YOLOv5至YOLOv12升级:水果新鲜程度检测系统的设计与实现(完整代码+界面+数据集项目)
摘要:开发基于深度学习的水果新鲜程度检测系统对于降低流通损耗、提升分级效率与保障食品安全具有重要意义。本文围绕“水果新鲜/轻度腐败/严重腐败”等典型质量状态,构建了端到端的视觉检测与判别流程:在数据层面,结合多场景采集与清洗标注,覆盖不同光照、遮挡与背景干扰,并通过颜色扰动、模糊、Cutout/Mosaic 等增强提升泛化;在模型层面,采用以卷积与注意力机制为主干的目标检测或图像分类网络,实现对水果外观缺陷(霉斑、褐变、机械损伤、软烂渗出)及整体新鲜度等级的联合判定,并通过置信度阈值、类别重加权与标签平滑缓解类间不均衡;在部署层面,面向实际分拣/零售场景,提供可视化推理界面与结果追溯能力,输出新鲜度等级、关键缺陷区域热力图/框选标记、统计报表与导出接口。实验结果表明,该系统在复杂背景与跨批次数据上仍能保持稳定识别性能,为水果品质在线检测与自动化分级提供了可落地的技术参考。
文章目录
功能效果展示视频:水果新鲜程度检测系统YOLOv12-v11至v5(八个模型,含示例论文)合集(完整Python项目演示,UI界面,含论文等)
1.前言综述
水果在采后分级、冷链流通与零售陈列环节中会经历持续的生理代谢与微生物作用,其“新鲜—轻度劣变—腐败”的状态演化往往伴随颜色、纹理、表皮水分与局部霉斑等外观线索的微小变化,但这些线索在复杂背景、非均匀照明与遮挡条件下很容易被弱化,从而导致人工质检的主观性强、稳定性差与效率受限。面向这一类高频且强工程约束的质量检验任务,学界与产业界长期依赖近红外/高光谱等非破坏检测与机器视觉方法来增强对品质属性的可测性,其中高光谱成像结合智能算法已被系统性梳理为覆盖成熟度、病斑、机械损伤与感官质量等多维指标的有效手段,并指出数据可用性、工业可迁移性与标准化仍是制约落地的关键因素之一1。在仅使用RGB图像的低成本路径上,传统视觉通常围绕颜色直方图、纹理算子与形态学特征构建判别器,但其对拍摄条件与品类差异高度敏感,难以在跨批次、跨场景的供应链链路中保持一致性能。基于深度学习的端到端特征学习为该问题提供了更强的表达能力与泛化潜力,也使“水果新鲜程度检测系统”能够在设备成本、速度与精度之间获得更可控的折中。
从国内外研究现状看,水果新鲜度检测的建模范式大致经历了“手工特征—深特征迁移—端到端多任务/检测化”的演进。以迁移学习为代表的深特征路线,常通过预训练网络提取表征,再在低维特征空间完成分类或回归,例如在Current Research in Food Science上有工作将GoogLeNet、DenseNet-201与ResNeXt-101等深特征进行融合并结合PCA降维,以提升果蔬新鲜度识别的客观性与效率2。进一步地,端到端学习开始关注“新鲜度判别”与“品类识别”等相关任务的耦合关系,Zhang等在Current Research in Food Science提出多任务卷积网络并以统计检验与嵌入相似度分析论证多任务学习相较单任务的优势,从而为同一系统内的联合判定提供了可复用的结构范式3。在国内食品领域,针对模型可解释性与“模型关注区域是否合理”的落地顾虑,中国食品学报报道了在ResNet34中引入CBAM并结合类激活图实现可解释新鲜度检测的思路,为工业质检中的可追溯判据提供了可操作路径4。与此同时,检测化(detection-as-grading)的趋势日益明显,即将“新鲜/腐败”与“缺陷位置”同时作为输出,使系统不仅给出等级结论,还能给出导致劣变判定的局部证据;例如食品与机械提出YOLO-FFD在YOLOv5框架上引入轻量化模块与结构替换以兼顾速度与精度,体现了将分级问题工程化为实时检测问题的典型取向5。在更偏工程实现的中文期刊中,也已有以YOLOv5为核心实现水果品质检测与分类的系统化尝试,强调了采集、标注与端侧推理在流水线场景中的可用性6。
为了更直观地概括上述路线与代表性工作,老思将与“新鲜度/缺陷检测”强相关的研究按输入模态与学习范式做一个简表归纳如下。
| 代表性工作 | 输入模态 | 学习范式 | 主要优势 | 主要局限 |
|---|---|---|---|---|
| 文献2 | RGB | 深特征提取 + 传统分类器 | 工程实现简单,数据需求相对可控 | 对域偏移与细粒度缺陷的表达仍受限 |
| 文献3 | RGB | 多任务端到端分类 | 利用任务相关性提升泛化与稳定性 | 标注体系需兼顾多任务一致性 |
| 文献4 | RGB | 注意力 + 可解释分类 | 提供可视化证据,利于质检审计 | 对复杂背景与遮挡仍需强增强 |
| 文献5 | RGB | YOLO检测化分级 | 同时输出类别与位置,适配实时 | 小目标/弱缺陷仍依赖高质量数据 |
| 文献1 | 高光谱/多光谱 | 光谱建模 + AI | 可覆盖内部与化学品质属性 | 设备成本与标定流程更复杂 |
在技术难点层面,水果新鲜程度检测之所以“看起来像分类、做起来像系统”,核心原因在于真实场景的误差来源具有叠加性:其一,轻度劣变往往呈现为低对比度、非结构化的纹理与色彩漂移,导致网络容易将背景反光、果蜡高光与包装纹理误当作劣变特征;其二,数据分布强烈依赖品类、产地、季节与拍摄链路(手机/工业相机、色温、曝光),跨域泛化是模型部署后性能衰减的主要诱因;其三,很多高价值缺陷在RGB下并不显著,促使研究转向紫外荧光、近红外与高光谱等增强成像方案,例如近期在Elsevier平台发表的工作将UV-荧光成像与YOLO11结合以突出“肉眼不易察觉”的早期病害与机械损伤,说明多模态增强对早期缺陷检出的价值正在被重新评估7。此外,内部品质(如糖酸比、硬度、内部褐变)与外观新鲜度并非总是同步变化,因此仅依赖RGB的系统天然存在“可见性天花板”,这也是工业分级线在高端场景引入X-ray或光谱传感的重要原因;例如ICCV 2023相关工作探讨了在X-ray分选机上以深度学习识别苹果内部质量的鲁棒模型选择问题,直接体现了“吞吐率约束下的内部质量判别”这一工程现实8。在预测型任务上,IEEE Transactions on Instrumentation and Measurement亦有研究将动态模态分解与深度学习用于苹果采后腐烂预测,强调了时间演化与存储条件对品质退化建模的重要性9;而在近红外高光谱结合深度学习的质量/成熟度预测方面,Postharvest Biology and Technology等平台也持续给出可复用的建模与波段解释范式,为“外观+内在”联合评估提供依据10。围绕高光谱与深度学习的交叉方向,Springer近期综述进一步总结了在SSC、pH与硬度等品质指标预测中的网络结构趋势与数据冗余问题,凸显了轻量化与可迁移性在真实部署中的优先级11。
从算法与系统实现角度,视觉主干网络的选择会显著影响在边缘设备与实时分拣线上的可用性:轻量分类与检测常以高效卷积网络为基底,例如EfficientNet通过复合缩放策略在精度与计算量之间取得更优折中,为“精度优先”与“速度优先”的不同部署档位提供了可扩展基线12;而ResNet所代表的残差学习框架因训练稳定、迁移性能强,仍是许多新鲜度分类与缺陷识别模型的强基线13。在注意力机制方面,CBAM以通道与空间注意力的顺序建模方式提升特征表达并保持较小开销,使其在食品质检这类“弱缺陷、强干扰”的任务中具有较高性价比14。在目标检测范式中,YOLO将检测重构为单阶段回归问题并以高吞吐推理特性奠定实时检测的主流路线,为将新鲜度分级与缺陷定位统一到同一推理框架提供了方法学基础15。
基于上述背景与研究进展,本文(老思在博客中)聚焦构建一个可落地的“基于深度学习的水果新鲜程度检测系统”:其主要工作是以YOLO系检测框架完成新鲜度等级与缺陷区域的联合输出,并对比不同YOLO家族模型在同一数据集上的精度与速度差异;同时建立面向特定应用场景的数据集并完成标注、预处理与划分,以支撑可复现实验;在工程实现上,提供可视化交互界面与结果导出机制,形成从数据到模型再到部署的完整闭环,便于读者复用与二次开发。
主要功能演示:
主要功能演示部分可以从“先完成身份进入,再进行检测任务的全流程操作”这一叙事顺序展开,使读者在阅读时能够自然地把界面交互与系统能力对应起来。首先是注册与登录:系统启动后进入登录页,用户可选择注册新账号或使用已有账号登录;注册流程将用户名、加密后的口令与头像等资料写入SQLite数据库,并在登录校验通过后加载该用户的个性化配置与历史检测记录,从而保证不同操作者之间的模型选择、阈值参数与结果空间相互隔离。登录成功后主窗口自动切换并初始化检测模块,界面状态栏同步提示当前用户与运行状态,形成“账户体系—配置加载—检测主流程”的顺畅衔接。
进入主界面后,页面布局以“输入区—显示区—控制区—结果区”的结构组织信息密度:左侧通常提供输入源管理与播放控制(图片/文件夹/视频/摄像头切换、开始/暂停/停止、帧进度条等),中部为检测可视化区域,用于实时显示原图与叠加推理结果(检测框、类别名、置信度);右侧或下方作为结果与统计区域,展示当前帧/当前批次的类别计数、置信度分布、耗时与FPS等指标,并提供保存、导出与清空等操作入口。该布局的设计目标是将“看结果”和“调参数”放在同一视觉闭环中,减少用户在多窗口之间频繁切换的成本。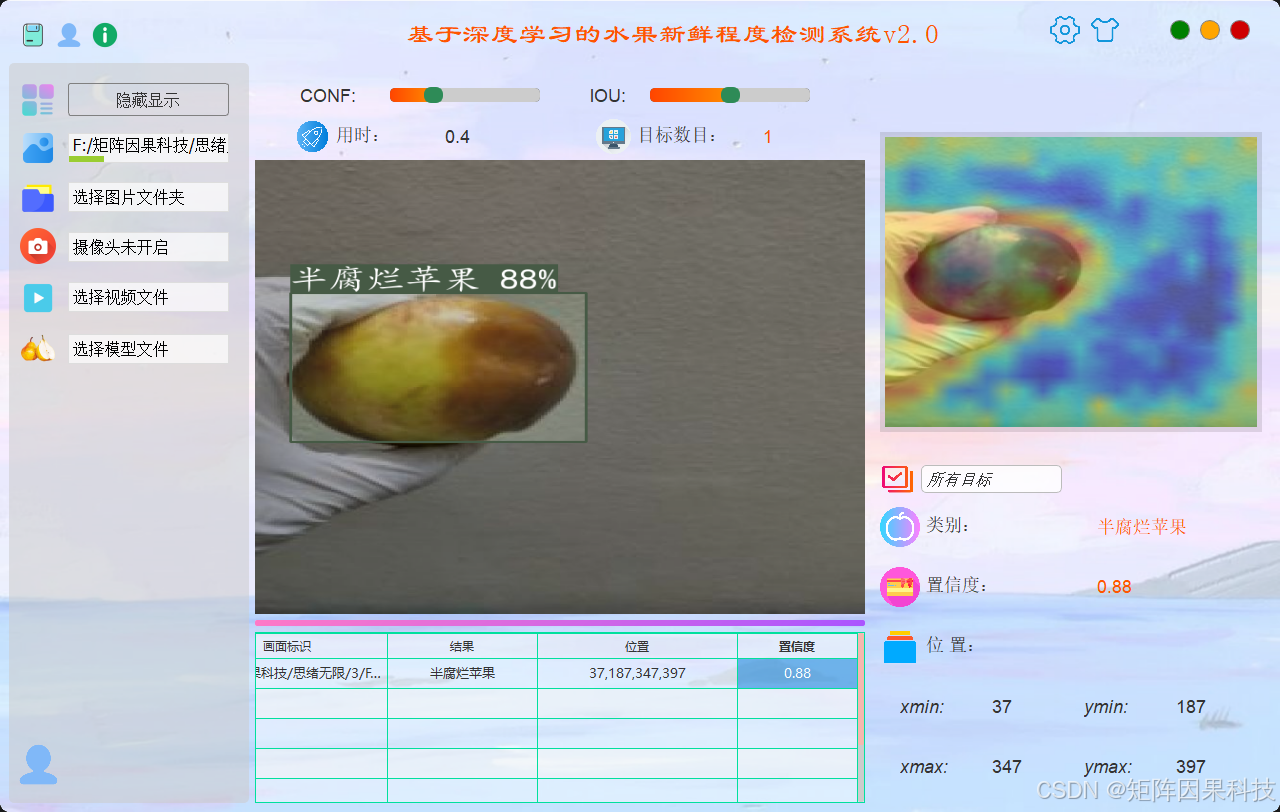
在模型选择方面,系统将检测器封装为可插拔模块,默认加载轻量化YOLO权重以满足实时性,同时允许用户在下拉框中切换不同YOLO系列或同系列不同规模的权重文件;切换时系统会先释放旧模型显存与推理上下文,再加载新权重并更新推理输入尺寸、后处理阈值等配置,使模型切换对用户透明且可控。为避免“换模型即重启”的低效体验,界面层通过信号-槽将“权重路径变更”“模型初始化完成”“推理状态变化”等事件与按钮状态、提示信息联动,确保在切换期间不会发生重复推理或资源冲突。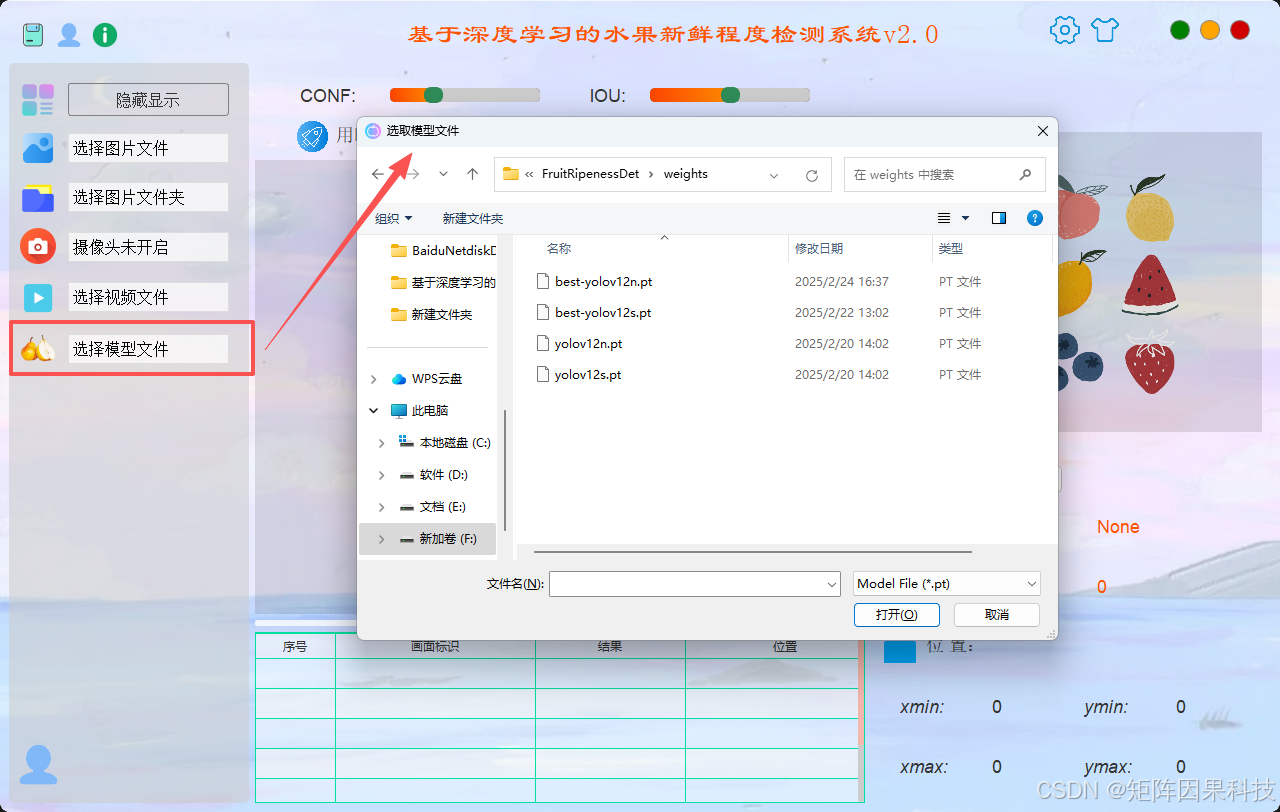
主题修改则主要服务于长时间使用下的可读性与场景适配:系统提供亮色/暗色主题与强调色切换,并支持对背景图、图标与关键字体颜色做统一替换;主题参数持久化写入用户配置表,确保下次登录自动恢复。与仅改变视觉风格不同,主题模块通常会同步调整表格行高、对比度与提示色等级,使检测框、置信度文字与统计图在不同光照环境(室内分拣线、户外移动端)下仍保持清晰辨识。对于演示而言,可通过一组“同一画面在不同主题下的对照截图”突出界面一致性与可读性提升。
2. 数据集介绍
本研究围绕“水果新鲜程度检测”这一细粒度视觉判别任务,构建了一个面向多品类、多退化阶段的目标检测数据集,总计 1974 张图像,并按训练/验证/测试三部分划分为 1326/437/211。数据覆盖了芒果、橙子、苹果、香蕉、梨、桃、瓜类以及葡萄等典型果品,并针对实际流通与存储过程中常见的外观变化,将同一品类进一步细分为“Fresh / Semifresh / Semirotten / Rotten”等状态标签;在标注层面以目标框形式同时提供“类别—位置”监督,使模型不仅输出新鲜度等级,还能给出可视化证据。结合你给出的可视化样例可以看到,腐烂样本通常呈现为局部霉斑、褐变、渗出与组织塌陷等纹理异常,而半熟/半腐烂往往仅表现为颜色与表面质感的弱变化,这使得数据在类间可分性上呈现明显梯度,属于典型的“弱缺陷、强背景”检测场景。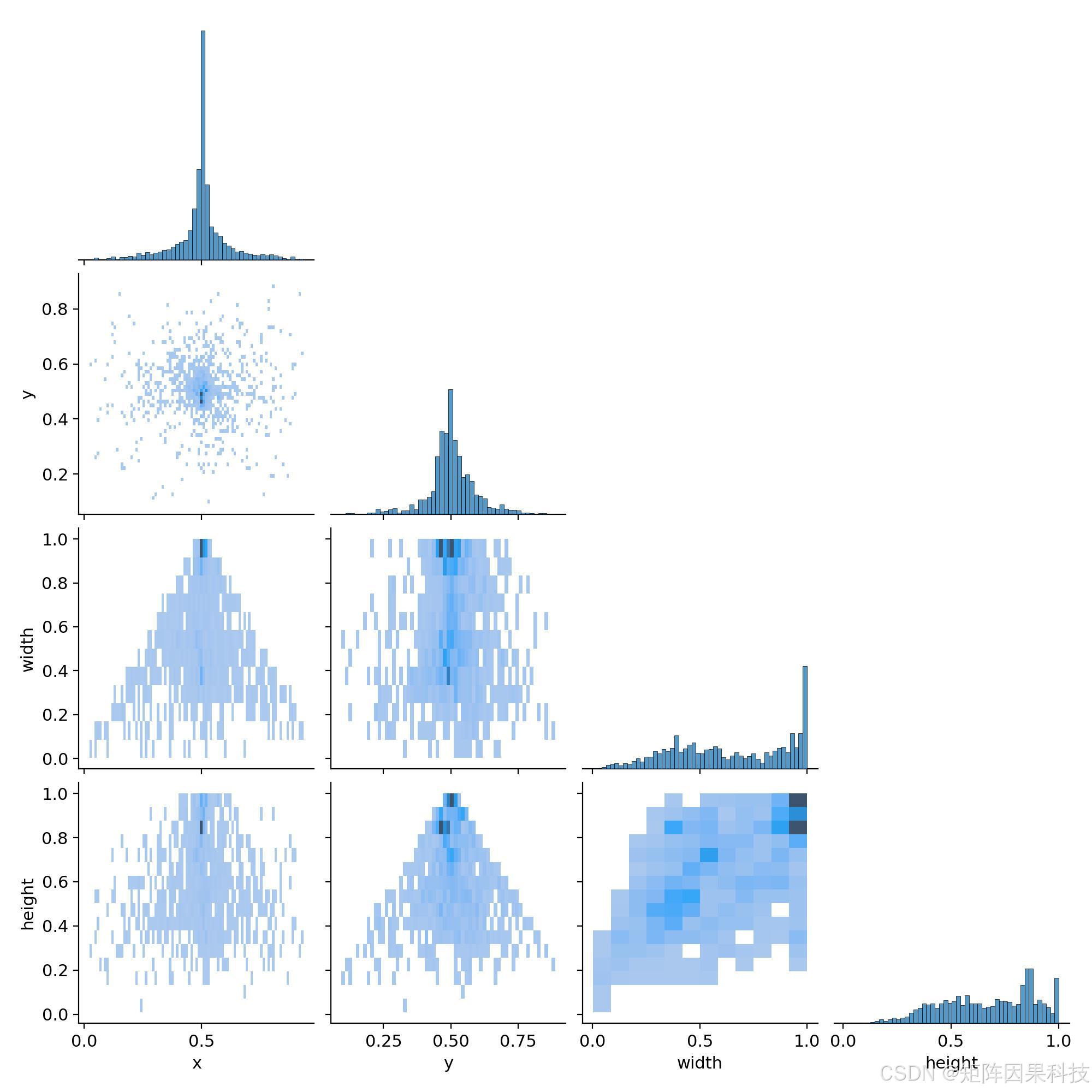
从标注统计分布看,边界框中心点在归一化坐标系中主要集中在画面中部附近,符合“单目标居中拍摄”为主的采集习惯;而宽高分布呈现较明显的长尾特征,说明同一类别在不同拍摄距离、裁切尺度与遮挡条件下目标尺度变化较大。该分布特性决定了训练阶段需要兼顾多尺度泛化与背景鲁棒性,通常会配合随机缩放、裁剪、色彩扰动以及Mosaic等增强来覆盖尺度与光照变化;同时,为了与YOLO系检测器的输入约束对齐,图像在送入网络前统一进行尺度归一化与letterbox填充,使标注框在归一化坐标下保持一致的几何语义,便于稳定训练与复现实验。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 1,326 张 (67.17%) |
| 验证集 (Val) | 437 张 (22.14%) | |
| 测试集 (Test) | 211 张 (10.69%) | |
| 总计 (Total) | 1,974 张 | |
| 类别清单 | Class ID: 0 | Apple Fresh(新鲜苹果) |
| Class ID: 1 | Apple Semifresh(半熟苹果) |
|
| Class ID: 2 | Apple Semirotten(半腐烂苹果) |
|
| Class ID: 3 | Apple Rotten(腐烂苹果) |
|
| Class ID: 4 | Banana Fresh(新鲜香蕉) |
|
| Class ID: 5 | Banana Semifresh(半熟香蕉) |
|
| Class ID: 6 | Banana Semirotten(半腐烂香蕉) |
|
| Class ID: 7 | Banana Rotten(腐烂香蕉) |
|
| Class ID: 8 | Mango Fresh(新鲜芒果) |
|
| Class ID: 9 | Mango Semifresh(半熟芒果) |
|
| Class ID: 10 | Mango Semirotten(半腐烂芒果) |
|
| Class ID: 11 | Mango Rotten(腐烂芒果) |
|
| Class ID: 12 | Melon Fresh(新鲜瓜类) |
|
| Class ID: 13 | Melon Semifresh(半熟瓜类) |
|
| Class ID: 14 | Melon Semirotten(半腐烂瓜类) |
|
| Class ID: 15 | Melon Rotten(腐烂瓜类) |
|
| Class ID: 16 | Orange Fresh(新鲜橙子) |
|
| Class ID: 17 | Orange Semifresh(半熟橙子) |
|
| Class ID: 18 | Orange Semirotten(半腐烂橙子) |
|
| Class ID: 19 | Orange Rotten(腐烂橙子) |
|
| Class ID: 20 | Peach Fresh(新鲜桃子) |
|
| Class ID: 21 | Peach Semifresh(半熟桃子) |
|
| Class ID: 22 | Peach Semirotten(半腐烂桃子) |
|
| Class ID: 23 | Peach Rotten(腐烂桃子) |
|
| Class ID: 24 | Pear Fresh(新鲜梨子) |
|
| Class ID: 25 | Pear Semifresh(半熟梨子) |
|
| Class ID: 26 | Pear Semirotten(半腐烂梨子) |
|
| Class ID: 27 | Pear Rotten(腐烂梨子) |
|
| Class ID: 28 | Ripe_Grape(成熟葡萄) |
|
| Class ID: 29 | Unripe_Grape(未成熟葡萄) |
|
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 混合数据集:实地拍摄与公开图像(手动清洗) |
3. 模型设计与实现
面向“水果新鲜程度检测”这一兼具细粒度外观差异与强场景干扰的任务,老思在模型侧优先选择以 YOLO 系列单阶段检测器作为统一建模框架:它能够在一次前向推理中同时给出目标位置与类别标签,从而把“新鲜度等级判别”和“缺陷证据定位”合并为同一输出接口,便于后续在系统端实现实时可视化与结果追溯。考虑到本文数据集具有多类别(30类)且类间差异呈渐变(Fresh/Semifresh/Semirotten/Rotten)这一特点,检测器不仅要具备对局部霉斑、褐变等高频纹理异常的敏感性,也要对光照反射、背景纹理、拍摄距离变化保持稳定;因此在基线选择上默认采用 Ultralytics YOLO12n 作为主模型,以“轻量化推理 + 注意力增强表征”的思路兼顾速度与细节建模能力。Ultralytics 对 YOLO12 的定位是“注意力中心”的实时检测架构,核心由 Area Attention、R-ELAN 等模块驱动,并可选用 FlashAttention 以降低注意力计算的内存访问开销。(Ultralytics Docs)
在网络结构上,模型可概括为 Backbone–Neck–Head 的三段式设计。Backbone 负责从输入图像中逐级提取语义特征,YOLO12 的改动重点在于将注意力机制以更“工程友好”的方式嵌入主干:一方面引入 Area Attention 将特征图划分为若干区域,在区域内进行注意力建模,以近似保持大感受野的同时控制计算量;另一方面通过 R-ELAN 重新组织特征聚合路径,并在块级引入残差与尺度化设计,缓解注意力堆叠带来的优化不稳定。与此同时,YOLO12 在注意力内部增加 7 × 7 7\times7 7×7 可分离卷积作为“位置感知器”,以隐式编码位置信息并减少显式位置编码带来的额外开销。(Ultralytics Docs) 这些结构对于本文任务的意义在于:当“半腐烂/半熟”仅表现为轻微色泽漂移或纹理粗糙度变化时,注意力模块更容易把判别性区域从复杂背景中聚焦出来,从而降低误检与混淆。
Neck 部分通常承担多尺度特征融合(FPN/PAN思想),其目标是在不同分辨率的特征层之间传递语义与细节信息,以同时覆盖大目标(整果)与局部缺陷(霉点、斑块等)。对于水果数据中常见的“目标尺度随拍摄距离变化而明显波动”的情况,多尺度融合能够显著改善小目标缺陷的召回,但也会引入更强的背景竞争,因此需要在训练中配合合适的数据增强与阈值策略来稳定输出。Head 部分则将融合后的多尺度特征映射为分类分数与边界框参数。Ultralytics 体系下的检测头通常采用 anchor-free 的预测方式,并以分布式回归思想引入 DFL(Distribution Focal Loss)以提升边界框定位精度;其具体实现与源码说明在 Ultralytics 的 loss 参考文档中给出了清晰的结构化定义。(Ultralytics Docs)
任务建模与损失函数方面,本文采用 YOLO 系列通行的多项损失加权形式,将分类、定位与分布回归同时纳入优化目标。整体损失可写为
L = λ box L ∗ box + λ ∗ cls L ∗ cls + λ ∗ dfl L ∗ dfl . \mathcal{L}=\lambda_{\text{box}}\mathcal{L}*{\text{box}}+\lambda*{\text{cls}}\mathcal{L}*{\text{cls}}+\lambda*{\text{dfl}}\mathcal{L}*{\text{dfl}} . L=λboxL∗box+λ∗clsL∗cls+λ∗dflL∗dfl.
其中, L ∗ box \mathcal{L}*{\text{box}} L∗box 通常基于 IoU 家族(如 CIoU 等)度量预测框与真实框的几何一致性,以减少偏移与尺度误差; L ∗ cls \mathcal{L}*{\text{cls}} L∗cls 通常采用二元交叉熵(BCE)或其改进形式(如 Focal/Varifocal 等)以应对类别不均衡与困难样本; L ∗ dfl \mathcal{L}*{\text{dfl}} L∗dfl 则将边界框回归从“直接回归一个连续值”转化为“回归离散分布并取期望”,从而提升定位的细粒度精度与梯度稳定性。Ultralytics 对 FocalLoss/VarifocalLoss 与 DFLoss 的实现逻辑在其参考文档中可直接对照复现。(Ultralytics Docs) 对本文数据而言, L cls \mathcal{L}_{\text{cls}} Lcls 的稳定性尤为关键:Fresh 与 Semifresh、Semifresh 与 Semirotten 的边界往往并非“形状差异”,而是由局部纹理与色彩统计的微差决定,若类间样本量存在偏斜或拍摄域差异较大,则更容易出现高置信度的错分,因此训练时应结合标签平滑、类权重或焦点损失等方式抑制“易样本主导”的梯度趋势(本文在训练策略章节再展开)。
在工程实现上,模型推理链路遵循“预处理—前向推理—后处理—可视化/导出”的闭环。预处理阶段将输入图像按 640 × 640 640\times640 640×640 统一尺度进行 letterbox 填充与归一化,以保证不同分辨率输入在几何语义上对齐;推理阶段输出多尺度候选框与类别分数;后处理阶段依据置信度阈值与 IoU 阈值执行筛选,并将最终结果映射回原图坐标系以叠加绘制检测框、类别名与置信度。你提供的 val_batch0_pred 可视化样例中,模型能够同时区分 Mango Fresh / Semifresh / Rotten 等状态,并在目标主体区域形成稳定框选,这也验证了“检测化分级”在系统展示层面的直观性:用户不仅看到等级,还能看到模型到底“看到了哪里”。此外,labels_correlogram 所呈现的框中心与宽高分布特征提示我们需要特别关注多尺度泛化与背景鲁棒性,这也是 YOLO12 在引入注意力与改进特征聚合后更适合作为本文默认基线的重要原因。(Ultralytics Docs)
4. 训练策略与模型优化
在水果新鲜程度检测的工程场景中,训练策略往往比“换一个更大模型”更能决定最终可用性,因为该任务的误差主要来自两类不稳定因素:其一是采集域的变化(光照色温、曝光、背景材质与相机成像链路),其二是类别边界的模糊性(Fresh 与 Semifresh、Semifresh 与 Semirotten 的外观差异呈渐变)。因此,老思在训练阶段遵循“先稳收敛、再提泛化、最后控误检”的思路组织流程:先用预训练权重快速获得可迁移的低层纹理与颜色统计表征,再通过数据增强与损失权重调节扩大有效样本覆盖,最后在验证集上以早停与阈值搜索把误检率压到系统可接受区间。
训练环境与流程配置上,默认采用 Ultralytics YOLO 框架在单卡 RTX 4090 上完成端到端训练与评估,输入分辨率统一设为 640 × 640 640\times640 640×640,以兼顾细粒度纹理与推理吞吐。训练轮数设置为 120 epochs,并启用 patience=50 的早停策略:当验证集指标在连续若干轮无提升时自动终止训练,避免后期在小数据集上出现过拟合与“验证集抖动式提升”。批大小取 batch=16,在 4090 显存条件下通常能够维持稳定的BatchNorm统计;优化器采用框架自适应(optimizer=auto),初始学习率取 lr0=0.01,并配合余弦或分段下降策略将末期学习率压至 l r 0 × l r f lr0\times lrf lr0×lrf(这里 l r f = 0.01 lrf=0.01 lrf=0.01),以在训练后段细化决策边界。为了改善早期收敛的梯度不稳定性,采用 warmup_epochs=3 的学习率预热,使网络在前几轮逐步建立合理的尺度与分类响应,再进入正常学习率区间进行有效学习;权重衰减取 weight_decay=5\times10^{-4},在检测任务中这一量级通常可在抑制过拟合与保持表征能力之间取得平衡。
迁移学习与微调策略上,本文默认启用 pretrained=true,即加载 COCO 等通用数据上训练得到的权重作为初始化。这样做的直接收益是:水果“腐烂/霉斑/褐变”的局部纹理与颜色突变,本质上依赖于边缘、斑点、粗糙度等低层与中层视觉模式,这些模式在大规模通用数据上已经被充分学习,迁移后只需在较少样本上调整高层语义即可获得较好的判别能力。实践中,若发现验证集在前十余轮上升缓慢或类别混淆严重,通常可以采用“分阶段解冻”的微调方式:先固定Backbone的前若干层,仅训练Neck与Head以快速适配新标签体系;当分类稳定后,再逐步解冻主干后段层,使模型在不破坏低层通用特征的前提下学习更适合“新鲜度渐变边界”的中高层表征。对于本文这类多类别细粒度任务,分阶段微调往往比一开始全量训练更稳定,尤其是在类别数量达到30类且部分状态类样本相对稀缺时。
数据增强与鲁棒性优化是该任务的关键环节。由于你提供的标注统计图显示目标大多位于画面中部且尺度分布存在长尾,训练时需要同时覆盖“尺度变化”和“背景变化”。默认启用 Mosaic(mosaic=1.0) 在训练前期合成多图场景以扩展背景多样性与目标尺度分布,并在训练后期通过 close_mosaic=10 关闭Mosaic,使模型在更接近真实分布的图像上收敛到更稳定的定位与分类边界;这一步往往能显著降低部署时的框偏移与误检。此外,还应结合随机HSV扰动、亮度/对比度抖动与轻微模糊来模拟不同相机与光照条件;对于“半腐烂”这类依赖局部细节的类别,过强的模糊或过度压缩可能会破坏有效纹理,因此增强强度宜以“提升域鲁棒性但不抹平缺陷纹理”为原则,通过验证集的误差类型来反向调整。
在模型优化层面,针对细粒度类别易混淆的问题,老思更倾向于在“损失与采样”上做小幅但有效的改动,而不是堆叠复杂结构。第一类优化是类别不均衡的处理:当某些品类或状态(如 Rotten)样本数量显著少于 Fresh 时,分类头容易被多数类主导,表现为少数类召回偏低或置信度偏低。此时可以采用标签平滑(缓解过置信)、类别权重重标定或焦点类损失(强调难样本)来改善梯度分配,使模型更愿意学习那些“外观差异微弱但业务上更关键”的边界。第二类优化是阈值与后处理策略:系统最终面向使用者时更关心“错把腐烂当新鲜”这类高代价错误,因此在验证集上应对置信度阈值 τ \tau τ 与 NMS 的 IoU 阈值 θ \theta θ 做网格搜索或按类别自适应设置,使得在不显著牺牲整体 mAP 的情况下,优先压低关键类别的漏检与误判风险。第三类优化是推理侧加速:在 4090 上可采用 FP16 推理并配合 TensorRT/ONNX 导出;在保证精度的前提下,轻量模型(如 YOLO12n)在边缘端的吞吐更稳定,适合与 PySide6 实时界面联动。
最后,训练过程的监控与诊断应贯穿全程。训练早期若出现分类损失下降而验证集指标不升,往往意味着增强过强或类别映射存在噪声;若定位损失长期高企,则需要检查标注框质量与输入缩放的letterbox回填是否一致;若特定类别长期混淆(例如 Semifresh 与 Semirotten),建议在数据层面补充“临界状态”样本,并在推理侧输出混淆对的Top-k概率用于人工复核,从而让系统在真实业务流中具备可解释的容错机制。通过上述策略,训练不再只是“跑完 epochs”,而是围绕部署目标对稳定性、鲁棒性与误检代价进行面向应用的优化。
5. 实验与结果分析
本节在同一数据集划分(Train/Val/Test = 1326/437/211)与统一训练配置( i m g s z = 640 imgsz=640 imgsz=640, e p o c h s = 120 epochs=120 epochs=120,相同增强与评估脚本)下,对 YOLOv5–YOLOv12 的 **n 型(轻量)**与 **s 型(小型)**模型进行对比实验。实验硬件为 NVIDIA GeForce RTX 3070 Laptop GPU(8GB),并记录端到端推理链路的三段耗时:预处理(PreTime)、模型前向(InfTime)与后处理(PostTime),以便从“精度—速度—稳定性”三个维度评估其工程可用性。度量指标采用检测任务通用的 Precision、Recall、F1 Score 与 mAP,其中 mAP50 表示 IoU=0.5 下的平均精度,mAP50-95 则更严格地综合 IoU ∈ [ 0.5 , 0.95 ] \text{IoU}\in[0.5,0.95] IoU∈[0.5,0.95] 的多阈值表现,通常更能反映定位与分类的整体稳健性。
从训练收敛过程看,多模型的 mAP50 曲线在前 10 个 epoch 快速上升并在 20–30 epoch 左右进入平台期,随后仅做小幅震荡式提升,说明在该数据规模下预训练初始化与增强策略能够迅速建立可分离特征,后期提升主要来自对细粒度边界(如 Semifresh 与 Semirotten)以及少数类的渐进拟合。以 s 型为例,YOLOv8s/9s/11s/12s 的 mAP50 最终基本收敛在 0.79–0.82 区间,曲线差异主要体现在“前期爬升速度”和“平台期抖动幅度”,其中 YOLOv11s、YOLOv12s 在平台期波动更小,训练过程更平滑,反映出其特征聚合与优化稳定性更利于细粒度检测任务的可复现训练(如下图所示)。
图:mAP50 收敛曲线(s 型)
在精度层面,Average PR 曲线给出了不同模型在召回率变化时精度衰减的整体趋势。就 n 型模型而言,平均 PR 曲线显示 YOLOv5su(注:图中给出的对比包含 v5/v6 的其它变体)在中高召回区间能够保持更高的 Precision 上界,而 YOLOv12n 的曲线在高 Recall 末端下降更快,意味着其在“尽量不漏检”的设置下更容易引入误检;这与后续混淆矩阵中“相邻状态类互相误判”的现象是一致的(如下图所示)。
图:平均 PR 曲线(s 型)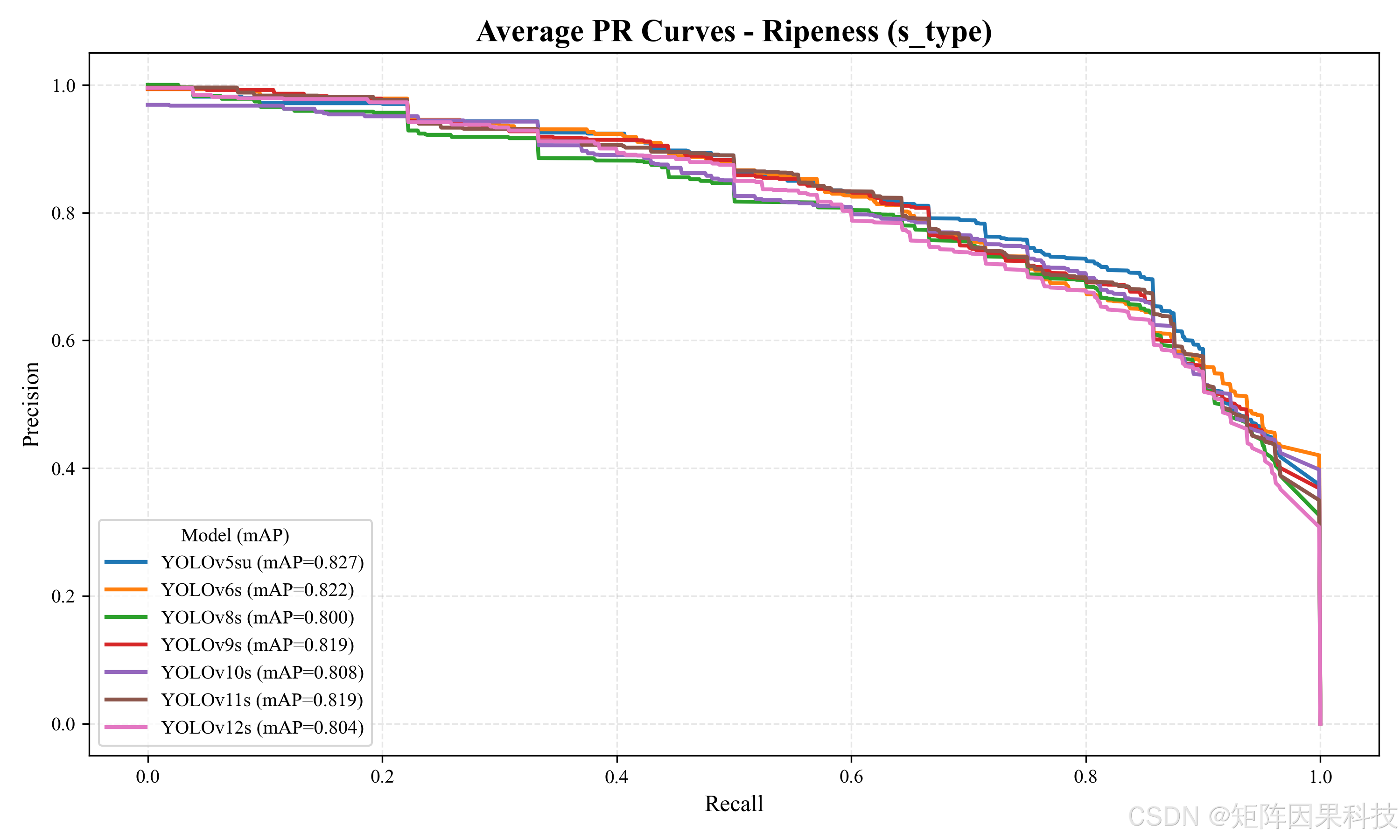
图:平均 PR 曲线(n 型)
为了更贴近系统部署,本研究进一步给出 F1–Confidence 曲线,用于确定统一阈值下的“综合最优点”。结果显示全类别的最优点出现在置信度阈值约 τ ≈ 0.506 \tau\approx 0.506 τ≈0.506,此时总体 F 1 ≈ 0.74 F1\approx 0.74 F1≈0.74,表明该任务在默认 NMS 策略下存在一个较稳定的阈值工作区间:阈值过低将明显放大背景误检与相邻等级误判,阈值过高则会带来腐烂/半腐烂等关键类别的漏检风险(如下图所示)。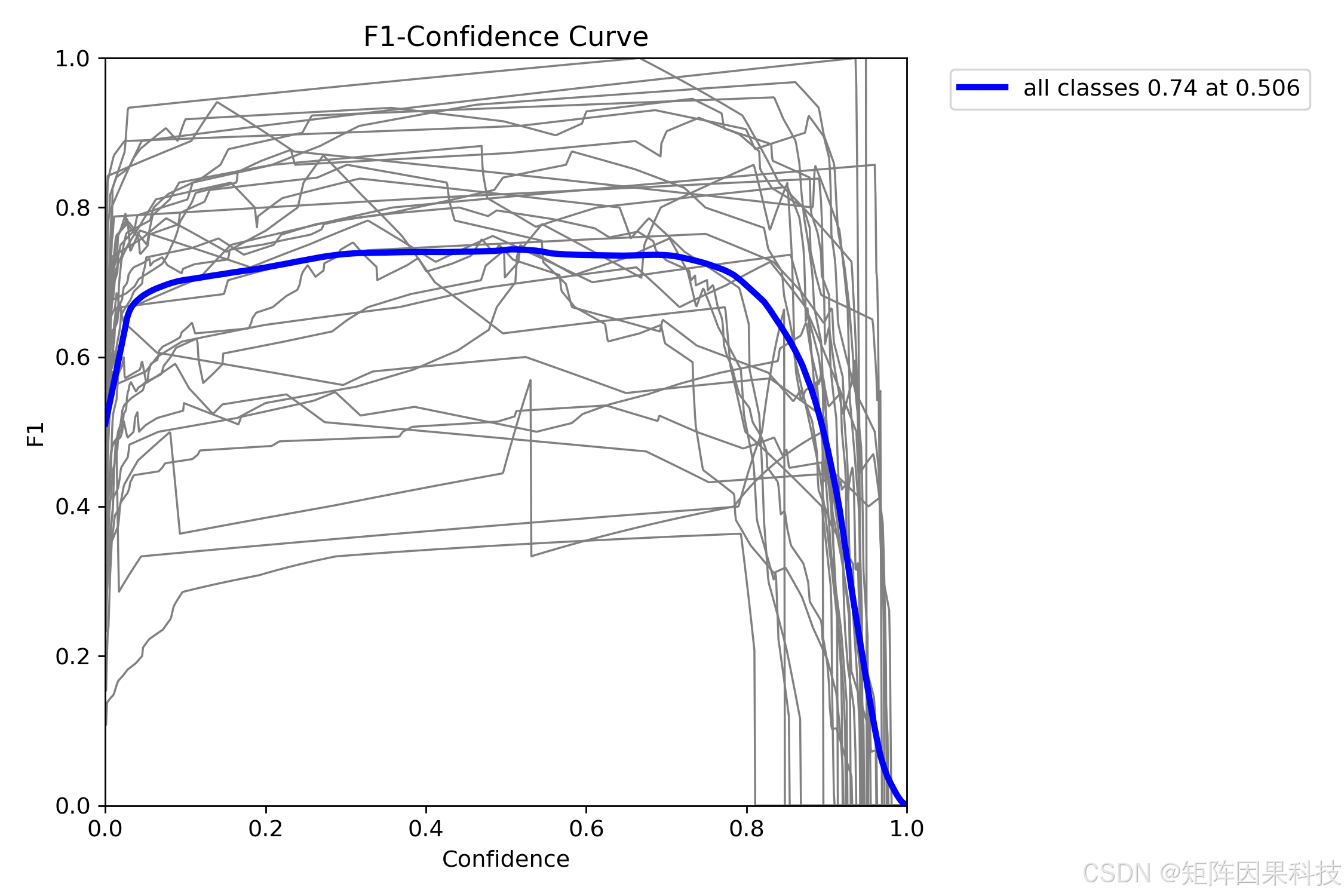
图:F1–Confidence 曲线(最优阈值点)
混淆矩阵(归一化)从类别层面揭示了错误的主要来源:对角线整体较深,说明大多数类别可被稳定识别;非对角线的“浅色块”主要集中在同一水果内部的相邻等级对上,例如 Fresh 与 Semifresh、Semifresh 与 Semirotten 之间更容易互相混淆,而跨水果类别(如 Mango 与 Orange)之间的误判较少。这一现象符合任务的视觉本质:同一水果不同新鲜度阶段的差异往往体现为颜色饱和度、表面蜡质反光与局部纹理的连续变化,缺少明确的几何边界;因此,仅依赖 RGB 外观的检测模型在“临界状态样本”上更依赖数据覆盖与标注一致性,而不是单纯扩大参数规模(如下图所示)。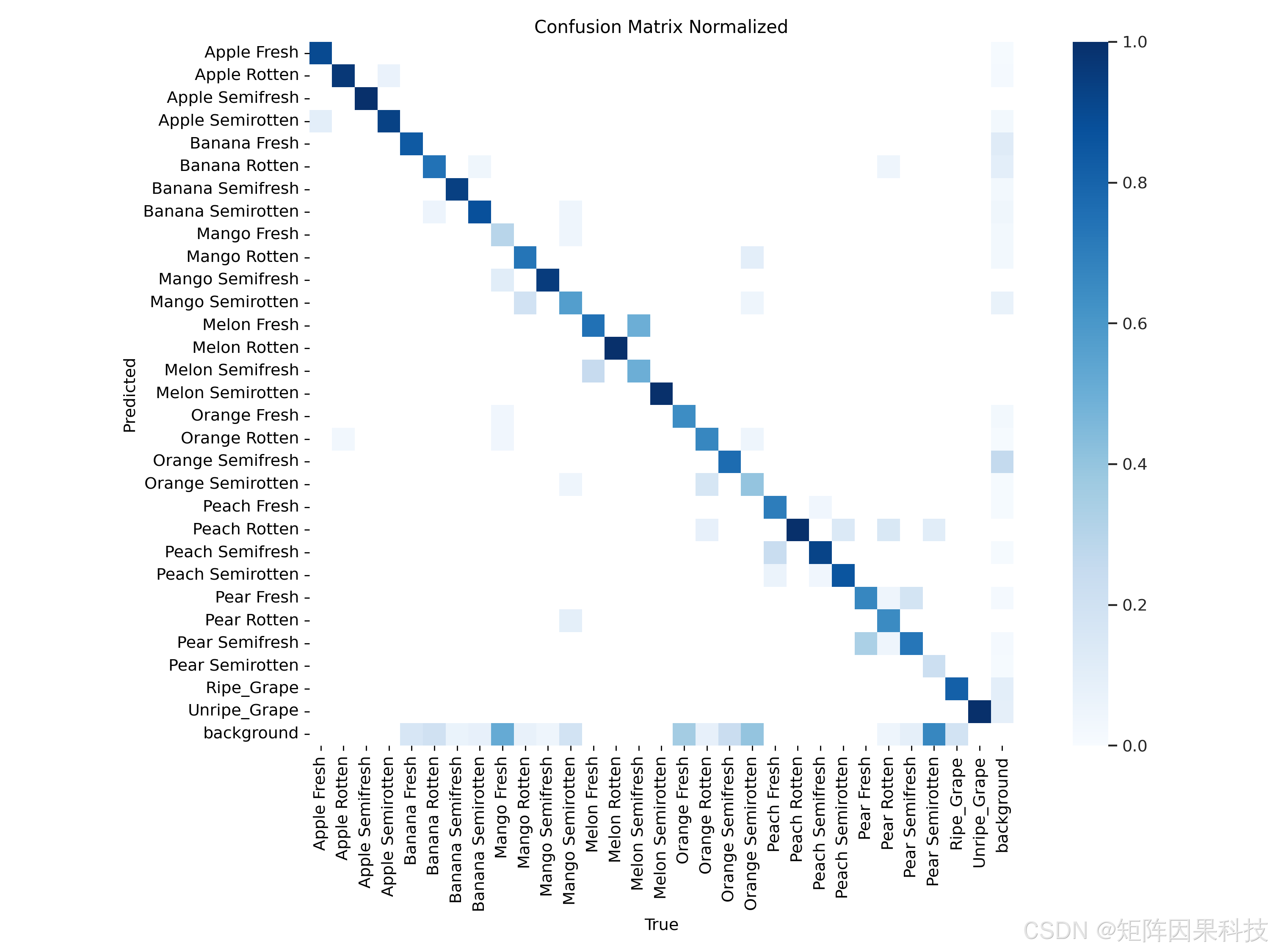
图:归一化混淆矩阵(类别级错误分析)
在定量对比上,老思把你提供的 n 型与 s 型结果按“精度(mAP50/mAP50-95、F1)—速度(InfTime)”的工程视角做归纳。总体上,n 型模型在 6–12 ms 的推理延时范围内已经具备实时交互基础,但不同版本存在明显的“召回—精度”取舍;s 型模型 mAP50-95 整体略优且更稳定,但推理耗时与算力需求显著上升,适合作为“精度优先”的离线复核或高端部署档位。
n 型(轻量)对比结论:YOLOv9t 在 mAP50 上达到最高(0.8215),并且 Recall 很高(0.8485),但 Precision 明显偏低(0.6537),说明它更倾向于“宁可多报也不漏报”,在腐烂检出这类高风险场景可能有价值,但会增加误检复核成本;YOLOv8n 的 F1 最高(0.7775)且 Precision/Recall 更均衡,同时推理仅 6.83 ms,属于综合最稳的实时配置;YOLOv5nu 的 mAP50 为 0.8185、Precision 达 0.8083,在“误检代价高于漏检”的零售端场景更友好。YOLOv12n 的 Precision 最高(0.8271)但 Recall 偏低(0.7082),更像是“保守型”检测器,若不做阈值与类别权重的专门校准,容易在半腐烂/腐烂早期样本上出现漏检。
s 型(小型)对比结论:YOLOv5su 的 mAP50 最高(0.8250),且 mAP50-95 维持在 0.6427,表现出较强的定位与分类综合能力;YOLOv11s 的 mAP50-95 最高(0.6489),说明其在更严格 IoU 阈值下的定位质量更稳定,适合需要更准确框选缺陷证据的可视化展示;YOLOv10s 的 F1 最高(0.7779)且 Recall 较高(0.8114),适合偏召回的分拣场景。需要注意的是,YOLOv9s 的推理耗时显著偏大(18.66 ms),即使精度不弱,也会在实时 UI 中造成更明显的帧率波动,不利于交互体验。
下面给出便于工程选型的简化汇总(完整表格即为你提供的原始数据):
| 模型 | F1 | mAP50 | mAP50-95 | InfTime(ms) | 取向建议 |
|---|---|---|---|---|---|
| YOLOv8n | 0.7775 | 0.8130 | 0.6361 | 6.83 | 实时综合最均衡 |
| YOLOv5nu | 0.7725 | 0.8185 | 0.6417 | 7.73 | 偏高 Precision,误检更少 |
| YOLOv9t | 0.7385 | 0.8215 | 0.6392 | 16.51 | 高 Recall,需控误检 |
| YOLOv11s | 0.7687 | 0.8173 | 0.6489 | 9.74 | 定位更稳,适合证据展示 |
| YOLOv5su | 0.7736 | 0.8250 | 0.6427 | 8.45 | s 型总体最强之一 |
| YOLOv10s | 0.7779 | 0.8062 | 0.6323 | 11.38 | 偏召回的分拣策略 |
结合系统落地,老思更建议采用“双档位策略”:在 PySide6 实时界面中默认使用 YOLOv8n 或 YOLOv5nu 作为在线推理主力,以保证帧率与交互稳定;对误检敏感或需要更精确框选证据的场景(例如抽检复核、数据回流再标注),再切换 YOLOv11s 或 YOLOv5su 进行离线复核。这样既能利用轻量模型的吞吐优势,也能在关键环节通过更强模型提升定位质量与难例判别能力,从而更符合“新鲜度渐变边界 + 工程实时约束”的综合需求。
6.系统设计与实现
6.1 系统设计思路
本系统面向“水果新鲜程度检测”的实时交互需求,在工程结构上采用典型的三层解耦:界面层负责 PySide6 控件组织与事件响应,控制层负责状态机与任务调度,处理层负责模型推理与后处理。老思在实现时将 UI 渲染与推理解耦为“信号—槽”驱动的异步协作关系:界面只发出输入源切换、开始/暂停、阈值更新、导出等信号;推理线程只回传检测结果与统计信息,避免 UI 主线程因 GPU 推理阻塞而卡顿。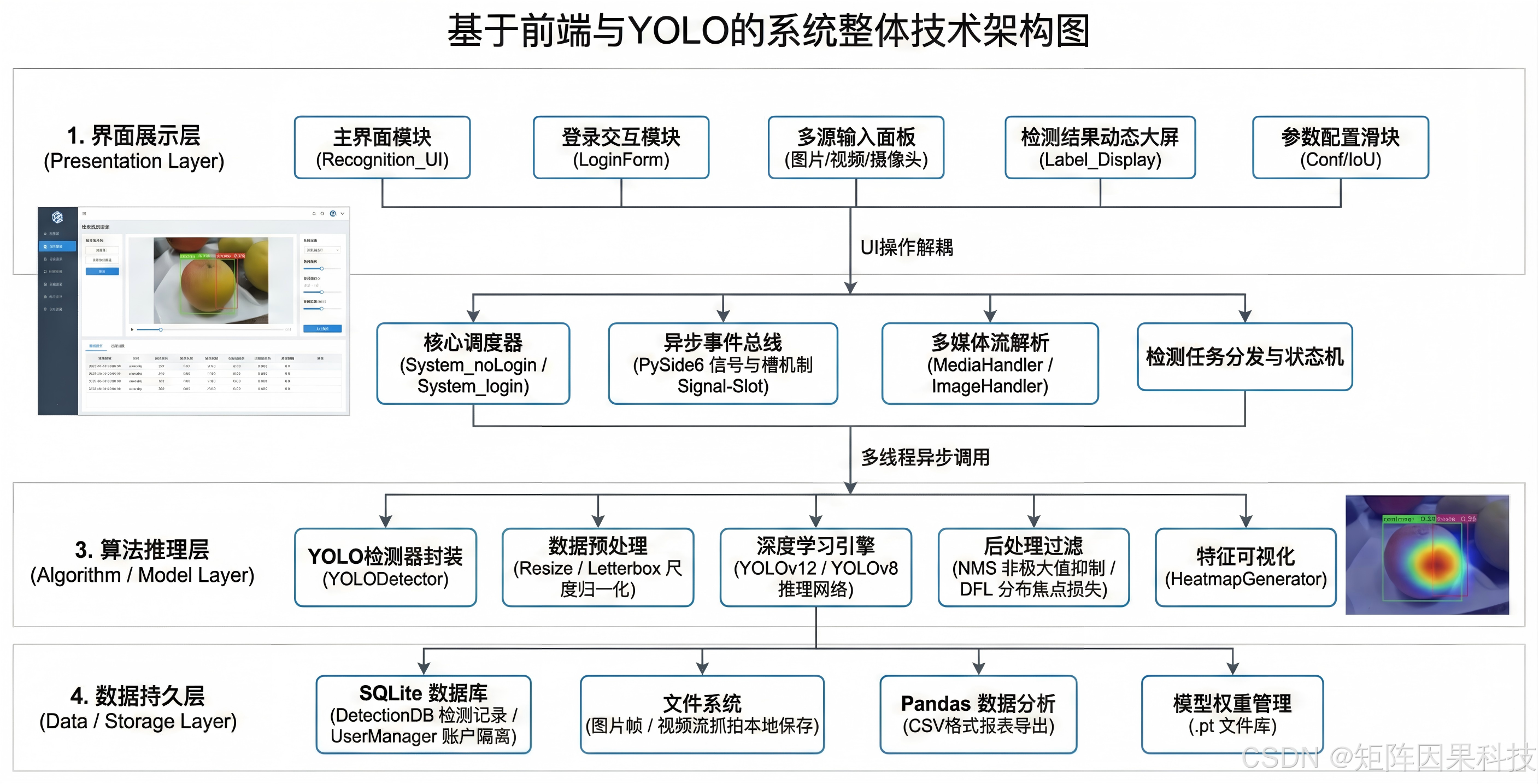
在模块划分上,MainWindow 作为控制中枢,维护当前输入源类型、播放状态、阈值参数(Conf/IoU)、模型与设备信息等全局状态,并以槽函数统一处理按钮事件;Ui_MainWindow 仅承担控件布局与样式资源加载,不直接涉及业务逻辑;Detector 则封装模型加载、预处理(letterbox/归一化/张量化)、推理、NMS 与坐标回映射,并生成可直接用于绘制的结构化输出(框坐标、类别、置信度、每类计数、耗时/FPS)。这种分层方式的关键价值在于:一方面便于在不改 UI 的前提下切换 YOLO 家族权重与推理后端,另一方面便于将检测结果写入 SQLite 或导出文件时保持数据结构一致,减少“展示逻辑”和“存储逻辑”之间的耦合。
系统运行时遵循“输入—推理—更新—交互闭环”的主线:用户选择图片/视频/摄像头后,控制层启动推理循环;处理层对每帧完成预处理与 YOLO 推理,并在后处理阶段完成阈值筛选与统计;界面层接收结果后刷新画面与表格,同时允许用户在任意时刻调整阈值、暂停/继续或导出结果。由于新鲜度等级属于细粒度类别,系统在交互上特别强调可解释输出:不仅显示最终类别,还通过框选与置信度把模型“判定依据”显式呈现,便于质检复核与数据回流再标注。
图 系统流程图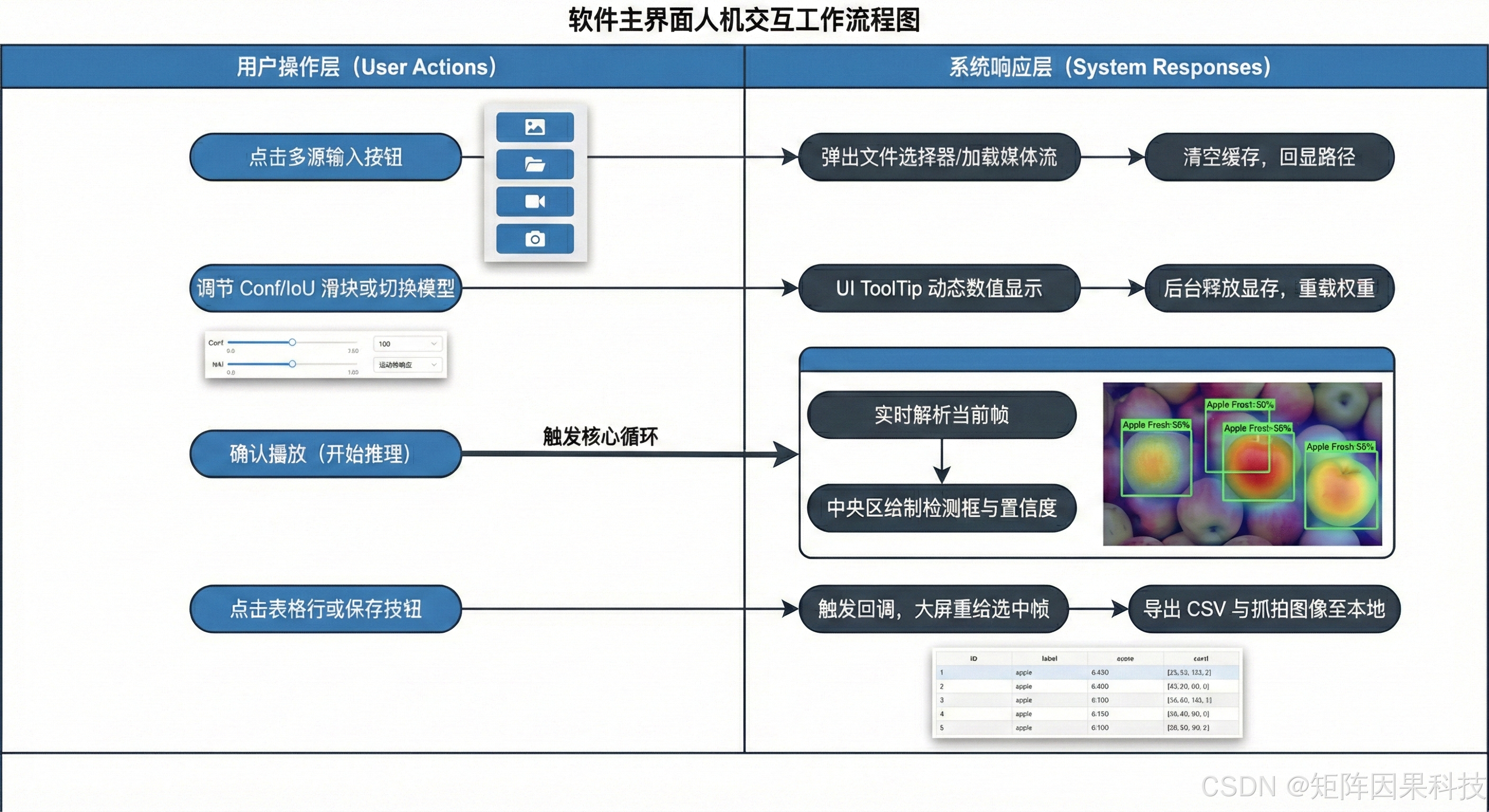
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理 — 流程图
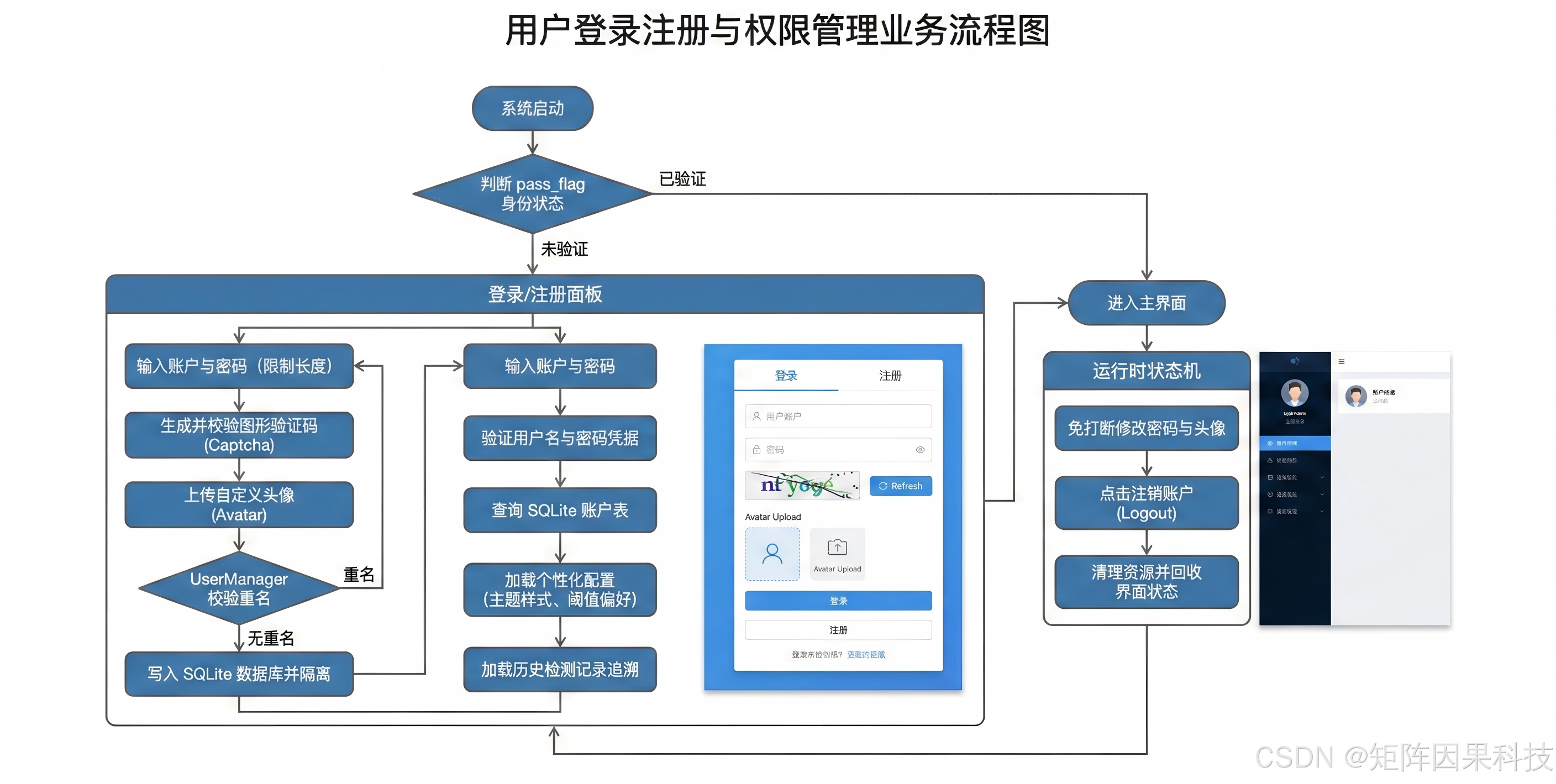
系统在登录入口引入基于 PySide6 与 SQLite 的账户体系,其核心并不止于“能登录”,而是为每位用户提供独立的配置空间与结果空间:注册阶段将用户名与加密口令、头像等信息写入数据库,登录阶段完成查询校验并加载该用户的主题样式、阈值偏好与历史检测记录,从而保证多操作者在同一设备上使用时互不干扰。进入主界面后,用户可在不中断检测主流程的前提下修改头像与密码,系统将变更持久化并在下次启动自动恢复;当用户注销或切换账号时,会话状态与界面状态被统一回收,确保检测结果导出、历史查询与个性化配置始终与当前身份绑定,从而把“账户管理”自然嵌入到“检测—统计—导出”的业务链路中,提升可追溯性与使用体验。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件(包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
功能效果展示视频:水果新鲜程度检测系统YOLOv12-v11至v5(八个模型,含示例论文)合集(完整Python项目演示,UI界面,含论文等)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8.参考文献
1 WIEME J, MOLLAZADE K, MALOUNAS I, et al. Application of hyperspectral imaging systems and artificial intelligence for quality assessment of fruit, vegetables and mushrooms: A review[J]. Biosystems Engineering, 2022. (ScienceDirect)
2 YUAN Y, CHEN X. Vegetable and fruit freshness detection based on deep features and principal component analysis[J]. Current Research in Food Science, 2023. (ScienceDirect)
3 ZHANG Y, YANG X, CHENG Y, et al. Fruit freshness detection based on multi-task convolutional neural network[J]. Current Research in Food Science, 2024. (ScienceDirect)
4 张寅升, 宋曾林, 王海燕. 基于注意力机制的水果新鲜度检测可解释模型[J]. 中国食品学报, 2024. (Zgspxb)
5 鄢紫, 陈良艳, 刘卫华, 等. 基于YOLO-FFD的水果品种和新鲜度识别方法[J]. 食品与机械, 2024. (iFoodMM)
6 基于YOLOv5的水果品质检测与分类方法研究[J]. 软件导刊, 2022. (Rjdk)
7 Beyond human vision: Highlighting and detecting inconspicuous defects based on UV-fluorescence imaging and advanced YOLO11 deep learning[J/OL]. Elsevier, 2026. (ScienceDirect)
8 TEMPELAERE W, et al. Deep Learning for Apple Fruit Quality Inspection Using X-Ray Imaging[C]//ICCV Workshops, 2023. (CVF Open Access)
9 STASENKO N, SHADRIN D, KATRUTSA A, SOMOV A. Dynamic Mode Decomposition and Deep Learning for Postharvest Decay Prediction in Apples[J]. IEEE Transactions on Instrumentation and Measurement, 2023. (ResearchGate)
10 Determination of quality and maturity of processing tomatoes using near-infrared hyperspectral imaging combined with deep learning[J]. Postharvest Biology and Technology, 2023. (ScienceDirect)
11 Recent trends in deep learning and hyperspectral imaging for fruit quality analysis[J]. Springer, 2025. (Springer)
12 TAN M, LE Q V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[C]//Proceedings of the 36th International Conference on Machine Learning (ICML), 2019. (Proceedings of Machine Learning Research)
13 HE K, ZHANG X, REN S, SUN J. Deep Residual Learning for Image Recognition[C]//CVPR, 2016. (CVF Open Access)
14 WOO S, PARK J, LEE J Y, KWEON I S. CBAM: Convolutional Block Attention Module[C]//ECCV, 2018. (CVF Open Access)
15 REDMON J, DIVVALA S, GIRSHICK R, FARHADI A. You Only Look Once: Unified, Real-Time Object Detection[C]//CVPR, 2016. (cv-foundation.org)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 20
20 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

{kind=link}
所有评论(0)