(四)OpenDriveVLA的5类Prompt设计与跨模态特征注入机制
导读:随着 Vision-Language-Action (VLA) 模型在自动驾驶领域的快速演进,Prompt 已从传统的“文本指令”升维为多模态控制信号的结构化载体。OpenDriveVLA 基于 Qwen2.5-Instruct 骨干网络与 LLaVA NeXT 框架构建,通过扩展特殊语义 Token 与跨模态投影对齐,实现了高维视觉特征与语言推理的深度融合。本文将系统拆解该项目中 5 类 Prompt 的分层设计范式,厘清训练阶段模型能力内化与推理阶段任务输入的边界,并重点剖析基于占位符的视觉特征注入机制。
一、 系统架构与数据流转:双分支并行处理
OpenDriveVLA 采用“视觉特征分支”与“文本指令分支”双路并行架构,最终在大语言模型(Qwen2.5-Instruct)的词表空间完成深度融合。完整的数据流转可划分为三个核心阶段:
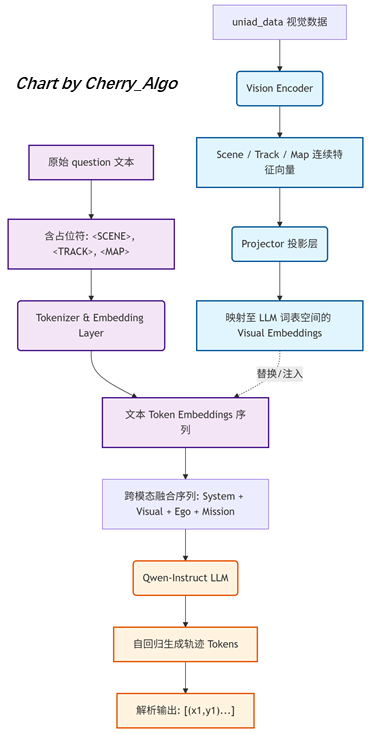
(1)视觉特征提取与投影: 多视角图像经 Vision Encoder 编码,输出 Scene(全局场景)、Track(目标跟踪)、Map(环境地图)三类高维连续特征向量。然后通过轻量级 Projector(论文中为:两层 MLP 投射层)将其投影至与 Qwen2.5-Instruct 词表 Embedding 维度完全一致的向量空间,生成可直接与文本融合的 Visual Embeddings。
(2)文本指令结构化: 通过在驾驶任务文本中插入 <SCENE>、<TRACK>、<MAP> 等占位符,构建出结构化的多模态指令;经 Tokenizer 与 Embedding 层处理后,形成基础的文本 Token 序列。
(3)跨模态融合与自回归生成: 系统精确定位文本序列中的占位符槽位,用对齐后的视觉特征向量替换占位符原本的文本 Embedding。融合后的完整序列输入 Qwen-Instruct LLM,模型以自回归方式逐 Token 预测,解码后即可得到 3 秒内的 6 个规划轨迹点。
二、 5类Prompt的训练与推理边界
2.1 五类 Prompt 的功能
OpenDriveVLA 论文中明确定义了 5 类功能各异的 Prompt(详见论文Appendix-B:Prompting Techniques),但推理阶段仅需其中 2 类。其核心逻辑在于“训练阶段提升模型能力”与“推理阶段的任务输入”存在严格的工程边界。
| Prompt类型 | 核心作用 | 训练阶段 | 推理阶段 |
|---|---|---|---|
| System Prompt (系统提示) | 定义模型角色、坐标系、任务要求与固定输出格式 | ✅ | ✅ |
| Hierarchical Feature Alignment (分层特征对齐) | 引导视觉特征与文本语义对齐,完成跨模态映射建模 | ✅ | ❌ |
| Driving Question Answering (驾驶问答) | 通过大规模问答样本,微调模型的驾驶常识与交通规则理解 | ✅ | ❌ |
| Agent-Env-Ego Interaction (交互建模) | 对交通参与者进行轨迹预测,用于交互训练 | ✅ | ❌ |
| Trajectory Planning Tuning (轨迹规划微调) | 生成适配当前场景的自车规划轨迹 | ✅ | ✅ |
2.2 训练与推理的 Prompt 解析
2.2.1 训练专用 Prompt 辅助模型能力内化
分层特征对齐、驾驶问答、交互建模这三类 Prompt,本质上是模型训练阶段的“教学信号”。微调完成后,视觉-语言对齐能力、驾驶常识与交互博弈逻辑已固化在模型权重中。鉴于推理阶段模型已具备上述能力,故无需再额外引入此类引导性的 Prompt。
2.2.2 轨迹规划 Prompt 的双重作用
Trajectory Planning Tuning Prompt 是唯一同时在训练和推理阶段生效的任务型 Prompt。如论文所述:
‘This prompt is used in the training stage 3 for trajectory planning tuning, where the model is supervised to generate a 3-second driving plan based on structured multi-modal context.’
- 训练阶段:作为监督学习的输入模板,引导模型学习 “结构化多模态上下文→轨迹输出” 的映射关系,并基于模型预测轨迹与真实轨迹数据计算 Loss。
- 推理阶段:作为任务输入接口,将当前场景、自车状态、历史轨迹与导航指令封装为结构化输入。这确保了推理输入分布与训练阶段对齐,从而稳定输出安全可行的自车轨迹。
三、 占位符的跨模态特征注入
<SCENE>、<TRACK>、<MAP> 在文本 Prompt 中作为占位标记存在。它们是将视觉检测结果转成自然语言后拼接进 Prompt 的吗?答案是否定的。因为自然语言难以无损表达复杂的空间几何与目标的运动学信息, 它们并非用于承载自然语言语义的文本标记,而是作为跨模态特征注入的位置锚点,直接在连续的 Embedding 空间中完成特征的融合。附:下图为笔者论文阅读笔记,

跨模态特征注入流程:
- 视觉特征提取:多视角图像经 Vision Encoder 编码,输出 Scene、Track、Map 三类高维连续特征向量,完整保留场景的空间几何拓扑与目标运动学信息。
- 跨模态投影对齐:通过轻量级 MLP 投影网络,将上述视觉特征映射至与 Qwen-Instruct 词表 Embedding 维度一致的特征空间,实现维度与语义的对齐。
- 占位符定位与替换:文本 Prompt 中的边界标记(如
<scene_start><SCENE><scene_end>)在 Token 序列中预留了固定槽位。模型前向传播时,系统精确定位这些锚点槽位,将投影后的连续视觉向量直接覆写占位符的原始 Embedding,实现视觉信息的无缝注入。 - 自回归轨迹生成:融合后的完整输入序列(System Prompt + 视觉特征 + 自车状态 + 导航指令)送入 Qwen-Instruct LLM,模型以自回归方式逐 Token 预测,最终由下游解析模块解码出自车轨迹的坐标序列。
四、 总结
OpenDriveVLA 通过分层 Prompt 设计与基于占位符的跨模态注入机制,并非简单地将感知结果“翻译”给大模型,而是通过 Embedding 级的特征对齐与注入,让 LLM 直接“看见”并“理解”连续的物理世界。
(本文为CSDN原创,转载请注明出处。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)