Claude Code 架构深度解析:一文搞懂 Sub-Agent、Skill 与底层模型之间的协同机制
Claude Code 架构深度解析:一文搞懂 Sub-Agent、Skill 与底层模型之间的协同机制
Claude Code 凭什么成为 AI 编程工具市场占有率第一?本文深入拆解其内部四层架构——Skill 拦截层、Claude Code 编排器、Sub-Agent 执行层、底层大模型推理层——带你彻底理解这套被行业争相模仿的 Agent 架构设计。

目录
- 从一个问题说起
- 全局架构:四层协同模型
- 第一层:Skill 拦截层
- 第二层:Claude Code 编排器
- 第三层:Sub-Agent 执行层
- 第四层:底层大模型推理引擎
- 完整调用链路实战
- Skill vs Agent:一张表讲清区别
- 为什么这套架构能拿下 SWE-bench 80.9%?
- 对开发者的启示
- 结语
1. 从一个问题说起
如果你用过 Claude Code,你一定被它的能力震撼过——它能在 200K 上下文中理解整个代码库,能自主规划并执行持续数小时的复杂重构任务,能在 SWE-bench 上拿到 80.9% 的业界最高分。
但你有没有想过一个问题:Claude Code 的内部到底是怎么工作的?
它为什么有时会"自己直接干活",有时又"派一个小弟去搜代码"?它和底层大模型(比如 DeepSeek V4 Pro)是什么关系?所谓的 “Skill” 和 “Sub-Agent” 又有什么区别?
这篇文章将用一张架构图 + 三个实战场景,彻底讲清楚这些问题。
2. 全局架构:四层协同模型
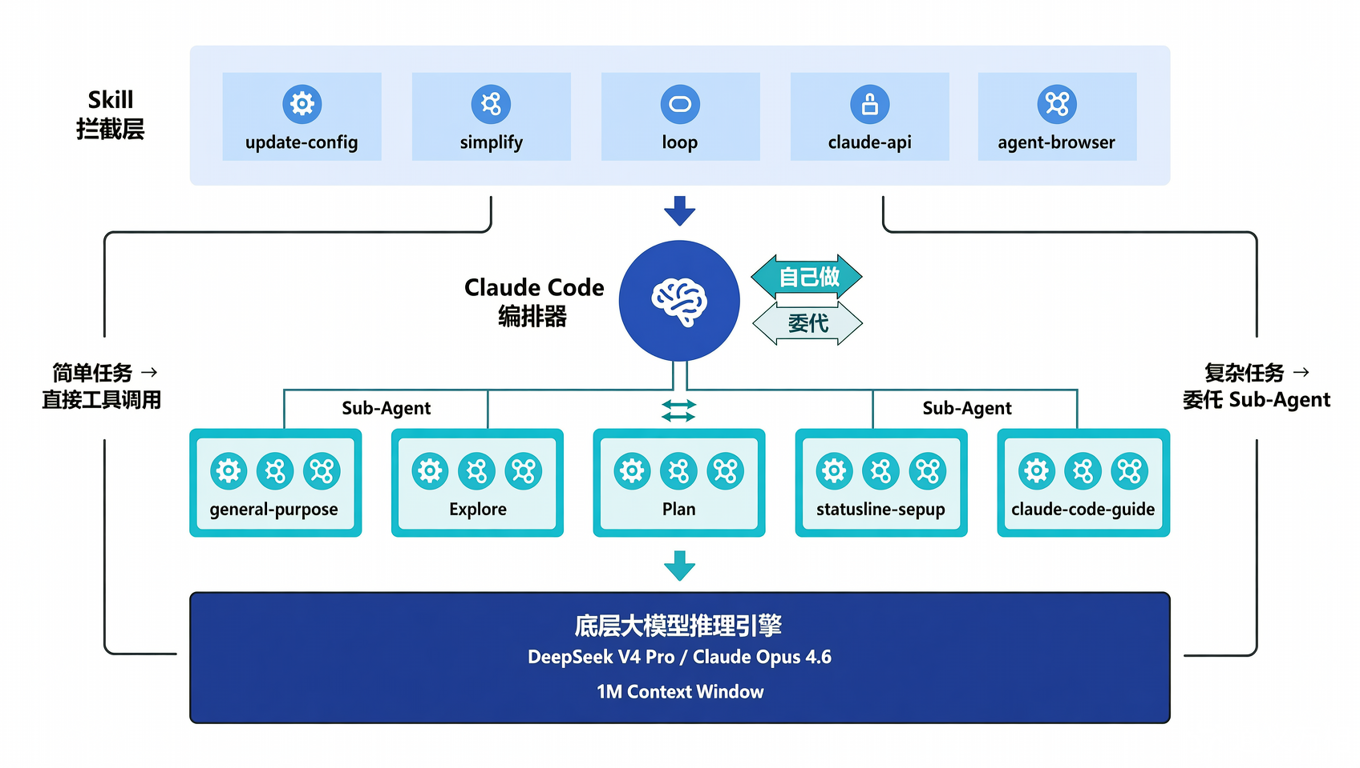
先看一张全景架构图(简化版):
先看一张全景架构图(简化版)
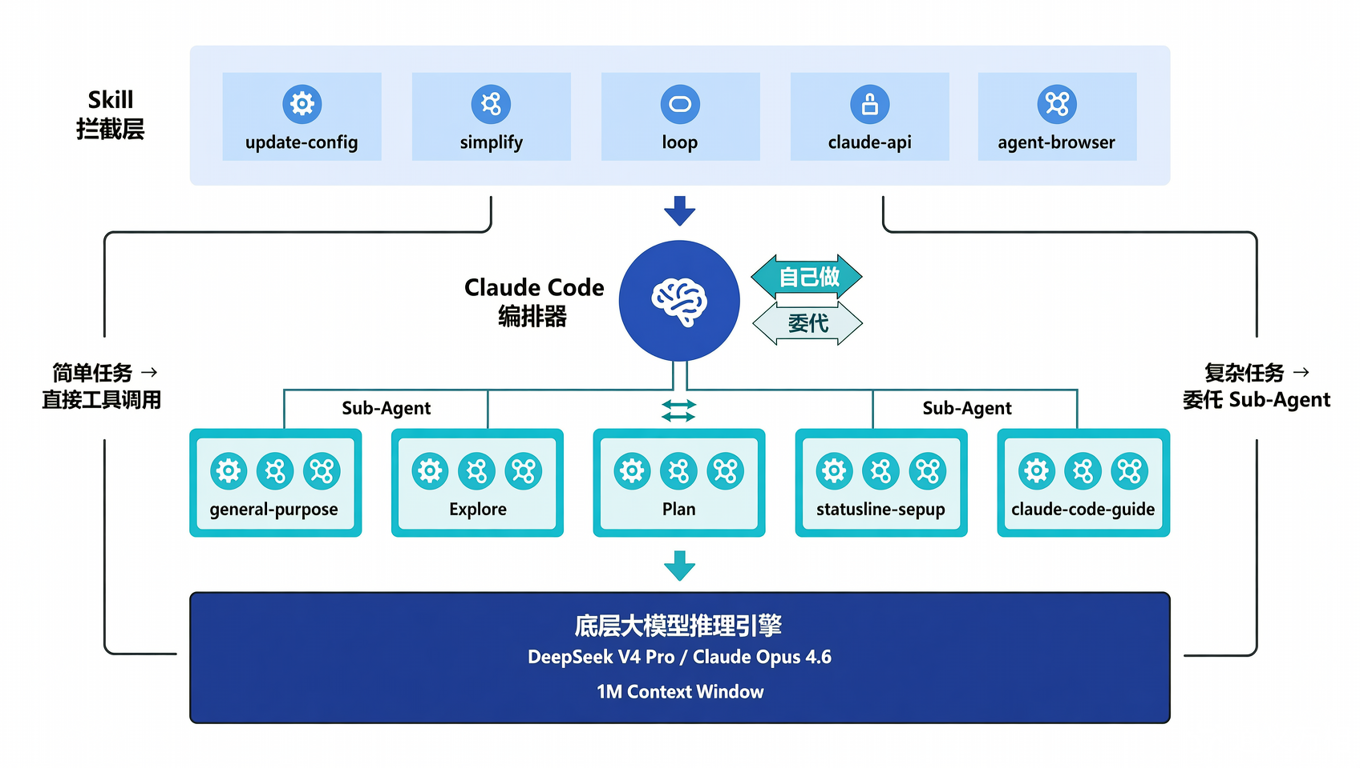
四层各司其职:
- Skill 层:最早拦截,给 Claude Code “加载插件”
- 编排器层:做决策,“这件事我自己干还是派人干”
- Agent 层:独立执行,“领到任务就去干活,干完回来汇报”
- 模型层:提供算力和推理,“所有人的大脑”
3. 第一层:Skill 拦截层
3.1 什么是 Skill?
Skill 是 Claude Code 的 “内置插件系统”。它不是独立的进程,而是在主会话内部动态加载的专项能力模块。
Claude Code 目前内置 5 个 Skill:
| Skill | 功能 | 触发方式 |
|---|---|---|
| update-config | 配置 settings.json,设置 hooks 和自动化行为 | 用户说"配置 Claude Code" |
| simplify | 审查代码的复用性、质量和效率,自动修复问题 | 代码变更后审查 |
| loop | 按固定间隔重复运行某个命令或 prompt | /loop 5m check deploy |
| claude-api | 加载 Claude API / Anthropic SDK 使用指南 | 代码中导入 anthropic 时自动触发 |
| agent-browser | 无头浏览器自动化,基于无障碍树操作网页 | 需要浏览器自动化时触发 |
3.2 Skill 的本质
Skill 不是独立进程,而是一段预设的 System Prompt 扩展。当 Skill 被触发时,相当于给 Claude Code 主会话"加载了一个知识包"。
举个例子,当你输入 /loop 5m check deploy 时:
1. Skill 拦截层识别到 /loop 命令
2. loop Skill 在主会话内展开——它将用户的指令转化为定时任务配置
3. Claude Code 获得"定时执行"的能力,不需要启动任何子进程
关键区别:Skill 让 Claude Code 本身变得更强大,Agent 则是派出去干活的"外包团队"。
4. 第二层:Claude Code 编排器
4.1 编排器的职责
这是整个系统的大脑。每收到一个用户指令,编排器需要做以下决策:
用户指令
│
▼
┌──────────────┐
│ 意图解析 │ ← 这到底是要干啥?
└──────┬───────┘
▼
┌──────────────┐
│ 复杂度评估 │ ← 简单还是复杂?需要几个步骤?
└──────┬───────┘
▼
┌──────────────┐ 简单 ┌──────────────┐
│ 执行路径决策 │─────────→│ 直接工具调用 │
│ │ │ Read/Write/ │
│ │ │ Edit/Bash/ │
│ │ │ Grep/Glob │
└──────┬───────┘ └──────────────┘
│ 复杂
▼
┌──────────────┐
│ 任务拆解 │ ← 拆成几个子任务?
└──────┬───────┘
▼
┌──────────────┐
│ Agent 委派 │ ← 派哪种 Agent?前台还是后台?
└──────┬───────┘
▼
┌──────────────┐
│ 结果汇总 │ ← 把 Agent 的结果整合,生成最终回复
└──────────────┘
4.2 亲自做 vs 委派子代理的判断标准
| 场景 | 决策 | 原因 |
|---|---|---|
| 读一个已知路径的文件 | 自己做 | 单次操作,不需要独立上下文 |
| 重命名一个变量(全局替换) | 自己做 | 用 Grep + Edit 直接完成 |
| “找出项目中所有 API 端点” | 委派 Explore Agent | 需要多轮搜索,范围不确定 |
| “实现用户登录功能” | 委派 Plan Agent 先规划 | 需要架构设计 |
| “同时搜索前端和后端代码” | 并行委派 2 个 Agent | 前后端搜索互不依赖 |
5. 第三层:Sub-Agent 执行层
5.1 五种 Sub-Agent 详解
| Agent 类型 | 专长 | 可用工具 | 典型场景 |
|---|---|---|---|
| general-purpose | 通用复杂任务 | 全部工具 | 多步骤实现、调试、重构 |
| Explore | 代码库搜索探索 | Grep/Glob/Read/WebFetch/WebSearch | “找所有调用 deleteUser 的地方” |
| Plan | 架构设计与方案规划 | 只读工具(不可写代码) | “设计缓存层的实现方案” |
| statusline-setup | 配置状态栏 | Read/Edit | 定制终端状态栏显示 |
| claude-code-guide | 知识问答 | Grep/Glob/Read/WebFetch | “Claude Code 怎么配置 hooks?” |
5.2 Sub-Agent 的独立特性
每个 Sub-Agent 启动时具备以下特性:
┌────────────────────────────────────┐
│ Sub-Agent 实例 │
│ │
│ ✅ 独立的上下文窗口 │
│ (不会污染主会话上下文) │
│ │
│ ✅ 独立的工具权限 │
│ (可按类型限制工具) │
│ │
│ ✅ 独立调用底层模型 │
│ (每次推理都调用 DeepSeek V4 Pro) │
│ │
│ ✅ 可选后台运行 │
│ (run_in_background: true) │
│ │
│ ✅ 可选 Git Worktree 隔离 │
│ (在临时分支上操作,不影响主工作区) │
│ │
│ ❌ 无法看到主会话的对话历史 │
│ (需要我写好完整的任务说明) │
└────────────────────────────────────┘
关键设计理念:Sub-Agent 是"派出去的助手"——你需要告诉它完整上下文和明确任务,但它不会干扰你的主工作区。
5.3 Agent 并行执行
Claude Code 支持同时启动多个 Agent:
用户:"把前后端的 API 端点都梳理出来,然后写一份接口文档"
┌──────────────────┐
│ Claude Code 编排器 │
└──────┬───────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Explore │ │ Explore │ │ 我直接写 │
│ Agent #1 │ │ Agent #2 │ │ 文档 │
│ │ │ │ │ │
│ 搜索前端 │ │ 搜索后端 │ │ 等两个 │
│ API 调用 │ │ API 定义 │ │ Agent │
│ │ │ │ │ 返回后 │
│ 返回结果 │ │ 返回结果 │ │ 整合输出 │
└──────────┘ └──────────┘ └──────────┘
这种设计带来了巨大的效率优势——两个独立的搜索任务互不阻塞,充分利用并行计算能力。
6. 第四层:底层大模型推理引擎
6.1 "大脑"的角色
无论是 Claude Code 编排器的决策,还是 Sub-Agent 的独立推理,都需要底层大模型提供算力。可以把这层理解为整个系统的"大脑"——它本身不执行任何工具操作,但为所有上层提供推理能力。
当前会话中,驱动我的是 DeepSeek V4 Pro,核心参数:
| 指标 | 数值 |
|---|---|
| 上下文窗口 | 1M tokens |
| 架构 | MoE(混合专家) |
| 参数规模 | 1.6T |
| Arena 排名 | 全球 Top 10 |
6.2 模型可替换性
Claude Code 的设计允许替换底层模型。在 Anthropic 官方部署中,可以使用的模型包括:
| 模型 | 定位 | 适用场景 |
|---|---|---|
| Claude Opus 4.6 | 旗舰 | 最复杂任务,SWE-bench 80.9% |
| Claude Sonnet 4.6 | 平衡 | 速度与能力最佳折中 |
| Claude Haiku 4.5 | 轻量 | 低延迟、高吞吐场景 |
| DeepSeek V4 Pro | 第三方旗舰 | 当前会话引擎,1M 上下文 |
这意味着:Claude Code 是一个"模型无关"的 Agent 框架。上层架构(Skill、编排器、Agent)不变,底层的推理引擎可以根据成本、速度、能力需求灵活切换。
7. 完整调用链路实战
场景一:简单命令 /loop 5m check deploy
时间线 →
T0: 用户输入 "/loop 5m check deploy"
│
T1: 【Skill 拦截层】匹配到 /loop 命令
│ loop Skill 在主会话内展开
│ 将指令转化为:创建定时任务,每5分钟执行 "check deploy"
│
T2: 【编排器】解析 Skill 展开后的指令
│ 判断:这是配置类任务,简单直接
│ 决策:我自己做
│
T3: 【编排器】调用 CronCreate 工具
│ 参数:cron="*/5 * * * *", prompt="check deploy"
│
T4: 【底层模型】DeepSeek V4 Pro 生成确认消息
│
T5: ✅ 用户收到确认:"已设置每5分钟检查部署状态"
全程在【主会话】内完成,未启动任何 Sub-Agent
底层模型被调用了 2 次(Skill 展开 1 次 + 生成回复 1 次)
场景二:复杂搜索 “找出项目里所有 SQL 注入风险”
时间线 →
T0: 用户输入 "找出项目里所有 SQL 注入风险"
│
T1: 【Skill 拦截层】无匹配,透传给编排器
│
T2: 【编排器】解析意图
│ 判断:需要在全项目中搜索多种 SQL 注入模式
│ 涉及大量文件,搜索结果可能很长
│ 决策:委派 Explore Agent(避免污染主会话上下文)
│
T3: 【编排器】准备 Agent 任务说明
│ 写明:搜索字符串拼接SQL、未参数化查询、动态SQL构建等模式
│ 限定:只读搜索,不修改代码
│
T4: 【Agent Tool】启动 Explore Agent(独立子进程)
│
├── Explore Agent 开始独立工作:
│ ├── 调用 Grep 搜索 "execute\s*\(.*\+" 模式
│ ├── 调用 Grep 搜索 "Statement\.execute"
│ ├── 调用 Grep 搜索 "format.*INSERT\|UPDATE\|DELETE"
│ ├── 每次搜索后调用底层模型分析结果
│ └── 汇总所有发现,生成结构化报告
│
T5: Explore Agent 返回结果给编排器
│
T6: 【编排器】收到 Agent 报告
│ 整合结果,调用底层模型生成面向用户的总结
│
T7: ✅ 用户收到完整的 SQL 注入风险报告
全程启动【1 个 Explore Agent】
主会话上下文保持干净(搜索结果在 Agent 内处理)
场景三:并行任务
时间线 →
T0: 用户输入 "优化首页加载速度,分析前后端各自的问题"
T1: 【Skill 拦截层】无匹配 → 透传
T2: 【编排器】任务分解
├── 子任务A:分析前端 bundle 大小、渲染性能、资源加载
└── 子任务B:分析后端 API 响应时间、数据库查询、缓存策略
T3: 【并行委派】同时启动 2 个 Agent
│
├── Agent A (Explore, 后台) ├── Agent B (Explore, 后台)
│ 搜索前端性能相关代码 │ 搜索后端性能相关代码
│ 分析 webpack 配置 │ 分析数据库查询
│ 检查组件渲染逻辑 │ 检查 API 中间件
│ ... │ ...
│ 完成,返回报告 │ 完成,返回报告
│ │
└─────────────────┬────────────────┘
│
T4: 【编排器】两个 Agent 都返回后
│ 整合两份报告,调用底层模型生成优化方案
│
T5: ✅ 用户收到完整的前后端性能优化方案
总计【2 个 Agent 并行】,耗时 ≈ 单 Agent 时间
8. Skill vs Agent:一张表讲清区别
这是最容易混淆的概念。简而言之:
| 维度 | Skill | Sub-Agent |
|---|---|---|
| 运行位置 | 主会话内 | 独立子进程 |
| 本质 | System Prompt 扩展(“知识包”) | 独立的 Claude Code 实例 |
| 触发方 | 用户命令或关键词自动匹配 | 编排器主动决策委派 |
| 是否有独立上下文 | 否,共用主会话上下文 | 是,独立上下文窗口 |
| 能否后台运行 | 否 | 是(run_in_background) |
| 能否并行执行 | 否,Skill 顺序加载 | 是,多个 Agent 可并行 |
| 典型用途 | 扩展能力、定时任务、浏览器自动化 | 复杂搜索、并行分析、架构规划 |
| 对用户可见性 | 显式调用(如 /loop)或自动加载 | 对用户透明,用户只看到最终结果 |
一句话总结:
Skill 是给我(Claude Code)加载的"技能插件"——我获得了新能力,但我还是我。
Agent 是我派出去的"独立助手"——它有自己的一整套工具、上下文和模型调用,干完活向我汇报。
9. 为什么这套架构能拿下 SWE-bench 80.9%?
SWE-bench 测试的是 AI 解决真实 GitHub Issue 的能力——需要理解大型代码库、定位问题、修改多处代码、确保测试通过。这恰恰是单体 LLM 难以胜任的任务。
Claude Code 的架构设计精准解决了这些痛点:
9.1 上下文隔离
问题:一次加载整个大型代码库会撑爆上下文窗口
解决:Explore Agent 独立搜索,只把结果摘要返回主会话
效果:200K 上下文 → 实际可用信息量放大 10 倍+
9.2 任务分工
单体 LLM:一个脑子同时搜索 + 分析 + 写代码 + 审查 → 注意力分散
Claude Code:
├── Explore Agent → 专门搜索(不会分心去写代码)
├── Plan Agent → 专门规划(不会被实现细节干扰)
└── 编排器 → 专门执行(已有清晰计划,只需实现)
9.3 并行加速
传统串行:搜索 → 分析 → 搜索 → 分析 → ...(慢)
Claude Code:
├── Agent A 搜索前端相关代码
├── Agent B 搜索后端相关代码 (同时进行)
└── Agent C 搜索测试文件
→ 时间效率提升 2-3 倍
9.4 错误隔离
单体 LLM:一处分析错误 → 整个任务跑偏
Claude Code:
├── Agent A 结果有误 → 编排器可以丢弃,重新委派
└── Agent B 结果正确 → 不受影响,继续使用
这就是为什么 Claude Code 能在 SWE-bench 上拿到 80.9%——不是模型最强,而是架构最合理。
10. 对开发者的启示
10.1 如果你在用 Claude Code
了解这套架构后,你可以更高效地使用它:
✅ 需要探索大型代码库时 → 直接提复杂问题,它自动委派 Explore Agent
✅ 需要多模块并行分析时 → 一次说清楚所有需求,让它并行启动 Agent
✅ 简单修改 → 直接说,它不会浪费资源启动 Agent
✅ 复杂重构 → 先让它规划(会触发 Plan Agent),再执行
10.2 如果你在构建 AI Agent
Claude Code 的架构提供了几个可复用的设计原则:
原则 1:分层拦截
→ 通用能力用 Skill 扩展(主会话内,轻量)
→ 专项任务用 Agent 处理(独立进程,隔离)
→ 不要把所有能力都堆在主 Agent 里
原则 2:上下文隔离
→ 搜索和探索类任务委派给子 Agent
→ 只把关键结果返回主会话
→ 保持主会话上下文干净、高效
原则 3:错误隔离
→ 子 Agent 失败不影响整体任务
→ 编排器可以丢弃错误结果、重新委派
→ 比单体 LLM 的容错能力高一个数量级
原则 4:模型无关
→ 框架层和模型层解耦
→ 可以随时替换底层模型(Opus → DeepSeek → 未来的模型)
→ 保护架构投资
11. 结语
回到开头的问题:Claude Code 的内部到底是怎么工作的?
答案是四层协同:
- Skill 层先加载需要的"技能插件"
- 编排器判断任务复杂度,决策"自己做"还是"派人做"
- Agent 层独立执行复杂任务,完成后汇报
- 模型层为所有层级提供推理算力
这套架构的精妙之处不在于单点有多强,而在于分工明确、隔离良好、灵活替换。它不是"让一个超级大脑做所有事",而是"组建一个协作高效的团队"。
这或许也是为什么 Claude Code 能以终端 CLI 这种"原始"形态击败一众 IDE 类竞品——体验的差距可以用架构的优势来弥补,反过来则不然。
📌 如果这篇文章有帮助,欢迎:
- 👍 点赞 让更多人看到
- 💬 评论 聊聊你对 Claude Code 架构的看法
- 🔖 收藏 方便随时查阅架构图
- 🔄 分享 给正在学习 AI Agent 设计的朋友
本文基于 Claude Code 实际对话中的架构探索整理,架构图和数据截至 2026 年 5 月。底层模型信息随部署环境不同而有所差异。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)