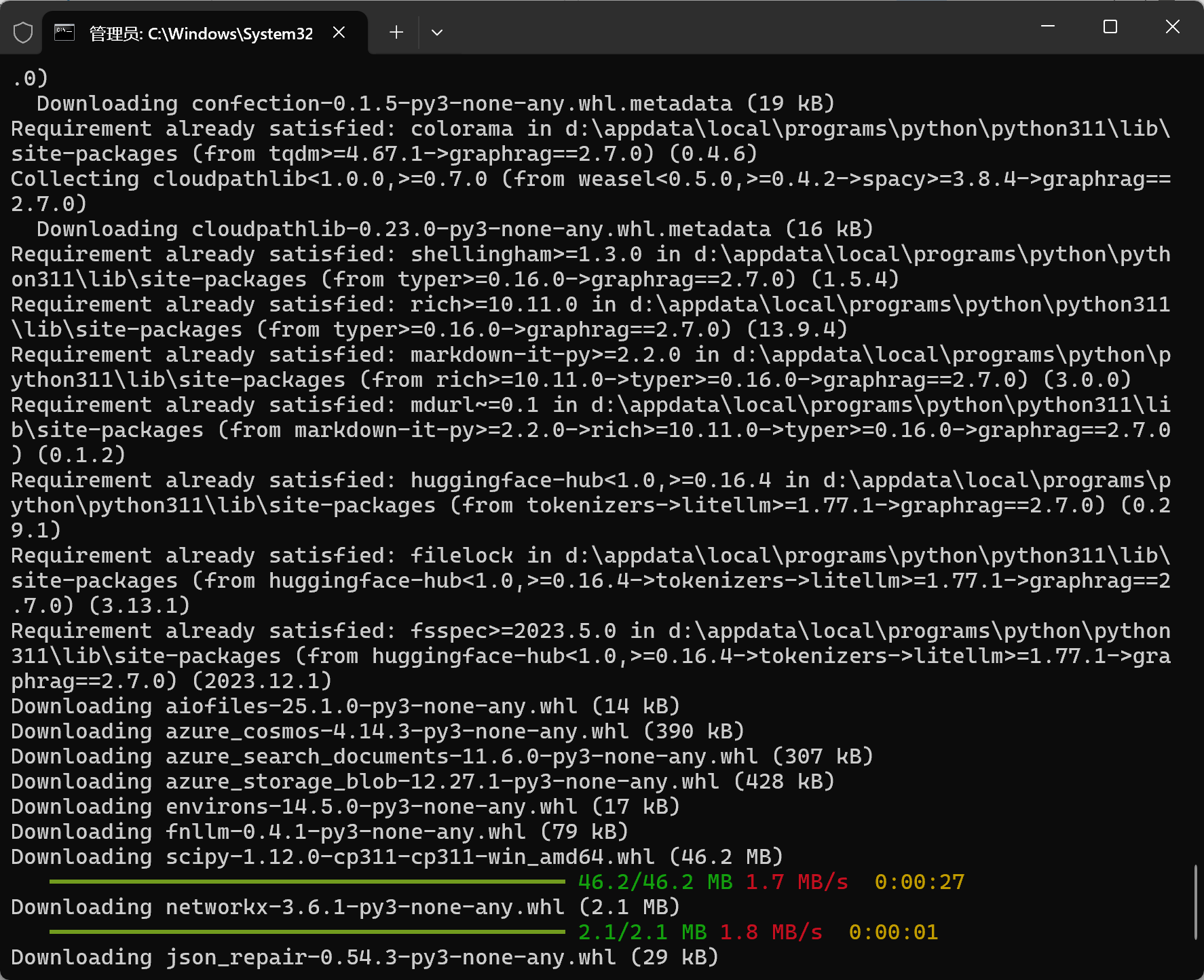
Step3, 直接运行 graphrag 命令
graphrag init --root .
正确运行后,此处会在graphrag目录下生成prompts、.env、settings.yaml文件
settings.yaml - 主配置文件,包含:
• LLM 模型配置:默认使用 OpenAI 的 gpt-4-turbo-preview 和text-embedding-3-small
• 输入设置:从 input 文件夹读取文本文件
• 输出设置:结果存到 output,缓存到 cache,日志到 logs
• 向量存储:使用 LanceDB
• 图抽取/社区报告等工作流配置
• 查询设置:local_search, global_search, drift_search 等
.env - 环境变量文件:
GRAPHRAG_API_KEY=<API_KEY>
你需要把 <API_KEY> 替换成你的 OpenAI API Key或者DASHSCOPE_API_KEY。
prompts/ 文件夹:
生成了一些 prompt 模板文件
Step4, 参数文件配置
配置 settings.yaml
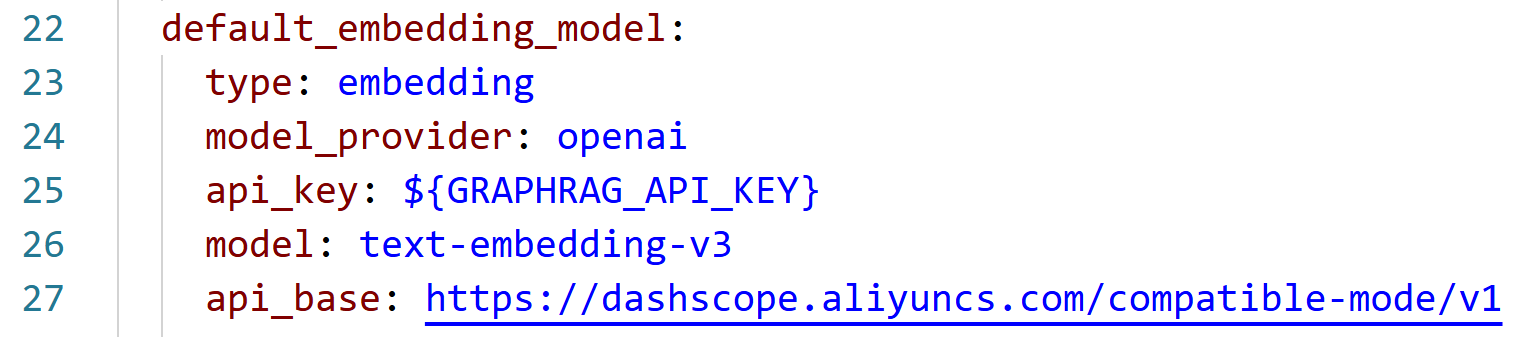
对 .env文件配置 api_key:

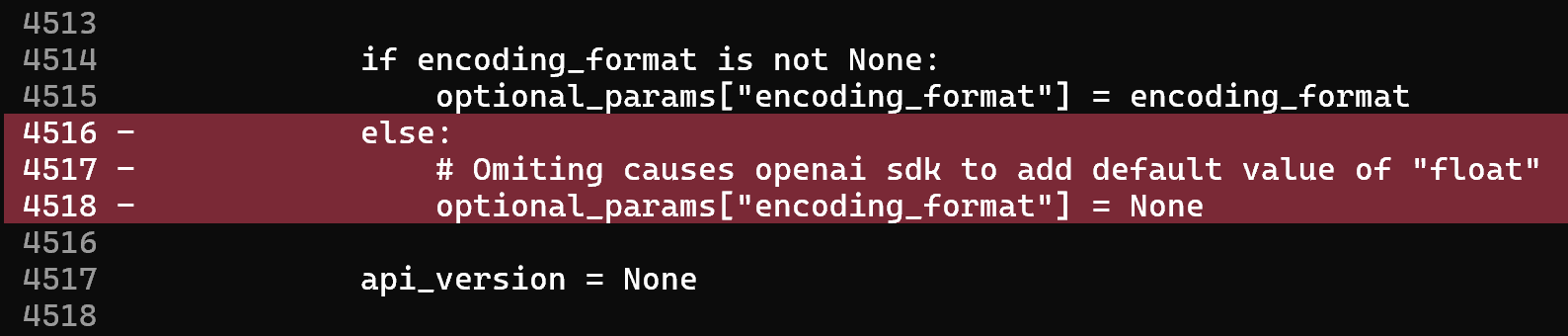
Step5, 将待检索的文档放到 ./input 目录下

说明:更新最新的 graphrag,运行时可能报错,需要修改litellm源码,即:
Step6, 创建GraphRAG索引(耗时较长,取决于文本的大小)graphrag index --root .
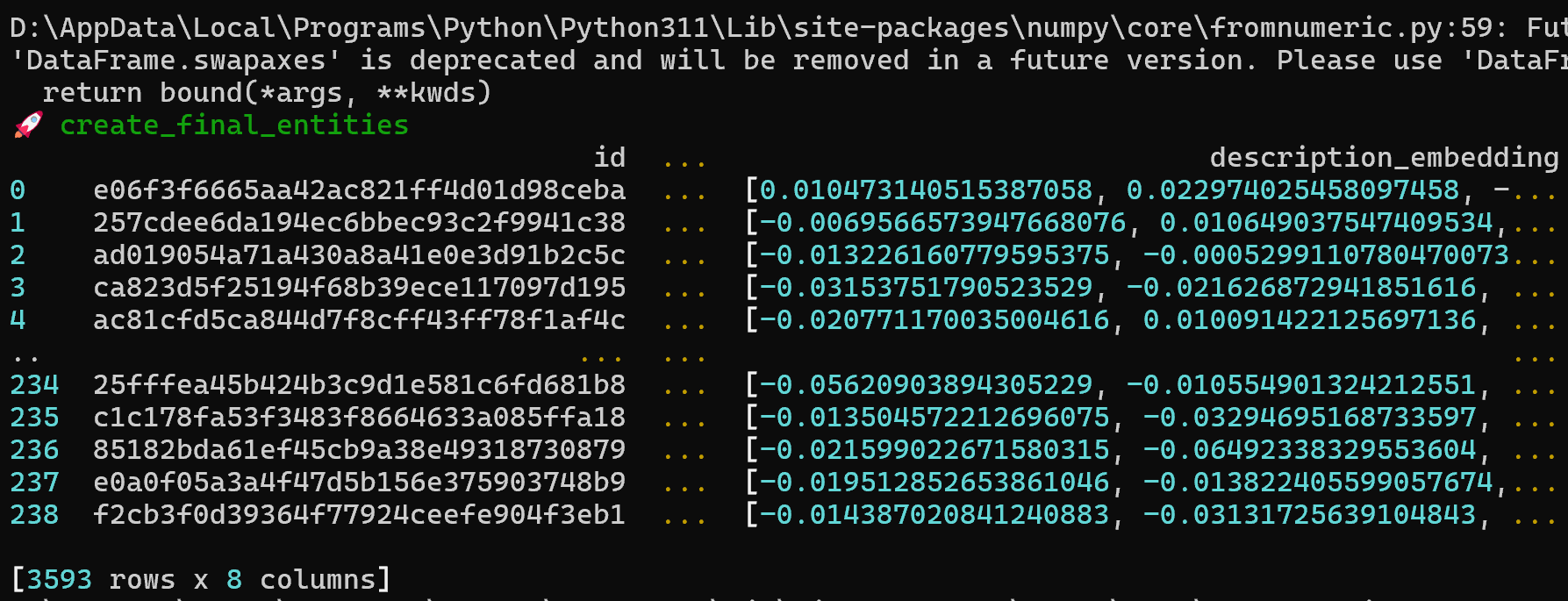
创建GraphRAG索引后,会在./cache文件夹下面生成4个文件夹,方便后续进行提问

Step7, 进行查询
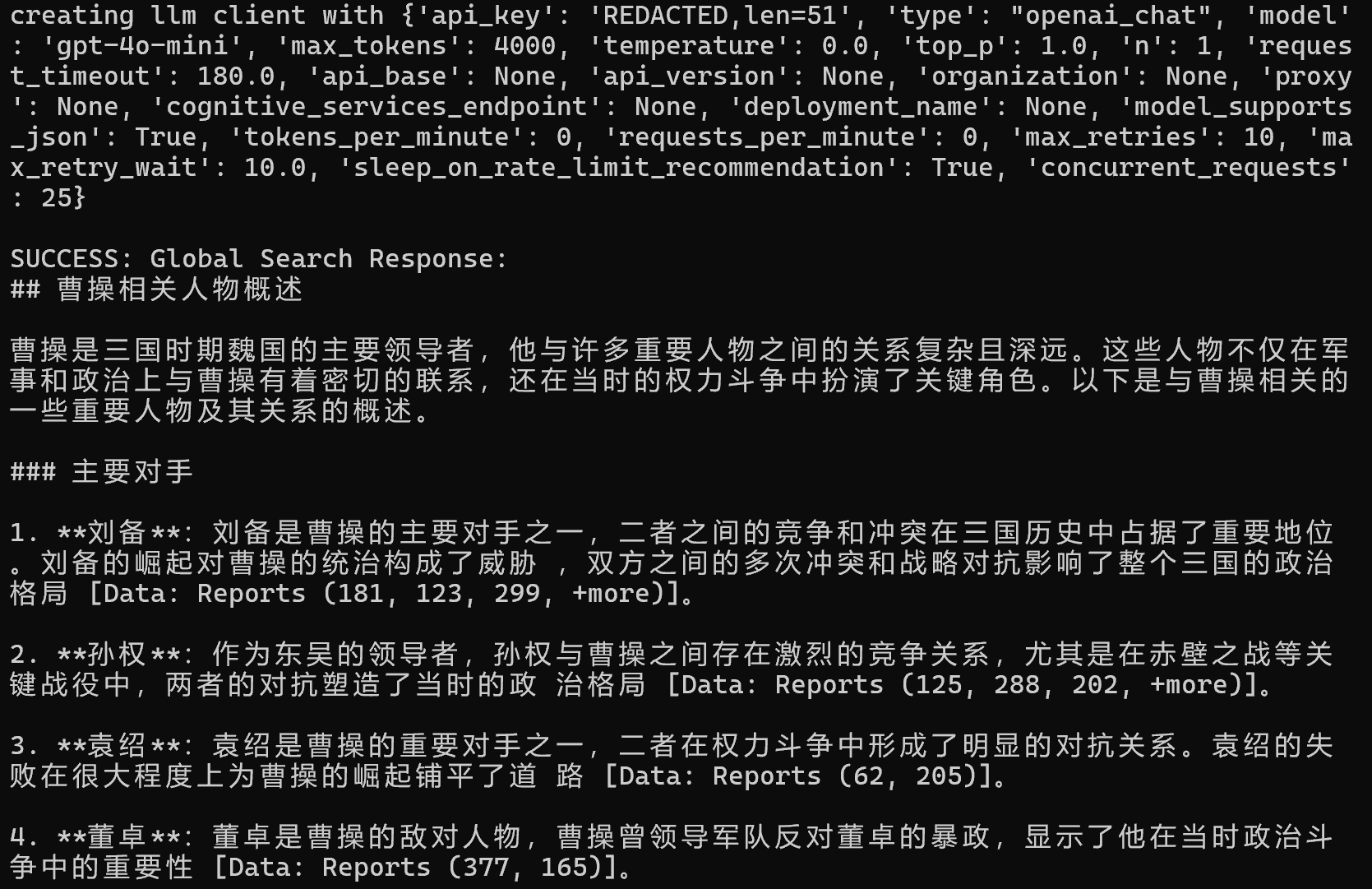
graphrag query --root . --method global --query “和曹操相关的人物都有哪些?”
它是LLM的推理后的文案,不像NativeRAG的chunk,chunk是原始知识
GraphRAG查询模式
GraphRAG 提供了两种查询模式:
- Global Query(全局查询)
- Local Query(本地查询)
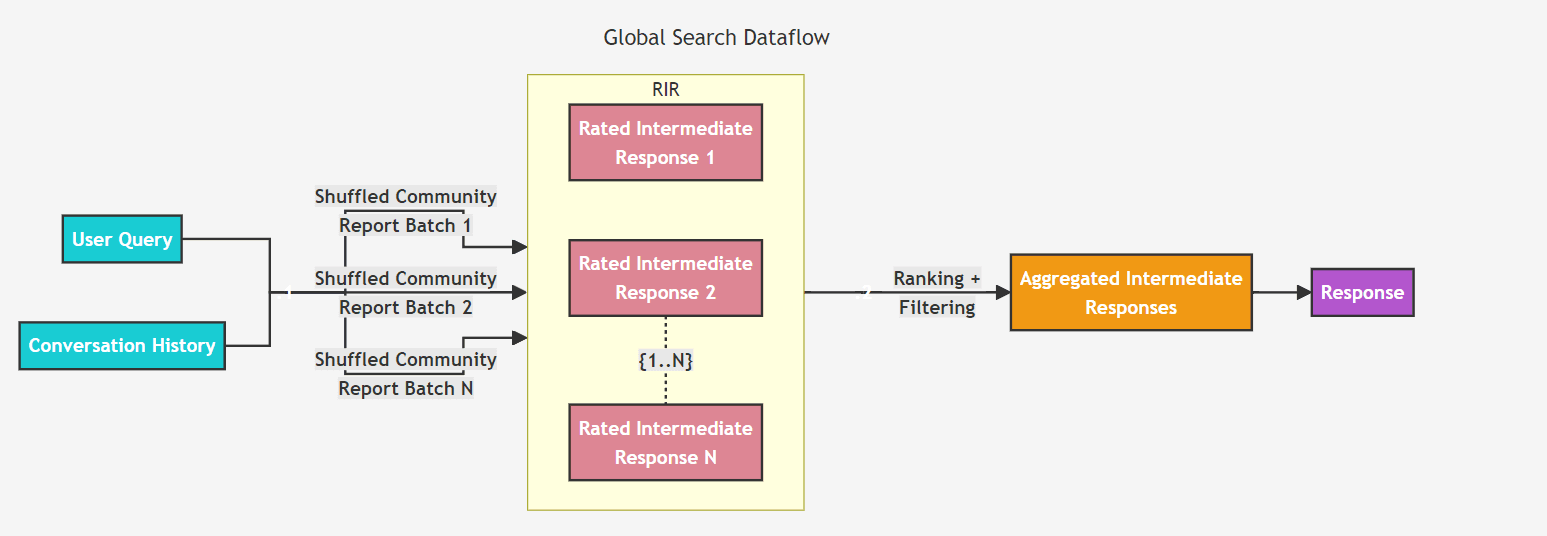
Global Query(全局查询):
用于回答全局性的问题,例如“《三国演义》的主题是什么”。它通过利用社区摘要,对整个语料库进行整体问题的推理,利用LLM生成的知识图谱来组织和聚合信息。
在具体实现上,Global Query 方法使用从社区层次结构指定层级中收集的报告作为上下文数据,以类似Map-Reduce的方式生成响应。
在Map步骤中,社区报告被分割成文本块,每个文本块用于生成中间响应,其中每个点都有一个数值评级。
在Reduce步骤中,从中间响应中挑选出最重要的点并进行聚合,最终形成用于生成最终响应的上下文。这种方法的直观理解是:越宏观的问题需要越宏观的视角和信息来回答。
这种查询方式是资源密集型的,但通常能够很好地回答那些需要对数据集整体有全面理解的问题。
全局搜索数据流:
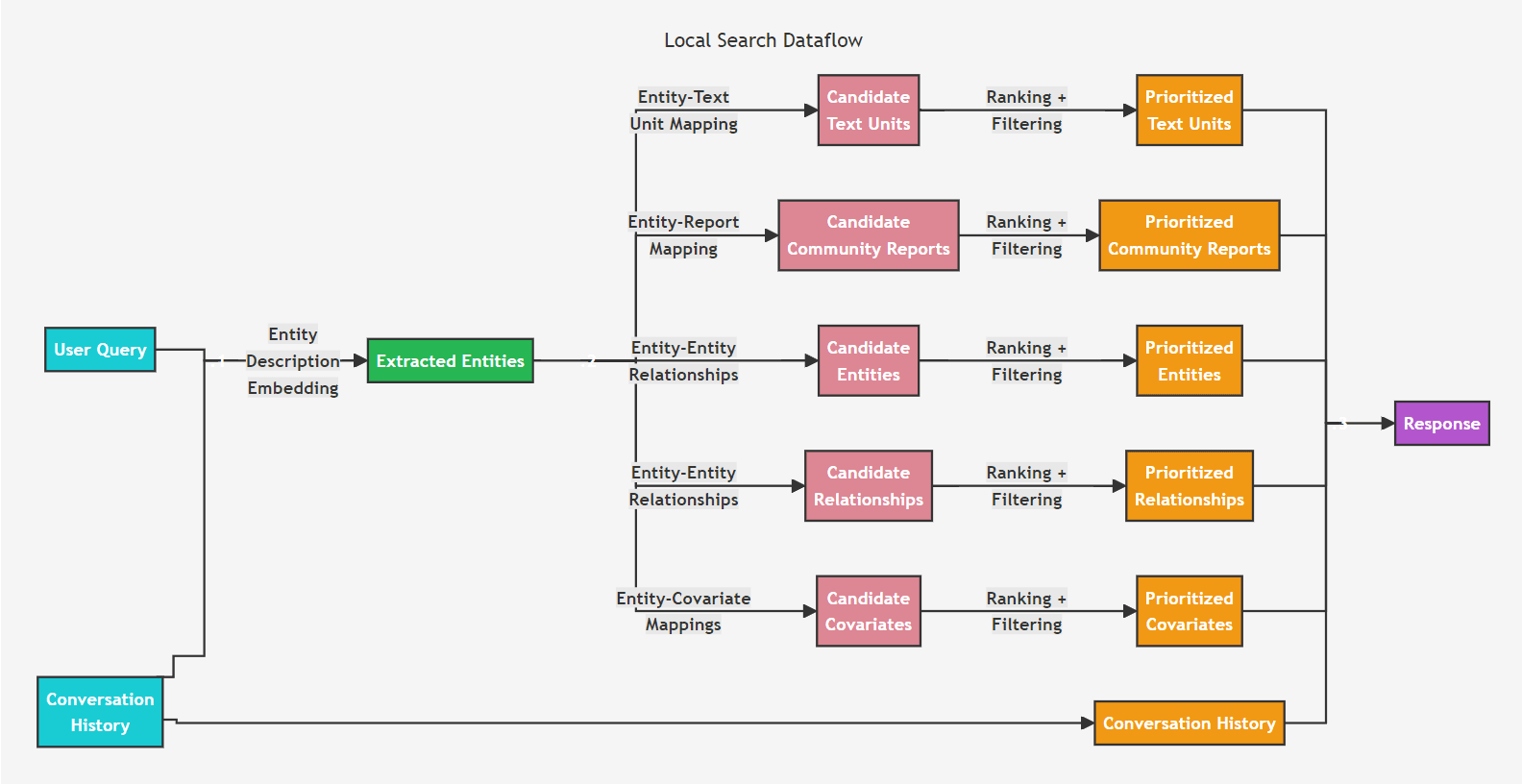
Local Query(本地查询):
用于回答更加具体的问题,例如询问“洋甘菊有哪些治疗特性?”。
本地查询则基于更加微观的视角,结合知识图谱中的结构化数据与原始文档中的非结构化数据,来增强检索和生成过程中的上下文。
在具体实现上,系统将依据原始提问,从知识图谱中识别出一组与用户输入语义相关的实体。然后,利用这些实体作为查询条件,在知识图谱或相关数据库中进行检索,找到与这些实体直接相关的内容,包含:TextUnit、社区报告、实体、关系或协变量(如主张)。检索的结果经过过滤和重排序后,选择高质量的数据源,并将其整合进一个预定义大小的上下文窗口。
这种方法适用于需要理解输入文档中特定实体的问题,通过结合AI提取的知识图谱和原始文档的文本块生成答案。
Global Query 适合处理需要跨数据集汇总信息的宏观问题,而Local Query 适合处理需要理解文档中特定实体的微观问题。
局部搜索数据流:
Global与Local模式对比:

Local答案生成: 针对具体问题,GraphRAG通过结合元素和元素摘要生成初步答案,这些答案来源于GraphRAG中的特定社区,
Global答案生成: 对于需要涵盖整个数据集的全局性问题,GraphRAG采用Map-Reduce机制,将所有社区的初步答案组合起来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)